Mineração de Dados em Grandes Bancos de Dados Geográficos
|
|
|
- Mafalda Lima Balsemão
- 8 Há anos
- Visualizações:
Transcrição
1 Programa de Ciência e Tecnologia para Gestão de Ecosistemas Ação "Métodos, modelos e geoinformação para a gestão ambiental Mineração de Dados em Grandes Bancos de Dados Geográficos Marcos Corrêa Neves Corina Costa Freitas Gilberto Câmara Relatório Técnico Novembro,

2 SUMÁRIO TEMA...ERRO! ERRO! INDICADOR NÃO DEFINIDO. 1 INTRODUÇÃO OBJETIVOS REVISÃO BIBLIOGRÁFICA Data Mining Clustering Métodos hierárquicos Métodos de particionamento Métodos para Spatial Data Mining CLARA CLARANS Clustering com Restrição de contiguidade METODOLOGIA RESULTADOS ESPERADOS CRONOGRAMA...32 REFERÊNCIAS BIBLIOGRÁFICAS

3 1 INTRODUÇÃO A disseminação do uso de meios eletrônicos na sociedade moderna tem gerado um grande volume de dados. Sistemas gerenciadores de banco de dados estão presentes na maioria das organizações públicas e empresas de médio e grande porte, contendo os mais diferentes dados sobre produtos, fornecedores, clientes, empregados, etc. Além disso, avanços em aquisição de dados, desde um simples leitor de código de barras até sistemas de sensoriamento remoto, geram mais e mais dados. A cada dia, mais operações corriqueiras são automatizadas, e a cada nova transação, como compras com cartão de crédito, operações bancárias, terminais de venda, novos registros correspondentes são armazenados. Todo este considerável conjunto de dados contém uma preciosa quantidade de informação. Entretanto, muitos dos bancos de dados atuais, contém um volume tal de registros, que inviabiliza a possibilidade de análise humana. Esta dificuldade criou a necessidade do desenvolvimento de ferramentas para auxiliar a análise, possibilitando a transformação de grandes volumes de dados em informação útil (Goebel e Gruenwald, 1999). Este contexto, motivou a criação de um novo campo de pesquisa que busca desenvolver meios de prospecção de conhecimento em grandes bases de dados, também chamado de Knowledge Discovery in Database (KDD). Fayyad et al. (1996) definiu KDD como sendo um processo não trivial de identificação de padrões válidos, novos, úteis e implicitamente presentes em grandes volumes de dados. Inicialmente as ferramentas de prospecção de conhecimento foram empregadas em ambientes de pesquisa e experimentação; atualmente já estão disponíveis no mercado vários produtos, sobretudo voltados para aplicações comerciais (Goebel e Gruenwald, 1999) (Ester, Kriegel et al., 1999). O núcleo central do processo de prospecção de conhecimento é composto pelos métodos de mineração de dados (Data Mining). Mineração de dados consiste da busca, automática ou semi-automática, em grandes quantidades de dados com o objetivo de descobrir padrões importantes, utilizando algoritmos com eficiência computacional aceitável (Ng and Han, 1994; Ester et al., 1999). Enquanto KDD é um processo interativo e iterativo, envolvendo muitos passos, Data Mining, em particular, é o passo onde são aplicados algoritmos voltados para atingir objetivos específicos, produzindo uma enumeração particular de padrões nos dados (Goebel e Gruenwald, 1999). Portanto, em um processo completo de descoberta de conhecimento, podem ser utilizados diversos algoritmos de Data Mining. Spatial Data Mining, ou mineração de dados espaciais, é uma extensão de Data Mining voltada para domínios de aplicação onde a consideração da dimensão espacial é essencial na extração de conhecimento. De forma similar, existem desenvolvimentos de - 3 -

4 trabalhos considerando o contexto temporal (Temporal Data Mining) e ainda, considerando ambas as dimensões (Spatio-Temporal Data Mining). Roddick et al.(2001) apresenta uma seleção de trabalhos nestas áreas. A principal diferença entre Data Mining e Spatial Data Mining é a consideração dos relacionamentos espaciais existentes entre as entidades do mundo real. Ester et al. (1999) apresenta três tipos básicos de relações espaciais, as quais denomina: relações topológicas, de distâncias e de direção. Algumas relações topológicas entre dois objetos espaciais, A e B, são: A sobrepõe B, A contém B, A está contido em B, A é disjunto de B, A igual a B e A é adjacente a B (A vizinho a B). As relações de vizinhança são importantes em estudos onde os objetos espaciais em análise são do tipo área. Neste tipo de dado espacial, cada objeto é representado espacialmente por polígonos. Neste caso, as relações de vizinhança fornecem a estrutura espacial e são utilizadas como critério de proximidade, já que a distância euclidiana, não pode ser diretamente empregada, como no caso de objetos espaciais representados por pontos. A importância da consideração dos relacionamentos de vizinhança, está no fato que para processos espaciais, a medida associada a um local, ou objeto, tende a ser similar às medidas em locais próximos. Este fato é conhecido como a 1 ª lei da geografia, especificada por Topler (Zeitoune et al. 2001). Nos algoritmos aplicados em Spatial data Mining, para que possamos avaliar a dependência espacial, teremos que utilizar a informação sobre os relacionamentos de vizinhança dos objetos (Ester et al. 1999). Métodos estatísticos tradicionais presumem a independência amostral. Ao aplicarmos, por exemplo, o método estatístico de regressão linear em dados espaciais, os resultados obtidos serão falseados para o teste de ajuste do modelo, bem como, para os intervalos de confiança dos coeficientes do modelo e das predições (Bailey e Gatrell, 1995) (Anselin e Bao, 1997) (Neter et al., 1989). Buttenfield et al. (2001) afirma que as aplicações correntes em prospecção de conhecimento aplicados a dados geográficos (GKD), geralmente utilizam representações simples para objetos geográficos e para os relacionamentos espaciais. Os métodos de Spatial Data Mining deveriam reconhecer tipos mais complexos de dados (linhas e polígonos), uma vez que nem sempre os objetos espaciais podem ser reduzidos a um ponto, e os métodos deveriam considerar os relacionamentos espaciais entre os objetos (distância não-euclidiana, direção, conectividade). Koperski et al.(1997) diz que o crucial desafio para Spatial Data Mining é a eficiência dos algoritmos empregados devido ao volume de dados espaciais, complexidade dos tipos de dados e aos métodos de acesso aos dados espaciais. Neste contexto, nosso trabalho tem a intenção de contribuir com o desenvolvimento de métodos para Spatial Data Mining que considere objetos espaciais do tipo área; os relacionamentos entre os objetos (especificamente, relações de vizinhança); e a dependência espacial existente entre eles
 apresenta três tipos básicos de relações espaciais, as quais denomina: relações topológicas, de distâncias e de direção.")
5 2 OBJETIVOS Objetivo geral do trabalho é: Desenvolver métodos de Spatial Data Mining que sejam aplicáveis a objetos espaciais com representação poligonal, considerando as relações de vizinhanças entres os objetos e a dependência espacial entre os atributos. Objetivos específicos: Adaptar, implementar e avaliar um conjunto de algoritmos de Spatial Data Mining combinando diferentes abordagens e métodos de clustering espacial aplicáveis a objetos do tipo área. - Analisar a influência da dependência espacial no comportamento dos procedimentos de Spatial Data Mining. verificando a viabilidade de utilizar medidas de autocorrelação espacial como elemento direcional no processo de clustering, na escolha e eliminação de atributos e na avaliação dos procedimentos. - Desenvolver um algoritmo de Spatial Data Mining que considere a informação de dependência espacial. - Aplicar os métodos de Spatial Data Mining a um caso prático, envolvendo grandes volumes de dados espaciais

6 3 REVISÃO BIBLIOGRÁFICA Esta seção está dividida em 4 partes. Na primeira, situamos Data Mining dentro do processo de prospecção de conhecimento e apresentamos o papel dos métodos de clustering nos procedimentos de mineração. Na segunda parte, enfocamos clustering, apresentando alguns conceitos e métodos básicos. Na terceira, são mostrados os métodos de clustering propostos para Spatial Data Mining. E por fim, na última parte, são apresentados as diferentes abordagens para clustering com restrição espacial e um método específico baseado no algoritmo da árvore geradora mínima. 3.1 Data Mining Para melhor situarmos Data Mining em relação a KDD, é apresentado a seguir, a seqüência completa de passos existentes em um processo de prospecção de conhecimento, conforme Goebel e Gruenwald (1999): i) entendimento do domínio da aplicação; ii) definição das metas do processo; iii) seleção do conjunto de dados alvo; iv) integração e checagem dados; v) limpeza, pré-processamento e transformação dos dados; vi) escolha dos algoritmos apropriados de Data Mining; vii) interpretação e visualização dos resultados; viii) teste dos resultados; e ix) uso e manutenção do conhecimento descoberto. As ferramentas correntemente disponíveis para a execução das tarefas de Data Mining são genéricas e derivadas de outras áreas do conhecimento, em especial, da Estatística e Inteligência Artificial. As técnicas utilizadas, podem ser classificadas como: métodos estatísticos, redes neurais, regras de indução, árvores de decisão, séries temporais, análise exploratória de dados, algoritmos genéticos, conjuntos nebulosos, Rough sets. Portando, Data Mining compreende uma coleção de técnicas, capazes de auxiliar a obtenção de informação adicional. Diferentes métodos de mineração atendem - 6 -

7 a diferentes propósitos, cada qual, oferecendo vantagens e desvantagens (Goebel e Gruenwald, 1999). Uma das técnicas estatísticas utilizadas em Data Mining é Clustering (Análise de Cluster, ou agrupamentos). Clustering é um ramo da Estatística Multivariada que engloba métodos utilizados para descobrir estruturas em um conjunto complexo de dados. O objetivo principal de clustering é separar objetos ou observações em classes naturais de forma que os elementos pertencentes a um mesmo grupo tenham um alto grau de semelhança ou similaridade, enquanto que, quaisquer elementos pertencentes a grupos distintos, tenham pouca semelhança entre si (Andeberg, 1973). O atrativo dos métodos de clustering para tarefas de mineração de dados é a sua habilidade de extrair estruturas diretamente dos dados, sem nenhum conhecimento prévio. Métodos de clustering para Data Mining, são utilizados com modificações em relação aos algoritmos tradicionais, sobretudo visando aumentar sua eficiência, diante da quantidade de objetos a serem classificados no contexto de Data Mining (Ng e Han, 1994) (Koperski, et al., 1997) (Zhang et al., 2001). Métodos de clustering também têm sido utilizados em análise exploratória de dados espaciais (ESDA) e em procedimentos de regionalização. Nestes, os algoritmos de clustering com restrição de contigüidade espacial são utilizados com o objetivo de agrupar áreas homogêneas em regiões contíguas (Openshaw e Wymer, 1995) (Assunção, 2000). Wise et al.(1997) apresenta algumas razões para se agrupar unidades espaciais básicas, como setores censitários, formando regiões maiores: aumento da representatividade nos valores dos atributos e taxas associadas; redução dos efeitos da imprecisão nos valores das variáveis; redução dos erros associados ao posicionamento geográfico de eventos; e redução no custo de análise dos dados. 3.2 Clustering A tarefa básica de clustering é classificar um conjunto de objetos em subconjuntos segundo um ou mais critérios apropriados. Os critérios mais comuns adotados em clustering são: homogeneidade e separação. A homogeneidade refere-se a objetos pertencentes a um mesmo cluster, que devem ser tão similares quanto possível; Enquanto que a separação, está relacionada a objetos de diferentes clusters, que devem ser distintos entre si, tanto quanto possível (Maravalle et al., 1997). A qualidade do resultado obtido pela utilização de técnicas de Clustering depende de uma série de definições coerentes por parte do usuário. Alguns elementos importantes presentes no desenvolvimento dos procedimentos de Clustering são: escolha dos atributos; homogeneização das variáveis; medidas de dissimilaridade; critérios de agrupamento; escolha do algoritmo; e definição do número de clusters

8 Métodos de clustering normalmente utilizam uma medida de dissimilaridade para avaliar o grau de semelhança entre dois objetos durante o processo de agrupamento. Muitas vezes, esta medida é apresentada como sendo a distância entre dois objetos. A combinação entre a escolha das variáveis, transformações das variáveis (homogeneização) e as medidas de dissimilaridade escolhidas, é que traduz operacionalmente o termo associação natural entre objetos (Andeberg, 1973). Métricas comumente utilizadas são: a Distância Euclidiana, dada pela seguinte forma: 1/ 2 2 ( xik x jk ) p d ij =, k= 1 e a distância quarteirão (city block), dada por: d ij = p k = 1 x ik x jk, onde: d ij é a dissimilaridade entre os objetos i e j; x ik é o valor é o valor do atributo k para o objeto i, e x jk é o valor é o valor do atributo k para o objeto j. Os algoritmos de clustering podem ser classificados em duas categorias principais: métodos hierárquicos e métodos de particionamento ou relocação iterativa. A seguir, apresentaremos os principais métodos dentro destas categorias Métodos hierárquicos Métodos hierárquicos podem ser aglomerativos ou divisivos. Nos métodos hierárquicos aglomerativos, inicialmente, cada objeto é um cluster e, a cada passo do procedimento, os dois clusters mais próximos (similares) são fundidos, até que, ao final, exista somente um grande cluster, contendo todos os objetos. Este algoritmo é chamado de hierárquico pois ele permite obter vários níveis de agrupamento. Uma informação gráfica, contendo o histórico das fusões é facilmente gerada neste método. Este dispositivo gráfico recebe o nome de dendrograma (Andeberg, 1973; Gordon, 1981; Richards, 1995). A Figura 1, mostra vários estágios para um processamento fictício. Nesta figura é possível acompanhar o desenvolvimento do algoritmo para um caso simples, onde existem apenas duas variáveis (espaço bidimensional). De forma análoga, métodos hierárquicos divisivos, inicia-se com todos os objetos pertencendo a um único agrupamento, o qual vai sendo sucessivamente dividido, até que no final, cada cluster contenha um único elemento. Esta variação é - 8 -
.")
9 mais dispendiosa computacionalmente e raramente utilizada. Em Sensoriamento Remoto, ela é praticamente descartada pelo grande número de objetos, pixels, existentes nas imagens de satélite (Richards, 1995). Os passos do algoritmo hierárquico aglomerativo são: Passo 1: 1 Iniciar com n clusters, cada um contendo um objeto. Passo 2: 2 Calcular as dissimilaridades entre os objetos. Passo3 : Procurar o par de clusters com menor dissimilaridade; Passo 4: 4 Recalcular a dissimilaridade do cluster fundido com os demais clusters. Passo 5: 5 Repete os passos 3 e 4, n 1vezes

10 Figura 1: Algoritmo hierárquico aglomerativo. (adaptado de Richads

11 O cálculo da dissimilaridade entre clusters no algoritmo hierárquico apresentado acima e ilustrado na Figura 1, utiliza um ponto central para representar o cluster, definido pelos valores médios dos atributos dos objetos membros de cada cluster. No método hierárquico chamado de Ligação Única, a dissimilaridade entre dois clusters é igual a menor dissimilaridade existente entre dois objetos quaisquer, um objeto pertencente a cada um dos clusters envolvidos. Este método, elimina o cálculo das médias dos atributos a cada passo do algoritmo, mas apresenta o inconveniente de produzir clusters de forma alongada, efeito denominado de encadeiamento (Andeberg, 1973). Outra variação do método hierárquico aglomerativo, utiliza o valor da maior dissimilaridade entre dois objetos de clusters distintos como medida de dissimilaridade entre estes clusters (Ligação Completa) (Andeberg, 1973; Gordon, 1981). Embora os métodos hierárquicos sejam empregados com sucesso em aplicações biológicas, como taxinomia de animais e plantas, existe uma deficiência inerente a este método. Nele não existe uma revisão dos clusters durante a execução do procedimento, ou seja, no método hierárquico aglomerativo, uma vez realizado a fusão de dois objetos dentro de um mesmo cluster, os objetos nunca mais são separados, permanecendo até o final do procedimento, sempre juntos em um mesmo cluster. De forma análoga, no hierárquico divisivo, uma vez separados dois objetos, eles nunca mais serão agrupados em um mesmo cluster (Ng e Han, 1994) Métodos de particionamento Os métodos de particionamento buscam encontrar, iterativamente, a melhor partição dos n objetos em k grupos. Freqüentemente os k clusters encontrados pelos métodos de particionamento são de melhor qualidade (grupos internamente mais homogêneos) do que os k clusters produzidos pelos métodos hierárquicos. Devido a este melhor desempenho, os algoritmos de particionamento têm sido mais investigados e utilizados (Ng e Han, 1994). Os métodos de particionamento mais utilizados são baseados em um ponto central (média dos atributos dos objetos - k-médias) (Zhang et al., 2001) ou em um objeto representativo para o cluster (k-medoids) (Kaufman e Rousseeuw, 1990). Método de particionamento K-médias K-médias é um método bastante difundido, existindo muitas variações propostas na literatura, recebendo diversos nomes como, isodata ou migração de médias. Ele é muito utilizado em Sensoriamento Remoto, com a finalidade de executar procedimentos de classificação não supervisionada de imagens de satélite (Schowengerdt, 1997). Este método exige a definição prévia do número de clusters e do posicionamento inicial dos centros dos k clusters no espaço de atributos. As variações e melhorias propostas para o método ficam por conta da definição inicial dos centros dos clusters e de avaliações realizadas no final ou durante o processo de agrupamento (Richards 1995; Zhang et al. 2001). Os passos básicos de um algoritmo baseado em k-médias, são:

12 Passo 1: 1 Escolha de k objetos para serem centros iniciais dos k clusters. Passo 2: 2 Cada objeto é associado a um cluster, para o qual a dissimilaridade entre objeto e o centro deste cluster é a menor que as demais. Passo 3: 3 Os centros dos clusters são recalculados, redefinindo cada um, em função dos atributos de todos os objetos pertencentes ao cluster; Passo 4: 4 Volta ao passo 2, até que os centros dos clusters se estabilizem. A cada iteração, os objetos são agrupados em função do centro do cluster mais próximo e, por conseqüência, os centros dos clusters são reavaliados (passo 3). Isto provoca no espaço de atributo um deslocamento dos centros médios. O algoritmo é interrompido quando as médias não mais são deslocadas, ou há uma insignificante relocação de objetos entre os clusters. A Figura 2, ilustra o desenvolvimento do método, para o mesmo caso simples apresentado anteriormente
.")
13 Figura 2: Algoritmo k médias

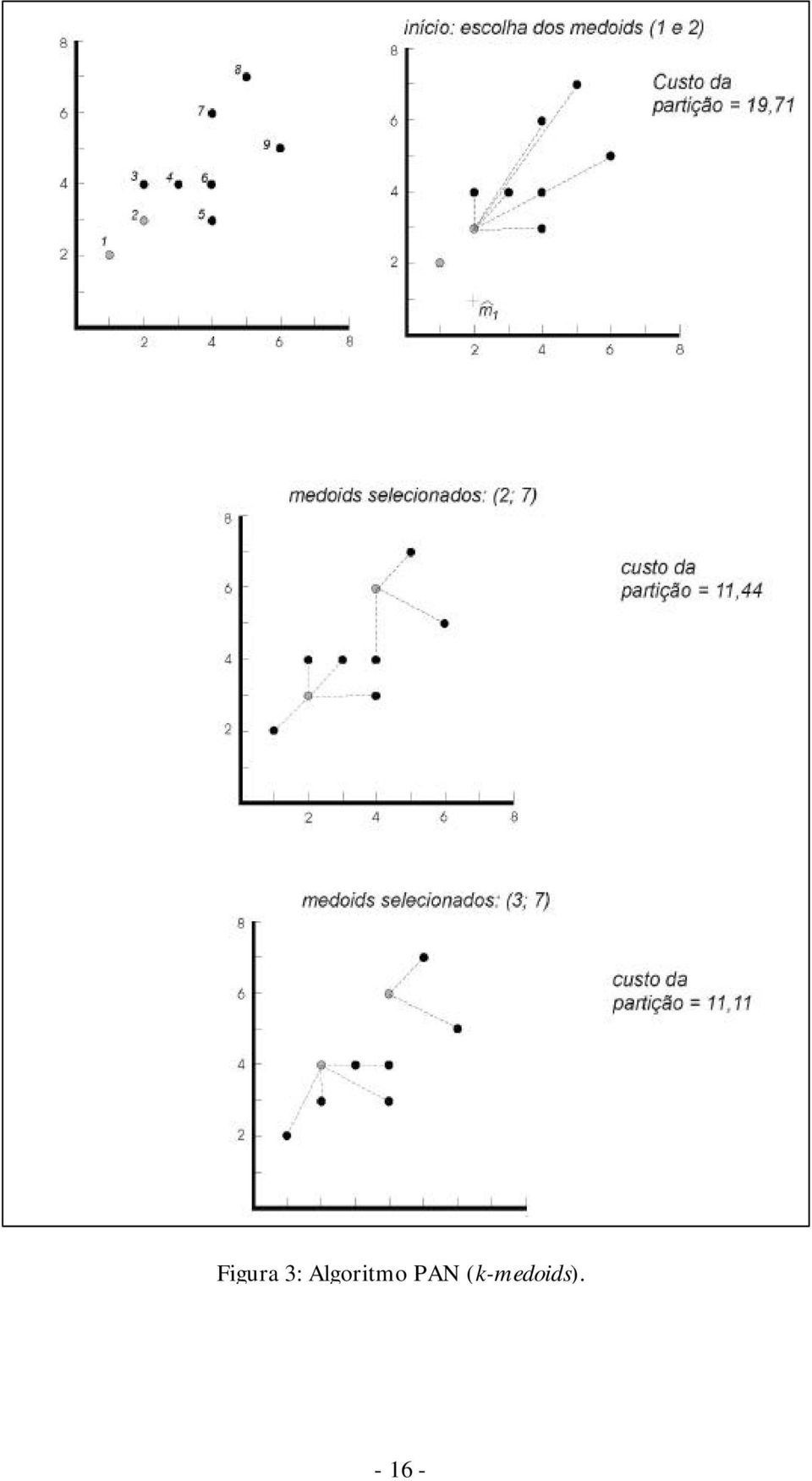
14 Método de particionamento K-medoids Outro grupo de métodos de particionamento, são baseados k-medoids. A diferença básica em relação ao k-médias está na utilização de um objeto representativo, chamado de medoid, localizado mais ao centro possível do cluster, ao invés de um centro médio. O método de clustering PAM (Particioning Around Medoids), baseado em k-medoid, foi proposto Kaufman and Rousseeuw (1990). Ele realiza em cada passo uma busca exaustiva pela troca de um dos k medoids previamente selecionados por um dos demais (n-k) objetos, que minimize as dissimilaridades entre os k medoids e os membros dos k clusters. Para apresentarmos o algoritmo PAN, passaremos a considerar o problema de classificação como a busca por uma partição ótima do conjunto de dados. Do ponto de vista da otimização, temos que: { 1,2,3, K n} V =,, { C, C, 2, } π =, f (π ), 1 K C k onde: V é o conjunto de n objetos a serem particionados em classes, C i é o cluster i, π é uma dada partição em k clusters e f (π) é uma função objetivo que fornece uma medida de qualidade da partição. A qualidade da partição está geralmente ligada aos critérios de homogeneidade interna (referente aos elementos de um mesmo cluster), e separação (referente aos elementos de clusters distintos). Dentro do contexto de otimização, o objetivo final é conseguir uma partição que maximize (ou minimize, dependendo do caso) a função objetivo. Um exemplo simples para uma função objetivo é dado por: f (π ) Di. = k i= 1 onde, Di é a soma das distâncias euclidianas entre cada membro de um cluster i e o medoid correspondente. Se os cluster são homogêneos e compactos, o que é desejável, os valores de Di para cada cluster tendem a ser pequenos. A função objetivo, neste caso, deve ser minimizada, para produzirmos um bom resultado dentro de um processo de otimização. A seguir, são apresentados os passos do algoritmo utilizado no PAN, onde a função objetivo utilizada, é a mesma apresentada anteriormente: Passos do algoritmo PAN: Passo 1: 1 Selecionar arbitrariamente k medoids entre os n objetos
 objetos, que minimize as dissimilaridades entre os k medoids e os membros")
15 Passo 2: Agrupar os objetos em função do medoid mais similar, definindo a partição corrente, π, e calcular ( ) corrente f π. corrente Passo 3: Verificar todas as trocas possíveis entre um medoid e um objeto não selecionado, escolhendo um novo conjunto de k medoids, que produza uma partição, π, tal que o valor para a f ( π ) é o menor dentre todas as possibilidades. Passo 4: Se o f ( ) f ( π ) π < corrente, efetivar a troca, π corrente = π ; e voltar ao passo 2. Passo 5: Se não, fim do procedimento. Ng and Han (1994) afirma que os métodos baseados em k-medoids apresentam duas vantagens em relação aos métodos baseados em centros médios: são mais robustos à presença de outliers (objetos fora do padrão dos demais objetos) e são independentes da ordem pela qual os objetos são examinados. A Figura 3, apresenta a evolução das partições, em busca de uma partição com custo mínimo. Por procurar exaustivamente, no passo 3, pelo conjunto que k medoids que minimiza as dissimilaridades, PAN não é eficiente, principalmente quando aplicado a grandes volumes de dados. Para cada medoid, são investigados (n-k) possibilidades de troca; considerando todos os medoids, temos um total de k(n-k) trocas. Como exemplo, em um caso, envolvendo 1000 objetos e 10 clusters, seriam avaliadas trocas em cada iteração do algoritmo
 afirma que os métodos baseados em k-medoids apresentam duas vantagens em relação aos métodos baseados em centros médios: são mais robustos à presença de outliers (objetos fora do")
16 Figura 3: Algoritmo PAN (k-medoids)
17 3.3 Métodos para Spatial Data Mining CLARA O algoritmo CLARA (Clustering Large Applications) utiliza uma amostra contendo m dos n objetos e realiza o algoritmo PAN sobre ela, de forma a determinar os k medoids que minimiza f ( π ) utilizando apenas m objetos. Então, definidos os medoids, os (n m) objetos restantes são agrupados, em função da menor dissimilaridade em relação ao conjunto de medoids. Se a amostra é bem realizada, e consequentemente representativa, os medoids determinados sobre a amostra tendem a se aproximar no espaço de atributos dos medoids que seriam obtidos considerando todo o conjunto de n objetos. É sugerido que na execução deste algoritmo, se realize múltiplas amostras para escolher dentre elas, a amostra para qual o resultado apresente uma menor dissimilaridade média entre os k- clusters (Ng e Han, 1994) (Koperski et al., 1997). O algoritmo CLARA, obviamente, é bem mais rápido que o PAN, pois examina apenas um subconjunto de k medoids possíveis, mas a qualidade do resultado é evidentemente dependente da qualidade da amostra e sua aplicabilidade cresce junto com o número de objetos a serem analisados. Segundo Kaufman [1990 #75] (citado por (Ng and Han 1994)), resultados experimentais indicam que 5 amostras contendo ( k) objetos cada uma, produzem resultados satisfatórios. Algoritmo CLARA: Passo 1: 1 Para i = 1 até 5, repetir os seguintes passos: Passo 2: Realizar uma amostra de m objetos; Passo 3: 3 Executar o algoritmo PAN, sobre os m objetos da amostra, determinando os k medoids ótimos. Passo 4: Agrupar os demais ( n m ) objetos restantes, em função da menor dissimilaridade em relação aos k medoids. Passo 5: Calcular o valor de f ( π ) mínimo corrente; i, considerando todos os n objetos e comparar o valor Passo 6: Retornar ao passo 1, para a próxima iteração. Passo 7: 7 Escolher dentre as cinco partições, a correspondente ao mínimo corrente; fim

18 CLARANS Ng e Han (1994) propõe um terceiro algoritmo baseado em k-medoids denominado de CLARANS (Clustering Large Applications based on Randomized Search). Assim como o CLARA, este algoritmo realiza a procura por um conjunto ótimo de k medoids apenas em um subconjunto das possíveis combinações de objetos, porém este subconjunto não é fixo e nem pré-determinado por uma amostra como no CLARA, e sim, ele executa uma busca contínua e com certa aleatoriedade por ótimos locais. Este algoritmo produz resultados melhores que o CLARA e converge para o resultado mais rapidamente que o PAN, sendo por isto indicado pelo autor como um método eficiente para Spatial Data Mining. Para explicar o mecanismo de busca do CLARANS e comparar sua eficiência em relação ao CLARA e ao PAN, (Ng e Han, 1994) faz a seguinte abstração, utilizando grafos. Cada nó do grafo corresponde a uma partição, representada por um conjunto de k medoids. Dois nós do grafo, Ni e N j, são vizinhos se Ni I N j, resultar em um conjunto com ( k 1) objetos. Ou seja, dois nós são vizinhos, se eles diferem de apenas um medoid. Desta forma, o número de vizinhos para cada nó do grafo é igual a: n( n k) vizinhos. Isto é equivalente ao número de trocas possíveis entre um dos medoids e os demais objetos no algoritmo PAN. Como cada nó do grafo corresponde a uma partição, podemos atribuir um custo, f π, dada anteriormente. calculado por uma função objetivo, como ( ) Nesta abstração, o algoritmo PAN, pode ser visto como uma busca neste grafo, onde em cada passo, a partição corrente corresponde a um nó e procuramos por um nó vizinho, dentre todos os vizinhos possíveis, que minimize f ( π ). No algoritmo CLARA, temos um subgrafo do grafo original, contendo um subconjunto de nós, determinados pela combinação dos m objetos da amostra tomados k a k. Portando, somente uma parte menor das partições possíveis são investigadas. De forma semelhante ao método CLARA, o CLARANS, em cada passo do algoritmo, verifica apenas parte dos nós vizinhos. Porém, os vizinhos investigados são escolhidos aleatoriamente. Desta forma, o CLARANS não realiza uma busca em um subgrafo restrito e pré-definido por uma amostra, e sim, investiga parte dos nós vizinhos definidos dinamicamente, durante a sua execução. Os passos do algoritmo CLARANS, são descritos a seguir: Passo 1: 1 Entrar com os parâmetros: número de mínimos locais (num_min_local) e número máximo de vizinhos avaliados por iteração (num_max_vizinhos). Passo 2: 2 Fazer i = 1 e custo_mínimo = valor grande (custo mínimo. armazena menor custo durante o procedimento). Passo 3: 3 Arbitrar um nó do grafo como nó corrente

19 Passo 4: 4 Fazer j = 1. Passo 5: 5 Escolher aleatoriamente um nó vizinho, N, e calcular o custo diferencial entre os dois nós. Passo 6: 6 Se N tem menor custo, fazer de N o nó corrente e voltar ao passo 4. Passo 7: 7 Caso contrário; incrementar j de uma unidade. Se para o passo 5. j num _ max_ vizinhos, ir Passo 8: 8 Caso contrário (j > num_max_vizinhos); comparar custo do nó corrente com o custo_mínimo. Se menor, fazer custo_mínimo igual ao custo do nó corrente e fazer do nó corrente o melhor_nó (armazena a melhor partição). Passo 9: 9 Incrementar i de uma unidade. Se informar melho_nó, e fim do procedimento. i num_ local, voltar ao passo 3; senão, O algoritmo acima, procura em cada iteração por um nó vizinho de menor custo (passo 4 ao passo 7), até encontrá-lo ou atingir o número máximo de tentativas dado por num_max_vizinhos. Se um nó vizinho é encontrado, nova busca é iniciada a partir dele. Ao se verificar o número máximo de vizinhos, sem identificar um nó de menor custo, o nó corrente é declarado com sendo um mínimo local e a variável i, utilizada para contagem do número de mínimos locais, é incrementada. Atingido o número de mínimos locais definido por num_min_locais, o algoritmo termina, informando o nó com a menor f (π ) como a melhor partição. A justificativa para o bom desempenho do CLARANS está no fato que o grafo correspondente apresenta um número elevado de nós e muitas conexões entre eles, apresentado uma multiplicidade de caminhos, que levam a um mesmo nó. Assim é muito provável que o mínimo local encontrado pelo algoritmo, seja uma solução de qualidade aceitável. Existem estudos para definir os valores dos parâmetros de entrada do algoritmo, num_max_vizinhos e num_min_locais, de forma a estabelecer uma relação de compromisso entre o tempo de processamento e a qualidade do resultado (Ng e Han, 1994)
. Passo 9: 9 Incrementar i de uma unidade.")
20 3.4 Clustering com Restrição de contiguidade Nos algoritmos apresentados na seção anterior e na maioria dos estudos envolvendo o uso de métodos de clustering aplicados à Spatial Data Mining são empregados a distância euclidiana para medir as dissimilaridades entre os objetos e são restritos à representação por ponto. Para aplicarmos métodos de clustering também a objetos espaciais do tipo área, onde a distância euclidiana não pode ser empregada diretamente, teremos que utilizar os relacionamentos de vizinhança entre os objetos. Trabalhos envolvendo regionalização e clustering com restrição de contigüidade espacial, aplicam métodos de clustering em objetos espaciais representados tanto por ponto quanto por área. Nesta seção, veremos algumas abordagens utilizadas nestes trabalhos, além de um algoritmo específico, chamado de árvore geradora mínima. Segundo Gordon (1996) existem três abordagens para a classificação com restrição de contigüidade espacial. Na primeira delas, o procedimento de classificação é realizado em dois estágios. No primeiro estágio, não é considerada a informação espacial e um procedimento de clustering convencional é executado, utilizando somente os atributos não-espaciais. No segundo estágio, os clusters são reavaliados observando as relações de vizinhança dos objetos. Assim, objetos similares agrupados em um cluster no primeiro estágio mas sem contigüidade espacial, serão separados no segundo estágio formando regiões distintas. Este tipo de abordagem permite identificar, entre os dois estágios, se objetos similares estão ou não espalhados por toda a área de abrangência do estudo, o que pode ser utilizado como uma rápida avaliação da dependência espacial entre os objetos. Outro aspecto positivo assinalado por Opensahw e Wymer (1995) é referente ao controle da similaridade entre os objetos de uma mesma região, garantido pelo primeiro estágio do processo de regionalização. O inconveniente desta abordagem está na falta de controle sobre o número de regiões resultantes. Para os casos onde existam pequena dependência espacial, haverá a tendência a produzir muitas regiões (Wise et al., 1997). Na segunda abordagem, a dissimilaridade entre os objetos é avaliada considerando simultaneamente a posição geográfica dos objetos e seus atributos não-espaciais. As coordenadas do centróide são consideradas atributos adicionais. São utilizados algoritmos convencionais de clustering, onde a avaliação da dissimilaridade contém duas componentes ponderadas, uma para o espaço de atributos e, a outra componente, para a distância geográfica. Se o peso dado para a componente correspondente à distância geográfica for forte o suficiente, os grupos resultantes do processo de classificação serão contíguos. Este tipo de abordagem possui a dificuldade de se estabelecer os pesos ideais para as duas componentes. Esta abordagem é utilizada pelo sistema SAGE (Spatial Analysis in a GIS Environment) em seu algoritmo de regionalização. Ele utiliza um procedimento de clustering baseado

21 no método de particionamento k-médias, cuja a função objetivo é formada a partir de três critérios (Wise et al., 1997): a) homogeneidade: regiões formados por objetos similares, considerando atributos não-espaciais; campacidade: as coordenadas dos objetos membros são próximas; igualdade: a soma do valores de um determinado atributo, considerando todos os objetos membros (população, por exemplo), são semelhantes para todas as regiões. A função objetivo ( f o ) do algoritmo de regionalização do SAGE é definida como uma soma ponderada, dada por (Ma et al., 1997): f = w f + w f + w f, o h h c c i i onde: - w h, wc e wi são os pesos referentes às três componentes homogeneidade, compacidade e igualdade; - f h : é uma medida da variância de um ou mais atributos dos objetos nas regiões; - f c : é uma medida da soma das distâncias dos objetos aos centros dos clusters, considerando todas as regiões; - f i : é uma medida do desvio entre as somas dos valores de um atributo dos objetos membros das regiões em relação ao valor médio. A componente correspondente ao critério igualdade foi considerada no SAGE, para estabelecer no fim do processo, regiões com valores totais próximos de um atributo qualquer, de modo a possibilitar comparações mais apropriadas entre as regiões (exemplo: taxa de mortalidade por câncer). O atributo é definido pelo usuário do SAGE. Openshaw et al. (1998) critica a abordagem utilizada no procedimento de regionalização do sistema SAGE e em outros trabalhos anteriores que utilizam abordagens semelhantes (Cliff et al., 1975) (Martin, 1998). Nestes métodos, cada componente da função objetivo, é uma função isolada e utilizam em seus cálculos variáveis que medem fenômenos distintos, medido em unidades diferentes e necessitam ser apropriadamente padronizadas. A qualidade da solução depende dos pesos atribuídos às componentes e como cada uma delas são padronizadas. Openshaw et al. (1998) afirma que uma estratégia melhor e mais simples é selecionar uma das funções componentes como a função objetivo e tratar os outros critérios como restrições de igualdade ou desigualdade (maior que, menor ou igual a, etc.) definindo de forma explícita seus valores (ex.: população mínima dentro de uma região). A forma mais simples, segundo os autores, para tratar com restrições em problemas de otimização é a adicionar à função objetivo, funções de penalização que refletem a violação das restrições. Esta solução foi utilizada pelos autores no desenvolvimento do seu sistema de zoneamento automático denominado de ZDES
22 A terceira abordagem de clustering com restrição de contiguidade espacial considerara a informação espacial utilizando dispositivos auxiliares, grafo ou matriz, para representar a relação de vizinhança dos objetos. No caso da utilização de uma matriz, denominada matriz de contigüidade, C, cada elemento da matriz, c ij, indica se os objetos i e j são contíguos ou não. Desta forma, c ij = 0 para objetos não vizinhos, e c ij = 1 para objetos contíguos. De forma equivalente, quando são utilizados grafos, cada objeto é representado por um vértice ou nó. Somente quando os objetos são vizinhos, existe uma aresta ligando os dois vértices. A Figura 4 mostra a representação da estrutura espacial pela matriz C e por meio de um grafo correspondente. A forma pela qual as aplicações de clustering espacial usam grafos para explicitar as relações espaciais de vizinhança é distinta da forma utilizada anteriormente, na seção , para explicar a execução do algoritmo CLARANS. Lá, cada nó do grafo representava uma partição (um conjunto de k medoids), enquanto que agora, cada nó representa um objeto espacial. Maravalle et al. (1997) destaca a utilização de grafos como forma explicitar os relacionamentos de vizinhança nos procedimentos de clustering com restrição de contigüidade. Dentro desta terceira abordagem, os algoritmos de clustering tradicionais precisão ser adaptados para o uso em procedimentos com restrição de contigüidade espacial. Nos algoritmos hierárquicos aglomerativos, por exemplo, dois clusters mais similares são aglutinados somente se existem, dois objetos contíguos, um em cada cluster. Nos algoritmos de relocação iterativa adaptados para a restrição de contigüidade, um objeto só pode ser relocado em clusters que possuam ao menos um objeto contíguo a ele (Gordon, 1996). 0 1 C = P2 P1 P4 P3 Figura 4: Representação da relação espacial de vizinhança por matriz e grafo
23 Do ponto de vista da implementação dos métodos com restrição de contiguidade, a verificação da existência de objetos contíguos é bem mais fácil de ser executada nos algoritmos hierárquicos. Uma vez definido os dois clusters com menor dissimilaridade, Ci e Cj, teríamos alguns passos adicionais, procurando se nos vizinhos de cada um dos objetos de Ci, existe um objeto pertencente a Cj. Encontrado um vizinho pertencente a Cj, a busca é interrompida e a fusão efetivada. Não encontrando, o próximo par de clusters de menor dissimilaridade é avaliado. Nos algoritmos de particionamento, a verificação da contiguidade espacial é mais complexa, pois ela é dependente da ordem pela qual os objetos vão sendo associados aos clusters, necessitando de reavaliações até que todos os objetos possam ser atribuídos a um dos clusters contíguos. Assunção et al., (2000) também utiliza grafos para propor um método de clustering com restrição de contiguidade espacial, dentro do contexto de otimização, e contornando o problema apontado acima. A seguir, serão apresentados, os conceitos e as idéias principais utilizadas neste trabalho. Um conglomerado (cluster) é um subconjunto de áreas idealmente homogêneas. Um cluster pode ser formados por um único objeto. Um cluster é conectado se, para toda subdivisão do cluster, em dois subconjuntos disjuntos e complementares, existe pelo menos uma área de um subconjunto vizinha de pelo menos uma área do outro subconjunto. O que é equivalente ao conceito que vínhamos utilizando para um cluster contíguo. Um cluster que contenha apenas um objeto, também é considerado contíguo. E, por fim, uma região é dita particionada em clusters espaciais, quando as áreas foram agrupadas em clusters disjuntos e internamente conectados. Da teoria de grafos, temos que: - Um caminho entre dois vértices (nós), v1 e v k, é uma seqüência de nós, v 1, v2, v3, K, v k, que são conectados pelas arestas: ( v 1, v2),( v2, v3), K,( v k 1, v k ). - Um grafo é conexo, se existe ao menos um caminho ligando dois nós quaisquer do grafo. - Um circuito em um grafo, é um caminho onde os nós, inicial e final, são os mesmos. Ou, há dois caminhos diferentes, ligando dois nós. - Uma árvore é um grafo conexo, que não contém circuitos. - Uma árvore geradora para um grafo G, é uma árvore que contém todos os nós de G. Logo, o número de arestas é igual ao número de nós de G, menos uma unidade (n 1)
24 Um mapa contento objetos do tipo área é representado por um grafo de forma que cada nó da árvore representa um objeto do mapa e os objetos vizinhos no mapa são nós ligados por arestas no grafo. A cada aresta, é então, associado um custo, correspondendo a dissimilaridade entre os objetos. A idéia principal é eliminar sucessivamente as arestas mais caras, de forma a reduzir o grafo original a uma árvore geradora, ou seja, sem circuitos, contendo as arestas de menor custo. A árvore resultante deste procedimento é denominada árvore geradora mínima. A principal importância da árvore geradora mínima é que, ao removermos dela qualquer aresta, o grafo é dividido em duas sub-árvores desconectadas. Portanto, a árvore geradora mínima, representa uma condição que a partir da qual, estaremos particionando os objetos espaciais em regiões distintas. A Figura 5 representa a construção de uma árvore geradora mínima para um exemplo hipotético. A largura das arestas que ligam os nós, são proporcionais às dissimilaridades entre as áreas. Assim, do grafo original, foram eliminadas sucessivamente as arestas mais largas, até se obter um subgrafo conectado e sem circuitos de custo mínimo, correspondente a árvore geradora mínima. Figura 5: Construção da árvore geradora mínima. O algoritmo para a construção da árvore geradora mínima é apresentado por Assunção et al. (2000). Esse algoritmo parte do grafo correspondente ao mapa de objetos, conexo e com custos associados às arestas previamente calculados. A idéia é construir a árvore geradora mínima de uma forma recursiva, a partir de uma árvore inicial T 1, formada de apenas um nó, e adicionando nós progressivamente, de forma que novas árvores intermediárias vão sendo geradas ( T2, T3, T4 K) até chegarmos na árvore final, T n
25 Uma versão desse algoritmo, em 3 passos, é apresentado a seguir: Passo 1: 1 Escolher qualquer nó, v i, pertencente ao conjunto completo de n nós, V, fazendo: T = { } k = T 1 v i Passo 2: 2 Encontrar a aresta de menor custo que ligue qualquer nó pertencente a Tk a um outro nó, não pertencente a T k, e acrescentar este nó à árvore, gerando uma nova árvore, T k + 1. Passo 3: 3 Repita o passo 2, até que todos os nós de V tenham sido incluídos. Ao final da execução do procedimento descrito por este algoritmo, temos a árvore geradora mínima, que contém todos os nós, representando todos os objetos. Neste ponto, cada aresta que for eliminada, dividirá a árvore em dois subgrafos desconexos, correspondendo a dois clusters espaciais (regiões), tais como definidos anteriormente. Portanto, a classificação propriamente dita, se dará com a escolha e eliminação de determinadas arestas a partir da árvore geradora mínima. Este processo de escolha e eliminação de aresta corresponde, segundo o autor, a uma poda da árvore geradora mínima. Assunção et al. (2000) apresenta dois critérios para a escolha e eliminação das arestas. O primeiro critério, que é uma escolha mais natural, é a eliminação sucessiva das arestas de custo mais elevado, até obter o número desejado de regiões. A cada eliminação é gerado um novo subgrafo conexo e desconectado dos demais. O custo do grafo particionado é a soma dos custos de todos os subgrafos. Este critério de poda possui o inconveniente de separar clusters contendo um número variável de elementos, ou seja, alguns agrupamentos numerosos e outros com poucos objetos. No segundo critério apresentado pelo autor, o custo das arestas é alterado na fase de poda da árvore geradora mínima, passando a ser dado por: Custo da aresta l = SSTO G SSA l, onde: 1) SSTO G é soma dos quadrados dos desvios, associada a árvore, G, dada por: SSTO G = m n ( xij x j ) j= 1 i= 1 2, sendo: n, o número total de objetos (nós) em G; x ij, o atributo j do objeto i; m, o número de atributos considerados; x,o valor médio do atributo j, dado por: j x 1 = n j x ij n i=
26 2) SSA l é a soma das duas parcelas obtidas da soma dos quadrados dos desvios das duas sub-árvores, G a e G b, geradas pela retirada da aresta l da árvore G: SSA = SSTO + SSTO l Ga Gb Para calcular a soma dos quadrados dos desvios para as duas sub-árvores, são calculados os valores médios dos m atributos, tal como feito para o cálculo de SSTO G, porém, considerando-se apenas os atributos referentes aos objetos pertencentes a cada sub-árvore de G, G a e G b. As podas seguintes são feitas de forma recursiva, escolhendo sempre a aresta de menor custo. As Figuras 6, 7, 8 e 9 foram retiradas do exemplo de aplicação do algoritmo de regionalização, utilizando a árvore geradora mínima apresentado em Assunção (2000). Neste exemplo, o procedimento de regionalização foi aplicado aos 353 setores censitários do município de São João do Meriti (RJ), utilizando algumas variáveis do censo de A Figura 6 mostra o grafo correspondente ao mapa dos setores censitários do município, onde cada setor aparece como um nó e os setores vizinhos, conectados. A Figura 7, mostra a árvore geradora mínima. A Figura 8, mostra as diversas sub-árvores após a retirada de 16 arestas. A Figura 9, ilustra as 17 regiões obtidas. Nesta revisão bibliográfica, nós destacamos o algoritmo da árvore geradora mínima, por ele ser aplicável a objetos do tipo área e utilizar explicitamente as relações de vizinhança dos objetos. Além disso, o fato do processo de otimização, propriamente dito, ocorrer após a construção da árvore geradora mínima, faz com que o número de arestas investigadas seja bem reduzido em comparação ao número de arestas existentes no grafo original, diminuindo o custo computacional utilizado no processo de otimização. No algoritmo PAN, em cada iteração eram investigadas k(n-k) possibilidades de troca entre os k medoids e os (n-k) objetos restantes. Nós utilizamos, anteriormente, um número fictício de objetos e clusters (1.000 objetos em 10 clusters) para compararmos a eficiência do PAN à outros métodos. Isto resultou em possibilidades de troca em apenas uma iteração do PAN. Se fôssemos utilizar um método baseado na árvore geradora mínima, na primeira poda, seriam investigadas 999 arestas; na segunda 998, e assim sucessivamente, resultando no valor total em possibilidades de poda. Este valor é próximo ao número de partições investigadas em apenas uma iteração do algoritmo PAN. Ainda que, para uma comparação precisa, tenhamos que considerar o custo computacional adicional para a geração da árvore geradora mínima e que as funções objetivo associada a cada nova partição nos dois métodos não são iguais, a diferença na quantidade de possibilidades a serem investigadas a cada iteração, indicam que o uso da árvore geradora mínima é promissor no contexto de Spatial Data Mining
27 coordenada y 7.476*10^ *10^ *10^ *10^6 Grafo/Mapa de Sao Joao do Meriti coordenada x 1 2 Figura 6: Grafo correspondente aos setores censitários de São João do Meriti. (extraído de Assunção, coordenada y 7.476*10^ *10^ *10^ *10^ Arvore Geradora Minima Sao Joao do Meriti coordenada x 1 2 Figura 7: Árvore geradora mínima. (extraído de Assunção, 2000.)
28 coordenada y 7.477*10^ *10^ *10^ coordenada x Figura 8: Particionado em 17 regiões (sub-árvores). (extraído de Assunção, 2000) Figura 7: Árvore geradora mínima. (extraído de Assunção, 2000)
29 4 - METODOLOGIA Para atingir os objetivos deste trabalho de pesquisa, pretendemos desenvolver um ambiente de experimentação, adaptar e implementar diferentes métodos de clustering espacial, utilizando dados reais e experimentais, verificando a eficiência e o comportamento geral dos métodos. As etapas do desenvolvimento do trabalho, bem como, os dados que serão utilizados, são apresentados a seguir: i) Escolha e preparação dos dados Um dos passos do processo de KDD, anterior ao passo de aplicação dos algoritmos de mineração, propriamente dito, é a preparação dos dados. No nosso caso, estamos desenvolvendo métodos específicos de Data Mining, e os dados serão preparados de uma forma isolada e prévia à aplicação dos procedimentos de mineração. Os objetos espaciais utilizados neste estudo de técnicas de Spatial Data Mining, serão os municípios brasileiros incluídos na bacia hidrográfica do Rio São Francisco. Estes municípios pertencem a cinco estados (Alagoas, Bahia, Minas Gerais, Pernambuco e Sergipe). Os atributos não-espaciais selecionados, estão diretamente e indiretamente ligados ao uso e demanda de água, fonte de poluição hídrica, doenças com vinculação hídrica e condições socioeconômicas das populações, entre outros. Estes dados são oriundos de diferentes bases de dados: censo demográfico (Instituto Brasileiro de Geografia e Estatística - IBGE), censo agropecuário (IBGE), divisão municipal (IBGE) e dados de mortalidade por doença (Sistema Único de Saúde - SUS). ii) Construção de um ambiente de experimentação O ambiente de experimentação tem como objetivo suportar o desenvolvimento e avaliação dos algoritmos de clustering espacial. Ele deverá permitir a interface com o usuário, para a definição dos parâmetros e dos atributos, dados, além de dispositivos de visualização dos dados (atributos, geometria) e dos resultados dos procedimentos. Este ambiente será desenvolvido utilizando sistema operacional Windows, linguagem de programação C++ e a biblioteca TerraLIB. A TerraLib é uma biblioteca de componentes de Sistemas de Informação Geográfica (SIG) que está sendo desenvolvida pelo INPE e parceiros. O objetivo da TerraLib é suportar desenvolvimentos de uma nova geração de aplicações em SIG (Câmara, Vinhas et al. 2001). iii) Escolha dos métodos a serem desenvolvidos Serão desenvolvidos um conjunto de métodos de clustering com restrição espacial, utilizando as abordagens apresentadas em (Gordon, 1996) (em dois estágios e consideração direta das relações de vizinhança), combinando com métodos de particionamento, hierárquico aglomerativo e árvore geradora mínima. Os métodos de
Extensão do WEKA para Métodos de Agrupamento com Restrição de Contigüidade
 Extensão do WEKA para Métodos de Agrupamento com Restrição de Contigüidade Carlos Eduardo R. de Mello, Geraldo Zimbrão da Silva, Jano M. de Souza Programa de Engenharia de Sistemas e Computação Universidade
Extensão do WEKA para Métodos de Agrupamento com Restrição de Contigüidade Carlos Eduardo R. de Mello, Geraldo Zimbrão da Silva, Jano M. de Souza Programa de Engenharia de Sistemas e Computação Universidade
MINERAÇÃO DE DADOS APLICADA. Pedro Henrique Bragioni Las Casas pedro.lascasas@dcc.ufmg.br
 MINERAÇÃO DE DADOS APLICADA Pedro Henrique Bragioni Las Casas pedro.lascasas@dcc.ufmg.br Processo Weka uma Ferramenta Livre para Data Mining O que é Weka? Weka é um Software livre do tipo open source para
MINERAÇÃO DE DADOS APLICADA Pedro Henrique Bragioni Las Casas pedro.lascasas@dcc.ufmg.br Processo Weka uma Ferramenta Livre para Data Mining O que é Weka? Weka é um Software livre do tipo open source para
ADM041 / EPR806 Sistemas de Informação
 ADM041 / EPR806 Sistemas de Informação UNIFEI Universidade Federal de Itajubá Prof. Dr. Alexandre Ferreira de Pinho 1 Sistemas de Apoio à Decisão (SAD) Tipos de SAD Orientados por modelos: Criação de diferentes
ADM041 / EPR806 Sistemas de Informação UNIFEI Universidade Federal de Itajubá Prof. Dr. Alexandre Ferreira de Pinho 1 Sistemas de Apoio à Decisão (SAD) Tipos de SAD Orientados por modelos: Criação de diferentes
Universidade Tecnológica Federal do Paraná UTFPR Programa de Pós-Graduação em Computação Aplicada Disciplina de Mineração de Dados
 Universidade Tecnológica Federal do Paraná UTFPR Programa de Pós-Graduação em Computação Aplicada Disciplina de Mineração de Dados Prof. Celso Kaestner Poker Hand Data Set Aluno: Joyce Schaidt Versão:
Universidade Tecnológica Federal do Paraná UTFPR Programa de Pós-Graduação em Computação Aplicada Disciplina de Mineração de Dados Prof. Celso Kaestner Poker Hand Data Set Aluno: Joyce Schaidt Versão:
UNIVERSIDADE FEDERAL DE SANTA CATARINA GRADUAÇÃO EM SISTEMAS DE INFORMAÇÃO DEPARTAMENTO DE INFORMÁTICA E ESTATÍSTICA DATA MINING EM VÍDEOS
 UNIVERSIDADE FEDERAL DE SANTA CATARINA GRADUAÇÃO EM SISTEMAS DE INFORMAÇÃO DEPARTAMENTO DE INFORMÁTICA E ESTATÍSTICA DATA MINING EM VÍDEOS VINICIUS DA SILVEIRA SEGALIN FLORIANÓPOLIS OUTUBRO/2013 Sumário
UNIVERSIDADE FEDERAL DE SANTA CATARINA GRADUAÇÃO EM SISTEMAS DE INFORMAÇÃO DEPARTAMENTO DE INFORMÁTICA E ESTATÍSTICA DATA MINING EM VÍDEOS VINICIUS DA SILVEIRA SEGALIN FLORIANÓPOLIS OUTUBRO/2013 Sumário
Banco de Dados Aula 1 Introdução a Banco de Dados Introdução Sistema Gerenciador de Banco de Dados
 Banco de Dados Aula 1 Introdução a Banco de Dados Introdução Um Sistema Gerenciador de Banco de Dados (SGBD) é constituído por um conjunto de dados associados a um conjunto de programas para acesso a esses
Banco de Dados Aula 1 Introdução a Banco de Dados Introdução Um Sistema Gerenciador de Banco de Dados (SGBD) é constituído por um conjunto de dados associados a um conjunto de programas para acesso a esses
INTELIGÊNCIA ARTIFICIAL Data Mining (DM): um pouco de prática. (1) Data Mining Conceitos apresentados por
: um pouco de prática. (1) Data Mining Conceitos apresentados por") INTELIGÊNCIA ARTIFICIAL Data Mining (DM): um pouco de prática (1) Data Mining Conceitos apresentados por 1 2 (2) ANÁLISE DE AGRUPAMENTOS Conceitos apresentados por. 3 LEMBRE-SE que PROBLEMA em IA Uma busca
INTELIGÊNCIA ARTIFICIAL Data Mining (DM): um pouco de prática (1) Data Mining Conceitos apresentados por 1 2 (2) ANÁLISE DE AGRUPAMENTOS Conceitos apresentados por. 3 LEMBRE-SE que PROBLEMA em IA Uma busca
Módulo 4. Construindo uma solução OLAP
 Módulo 4. Construindo uma solução OLAP Objetivos Diferenciar as diversas formas de armazenamento Compreender o que é e como definir a porcentagem de agregação Conhecer a possibilidade da utilização de
Módulo 4. Construindo uma solução OLAP Objetivos Diferenciar as diversas formas de armazenamento Compreender o que é e como definir a porcentagem de agregação Conhecer a possibilidade da utilização de
Gerenciamento de Projetos Modulo II Ciclo de Vida e Organização do Projeto
 Gerenciamento de Projetos Modulo II Ciclo de Vida e Organização do Projeto Prof. Walter Cunha falecomigo@waltercunha.com http://waltercunha.com PMBoK Organização do Projeto Os projetos e o gerenciamento
Gerenciamento de Projetos Modulo II Ciclo de Vida e Organização do Projeto Prof. Walter Cunha falecomigo@waltercunha.com http://waltercunha.com PMBoK Organização do Projeto Os projetos e o gerenciamento
No mundo atual, globalizado e competitivo, as organizações têm buscado cada vez mais, meios de se destacar no mercado. Uma estratégia para o
 DATABASE MARKETING No mundo atual, globalizado e competitivo, as organizações têm buscado cada vez mais, meios de se destacar no mercado. Uma estratégia para o empresário obter sucesso em seu negócio é
DATABASE MARKETING No mundo atual, globalizado e competitivo, as organizações têm buscado cada vez mais, meios de se destacar no mercado. Uma estratégia para o empresário obter sucesso em seu negócio é
ROTEIRO PARA ELABORAÇÃO DE PROJETOS
 APRESENTAÇÃO ROTEIRO PARA ELABORAÇÃO DE PROJETOS Breve histórico da instituição seguido de diagnóstico e indicadores sobre a temática abrangida pelo projeto, especialmente dados que permitam análise da
APRESENTAÇÃO ROTEIRO PARA ELABORAÇÃO DE PROJETOS Breve histórico da instituição seguido de diagnóstico e indicadores sobre a temática abrangida pelo projeto, especialmente dados que permitam análise da
3 Classificação. 3.1. Resumo do algoritmo proposto
 3 Classificação Este capítulo apresenta primeiramente o algoritmo proposto para a classificação de áudio codificado em MPEG-1 Layer 2 em detalhes. Em seguida, são analisadas as inovações apresentadas.
3 Classificação Este capítulo apresenta primeiramente o algoritmo proposto para a classificação de áudio codificado em MPEG-1 Layer 2 em detalhes. Em seguida, são analisadas as inovações apresentadas.
Revisão de Estatística Básica:
 Revisão de Estatística Básica: Estatística: Um número é denominado uma estatística (singular). Ex.: As vendas de uma empresa no mês constituem uma estatística. Estatísticas: Uma coleção de números ou fatos
Revisão de Estatística Básica: Estatística: Um número é denominado uma estatística (singular). Ex.: As vendas de uma empresa no mês constituem uma estatística. Estatísticas: Uma coleção de números ou fatos
Classificação da imagem (ou reconhecimento de padrões): objectivos Métodos de reconhecimento de padrões
: objectivos Métodos de reconhecimento de padrões") Classificação de imagens Autor: Gil Gonçalves Disciplinas: Detecção Remota/Detecção Remota Aplicada Cursos: MEG/MTIG Ano Lectivo: 11/12 Sumário Classificação da imagem (ou reconhecimento de padrões): objectivos
Classificação de imagens Autor: Gil Gonçalves Disciplinas: Detecção Remota/Detecção Remota Aplicada Cursos: MEG/MTIG Ano Lectivo: 11/12 Sumário Classificação da imagem (ou reconhecimento de padrões): objectivos
PONTIFÍCIA UNIVERSIDADE CATÓLICA DE GOIÁS Curso Superior de Tecnologia em Análise e Desenvolvimento de Sistemas
 PONTIFÍCIA UNIVERSIDADE CATÓLICA DE GOIÁS Curso Superior de Tecnologia em Análise e Desenvolvimento de Sistemas CMP1132 Processo e qualidade de software II Prof. Me. Elias Ferreira Sala: 402 E Quarta-Feira:
PONTIFÍCIA UNIVERSIDADE CATÓLICA DE GOIÁS Curso Superior de Tecnologia em Análise e Desenvolvimento de Sistemas CMP1132 Processo e qualidade de software II Prof. Me. Elias Ferreira Sala: 402 E Quarta-Feira:
CAPÍTULO 1 - CONTABILIDADE E GESTÃO EMPRESARIAL A CONTROLADORIA
 CAPÍTULO 1 - CONTABILIDADE E GESTÃO EMPRESARIAL A CONTROLADORIA Constata-se que o novo arranjo da economia mundial provocado pelo processo de globalização tem afetado as empresas a fim de disponibilizar
CAPÍTULO 1 - CONTABILIDADE E GESTÃO EMPRESARIAL A CONTROLADORIA Constata-se que o novo arranjo da economia mundial provocado pelo processo de globalização tem afetado as empresas a fim de disponibilizar
Este documento foi elaborado sob a licença
 1 2 Este documento foi elaborado sob a licença Atribuição - Não Comercial - Sem Trabalhos Derivados Brasil (CC BY-NC-ND 4.0) Sobre este documento, você tem o direito de: Compartilhar - reproduzir, distribuir
1 2 Este documento foi elaborado sob a licença Atribuição - Não Comercial - Sem Trabalhos Derivados Brasil (CC BY-NC-ND 4.0) Sobre este documento, você tem o direito de: Compartilhar - reproduzir, distribuir
a 1 x 1 +... + a n x n = b,
 Sistemas Lineares Equações Lineares Vários problemas nas áreas científica, tecnológica e econômica são modelados por sistemas de equações lineares e requerem a solução destes no menor tempo possível Definição
Sistemas Lineares Equações Lineares Vários problemas nas áreas científica, tecnológica e econômica são modelados por sistemas de equações lineares e requerem a solução destes no menor tempo possível Definição
Sistemas Operacionais
 Sistemas Operacionais Aula 13 Gerência de Memória Prof.: Edilberto M. Silva http://www.edilms.eti.br Baseado no material disponibilizado por: SO - Prof. Edilberto Silva Prof. José Juan Espantoso Sumário
Sistemas Operacionais Aula 13 Gerência de Memória Prof.: Edilberto M. Silva http://www.edilms.eti.br Baseado no material disponibilizado por: SO - Prof. Edilberto Silva Prof. José Juan Espantoso Sumário
Departamento de Matemática - UEL - 2010. Ulysses Sodré. http://www.mat.uel.br/matessencial/ Arquivo: minimaxi.tex - Londrina-PR, 29 de Junho de 2010.
 Matemática Essencial Extremos de funções reais Departamento de Matemática - UEL - 2010 Conteúdo Ulysses Sodré http://www.mat.uel.br/matessencial/ Arquivo: minimaxi.tex - Londrina-PR, 29 de Junho de 2010.
Matemática Essencial Extremos de funções reais Departamento de Matemática - UEL - 2010 Conteúdo Ulysses Sodré http://www.mat.uel.br/matessencial/ Arquivo: minimaxi.tex - Londrina-PR, 29 de Junho de 2010.
4 Segmentação. 4.1. Algoritmo proposto
 4 Segmentação Este capítulo apresenta primeiramente o algoritmo proposto para a segmentação do áudio em detalhes. Em seguida, são analisadas as inovações apresentadas. É importante mencionar que as mudanças
4 Segmentação Este capítulo apresenta primeiramente o algoritmo proposto para a segmentação do áudio em detalhes. Em seguida, são analisadas as inovações apresentadas. É importante mencionar que as mudanças
Agrupamento de dados
 Organização e Recuperação de Informação: Agrupamento de dados Marcelo K. A. Faculdade de Computação - UFU Agrupamento de dados / 7 Overview Agrupamento: introdução Agrupamento em ORI 3 K-médias 4 Avaliação
Organização e Recuperação de Informação: Agrupamento de dados Marcelo K. A. Faculdade de Computação - UFU Agrupamento de dados / 7 Overview Agrupamento: introdução Agrupamento em ORI 3 K-médias 4 Avaliação
MODELAGEM DE DADOS MODELAGEM DE DADOS. rafaeldiasribeiro.com.br 04/08/2012. Aula 7. Prof. Rafael Dias Ribeiro. M.Sc. @ribeirord
 MODELAGEM DE DADOS PROF. RAFAEL DIAS RIBEIRO, M.Sc. @ribeirord MODELAGEM DE DADOS Aula 7 Prof. Rafael Dias Ribeiro. M.Sc. @ribeirord 1 Objetivos: Aprender sobre a modelagem lógica dos dados. Conhecer os
MODELAGEM DE DADOS PROF. RAFAEL DIAS RIBEIRO, M.Sc. @ribeirord MODELAGEM DE DADOS Aula 7 Prof. Rafael Dias Ribeiro. M.Sc. @ribeirord 1 Objetivos: Aprender sobre a modelagem lógica dos dados. Conhecer os
Factor Analysis (FACAN) Abrir o arquivo ven_car.sav. Clique Extraction. Utilizar as 10 variáveis a partir de Vehicle Type.
 Abrir o arquivo ven_car.sav. Clique Extraction. Utilizar as 10 variáveis a partir de Vehicle Type.") Prof. Lorí Viali, Dr. viali@pucrs.br; viali@mat.ufrgs.br; http://www.pucrs.br/famat/viali; http://www.mat.ufrgs.br/~viali/ Factor Analysis (FACAN) Abrir o arquivo ven_car.sav Utilizar as 10 variáveis a
Prof. Lorí Viali, Dr. viali@pucrs.br; viali@mat.ufrgs.br; http://www.pucrs.br/famat/viali; http://www.mat.ufrgs.br/~viali/ Factor Analysis (FACAN) Abrir o arquivo ven_car.sav Utilizar as 10 variáveis a
5 Extraindo listas de produtos em sites de comércio eletrônico
 5 Extraindo listas de produtos em sites de comércio eletrônico Existem diversos trabalhos direcionadas à detecção de listas e tabelas na literatura como (Liu et. al., 2003, Tengli et. al., 2004, Krüpl
5 Extraindo listas de produtos em sites de comércio eletrônico Existem diversos trabalhos direcionadas à detecção de listas e tabelas na literatura como (Liu et. al., 2003, Tengli et. al., 2004, Krüpl
SISTEMAS INTEGRADOS DE GESTÃO PAS 99:2006. Especificação de requisitos comuns de sistemas de gestão como estrutura para a integração
 Coleção Risk Tecnologia SISTEMAS INTEGRADOS DE GESTÃO PAS 99:2006 Especificação de requisitos comuns de sistemas de gestão como estrutura para a integração RESUMO/VISÃO GERAL (visando à fusão ISO 31000
Coleção Risk Tecnologia SISTEMAS INTEGRADOS DE GESTÃO PAS 99:2006 Especificação de requisitos comuns de sistemas de gestão como estrutura para a integração RESUMO/VISÃO GERAL (visando à fusão ISO 31000
Projeto de Redes Neurais e MATLAB
 Projeto de Redes Neurais e MATLAB Centro de Informática Universidade Federal de Pernambuco Sistemas Inteligentes IF684 Arley Ristar arrr2@cin.ufpe.br Thiago Miotto tma@cin.ufpe.br Baseado na apresentação
Projeto de Redes Neurais e MATLAB Centro de Informática Universidade Federal de Pernambuco Sistemas Inteligentes IF684 Arley Ristar arrr2@cin.ufpe.br Thiago Miotto tma@cin.ufpe.br Baseado na apresentação
Na medida em que se cria um produto, o sistema de software, que será usado e mantido, nos aproximamos da engenharia.
 1 Introdução aos Sistemas de Informação 2002 Aula 4 - Desenvolvimento de software e seus paradigmas Paradigmas de Desenvolvimento de Software Pode-se considerar 3 tipos de paradigmas que norteiam a atividade
1 Introdução aos Sistemas de Informação 2002 Aula 4 - Desenvolvimento de software e seus paradigmas Paradigmas de Desenvolvimento de Software Pode-se considerar 3 tipos de paradigmas que norteiam a atividade
Notas da Aula 17 - Fundamentos de Sistemas Operacionais
 Notas da Aula 17 - Fundamentos de Sistemas Operacionais 1. Gerenciamento de Memória: Introdução O gerenciamento de memória é provavelmente a tarefa mais complexa de um sistema operacional multiprogramado.
Notas da Aula 17 - Fundamentos de Sistemas Operacionais 1. Gerenciamento de Memória: Introdução O gerenciamento de memória é provavelmente a tarefa mais complexa de um sistema operacional multiprogramado.
Modelo Cascata ou Clássico
 Modelo Cascata ou Clássico INTRODUÇÃO O modelo clássico ou cascata, que também é conhecido por abordagem top-down, foi proposto por Royce em 1970. Até meados da década de 1980 foi o único modelo com aceitação
Modelo Cascata ou Clássico INTRODUÇÃO O modelo clássico ou cascata, que também é conhecido por abordagem top-down, foi proposto por Royce em 1970. Até meados da década de 1980 foi o único modelo com aceitação
Projeto e Análise de Algoritmos Projeto de Algoritmos Introdução. Prof. Humberto Brandão humberto@dcc.ufmg.br
 Projeto e Análise de Algoritmos Projeto de Algoritmos Introdução Prof. Humberto Brandão humberto@dcc.ufmg.br aula disponível no site: http://www.bcc.unifal-mg.edu.br/~humberto/ Universidade Federal de
Projeto e Análise de Algoritmos Projeto de Algoritmos Introdução Prof. Humberto Brandão humberto@dcc.ufmg.br aula disponível no site: http://www.bcc.unifal-mg.edu.br/~humberto/ Universidade Federal de
DATA WAREHOUSE. Introdução
 DATA WAREHOUSE Introdução O grande crescimento do ambiente de negócios, médias e grandes empresas armazenam também um alto volume de informações, onde que juntamente com a tecnologia da informação, a correta
DATA WAREHOUSE Introdução O grande crescimento do ambiente de negócios, médias e grandes empresas armazenam também um alto volume de informações, onde que juntamente com a tecnologia da informação, a correta
7.Conclusão e Trabalhos Futuros
 7.Conclusão e Trabalhos Futuros 158 7.Conclusão e Trabalhos Futuros 7.1 Conclusões Finais Neste trabalho, foram apresentados novos métodos para aceleração, otimização e gerenciamento do processo de renderização
7.Conclusão e Trabalhos Futuros 158 7.Conclusão e Trabalhos Futuros 7.1 Conclusões Finais Neste trabalho, foram apresentados novos métodos para aceleração, otimização e gerenciamento do processo de renderização
Engenharia de Software II
 Engenharia de Software II Aula 10 http://www.ic.uff.br/~bianca/engsoft2/ Aula 10-24/05/2006 1 Ementa Processos de desenvolvimento de software Estratégias e técnicas de teste de software (Caps. 13 e 14
Engenharia de Software II Aula 10 http://www.ic.uff.br/~bianca/engsoft2/ Aula 10-24/05/2006 1 Ementa Processos de desenvolvimento de software Estratégias e técnicas de teste de software (Caps. 13 e 14
3 Metodologia para Segmentação do Mercado Bancário
 3 Metodologia para Segmentação do Mercado Bancário Este capítulo descreve a metodologia proposta nesta dissertação para a segmentação do mercado bancário a partir da abordagem post-hoc, servindo-se de
3 Metodologia para Segmentação do Mercado Bancário Este capítulo descreve a metodologia proposta nesta dissertação para a segmentação do mercado bancário a partir da abordagem post-hoc, servindo-se de
Arquitetura de Computadores. Sistemas Operacionais IV
 Arquitetura de Computadores Sistemas Operacionais IV Introdução Multiprogramação implica em manter-se vários processos na memória. Memória necessita ser alocada de forma eficiente para permitir o máximo
Arquitetura de Computadores Sistemas Operacionais IV Introdução Multiprogramação implica em manter-se vários processos na memória. Memória necessita ser alocada de forma eficiente para permitir o máximo
Tabela de Símbolos. Análise Semântica A Tabela de Símbolos. Principais Operações. Estrutura da Tabela de Símbolos. Declarações 11/6/2008
 Tabela de Símbolos Análise Semântica A Tabela de Símbolos Fabiano Baldo Após a árvore de derivação, a tabela de símbolos é o principal atributo herdado em um compilador. É possível, mas não necessário,
Tabela de Símbolos Análise Semântica A Tabela de Símbolos Fabiano Baldo Após a árvore de derivação, a tabela de símbolos é o principal atributo herdado em um compilador. É possível, mas não necessário,
Filosofia e Conceitos
 Filosofia e Conceitos Objetivo confiabilidade para o usuário das avaliações. 1. Princípios e definições de aceitação genérica. 2. Comentários explicativos sem incluir orientações em técnicas de avaliação.
Filosofia e Conceitos Objetivo confiabilidade para o usuário das avaliações. 1. Princípios e definições de aceitação genérica. 2. Comentários explicativos sem incluir orientações em técnicas de avaliação.
AULA 6 - Operações Espaciais
 6.1 AULA 6 - Operações Espaciais Essa aula descreve as operações espaciais disponíveis no TerraView. Antes de iniciar sua descrição é necessário importar alguns dados que serão usados nos exemplos. Exercício:
6.1 AULA 6 - Operações Espaciais Essa aula descreve as operações espaciais disponíveis no TerraView. Antes de iniciar sua descrição é necessário importar alguns dados que serão usados nos exemplos. Exercício:
)HUUDPHQWDV &RPSXWDFLRQDLV SDUD 6LPXODomR
HUUDPHQWDV &RPSXWDFLRQDLV SDUD 6LPXODomR") 6LPXODomR GH6LVWHPDV )HUUDPHQWDV &RPSXWDFLRQDLV SDUD 6LPXODomR #5,6. Simulador voltado para análise de risco financeiro 3RQWRV IRUWHV Fácil de usar. Funciona integrado a ferramentas já bastante conhecidas,
6LPXODomR GH6LVWHPDV )HUUDPHQWDV &RPSXWDFLRQDLV SDUD 6LPXODomR #5,6. Simulador voltado para análise de risco financeiro 3RQWRV IRUWHV Fácil de usar. Funciona integrado a ferramentas já bastante conhecidas,
Estudo da Viabilidade da utilização de Cartão de Crédito para um Grupo de Clientes Essenciais
 Estudo da Viabilidade da utilização de Cartão de Crédito para um Grupo de Clientes Essenciais Cleyton Zanardo de Oliveira CER, DEs, UFSCar Vera Lúcia Damasceno Tomazella, DEs, UFSCar Resumo Uma única pessoa
Estudo da Viabilidade da utilização de Cartão de Crédito para um Grupo de Clientes Essenciais Cleyton Zanardo de Oliveira CER, DEs, UFSCar Vera Lúcia Damasceno Tomazella, DEs, UFSCar Resumo Uma única pessoa
TÉCNICAS DE PROGRAMAÇÃO
 TÉCNICAS DE PROGRAMAÇÃO (Adaptado do texto do prof. Adair Santa Catarina) ALGORITMOS COM QUALIDADE MÁXIMAS DE PROGRAMAÇÃO 1) Algoritmos devem ser feitos para serem lidos por seres humanos: Tenha em mente
TÉCNICAS DE PROGRAMAÇÃO (Adaptado do texto do prof. Adair Santa Catarina) ALGORITMOS COM QUALIDADE MÁXIMAS DE PROGRAMAÇÃO 1) Algoritmos devem ser feitos para serem lidos por seres humanos: Tenha em mente
IW10. Rev.: 02. Especificações Técnicas
 IW10 Rev.: 02 Especificações Técnicas Sumário 1. INTRODUÇÃO... 1 2. COMPOSIÇÃO DO IW10... 2 2.1 Placa Principal... 2 2.2 Módulos de Sensores... 5 3. APLICAÇÕES... 6 3.1 Monitoramento Local... 7 3.2 Monitoramento
IW10 Rev.: 02 Especificações Técnicas Sumário 1. INTRODUÇÃO... 1 2. COMPOSIÇÃO DO IW10... 2 2.1 Placa Principal... 2 2.2 Módulos de Sensores... 5 3. APLICAÇÕES... 6 3.1 Monitoramento Local... 7 3.2 Monitoramento
Figura 5.1.Modelo não linear de um neurônio j da camada k+1. Fonte: HAYKIN, 2001
 47 5 Redes Neurais O trabalho em redes neurais artificiais, usualmente denominadas redes neurais ou RNA, tem sido motivado desde o começo pelo reconhecimento de que o cérebro humano processa informações
47 5 Redes Neurais O trabalho em redes neurais artificiais, usualmente denominadas redes neurais ou RNA, tem sido motivado desde o começo pelo reconhecimento de que o cérebro humano processa informações
ISO/IEC 12207: Gerência de Configuração
 ISO/IEC 12207: Gerência de Configuração Durante o processo de desenvolvimento de um software, é produzida uma grande quantidade de itens de informação que podem ser alterados durante o processo Para que
ISO/IEC 12207: Gerência de Configuração Durante o processo de desenvolvimento de um software, é produzida uma grande quantidade de itens de informação que podem ser alterados durante o processo Para que
Gerenciamento de projetos. cynaracarvalho@yahoo.com.br
 Gerenciamento de projetos cynaracarvalho@yahoo.com.br Projeto 3URMHWR é um empreendimento não repetitivo, caracterizado por uma seqüência clara e lógica de eventos, com início, meio e fim, que se destina
Gerenciamento de projetos cynaracarvalho@yahoo.com.br Projeto 3URMHWR é um empreendimento não repetitivo, caracterizado por uma seqüência clara e lógica de eventos, com início, meio e fim, que se destina
Engenharia de Software III
 Engenharia de Software III Casos de uso http://dl.dropbox.com/u/3025380/es3/aula6.pdf (flavio.ceci@unisul.br) 09/09/2010 O que são casos de uso? Um caso de uso procura documentar as ações necessárias,
Engenharia de Software III Casos de uso http://dl.dropbox.com/u/3025380/es3/aula6.pdf (flavio.ceci@unisul.br) 09/09/2010 O que são casos de uso? Um caso de uso procura documentar as ações necessárias,
ATIVIDADES DE LINHA E DE ASSESSORIA
 1 ATIVIDADES DE LINHA E DE ASSESSORIA SUMÁRIO Introdução... 01 1. Diferenciação das Atividades de Linha e Assessoria... 02 2. Autoridade de Linha... 03 3. Autoridade de Assessoria... 04 4. A Atuação da
1 ATIVIDADES DE LINHA E DE ASSESSORIA SUMÁRIO Introdução... 01 1. Diferenciação das Atividades de Linha e Assessoria... 02 2. Autoridade de Linha... 03 3. Autoridade de Assessoria... 04 4. A Atuação da
PROCESSO DE DESENVOLVIMENTO DE SOFTWARE. Modelos de Processo de Desenvolvimento de Software
 PROCESSO DE DESENVOLVIMENTO DE SOFTWARE Introdução Modelos de Processo de Desenvolvimento de Software Os modelos de processos de desenvolvimento de software surgiram pela necessidade de dar resposta às
PROCESSO DE DESENVOLVIMENTO DE SOFTWARE Introdução Modelos de Processo de Desenvolvimento de Software Os modelos de processos de desenvolvimento de software surgiram pela necessidade de dar resposta às
Governança de TI. ITIL v.2&3. parte 1
 Governança de TI ITIL v.2&3 parte 1 Prof. Luís Fernando Garcia LUIS@GARCIA.PRO.BR ITIL 1 1 ITIL Gerenciamento de Serviços 2 2 Gerenciamento de Serviços Gerenciamento de Serviços 3 3 Gerenciamento de Serviços
Governança de TI ITIL v.2&3 parte 1 Prof. Luís Fernando Garcia LUIS@GARCIA.PRO.BR ITIL 1 1 ITIL Gerenciamento de Serviços 2 2 Gerenciamento de Serviços Gerenciamento de Serviços 3 3 Gerenciamento de Serviços
Projeto e Análise de Algoritmos Projeto de Algoritmos Tentativa e Erro. Prof. Humberto Brandão humberto@bcc.unifal-mg.edu.br
 Projeto e Análise de Algoritmos Projeto de Algoritmos Tentativa e Erro Prof. Humberto Brandão humberto@bcc.unifal-mg.edu.br Laboratório de Pesquisa e Desenvolvimento Universidade Federal de Alfenas versão
Projeto e Análise de Algoritmos Projeto de Algoritmos Tentativa e Erro Prof. Humberto Brandão humberto@bcc.unifal-mg.edu.br Laboratório de Pesquisa e Desenvolvimento Universidade Federal de Alfenas versão
UFGD FCA PROF. OMAR DANIEL BLOCO 6 CLASSIFICAÇÃO DE IMAGENS
 UFGD FCA PROF. OMAR DANIEL BLOCO 6 CLASSIFICAÇÃO DE IMAGENS Obter uma imagem temática a partir de métodos de classificação de imagens multi- espectrais 1. CLASSIFICAÇÃO POR PIXEL é o processo de extração
UFGD FCA PROF. OMAR DANIEL BLOCO 6 CLASSIFICAÇÃO DE IMAGENS Obter uma imagem temática a partir de métodos de classificação de imagens multi- espectrais 1. CLASSIFICAÇÃO POR PIXEL é o processo de extração
AMBIENTE PARA AUXILIAR O DESENVOLVIMENTO DE PROGRAMAS MONOLÍTICOS
 UNIVERSIDADE REGIONAL DE BLUMENAU CENTRO DE CIÊNCIAS EXATAS E NATURAIS CURSO DE CIÊNCIAS DA COMPUTAÇÃO BACHARELADO AMBIENTE PARA AUXILIAR O DESENVOLVIMENTO DE PROGRAMAS MONOLÍTICOS Orientando: Oliver Mário
UNIVERSIDADE REGIONAL DE BLUMENAU CENTRO DE CIÊNCIAS EXATAS E NATURAIS CURSO DE CIÊNCIAS DA COMPUTAÇÃO BACHARELADO AMBIENTE PARA AUXILIAR O DESENVOLVIMENTO DE PROGRAMAS MONOLÍTICOS Orientando: Oliver Mário
Metodologias de Desenvolvimento de Sistemas. Analise de Sistemas I UNIPAC Rodrigo Videschi
 Metodologias de Desenvolvimento de Sistemas Analise de Sistemas I UNIPAC Rodrigo Videschi Histórico Uso de Metodologias Histórico Uso de Metodologias Era da Pré-Metodologia 1960-1970 Era da Metodologia
Metodologias de Desenvolvimento de Sistemas Analise de Sistemas I UNIPAC Rodrigo Videschi Histórico Uso de Metodologias Histórico Uso de Metodologias Era da Pré-Metodologia 1960-1970 Era da Metodologia
Arquitetura de Rede de Computadores
 TCP/IP Roteamento Arquitetura de Rede de Prof. Pedro Neto Aracaju Sergipe - 2011 Ementa da Disciplina 4. Roteamento i. Máscara de Rede ii. Sub-Redes iii. Números Binários e Máscara de Sub-Rede iv. O Roteador
TCP/IP Roteamento Arquitetura de Rede de Prof. Pedro Neto Aracaju Sergipe - 2011 Ementa da Disciplina 4. Roteamento i. Máscara de Rede ii. Sub-Redes iii. Números Binários e Máscara de Sub-Rede iv. O Roteador
Introdução aos Sistemas de Informação Geográfica
 Introdução aos Sistemas de Informação Geográfica Mestrado Profissionalizante 2015 Karla Donato Fook karladf@ifma.edu.br IFMA / DAI Análise Espacial 2 1 Distribuição Espacial A compreensão da distribuição
Introdução aos Sistemas de Informação Geográfica Mestrado Profissionalizante 2015 Karla Donato Fook karladf@ifma.edu.br IFMA / DAI Análise Espacial 2 1 Distribuição Espacial A compreensão da distribuição
Prof. Júlio Cesar Nievola Data Mining PPGIa PUCPR
 Uma exploração preliminar dos dados para compreender melhor suas características. Motivações-chave da exploração de dados incluem Ajudar na seleção da técnica correta para pré-processamento ou análise
Uma exploração preliminar dos dados para compreender melhor suas características. Motivações-chave da exploração de dados incluem Ajudar na seleção da técnica correta para pré-processamento ou análise
Grafos. Redes Sociais e Econômicas. Prof. André Vignatti
 Grafos Redes Sociais e Econômicas Prof. André Vignatti Teoria dos Grafos e Redes Sociais Veremos algumas das idéias básicas da teoria dos grafos Permite formular propriedades de redes em uma linguagem
Grafos Redes Sociais e Econômicas Prof. André Vignatti Teoria dos Grafos e Redes Sociais Veremos algumas das idéias básicas da teoria dos grafos Permite formular propriedades de redes em uma linguagem
Complemento II Noções Introdutória em Redes Neurais
 Complemento II Noções Introdutória em Redes Neurais Esse documento é parte integrante do material fornecido pela WEB para a 2ª edição do livro Data Mining: Conceitos, técnicas, algoritmos, orientações
Complemento II Noções Introdutória em Redes Neurais Esse documento é parte integrante do material fornecido pela WEB para a 2ª edição do livro Data Mining: Conceitos, técnicas, algoritmos, orientações
REDUZINDO AS QUEBRAS ATRAVÉS DA MANUTENÇÃO PROFISSIONAL
 REDUZINDO AS QUEBRAS ATRAVÉS DA MANUTENÇÃO PROFISSIONAL Luiz Rodrigo Carvalho de Souza (1) RESUMO O alto nível de competitividade exige que as empresas alcancem um nível de excelência na gestão de seus
REDUZINDO AS QUEBRAS ATRAVÉS DA MANUTENÇÃO PROFISSIONAL Luiz Rodrigo Carvalho de Souza (1) RESUMO O alto nível de competitividade exige que as empresas alcancem um nível de excelência na gestão de seus
CAPÍTULO 3 - TIPOS DE DADOS E IDENTIFICADORES
 CAPÍTULO 3 - TIPOS DE DADOS E IDENTIFICADORES 3.1 - IDENTIFICADORES Os objetos que usamos no nosso algoritmo são uma representação simbólica de um valor de dado. Assim, quando executamos a seguinte instrução:
CAPÍTULO 3 - TIPOS DE DADOS E IDENTIFICADORES 3.1 - IDENTIFICADORES Os objetos que usamos no nosso algoritmo são uma representação simbólica de um valor de dado. Assim, quando executamos a seguinte instrução:
MATERIAL DIDÁTICO: APLICAÇÕES EMPRESARIAIS SISTEMA DE APOIO À DECISÃO (SAD)
") AULA 07 MATERIAL DIDÁTICO: APLICAÇÕES EMPRESARIAIS SISTEMA DE APOIO À DECISÃO (SAD) JAMES A. O BRIEN MÓDULO 01 Páginas 286 à 294 1 AULA 07 SISTEMAS DE APOIO ÀS DECISÕES 2 Sistemas de Apoio à Decisão (SAD)
AULA 07 MATERIAL DIDÁTICO: APLICAÇÕES EMPRESARIAIS SISTEMA DE APOIO À DECISÃO (SAD) JAMES A. O BRIEN MÓDULO 01 Páginas 286 à 294 1 AULA 07 SISTEMAS DE APOIO ÀS DECISÕES 2 Sistemas de Apoio à Decisão (SAD)
MÓDULO 6 INTRODUÇÃO À PROBABILIDADE
 MÓDULO 6 INTRODUÇÃO À PROBBILIDDE Quando estudamos algum fenômeno através do método estatístico, na maior parte das vezes é preciso estabelecer uma distinção entre o modelo matemático que construímos para
MÓDULO 6 INTRODUÇÃO À PROBBILIDDE Quando estudamos algum fenômeno através do método estatístico, na maior parte das vezes é preciso estabelecer uma distinção entre o modelo matemático que construímos para
Universidade Federal de Goiás UFG Campus Catalão CAC Departamento de Engenharia de Produção. Sistemas ERP. PCP 3 - Professor Muris Lage Junior
 Sistemas ERP Introdução Sucesso para algumas empresas: acessar informações de forma rápida e confiável responder eficientemente ao mercado consumidor Conseguir não é tarefa simples Isso se deve ao fato
Sistemas ERP Introdução Sucesso para algumas empresas: acessar informações de forma rápida e confiável responder eficientemente ao mercado consumidor Conseguir não é tarefa simples Isso se deve ao fato
Requisitos de Software
 Requisitos de Software Centro de Informática - Universidade Federal de Pernambuco Kiev Gama kiev@cin.ufpe.br Slides originais elaborados por Ian Sommerville e adaptado pelos professores Márcio Cornélio,
Requisitos de Software Centro de Informática - Universidade Federal de Pernambuco Kiev Gama kiev@cin.ufpe.br Slides originais elaborados por Ian Sommerville e adaptado pelos professores Márcio Cornélio,
Pesquisa Operacional Programação em Redes
 Pesquisa Operacional Programação em Redes Profa. Alessandra Martins Coelho outubro/2013 Modelagem em redes: Facilitar a visualização e a compreensão das características do sistema Problema de programação
Pesquisa Operacional Programação em Redes Profa. Alessandra Martins Coelho outubro/2013 Modelagem em redes: Facilitar a visualização e a compreensão das características do sistema Problema de programação
Objetivos. Processos de Software. Tópicos abordados. O processo de software. Modelos genéricos de modelos de processo de software.
 Processos de Software Objetivos Apresentar os modelos de processo de software Conjunto coerente de atividades para especificar, projetar, implementar e testar s de software Descrever os diferentes modelos
Processos de Software Objetivos Apresentar os modelos de processo de software Conjunto coerente de atividades para especificar, projetar, implementar e testar s de software Descrever os diferentes modelos
Algoritmos e Estruturas de Dados II. Trabalho Prático 2
 Algoritmos e Estruturas de Dados II Entrega: 24/09/08 Devolução: 15/10/08 Trabalho individual Prof. Jussara Marques de Almeida Trabalho Prático 2 Você foi contratado pela XOL X Online para desenvolver
Algoritmos e Estruturas de Dados II Entrega: 24/09/08 Devolução: 15/10/08 Trabalho individual Prof. Jussara Marques de Almeida Trabalho Prático 2 Você foi contratado pela XOL X Online para desenvolver
3 Metodologia e Objeto de estudo
 Metodologia e Objeto de estudo 36 3 Metodologia e Objeto de estudo Neste capítulo, através da explanação da metodologia de pesquisa e do objeto de estudo, serão definidas as questões centrais de estudo,
Metodologia e Objeto de estudo 36 3 Metodologia e Objeto de estudo Neste capítulo, através da explanação da metodologia de pesquisa e do objeto de estudo, serão definidas as questões centrais de estudo,
Seção 2/E Monitoramento, Avaliação e Aprendizagem
 Seção 2/E Monitoramento, Avaliação e Aprendizagem www.bettercotton.org Orientação Text to go here O documento Monitoramento, Avaliação e Aprendizagem da BCI proporciona uma estrutura para medir as mudanças
Seção 2/E Monitoramento, Avaliação e Aprendizagem www.bettercotton.org Orientação Text to go here O documento Monitoramento, Avaliação e Aprendizagem da BCI proporciona uma estrutura para medir as mudanças
BCC204 - Teoria dos Grafos
 BCC204 - Teoria dos Grafos Marco Antonio M. Carvalho (baseado nas notas de aula do prof. Haroldo Gambini Santos) Departamento de Computação Instituto de Ciências Exatas e Biológicas Universidade Federal
BCC204 - Teoria dos Grafos Marco Antonio M. Carvalho (baseado nas notas de aula do prof. Haroldo Gambini Santos) Departamento de Computação Instituto de Ciências Exatas e Biológicas Universidade Federal
Algoritmos e Estrutura de Dados III. Árvores
 Algoritmos e Estrutura de Dados III Árvores Uma das mais importantes classes de estruturas de dados em computação são as árvores. Aproveitando-se de sua organização hierárquica, muitas aplicações são realizadas
Algoritmos e Estrutura de Dados III Árvores Uma das mais importantes classes de estruturas de dados em computação são as árvores. Aproveitando-se de sua organização hierárquica, muitas aplicações são realizadas
5 Mecanismo de seleção de componentes
 Mecanismo de seleção de componentes 50 5 Mecanismo de seleção de componentes O Kaluana Original, apresentado em detalhes no capítulo 3 deste trabalho, é um middleware que facilita a construção de aplicações
Mecanismo de seleção de componentes 50 5 Mecanismo de seleção de componentes O Kaluana Original, apresentado em detalhes no capítulo 3 deste trabalho, é um middleware que facilita a construção de aplicações
INSTITUTO FLORENCE DE ENSINO COORDENAÇÃO DE PÓS-GRADUAÇÃO CURSO DE PÓS-GRADUAÇÃO EM (TÍTULO DO PROJETO) Acadêmico: Orientador:
 Acadêmico: Orientador:") INSTITUTO FLORENCE DE ENSINO COORDENAÇÃO DE PÓS-GRADUAÇÃO CURSO DE PÓS-GRADUAÇÃO EM (TÍTULO DO PROJETO) Acadêmico: Orientador: São Luis 2015 (TÍTULO DO PROJETO) (NOME DO ALUNO) Projeto de Pesquisa do Programa
INSTITUTO FLORENCE DE ENSINO COORDENAÇÃO DE PÓS-GRADUAÇÃO CURSO DE PÓS-GRADUAÇÃO EM (TÍTULO DO PROJETO) Acadêmico: Orientador: São Luis 2015 (TÍTULO DO PROJETO) (NOME DO ALUNO) Projeto de Pesquisa do Programa
Podemos encontrar uma figura interessante no PMBOK (Capítulo 7) sobre a necessidade de organizarmos o fluxo de caixa em um projeto.
 sobre a necessidade de organizarmos o fluxo de caixa em um projeto.") Discussão sobre Nivelamento Baseado em Fluxo de Caixa. Item aberto na lista E-Plan Podemos encontrar uma figura interessante no PMBOK (Capítulo 7) sobre a necessidade de organizarmos o fluxo de caixa em
Discussão sobre Nivelamento Baseado em Fluxo de Caixa. Item aberto na lista E-Plan Podemos encontrar uma figura interessante no PMBOK (Capítulo 7) sobre a necessidade de organizarmos o fluxo de caixa em
Engenharia de Software e Gerência de Projetos Prof. Esp. André Luís Belini Bacharel em Sistemas de Informações MBA em Gestão Estratégica de Negócios
 Engenharia de Software e Gerência de Projetos Prof. Esp. André Luís Belini Bacharel em Sistemas de Informações MBA em Gestão Estratégica de Negócios Cronograma das Aulas. Hoje você está na aula Semana
Engenharia de Software e Gerência de Projetos Prof. Esp. André Luís Belini Bacharel em Sistemas de Informações MBA em Gestão Estratégica de Negócios Cronograma das Aulas. Hoje você está na aula Semana
Conteúdo. Disciplina: INF 02810 Engenharia de Software. Monalessa Perini Barcellos. Centro Tecnológico. Universidade Federal do Espírito Santo
 Universidade Federal do Espírito Santo Centro Tecnológico Departamento de Informática Disciplina: INF 02810 Prof.: (monalessa@inf.ufes.br) Conteúdo 1. Introdução 2. Processo de Software 3. Gerência de
Universidade Federal do Espírito Santo Centro Tecnológico Departamento de Informática Disciplina: INF 02810 Prof.: (monalessa@inf.ufes.br) Conteúdo 1. Introdução 2. Processo de Software 3. Gerência de
TRANSMISSÃO DE DADOS Prof. Ricardo Rodrigues Barcelar http://www.ricardobarcelar.com
 - Aula 3-1. A CAMADA DE REDE (Parte 1) A camada de Rede está relacionada à transferência de pacotes da origem para o destino. No entanto, chegar ao destino pode envolver vários saltos em roteadores intermediários.
- Aula 3-1. A CAMADA DE REDE (Parte 1) A camada de Rede está relacionada à transferência de pacotes da origem para o destino. No entanto, chegar ao destino pode envolver vários saltos em roteadores intermediários.
Algoritmos: Lógica para desenvolvimento de programação de computadores. Autor: José Augusto Manzano. Capítulo 1 Abordagem Contextual
 Algoritmos: Lógica para desenvolvimento de programação de computadores Autor: José Augusto Manzano Capítulo 1 Abordagem Contextual 1.1. Definições Básicas Raciocínio lógico depende de vários fatores para
Algoritmos: Lógica para desenvolvimento de programação de computadores Autor: José Augusto Manzano Capítulo 1 Abordagem Contextual 1.1. Definições Básicas Raciocínio lógico depende de vários fatores para
A memória é um recurso fundamental e de extrema importância para a operação de qualquer Sistema Computacional; A memória trata-se de uma grande
 A memória é um recurso fundamental e de extrema importância para a operação de qualquer Sistema Computacional; A memória trata-se de uma grande região de armazenamento formada por bytes ou palavras, cada
A memória é um recurso fundamental e de extrema importância para a operação de qualquer Sistema Computacional; A memória trata-se de uma grande região de armazenamento formada por bytes ou palavras, cada
O ESPAÇO NULO DE A: RESOLVENDO AX = 0 3.2
 3.2 O Espaço Nulo de A: Resolvendo Ax = 0 11 O ESPAÇO NULO DE A: RESOLVENDO AX = 0 3.2 Esta seção trata do espaço de soluções para Ax = 0. A matriz A pode ser quadrada ou retangular. Uma solução imediata
3.2 O Espaço Nulo de A: Resolvendo Ax = 0 11 O ESPAÇO NULO DE A: RESOLVENDO AX = 0 3.2 Esta seção trata do espaço de soluções para Ax = 0. A matriz A pode ser quadrada ou retangular. Uma solução imediata
Guia de utilização da notação BPMN
 1 Guia de utilização da notação BPMN Agosto 2011 2 Sumário de Informações do Documento Documento: Guia_de_utilização_da_notação_BPMN.odt Número de páginas: 31 Versão Data Mudanças Autor 1.0 15/09/11 Criação
1 Guia de utilização da notação BPMN Agosto 2011 2 Sumário de Informações do Documento Documento: Guia_de_utilização_da_notação_BPMN.odt Número de páginas: 31 Versão Data Mudanças Autor 1.0 15/09/11 Criação
Orientação a Objetos
 1. Domínio e Aplicação Orientação a Objetos Um domínio é composto pelas entidades, informações e processos relacionados a um determinado contexto. Uma aplicação pode ser desenvolvida para automatizar ou
1. Domínio e Aplicação Orientação a Objetos Um domínio é composto pelas entidades, informações e processos relacionados a um determinado contexto. Uma aplicação pode ser desenvolvida para automatizar ou
Casos de teste semânticos. Casos de teste valorados. Determinar resultados esperados. Gerar script de teste automatizado.
 1 Introdução Testes são importantes técnicas de controle da qualidade do software. Entretanto, testes tendem a ser pouco eficazes devido à inadequação das ferramentas de teste existentes [NIST, 2002].
1 Introdução Testes são importantes técnicas de controle da qualidade do software. Entretanto, testes tendem a ser pouco eficazes devido à inadequação das ferramentas de teste existentes [NIST, 2002].
Sistema de mineração de dados para descobertas de regras e padrões em dados médicos
 Sistema de mineração de dados para descobertas de regras e padrões em dados médicos Pollyanna Carolina BARBOSA¹; Thiago MAGELA² 1Aluna do Curso Superior Tecnólogo em Análise e Desenvolvimento de Sistemas
Sistema de mineração de dados para descobertas de regras e padrões em dados médicos Pollyanna Carolina BARBOSA¹; Thiago MAGELA² 1Aluna do Curso Superior Tecnólogo em Análise e Desenvolvimento de Sistemas
Diagrama de transição de Estados (DTE)
") Diagrama de transição de Estados (DTE) O DTE é uma ferramenta de modelação poderosa para descrever o comportamento do sistema dependente do tempo. A necessidade de uma ferramenta deste tipo surgiu das
Diagrama de transição de Estados (DTE) O DTE é uma ferramenta de modelação poderosa para descrever o comportamento do sistema dependente do tempo. A necessidade de uma ferramenta deste tipo surgiu das
Sistemas Operacionais
 Sistemas Operacionais Gerência de Arquivos Edson Moreno edson.moreno@pucrs.br http://www.inf.pucrs.br/~emoreno Sumário Conceituação de arquivos Implementação do sistemas de arquivo Introdução Sistema de
Sistemas Operacionais Gerência de Arquivos Edson Moreno edson.moreno@pucrs.br http://www.inf.pucrs.br/~emoreno Sumário Conceituação de arquivos Implementação do sistemas de arquivo Introdução Sistema de
Projetos. Universidade Federal do Espírito Santo - UFES. Mestrado em Informática 2004/1. O Projeto. 1. Introdução. 2.
 Pg. 1 Universidade Federal do Espírito Santo - UFES Mestrado em Informática 2004/1 Projetos O Projeto O projeto tem um peso maior na sua nota final pois exigirá de você a utilização de diversas informações
Pg. 1 Universidade Federal do Espírito Santo - UFES Mestrado em Informática 2004/1 Projetos O Projeto O projeto tem um peso maior na sua nota final pois exigirá de você a utilização de diversas informações
Introdução a computação móvel. Middlewares para Rede de Sensores sem Fio. Uma avaliação na ótica de Adaptação ao Contexto
 Introdução a computação móvel Monografia: Middlewares para Rede de Sensores sem Fio Uma avaliação na ótica de Adaptação ao Contexto Adriano Branco Agenda Objetivo do trabalho O que é uma WSN Middlewares
Introdução a computação móvel Monografia: Middlewares para Rede de Sensores sem Fio Uma avaliação na ótica de Adaptação ao Contexto Adriano Branco Agenda Objetivo do trabalho O que é uma WSN Middlewares
UNIVERSIDADE FEDERAL DO PARANÁ UFPR Bacharelado em Ciência da Computação
 SOFT DISCIPLINA: Engenharia de Software AULA NÚMERO: 10 DATA: / / PROFESSOR: Andrey APRESENTAÇÃO O objetivo desta aula é apresentar e discutir os conceitos de coesão e acoplamento. DESENVOLVIMENTO Projetar
SOFT DISCIPLINA: Engenharia de Software AULA NÚMERO: 10 DATA: / / PROFESSOR: Andrey APRESENTAÇÃO O objetivo desta aula é apresentar e discutir os conceitos de coesão e acoplamento. DESENVOLVIMENTO Projetar
CAPÍTULO 5 CONCLUSÕES, RECOMENDAÇÕES E LIMITAÇÕES. 1. Conclusões e Recomendações
 153 CAPÍTULO 5 CONCLUSÕES, RECOMENDAÇÕES E LIMITAÇÕES 1. Conclusões e Recomendações Um Estudo de Caso, como foi salientado no capítulo Metodologia deste estudo, traz à baila muitas informações sobre uma
153 CAPÍTULO 5 CONCLUSÕES, RECOMENDAÇÕES E LIMITAÇÕES 1. Conclusões e Recomendações Um Estudo de Caso, como foi salientado no capítulo Metodologia deste estudo, traz à baila muitas informações sobre uma
APOO Análise e Projeto Orientado a Objetos. Requisitos
 + APOO Análise e Projeto Orientado a Objetos Requisitos Requisitos 2 n Segundo Larman: n São capacidades e condições às quais o sistema e em termos mais amplos, o projeto deve atender n Não são apenas
+ APOO Análise e Projeto Orientado a Objetos Requisitos Requisitos 2 n Segundo Larman: n São capacidades e condições às quais o sistema e em termos mais amplos, o projeto deve atender n Não são apenas
IA: Problemas de Satisfação de Restrições. Prof. Msc. Ricardo Britto DIE-UFPI rbritto@ufpi.edu.br
 IA: Problemas de Satisfação de Restrições Prof. Msc. Ricardo Britto DIE-UFPI rbritto@ufpi.edu.br Introdução Um PSR é definido por um conjunto de variáveis X 1, X 2,..., X n, e por um conjunto de restrições,
IA: Problemas de Satisfação de Restrições Prof. Msc. Ricardo Britto DIE-UFPI rbritto@ufpi.edu.br Introdução Um PSR é definido por um conjunto de variáveis X 1, X 2,..., X n, e por um conjunto de restrições,
1. Conceitos de sistemas. Conceitos da Teoria de Sistemas. Conceitos de sistemas extraídos do dicionário Aurélio:
 1. Conceitos de sistemas Conceitos da Teoria de Sistemas OPTNER: É um conjunto de objetos com um determinado conjunto de relações entre seus objetos e seus atributos. TILLES: É um conjunto de partes inter-relacionadas.
1. Conceitos de sistemas Conceitos da Teoria de Sistemas OPTNER: É um conjunto de objetos com um determinado conjunto de relações entre seus objetos e seus atributos. TILLES: É um conjunto de partes inter-relacionadas.
Exemplo de Aplicação do DataMinig
 Exemplo de Aplicação do DataMinig Felipe E. Barletta Mendes 19 de fevereiro de 2008 INTRODUÇÃO AO DATA MINING A mineração de dados (Data Mining) está inserida em um processo maior denominado Descoberta
Exemplo de Aplicação do DataMinig Felipe E. Barletta Mendes 19 de fevereiro de 2008 INTRODUÇÃO AO DATA MINING A mineração de dados (Data Mining) está inserida em um processo maior denominado Descoberta
Algoritmos Genéticos em Mineração de Dados. Descoberta de Conhecimento. Descoberta do Conhecimento em Bancos de Dados
 Algoritmos Genéticos em Mineração de Dados Descoberta de Conhecimento Descoberta do Conhecimento em Bancos de Dados Processo interativo e iterativo para identificar padrões válidos, novos, potencialmente
Algoritmos Genéticos em Mineração de Dados Descoberta de Conhecimento Descoberta do Conhecimento em Bancos de Dados Processo interativo e iterativo para identificar padrões válidos, novos, potencialmente
Extração de Árvores de Decisão com a Ferramenta de Data Mining Weka
 Extração de Árvores de Decisão com a Ferramenta de Data Mining Weka 1 Introdução A mineração de dados (data mining) pode ser definida como o processo automático de descoberta de conhecimento em bases de
Extração de Árvores de Decisão com a Ferramenta de Data Mining Weka 1 Introdução A mineração de dados (data mining) pode ser definida como o processo automático de descoberta de conhecimento em bases de
Programação Estruturada e Orientada a Objetos. Fundamentos Orientação a Objetos
 Programação Estruturada e Orientada a Objetos Fundamentos Orientação a Objetos 2013 O que veremos hoje? Introdução aos fundamentos de Orientação a Objetos Transparências baseadas no material do Prof. Jailton
Programação Estruturada e Orientada a Objetos Fundamentos Orientação a Objetos 2013 O que veremos hoje? Introdução aos fundamentos de Orientação a Objetos Transparências baseadas no material do Prof. Jailton