Mineração de Dados. Profª Ma. CLEIANE GONÇALVES OLIVEIRA
|
|
|
- Tomás Canto Nunes
- 8 Há anos
- Visualizações:
Transcrição

1 Mineração de Dados Profª Ma. CLEIANE GONÇALVES OLIVEIRA

2 Agenda Mineração de Dados Ferramenta Weka Técnicas de mineração Aplicações Sistemas de recomendação PrefRec

3

4 O que é mineração de dados?

5 Histórico

6 Histórico Crescimento explosivo na capacidade de gerar, coletar e armazenar dados Barateamento de componentes e ambientes computacionais Exigências científicas / sociais Mudança de paradigmas (maior uso de tecnologia)

7 Histórico


8 Aquisição de Dados

9 Tsunami de dados O que fazer com tantos dados? Será que existe alguma informação contida nessa quantidade de dados? Como identificar Padrões Exceções Tendências Correlações O que existe de interessante nestes dados?

10

11 Para quê? Vantagem competitiva Informações obtidas não são óbvias e triviais Direcionar uma comunicação adequada para cada tipo de público Saber e entender as necessidades dos consumidores Avaliar informações rapidamente é fator de diferenciação Informação vale dinheiro!

12 Data Mining permite que: Um supermercado melhore a disposição de seus produtos nas prateleiras, através do padrão de consumo de seus clientes; Uma companhia de marketing direcione o envio de mensagens promocionais, obtendo melhores retornos; Empresas planejem melhor a logística de distribuição dos seus produtos, prevendo picos nas vendas; Empresas possam economizar identificando fraudes. PONNIAH, P. Data Warehousing Fundamentals: A Comprehensive Guide for IT Professionals. John Wiley and Sons, Inc, 2001.

13 Exemplos Walmart A mineração de dados apontou que às sextasfeiras as vendas de cerveja cresciam na mesma proporção que as de fraldas. Em geral, os compradores eram homens, que saíam à noite para comprar fraldas e aproveitavam para levar algumas latinhas para casa. Decisões administrativas: Os produtos foram postos lado a lado. Resultado: a venda de fraldas e cervejas disparou. das-cervejas-e-big-data/#.vgp1-vnf9qu

14 Exemplos Vestibular PUC-RJ Regra obtida: se o candidato é do sexo feminino, trabalha e teve aprovação com boas notas no vestibular, NÃO efetiva matrícula. Observação do comportamento: uma mulher na idade de vestibular, se trabalha é porque precisa, e neste caso deve ter feito inscrição para ingressar na universidade pública gratuita. Se teve boas notas, provavelmente, foi aprovada na universidade pública onde efetivará matrícula. Decisões?

15 Como

16 KDD Fonte cs/cti2010/introdm.pdf Knowledge Discovery Databases

17 Preparação dos Dados Numéricos Discretos ou contínuos Categóricos Nominais Ordinais Limpeza dos dados Integração dos dados Transformação dos dados Redução dos dados Processo de preparação dos dados compreende até 50% de todo o processo. OLSON, D. L; DELEN, D. Advanced Data Mining Techniques. Springer, 2008

18 Tarefas de Mineração Descobrir um certo tipo de PADRÃO Tarefas PREDITIVAS Classificação Tarefas DESCRITIVAS Associação Agrupamento

19 Sistemas de mineração Clementine WEKA Oracle Data Mining (ODM) Intelligent Miner (IBM) DBMiner Enterprise Miner MineSet Genamics Expressions Rapid Miner

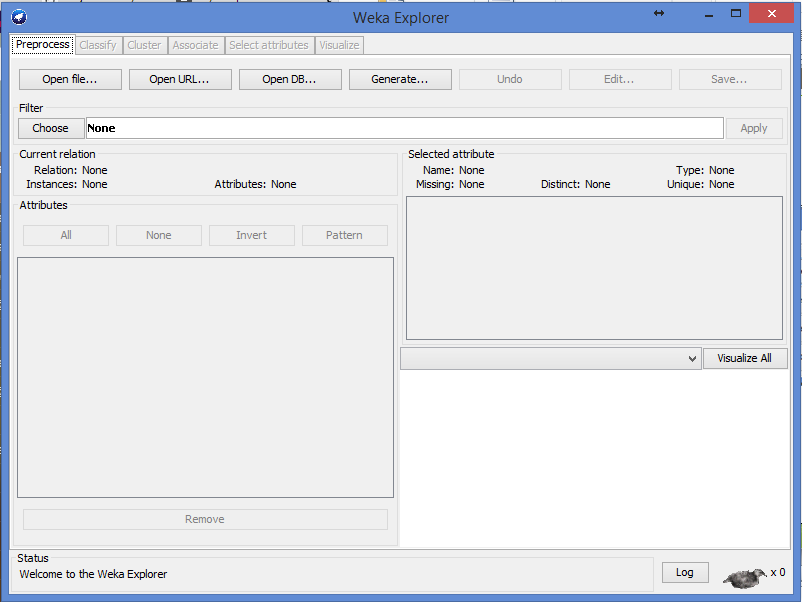
20 Ferramenta Weka

21
22 Ferramenta Weka Universidade de Waikato (Nova Zelândia) Implementado desde 1997 GNU General Public License (GPL) Linguagem Java GUI para interagir com arquivos de dados e produzir resultados visuais API geral, assim é possível incorporar o WEKA, como qualquer outra biblioteca, a seus próprios aplicativos.
23 Ferramenta WEKA Livro de referência sobre WEKA Curso sobre Weka thweka/course

24
25

26
27 Weka com MySQL o-de-dados-no-mysql-com-a-ferramentaweka/26360
28
29 Regras de Associação
30 Regras de Associação
31 Regras de Associação
32 Regras de Associação Descobrir combinações de itens ou valores de atributos que ocorrem com frequência significativa em uma base de dados 50% das compras que contêm fraldas, também contêm cerveja. 15% de todas as compras contêm os dois produtos. {fraldas} => {cerveja} A compra do produto milho verde aumenta em 5 vezes a chance de um cliente comprar ervilhas. {milho verde} => {ervilhas}
33 Regras de Associação
34 Regras de Associação Suporte de A1, A2, A3 A4 número de clientes que compraram A1,A2,A3,A4 Total de clientes Confiança de A1, A2, A3 A4 número de clientes que compraram A1,A2,A3,A4 número de clientes que compraram A1,A2,A3
35 ID Compras 1 Pão, Leite, Manteiga 2 Leite, Açucar 3 Leite, Manteiga 4 Manteiga, Açúcar 5 Manteiga, Pão Leite Manteiga Suporte = 2 5 = 40% Confiança = 2 3 = 66% Se o cliente compra Leite então compra Manteiga em 66% dos casos. Esta regra aplica-se a 40% das compras.
36 ID Compras 1 Pão, Leite, Manteiga 2 Leite, Açucar 3 Leite, Manteiga 4 Manteiga, Açúcar 5 Manteiga, Pão Manteiga Leite Suporte = 2 = 40% 5 Confiança = 2 = 50% 4 Se o cliente compra Manteiga então compra Leite em 50% dos casos. Esta regra aplica-se a 40% das compras.
37 Regras de Associação Passos Cliente inclui artigo A no cesto A loja conhece a regra A=> B A regra tem uma certa confiança (>20%) A loja informa que o artigo B pode interessar ao cliente O cliente decide comprar o artigo ou não Notas As regras são descobertas a partir da atividade comercial A descoberta é feita off-line A utilização das regras descobertas é feita on-line
38 Regras de Associação Ações possíveis Colocar a manteiga perto do leite Criar uma promoção que inclua manteiga e leite Vender um conjunto de produtos (pack) de manteiga e leite
39 Regras de Associação Weka Arquivo compras.arff Valores categóricos {sim, não}
40 Formato ARFF CABEÇALHO Atributos numéricos (real ou numeric) E categóricos DADOS
41
42 Regras de Associação Análise dos dados Algoritmo de associação Parâmetros Cesta_Compras Eliminar colunas desnecessárias
43 Classificação
44 Classificação Seguradora de automóveis Sexo Idade Acidente F 45 Não M 25 Sim F 18 Não F 32 Não M 37 Não M 18 Sim
45 Classificação Sexo Idade Acidente F 45 Não F 18 Não F 32 Não M 37 Não M 18 Sim M 25 Sim
46 Classificação O que é um classificador? Classificação é uma técnica que consiste na aplicação de um conjunto de exemplos pré-classificados para desenvolver um modelo capaz de classificar uma população maior de registros.
47 Etapas do Processo Amostras Classificadas REGRAS Banco de Testes Classificador REGRAS CONFIÁVEIS
48 Etapas do Processo Amostras Classificadas
49 Amostras classificadas Nome Idade Renda Profissão Classe Daniel 30 Média Estudante Sim João Média-Alta Professor Sim Carlos Média-Alta Engenheiro Sim Maria Baixa Vendedora Não Paulo 30 Baixa Porteiro Não Otavio > 60 Média-Alta Aposentado Não
50 Etapas do Processo Amostras Classificadas REGRAS Classificador
51 Se Regras idade = e Renda = Media-Alta então ClasseProdEletr = Sim. Se Renda = Baixa então ClasseProdEletr = Nao.

52 Etapas do Processo Amostras Classificadas REGRAS Banco de Testes Classificador
53 Nome Banco Idade de testes Renda Profissão Classe Pedro Média-Alta Ecologista Não José Média-Alta Professor Não Luiza Média-Alta Assistente Social Não Carla 30 Baixa Vendedora Não Wanda 30 Baixa Faxineira Não Felipe > 60 Média-Alta Aposentado Não Se idade = e Renda = Media-Alta então ClasseProdEletr = Sim. Se Renda = Baixa então ClasseProdEletr = Nao. Acurácia: 50%
54 Etapas do Processo Amostras Classificadas REGRAS Banco de Testes Classificador REGRAS CONFIÁVEIS
55 Classificadores Classificadores eager Árvore de decisão Classificadores lazy Knn
56 Classificação Árvore de decisão

57 Árvore de decisão Nós: testes sobre os atributos Folhas: determinação das classes Muito utilizada por ser facilmente interpretável
58 Árvore de decisão Cada caminho é uma regra Classificação de uma nova tupla: busca caminho ao enquadrar cada atributo na condição correspondente ao nó associado a tal atributo.
59 Árvore de decisão Weka Arquivo jogar_golfe
60 Árvore de decisão Arquivo jogar_golfe J48 Acurácia= 64 %
61 Árvore de decisão Arquivo bmw J48
62 Classificação K Nearest Neighbors KNN
63 KNN Uma tupla X = (x1,...,xn) não classificada Calcula-se a distância de X a cada uma das tuplas do banco de dados.
64 KNN Pega-se as k tuplas do banco de dados mais próximas de X. A classe de X é a classe que aparece com mais frequência entre as k tuplas mais próximas de X. K = 3
65 KNN K = 1 K = 2 K = 3
66 KNN Jogar_golfe Ibk Acurácia:??? Bmw Dispendiosa computacionalmente Necessidade de definir o parâmetro k
67 Classificação Classificador Bayesiano
68 Classificadores Bayesianos Classificadores estatísticos Classificam um objeto numa determinada classe C baseando-se na probabilidade do objeto pertencer à classe C Vantagens Processo de classificação rápido Grande acurácia quando aplicados a grandes volumes de dados.
69 Classificador Bayesiano Simples Hipótese: atributos não-classe são independentes Valor de um atributo não influencia o valor de outros atributos Exemplo: Idade, Profissão, Renda não são independentes. Um médico tem uma probabilidade maior de ter uma renda alta do que um porteiro. Gênero, Cidade, Idade são independentes Porque considerar atributos independentes? Cálculos envolvidos no processo de classificação são simplificados
70 Classificação de uma tupla X Envolve o cálculo de todas as probabilidades condicionais P[Ci X] para todo i = 1,,n, onde n = número de classes A probabilidade mais alta corresponde à classe em que X será classificada P[Ci X] : Probabilidade Posterior
71 Exemplo Compra-computador ID IDADE RENDA ESTUDANTE CREDITO CLASSE 1 30 Alta Não Bom Não 2 30 Alta Não Bom Não Alta Não Bom Sim 4 > 40 Média Não Bom Sim 5 > 40 Baixa Sim Bom Sim 6 > 40 Baixa Sim Excelente Não Baixa Sim Excelente Sim 8 30 Média Não Bom Não 9 30 Baixa Sim Bom Sim 10 > 40 Média Sim Bom Sim Média Sim Excelente Sim Média Não Excelente Sim Alta Sim Bom Sim 14 > 40 Média Não Excelente Não
72 Exemplo C1= sim, C2 = não Tupla desconhecida X = ( 30, Média,Sim,Bom) Precisamos maximizar P[X Ci] * P[Ci] para i =1,2 P[C1] = 9/14 = P[C2] = 5/14 = P[Idade 30 Compra = Sim ] = 2/9 = P[Idade 30 Compra = Não ] = 3/5 = 0.6 P[Renda = Média Compra = Sim ] = 4/9 = P[Renda = Média Compra = Não ] = 2/5 = 0.4 P[Est = sim Compra = Sim ] = 6/9 = P[Est = sim Compra = Não ] = 1/5 = 0.2 P[Crédito = bom Compra = Sim ] = 6/9 = P[Crédito = bom Compra = Não ] = 2/5 = 0.4
73 Exemplo P[X C1] = 0.222*0.444*0.667*0.667 = P[X C2] = 0.6*0.4*0.2*0.4 = P[X C1]*P[C1] = 0.044*0.643 = P[X C2]*P[C2] = 0.019*0.357 = Tupla X classificada na classe C1 (compra computador = sim)
74 Weka Bmw NaiveBayes Acurácia:???
75 Redes Bayesianas de Crença (Belief Bayesian Networks) Utilizadas quando a probabilidade de um atributo assumir um valor depende da probabilidade de valores para os outros atributos. Não há independência entre os atributos
76 Redes Bayesianas Um grafo dirigido acíclico Cada vértice representa um atributo Arestas ligando os vértices representam as dependências entre os atributos. y X depende de Y Tabela de Probabilidade Condicional (CPT) para cada atributo Z x y x Y é pai de X z P[Z {X,Y}] CPT (Z)
77 Tabela CPT (Z) Linhas : possíveis valores do atributo Z Colunas : combinações possíveis de valores dos pais de Z Na posição (i,j) da tabela temos a probabilidade condicional de Z ter o valor da linha i e seus pais terem os valores especificados na coluna j.
78 Tabela CPT(Z) Valores de X = { 1, 3} Valores de Y = {2,4} Valores de Z = {5,6} X Y X = 1 X = 1 X = 3 X = 3 Y = 2 Y = 4 Y = 2 Y = 4 Z Z = Z =
79 Exemplo HF F CP E RX+ D HF =história familiar E = Efisema F = fumante D = Dispnéia 1 CP = câncer de pulmão RX+ = raio X + 0 CPT(CP) CPT(HF) HF= 1 F = 1 HF= 1 F = 0 HF= 0 F = 1 HF= 0 F = CPT(E) CPT(RX+) F=1 F= 0 CP=1 CP= HF CPT(D) E=1, CP=1 E=1, CP=0 E=0, CP=1 E=0, CP= CPT(F) F
80 Cálculos X = (HF=1, F=1, E = 0, RX+ = 1, D=0) P[X CP=i] * P[CP=i] = P[HF=1] * P[F=1] * P[E=0 F=1] * P[RX=1 CP=i]*P[D=0 CP=i, E=0] * P[CP=i HF = 1, F=1]
81 Problemas É preciso descobrir : a topologia da rede e as tabelas de probabilidade CPT

82 Weka Bmw Bayesnet Acurácia:???
83 Classificação Comparação de classificadores
84 Critérios de Comparação dos Métodos Acurácia capacidade de classificar corretamente novas tuplas Rapidez tempo gasto na classificacao Robustez habilidade de classificar corretamente em presenca de ruidos e valores desconhecidos Escalabilidade eficiencia do classificador em grandes volumes de dados Interpretabilidade facilidade de um usuario entender as regras produzidas pelo classificador
85 Acurácia Taxa de erros Acc(M) = porcentagem das tuplas dos dados de teste que sao corretamente classificadas. Matriz de Confusão Classes Preditas C1 C2 Classes Reais C1 Positivos verdadeiros Falsos Negativos C2 Falsos Positivos Negativos verdadeiros
86 Outras medidas mais precisas Exemplo : acc(m) = 90% C1 = tem-câncer (4 pacientes) C2 = não-tem-câncer (500 pacientes) Classificou corretamente 454 pacientes que não tem câncer Acurácia = 454/504 = 90% Não acertou nenhum dos que tem câncer Pode ser classificado como bom classificador mesmo com acurácia alta?
87 Outras medidas mais precisas Precisão = true-pos true-pos + falso-pos % pacientes classificados corretamente com câncer dentre todos os que foram classificados com câncer Recall = true-pos true-pos + falso-neg % pacientes classificados corretamente com câncer dentre todos os que realmente tem câncer
88 Cross-Validation Validação Cruzada (k-fold Cross-validation) Dados iniciais são particionados em k partes D1,..., Dk de tamanhos aproximados Treinamento e testes são executados k vezes. Em cada iteração i (i=1...k) Di é escolhido para teste e o restante das partições são utilizadas como treinamento. Cada tupla de amostra é utilizada o mesmo número de vezes como tupla de treinamento e uma única vez como tupla de teste. Acurácia de um classificador = número total de tuplas bem classificadas nas k iterações dividido pelo total de tuplas no banco de dados original.
89 Cross-Validation
90 Comparação de classificadores Bmw Árvore de decisão Knn NaiveBayes BayesNet
91 Outros exemplos Diabetes Conjunto de dados sobre diagnóstico de diabetes Letter Reconhecimento de letras (20000 instancias) Observar o tempo Zoo Categorização de animais Leucemia Genótipo da doença
92 Aplicações Reconhecimento de voz Classificação de animais Mapas, definição de fronteiras Classificação automática de textos e imagens Reconhecimento de imagens (diagnóstico de doenças) Diagnóstico de pacientes Problemas em equipamentos mecânicos e elétricos Análise de crédito
93
94
95 Clusterização
96 Clusterização Encontrar grupos de objetos tais que os objetos de um grupo são similares (relacionados) e diferentes dos objetos de outros grupos.
97 Clusterização How many clusters? Six Clusters Two Clusters Four Clusters
98 a 1 a F b M a 2 a 3... c F d F e M Nome Sexo Sintomas Número de Clusters = 3 a 2 a 4 a 1 a 8 a 6 a 11 Doença X a 7 Doença Y a a 9 10 a 5 Doença Z Conceito = Doença
99 Clusterização versus Classificação Classificação Aprendizado Supervisionado Amostras de treinamento são classificadas Número de Classes é conhecido Aprendizado por Exemplo Clusterização Aprendizado Não Supervisionado Aprendizado por Observação
100 O que é um cluster? Como definir a noção de Cluster? Protótipos Bem separados Um cluster é um conjunto de objetos no qual cada objeto está mais próximo (ou é mais similar) a objetos dentro do cluster do que qualquer objeto fora do cluster. Baseados em Protótipos Um cluster é um conjunto de objetos no qual cada objeto está mais próximo ao protótipo que define o cluster do que dos protótipos de quaisquer outros clusters. Em geral: Protótipo = centróide Os clusters encontrados tendem a ser globulares.
101 O que é um cluster? Esta definição é utilizada quando os clusters são irregulares ou entrelaçados e quando ruído e outliers estão presentes. Baseados em Densidade Um cluster é uma região densa rodeada por uma região de baixa densidade. No exemplo, temos 3 clusters = 3 regiões densas A ponte de outliers ligando as duas esferas foi dissolvida nos outros outliers.
102 Técnicas de Clusterização Particionamento K-means: K-medóides: PAM, CLARA, CLARANS Particional e baseada em protótipos. Encontra um número k de clusters (k é fornecido pelo usuário) que são representados por seus centróides.
103 Particionamento BD com n amostras K = número de clusters desejado ( parâmetro ) K n
104 Dados de Treinamento Matriz de dados padronizados x 11 x 12 x x 1n x 21 x 22 x x 2n x 31 x 32 x x 3n x p1 x p2 x p3... x pn Matriz de dissimilaridade d(x 1,x 2 ) d(x 1,x 3 ) d(x 2,x 3 ) d(x 1,x p ) d(x 2,x p )... 0 Distância Euclidiana d(x,y) = (x 1 -y 1 ) 2 + (x 2 -y 2 ) (x p y p ) 2 Outras distâncias : Manhattan, Minkowski, Ponderada
105 Algoritmo K-means Exemplo K = ª 1ª Iteração
106 Algoritmo K-Means Objetivo do método K-means Minimizar a soma dos erros (SSE = sum of square errors) Maximizar a coesão (no caso de documentos) K SSE = Σ Σ d(x,ci) 2 i = 1 x ɛ Ci Problemas: Como definir o centróide inicial? Como definir a quantidade de clusters?
107 Clusterização Weka Arquivo bmw_browsers.arff SimpleKMeans SSE:?? Arquivo bank.arff X: cluster Y: instance number Color: variar os atributos
108 Algoritmos Baseados em Densidade Definição: Clusters são regiões de alta densidade de padrões separadas por regiões com baixa densidade, no espaço de padrões. Algoritmos baseados em densidade são projetados para encontrar clusters segundo esta definição.
109 O que são regiões densas? Definição baseada em centros: Uma região densa é uma região onde cada ponto tem muitos pontos em sua vizinhança. Muitos?? Vizinhança?? Parâmetros de Ajuste
110 Parâmetros de Ajuste Vizinhança: raio Eps Muitos : MinPts Assim, uma região densa é uma região em que todos os pontos têm pelo menos MinPts pontos num raio de Eps ao seu redor Eps MinPts = 13
111 Parâmetros versus Tipos de clusteres Eps MinPt Resultado Alto Alto Poucos clusters, grandes e densos Baixo Baixo Muitos clusters, pequenos e menos densos Alto Baixo Clusters grandes e menos densos Baixo Alto Clusters pequenos e densos
112 Avaliação de desempenho: qualidade dos clusteres produzidos Agrupamentos descobertos por CLARANS
113 Avaliação de desempenho: qualidade dos clusteres produzidos Agrupamentos descobertos por DBSCAN
114 Vantagens e Desvantagens Vantagens Eficiente em tratar grandes bases de dados Menos sensível a ruídos Forma clusters de formato arbitrário Usuário não precisa especificar a quantidade de clusters Desvantagens Sensível aos parâmetros de entrada(eps e MinPt) Produz resultados não confiáveis se os clusteres têm densidades muito diferentes.
115 Clusterização Weka Arquivo bmw_browsers.arff DBScan SSE:?? Arquivo bank.arff X: cluster Y: instance number Color: variar os atributos
116 Aplicações
117 Árvore de Decisão para Classificação de Ocorrências de Dengue nos Municípios de Ilhéus e Itabuna
118
119
120
121
122
123
124
125 Privacidade? Tendências Mineração de séries temporais Mineração de grafos Mineração de textos Mineração em redes sociais Big Data
126 Bases de dados

127 Bases de Dados
128
129
130
131 Weka no código
132 Weka no código Minicurso WebMedia 2012 Análise de Informações Contextuais através de Técnicas de Aprendizagem de Máquina dia2012_minicursos.pdf Weka na Munheca
133 Links úteis M.pdf ata%20sets/bookclub/ atamining Weka.pdf os-weka1/index.html
134 Tendências na área br/?page_id=2
135 Sistemas de recomendação
136
137
138
139
140
141
142 movielens.umn.edu

143 Last.fm
144 E-commerce
145 Quem viu X comprou Y
146 Top-N


147 Sistemas de recomendação
148 Sistemas de recomendação Realizam a filtragem da informação para recomendar itens, que possam ser relevantes ao usuário. Muitas vezes as pessoas só sabem o que querem depois que você mostra a elas. Steve Jobs
149 Usuários Produtos Compras Preferências Avaliações
150 Content-based 10

151
152 Collaborative filtering
153 Collaborative filtering
154 movielens.umn.edu
155 Sistemas de recomendação Satisfação Fidelidade Aumento nas vendas Direcionamento Diversidade
156 DESAFIOS
157 Escalabilidade
158 Content-based de filmes
159 Collaborative filtering de usuários
160 Esparsidade Usuário Cervejas Animais Frutas Móveis Celulares Jogos Paulo X X João X X Márcia X X X Carlos X Ana X X Mauro X Joaquim
161 Esparsidade Usuário Cervejas Animais Frutas Móveis Celulares Jogos Paulo X X João X X Márcia X X X Carlos X Ana X X Mauro X Joaquim
162 Esparsidade Cold-start de usuário Usuário Cervejas Animais Frutas Móveis Celulares Jogos Paulo X X João X X Márcia X X X Carlos X Ana X X Mauro X Joaquim
163 Esparsidade Cold-start de item Usuário Cervejas Animais Frutas Móveis Celulares Jogos Paulo X X João X X Márcia X X X Carlos X Ana X X Mauro X Joaquim
164 Medidas de qualidade Acurácia
165 Novidade


166 Surpreender!!!
167
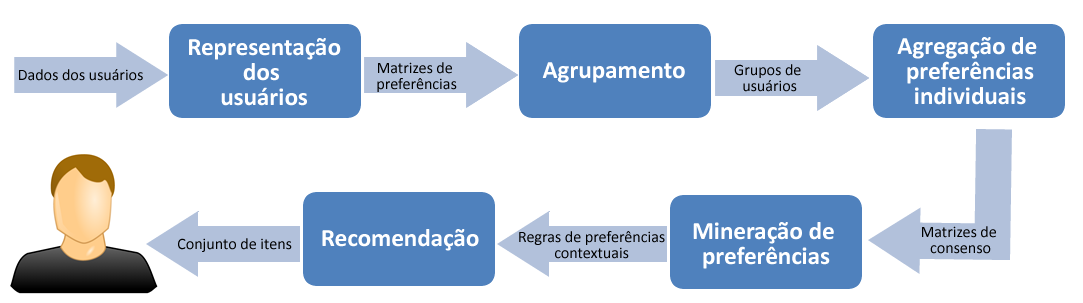
168 PREFREC: UMA METODOLOGIA PARA DESENVOLVIMENTO DE SISTEMAS DE RECOMENDAÇÃO UTILIZANDO ALGORITMOS DE MINERAÇÃO DE PREFERÊNCIAS Orientadora: Prof. Sandra de Amo Cleiane Gonçalves Oliveira

169 Filtragem Colaborativa [Resnick et al., 1994, CSCW] GroupLens: an open architecture for collaborative filtering of netnews.
170 Filtragem Colaborativa - Esparsidade Usuário Filme 1 Filme 2 Filme 3 Filme 4 Filme 5 Filme 6 Paulo X X João X X Márcia X X X Carlos Ana X X Mauro Joaqui m X X
171 Filtragem Colaborativa Cold-start de item Usuário Filme 1 Filme 2 Filme 3 Filme 4 Filme 5 Filme 6 Paulo X X João X X Márcia X X X Carlos Ana X X Mauro Joaqui m X X
172 Filtragem Colaborativa Cold-start de item Usuário Filme 1 Filme 2 Filme 3 Filme 4 Filme 5 Filme 6 Paulo X X João X X Márcia X X X Carlos Ana X X Mauro Joaqui m X X
173 Filtragem Colaborativa Cold-start de usuário Usuário Filme 1 Filme 2 Filme 3 Filme 4 Filme 5 Filme 6 Paulo X X João X X Márcia X X X Carlos Ana X X Mauro Joaqui m X X
174 Baseado em Conteúdo 10
175 Desafios Desafios Cold-start de item Over specialization Esparsidade dos dados Cold-start de usuário Escalabilidade
176 Trabalhos correlatos [LIEBERMAN, 1995, IJCAI] Perfil do usuário baseado em palavras chaves [BILLSUS e PAZZANI, 2000, User Model. U. Adapt. Interact.] Descarte de itens muito similares [AHN et al., 2007, WWW2007] Perfis separados para diferentes assuntos [BLANCO-FERNANDES et al., 2008, IEEE Trans. Cons. Electronics] Análise semântica e ontologias [IAQUINTA et al., 2008, Hybrid Intelligent Systems] Recomenda itens pouco similares ao perfil do usuário
177 Desafios Cold-start de item Over Specialization Esparsidade dos dados Cold-start de usuário Filtragem Colaborativa X X Baseado em Conteúdo Escalabilidade X X X X X X
178 Abordagens híbridas A maioria dos Sistemas de Recomendação usados na indústria são baseados em algum tipo de sistema híbrido. [AMATRIAIN, 2013, SIGKDD]
179 Trabalhos correlatos [KO e LEE, 2002, EC-WEB] CB e CF paralelos e agregados na recomendação [MELVILLE et al., 2002, Eighteenth National Conference on Articial Intelligence] CBCF: processamento offline CB e CF online [DEGEMMIS et al., 2007, User Modeling and User-Adapted Interaction] Perfis CB clusterizados para definição de vizinhos

180 PREFREC
181 PREFREC Metodologia híbrida entre as técnicas de Filtragem Colaborativa e Baseada em Conteúdo Utilização de algoritmos de mineração de preferências Tratamento do problema de cold-start de item
182 PrefRec
183 Representação dos usuários Item Avaliaçã o i 1 5 i 2 3 i 3 * i 4 1 Mpref i 1 i 2 i 3 i 4 i * 0.83 i * 0.75 i 3 * * 0.50 * i * 0.50 f i 1, i 4 = h r i 1, i 4 x = r i 1, i 4 = r 1 r 4 = 5 1 = 5 h x = x x + 1 = 5 6 = 0.83
184 PrefRec

185 Agrupamento dos usuários i 1 i 2 i 3 i 4 i 1 i 2 i i i 4 * 0.83 i 1 i 2 i 3 i 4 i * 0.83 i * i * 0.83 i * 0.75 i 1 i 2 i i 3 * 3 i * i * * 0.75 i 3 * * 0.50 * i * i * 0.50 i 3 * * i i 2 * i 3 i 4 i * 0.50 i 1 i 2 i 3 i 4 i * 0.75 i i * * i * 0.83 i 3 * * 0.50 * i * 0.75 i * 0.75 i * 0.50 i 3 * * 0.50 * i 3 * * 0.50 * i * 0.50 i * 0.50 Clusterização
186 Agrupamento dos usuários i 1 i 2 i 3 i 4 i * 0.83 i * 0.75 i 3 * * 0.50 * i * 0.50 i 1 i 2 i 3 i 4 i 1 i i i * 3 i i 1 i * * i 2 i * 0.50 * i 1 * 0.50 i * i 3 i 4 i 3 i 4 * 0.17 i 1 * * * * i 1 i 2 i 3 i 4 i * 0.83 i i i 2 * i i 4 i i * * 0.75 i 3 * * 0.50 * i * 0.50 i 3 i 1 * 0.50 * * * 0.83 i 4 i * * i 3 * * 0.50 * i * 0.50
187 PrefRec
188 Agregação de preferências individuais MPref consensual i 1 i 2 i 3 i 4 i * 0.83 i * 0.75 i 1 i 3 i 2 * i 3 * i * i i * * 0.50 i * i i 2 i 3 i 4 i 3 * * i * 0.63 * 0.83 i i 2 * * 0.75 i 3 * * 0.50 * i 1 i 2 i 3 i 4 i * 0.83 i * 0.75 i 3 * * 0.50 * i * 0.50 i * 0.50
189 Agregação de preferências individuais i 1 i 2 i 3 i 4 i * 0.83 i * 0.75 Cada grupo e suas respectivas Mpref s consensuais i 3 * * 0.50 * i * 0.50 i 1 i 2 i 3 i 4 i * 0.83 i * 0.75 i 3 * * 0.50 * i * 0.50 i 1 i 2 i 3 i 4 i * 0.83 i * 0.75 i 3 * * 0.50 * i * 0.50
190 PrefRec
191 Mineração de preferências

192 Mineração de preferências i 1 i 2 i 3 i 4 i * 0.83 i * 0.75 Perfis de preferência θ = (C, M) i 3 * * 0.50 * i * 0.50 Modelo i 1 i 2 i 3 i 4 i * 0.83 i * 0.75 i 3 * * 0.50 * i * 0.50 i 1 i 2 i 3 i 4 i * 0.83 i * 0.75 Modelo i 3 * * 0.50 * i * 0.50 Modelo
193 PrefRec

194 Recomendação i 1 i 2 i 3 i 4 i * 0.83 i * 0.75 i 3 * * 0.50 * i * 0.50 Modelo i 1 i 2 i 3 i 4 Modelo i * 0.83 i * 0.75 i 3 * * 0.50 * i * 0.50 i 1 i 2 i 3 i 4 i * 0.83 i * 0.75 i 3 * * 0.50 * i * 0.50 i 1 i 2 i 3 i 4 i * 0.83 i * 0.75 i 3 * * 0.50 * i * 0.50 Modelo

195 Recomendação i 1 i 2 i 3 i 4 i * 0.83 i * 0.75 i 3 * * 0.50 * i * 0.50 Modelo
196 Contribuições Framework geral para Sistemas de Recomendação Framework flexível que permite o ajuste de várias técnicas em função das medidas de qualidade que se quer otimizar Neste trabalho focamos um estudo empírico nas medidas de cobertura e acurácia
197 Contribuições Utilização de algoritmos de Mineração de preferências Quais características dos itens são preferidas pelo usuário Nova proposta de representação de usuários em Sistemas de Recomendação O usuário é representado a partir da sua preferência por pares de itens Tratamento do problema de cold-start de item Recomendação de itens a partir de suas características
198 Contribuições Agregação de preferências Estudo de técnicas para agregar as preferências dos usuários de um grupo de forma que represente um senso comum Estudo de fatores que influenciam na performance da metodologia Constatamos qual dos módulos influencia mais na melhoria dos resultados das medidas de cobertura e acurácia
199 Validação da Metodologia PrefRec Fatores que influenciam no Desempenho da Metodologia Acurácia Cobertura Comparação com outros trabalhos Acurácia Cobertura Novidade Serendipity

200 Validação da Metodologia PrefRec Dados de teste (BD_100) 296 usuários 262 itens avaliações 12.35% de esparsidade
201 Validação da Metodologia PrefRec Acurácia Precisão Revocação
202 Validação da Metodologia PrefRec Cobertura Itens desconhecidos do modelo Precisão Revocação
203 Fatores que influenciam no Desempenho da Metodologia Etapa 2 Agrupamento de usuários Etapa 3 Agregação de preferências Etapa 4 Mineração de preferências K-Means DBScan Cure Média aritmética Média ponderada pelo coeficiente de silhueta Quantificador fuzzy at least half Quantificador fuzzy as many as possible Quantificador fuzzy most Cprefminer Cprefminer*
204 Grupo de teste 1 Agrupamento de usuários Etapa 2 Agrupamento de usuários Etapa 3 Agregação de preferências Etapa 4 Mineração de preferências K-Means DBScan Cure Média aritmética Média ponderada pelo coeficiente de silhueta Quantificador fuzzy at least half Quantificador fuzzy as many as possible Quantificador fuzzy most Cprefminer Cprefminer*
205 Grupo de teste 1 Agrupamento de usuários BD_100 Acurácia Cobertura Precisão Revocação Precisão Revocação DBScan 76.10% 73.85% 63.16% 49.96% CURE 75.02% 71.64% 63.22% 48.57%
206 Grupo de teste 2 Agregação de Preferências Etapa 2 Agrupamento de usuários Etapa 3 Agregação de preferências Etapa 4 Mineração de preferências * [CHICLANA, 2001, Fuzzy Sets and Systems] K-Means DBScan Cure Média aritmética Média ponderada pelo coeficiente de silhueta Quantificador fuzzy at least half * Quantificador fuzzy as many as possible * Quantificador fuzzy most * Cprefminer Cprefminer*
207 Grupo de teste 2 Agregação de Preferências BD_100 (1) Média aritmética (2) Média ponderada pelo coeficiente de silhueta (3) Quantificador fuzzy Most Acurácia (4) Quantificador fuzzy At least half (5) Quantificador fuzzy As many as possible Cobertura Precisão Revocação Precisão Revocação (1) 76.10% 73.85% 63.16% 49.96% (2) 75.97% 73.71% 63.22% 50.12% (3) 63.82% 60.69% 56.92% 43.50% (4) 63.47% 60.41% 57.83% 43.79% (5) 63.83% 60.53% 59.05% 44.11%
208 Grupo de teste 3 Mineração de Preferências Etapa 2 Agrupamento de usuários Etapa 3 Agregação de preferências Etapa 4 Mineração de preferências K-Means DBScan Cure Média aritmética Média ponderada pelo coeficiente de silhueta Quantificador fuzzy at least half Quantificador fuzzy as many as possible Quantificador fuzzy most Cprefminer Cprefminer*
209 Grupo de teste 3 Mineração de Preferências CPrefMiner [de Amo et al, 2012, ICTAI]
210 Grupo de teste 3 Mineração de Preferências SE ENTÃO ator = Tom Hanks (gênero: drama > gênero: mistério) Contexto Preferência sobre os atributos dos itens CPrefMiner [de Amo et al, 2012, ICTAI]
211 Grupo de teste 3 Mineração de Preferências CPrefMiner* [de Amo et al., 2014, To appear] Acréscimo da Técnica de Range Voting em algoritmos de mineração de preferências Utiliza das inferências feitas pelo minerador de preferências para calcular preferências que o minerador não foi capaz de calcular ou retificar inferências feitas.
212 Grupo de teste 3 Mineração de Preferências BD_100 Precisão Acurácia Revocaçã o Precisão Cobertura Revocaçã o CprefMiner 76.10% 73.85% 63.16% 49.96% CprefMiner* 89.16% 88.49% 79.30% 78.79% O minerador de preferência é o fator que mais influencia no desempenho do Sistema de Recomendação.
213 Fatores que influenciam no Desempenho da Metodologia Etapa 2 Agrupamento de usuários DBScan Etapa 3 Agregação de preferências Etapa 4 Mineração de preferências Média aritmética Cprefminer*
214 Comparação com outros trabalhos CBCF [MELVILLE et al., 2002, Eighteenth National Conference on Articial Intelligence] Abordagem híbrida entre CF e CB; Tratamento do problema de cold-start de item; Predição de dados faltosos a partir da mineração de preferências sobre os atributos a partir de um classificador bayesiano.
215 Comparação com outros trabalhos XPrefRec Aplicação da abordagem CB para construção do modelo de preferências Comparação do usuário ativo com as MPref consensual de cada grupo Usuários representados por MPref Prediz relação de preferência Só recomenda itens sobre os quais consegue inferir algo O minerador CPrefMiner aplicado considera a dependência entre os atributos CBCF Aplicação da abordagem CB para predição de avaliações faltantes Comparação do usuário ativo com todos os usuários do sistema Usuários representados por vetor de avaliações Prediz notas para os itens Capaz de recomendar qualquer item Aplica um classificador bayesiano que considera os atributos como eventos independentes

216 Comparação com outros trabalhos Validação em bancos de dados mais esparsos

217 Comparação com outros trabalhos Acurácia Precisão Revocação

218 Comparação com outros trabalhos Cobertura Precisão Revocação
219 Comparação com outros trabalhos Novidade: Recomendação de itens pouco populares Definição de um ranking de 50 itens sobre os itens utilizados na medida de cobertura; Média de avaliações recebidas pelos usuários selecionados; Quanto menor o valor, melhor o Sistema se comporta em relação à novidade.

220 Comparação com outros trabalhos Novidade
221 Comparação com outros trabalhos Serendipity: Recomendação de itens surpreendentes Técnica proposta por [Shani e Gunawardana, 2011, Recommender Systems Handbook] Calcula o quanto os itens recomendados são distantes dos itens já conhecidos (treinamento) pelo usuário Ranking de 50 itens Quanto maior o valor, melhor o Sistema se comporta em relação à medida de serendipity.
222 Comparação com outros trabalhos Serendipity Diretor Idioma Ano Gênero Gênero Gênero Gênero Ator Ator Ator Ator Ator

223 Comparação com outros trabalhos Tempo de execução

224 Conclusão
MINERAÇÃO DE DADOS APLICADA. Pedro Henrique Bragioni Las Casas pedro.lascasas@dcc.ufmg.br
 MINERAÇÃO DE DADOS APLICADA Pedro Henrique Bragioni Las Casas pedro.lascasas@dcc.ufmg.br Processo Weka uma Ferramenta Livre para Data Mining O que é Weka? Weka é um Software livre do tipo open source para
MINERAÇÃO DE DADOS APLICADA Pedro Henrique Bragioni Las Casas pedro.lascasas@dcc.ufmg.br Processo Weka uma Ferramenta Livre para Data Mining O que é Weka? Weka é um Software livre do tipo open source para
Data Mining. Origem do Data Mining 24/05/2012. Data Mining. Prof Luiz Antonio do Nascimento
 Data Mining Prof Luiz Antonio do Nascimento Data Mining Ferramenta utilizada para análise de dados para gerar, automaticamente, uma hipótese sobre padrões e anomalias identificadas para poder prever um
Data Mining Prof Luiz Antonio do Nascimento Data Mining Ferramenta utilizada para análise de dados para gerar, automaticamente, uma hipótese sobre padrões e anomalias identificadas para poder prever um
Extração de Árvores de Decisão com a Ferramenta de Data Mining Weka
 Extração de Árvores de Decisão com a Ferramenta de Data Mining Weka 1 Introdução A mineração de dados (data mining) pode ser definida como o processo automático de descoberta de conhecimento em bases de
Extração de Árvores de Decisão com a Ferramenta de Data Mining Weka 1 Introdução A mineração de dados (data mining) pode ser definida como o processo automático de descoberta de conhecimento em bases de
UTILIZANDO O SOFTWARE WEKA
 UTILIZANDO O SOFTWARE WEKA O que é 2 Weka: software livre para mineração de dados Desenvolvido por um grupo de pesquisadores Universidade de Waikato, Nova Zelândia Também é um pássaro típico da Nova Zelândia
UTILIZANDO O SOFTWARE WEKA O que é 2 Weka: software livre para mineração de dados Desenvolvido por um grupo de pesquisadores Universidade de Waikato, Nova Zelândia Também é um pássaro típico da Nova Zelândia
Prof. Msc. Paulo Muniz de Ávila
 Prof. Msc. Paulo Muniz de Ávila O que é Data Mining? Mineração de dados (descoberta de conhecimento em bases de dados): Extração de informação interessante (não-trivial, implícita, previamente desconhecida
Prof. Msc. Paulo Muniz de Ávila O que é Data Mining? Mineração de dados (descoberta de conhecimento em bases de dados): Extração de informação interessante (não-trivial, implícita, previamente desconhecida
Mineração de Dados: Introdução e Aplicações
 Mineração de Dados: Introdução e Aplicações Luiz Henrique de Campos Merschmann Departamento de Computação Universidade Federal de Ouro Preto luizhenrique@iceb.ufop.br Apresentação Luiz Merschmann Engenheiro
Mineração de Dados: Introdução e Aplicações Luiz Henrique de Campos Merschmann Departamento de Computação Universidade Federal de Ouro Preto luizhenrique@iceb.ufop.br Apresentação Luiz Merschmann Engenheiro
ADM041 / EPR806 Sistemas de Informação
 ADM041 / EPR806 Sistemas de Informação UNIFEI Universidade Federal de Itajubá Prof. Dr. Alexandre Ferreira de Pinho 1 Sistemas de Apoio à Decisão (SAD) Tipos de SAD Orientados por modelos: Criação de diferentes
ADM041 / EPR806 Sistemas de Informação UNIFEI Universidade Federal de Itajubá Prof. Dr. Alexandre Ferreira de Pinho 1 Sistemas de Apoio à Decisão (SAD) Tipos de SAD Orientados por modelos: Criação de diferentes
Clustering: K-means and Aglomerative
 Universidade Federal de Pernambuco UFPE Centro de Informática Cin Pós-graduação em Ciência da Computação U F P E Clustering: K-means and Aglomerative Equipe: Hugo, Jeandro, Rhudney e Tiago Professores:
Universidade Federal de Pernambuco UFPE Centro de Informática Cin Pós-graduação em Ciência da Computação U F P E Clustering: K-means and Aglomerative Equipe: Hugo, Jeandro, Rhudney e Tiago Professores:
MINERAÇÃO DE DADOS EDUCACIONAIS: UM ESTUDO DE CASO APLICADO AO PROCESSO SELETIVO DO IFSULDEMINAS CÂMPUS MUZAMBINHO
 MINERAÇÃO DE DADOS EDUCACIONAIS: UM ESTUDO DE CASO APLICADO AO PROCESSO SELETIVO DO IFSULDEMINAS CÂMPUS MUZAMBINHO Fernanda Delizete Madeira 1 ; Aracele Garcia de Oliveira Fassbinder 2 INTRODUÇÃO Data
MINERAÇÃO DE DADOS EDUCACIONAIS: UM ESTUDO DE CASO APLICADO AO PROCESSO SELETIVO DO IFSULDEMINAS CÂMPUS MUZAMBINHO Fernanda Delizete Madeira 1 ; Aracele Garcia de Oliveira Fassbinder 2 INTRODUÇÃO Data
Sistema de mineração de dados para descobertas de regras e padrões em dados médicos
 Sistema de mineração de dados para descobertas de regras e padrões em dados médicos Pollyanna Carolina BARBOSA¹; Thiago MAGELA² 1Aluna do Curso Superior Tecnólogo em Análise e Desenvolvimento de Sistemas
Sistema de mineração de dados para descobertas de regras e padrões em dados médicos Pollyanna Carolina BARBOSA¹; Thiago MAGELA² 1Aluna do Curso Superior Tecnólogo em Análise e Desenvolvimento de Sistemas
Fases para um Projeto de Data Warehouse. Fases para um Projeto de Data Warehouse. Fases para um Projeto de Data Warehouse
 Definição escopo do projeto (departamental, empresarial) Grau de redundância dos dados(ods, data staging) Tipo de usuário alvo (executivos, unidades) Definição do ambiente (relatórios e consultas préestruturadas
Definição escopo do projeto (departamental, empresarial) Grau de redundância dos dados(ods, data staging) Tipo de usuário alvo (executivos, unidades) Definição do ambiente (relatórios e consultas préestruturadas
Planejamento Estratégico de TI. Prof.: Fernando Ascani
 Planejamento Estratégico de TI Prof.: Fernando Ascani Data Mining Os métodos tradicionais de Data Mining são: Classificação Associa ou classifica um item a uma ou várias classes categóricas pré-definidas.
Planejamento Estratégico de TI Prof.: Fernando Ascani Data Mining Os métodos tradicionais de Data Mining são: Classificação Associa ou classifica um item a uma ou várias classes categóricas pré-definidas.
Avaliando o que foi Aprendido
 Avaliando o que foi Aprendido Treinamento, teste, validação Predição da performance: Limites de confiança Holdout, cross-validation, bootstrap Comparando algoritmos: o teste-t Predecindo probabilidades:função
Avaliando o que foi Aprendido Treinamento, teste, validação Predição da performance: Limites de confiança Holdout, cross-validation, bootstrap Comparando algoritmos: o teste-t Predecindo probabilidades:função
XIII Encontro de Iniciação Científica IX Mostra de Pós-graduação 06 a 11 de outubro de 2008 BIODIVERSIDADE TECNOLOGIA DESENVOLVIMENTO
 XIII Encontro de Iniciação Científica IX Mostra de Pós-graduação 06 a 11 de outubro de 2008 BIODIVERSIDADE TECNOLOGIA DESENVOLVIMENTO EPE0147 UTILIZAÇÃO DA MINERAÇÃO DE DADOS EM UMA AVALIAÇÃO INSTITUCIONAL
XIII Encontro de Iniciação Científica IX Mostra de Pós-graduação 06 a 11 de outubro de 2008 BIODIVERSIDADE TECNOLOGIA DESENVOLVIMENTO EPE0147 UTILIZAÇÃO DA MINERAÇÃO DE DADOS EM UMA AVALIAÇÃO INSTITUCIONAL
Exemplo de Aplicação do DataMinig
 Exemplo de Aplicação do DataMinig Felipe E. Barletta Mendes 19 de fevereiro de 2008 INTRODUÇÃO AO DATA MINING A mineração de dados (Data Mining) está inserida em um processo maior denominado Descoberta
Exemplo de Aplicação do DataMinig Felipe E. Barletta Mendes 19 de fevereiro de 2008 INTRODUÇÃO AO DATA MINING A mineração de dados (Data Mining) está inserida em um processo maior denominado Descoberta
Aprendizagem de Máquina
 Aprendizagem de Máquina Professor: Rosalvo Ferreira de Oliveira Neto Disciplina: Inteligência Artificial Tópicos 1. Definições 2. Tipos de aprendizagem 3. Paradigmas de aprendizagem 4. Modos de aprendizagem
Aprendizagem de Máquina Professor: Rosalvo Ferreira de Oliveira Neto Disciplina: Inteligência Artificial Tópicos 1. Definições 2. Tipos de aprendizagem 3. Paradigmas de aprendizagem 4. Modos de aprendizagem
Microsoft Innovation Center
 Microsoft Innovation Center Mineração de Dados (Data Mining) André Montevecchi andre@montevecchi.com.br Introdução Objetivo BI e Mineração de Dados Aplicações Exemplos e Cases Algoritmos para Mineração
Microsoft Innovation Center Mineração de Dados (Data Mining) André Montevecchi andre@montevecchi.com.br Introdução Objetivo BI e Mineração de Dados Aplicações Exemplos e Cases Algoritmos para Mineração
Data Mining Software Weka. Software Weka. Software Weka 30/10/2012
 Data Mining Software Weka Prof. Luiz Antonio do Nascimento Software Weka Ferramenta para mineração de dados. Weka é um Software livre desenvolvido em Java. Weka é um É um pássaro típico da Nova Zelândia.
Data Mining Software Weka Prof. Luiz Antonio do Nascimento Software Weka Ferramenta para mineração de dados. Weka é um Software livre desenvolvido em Java. Weka é um É um pássaro típico da Nova Zelândia.
4. Que tipos de padrões podem ser minerados. 5. Critérios de classificação de sistemas de Data Mining. 6. Tópicos importantes de estudo em Data Mining
 Curso de Data Mining - Aula 1 1. Como surgiu 2. O que é 3. Em que tipo de dados pode ser aplicado 4. Que tipos de padrões podem ser minerados 5. Critérios de classificação de sistemas de Data Mining 6.
Curso de Data Mining - Aula 1 1. Como surgiu 2. O que é 3. Em que tipo de dados pode ser aplicado 4. Que tipos de padrões podem ser minerados 5. Critérios de classificação de sistemas de Data Mining 6.
Universidade Tecnológica Federal do Paraná UTFPR Programa de Pós-Graduação em Computação Aplicada Disciplina de Mineração de Dados
 Universidade Tecnológica Federal do Paraná UTFPR Programa de Pós-Graduação em Computação Aplicada Disciplina de Mineração de Dados Prof. Celso Kaestner Poker Hand Data Set Aluno: Joyce Schaidt Versão:
Universidade Tecnológica Federal do Paraná UTFPR Programa de Pós-Graduação em Computação Aplicada Disciplina de Mineração de Dados Prof. Celso Kaestner Poker Hand Data Set Aluno: Joyce Schaidt Versão:
Aprendizagem de Máquina. Ivan Medeiros Monteiro
 Aprendizagem de Máquina Ivan Medeiros Monteiro Definindo aprendizagem Dizemos que um sistema aprende se o mesmo é capaz de melhorar o seu desempenho a partir de suas experiências anteriores. O aprendizado
Aprendizagem de Máquina Ivan Medeiros Monteiro Definindo aprendizagem Dizemos que um sistema aprende se o mesmo é capaz de melhorar o seu desempenho a partir de suas experiências anteriores. O aprendizado
INTELIGÊNCIA ARTIFICIAL Data Mining (DM): um pouco de prática. (1) Data Mining Conceitos apresentados por
: um pouco de prática. (1) Data Mining Conceitos apresentados por") INTELIGÊNCIA ARTIFICIAL Data Mining (DM): um pouco de prática (1) Data Mining Conceitos apresentados por 1 2 (2) ANÁLISE DE AGRUPAMENTOS Conceitos apresentados por. 3 LEMBRE-SE que PROBLEMA em IA Uma busca
INTELIGÊNCIA ARTIFICIAL Data Mining (DM): um pouco de prática (1) Data Mining Conceitos apresentados por 1 2 (2) ANÁLISE DE AGRUPAMENTOS Conceitos apresentados por. 3 LEMBRE-SE que PROBLEMA em IA Uma busca
Faturamento personalizado (Customer Engaged Billing)
") Faturamento personalizado (Customer Engaged Billing) Transforme suas comunicações mais lidas em participações multicanais altamente direcionadas que reduzem custos, aumentam a satisfação do cliente e geram
Faturamento personalizado (Customer Engaged Billing) Transforme suas comunicações mais lidas em participações multicanais altamente direcionadas que reduzem custos, aumentam a satisfação do cliente e geram
INF 1771 Inteligência Artificial
 Edirlei Soares de Lima INF 1771 Inteligência Artificial Aula 12 Aprendizado de Máquina Agentes Vistos Anteriormente Agentes baseados em busca: Busca cega Busca heurística Busca local
Edirlei Soares de Lima INF 1771 Inteligência Artificial Aula 12 Aprendizado de Máquina Agentes Vistos Anteriormente Agentes baseados em busca: Busca cega Busca heurística Busca local
3 Metodologia para Segmentação do Mercado Bancário
 3 Metodologia para Segmentação do Mercado Bancário Este capítulo descreve a metodologia proposta nesta dissertação para a segmentação do mercado bancário a partir da abordagem post-hoc, servindo-se de
3 Metodologia para Segmentação do Mercado Bancário Este capítulo descreve a metodologia proposta nesta dissertação para a segmentação do mercado bancário a partir da abordagem post-hoc, servindo-se de
Algoritmos Genéticos em Mineração de Dados. Descoberta de Conhecimento. Descoberta do Conhecimento em Bancos de Dados
 Algoritmos Genéticos em Mineração de Dados Descoberta de Conhecimento Descoberta do Conhecimento em Bancos de Dados Processo interativo e iterativo para identificar padrões válidos, novos, potencialmente
Algoritmos Genéticos em Mineração de Dados Descoberta de Conhecimento Descoberta do Conhecimento em Bancos de Dados Processo interativo e iterativo para identificar padrões válidos, novos, potencialmente
IMPLEMENTAÇÃO DE UM ALGORITMO DE PADRÕES DE SEQUÊNCIA PARA DESCOBERTA DE ASSOCIAÇÕES ENTRE PRODUTOS DE UMA BASE DE DADOS REAL
 Universidade Federal de Ouro Preto - UFOP Instituto de Ciências Exatas e Biológicas - ICEB Departamento de Computação - DECOM IMPLEMENTAÇÃO DE UM ALGORITMO DE PADRÕES DE SEQUÊNCIA PARA DESCOBERTA DE ASSOCIAÇÕES
Universidade Federal de Ouro Preto - UFOP Instituto de Ciências Exatas e Biológicas - ICEB Departamento de Computação - DECOM IMPLEMENTAÇÃO DE UM ALGORITMO DE PADRÕES DE SEQUÊNCIA PARA DESCOBERTA DE ASSOCIAÇÕES
como ferramenta de análise de informações no mercado de saúde: o caso da Unimed-BH Ana Paula Franco Viegas Pereira
 como ferramenta de análise de informações no mercado de saúde: o caso da Unimed-BH Ana Paula Franco Viegas Pereira Setembro/2015 Agenda Nossos números Análise de Informações Estratégicas O papel do analista
como ferramenta de análise de informações no mercado de saúde: o caso da Unimed-BH Ana Paula Franco Viegas Pereira Setembro/2015 Agenda Nossos números Análise de Informações Estratégicas O papel do analista
No mundo atual, globalizado e competitivo, as organizações têm buscado cada vez mais, meios de se destacar no mercado. Uma estratégia para o
 DATABASE MARKETING No mundo atual, globalizado e competitivo, as organizações têm buscado cada vez mais, meios de se destacar no mercado. Uma estratégia para o empresário obter sucesso em seu negócio é
DATABASE MARKETING No mundo atual, globalizado e competitivo, as organizações têm buscado cada vez mais, meios de se destacar no mercado. Uma estratégia para o empresário obter sucesso em seu negócio é
Extração de Requisitos
 Extração de Requisitos Extração de requisitos é o processo de transformação das idéias que estão na mente dos usuários (a entrada) em um documento formal (saída). Pode se entender também como o processo
Extração de Requisitos Extração de requisitos é o processo de transformação das idéias que estão na mente dos usuários (a entrada) em um documento formal (saída). Pode se entender também como o processo
Prof. Júlio Cesar Nievola Data Mining PPGIa PUCPR
 Uma exploração preliminar dos dados para compreender melhor suas características. Motivações-chave da exploração de dados incluem Ajudar na seleção da técnica correta para pré-processamento ou análise
Uma exploração preliminar dos dados para compreender melhor suas características. Motivações-chave da exploração de dados incluem Ajudar na seleção da técnica correta para pré-processamento ou análise
Big Data. Como utilizar melhor e mais rápido seus dados e informações utilizando metodologias e tecnologias GED/ECM
 Big Data Como utilizar melhor e mais rápido seus dados e informações utilizando metodologias e tecnologias GED/ECM Irineu Granato, CDIA+ CBPP, AIIM (ECMp, ECMs, IOAp, BPMs, ERMs) AIIM Professional Member
Big Data Como utilizar melhor e mais rápido seus dados e informações utilizando metodologias e tecnologias GED/ECM Irineu Granato, CDIA+ CBPP, AIIM (ECMp, ECMs, IOAp, BPMs, ERMs) AIIM Professional Member
UNIVERSIDADE FEDERAL DE SANTA CATARINA GRADUAÇÃO EM SISTEMAS DE INFORMAÇÃO DEPARTAMENTO DE INFORMÁTICA E ESTATÍSTICA DATA MINING EM VÍDEOS
 UNIVERSIDADE FEDERAL DE SANTA CATARINA GRADUAÇÃO EM SISTEMAS DE INFORMAÇÃO DEPARTAMENTO DE INFORMÁTICA E ESTATÍSTICA DATA MINING EM VÍDEOS VINICIUS DA SILVEIRA SEGALIN FLORIANÓPOLIS OUTUBRO/2013 Sumário
UNIVERSIDADE FEDERAL DE SANTA CATARINA GRADUAÇÃO EM SISTEMAS DE INFORMAÇÃO DEPARTAMENTO DE INFORMÁTICA E ESTATÍSTICA DATA MINING EM VÍDEOS VINICIUS DA SILVEIRA SEGALIN FLORIANÓPOLIS OUTUBRO/2013 Sumário
Mídias sociais como apoio aos negócios B2C
 Mídias sociais como apoio aos negócios B2C A tecnologia e a informação caminham paralelas à globalização. No mercado atual é simples interagir, aproximar pessoas, expandir e aperfeiçoar os negócios dentro
Mídias sociais como apoio aos negócios B2C A tecnologia e a informação caminham paralelas à globalização. No mercado atual é simples interagir, aproximar pessoas, expandir e aperfeiçoar os negócios dentro
1 Tipos de dados em Análise de Clusters
 Curso de Data Mining Sandra de Amo Aula 13 - Análise de Clusters - Introdução Análise de Clusters é o processo de agrupar um conjunto de objetos físicos ou abstratos em classes de objetos similares Um
Curso de Data Mining Sandra de Amo Aula 13 - Análise de Clusters - Introdução Análise de Clusters é o processo de agrupar um conjunto de objetos físicos ou abstratos em classes de objetos similares Um
Técnicas de Clustering: Algoritmos K-means e Aglomerative
 Técnicas de Clustering: Algoritmos K-means e Aglomerative Danilo Oliveira, Matheus Torquato Centro de Informática Universidade Federal de Pernambuco 9 de outubro de 2012 Danilo Oliveira, Matheus Torquato
Técnicas de Clustering: Algoritmos K-means e Aglomerative Danilo Oliveira, Matheus Torquato Centro de Informática Universidade Federal de Pernambuco 9 de outubro de 2012 Danilo Oliveira, Matheus Torquato
Como vai a Governança de TI no Brasil? Resultados de pesquisa com 652 profissionais
 Fórum de Governança Tecnologia e Inovação LabGTI/UFLA Como vai a Governança de TI no Brasil? Resultados de pesquisa com 652 profissionais Pamela A. Santos pam.santos91@gmail.com Paulo H. S. Bermejo bermejo@dcc.ufla.br
Fórum de Governança Tecnologia e Inovação LabGTI/UFLA Como vai a Governança de TI no Brasil? Resultados de pesquisa com 652 profissionais Pamela A. Santos pam.santos91@gmail.com Paulo H. S. Bermejo bermejo@dcc.ufla.br
Curso de Data Mining
 Curso de Data Mining Sandra de Amo Aula 2 - Mineração de Regras de Associação - O algoritmo APRIORI Suponha que você seja gerente de um supermercado e esteja interessado em conhecer os hábitos de compra
Curso de Data Mining Sandra de Amo Aula 2 - Mineração de Regras de Associação - O algoritmo APRIORI Suponha que você seja gerente de um supermercado e esteja interessado em conhecer os hábitos de compra
)HUUDPHQWDV &RPSXWDFLRQDLV SDUD 6LPXODomR
HUUDPHQWDV &RPSXWDFLRQDLV SDUD 6LPXODomR") 6LPXODomR GH6LVWHPDV )HUUDPHQWDV &RPSXWDFLRQDLV SDUD 6LPXODomR #5,6. Simulador voltado para análise de risco financeiro 3RQWRV IRUWHV Fácil de usar. Funciona integrado a ferramentas já bastante conhecidas,
6LPXODomR GH6LVWHPDV )HUUDPHQWDV &RPSXWDFLRQDLV SDUD 6LPXODomR #5,6. Simulador voltado para análise de risco financeiro 3RQWRV IRUWHV Fácil de usar. Funciona integrado a ferramentas já bastante conhecidas,
Planejamento Estratégico de TI. Prof.: Fernando Ascani
 Planejamento Estratégico de TI Prof.: Fernando Ascani Data Warehouse - Conceitos Hoje em dia uma organização precisa utilizar toda informação disponível para criar e manter vantagem competitiva. Sai na
Planejamento Estratégico de TI Prof.: Fernando Ascani Data Warehouse - Conceitos Hoje em dia uma organização precisa utilizar toda informação disponível para criar e manter vantagem competitiva. Sai na
Módulo 4. Construindo uma solução OLAP
 Módulo 4. Construindo uma solução OLAP Objetivos Diferenciar as diversas formas de armazenamento Compreender o que é e como definir a porcentagem de agregação Conhecer a possibilidade da utilização de
Módulo 4. Construindo uma solução OLAP Objetivos Diferenciar as diversas formas de armazenamento Compreender o que é e como definir a porcentagem de agregação Conhecer a possibilidade da utilização de
DWARF DATAMINER: UMA FERRAMENTA GENÉRICA PARA MINERAÇÃO DE DADOS
 DWARF DATAMINER: UMA FERRAMENTA GENÉRICA PARA MINERAÇÃO DE DADOS Tácio Dias Palhão Mendes Bacharelando em Sistemas de Informação Bolsista de Iniciação Científica da FAPEMIG taciomendes@yahoo.com.br Prof.
DWARF DATAMINER: UMA FERRAMENTA GENÉRICA PARA MINERAÇÃO DE DADOS Tácio Dias Palhão Mendes Bacharelando em Sistemas de Informação Bolsista de Iniciação Científica da FAPEMIG taciomendes@yahoo.com.br Prof.
COMPARAÇÃO DOS MÉTODOS DE SEGMENTAÇÃO DE IMAGENS OTSU, KMEANS E CRESCIMENTO DE REGIÕES NA SEGMENTAÇÃO DE PLACAS AUTOMOTIVAS
 COMPARAÇÃO DOS MÉTODOS DE SEGMENTAÇÃO DE IMAGENS OTSU, KMEANS E CRESCIMENTO DE REGIÕES NA SEGMENTAÇÃO DE PLACAS AUTOMOTIVAS Leonardo Meneguzzi 1 ; Marcelo Massoco Cendron 2 ; Manassés Ribeiro 3 INTRODUÇÃO
COMPARAÇÃO DOS MÉTODOS DE SEGMENTAÇÃO DE IMAGENS OTSU, KMEANS E CRESCIMENTO DE REGIÕES NA SEGMENTAÇÃO DE PLACAS AUTOMOTIVAS Leonardo Meneguzzi 1 ; Marcelo Massoco Cendron 2 ; Manassés Ribeiro 3 INTRODUÇÃO
Pós-Graduação em Engenharia Elétrica Inteligência Artificial
 Pós-Graduação em Engenharia Elétrica Inteligência Artificial João Marques Salomão Rodrigo Varejão Andreão Inteligência Artificial Definição (Fonte: AAAI ): "the scientific understanding of the mechanisms
Pós-Graduação em Engenharia Elétrica Inteligência Artificial João Marques Salomão Rodrigo Varejão Andreão Inteligência Artificial Definição (Fonte: AAAI ): "the scientific understanding of the mechanisms
2 Diagrama de Caso de Uso
 Unified Modeling Language (UML) Universidade Federal do Maranhão UFMA Pós Graduação de Engenharia de Eletricidade Grupo de Computação Assunto: Diagrama de Caso de Uso (Use Case) Autoria:Aristófanes Corrêa
Unified Modeling Language (UML) Universidade Federal do Maranhão UFMA Pós Graduação de Engenharia de Eletricidade Grupo de Computação Assunto: Diagrama de Caso de Uso (Use Case) Autoria:Aristófanes Corrêa
http://www.publicare.com.br/site/5,1,26,5480.asp
 Página 1 de 7 Terça-feira, 26 de Agosto de 2008 ok Home Direto da redação Última edição Edições anteriores Vitrine Cross-Docking Assine a Tecnologística Anuncie Cadastre-se Agenda Cursos de logística Dicionário
Página 1 de 7 Terça-feira, 26 de Agosto de 2008 ok Home Direto da redação Última edição Edições anteriores Vitrine Cross-Docking Assine a Tecnologística Anuncie Cadastre-se Agenda Cursos de logística Dicionário
3 Market Basket Analysis - MBA
 2 Mineração de Dados 3 Market Basket Analysis - MBA Market basket analysis (MBA) ou, em português, análise da cesta de compras, é uma técnica de data mining que faz uso de regras de associação para identificar
2 Mineração de Dados 3 Market Basket Analysis - MBA Market basket analysis (MBA) ou, em português, análise da cesta de compras, é uma técnica de data mining que faz uso de regras de associação para identificar
Curso Superior de Tecnologia em Banco de Dados Disciplina: Projeto de Banco de Dados Relacional II Prof.: Fernando Hadad Zaidan
 Faculdade INED Curso Superior de Tecnologia em Banco de Dados Disciplina: Projeto de Banco de Dados Relacional II Prof.: Fernando Hadad Zaidan 1 Unidade 4.5 2 1 BI BUSINESS INTELLIGENCE BI CARLOS BARBIERI
Faculdade INED Curso Superior de Tecnologia em Banco de Dados Disciplina: Projeto de Banco de Dados Relacional II Prof.: Fernando Hadad Zaidan 1 Unidade 4.5 2 1 BI BUSINESS INTELLIGENCE BI CARLOS BARBIERI
DESENVOLVIMENTO DE UM SOFTWARE NA LINGUAGEM R PARA CÁLCULO DE TAMANHOS DE AMOSTRAS NA ÁREA DE SAÚDE
 DESENVOLVIMENTO DE UM SOFTWARE NA LINGUAGEM R PARA CÁLCULO DE TAMANHOS DE AMOSTRAS NA ÁREA DE SAÚDE Mariane Alves Gomes da Silva Eliana Zandonade 1. INTRODUÇÃO Um aspecto fundamental de um levantamento
DESENVOLVIMENTO DE UM SOFTWARE NA LINGUAGEM R PARA CÁLCULO DE TAMANHOS DE AMOSTRAS NA ÁREA DE SAÚDE Mariane Alves Gomes da Silva Eliana Zandonade 1. INTRODUÇÃO Um aspecto fundamental de um levantamento
Metodologias de Desenvolvimento de Sistemas. Analise de Sistemas I UNIPAC Rodrigo Videschi
 Metodologias de Desenvolvimento de Sistemas Analise de Sistemas I UNIPAC Rodrigo Videschi Histórico Uso de Metodologias Histórico Uso de Metodologias Era da Pré-Metodologia 1960-1970 Era da Metodologia
Metodologias de Desenvolvimento de Sistemas Analise de Sistemas I UNIPAC Rodrigo Videschi Histórico Uso de Metodologias Histórico Uso de Metodologias Era da Pré-Metodologia 1960-1970 Era da Metodologia
Administração de dados - Conceitos, técnicas, ferramentas e aplicações de Data Mining para gerar conhecimento a partir de bases de dados
 Universidade Federal de Pernambuco Graduação em Ciência da Computação Centro de Informática 2006.2 Administração de dados - Conceitos, técnicas, ferramentas e aplicações de Data Mining para gerar conhecimento
Universidade Federal de Pernambuco Graduação em Ciência da Computação Centro de Informática 2006.2 Administração de dados - Conceitos, técnicas, ferramentas e aplicações de Data Mining para gerar conhecimento
1 http://www.google.com
 1 Introdução A computação em grade se caracteriza pelo uso de recursos computacionais distribuídos em várias redes. Os diversos nós contribuem com capacidade de processamento, armazenamento de dados ou
1 Introdução A computação em grade se caracteriza pelo uso de recursos computacionais distribuídos em várias redes. Os diversos nós contribuem com capacidade de processamento, armazenamento de dados ou
Laudon & Laudon Essentials of MIS, 5th Edition. Pg. 1.1
 Laudon & Laudon Essentials of MIS, 5th Edition. Pg. 1.1 SISTEMA DE APOIO À DECISÃO Grupo: Denilson Neves Diego Antônio Nelson Santiago Sabrina Dantas CONCEITO É UM SISTEMA QUE AUXILIA O PROCESSO DE DECISÃO
Laudon & Laudon Essentials of MIS, 5th Edition. Pg. 1.1 SISTEMA DE APOIO À DECISÃO Grupo: Denilson Neves Diego Antônio Nelson Santiago Sabrina Dantas CONCEITO É UM SISTEMA QUE AUXILIA O PROCESSO DE DECISÃO
Profissionais de Alta Performance
 Profissionais de Alta Performance As transformações pelas quais o mundo passa exigem novos posicionamentos em todas as áreas e em especial na educação. A transferência pura simples de dados ou informações
Profissionais de Alta Performance As transformações pelas quais o mundo passa exigem novos posicionamentos em todas as áreas e em especial na educação. A transferência pura simples de dados ou informações
MÓDULO 9 METODOLOGIAS DE DESENVOLVIMENTO DE SISTEMAS
 MÓDULO 9 METODOLOGIAS DE DESENVOLVIMENTO DE SISTEMAS O termo metodologia não possui uma definição amplamente aceita, sendo entendido na maioria das vezes como um conjunto de passos e procedimentos que
MÓDULO 9 METODOLOGIAS DE DESENVOLVIMENTO DE SISTEMAS O termo metodologia não possui uma definição amplamente aceita, sendo entendido na maioria das vezes como um conjunto de passos e procedimentos que
4 Segmentação. 4.1. Algoritmo proposto
 4 Segmentação Este capítulo apresenta primeiramente o algoritmo proposto para a segmentação do áudio em detalhes. Em seguida, são analisadas as inovações apresentadas. É importante mencionar que as mudanças
4 Segmentação Este capítulo apresenta primeiramente o algoritmo proposto para a segmentação do áudio em detalhes. Em seguida, são analisadas as inovações apresentadas. É importante mencionar que as mudanças
Pós-Graduação em Gerenciamento de Projetos práticas do PMI
 Pós-Graduação em Gerenciamento de Projetos práticas do PMI Planejamento do Gerenciamento das Comunicações (10) e das Partes Interessadas (13) PLANEJAMENTO 2 PLANEJAMENTO Sem 1 Sem 2 Sem 3 Sem 4 Sem 5 ABRIL
Pós-Graduação em Gerenciamento de Projetos práticas do PMI Planejamento do Gerenciamento das Comunicações (10) e das Partes Interessadas (13) PLANEJAMENTO 2 PLANEJAMENTO Sem 1 Sem 2 Sem 3 Sem 4 Sem 5 ABRIL
Na medida em que se cria um produto, o sistema de software, que será usado e mantido, nos aproximamos da engenharia.
 1 Introdução aos Sistemas de Informação 2002 Aula 4 - Desenvolvimento de software e seus paradigmas Paradigmas de Desenvolvimento de Software Pode-se considerar 3 tipos de paradigmas que norteiam a atividade
1 Introdução aos Sistemas de Informação 2002 Aula 4 - Desenvolvimento de software e seus paradigmas Paradigmas de Desenvolvimento de Software Pode-se considerar 3 tipos de paradigmas que norteiam a atividade
Arquitetura de Banco de Dados
 Arquitetura de Banco de Dados Daniela Barreiro Claro MAT A60 DCC/IM/UFBA Arquitetura de Banco de dados Final de 1972, ANSI/X3/SPARC estabeleceram o relatório final do STUDY GROUP Objetivos do Study Group
Arquitetura de Banco de Dados Daniela Barreiro Claro MAT A60 DCC/IM/UFBA Arquitetura de Banco de dados Final de 1972, ANSI/X3/SPARC estabeleceram o relatório final do STUDY GROUP Objetivos do Study Group
Modelos de Qualidade de Produto de Software
 CBCC Bacharelado em Ciência da Computação CBSI Bacharelado em Sistemas de Informação Modelos de Qualidade de Produto de Software Prof. Dr. Sandro Ronaldo Bezerra Oliveira srbo@ufpa.br www.ufpa.br/srbo
CBCC Bacharelado em Ciência da Computação CBSI Bacharelado em Sistemas de Informação Modelos de Qualidade de Produto de Software Prof. Dr. Sandro Ronaldo Bezerra Oliveira srbo@ufpa.br www.ufpa.br/srbo
Prof. Júlio Cesar Nievola Data Mining PPGIa PUCPR
 Encontrar grupos de objetos tal que objetos em um grupo são similares (ou relacionados) uns aos outros e diferentes de (ou não relacionados) a objetos em outros grupos Compreensão Agrupa documentos relacionados
Encontrar grupos de objetos tal que objetos em um grupo são similares (ou relacionados) uns aos outros e diferentes de (ou não relacionados) a objetos em outros grupos Compreensão Agrupa documentos relacionados
TESTE QUI - QUADRADO DE UMA AMOSTRA (também chamado TESTE DE ADERÊNCIA ou TESTE DE EFICIÊNCIA DE AJUSTE)
") TESTE QUI - QUADRADO DE UMA AMOSTRA (também chamado TESTE DE ADERÊNCIA ou TESTE DE EFICIÊNCIA DE AJUSTE) O Teste Qui-quadrado de uma amostra é utilizado em pesquisa de marketing para verificar se a distribuição
TESTE QUI - QUADRADO DE UMA AMOSTRA (também chamado TESTE DE ADERÊNCIA ou TESTE DE EFICIÊNCIA DE AJUSTE) O Teste Qui-quadrado de uma amostra é utilizado em pesquisa de marketing para verificar se a distribuição
Data, Text and Web Mining
 Data, Text and Web Mining Fabrício J. Barth TerraForum Consultores Junho de 2010 Objetivo Apresentar a importância do tema, os conceitos relacionados e alguns exemplos de aplicações. Data, Text and Web
Data, Text and Web Mining Fabrício J. Barth TerraForum Consultores Junho de 2010 Objetivo Apresentar a importância do tema, os conceitos relacionados e alguns exemplos de aplicações. Data, Text and Web
ISO/IEC 12207: Gerência de Configuração
 ISO/IEC 12207: Gerência de Configuração Durante o processo de desenvolvimento de um software, é produzida uma grande quantidade de itens de informação que podem ser alterados durante o processo Para que
ISO/IEC 12207: Gerência de Configuração Durante o processo de desenvolvimento de um software, é produzida uma grande quantidade de itens de informação que podem ser alterados durante o processo Para que
GESTÃO DE PROJETOS PARA A INOVAÇÃO
 GESTÃO DE PROJETOS PARA A INOVAÇÃO Indicadores e Diagnóstico para a Inovação Primeiro passo para implantar um sistema de gestão nas empresas é fazer um diagnóstico da organização; Diagnóstico mapa n-dimensional
GESTÃO DE PROJETOS PARA A INOVAÇÃO Indicadores e Diagnóstico para a Inovação Primeiro passo para implantar um sistema de gestão nas empresas é fazer um diagnóstico da organização; Diagnóstico mapa n-dimensional
FURB - Universidade Regional de Blumenau TCC - Trabalho de Conclusão de Curso Acadêmico: Fernando Antonio de Lima Orientador: Oscar Dalfovo
 FURB - Universidade Regional de Blumenau TCC - Trabalho de Conclusão de Curso Acadêmico: Fernando Antonio de Lima Orientador: Oscar Dalfovo Roteiro Introdução Sistemas de Informação - SI Executive Information
FURB - Universidade Regional de Blumenau TCC - Trabalho de Conclusão de Curso Acadêmico: Fernando Antonio de Lima Orientador: Oscar Dalfovo Roteiro Introdução Sistemas de Informação - SI Executive Information
SISTEMA. Tecnologia. Software. Hardware. Prazos. Pessoas. Qualidade. Custo GERENCIAMENTO DE RISCO: COMO GARANTIR O SUCESSO DOS PROJETOS DE TI?
 GERENCIAMENTO DE RISCO: COMO GARANTIR O SUCESSO DOS PROJETOS DE TI? Os projetos de Tecnologia de Informação possuem características marcantes, que os diferencia dos demais são projetos onde o controle
GERENCIAMENTO DE RISCO: COMO GARANTIR O SUCESSO DOS PROJETOS DE TI? Os projetos de Tecnologia de Informação possuem características marcantes, que os diferencia dos demais são projetos onde o controle
Extração de Conhecimento & Mineração de Dados
 Extração de Conhecimento & Mineração de Dados Nesta apresentação é dada uma breve introdução à Extração de Conhecimento e Mineração de Dados José Augusto Baranauskas Departamento de Física e Matemática
Extração de Conhecimento & Mineração de Dados Nesta apresentação é dada uma breve introdução à Extração de Conhecimento e Mineração de Dados José Augusto Baranauskas Departamento de Física e Matemática
Universidade Federal de Minas Gerais ICEx / DCC
 Universidade Federal de Minas Gerais ICEx / DCC Belo Horizonte, 15 de dezembro de 2006 Relatório sobre aplicação de Mineração de Dados Mineração de Dados em Bases de Dados de Vestibulares da UFMG Professor:
Universidade Federal de Minas Gerais ICEx / DCC Belo Horizonte, 15 de dezembro de 2006 Relatório sobre aplicação de Mineração de Dados Mineração de Dados em Bases de Dados de Vestibulares da UFMG Professor:
Nos próximos. 30 minutos. 1 Objetivos 2 Metodologia 3 Perfil do Consumidor 4 Processo de Decisão 5 Conclusões
 Nos próximos 30 minutos 1 Objetivos 2 Metodologia 3 Perfil do Consumidor 4 Processo de Decisão 5 Conclusões Objetivos do estudo Buscando melhor entender a demanda e relevância da internet no processo de
Nos próximos 30 minutos 1 Objetivos 2 Metodologia 3 Perfil do Consumidor 4 Processo de Decisão 5 Conclusões Objetivos do estudo Buscando melhor entender a demanda e relevância da internet no processo de
Lean Seis Sigma e Benchmarking
 Lean Seis Sigma e Benchmarking Por David Vicentin e José Goldfreind O Benchmarking elimina o trabalho de adivinhação observando os processos por trás dos indicadores que conduzem às melhores práticas.
Lean Seis Sigma e Benchmarking Por David Vicentin e José Goldfreind O Benchmarking elimina o trabalho de adivinhação observando os processos por trás dos indicadores que conduzem às melhores práticas.
Redes Complexas Aula 2
 Redes Complexas Aula 2 Aula passada Logística, regras Introdução e motivação Aula de hoje Redes sociais Descobrimento Características Redes Sociais Vértices: pessoas ou grupo de pessoas Arestas: algum
Redes Complexas Aula 2 Aula passada Logística, regras Introdução e motivação Aula de hoje Redes sociais Descobrimento Características Redes Sociais Vértices: pessoas ou grupo de pessoas Arestas: algum
Requisitos de Software. Teresa Maciel DEINFO/UFRPE
 Requisitos de Software Teresa Maciel DEINFO/UFRPE 1 Requisito de Software Características que o produto de software deverá apresentar para atender às necessidades e expectativas do cliente. 2 Requisito
Requisitos de Software Teresa Maciel DEINFO/UFRPE 1 Requisito de Software Características que o produto de software deverá apresentar para atender às necessidades e expectativas do cliente. 2 Requisito
KDD. Fases limpeza etc. Datamining OBJETIVOS PRIMÁRIOS. Conceitos o que é?
 KDD Conceitos o que é? Fases limpeza etc Datamining OBJETIVOS PRIMÁRIOS TAREFAS PRIMÁRIAS Classificação Regressão Clusterização OBJETIVOS PRIMÁRIOS NA PRÁTICA SÃO DESCRIÇÃO E PREDIÇÃO Descrição Wizrule
KDD Conceitos o que é? Fases limpeza etc Datamining OBJETIVOS PRIMÁRIOS TAREFAS PRIMÁRIAS Classificação Regressão Clusterização OBJETIVOS PRIMÁRIOS NA PRÁTICA SÃO DESCRIÇÃO E PREDIÇÃO Descrição Wizrule
Chapter 3. Análise de Negócios e Visualização de Dados
 Chapter 3 Análise de Negócios e Visualização de Dados Objetivos de Aprendizado Descrever a análise de negócios (BA) e sua importância par as organizações Listar e descrever brevemente os principais métodos
Chapter 3 Análise de Negócios e Visualização de Dados Objetivos de Aprendizado Descrever a análise de negócios (BA) e sua importância par as organizações Listar e descrever brevemente os principais métodos
APLICAÇÃO DE MINERAÇÃO DE DADOS PARA O LEVANTAMENTO DE PERFIS: ESTUDO DE CASO EM UMA INSTITUIÇÃO DE ENSINO SUPERIOR PRIVADA
 APLICAÇÃO DE MINERAÇÃO DE DADOS PARA O LEVANTAMENTO DE PERFIS: ESTUDO DE CASO EM UMA INSTITUIÇÃO DE ENSINO SUPERIOR PRIVADA Lizianne Priscila Marques SOUTO 1 1 Faculdade de Ciências Sociais e Aplicadas
APLICAÇÃO DE MINERAÇÃO DE DADOS PARA O LEVANTAMENTO DE PERFIS: ESTUDO DE CASO EM UMA INSTITUIÇÃO DE ENSINO SUPERIOR PRIVADA Lizianne Priscila Marques SOUTO 1 1 Faculdade de Ciências Sociais e Aplicadas
Engenharia de Software: Introdução. Mestrado em Ciência da Computação 2008 Profa. Itana Gimenes
 Engenharia de Software: Introdução Mestrado em Ciência da Computação 2008 Profa. Itana Gimenes Programa 1. O processo de engenharia de software 2. UML 3. O Processo Unificado 1. Captura de requisitos 2.
Engenharia de Software: Introdução Mestrado em Ciência da Computação 2008 Profa. Itana Gimenes Programa 1. O processo de engenharia de software 2. UML 3. O Processo Unificado 1. Captura de requisitos 2.
17/10/2012. dados? Processo. Doutorado em Engenharia de Produção Michel J. Anzanello. Doutorado EP - 2. Doutorado EP - 3.
 Definição de Data Mining (DM) Mineração de Dados (Data Mining) Doutorado em Engenharia de Produção Michel J. Anzanello Processo de explorar grandes quantidades de dados à procura de padrões consistentes
Definição de Data Mining (DM) Mineração de Dados (Data Mining) Doutorado em Engenharia de Produção Michel J. Anzanello Processo de explorar grandes quantidades de dados à procura de padrões consistentes
Análise de Regressão. Tópicos Avançados em Avaliação de Desempenho. Cleber Moura Edson Samuel Jr
 Análise de Regressão Tópicos Avançados em Avaliação de Desempenho Cleber Moura Edson Samuel Jr Agenda Introdução Passos para Realização da Análise Modelos para Análise de Regressão Regressão Linear Simples
Análise de Regressão Tópicos Avançados em Avaliação de Desempenho Cleber Moura Edson Samuel Jr Agenda Introdução Passos para Realização da Análise Modelos para Análise de Regressão Regressão Linear Simples
Artigo Lean Seis Sigma e Benchmarking
 Artigo Lean Seis Sigma e Benchmarking David Vicentin e José Goldfreind Benchmarking pode ser definido como o processo de medição e comparação de nossa empresa com as organizações mundiais best-in-class.
Artigo Lean Seis Sigma e Benchmarking David Vicentin e José Goldfreind Benchmarking pode ser definido como o processo de medição e comparação de nossa empresa com as organizações mundiais best-in-class.
PRIMAVERA RISK ANALYSIS
 PRIMAVERA RISK ANALYSIS PRINCIPAIS RECURSOS Guia de análise de risco Verificação de programação Risco rápido em modelo Assistente de registro de riscos Registro de riscos Análise de riscos PRINCIPAIS BENEFÍCIOS
PRIMAVERA RISK ANALYSIS PRINCIPAIS RECURSOS Guia de análise de risco Verificação de programação Risco rápido em modelo Assistente de registro de riscos Registro de riscos Análise de riscos PRINCIPAIS BENEFÍCIOS
COLETA DE INFORMAÇÕES E PREVISÃO DE DEMANDA
 COLETA DE INFORMAÇÕES E PREVISÃO DE DEMANDA 1) Quais são os componentes de um moderno sistema de informações de marketing? 2) Como as empresas podem coletar informações de marketing? 3) O que constitui
COLETA DE INFORMAÇÕES E PREVISÃO DE DEMANDA 1) Quais são os componentes de um moderno sistema de informações de marketing? 2) Como as empresas podem coletar informações de marketing? 3) O que constitui
Desenvolvimento do Módulo de Pré-processamento e Geração de Imagens de. Imagens de Teste do Sistema DTCOURO
 Desenvolvimento do Módulo de Pré-processamento e Geração de Imagens de Teste do Sistema DTCOURO Willian Paraguassu Amorim 27 de julho de 2005 1 Título Desenvolvimento do Módulo de Pré-processamento e Geração
Desenvolvimento do Módulo de Pré-processamento e Geração de Imagens de Teste do Sistema DTCOURO Willian Paraguassu Amorim 27 de julho de 2005 1 Título Desenvolvimento do Módulo de Pré-processamento e Geração
DESENVOLVIMENTO DE INTERFACE WEB MULTIUSUÁRIO PARA SISTEMA DE GERAÇÃO AUTOMÁTICA DE QUADROS DE HORÁRIOS ESCOLARES. Trabalho de Graduação
 DESENVOLVIMENTO DE INTERFACE WEB MULTIUSUÁRIO PARA SISTEMA DE GERAÇÃO AUTOMÁTICA DE QUADROS DE HORÁRIOS ESCOLARES Trabalho de Graduação Orientando: Vinicius Stein Dani vsdani@inf.ufsm.br Orientadora: Giliane
DESENVOLVIMENTO DE INTERFACE WEB MULTIUSUÁRIO PARA SISTEMA DE GERAÇÃO AUTOMÁTICA DE QUADROS DE HORÁRIOS ESCOLARES Trabalho de Graduação Orientando: Vinicius Stein Dani vsdani@inf.ufsm.br Orientadora: Giliane
Laboratório de Mídias Sociais
 Laboratório de Mídias Sociais Aula 02 Análise Textual de Mídias Sociais parte I Prof. Dalton Martins dmartins@gmail.com Gestão da Informação Universidade Federal de Goiás O que é Análise Textual? Análise
Laboratório de Mídias Sociais Aula 02 Análise Textual de Mídias Sociais parte I Prof. Dalton Martins dmartins@gmail.com Gestão da Informação Universidade Federal de Goiás O que é Análise Textual? Análise
Resumo dos principais conceitos. Resumo dos principais conceitos. Business Intelligence. Business Intelligence
 É um conjunto de conceitos e metodologias que, fazem uso de acontecimentos e sistemas e apoiam a tomada de decisões. Utilização de várias fontes de informação para se definir estratégias de competividade
É um conjunto de conceitos e metodologias que, fazem uso de acontecimentos e sistemas e apoiam a tomada de decisões. Utilização de várias fontes de informação para se definir estratégias de competividade
Gerenciamento de Projeto: Executando o Projeto III. Prof. Msc Ricardo Britto DIE-UFPI rbritto@ufpi.edu.br
 Gerenciamento de Projeto: Executando o Projeto III Prof. Msc Ricardo Britto DIE-UFPI rbritto@ufpi.edu.br Sumário Realizar Aquisições Realizar a Garantia de Qualidade Distribuir Informações Gerenciar as
Gerenciamento de Projeto: Executando o Projeto III Prof. Msc Ricardo Britto DIE-UFPI rbritto@ufpi.edu.br Sumário Realizar Aquisições Realizar a Garantia de Qualidade Distribuir Informações Gerenciar as
Nathalie Portugal Vargas
 Nathalie Portugal Vargas 1 Introdução Trabalhos Relacionados Recuperação da Informação com redes ART1 Mineração de Dados com Redes SOM RNA na extração da Informação Filtragem de Informação com Redes Hopfield
Nathalie Portugal Vargas 1 Introdução Trabalhos Relacionados Recuperação da Informação com redes ART1 Mineração de Dados com Redes SOM RNA na extração da Informação Filtragem de Informação com Redes Hopfield
A Grande Importância da Mineração de Dados nas Organizações
 A Grande Importância da Mineração de Dados nas Organizações Amarildo Aparecido Ferreira Junior¹, Késsia Rita da Costa Marchi¹, Jaime Willian Dias¹ ¹Universidade Paranaense (Unipar) Paranavaí PR Brasil
A Grande Importância da Mineração de Dados nas Organizações Amarildo Aparecido Ferreira Junior¹, Késsia Rita da Costa Marchi¹, Jaime Willian Dias¹ ¹Universidade Paranaense (Unipar) Paranavaí PR Brasil
Instalações Máquinas Equipamentos Pessoal de produção
 Fascículo 6 Arranjo físico e fluxo O arranjo físico (em inglês layout) de uma operação produtiva preocupa-se com o posicionamento dos recursos de transformação. Isto é, definir onde colocar: Instalações
Fascículo 6 Arranjo físico e fluxo O arranjo físico (em inglês layout) de uma operação produtiva preocupa-se com o posicionamento dos recursos de transformação. Isto é, definir onde colocar: Instalações
2.1 Os projetos que demonstrarem resultados (quádrupla meta) serão compartilhados na Convenção Nacional.
 serão compartilhados na Convenção Nacional.") O Prêmio Inova+Saúde é uma iniciativa da SEGUROS UNIMED que visa reconhecer as estratégias de melhoria e da qualidade e segurança dos cuidados com a saúde dos pacientes e ao mesmo tempo contribua com a
O Prêmio Inova+Saúde é uma iniciativa da SEGUROS UNIMED que visa reconhecer as estratégias de melhoria e da qualidade e segurança dos cuidados com a saúde dos pacientes e ao mesmo tempo contribua com a
ENGENHARIA DE SOFTWARE I
 ENGENHARIA DE SOFTWARE I Prof. Cássio Huggentobler de Costa [cassio.costa@ulbra.br] Twitter: www.twitter.com/cassiocosta_ Agenda da Aula (002) Metodologias de Desenvolvimento de Softwares Métodos Ágeis
ENGENHARIA DE SOFTWARE I Prof. Cássio Huggentobler de Costa [cassio.costa@ulbra.br] Twitter: www.twitter.com/cassiocosta_ Agenda da Aula (002) Metodologias de Desenvolvimento de Softwares Métodos Ágeis
5 Extraindo listas de produtos em sites de comércio eletrônico
 5 Extraindo listas de produtos em sites de comércio eletrônico Existem diversos trabalhos direcionadas à detecção de listas e tabelas na literatura como (Liu et. al., 2003, Tengli et. al., 2004, Krüpl
5 Extraindo listas de produtos em sites de comércio eletrônico Existem diversos trabalhos direcionadas à detecção de listas e tabelas na literatura como (Liu et. al., 2003, Tengli et. al., 2004, Krüpl
Classificação da imagem (ou reconhecimento de padrões): objectivos Métodos de reconhecimento de padrões
: objectivos Métodos de reconhecimento de padrões") Classificação de imagens Autor: Gil Gonçalves Disciplinas: Detecção Remota/Detecção Remota Aplicada Cursos: MEG/MTIG Ano Lectivo: 11/12 Sumário Classificação da imagem (ou reconhecimento de padrões): objectivos
Classificação de imagens Autor: Gil Gonçalves Disciplinas: Detecção Remota/Detecção Remota Aplicada Cursos: MEG/MTIG Ano Lectivo: 11/12 Sumário Classificação da imagem (ou reconhecimento de padrões): objectivos
E - Simulado 02 Questões de Tecnologia em Marketing
 E - Simulado 02 Questões de Tecnologia em Marketing Questão 01: (ENADE 2009): Um fabricante de sapatos pode usar a mesma marca em duas ou mais linhas de produtos com o objetivo de reduzir os custos de
E - Simulado 02 Questões de Tecnologia em Marketing Questão 01: (ENADE 2009): Um fabricante de sapatos pode usar a mesma marca em duas ou mais linhas de produtos com o objetivo de reduzir os custos de
SERVIÇO DE ANÁLISE DE REDES DE TELECOMUNICAÇÕES APLICABILIDADE PARA CALL-CENTERS VISÃO DA EMPRESA
 SERVIÇO DE ANÁLISE DE REDES DE TELECOMUNICAÇÕES APLICABILIDADE PARA CALL-CENTERS VISÃO DA EMPRESA Muitas organizações terceirizam o transporte das chamadas em seus call-centers, dependendo inteiramente
SERVIÇO DE ANÁLISE DE REDES DE TELECOMUNICAÇÕES APLICABILIDADE PARA CALL-CENTERS VISÃO DA EMPRESA Muitas organizações terceirizam o transporte das chamadas em seus call-centers, dependendo inteiramente
Pós-Graduação "Lato Sensu" Especialização em Análise de Dados e Data Mining
 Pós-Graduação "Lato Sensu" Especialização em Análise de Dados e Data Mining Inscrições Abertas Início das Aulas: 24/03/2015 Dias e horários das aulas: Terça-Feira 19h00 às 22h45 Semanal Quinta-Feira 19h00
Pós-Graduação "Lato Sensu" Especialização em Análise de Dados e Data Mining Inscrições Abertas Início das Aulas: 24/03/2015 Dias e horários das aulas: Terça-Feira 19h00 às 22h45 Semanal Quinta-Feira 19h00
Semântica para Sharepoint. Busca semântica utilizando ontologias
 Semântica para Sharepoint Busca semântica utilizando ontologias Índice 1 Introdução... 2 2 Arquitetura... 3 3 Componentes do Produto... 4 3.1 OntoBroker... 4 3.2 OntoStudio... 4 3.3 SemanticCore para SharePoint...
Semântica para Sharepoint Busca semântica utilizando ontologias Índice 1 Introdução... 2 2 Arquitetura... 3 3 Componentes do Produto... 4 3.1 OntoBroker... 4 3.2 OntoStudio... 4 3.3 SemanticCore para SharePoint...