Experiências em Armazenamento e Recuperação de Informação
|
|
|
- Liliana de Figueiredo Lopes
- 6 Há anos
- Visualizações:
Transcrição

1 Experiências em Armazenamento e Recuperação de Informação Ana Sofia Queimado ci05006 Filipa Ramalho ci05020 Jennifer Gonçalves ci05032 Faculdade de Engenharia da Universidade do Porto Licenciatura em Ciência da Informação Rua Roberto Frias, s/n, Porto, Portugal Dezembro de 2007
2 Experiências em Armazenamento e Recuperação de Informação Ana Sofia Queimado ci05006 (ci05006@fe.up.pt) Filipa Ramalho ci05020 (ci05020@fe.up.pt) Jennifer Gonçalves ci05032 (ci05032@fe.up.pt) Trabalho realizado no âmbito da disciplina de Armazenamento e Recuperação da Informação I, do 1º semestre, do 3º ano, da Licenciatura em Ciência da Informação da Universidade do Porto, leccionada por Rui Ferreira da Silva. Faculdade de Engenharia da Universidade do Porto Licenciatura em Ciência da Informação Rua Roberto Frias, s/n, Porto, Portugal Dezembro de 2007 Pág.2/38
3 Resumo Este trabalho, através de experiências, leva à compreensão dos aspectos técnicos, semânticos e pragmáticos do armazenamento e recuperação da Informação e também dá a conhecer as técnicas de organização, pesquisa e processamento de informação textual. 0 tema escolhido foi Cancer, com os sub-temas Cancer treatments e Quality of life in persons with câncer. Numa primeira parte, a fase de pré-processamento, foram realizadas três tarefas:filtragem; remoção de stop-words; e stemização. Depois, seguiu-se ao processo de indexação automática. No fim, são descritas as experiências feitas em armazenamento e recuperação de documentos que foram baseadas nos modelos Booleano e Vectorial. Pág.3/38
4 Sumário 1. INTRODUÇÃO ENQUADRAMENTO MOTIVAÇÃO OBJECTIVOS TEMA ESCOLHIDO ESTRUTURA DO TRABALHO 6 2. EXPERIÊNCIAS EM ARMAZENAMENTO DE INFORMAÇÃO CARACTERIZAÇÃO DO REPOSITÓRIO PRÉ-PROCESSAMENTO INDEXAÇÃO 9 3. EXPERIÊNCIAS EM RECUPERAÇÃO DE INFORMAÇÃO MODELO BOOLEANO Experiências com Modelo Booleano Resultados e comentários MODELO VECTORIAL Experiências com Modelo Vectorial Resultados e Comentários CONCLUSÃO MELHORAMENTOS REFERÊNCIAS BIBLIOGRÁFICAS APÊNDICES URLS TABELA DE URLS DO REPOSITÓRIO TABELA DE RECUPERAÇÃO EXAUSTIVA DAS PALAVRAS-CHAVE 38 Índice de Ilustrações FIGURA 2 LISTA DE PALAVRAS-CHAVE...10 FIGURA 4 TABELA EVOLUÇÃO DO Nº DE PALAVRAS DIFERENTES DOS DOCUMENTOS...12 FIGURA 5 RECUPERAÇÃO DE DOC.PELO MODELO BOOLEANO- PERGUNTA: CANCER...16 FIGURA 6 TABELA RESULTADOS EXPERIÊNCIAS TEMA 1-MODELO BOOLEANO...21 FIGURA 7 TABELA RESULTADOS EXPERIÊNCIAS TEMA 2 MODELO BOOLEANO...22 FIGURA 8 MODELO VECTORIAL...24 FIGURA 9 MODELO VECTURIAL COM DUAS DIMENSÕES...24 FIGURA 10 FÓRMULA DE SIMILARIADADE...25 FIGURA 11 - RECUPERAÇÃO DE DOC.PELO MODELO VECTORIAL- PERGUNTA: CANCER...27 FIGURA 12 TABELA RESULTADOS TEMA 1 MODELO VECTORIAL...31 FIGURA 13 TABELA RESULTADOS TEMA 2 MODELO VECTORIAL...31 Pág.4/38
5 1. Introdução 1.1. Enquadramento Este trabalho foi realizado no âmbito da disciplina de Armazenamento e Recuperação da Informação I, da licenciatura de Ciência da Informação. Pretendemos, com este relatório, relatar as nossas experiências em Armazenamento e Recuperação da Informação Motivação As nossas principais motivações para fazer este trabalho prenderam-se essencialmente com o experimentar os objectivos principais da cadeira de maneira a percebermos melhor a matéria leccionada e a perceber na prática os aspectos técnicos e as técnicas de organização, pesquisa e processamento da informação, e também ver como devem ser representados os documentos, as interrogações e as respostas na pesquisa. Assim, a nossa motivação passa por termos a hipótese de ver na prática a matéria leccionada nas aulas teóricas o que se revela muito interessante e até faz crescer uma certa curisodade já que a aplicação foi sendo desenvolvida aos poucos e, portanto só poderiamos experimentar aos poucos Objectivos Este trabalho tem como principal objectivo fazer experiências em Armazenamento e Recuperação de Informação. Assim sendo, pretendemos compreender os aspectos técnicos, semânticos e pragmáticos do armazenamento e recuperação da Informação e também conhecer as técnicas de organização, pesquisa e processamento de informação textual. Por último, temos como objectivo explorar os domínios de aplicação e as questões em aberto no armazenamento e recuperação de Informação Tema escolhido 0 tema escolhido para a elaboração deste trabalho foi Cancer (cancro), com os sub-temas Cancer treatments e Quality of life in persons with câncer Pág.5/38
6 A escolha deste tema recaiu sobre o facto de, infelizmente, este ser um tema actual e muito presente na nossa sociedade devido á enorme quantidade de casos de cancro existentes nos dias de hoje. Este facto faz com que o tema seja interessante para a cadeira de ARI1 uma vez que existe uma considerável quantidade de informação sobre o tema e, portanto, poderíamos experimentar se seria possível fazer uma boa recuperação de informação consoante a relevância dos documentos do repositório Estrutura do Trabalho Este relatório é constituído por cinco partes distintas. A primeira parte é a introdução na qual fazemos um enquadramento do trabalho e falamos da motivação, objectivos e tema escolhido. Numa segunda parte, Experiências em Armazenamento de Documentos, fazemos a caracterização do nosso repositório e descrevemos as experiências com as operações de pré-processamento e indexação. Na terceira parte, Experiências em Recuperação de Documentos, fazemos uma resumida explicação do Modelo Booleano e do Modelo Vectorial e apresentamos as experiencias feitas em cada um deles. A quarta e quinta parte são a conclusão e o apêndice respectivamente. Pág.6/38
7 2. Experiências em Armazenamento de Informação 2.1. Caracterização do Repositório O nosso repositório é constituído por dois temas que já enunciamos anteriormente. Após a entrada no repositório é apresentada uma sucinta descrição de cada tema. Ambos derivam do tema principal Cancer.O tema 1 é "Quality of life in persons with cancer" e com ele pretendemos adquirir um conjunto de documentos que aborde directamente a qualidade de Vida de doentes com cancro. Já com tema 2, "Cancer Treatments pretendemos adquirir um conjunto de documentos que aborde directamente os diferentes tratamentos para o cancro. Contudo tivemos alguns problemas na recolha dos links uma vez que, após termos realizado a recolha, na passagem para o repositório deparamo-nos com a situação de muitos links estarem indisponíveis, tendo que fazer uma nova pesquisa. Tivemos também alguma dificuldade em escolher os artigos irrelevantes visto que nos foi díficil distinguir os relevantes dos irrelevantes, uma vez que os irrelevantes para um tema poderiam ser relevantes para o outro tema. O repositório mostra uma tabela que identifica o conteúdo do repositório em si, sendo constituído por 51 documentos. Destes 51 documentos 19 são relevantes para o sub tema 1, 20 são relevantes para o sub tema 2, apenas dois são relevantes para ambos os temas e 10 são irrelevantes (para ambos os temas). Ao longo do trabalho vamos observando que, através das diferentes partes do pré-processamento, o tamanho dos documentos vai diminuindo. Apresentamos de seguida uma estimativa do tamanho do conjunto dos documentos no seu original. Para o tema 1 tem o tamanho total de: bytes; e para o tema 2 tem o tamanho total de bytes; por fim, o tamanho total do conjunto dos documentos relevantes era de bytes Pré-processamento Na fase de pré-processamento foram realizadas três tarefas: filtragem; remoção de stop-words; e stemização. A tarefa de filtragem dos documentos consistiu em remover caracteres especiais e desnecessários, números sem interesse e até texto ou palavras consideradas Pág.7/38
8 desnecesárias. Desta maneira, procedeu-se a uma observação documento a documento fazendo-se um levantamento dos caracteres e das palavras a eliminar, filtrando-os assim. Os caracteres eliminados foram toda a pontuação em si, como por exemplo, os pontos finais, as vírgulas, os ponto e vírgulas, as reticências, pontos de exclamação e interrogração, todo os acentos, as aspas, os hiféns, etc. A nível de caracteres especiais foram eliminados, por exemplo:, <, >, #, $, %, &, =, *, +,,,,,, De seguida foi realizada a tarefa de remoção de stop-words que consistiu em remover todos os termos que ocorressem com muita frequência. Esta tarefa foi realizada completamente de forma automatica com o recurso à aplicação programada pelo professor. Por fim, concluimos a fase do pré-processamento com a tarefa da stemização que consistiu em converter cada palavra para o seu radical, eliminando sufixos representados por flexões verbais e plurala. Os algoritmos de stemização geralmente incorporam um grande conhecimento de linguística e, por essa razão são dependentes da linguagem. Esta tarefa também foi realizada de forma 100% automática na aplicação desenvolvidada pelo professor. É importante referir que esta fase de pré-processamento ficou registada no repositório (na aplicação), nomeadamente na tabela do listar documentos. Nesta tabela é apresentado, na 1ª coluna, o ID associado a cada documento (um número inteiro de 1 a 51 respectivamente). A 2ª coluna diz respeito ao URL de onde foi retirado o documento original. Na coluna a seguir temos a informação do documento original indicando o chars (tamanho), o pd (numero de palavras diferentes) e a rel (relevância) de cada documento. De notar que estes números são números adquiridos após a filtragem dos documentos. Na 4ª coluna da tabela é apresentada a tarefa da remoção das stopwords ( s/stopwords ), onde é apresentado o novo valor para o chars e para o pd de cada documento. A 5ª coluna diz respeito à última tarefa da fase do pré-processamento dos documentos que é a stemização onde são apresentados novamente os novos valores do chars e para o pd de cada documento. A 6ª e última coluna é relativa à indexação dos documentos de que vamos falar no ponto a seguir. Pág.8/38
9 Na figura seguinte apresentamos um print-sreen de uma linha da tabela para exemplificar o registo que acbamos de explicar: Figura 1 exemplo de registo na tabela do repositório Tabém é de referir que fomos registando numa tabela excel toda esta fase, tabela essa que está disponível em apêndice Indexação O processo de descrição onde as palavras dos documentos são colocadas num índice é denominado de indexação. O processo de indexação automática consiste em identificar palavras relevantes nos documentos de uma colecção de documentos e armazená-las numa estrutura de índice. A identificação dos termos corresponde nada mais é do que à aplicação de um parser (analisador do léxico) que identifique as palavras presentes nos documentos, ignorando os símbolos e caracteres de controlo de arquivo ou de formatação. Desta maneira, o processo de indexação foi feito automáticamente na aplicação com base na lista de palavras-chave definidas por nós. Para identificação das palavras-chave passou-se por duas fases: uma primeira que foi efectuada ao longo da escolha dos links onde se foram recolhendo as palavras que achámos mais importantes; e depois de recolhidos todos os links procedeu-se a uma segunda fase, onde se analisaram todos os documentos relevantes e se fez uma nova recolha das palavras mais importantes e das que mais se repetiam ao longo dos diversos documentos. Após recolhidas todas as palavras aplicamos técnicas adicionais, tais como eliminação de hífens, passagem de todas as palavras para a forma minúscula e passagem das palavras para o singular. O nosso repositório é constituído por 34 palavras-chave. Pág.9/38



10 Na figura seguinte podemos ver as palavras da nossa lista de palavras-chave. Figura 2 Lista de Palavras-chave Para este processo foi importante toda a fase de pré-processamento, principalmente a tarefa de stemização. Para concluir apresentamos de seguida duas tabelas que mostram a evolução do tamanho em todas as tarefas da fase de pré-processamento e indexação e da mesma forma a evolução do número de palavras diferentes: Pág.10/38
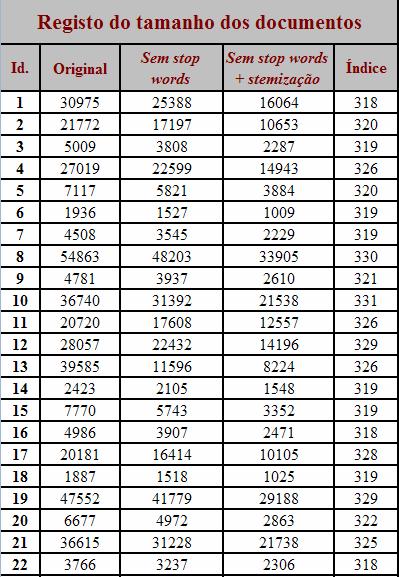
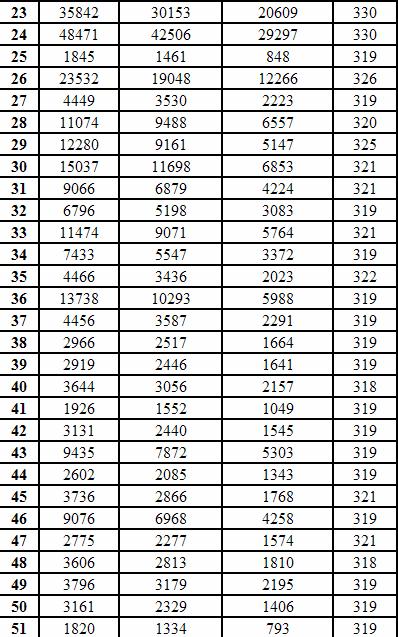
11 Pág.11/38
, tanto o tamanho dos documentos como o")

12 Figura 3 Tabela evolução do nº de palavras diferentes dos documentos Como podemos ver (e como seria de esperar), tanto o tamanho dos documentos como o número de palavras diferentes dos documentos foram diminuindo ao longo do seu tratamento: primeiro com a remoção das stop-words depois com a remoçao de stop- Pág.12/38
13 words + stemização e finalmente com o índice. Podemos afirmar que no tamanho dos documentos a redução mais significativa foi aquando a remoção das stop-words + stemização, sendo maior a diferença no número de palavras diferentes dos documentos quando se da a remoção de stop-words Pág.13/38
14 3. Experiências em Recuperação de Informação Os modelos clássicos de recuperação de informação apresentam estratégias de pesquisa de documentos relevantes para uma consulta. Nestes modelos cada documento é descrito por um conjunto de palavras-chave representativas que procuram representar o assunto do documento e sumariar o seu conteúdo de forma significativa. Os modelos clássicos de recuperação de informação são três: modelo booleano, modelo vectorial e modelo probabilístico. Apenas nos iremos debruçar sobre o modelo booleano e o modelo vectorial Modelo Booleano O Modelo Booleano considera uma consulta como uma expressão booleana convencional, que liga os seus termos através de conectivos lógicos AND, OR, NOT. As expressões booleanas são capazes de unir conjuntos, descrever interjeições e retirar partes de um conjunto.¹ Numa pesquisa o utilizador indica quais são as palavras que o documento resultante deve ter para que seja retornado. Assim os documentos possuem uma intersecção com a consulta e são retornados. Contudo a partir dos conectivos lógicos (and, or e not), o modelo pode ser compreendido de uma outra forma, onde o conjunto de documentos relevantes à consulta é o conjunto de documentos que satisfaz as restrições especificadas na consulta. No modelo booleano um documento é considerado relevante ou não relevante a uma consulta, não existe resultado parcial e não há informação que permita a ordenação do resultado da consulta. Este modelo é mais utilizado para recuperação de dados do que para recuperação de informação. É um bom modelo para quem entende de álgebra booleana contudo, a maioria os utilizadores não entende. Pág.14/38
15 O modelo booleano tem vantagens e desvantagens. As vantagens deste modelo são as seguintes: simplicidade e clareza de expressão lógica; facilidade de implementação e facilidade de interpretação dos resultados de pesquisa. As suas desvantagens são: dificuldade de exprimir queries com expressões booleanas; um documento ou é (1) ou não é (0) relevante; não existe graduação do tipo: pouco similar, muito simila, etc; ausência de ordem na resposta; as respostas podem ser nulas ou muito grandes e por fim este modelo tem tendência a devolver muito poucos ou demasiados documentos. Existem formas para tentar aperfeiçoar os resultados gerados por este modelo como, por exemplo: dar pesos aos termos; usar conjuntos fuzzy; categorização em IR; ordenar a saída, etc Experiências com Modelo Booleano Relatando agora as experiências que realizamos no modelo Booleano é importante começar por dizer quais as instruções para realizarmos estas experiências na aplicação. Sendo assim, sabiamos que só se podia utilizar as conectivas lógicas: e; ou; sem (sem significa NOT); por fim, também sabiamos que o padrão da interrogação tinha que obedecer a uma das seguintes opções: um Termo (uma palavra ou a sua negação); uma conjunção ('e') de Termos; ou um conjunto de disjunções de conjunções de Termos. Primeiramente, começamos por experimentar fazer perguntas à sorte com as palvras-chave, mas os resultados não eram como esperavamos sendo que não conseguiamos recuperar todos os documentos relevantes e recuperavamos muitos irrelevantes. Assim, decidimos fazer uma recuperação exaustiva por cada termo, palavra-chave, e registamos os resultados numa folha excel com manchas de cores com o objectivo de, no final, conseguirmos ter uma ideia geral do que cada palavra recuperava, que documentos relavantes para qual tema, etc. Esta tabela está disponível no fim do relatório, em apêndice. Assim, vamos apenas evidenciar aqui as experiências que realizamos após termos efectuado essa recuperação exaustiva. Para cada tema vamos apresentar as interrogações efectuadas, juntamente com os resultados obtidos. No que concerne aos Pág.15/38
16 resultados apresentados, estes indicam todos os documentos recuperados através da interrogação efectuada, identificados pelo seu número (de 1 a 51) e, para cada documento é apresentada a sua relevância (0 irrelevante; 1 relevante para o tema 1; 2 relevante para o tema 2; 3 relevante para ambos os temas). Consideramos também importante apresentar para cada experiência a taxa de Recuperação (Recall) e de Precisão (precision). É importante, por isso, dizer que a precision e a recall são medidas para avaliar o SRI, que comparam o conjunto de documentos relevantes com o que é obtido pelo SRI, avaliando a qualidade da estratégia de recuperação. A taxa de recall é o número de documentos relevantes recuperados sobre o número total de documentos relevantes; e a taxa de precision é o número de documentos relevantes recuperados sobre o numeros total de documentos recuperados. A nossa primeira experiência cosnsistiu em escolher uma palavra-chave que era comum aos dois temas, cancer, fizemos a pergunta com o Termo cancer em que obtivemos o resultado que podemos ver na figura 3. Figura 4 Recuperação de Doc. Pelo Modelo Booleano- pergunta: cancer Com este resultado reparamos que a palavra cancer aparece em praticamente todos os documentos, ou seja, recupera todos os documentos relavantes à excepção do documento 16 (relevante para o tema 1) e o documento 25 (relevante para o tema 2); e também recupera todos os docuemntos irrelevantes à excepção do do documento 1. Recall = 39/41 = 0,95 = 95% Precision = 39/48 = 0,81 = 81% 2. De seguida vamos apresentar as experiências para o tema 1 e depois para o tema Pág.16/38
17 Tema 1 - Quality of life in persons with cancer Pergunta 1: quality Recall = 20/21 = 0,95 = 95% Precision = 20/23 = 0,87 = 87% Pergunta 2: life Recall = 20/21 = 0,95 = 95% Precision = 20/22 = 0,91 = 91% Pergunta 3: diagnosis Recall = 12/21 = 0,57 = 57% Precision = 12/13 = 0,92 = 92% Pergunta 4: depression ou discomfort ou fatigued Recall = 12/21 = 0,57 = 57% Precision = 12/27 = 0,44 = 44% Pág.17/38
18 Pergunta 5: physical e patient Recall = 12/21 = 0,57 = 57% Precision = 12/15 = 0,80 = 80% Pergunta 6: life e diagnosis Recall = 11/21 = 0,52 = 52% Precision = 11/11 = 1 = 100% Pergunta 7: quality e life Recall = 20/21 = 0,95 = 95% Precision = 20/20 = 1 = 100% Pergunta 8: life ou diagnosis Recall = 21/21 = 1 = 100% Precision = 21/24 = 0,88 = 88% Pág.18/38
19 Tema 2 Cancer treatments Pergunta 1: chemotherapy Recall = 17/22 = 0,77 = 77% Precision = 17/28 = 0,61 = 61% Pergunta 2: radiotherapy Recall = 8/22 = 0,36 = 36% Precision = 8/9 = 0,89 = 89% Pergunta 3: drug Recall = 12/22 = 0,55 = 55% Precision = 12/14 = 0,86 = 86% Pergunta 4: treatment Recall = 21/22 = 0,95 = 95% Precision = 21/27 = 0,78 = 78% Pág.19/38
20 Pergunta 5: sem life e medication Recall = 13/22 = 0,59 = 59% Precision = 20/21 = 0,62 = 62% Pergunta 6: sem physical ou (symptom e drug) Recall = 20/22 = 0,91 = 91% Precision = 20/32 = 0,63 = 63% Pergunta 7: (treatment e chemotherapy) ou (treatment e radiotherapy) Recall = 18/22 = 0,82 = 82% Precision = 18/22 = 0,82 = 82% Resultados e comentários Em relação ao tema 1, no decorrer das experiências realizadas foi-nos possível recuperar numa única pergunta os 20 documentos relevantes para o tema 1 mais os 2 documentos relevantes para ambos os temas, apesar de na mesma terem sido recuperados também documentos irrelevantes, mas foram apenas 2. Na tabela seguinte, é possível ter uma visão geral dos resultados obtidos: Pág.20/38

21 Figura 5 Tabela resultados experiências tema 1-Modelo Booleano Como se pode constatar na tabela, os melhores resultados obtidos foram o da pergunta 8 onde foram recuperados os 21 documentos relevantes e logo de seguida das perguntas 7, 1 e 2 em que foram recuperados 20, 23 e 22 documentos respectivamente e desses recuperados, em todas as perguntas, 20 eram relevantes para o tema 1. De todas as perguntas realizadas apenas uma obteve um recall de 100% (pergunta 8 que recuperou todos os documentos relevantes) e as que obtiveram uma melhor precision (de 100%) foram as pergunta 6 e 7 (em que apenas obtiveram documentos relevantes) porém o recall, na primeira foi apenas de 52% e noutra de 95%. Das restantes perguntas, a que teve piores resultados, no geral, foi a pergunta 4, com 57% de recall e apenas 44% de precision. O comentário que podemos tecer acerca destas experiências é que consideramos que os melhores resultados foram os das pergunas 7 e 8, sendo que das duas optaríamos pela pergunta 7, uma vez que, apesar de não recuperar os 21 documentos relevantes (como a pergunta 8), recupera apenas menos um (20) e tem uma taxa de precision de 100%, enquanto que na pergunta 8 a taxa de precision é de 88%. Já em relação ao tema 2, apesar de todas as experiências realizadas não conseguimos recuperar numa pergunta todos os documentos relevantes para o tema 2, incluindo os 2 documentos relevantes para ambos os temas. No entanto dos 22 temas que eram relevantes para o tema 2 conseguimos numa pergunta recuperar 21 relevantes, embora tivessemos nessa mesma pergunta recuperado mias 6 irrelevantes. Na tabela seguinte, é possível observar uma visão geral dos resultados obtidos com as 7 perguntas referidas: Pág.21/38

22 Figura 6 Tabela resultados experiências tema 2 Modelo Booleano Como é possível verificar, o melhor resultado que obtivemos foi o resultado da Pergunta 4 em que foram recuperados 27 documentos, 21 dos quais relevantes para o tema 2. Ou seja, de todas as perguntas que efectuámos nunca obtivemos um recall de 100%, sendo as que obtiveram melhor recall foram as perguntas 4, 6 e 7 com 95%, 91% e 82% respectivamente. Em relação ao precision as que tiveram melhores resultados foram as perguntas 2, 3 e 7 com 89%, 86% e 82% respectivamente. Das restantes perguntas a que teve resultados menos satisfatórios a nível de recall foi a pergunta 2 e a nível de precision foi a pergunta 1. O comentário que podemos tecer em relação aos resultados é que foram bastante diferentes, sendo que se quisermos dar mais importância à taxa de recall escolheríamos a pergunta 4, no entanto se quiséssemos dar mais importância à precision escolheríamos a pergunta 2. Nós optaríamos, neste caso pela pergunta 4 na medida em que na pergunta 2 apenas obtemos 8 documentos dos 22 relevantes. Em relação a conlusões, podemos dizer que depoi todas as experiências e do contacto que tivemos com este modelo, de maneira geral, quando se consegue aumentar a precision o recall diminui e quando se consegue aumentar o recall a precision diminui. Se utilizarmos disjunções obtemos mais docuemntos, mas tanto devolve mais documentos relevantes, como documentos irrelevantes. Depois, ao utilizar da conectiva lógica e, restringimos o número dos documentos devolvidos. Pág.22/38
23 3.2. Modelo Vectorial O Modelo Vectorial (também chamado de modelo espaço-vectorial) foi criado por Gerard Salton, com o objectivo de ser utilizado num Sistema de Recuperação de Informação (SRI) chamado SMART.³ Neste modelo, cada documento é representado como um vector de termos em que cada termo tem um valor associado a si indicando o grau de importância (peso - weight) do termo no ocumento. Desta maneira, cada documento possui um vector associado é constituído por pares de elementos na forma {(palavra_1, peso_1), (palavra_2,peso_2),..., (palavra_n, peso_n)}. È importante dizer que, os documentos são representados como vectores no espaço de termos. Estes termos são ocorrências únicas nos documentos, que por sua vez são representados pela presença ou ausência de um termo. Todos os termos combinados podem definir cada documento. Além disso, as consultas são representadas da mesma forma, sendo que aos termos das consultas e documentos são acrescentados pesos. Estes pesos especificam o tamanho e a direcção da sua especificação como vector. A distância entre os vectores mede a relação numa consulta. No que toca ao peso dos termos, podemos dizer que o peso de um termo num documento pode ser calculado de diversas formas. Os pesos são usados para calcular a similaridade entre cada documento armazenado e também numa consulta feita pelo usuário. Os métodos de cálculo de peso baseiam-se normalmente no número de ocorrências do termo no documento (frequência). Salton e Buckey dão uma das formas para calcular o peso. Esta forma pretende balancear as características em comum nos documentos (intra-document) e as características para fazer a distinção entre os documentos (inter-document). Assim apresentamos a forma dada por Salton e Buckey em que freq (k,s) _ TF consiste na frequência do termo k no documento/consulta S; log (N / nk) _ IDF (inverse document frequency), onde N é o número de termos na colecção e nk número de vezes que o termo ocorre na colecção. O TF reflete as características intra-documentos e IDF dá uma medida de distinções inter-documento. Os pesos baseados no produto freq (k,s) log (N / nk), são chamados de abordagem tf-idf. Cada elemento do vector de termos é Pág.23/38
24 considerado uma coordenada dimensional. Assim, os documentos podem ser colocados num espaço euclidiano de n dimensões (onde n é o número de termos) e a posição do documento em cada dimensão é dada pelo seu peso. A Figura seguinte mostra o modelo vectorial. Figura 7 Modelo vectorial Podemos dizer que cada dimensão corresponde a um termo, e o valor do documento em cada dimensão varia entre 0 (irrelevante ou não presente) e 1 (totalmente relevante). A figura seguinte apresenta um espaço com duas dimensões (2 termos) representando os documentos. Nesse caso só dois termos são considerados importantes na descrição dos documentos -todos os outros termos são desconsiderados na representação e indexação. Figura 8 Modelo vecturial com duas dimensões As distâncias entre um documento e outro indicam o seu grau de similaridade, ou seja, os documentos que possuem os mesmos termos acabam por ser colocados numa mesma região do espaço e, em teoria, tratam de assuntos idênticos. Pág.24/38
25 A consulta do usuário também é representada por um vector. Desta forma, os vetores dos documentos podem ser comparados com o vector da consulta e o grau de similaridade entre cada um deles pode ser identificado. Os documentos mais similares (mais próximos no espaço) à consulta são considerados relevantes para o usuário e retornados como resposta para ela. Uma das formas de calcular a proximidade entre os vectores é testar o ângulo entre estes vectores. No modelo original, é utilizada uma função denominada de cosine vector similarity que calcula o produto dos vectores de documentos através da fórmula:² Figura 9 fórmula de similariadade Nesta fórmula Q representa o vector de termos da consulta; D é o vector de termos do documento; Wqk são os pesos dos termos da consulta; e Wdk são os pesos dos termos do documento. Depois dos graus de similaridade terem sido calculados, é possível montar uma lista ordenada (ranking) de todos os documentos e seus respectivos graus de relevância à consulta, da maior para a menor relevância. O modelo vectorial tem vantagens tais como: atribuir pesos aos termos melhora o desempenho; é uma estratégia de encontro parcial (função de similaridade), que é melhor que a exatidão do modelo booleano; os documentos são ordenados de acordo com seu grau de similaridade com a consulta. No entanto também possui desvantagens como, por exemplo: ausência de ortogonalidade entre os termos em que poderia encontrar relações entre termos que aparentemente não têm nada em comum; é um modelo generalizado; um documento relevante pode não conter termos da consulta. Pág.25/38
26 Experiências com Modelo Vectorial No que concerne às regras para realizar as experências no Modelo Vectorial, estas eram parecidas com as do Booleano, mas não iguais. Assm, sabíamos que só se podia utilizar as conectivas lógicas: e ou; ou. Cada palavra na sua pergunta podia ser antecedida de um número positivo (o peso da palavra) e, caso não colocassemos um número antes de uma palavra o seu peso era considerado 1. Sabiamos igualmente que deveriamos utilizar o peso 0 (zero) se não quisessemos que uma palavra ocorresse nos documentos. Por fim, sabíamos que o padrão da interrogação tinha que obedecer a uma das seguintes opções: palavra; uma conjunção ('e') de palavras; ou um conjunto de disjunções de conjunções de palavras. Para as experiências com o Modelo Vectorial optamos por fazer as mesmas experiências que fizemos com o Modelo Booleano adaptando as perguntas á sua gramática e atribuindo pesos para dar mais importância a um termo do que a outro. Esta opção deveu-se ao facto de que já tínhamos tido muita dificuldade em conseguir experiências com resultados que fossem mais ao emnos claros e assim podemos também ver as diferenças na recuperação de um para o outro modelo com as mesmas perguntas. Mais uma vez, para cada tema vamos apresentar as interrogações efectuadas, juntamente com os resultados obtidos. No que concerne aos resultados apresentados, relembramos que estes indicam todos os documentos recuperados através da interrogação efectuada, identificados pelo seu número (de 1 a 51) e, para cada documento é apresentada a sua relevância (especialista- nossa : 0 irrelevante; 1 relevante para o tema 1; 2 relevante para o tema 2; 3 relevante para ambos os temas) e, agora, a relevância do modelo (0- totalmente irrelevante a 1 totalmente relevante). Consideramos mais uma vez importante apresentar para cada experincia a taxa de Recuperação (Recall) e de Precisão (precision) que, apesar de serem em quase todas as experiências os mesmos valores que no modelo Booleano, alguns podem ser diferentes já que entra um novo facto que é o n resultados e o peso. Como no Modelo Booleano, a nossa primeira experiência cosnsistiu em escolher uma palavra-chave que era comum aos dois temas, cancer, fizemos a pergunta com o Termo cancer em que obtivemos o resultado que podemos ver na figura seguinte. Pág.26/38
27 Figura 10 - Recuperação de Doc. Pelo Modelo Vectorial- pergunta: cancer Recall = 26/41 = 0,63 = 63% Precision = 26/31 = 0,83 = 83% De seguida apresentamos as experiências para o tema 1 e depois para o tema 2. Tema 1 - Quality of life in persons with cancer Pergunta 1: quality Recall = 20/21 = 0,95 = 95% Precision = 20/23 = 0,86 = 86% Pergunta 2: life Recall = 20/21 = 0,95 = 95% Precision = 20/22 = 0,90 = 90% Pergunta 3: diagnosis Recall = 12/21 = 0,57 = 57% Precision = 12/13 = 0,92 = 92% Pág.27/38
28 Pergunta 4: 8 depression ou 6 discomfort ou 4 fatigued Recall = 9/21 = 0,43 = 43% Precision = 9/25 = 0,36 = 36% Pergunta 5: 8 patient e 6 physical Recall = 11/21 = 0,52 = 52% Precision = 11/15 = 0,73 = 73% Pergunta 6: 6 life e 4 diagnosis Recall = 11/21 = 0,52 = 52% Precision = 11/12 = 0,92 = 92% Pergunta 7: 6 quality e 4 life Recall = 19/21 = 0,90 = 90% Precision = 19/20 = 0,95 = 95% Pág.28/38
29 Pergunta 8: 6 life ou 4 diagnosis Recall = 21/21 = 1 = 100% Precision = 21/25 = 0,84 = 84% Tema 2 Cancer treatments Pergunta 1: chemotherapy Recall = 17/22 = 0,77 = 77% Precision = 17/28 = 0,60 = 60% Pergunta 2: radiotherapy Recall = 8/22 = 0,36 = 36% Precision = 8/9 = 0,88 = 88% Pergunta 3: drug Recall = 12/22 = 0,54 = 54% Precision = 12/14 = 0,85 = 85% Pág.29/38
30 Pergunta 4: treatment Recall = 21/22 = 0,95 = 95% Precision = 21/27 = 0,77 = 77% Pergunta 5: 0 life e 8 medication Recall = 7/22 = 0,32 = 32% Precision = 7/20 = 0,35 = 35% Pergunta 6: 0 physical ou ( 4 symptom e 6 drug) Recall = 16/22 = 0,73 = 73% Precision = 16/30 = 0,53 = 53% Pergunta 7: (6 treatment e 8 chemotherapy) ou (6 treatment e 8 radiotherapy) Recall = 20/22 = 0,91 = 91% Precision = 20/22 = 0,91 = 91% Pág.30/38


31 Resultados e Comentários Em relação ao tema 1, após as experiências realizadas pudemos sintetizar os resultados obtidos na seguinte tabela: Figura 11 Tabela Resultados tema 1 Modelo Vectorial Como é possível verificar, o valor máximo obtido no recall é 100%, uma vez que, tal como já foi referido, fizemos as mesmas perguntas do modelo Booleano. Relativamente à precision, sempre que o valor do recall atingia os 95%. Em relação aos comentários, com este modelo os melhores resultados obtiveram os mesmo valores de recall e precision do modelo Booleano, mas é importante referir que, no conjunto das perguntas conseguimos detectar, por exemplo, que documentos considerados (por nós) irrelevantes obtinham uma relevância neste modelo muito superior a muitos dos documentos recuperados relevantes. Em relação ao tema 2, após as experiências realizadas pudemos sintetizar os resultados obtidos na seguinte tabela: Figura 12 Tabela resultados Tema 2 Modelo Vectorial Pág.31/38
32 Como se pode ver o melhor resultado de recall foi o da pergunta 4, mais uam vez, e o de precision foi o da pergunta 7, o que difere do modelo booleano. Já também diferente do modelo booleano foi o pior resultado, sendo que este coube à pergunta 5 com 32% de taxa de recall e 35% de taxa de precision. Como comentário podemos dizer que neste tema obtivemos valores diferentes sendo que ficou aqui mais claro qual a pergunta melhor, de maneira geral, para a recuperação dos documentos. Aqui escolheríamos a pergunta 7 já que tem uma taxa de recall de 91% (com 20 documentos relevantes recuperados de 22) e uma taxa de precision de 91% (uma vez que o numero de documentos recuperados é igual ao numero de documentos relevantes). Em relação às conclusões deste modelos, depois de todas as experiências e do contacto com o modelo vectorial podemos dizer que, de maneira geral, que o modelo vectorial em relação ao booleano tem vantagens. Essas vantages são o facto de permitir a ordenação dos documentos recuperados de acordo com o maior nível de relevância em função da pergunta efectuada e, deste modo, limitando o número de documentos recuperados, é possível eliminar a devolução de documentos irrelevantes e permite a atribuição de pesos diferentes às palavras-chave, e, assim, torna-se mais fácil e simples recuperar apenas os documentos relevantes. Pág.32/38
33 4. Conclusão Com este trabalho tivemos a oportunidade de realizar experiências em Armazenamento de Informação e experiências em Recuperação de Informação e, por isso, estamos agora prontas para fazer as principais conlusões após a realização destas experiências. No que concerne à pesquisa de documentos para a construção do nosso repositório podemos concluir que: Deveriamos ter escolhido temas não tão proximos tematicamente, ou seja, com uma larga ligação. Tecemos esta conclusão porque os temas que escolhemos revelaram-se, consequentemente nos documentos escolhidos, muito próximos, o que resultou em experiências de Recuperação de Informação dificeis e não muito claras uma vez que a maioria das palavras-chave funcionavam para todos os documentos do repositório; Quanto aos documentos irrelevantes, estes mostraram-se mal escolhidos no sentido em que, apesar de irrevelevantes para os temas, situavam-se na grande Temática do cancer o que veio a tornar-se num obstáculo já que os irrelevanmtes também continham a maioria das palavras-chave. é que: No que toca às fases de pré-processamento e indexação o que podemos concluir Existe, na verdade, uma gande vantagem na remoção de pontuação, caracteres indesejáveis e stop-words, assim como da radicalização e indexação com o objectivo da redução no tamanho dos documentos existentes no repositório; Em relação a problemas, no que concerne à tarefa da filtragem é importante dizer que foi dolorosa uma vez que tívemos que rever documento a documento e, em relação à radicalização, detectamos problemas porque em palavras-chave como medical e medication ambas têm o mesmo radical apesar de terem significados diferentes e isso prejudicaria as experiências em Recuperação de Informação. Pág.33/38
34 Por fim, em relação às experiências em recuperação de informação, realizadas com o Modelo Booleano e o Modelo Vectorial, retiramos as seguintes conclusões: Através das experiências realizadas observamos que havia uma grande dificuldade em recuperar os documentos relevantes sem recuperar simultaneamente os irrelevantes, isto porque como já foi dito anteriormente os temas são muito próximos daí a dificuldade em recuperar apenas os relevantes para um tema sem recuperar também os relevantes para o outro tema. No que toca à relevância dos documentos, conseguimos observar nas experiências do modelo vectorial que, por vezes, documentos que consideramos totalmente irrelevantes têm uma relevância no modelo bastante alta o que faz com que duvidemos da nossa classificação, mas ao mesmo tempo nos faz concluir que o facto de uma palavra aparecer imensas vezes num docuemento não quer necessáriamente dizer que esse docuemnto é relevante na busca por esse termo. Pág.34/38
35 5. Melhoramentos Ao longo da realização deste trabalho foram detectados alguns melhoramentos que agora devemos sugerir. Após realizada cada tarefa da fase de pré-processamento deveria haver a possibilidade de aceder ao documentos a fim de se fazerem comparações e verificações. Da mesma maneira, após a indexação também deveria ser possivel aceder aos documentos para facilitar a consulta dos mesmos na fase das experiências em recuperação da Informação para observar quais as pslavraschave presentes nos documentos; Para sentirmos e sermos mais correctos na escolha das palvras fases, ou para consultarmos de que maneira fomos correctos na escolha das mesmas, deveria constar na lista de índices (palavras-chave) o número de vezes que cada palavrachave aparece em cada documento; A linguagem das interrograções no modelo Booleano deveria ser menos restritiva ou primitiva na medida em que as conectivas lógicas deveriam ter a possibilidade de serem utilizadas de diversas maneiras e não em condições tão restritas; Deveria ser possivel modificar ou escolher como uma palavra-chave deve ser radicalizada de maneira a ultrapassar o obstáculo das palvras com significados diferentes, mas que têm o mesmo radical; No que concerne a melhoramentos que não estão directamente ligados com a aplicação destacámos alguns como a reformulação dos temas ou das palavraschave; e mais tempo para realizar as experiências em ambos os modelos já que tivemos pouco tempo para o fazer porque para além de fazer as perguntas é preciso meditar nos resultados para as reformular. Pág.35/38
36 6. Referências Bibliográficas ¹ SALTON, Gerard; MACGILL, Michael J. Introduction to Modern Information Retrieval. New York: McGRAW-Hill, p ² SALTON, Gerard; Buckley, Christopher - Term-Weighting Approaches in Automatic Text Retrieval. Department of Computer Science, Cornell University, Ithaca, NY 14853, USA ³BAEZA-YATES, Ricardo - Modern information retrieval. New York: ACM Press, cop ISBN X Pág.36/38


37 7. Apêndices 7.1. URLs Modelos para Recuperação da Informação. Disponível em Tabela de URLs do Repositório Pág.37/38

38 7.3. Tabela de recuperação exaustiva das palavras-chave Pág.38/38
Modelo Espaço Vetorial. Mariella Berger
 Modelo Espaço Vetorial Mariella Berger Agenda Introdução Atribuição de Pesos Frequência TF-IDF Similaridade Exemplo Vantagens e Desvantagens Modelo Espaço Vetorial Introdução Modelo Espaço Vetorial O modelo
Modelo Espaço Vetorial Mariella Berger Agenda Introdução Atribuição de Pesos Frequência TF-IDF Similaridade Exemplo Vantagens e Desvantagens Modelo Espaço Vetorial Introdução Modelo Espaço Vetorial O modelo
Profª Ana Lúcia Lima Marreiros Maia Profª Fabiana Cristina Bertoni
 Profª Ana Lúcia Lima Marreiros Maia Profª Fabiana Cristina Bertoni Motivação e Objetivos Etapas do Desenvolvimento de um Sistema de Recuperação de Informações (SRI): Pré-processamento; Representação; Extração
Profª Ana Lúcia Lima Marreiros Maia Profª Fabiana Cristina Bertoni Motivação e Objetivos Etapas do Desenvolvimento de um Sistema de Recuperação de Informações (SRI): Pré-processamento; Representação; Extração
4 Recuperação de Informação
 4 Recuperação de Informação No presente capítulo são apresentados os fundamentos da área de Recuperação de Informação utilizados em Mineração de Textos, como por exemplo, os modelos de representação de
4 Recuperação de Informação No presente capítulo são apresentados os fundamentos da área de Recuperação de Informação utilizados em Mineração de Textos, como por exemplo, os modelos de representação de
03/07/2017. Modelo de Recuperação de Informação
 Modelo de Recuperação de Informação Modelo de Recuperação de Informação Um modelo de recuperação de informação é a especificação formal de três elementos: a representação dos documentos; a representação
Modelo de Recuperação de Informação Modelo de Recuperação de Informação Um modelo de recuperação de informação é a especificação formal de três elementos: a representação dos documentos; a representação
Recuperação de Informação
 Recuperação de Informação Avaliação de Desempenho de Sistemas de Recuperação de Informação Renato Fernandes Corrêa 1 Para que avaliar? Existem muitos modelos de RI, mas qual é o melhor? Qual a melhor escolha
Recuperação de Informação Avaliação de Desempenho de Sistemas de Recuperação de Informação Renato Fernandes Corrêa 1 Para que avaliar? Existem muitos modelos de RI, mas qual é o melhor? Qual a melhor escolha
Recuperação de Informações
 Recuperação de Informações Ana Carolina Salgado & Fernando Fonseca Comparação (matching) Dados Inferência Modelo Ling Consulta Esp da Consulta Recuperação de Dado X Informação Recuperação de Recuperação
Recuperação de Informações Ana Carolina Salgado & Fernando Fonseca Comparação (matching) Dados Inferência Modelo Ling Consulta Esp da Consulta Recuperação de Dado X Informação Recuperação de Recuperação
Recuperação de Dado X Informação. Gerenciamento de Dados e Informação. Histórico. Recuperação de Informação. Histórico. Histórico
 Recuperação de Dado X Informação Gerenciamento de Dados e Informação Recuperação de Informação Fernando Fonseca Ana Carolina Robson Fidalgo Comparação (matching) Recuperação de Dados Exata Recuperação
Recuperação de Dado X Informação Gerenciamento de Dados e Informação Recuperação de Informação Fernando Fonseca Ana Carolina Robson Fidalgo Comparação (matching) Recuperação de Dados Exata Recuperação
Realimentação de Relevância
 Wendel Melo Faculdade de Computação Universidade Federal de Uberlândia Recuperação da Informação Ciclo de realimentação onde uma consulta q recebida do usuário é transformada em uma consulta modificada
Wendel Melo Faculdade de Computação Universidade Federal de Uberlândia Recuperação da Informação Ciclo de realimentação onde uma consulta q recebida do usuário é transformada em uma consulta modificada
Gestão e Recuperação de Informação. Avaliação em Sistemas de Recuperação de Informação. José Borbinha DEI/IST
 Gestão e Recuperação de Informação Avaliação em Sistemas de Recuperação de Informação José Borbinha DEI/IST Problema: Como avaliar um sistema de RI? 2 Comecemos, analisando um exemplo... 3 Exemplo... 4
Gestão e Recuperação de Informação Avaliação em Sistemas de Recuperação de Informação José Borbinha DEI/IST Problema: Como avaliar um sistema de RI? 2 Comecemos, analisando um exemplo... 3 Exemplo... 4
Pré-Processamento de Documentos
 Pré-Processamento de Documentos Introdução Pré-Processamento : Análise léxica; Stopwords; Stemming; Vocabulário; Thesaurus Compressão: Fundamentos; Método Estatístico; Método Dicionário; Arquivos Invertidos
Pré-Processamento de Documentos Introdução Pré-Processamento : Análise léxica; Stopwords; Stemming; Vocabulário; Thesaurus Compressão: Fundamentos; Método Estatístico; Método Dicionário; Arquivos Invertidos
3 Recuperação de Informações Textuais
 3 Recuperação de Informações Textuais Tudo deveria se tornar o mais simples possível, mas não simplificado. Albert Einstein Sistemas tradicionais de indexação costumam utilizar-se de termos-índice, que
3 Recuperação de Informações Textuais Tudo deveria se tornar o mais simples possível, mas não simplificado. Albert Einstein Sistemas tradicionais de indexação costumam utilizar-se de termos-índice, que
Mineração de Textos. Mineração de Textos
 Mineração de Textos Os estudos em Aprendizado de Máquina normalmente trabalham com dados estruturados Entretanto, uma grande quantidade de informação é armazenada em textos, que são dados semi-estruturados
Mineração de Textos Os estudos em Aprendizado de Máquina normalmente trabalham com dados estruturados Entretanto, uma grande quantidade de informação é armazenada em textos, que são dados semi-estruturados
Ficha de Exercícios nº 1
 Nova School of Business and Economics Álgebra Linear Ficha de Exercícios nº 1 Espaços Vectoriais 1 Qual das seguintes afirmações é verdadeira? a) Um espaço vectorial pode ter um número ímpar de elementos.
Nova School of Business and Economics Álgebra Linear Ficha de Exercícios nº 1 Espaços Vectoriais 1 Qual das seguintes afirmações é verdadeira? a) Um espaço vectorial pode ter um número ímpar de elementos.
Universidade do Sul de Santa Catarina Ciência da Computação Aula 09 Introdução a Análise de Textos Prof. Max Pereira
 Universidade do Sul de Santa Catarina Ciência da Computação Técnicasde InteligênciaArtificial Aula 09 Introdução a Análise de Textos Prof. Max Pereira Processamento de Linguagem Natural Conjunto de técnicas
Universidade do Sul de Santa Catarina Ciência da Computação Técnicasde InteligênciaArtificial Aula 09 Introdução a Análise de Textos Prof. Max Pereira Processamento de Linguagem Natural Conjunto de técnicas
Organizaçãoe Recuperaçãode Informação GSI521. Prof. Dr. Rodrigo Sanches Miani FACOM/UFU
 Organizaçãoe Recuperaçãode Informação GSI521 Prof. Dr. Rodrigo Sanches Miani FACOM/UFU Pré-processamento de documentos Organização e Recuperação de Informação(GSI521) Introdução O pré-processamento de
Organizaçãoe Recuperaçãode Informação GSI521 Prof. Dr. Rodrigo Sanches Miani FACOM/UFU Pré-processamento de documentos Organização e Recuperação de Informação(GSI521) Introdução O pré-processamento de
Trabalho de LP 15/07/2013. Prof. Flávio Miguel Varejão
 15/07/2013 Trabalho de LP Prof. Flávio Miguel Varejão OBSERVAÇÃO IMPORTANTE: LEIA ATENTAMENTE TODA A ESPECIFICAÇÃO DO TRABALHO E INSTRUÇÕES DE SUBMISSÃO DE MODO A NÃO COMETER ENGANOS POR DESATENÇÃO E SER
15/07/2013 Trabalho de LP Prof. Flávio Miguel Varejão OBSERVAÇÃO IMPORTANTE: LEIA ATENTAMENTE TODA A ESPECIFICAÇÃO DO TRABALHO E INSTRUÇÕES DE SUBMISSÃO DE MODO A NÃO COMETER ENGANOS POR DESATENÇÃO E SER
Revisão. Meio ambiente da Recuperação de Informação. Linguagem Analógico x Digital
 Revisão Meio ambiente da Recuperação de Informação Linguagem Analógico x Digital 1 Recuperação de Informação Recuperação de informação é o nome dado ao processo ou método pelo qual um potencial usuário
Revisão Meio ambiente da Recuperação de Informação Linguagem Analógico x Digital 1 Recuperação de Informação Recuperação de informação é o nome dado ao processo ou método pelo qual um potencial usuário
Organizaçãoe Recuperaçãode Informação GSI521. Prof. Dr. Rodrigo Sanches Miani FACOM/UFU
 Organizaçãoe Recuperaçãode Informação GSI521 Prof. Dr. Rodrigo Sanches Miani FACOM/UFU Modelosde RI e o ModeloBooleano Organização e Recuperação de Informação(GSI521) Tópicos Modelagem em RI; Caracterização
Organizaçãoe Recuperaçãode Informação GSI521 Prof. Dr. Rodrigo Sanches Miani FACOM/UFU Modelosde RI e o ModeloBooleano Organização e Recuperação de Informação(GSI521) Tópicos Modelagem em RI; Caracterização
Terceira Geração de Sistemas de Pesquisa de Informação
 Terceira Geração de Sistemas de Pesquisa de Informação João Ferreira Rui Jesus Arnaldo Abrantes jferreira@deetc.isel.ipl.pt rmfj@isel.ipl.pt aja@cedet.isel.ipl.pt Sumário: Pretende-se discutir e fundamentar
Terceira Geração de Sistemas de Pesquisa de Informação João Ferreira Rui Jesus Arnaldo Abrantes jferreira@deetc.isel.ipl.pt rmfj@isel.ipl.pt aja@cedet.isel.ipl.pt Sumário: Pretende-se discutir e fundamentar
Qualidade. Ana Madureira
 Qualidade Ana Madureira Qualidade da Informação A qualidade de uma informação é apreciada em função da sua pertinência (adaptação às necessidades do sistema de gestão). Três características permitem medir
Qualidade Ana Madureira Qualidade da Informação A qualidade de uma informação é apreciada em função da sua pertinência (adaptação às necessidades do sistema de gestão). Três características permitem medir
Teoria dos conjuntos difusos
 Teoria dos conjuntos difusos Documento complementar à dissertação José Iria ee06210@fe.up.pt - 10-03-2011. A teoria dos conjuntos difusos foi proposta por Lotfi Zadeh num artigo publicado em 1965 na revista
Teoria dos conjuntos difusos Documento complementar à dissertação José Iria ee06210@fe.up.pt - 10-03-2011. A teoria dos conjuntos difusos foi proposta por Lotfi Zadeh num artigo publicado em 1965 na revista
25/04/2017. Modelo de Recuperação de Informação
 Modelo de Recuperação de Informação Modelo de Recuperação de Informação Um modelo de recuperação de informação é a especificação formal de três elementos: a representação dos documentos; a representação
Modelo de Recuperação de Informação Modelo de Recuperação de Informação Um modelo de recuperação de informação é a especificação formal de três elementos: a representação dos documentos; a representação
Indexação e Modelos Clássicos
 Wendel Melo Faculdade de Computação Universidade Federal de Uberlândia Recuperação da Informação Adaptado do Material da Profª Vanessa Braganholo - IC/UFF Construção de um Sistema de Busca 1ª Etapa: Definir
Wendel Melo Faculdade de Computação Universidade Federal de Uberlândia Recuperação da Informação Adaptado do Material da Profª Vanessa Braganholo - IC/UFF Construção de um Sistema de Busca 1ª Etapa: Definir
Arquivos invertidos 39
 Arquivos invertidos 39 Arquivos invertidos É um mecanismo que utiliza palavras para indexar uma coleção de documentos a fim de facilitar a busca e a recuperação Estruturas de um arquivo invertido Vocabulário
Arquivos invertidos 39 Arquivos invertidos É um mecanismo que utiliza palavras para indexar uma coleção de documentos a fim de facilitar a busca e a recuperação Estruturas de um arquivo invertido Vocabulário
Apêndice B - Sistemas Numéricos
 Página 1 de 5 Microcontroladores PIC on-line GRÁTIS! Indice Sistema de desenvolvimento Contacte-nos Apêndice B Sistemas Numéricos Introdução B.1 Sistema numérico decimal B.2 Sistema numérico binário B.3
Página 1 de 5 Microcontroladores PIC on-line GRÁTIS! Indice Sistema de desenvolvimento Contacte-nos Apêndice B Sistemas Numéricos Introdução B.1 Sistema numérico decimal B.2 Sistema numérico binário B.3
Recursos B-on CURRENT CONTENTS. Saber usar. Novembro,2008
 Recursos B-on CURRENT CONTENTS Saber usar Novembro,2008 Bases de referência O que são? As bases de referência permitem-nos pesquisar as referências de um documento e desta forma obter a sua localização.
Recursos B-on CURRENT CONTENTS Saber usar Novembro,2008 Bases de referência O que são? As bases de referência permitem-nos pesquisar as referências de um documento e desta forma obter a sua localização.
Lista de exercícios 2 Recuperação de Informação Textual
 Lista de exercícios 2 Recuperação de Informação Textual 2 de dezembro de 2015 0.1 O que é o modelo bag-of-words? Porque ele é uma simplificação? Dê um exemplo em que ele estaria incorreto. 0.2 O que é
Lista de exercícios 2 Recuperação de Informação Textual 2 de dezembro de 2015 0.1 O que é o modelo bag-of-words? Porque ele é uma simplificação? Dê um exemplo em que ele estaria incorreto. 0.2 O que é
TÉCNICO DE INFORMÁTICA - SISTEMAS
 782 - Programação em C/C++ - estrutura básica e conceitos fundamentais Linguagens de programação Linguagem de programação são conjuntos de palavras formais, utilizadas na escrita de programas, para enunciar
782 - Programação em C/C++ - estrutura básica e conceitos fundamentais Linguagens de programação Linguagem de programação são conjuntos de palavras formais, utilizadas na escrita de programas, para enunciar
Aula 02: Custos de um algoritmo e funções de complexidade
 MCTA028 Programação Estruturada Aula 02: Custos de um algoritmo e funções de complexidade Prof. Jesús P. Mena-Chalco jesus.mena@ufabc.edu.br 3Q-20106 1 Linguagem C: Tipos de dados 2 Linguagem C: Tipos
MCTA028 Programação Estruturada Aula 02: Custos de um algoritmo e funções de complexidade Prof. Jesús P. Mena-Chalco jesus.mena@ufabc.edu.br 3Q-20106 1 Linguagem C: Tipos de dados 2 Linguagem C: Tipos
Expansão/Redução de imagens no domínio das frequências
 Faculdade de Engenharia da Universidade do Porto LEEC 5ºAno/1ºSemestre Televisão Digital 2006/2007 Trabalho 1: Expansão/Redução de imagens no domínio das frequências Grupo 8: Pedro Cunha (ee00047@fe.up.pt)
Faculdade de Engenharia da Universidade do Porto LEEC 5ºAno/1ºSemestre Televisão Digital 2006/2007 Trabalho 1: Expansão/Redução de imagens no domínio das frequências Grupo 8: Pedro Cunha (ee00047@fe.up.pt)
Segundo trabalho de Organização e Recuperação da Informação
 FACOM- UFU Professor: Wendel Melo Segundo trabalho de Organização e Recuperação da Informação 2018-02 Descrição Este trabalho consiste em duas etapas: 1. Implementação de cálculo da ponderação TF-IDF,
FACOM- UFU Professor: Wendel Melo Segundo trabalho de Organização e Recuperação da Informação 2018-02 Descrição Este trabalho consiste em duas etapas: 1. Implementação de cálculo da ponderação TF-IDF,
Tabelas de Hash MBB. Novembro de Algoritmos e Complexidade LEI-LCC
 Tabelas de Hash Algoritmos e Complexidade LEI-LCC 2010-2011 MBB Novembro de 2010 Tabelas e Acesso a Informação As estruturas de dados apresentadas anteriormente têm como objectivo o armazenamento de informação,
Tabelas de Hash Algoritmos e Complexidade LEI-LCC 2010-2011 MBB Novembro de 2010 Tabelas e Acesso a Informação As estruturas de dados apresentadas anteriormente têm como objectivo o armazenamento de informação,
Universidade de Santa Cruz do Sul UNISC Departamento de informática COMPILADORES. Introdução. Geovane Griesang
 Universidade de Santa Cruz do Sul UNISC Departamento de informática COMPILADORES Introdução geovanegriesang@unisc.br Processadores de linguagem Linguagens de programação são notações para se descrever
Universidade de Santa Cruz do Sul UNISC Departamento de informática COMPILADORES Introdução geovanegriesang@unisc.br Processadores de linguagem Linguagens de programação são notações para se descrever
Recuperação de Informação em Bases de Texto
 Recuperação de Informação em Bases de Texto Mestrado em Engenharia Informática Universidade de Évora 2010/2011 Paulo Quaresma pq@di.uevora.pt http://www.moodle.uevora.pt 1 Objectivos Programa Avaliação
Recuperação de Informação em Bases de Texto Mestrado em Engenharia Informática Universidade de Évora 2010/2011 Paulo Quaresma pq@di.uevora.pt http://www.moodle.uevora.pt 1 Objectivos Programa Avaliação
Concepção e Fabrico Assistido por Computador
 Concepção e Fabrico Assistido por Computador João Pedro Amorim Lobato: gei00017@fe.up.pt Turma: LGEI Trabalho sobre Regressões em Visual Basic Licenciatura em Gestão e Engenharia Industrial
Concepção e Fabrico Assistido por Computador João Pedro Amorim Lobato: gei00017@fe.up.pt Turma: LGEI Trabalho sobre Regressões em Visual Basic Licenciatura em Gestão e Engenharia Industrial
Manual de Utilizador
 Manual de Utilizador Introdução Este manual de utilizador tem por objectivo a introdução ao programa de gestão de um campeonato de voleibol aos seus utilizadores. Para isso, a informação será organizada
Manual de Utilizador Introdução Este manual de utilizador tem por objectivo a introdução ao programa de gestão de um campeonato de voleibol aos seus utilizadores. Para isso, a informação será organizada
CAP. VI ANÁLISE SEMÂNTICA
 CAP. VI ANÁLISE SEMÂNTICA VI.1 Introdução Semântica SIGNIFICADO, SENTIDO LÓGICO, COERÊNCIA,... Diferença entre SINTAXE e SEMÂNTICA Sintaxe : descreve as estruturas de uma linguagem; Semântica : descreve
CAP. VI ANÁLISE SEMÂNTICA VI.1 Introdução Semântica SIGNIFICADO, SENTIDO LÓGICO, COERÊNCIA,... Diferença entre SINTAXE e SEMÂNTICA Sintaxe : descreve as estruturas de uma linguagem; Semântica : descreve
Marina Andretta. 10 de outubro de Baseado no livro Introduction to Linear Optimization, de D. Bertsimas e J. N. Tsitsiklis.
 Solução básica viável inicial Marina Andretta ICMC-USP 10 de outubro de 2016 Baseado no livro Introduction to Linear Optimization, de D. Bertsimas e J. N. Tsitsiklis. Marina Andretta (ICMC-USP) sme0211
Solução básica viável inicial Marina Andretta ICMC-USP 10 de outubro de 2016 Baseado no livro Introduction to Linear Optimization, de D. Bertsimas e J. N. Tsitsiklis. Marina Andretta (ICMC-USP) sme0211
Análise e Processamento de Bio-Sinais. Mestrado Integrado em Engenharia Biomédica. Sinais e Sistemas. Licenciatura em Engenharia Física
 Análise e Processamento de Bio-Sinais Mestrado Integrado em Engenharia Biomédica Licenciatura em Engenharia Física Faculdade de Ciências e Tecnologia Slide 1 Slide 1 Sobre Modelos para SLIT s Introdução
Análise e Processamento de Bio-Sinais Mestrado Integrado em Engenharia Biomédica Licenciatura em Engenharia Física Faculdade de Ciências e Tecnologia Slide 1 Slide 1 Sobre Modelos para SLIT s Introdução
SEBENTA INTRODUÇÃO Á ALGORITMIA
 SEBENTA INTRODUÇÃO Á ALGORITMIA O desenvolvimento de programas para computador está sempre baseado na tarefa de programar um computador para seja resolvido um problema ou executada uma função e assim dar
SEBENTA INTRODUÇÃO Á ALGORITMIA O desenvolvimento de programas para computador está sempre baseado na tarefa de programar um computador para seja resolvido um problema ou executada uma função e assim dar
Compiladores. Análise Léxica
 Compiladores Análise Léxica Regras Léxicas Especificam o conjunto de caracteres que constituem o alfabeto da linguagem, bem como a maneira que eles podem ser combinados; Exemplo Pascal: letras maiúsculas
Compiladores Análise Léxica Regras Léxicas Especificam o conjunto de caracteres que constituem o alfabeto da linguagem, bem como a maneira que eles podem ser combinados; Exemplo Pascal: letras maiúsculas
Algoritmos - 1. Alexandre Diehl. Departamento de Física - UFPel
 Algoritmos - 1 Alexandre Diehl Departamento de Física - UFPel Conceitos básicos Computador: conceito clássico (até quando????) HARDWARE (partes físicas) SOFTWARE (programas) SCEF 2 Conceitos básicos Computador:
Algoritmos - 1 Alexandre Diehl Departamento de Física - UFPel Conceitos básicos Computador: conceito clássico (até quando????) HARDWARE (partes físicas) SOFTWARE (programas) SCEF 2 Conceitos básicos Computador:
Construção e Energias Renováveis. Volume I Energia Eólica (parte 1) um Guia de O Portal da Construção.
 um Guia de O Portal da Construção.") Construção e Energias Renováveis Volume I Energia Eólica (parte 1) um Guia de Copyright, todos os direitos reservados. Este Guia Técnico não pode ser reproduzido ou distribuído sem a expressa autorização
Construção e Energias Renováveis Volume I Energia Eólica (parte 1) um Guia de Copyright, todos os direitos reservados. Este Guia Técnico não pode ser reproduzido ou distribuído sem a expressa autorização
2.3.4 Algoritmos de SAT
 114 CAÍTULO 2. LÓGICA ROOSICIONAL 2.3.4 Algoritmos de SAT Os algoritmos de SAT (do inglês satisfiability ) têm o objectivo de determinar se uma dada fbf α é satisfazível ou não; em caso afirmativo, devolvem
114 CAÍTULO 2. LÓGICA ROOSICIONAL 2.3.4 Algoritmos de SAT Os algoritmos de SAT (do inglês satisfiability ) têm o objectivo de determinar se uma dada fbf α é satisfazível ou não; em caso afirmativo, devolvem
Como construir um compilador utilizando ferramentas Java
 Como construir um compilador utilizando ferramentas Java p. 1/2 Como construir um compilador utilizando ferramentas Java Aula 1 - Introdução Prof. Márcio Delamaro delamaro@icmc.usp.br Como construir um
Como construir um compilador utilizando ferramentas Java p. 1/2 Como construir um compilador utilizando ferramentas Java Aula 1 - Introdução Prof. Márcio Delamaro delamaro@icmc.usp.br Como construir um
AS FERRAMENTAS COLABORATIVAS COMPUTACIONAIS UTILIZADAS PELO CORPO DOCENTE DA FEUP
 Porto, Outubro de 2010 RELATÓRIO DO PROJECTO FEUP 2010/2011 AS FERRAMENTAS COLABORATIVAS COMPUTACIONAIS UTILIZADAS PELO CORPO DOCENTE DA FEUP Mestrado Integrado em Engenharia Informática e Computação Mestrado
Porto, Outubro de 2010 RELATÓRIO DO PROJECTO FEUP 2010/2011 AS FERRAMENTAS COLABORATIVAS COMPUTACIONAIS UTILIZADAS PELO CORPO DOCENTE DA FEUP Mestrado Integrado em Engenharia Informática e Computação Mestrado
Modelos matemáticos para resolução de problemas de afectação de operações a recursos produtivos
 Métodos de Análise de Sistemas Produtivos Modelos matemáticos para resolução de problemas de afectação de operações a recursos produtivos 17 de Maio de 2002 Alunos: Álvaro Magalhães Bernardo Ribeiro João
Métodos de Análise de Sistemas Produtivos Modelos matemáticos para resolução de problemas de afectação de operações a recursos produtivos 17 de Maio de 2002 Alunos: Álvaro Magalhães Bernardo Ribeiro João
Lista Série de linhas da folha de cálculo que contém dados relacionados, como por exemplo, uma base de dados.
 Listas de dados Lista Série de linhas da folha de cálculo que contém dados relacionados, como por exemplo, uma base de dados. Base de Dados Conjunto de dados relacionados, organizados de uma forma lógica
Listas de dados Lista Série de linhas da folha de cálculo que contém dados relacionados, como por exemplo, uma base de dados. Base de Dados Conjunto de dados relacionados, organizados de uma forma lógica
Mobilidade na FEUP. Deslocamento vertical na FEUP. Bruno Miguel Paiva de Azevedo. Cheila Carina Carvalho Pacheco. Fernando Carlos Carvalheira Carneiro
 Mobilidade na FEUP Deslocamento vertical na FEUP Bruno Miguel Paiva de Azevedo Cheila Carina Carvalho Pacheco Fernando Carlos Carvalheira Carneiro Francisco Castro Neves Mesquita Alves José Rafael Fernandes
Mobilidade na FEUP Deslocamento vertical na FEUP Bruno Miguel Paiva de Azevedo Cheila Carina Carvalho Pacheco Fernando Carlos Carvalheira Carneiro Francisco Castro Neves Mesquita Alves José Rafael Fernandes
Barómetro Regional da Qualidade Avaliação da Satisfação dos Utentes dos Serviços da Administração Pública Regional e Local
 Avaliação da Satisfação dos Utentes dos Serviços da Administração Pública Regional e Local Entidade Promotora Enquadramento Concepção e Realização Avaliação da Satisfação dos Utentes dos Serviços da Administração
Avaliação da Satisfação dos Utentes dos Serviços da Administração Pública Regional e Local Entidade Promotora Enquadramento Concepção e Realização Avaliação da Satisfação dos Utentes dos Serviços da Administração
Introdução. A disciplina de Técnicas Laboratoriais de Física
 A disciplina de Técnicas Laboratoriais de Física Objectivos formativos 8 Programa 8 Bibliografia 8 Outros elementos de estudo facultados 8 Modo de funcionamento 9 Avaliação 11 A importância da formação
A disciplina de Técnicas Laboratoriais de Física Objectivos formativos 8 Programa 8 Bibliografia 8 Outros elementos de estudo facultados 8 Modo de funcionamento 9 Avaliação 11 A importância da formação
1. Nota Prévia. 2. Aspectos globais
 Exame Nacional do Ensino Secundário Parecer sobre as provas de exame correspondentes à 2ª fase Disciplina de Matemática (Código 435 e 635-21 de Julho de 2006) 1. Nota Prévia Relativamente ao facto de as
Exame Nacional do Ensino Secundário Parecer sobre as provas de exame correspondentes à 2ª fase Disciplina de Matemática (Código 435 e 635-21 de Julho de 2006) 1. Nota Prévia Relativamente ao facto de as
Informática para Ciências e Engenharias 2013/14. Teórica 7
 Informática para Ciências e Engenharias 2013/14 Teórica 7 Na aula de hoje... Controlo de execução ciclos condicionais while end Exemplos raiz quadrada histograma fórmula química while while e matrizes
Informática para Ciências e Engenharias 2013/14 Teórica 7 Na aula de hoje... Controlo de execução ciclos condicionais while end Exemplos raiz quadrada histograma fórmula química while while e matrizes
Descoberta de conhecimento em redes sociais e bases de dados públicas
 Descoberta de conhecimento em redes sociais e bases de dados públicas Trabalho de Formatura Supervisionado Bacharelado em Ciência da Computação - IME USP Aluna: Fernanda de Camargo Magano Orientadora:
Descoberta de conhecimento em redes sociais e bases de dados públicas Trabalho de Formatura Supervisionado Bacharelado em Ciência da Computação - IME USP Aluna: Fernanda de Camargo Magano Orientadora:
Conjuntos disjuntos. Objectivo resolver eficientemente o problema da equivalência estrutura de dados simples (vector) implementação rápida
 implementação rápida") Conjuntos disjuntos Objectivo resolver eficientemente o problema da equivalência estrutura de dados simples (vector) implementação rápida Desempenho análise complicada Uso problemas de grafos equivalência
Conjuntos disjuntos Objectivo resolver eficientemente o problema da equivalência estrutura de dados simples (vector) implementação rápida Desempenho análise complicada Uso problemas de grafos equivalência
Tratamento dos Erros de Sintaxe. Adriano Maranhão
 Tratamento dos Erros de Sintaxe Adriano Maranhão Introdução Se um compilador tivesse que processar somente programas corretos, seu projeto e sua implementação seriam grandemente simplificados. Mas os programadores
Tratamento dos Erros de Sintaxe Adriano Maranhão Introdução Se um compilador tivesse que processar somente programas corretos, seu projeto e sua implementação seriam grandemente simplificados. Mas os programadores
BUSCA EM ARRAYS. Prof. André Backes. Ato de procurar por um elemento em um conjunto de dados
 BUSCA EM ARRAYS Prof. André Backes Definição 2 Ato de procurar por um elemento em um conjunto de dados Recuperação de dados armazenados em um repositório ou base de dados A operação de busca visa responder
BUSCA EM ARRAYS Prof. André Backes Definição 2 Ato de procurar por um elemento em um conjunto de dados Recuperação de dados armazenados em um repositório ou base de dados A operação de busca visa responder
Simplex. Investigação Operacional José António Oliveira Simplex
 18 Considere um problema de maximização de lucro relacionado com duas actividades e três recursos. Na tabela seguinte são dados os consumos unitários de cada recurso (A, B e C) por actividade (1 e 2),
18 Considere um problema de maximização de lucro relacionado com duas actividades e três recursos. Na tabela seguinte são dados os consumos unitários de cada recurso (A, B e C) por actividade (1 e 2),
Aula 9: Estouro e Representação em Ponto Flutuante
 Aula 9: Estouro e Representação em Ponto Flutuante Diego Passos Universidade Federal Fluminense Fundamentos de Arquiteturas de Computadores Diego Passos (UFF) Estouro e Ponto Flutuante FAC 1 / 43 Revisão
Aula 9: Estouro e Representação em Ponto Flutuante Diego Passos Universidade Federal Fluminense Fundamentos de Arquiteturas de Computadores Diego Passos (UFF) Estouro e Ponto Flutuante FAC 1 / 43 Revisão
Consultas por Similaridade em Domínios de Dados Complexos
 Consultas por Similaridade em Domínios de Dados Complexos Guilherme Felipe Zabot Orientador: Profº Dr Caetano Traina Jr Roteiro Objetivo Introdução Dados Complexos Representação de Dados Complexos Extração
Consultas por Similaridade em Domínios de Dados Complexos Guilherme Felipe Zabot Orientador: Profº Dr Caetano Traina Jr Roteiro Objetivo Introdução Dados Complexos Representação de Dados Complexos Extração
AED2 - Aula 01 Apresentação, estruturas de dados, tabelas de símbolos e hash tables
 AED2 - Aula 01 Apresentação, estruturas de dados, tabelas de símbolos e hash tables É esperado de um projetista de algoritmos que ele entenda o problema a resolver e compreenda as ferramentas a sua disposição,
AED2 - Aula 01 Apresentação, estruturas de dados, tabelas de símbolos e hash tables É esperado de um projetista de algoritmos que ele entenda o problema a resolver e compreenda as ferramentas a sua disposição,
Significância do Coeficiente de Correlação
 Significância do Coeficiente de Correlação A primeira coisa que vamos tentar fazer nesta aula é apresentar o conceito de significância do coeficiente de correlação. Uma vez entendido este conceito, vocês
Significância do Coeficiente de Correlação A primeira coisa que vamos tentar fazer nesta aula é apresentar o conceito de significância do coeficiente de correlação. Uma vez entendido este conceito, vocês
Informática para Ciências e Engenharias 2014/15. Teórica 7
 Informática para Ciências e Engenharias 2014/15 Teórica 7 Na aula de hoje... Controlo de execução ciclos condicionais while end Exemplos raiz quadrada histograma fórmula química while while e matrizes
Informática para Ciências e Engenharias 2014/15 Teórica 7 Na aula de hoje... Controlo de execução ciclos condicionais while end Exemplos raiz quadrada histograma fórmula química while while e matrizes
Algoritmos I Introdução a Algoritmos. Carlos de Salles Soares Neto Segundas e Quartas, 17h40 às 19h10
 Algoritmos I Introdução a Algoritmos Carlos de Salles Soares Neto csalles@deinf.ufma.br Segundas e Quartas, 17h40 às 19h10 Sejam bem-vindos! Os celulares têm que ficar no silencioso ou desligados Não se
Algoritmos I Introdução a Algoritmos Carlos de Salles Soares Neto csalles@deinf.ufma.br Segundas e Quartas, 17h40 às 19h10 Sejam bem-vindos! Os celulares têm que ficar no silencioso ou desligados Não se
CAPITULO III METODOLOGIA
 CAPITULO III METODOLOGIA Após o enquadramento teórico dos diversos conceitos implícitos nesta investigação, assim como uma revisão da literatura que se debruçaram sobre esta área de estudo, passamos a
CAPITULO III METODOLOGIA Após o enquadramento teórico dos diversos conceitos implícitos nesta investigação, assim como uma revisão da literatura que se debruçaram sobre esta área de estudo, passamos a
TECNOLOGIAS DA INFORMAÇÃO E COMUNICAÇÃO SISTEMAS DE GESTÃO DE BASE DE DADOS O MODELO RELACIONAL
 TECNOLOGIAS DA INFORMAÇÃO E COMUNICAÇÃO O MODELO RELACIONAL de base de dados é actualmente o modelo de implementação mais utilizado. Este sucesso pode ser explicado pela sua simplicidade e grande capacidade
TECNOLOGIAS DA INFORMAÇÃO E COMUNICAÇÃO O MODELO RELACIONAL de base de dados é actualmente o modelo de implementação mais utilizado. Este sucesso pode ser explicado pela sua simplicidade e grande capacidade
AULA TEÓRICA 10. Tema 7. Introdução ao Microsoft Access Ø. conceitos
 AULA TEÓRICA 10 Tema 7. Introdução ao Microsoft Access Ø conceitos 1 Introdução ao Microsoft Access Microsoft Access é uma aplicação que permite criar bases de dados e ter acesso a informação com a simplicidade
AULA TEÓRICA 10 Tema 7. Introdução ao Microsoft Access Ø conceitos 1 Introdução ao Microsoft Access Microsoft Access é uma aplicação que permite criar bases de dados e ter acesso a informação com a simplicidade
Sistemas e Tecnologias de Informação. Adobe Connect 8. Manual de Utilização. Universidade Católica Portuguesa Centro Regional do Porto
 Sistemas e Tecnologias de Informação Adobe Connect 8 Manual de Utilização Universidade Católica Portuguesa Centro Regional do Porto Este manual tem como objectivo melhorar a interacção dos utilizadores
Sistemas e Tecnologias de Informação Adobe Connect 8 Manual de Utilização Universidade Católica Portuguesa Centro Regional do Porto Este manual tem como objectivo melhorar a interacção dos utilizadores
Modelo Probabilístico
 Wendel Melo Faculdade de Computação Universidade Federal de Uberlândia Recuperação da Informação Adaptado do Material da Profª Vanessa Braganholo - IC/UFF Proposto em 1976 por Roberstson e Sparck Jones;
Wendel Melo Faculdade de Computação Universidade Federal de Uberlândia Recuperação da Informação Adaptado do Material da Profª Vanessa Braganholo - IC/UFF Proposto em 1976 por Roberstson e Sparck Jones;
Álgebra Linear Aplicada à Compressão de Imagens. Universidade de Lisboa Instituto Superior Técnico. Mestrado em Engenharia Aeroespacial
 Álgebra Linear Aplicada à Compressão de Imagens Universidade de Lisboa Instituto Superior Técnico Uma Breve Introdução Mestrado em Engenharia Aeroespacial Marília Matos Nº 80889 2014/2015 - Professor Paulo
Álgebra Linear Aplicada à Compressão de Imagens Universidade de Lisboa Instituto Superior Técnico Uma Breve Introdução Mestrado em Engenharia Aeroespacial Marília Matos Nº 80889 2014/2015 - Professor Paulo
Resolução De Problemas Em Informática. Docente: Ana Paula Afonso Resolução de Problemas. 1. Analisar o problema
 ALGORITMIA Resolução De Problemas Em Informática Docente: Ana Paula Afonso 2000-2001 Resolução de Problemas 1. Analisar o problema Conhecer o bem o problema Descrever o problema: subdividir, detalhar 2.
ALGORITMIA Resolução De Problemas Em Informática Docente: Ana Paula Afonso 2000-2001 Resolução de Problemas 1. Analisar o problema Conhecer o bem o problema Descrever o problema: subdividir, detalhar 2.
Os Quatro Subespaços Fundamentais
 Álgebra Linear e Geometria Analítica Texto de apoio Professor João Soares 7 páginas Universidade de Coimbra 26 de Novembro de 29 Os Quatro Subespaços Fundamentais Seja A uma matriz m n de elementos reais.
Álgebra Linear e Geometria Analítica Texto de apoio Professor João Soares 7 páginas Universidade de Coimbra 26 de Novembro de 29 Os Quatro Subespaços Fundamentais Seja A uma matriz m n de elementos reais.
Teste de Funções por Partição do Espaço de Entrada
 Teste de Funções por Partição do Espaço de Entrada Programação II Universidade de Lisboa Faculdade de Ciências Departamento de Informática Licenciatura em Tecnologias da Informação Vasco Thudichum Vasconcelos
Teste de Funções por Partição do Espaço de Entrada Programação II Universidade de Lisboa Faculdade de Ciências Departamento de Informática Licenciatura em Tecnologias da Informação Vasco Thudichum Vasconcelos
CAPÍTULO VI- CONCLUSÕES, LIMITAÇÕES E RECOMENDAÇÕES
 CAPITULO VI CONCLUSÕES, LIMITAÇÕES E RECOMENDAÇÕES Neste capítulo iremos apresentar as conclusões do presente estudo, tendo também em conta os resultados e a respectiva discussão, descritas no capítulo
CAPITULO VI CONCLUSÕES, LIMITAÇÕES E RECOMENDAÇÕES Neste capítulo iremos apresentar as conclusões do presente estudo, tendo também em conta os resultados e a respectiva discussão, descritas no capítulo
Universidade Federal de Goiás Bacharelado em Ciências da Computacão Compiladores
 Universidade Federal de Goiás Bacharelado em Ciências da Computacão Compiladores 2013-2 Compilador para a Linguagem Cafezinho Especificação dos trabalhos: T2 (Geração da Representação Intermediária e Análise
Universidade Federal de Goiás Bacharelado em Ciências da Computacão Compiladores 2013-2 Compilador para a Linguagem Cafezinho Especificação dos trabalhos: T2 (Geração da Representação Intermediária e Análise
Lógica Proposicional. LEIC - Tagus Park 2 o Semestre, Ano Lectivo 2007/08. c Inês Lynce c Luísa Coheur
 Capítulo 2 Lógica Proposicional Lógica para Programação LEIC - Tagus Park 2 o Semestre, Ano Lectivo 2007/08 c Inês Lynce c Luísa Coheur Programa Apresentação Conceitos Básicos Lógica Proposicional ou Cálculo
Capítulo 2 Lógica Proposicional Lógica para Programação LEIC - Tagus Park 2 o Semestre, Ano Lectivo 2007/08 c Inês Lynce c Luísa Coheur Programa Apresentação Conceitos Básicos Lógica Proposicional ou Cálculo
Álgebra Linear Semana 01
 Álgebra Linear Semana 01 Diego Marcon 27 de Março de 2017 Conteúdo 1 Estrutura do Curso 1 2 Sistemas Lineares 1 3 Formas escalonadas e formas escalonadas reduzidas 4 4 Algoritmo de escalonamento 5 5 Existência
Álgebra Linear Semana 01 Diego Marcon 27 de Março de 2017 Conteúdo 1 Estrutura do Curso 1 2 Sistemas Lineares 1 3 Formas escalonadas e formas escalonadas reduzidas 4 4 Algoritmo de escalonamento 5 5 Existência
Mensagem descodificada. Mensagem recebida. c + e
 Suponhamos que, num determinado sistema de comunicação, necessitamos de um código com, no máximo, q k palavras. Poderemos então usar todas as palavras a a 2 a k F k q de comprimento k. Este código será
Suponhamos que, num determinado sistema de comunicação, necessitamos de um código com, no máximo, q k palavras. Poderemos então usar todas as palavras a a 2 a k F k q de comprimento k. Este código será
Equipa: r_euclides 2ª COMPETIÇÃO EUROPEIA DE ESTATÍSTICA - 2ª AVALIAÇÃO 1
 Equipa: r_euclides FASE NACIONAL 2ª AVALIAÇÃO ESCOLA SECUNDÁRIA DR. JOÃO DE ARAÚJO CORREIA CATEGORIA B REGIÃO DO DOURO 2ª COMPETIÇÃO EUROPEIA DE ESTATÍSTICA - 2ª AVALIAÇÃO 1 Atualmente sabemos que há uma
Equipa: r_euclides FASE NACIONAL 2ª AVALIAÇÃO ESCOLA SECUNDÁRIA DR. JOÃO DE ARAÚJO CORREIA CATEGORIA B REGIÃO DO DOURO 2ª COMPETIÇÃO EUROPEIA DE ESTATÍSTICA - 2ª AVALIAÇÃO 1 Atualmente sabemos que há uma
Pedro Oliveira
 Pedro Oliveira pcoliv@student.dei.uc.pt O que é a radicalização Aplicações Radicalização em Inglês Radicalização em Português Experiência com algoritmos para o Português Vantagens e Desvantagens 2 Processo
Pedro Oliveira pcoliv@student.dei.uc.pt O que é a radicalização Aplicações Radicalização em Inglês Radicalização em Português Experiência com algoritmos para o Português Vantagens e Desvantagens 2 Processo
Aplicação de uma Técnica Tradicional de Expansão de Consulta ao Modelo TR+
 Pontifícia Universidade Católica do Rio Grande do Sul Faculdade de Informática Programa de Pós-Graduação em Ciência da Computação Aplicação de uma Técnica Tradicional de Expansão de Consulta ao Modelo
Pontifícia Universidade Católica do Rio Grande do Sul Faculdade de Informática Programa de Pós-Graduação em Ciência da Computação Aplicação de uma Técnica Tradicional de Expansão de Consulta ao Modelo
CAL ( ) MIEIC/FEUP Estruturas de Dados ( )
 MIEIC/FEUP Estruturas de Dados ( )") Conjuntos Disjuntos R. Rossetti, A.P. Rocha, A. Pereira, P.B. Silva, T. Fernandes FEUP, MIEIC, CPAL, 2010/2011 1 Conjuntos Disjuntos Objectivo resolver eficientemente o problema da equivalência estrutura
Conjuntos Disjuntos R. Rossetti, A.P. Rocha, A. Pereira, P.B. Silva, T. Fernandes FEUP, MIEIC, CPAL, 2010/2011 1 Conjuntos Disjuntos Objectivo resolver eficientemente o problema da equivalência estrutura
Instituto Superior Politécnico de VISEU. Escola Superior de Tecnologia
 1 Vamos considerar os seguintes elementos e estruturas fundamentais que são habitualmente usados em programação: Tipos de Dados Operadores Atribuições Entrada e Saída de Dados Estruturas de Controlo Procedimentos
1 Vamos considerar os seguintes elementos e estruturas fundamentais que são habitualmente usados em programação: Tipos de Dados Operadores Atribuições Entrada e Saída de Dados Estruturas de Controlo Procedimentos
Supervisão e Controlo dos Sistemas de Mistura e Tratamento Térmico da Peças
 Faculdade de Engenharia da Universidade do Porto Licenciatura em Engenharia Electrotécnica e de Computadores 4º Ano, 2º Semestre Sistemas Flexíveis de Fabrico - 2000/2001 Relatório do trabalho laboratorial
Faculdade de Engenharia da Universidade do Porto Licenciatura em Engenharia Electrotécnica e de Computadores 4º Ano, 2º Semestre Sistemas Flexíveis de Fabrico - 2000/2001 Relatório do trabalho laboratorial
Avaliação de Desempenho de SRI
 Avaliação de Desempenho de SRI Desempenho espaço x tempo é usual em computação quão preciso é o conjunto resposta (ranking) é usual em SRI Avaliação baseada em coleção de referência = documentos + consultas
Avaliação de Desempenho de SRI Desempenho espaço x tempo é usual em computação quão preciso é o conjunto resposta (ranking) é usual em SRI Avaliação baseada em coleção de referência = documentos + consultas
Ambiente de Data Warehouse Para Imagens Médicas Baseado Em Similaridade
 Universidade de São Paulo - USP Instituto de Ciências Matemáticas e de Computação - ICMC Programa de Pós-Graduação em Ciências da Computação e Matemática Computacional Ambiente de Data Warehouse Para Imagens
Universidade de São Paulo - USP Instituto de Ciências Matemáticas e de Computação - ICMC Programa de Pós-Graduação em Ciências da Computação e Matemática Computacional Ambiente de Data Warehouse Para Imagens
Computação e Programação
 Computação e Programação MEMec, LEAN - 1º Semestre 2015-2016 Aula Teórica 10 Exemplo de desenvolvimento de Programa Modular: Máquina de venda de bilhetes D.E.M. Área Científica de Controlo Automação e
Computação e Programação MEMec, LEAN - 1º Semestre 2015-2016 Aula Teórica 10 Exemplo de desenvolvimento de Programa Modular: Máquina de venda de bilhetes D.E.M. Área Científica de Controlo Automação e
Segundo trabalho de Organização e Recuperação da Informação FACOM- UFU Professor: Wendel Melo
 Segundo trabalho de Organização e Recuperação da Informação 2017-02 FACOM- UFU Professor: Wendel Melo Descrição O trabalho consiste na implementação de um programa que, a partir da construção do índice
Segundo trabalho de Organização e Recuperação da Informação 2017-02 FACOM- UFU Professor: Wendel Melo Descrição O trabalho consiste na implementação de um programa que, a partir da construção do índice
1 Espaços Vectoriais
 Nova School of Business and Economics Apontamentos Álgebra Linear 1 Definição Espaço Vectorial Conjunto de elementos que verifica as seguintes propriedades: Existência de elementos: Contém pelo menos um
Nova School of Business and Economics Apontamentos Álgebra Linear 1 Definição Espaço Vectorial Conjunto de elementos que verifica as seguintes propriedades: Existência de elementos: Contém pelo menos um
Derivadas de funções reais de variável real
 Derivadas de funções reais de variável real O conceito de derivada tem grande importância pelas suas inúmeras aplicações em Matemática, em Física e em muitas outras ciências. Neste capítulo vamos dar a
Derivadas de funções reais de variável real O conceito de derivada tem grande importância pelas suas inúmeras aplicações em Matemática, em Física e em muitas outras ciências. Neste capítulo vamos dar a
Um SGBD permite que cada utilizador tenha uma vista diferente (abstrata) do conteúdo da base de dados;
 do conteúdo da base de dados;") 1 Bioinformatica Conceitos Básicos Camadas de abstração Um SGBD permite que cada utilizador tenha uma vista diferente (abstrata) do conteúdo da base de dados; Cada utilizador necessita de ter acesso a
1 Bioinformatica Conceitos Básicos Camadas de abstração Um SGBD permite que cada utilizador tenha uma vista diferente (abstrata) do conteúdo da base de dados; Cada utilizador necessita de ter acesso a
Alexandra Costa e Alexandra Gomes IE-Universidade do Minho e CIEC/IE-Universidade do Minho.
 Problemas e Desafios Grelhas de Sudoku Alexandra Costa e Alexandra Gomes IE-Universidade do Minho e CIEC/IE-Universidade do Minho magomes@ie.uminho.pt Resumo: Hoje em dia praticamente todos ouviram falar
Problemas e Desafios Grelhas de Sudoku Alexandra Costa e Alexandra Gomes IE-Universidade do Minho e CIEC/IE-Universidade do Minho magomes@ie.uminho.pt Resumo: Hoje em dia praticamente todos ouviram falar
DESCOBERTA DO CONHECIMENTO COM O USO DE TEXT MINING APLICADA AO SAC TEXT MINING. Aluno José Lino Uber. Orientador Paulo Roberto Dias
 DESCOBERTA DO CONHECIMENTO COM O USO DE TEXT MINING APLICADA AO SAC TEXT MINING Aluno José Lino Uber Orientador Paulo Roberto Dias Dezembro/2004 Roteiro Introdução Objetivo Conceitos Motivação / Tipos
DESCOBERTA DO CONHECIMENTO COM O USO DE TEXT MINING APLICADA AO SAC TEXT MINING Aluno José Lino Uber Orientador Paulo Roberto Dias Dezembro/2004 Roteiro Introdução Objetivo Conceitos Motivação / Tipos
TELEVISÃO DIGITAL LEEC 2006/2007
 TELEVISÃO DIGITAL LEEC 2006/2007 DETECÇÃO DE CONTORNOS GRUPO 6: Hugo Miguel Rodrigues Gonçalves Dinis Guedes Afonso ee01171 ee01148 Introdução Este trabalho tem como objectivo a implementação de métodos
TELEVISÃO DIGITAL LEEC 2006/2007 DETECÇÃO DE CONTORNOS GRUPO 6: Hugo Miguel Rodrigues Gonçalves Dinis Guedes Afonso ee01171 ee01148 Introdução Este trabalho tem como objectivo a implementação de métodos
Desenvolvimento de um Web Crawler para indexação de documentos científicos
 Desenvolvimento de um Web Crawler para indexação de documentos científicos Heitor de Sousa Miranda¹, Rafael Gonçalves Barreira², Edeilson Milhomem da Silva³ Curso de Sistemas de Informação - CEULP/ULBRA
Desenvolvimento de um Web Crawler para indexação de documentos científicos Heitor de Sousa Miranda¹, Rafael Gonçalves Barreira², Edeilson Milhomem da Silva³ Curso de Sistemas de Informação - CEULP/ULBRA
Exame Final Nacional de Matemática Aplicada às Ciências Sociais Prova 835 Época Especial Ensino Secundário º Ano de Escolaridade
 Exame Final Nacional de Matemática Aplicada às Ciências Sociais Prova 835 Época Especial Ensino Secundário 2017 11.º Ano de Escolaridade Decreto-Lei n.º 139/2012, de 5 de julho Critérios de Classificação
Exame Final Nacional de Matemática Aplicada às Ciências Sociais Prova 835 Época Especial Ensino Secundário 2017 11.º Ano de Escolaridade Decreto-Lei n.º 139/2012, de 5 de julho Critérios de Classificação
BC1424 Algoritmos e Estruturas de Dados I Aula 05 Custos de um algoritmo e funções de complexidade
 BC1424 Algoritmos e Estruturas de Dados I Aula 05 Custos de um algoritmo e funções de complexidade Prof. Jesús P. Mena-Chalco 1Q-2016 1 1995 2015 2 Custo de um algoritmo e funções de complexidade Introdução
BC1424 Algoritmos e Estruturas de Dados I Aula 05 Custos de um algoritmo e funções de complexidade Prof. Jesús P. Mena-Chalco 1Q-2016 1 1995 2015 2 Custo de um algoritmo e funções de complexidade Introdução
2 o Trabalho de Laboratório - Circuitos Resistivos
 2 o Trabalho de Laboratório - Circuitos Resistivos Grupo 18, Turno 4 a feira André Patrício (67898) Bavieche Samgi (67901) Miguel Aleluia (67935) MEFT, TCFE 10 de Maio de 2011 Resumo Neste trabalho experimental,
2 o Trabalho de Laboratório - Circuitos Resistivos Grupo 18, Turno 4 a feira André Patrício (67898) Bavieche Samgi (67901) Miguel Aleluia (67935) MEFT, TCFE 10 de Maio de 2011 Resumo Neste trabalho experimental,
GIRS - GENETIC INFORMATION RETRIEVAL SYSTEM - UMA PROPOSTA EVOLUTIVA PARA SISTEMAS DE RECUPERAÇÃO DE INFORMAÇÕES
 GIRS - GENETIC INFORMATION RETRIEVAL SYSTEM - UMA PROPOSTA EVOLUTIVA PARA SISTEMAS DE RECUPERAÇÃO DE INFORMAÇÕES - (-) - A recuperação de informação é uma subárea da ciência da computação que estuda o
GIRS - GENETIC INFORMATION RETRIEVAL SYSTEM - UMA PROPOSTA EVOLUTIVA PARA SISTEMAS DE RECUPERAÇÃO DE INFORMAÇÕES - (-) - A recuperação de informação é uma subárea da ciência da computação que estuda o