Oracle Tuning: SQL. Ricardo Portilho Proni
|
|
|
- Sebastião Azambuja Moreira
- 8 Há anos
- Visualizações:
Transcrição
1 Oracle Tuning: SQL Ricardo Portilho Proni Esta obra está licenciada sob a licença Creative Commons Atribuição-SemDerivados 3.0 Brasil. Para ver uma cópia desta licença, visite 1

2 Dicas de SQL Tuning? 2 2

3 Lendas de SQL O Custo não quer dizer nada? Índice BITMAP em baixa cardinalidade? Sintaxe Oracle ou ANSI? SELECT(1) ou SELECT COUNT(*)? Ordem da cláusula WHERE? Ordem de JOIN? CHAR ou VARCHAR2? Evite Subqueries? Evite VIEWs? Evite EXISTS? Evite Listas IN? NESTED LOOPs é ruim? < > é melhor que BETWEEN? 3

4 Lab 1 Lendas de SQL Hands On! 4

5 Lab 1.1: Lendas de SQL - COUNT(*) Desbloqueie os usuários teste do Oracle Database, e dê as permissões abaixo. $ sqlplus / AS SYSDBA ALTER USER SCOTT ACCOUNT UNLOCK IDENTIFIED BY TIGER; ALTER USER HR ACCOUNT UNLOCK IDENTIFIED BY HR; ALTER USER SH ACCOUNT UNLOCK IDENTIFIED BY SH; ALTER USER SHSB ACCOUNT UNLOCK IDENTIFIED BY SHSB; ALTER USER SHSBP ACCOUNT UNLOCK IDENTIFIED BY SHSBP; ALTER USER OE ACCOUNT UNLOCK IDENTIFIED BY OE; GRANT ALTER SESSION, RESOURCE, SELECT ANY DICTIONARY GRANT ALTER SESSION, RESOURCE, SELECT ANY DICTIONARY GRANT ALTER SESSION, RESOURCE, SELECT ANY DICTIONARY GRANT ALTER SESSION, RESOURCE, SELECT ANY DICTIONARY GRANT ALTER SESSION, RESOURCE, SELECT ANY DICTIONARY GRANT ALTER SESSION, RESOURCE, SELECT ANY DICTIONARY GRANT ALTER SESSION, RESOURCE, SELECT ANY DICTIONARY TO TO TO TO TO TO TO SCOTT; HR; SH; SHSB; SHSBP; OE; SOE; 5

6 Lab 1.2: Lendas de SQL - COUNT(*) Execute logon com o usuário SCOTT, e verifique qual é seu arquivo de TRACE: $ sqlplus SCOTT/TIGER COLUMN TRACEFILE FORMAT A100 SELECT P.TRACEFILE FROM V$SESSION S, V$PROCESS P WHERE S.PADDR = P.ADDR AND S.USERNAME = 'SCOTT'; Coloque sua sessão em TRACE 10053, e execute os comandos abaixo. ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; SELECT COUNT(EMPNO) FROM EMP; SELECT COUNT(1) FROM EMP; SELECT COUNT(2) FROM EMP; SELECT COUNT(*) FROM EMP; SELECT COUNT(ROWID) FROM EMP; SELECT COUNT(MGR) FROM EMP; Edite o seu arquivo de TRACE. $ vi /u01/app/oracle/rdbms/orcl/orcl/trace/orcl_ora_1234.trc 6
 FROM EMP; SELECT COUNT(1) FROM EMP; SELECT COUNT(2) FROM EMP; SELECT")
7 Lab 1.3: Lendas de SQL - COUNT(*) No arquivo de Trace, procure pelo texto CNT : Legend The following abbreviations are used by optimizer trace. CBQT - cost-based query transformation JPPD - join predicate push-down OJPPD - old-style (non-cost-based) JPPD FPD - filter push-down PM - predicate move-around CVM - complex view merging SPJ - select-project-join SJC - set join conversion SU - subquery unnesting OBYE - order by elimination OST - old style star transformation ST - new (cbqt) star transformation CNT - count(col) to count(*) transformation JE - Join Elimination JF - join factorization 7
 star transformation CNT - count(col) to count(*) transformation JE - Join Elimination JF - join")
8 Lab 1.4: Lendas de SQL - COUNT(*) Procure novamente pelo texto CNT : CNT: Considering count(col) to count(*) on query block SEL$1 (#0) ************************* Count(col) to Count(*) (CNT) ************************* CNT: Converting COUNT(EMPNO) to COUNT(*). CNT: COUNT() to COUNT(*) done. Procure pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT COUNT(*) "COUNT(EMPNO)" FROM "SCOTT"."EMP" "EMP" 8
 to COUNT(*). CNT: COUNT() to COUNT(*) done.")
9 Lab 1.5: Lendas de SQL - COUNT(*) Procure novamente pelo texto CNT : CNT: Considering count(col) to count(*) on query block SEL$1 (#0) ************************* Count(col) to Count(*) (CNT) ************************* CNT: COUNT() to COUNT(*) done. Procure novamente pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT COUNT(*) "COUNT(1)" FROM "SCOTT"."EMP" "EMP" 9
 to COUNT(*) done.")
10 Lab 1.6: Lendas de SQL - COUNT(*) Procure novamente pelo texto CNT : CNT: Considering count(col) to count(*) on query block SEL$1 (#0) ************************* Count(col) to Count(*) (CNT) ************************* CNT: COUNT() to COUNT(*) done. Procure novamente pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT COUNT(*) "COUNT(2)" FROM "SCOTT"."EMP" "EMP" 10
 to COUNT(*) done.")
11 Lab 1.7: Lendas de SQL - COUNT(*) Procure novamente pelo texto CNT : CNT: Considering count(col) to count(*) on query block SEL$1 (#0) ************************* Count(col) to Count(*) (CNT) ************************* CNT: COUNT() to COUNT(*) not done. Procure novamente pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT COUNT(*) "COUNT(*)" FROM "SCOTT"."EMP" "EMP" 11
 to COUNT(*) not done.")
12 Lab 1.8: Lendas de SQL - COUNT(*) Procure novamente pelo texto CNT : CN T: Considering count(col) to count(*) on query block SEL$1 (# 0) ************************* Count(col) to Count(*) (CN T) ************************* CN T: CO U N T() to CO U N T(*) not done. Procure novamente pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT COUNT("EMP".ROWID) "COUNT(ROWID)" FROM "SCOTT"."EMP" "EMP" 12
 to CO U N T(*) not done.")
13 Lab 1.9: Lendas de SQL - ANSI Execute os comandos abaixo. SELECT FROM SELECT FROM E.ENAME, E.JOB, D.DNAME EMP E, DEPT D WHERE E.DEPTNO = D.DEPTNO; E.ENAME, E.JOB, D.DNAME EMP E INNER JOIN DEPT D ON E.DEPTNO = D.DEPTNO; Procure novamente pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT "E"."ENAME" "ENAME","E"."JOB" "JOB","D"."DNAME" "DNAME" FROM "SCOTT"."EMP" "E","SCOTT"."DEPT" "D" WHERE "E"."DEPTNO"="D"."DEPTNO" Procure novamente pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT "E"."ENAME" "ENAME","E"."JOB" "JOB","D"."DNAME" "DNAME" FROM "SCOTT"."EMP" "E","SCOTT"."DEPT" "D" WHERE "E"."DEPTNO"="D"."DEPTNO" 13

14 Lab 1.10: Lendas de SQL- Listas IN Execute os comandos abaixo. SELECT E.ENAME, E.JOB, D.DNAME FROM EMP E, DEPT D WHERE E.DEPTNO = D.DEPTNO AND EMPNO IN (7369,7499,7521,7566,7654); Procure novamente pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT "E"."ENAME" "ENAME","E"."JOB" "JOB","D"."DNAME" "DNAME" FROM "SCOTT"."EMP" "E","SCOTT"."DEPT" "D" WHERE "E"."DEPTNO"="D"."DEPTNO" AND ("E"."EMPNO"=7369 OR "E"."EMPNO"=7499 OR "E"."EMPNO"=7521 OR "E"."EMPNO"=7566 OR "E"."EMPNO"=7654) 14

15 Top Ten Mistakes 1 - Bad connection management 2 - Bad use of cursors and the shared pool 3 - Bad SQL 4 - Use of nonstandard initialization parameters 5 - Getting database I/O wrong 6 - Online redo log setup problems 7 - Serialization of data blocks in the buffer cache due to lack of free lists, free list groups, transaction slots (INITRANS), or shortage of rollback segments. 8 - Long full table scans 9 - High amounts of recursive (SYS) SQL 10 - Deployment and migration errors Fonte: Oracle Database Performance Tuning Guide
 SQL 10 - Deployment and migration errors Fonte: Oracle Database Performance Tuning Guide")
16 SQL ou PL/SQL? Se você pode fazer algo em SQL, faça-o em SQL. Se você não pode faze-lo em SQL, faça em PL/SQL. Se você não pode faze-lo em PL/SQL, faça em Java. Se você não pode faze-lo em Java, faça em C++. Se você não pode fazer em C++, não o faça. Thomas Kyte - O que você aprendeu sobre carros, quando aprendeu a dirigir? - Quanto tempo você levou para aprender SQL? - Utilizamos apenas cerca de 20% das capacidades de um programa ou linguagem

17 Conteúdo Iremos abordar: - SQL Não iremos: - PL/SQL - Analytic / OLAP / Data Mining - LOB / SecureFiles - XML - HTML DB / APEX - Oracle Text - Oracle Spatial - Intermedia / Image - JDBC / OCI - ODBC / ADO /.NET 17 17

18 Agenda - Lendas de SQL - Custo - Configuração do CBO - Seletividade e Cardinalidade - SQL Engine - Access Paths - Query Transformation - Join Methods - Índices - Análise de Estatísticas - Coleta de Estatísticas - Modelagem / Data Types - Extração de Planos de Execução - Análise de Planos de Execução - Estabilidade de Plano de Execução - Ferramentas (Trace 10046, Trace 10053, SQLHC, SQLT) - Otimizações (Paralelismo / CTAS / External Tables / Compressão / InMemory) - Melhores Práticas em SQL 18 18
 - Otimizações (Paralelismo / CTAS / External Tables / Compressão / InMemory) - Melhores")
19 Cost Based Optimizer 19

20 SQL Tuning Guide 20 20


21 Oracle Optimizer Blog 21 21
22 Cost Based Optimizer Exite uma teoria de que se alguém descobrir o que o CBO faz e como ele funciona, ele irá desaparecer instantaneamente e será substituído por algo ainda mais bizarro e inexplicável. Existe outra teoria de que isto já aconteceu... duas vezes. Jonathan Lewis, parafraseando Douglas Adams
23 O que é o Custo? Execution Plan Id Operation Name Rows Bytes Cost (%CPU) Time SELECT STATEMENT (0) 00:00:01 1 TABLE ACCESS FULL EMP (0) 00:00: Cost = ( #SRds * sreadtim + #MRds * mreadtim + #CPUCycles / cpuspeed ) / sreadtim OU Custo = ( Quantidade de leituras de um único bloco * Tempo de leitura de um único bloco + Quantidade de leituras de múltiplos blocos * Tempo de leitura de múltiplos blocos + Ciclos de CPU / Velocidade da CPU ) / Tempo de leitura de um único bloco 23
24 O que é o Custo? 24
25 O que é o Custo? 25
26 Seletividade e Cardinalidade Seletividade É um valor entre 0 e 1 que representa a fração de linhas obtidas por uma operação. Cardinalidade É o número de linhas retornadas por uma operação. Exemplo: SELECT COUNT(MODELS) FROM CARS; 120 rows selected. SELECT COUNT(MODELS) FROM CARS WHERE FAB = 'FORD'; 18 rows selected. Cardinalidade = 18. Seletividade = 0.15 (18/120). 26
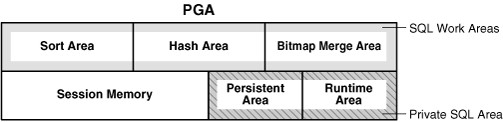
27 Configuração do CBO OPTIMIZER_MODE (FIRST_ROWS_n / ALL_ROWS) DB_FILE_MULTIBLOCK_READ_COUNT RESULT_CACHE INMEMORY OPTIMIZER_SECURE_VIEW_MERGING QUERY_REWRITE_ENABLED QUERY_REWRITE_INTEGRITY STAR_TRANSFORMATION_ENABLED GATHER_SYSTEM_STATISTICS GATHER_DATABASE_STATISTICS OPTIMIZER_DYNAMIC_SAMPLING WORKAREA_SIZE_POLICY (AUTO / MANUAL) AUTO: PGA_AGGREGATE_TARGET MANUAL: BITMAP_MERGE_AREA_SIZE HASH_AREA_SIZE SORT_AREA_SIZE SORT_AREA_RETAINED_SIZE OPTIMIZER_INDEX_CACHING (0 a 100, padrão 0) OPTIMIZER_INDEX_COST_ADJ (1 a 10000, padrão 100) Histograms Extended Statistics 27
28 Configuração do CBO - OLTP OPTIMIZER_MODE (FIRST_ROWS_n / ALL_ROWS) < DB_FILE_MULTIBLOCK_READ_COUNT RESULT_CACHE INMEMORY OPTIMIZER_SECURE_VIEW_MERGING QUERY_REWRITE_ENABLED QUERY_REWRITE_INTEGRITY STAR_TRANSFORMATION_ENABLED GATHER_SYSTEM_STATISTICS GATHER_DATABASE_STATISTICS OPTIMIZER_DYNAMIC_SAMPLING WORKAREA_SIZE_POLICY (AUTO / MANUAL) AUTO: PGA_AGGREGATE_TARGET MANUAL: BITMAP_MERGE_AREA_SIZE HASH_AREA_SIZE SORT_AREA_SIZE SORT_AREA_RETAINED_SIZE > OPTIMIZER_INDEX_CACHING < OPTIMIZER_INDEX_COST_ADJ Histograms Extended Statistics 28
29 Configuração do CBO - OLAP OPTIMIZER_MODE (FIRST_ROWS_n / ALL_ROWS) > DB_FILE_MULTIBLOCK_READ_COUNT RESULT_CACHE INMEMORY OPTIMIZER_SECURE_VIEW_MERGING QUERY_REWRITE_ENABLED QUERY_REWRITE_INTEGRITY STAR_TRANSFORMATION_ENABLED GATHER_SYSTEM_STATISTICS GATHER_DATABASE_STATISTICS OPTIMIZER_DYNAMIC_SAMPLING WORKAREA_SIZE_POLICY (AUTO / MANUAL) AUTO: PGA_AGGREGATE_TARGET MANUAL: BITMAP_MERGE_AREA_SIZE HASH_AREA_SIZE SORT_AREA_SIZE SORT_AREA_RETAINED_SIZE < OPTIMIZER_INDEX_CACHING > OPTIMIZER_INDEX_COST_ADJ Histograms Extended Statistics 29
30 Ferramentas Básicas 30
31 AUTOTRACE SET AUTOTRACE ON; SELECT ENAME FROM EMP; ENAME SMITH rows selected. Execution Plan Plan hash value: Id Operation Name Rows Bytes Cost (%CPU) Time SELECT STATEMENT (0) 00:00:01 1 TABLE ACCESS FULL EMP (0) 00:00: Statistics recursive calls... 0 sorts (disk) 14 rows processed 31
32 AUTOTRACE SET AUTOTRACE TRACEONLY; SELECT ENAME FROM EMP; 14 rows selected. Execution Plan Plan hash value: Id Operation Name Rows Bytes Cost (%CPU) Time SELECT STATEMENT (0) 00:00:01 1 TABLE ACCESS FULL EMP (0) 00:00: Statistics recursive calls 0 db block gets... 0 sorts (disk) 14 rows processed 32
33 AUTOTRACE SET AUTOTRACE TRACEONLY EXPLAIN; SELECT ENAME FROM EMP; Execution Plan Plan hash value: Id Operation Name Rows Bytes Cost (%CPU) Time SELECT STATEMENT (0) 00:00:01 1 TABLE ACCESS FULL EMP (0) 00:00:
34 AUTOTRACE SET AUTOTRACE TRACEONLY STATISTICS; SELECT ENAME FROM EMP; 14 rows selected. Statistics recursive calls 0 db block gets 8 consistent gets 0 physical reads 0 redo size 731 bytes sent via SQL*Net to client 551 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 14 rows processed 34

35 SQL Developer: Plano de Execução 35

36 SQL Developer: Plano de Execução 36
37 SQL Trace (Event 10046): Níveis 0 - Trace OFF 2 - Regular SQL Trace 4 - Nível 2, + Bind Variable 8 - Nível 2 + Wait Events 12 - Nível 2, + Bind Variable + Wait Events 37
38 SQL Trace (Event 10046): Ativação Todas versões: ALTER SESSION SET SQL_TRACE=TRUE; ALTER SESSION SET SQL_TRACE=FALSE; EXEC DBMS_SESSION.SET_SQL_TRACE(SQL_TRACE => TRUE); EXEC DBMS_SESSION.SET_SQL_TRACE(SQL_TRACE => FALSE); EXEC DBMS_SYSTEM.SET_SQL_TRACE_IN_SESSION (SID=>123, SERIAL#=>1234, SQL_TRACE=>TRUE); EXEC DBMS_SYSTEM.SET_SQL_TRACE_IN_SESSION (SID=>123, SERIAL#=>1234, SQL_TRACE=>FALSE); ALTER SESSION SET EVENTS '10046 TRACE NAME CONTEXT FOREVER, LEVEL 12'; ALTER SESSION SET EVENTS '10046 TRACE NAME CONTEXT OFF'; EXEC DBMS_SYSTEM.SET_EV(SI=>123, SE=>1234, EV=>10046, LE=>12, NM=>''); EXEC DBMS_SYSTEM.SET_EV(SI=>123, SE=>1234, EV=>10046, LE=>0, NM=>''); 38
39 SQL Trace (Event 10046): Ativação Versões >= 8I SELECT P.SPID OS_PROCESS_ID FROM V$SESSION S, V$PROCESS P WHERE S.PADDR = P.ADDR AND S.USERNAME = 'SCOTT'; ORADEBUG SETOSPID 12345; ORADEBUG EVENT TRACE NAME CONTEXT FOREVER, LEVEL 12; ORADEBUG TRACEFILE_NAME; ORADEBUG EVENT TRACE NAME CONTEXT OFF; 39
40 SQL Trace (Event 10046): Ativação CREATE OR REPLACE TRIGGER SET_TRACE AFTER LOGON ON DATABASE BEGIN IF USER IN ('SCOTT') THEN EXECUTE IMMEDIATE 'ALTER SESSION SET TRACEFILE_IDENTIFIER=''SESSAO_RASTREADA_PORTILHO'''; EXECUTE IMMEDIATE 'ALTER SESSION SET TIMED_STATISTICS=TRUE'; EXECUTE IMMEDIATE 'ALTER SESSION SET MAX_DUMP_FILE_SIZE=UNLIMITED'; EXECUTE IMMEDIATE 'ALTER SESSION SET EVENTS ''10046 TRACE NAME CONTEXT FOREVER, LEVEL 12'''; END IF; END; / 40
41 SQL Trace (Event 10046): Ativação Todas versões: EXEC DBMS_SUPPORT.START_TRACE(WAITS=>TRUE, BINDS=>FALSE); EXEC DBMS_SUPPORT.STOP_TRACE; EXEC DBMS_SUPPORT.START_TRACE_IN_SESSION (SID=>123, SERIAL=>1234, WAITS=>TRUE, BINDS=>TRUE); EXEC DBMS_SUPPORT.STOP_TRACE_IN_SESSION (SID=>123, SERIAL=>1234); Versões >= 10G EXEC DBMS_MONITOR.SESSION_TRACE_ENABLE (SESSION_ID =>1234, SERIAL_NUM=>1234, WAITS=>TRUE, BINDS=>FALSE); EXEC DBMS_MONITOR.SESSION_TRACE_DISABLE (SESSION_ID=>1234, SERIAL_NUM=>1234); EXEC DBMS_MONITOR.CLIENT_ID_TRACE_ENABLE (CLIENT_ID=>'PORTILHO', WAITS=>TRUE, BINDS=>TRUE); EXEC DBMS_MONITOR.CLIENT_ID_TRACE_DISABLE(CLIENT_ID=>'PORTILHO'); EXEC DBMS_MONITOR.SERV_MOD_ACT_TRACE_ENABLE (SERVICE_NAME=>'OLTP', MODULE_NAME=>'TESTE', ACTION_NAME=>'RUNNING', WAITS=>TRUE, BINDS=>TRUE); EXEC DBMS_MONITOR.SERV_MOD_ACT_TRACE_DISABLE (SERVICE_NAME=>'OLTP', MODULE_NAME=>'TESTE', ACTION_NAME=>'RUNNING'); ALTER SESSION SET EVENTS 'trace[rdbms.sql_optimizer.*][sql:sql_id]'; 41
42 SQL Trace (Event 10046): Ativação ALTER SESSION SET EVENTS '10046 TRACE NAME CONTEXT FOREVER, LEVEL 12'; ALTER SESSION SET EVENTS '10046 TRACE NAME CONTEXT OFF'; OU SELECT P.SPID, P.TRACEFILE FROM V$SESSION S, V$PROCESS P WHERE S.PADDR = P.ADDR AND S.USERNAME = 'SCOTT'; oradebug setospid 9999; oradebug tracefile_name; oradebug unlimit; oradebug event trace name context forever, level 12; 42
43 SQL Trace (Event 10046): tkprof $ tkprof Usage: tkprof tracefile outputfile [explain= ] [table= ] [print= ] [insert= ] [sys= ] [sort= ] table=schema.tablename Use 'schema.tablename' with 'explain=' option. explain=user/password Connect to ORACLE and issue EXPLAIN PLAN. print=integer List only the first 'integer' SQL statements. aggregate=yes no insert=filename List SQL statements and data inside INSERT statements. sys=no TKPROF does not list SQL statements run as user SYS. record=filename Record non-recursive statements found in the trace file. waits=yes no Record summary for any wait events found in the trace file. sort=option Set of zero or more of the following sort options: prscnt number of times parse was called prscpu cpu time parsing prsela elapsed time parsing prsdsk number of disk reads during parse prsqry number of buffers for consistent read during parse prscu number of buffers for current read during parse prsmis number of misses in library cache during parse... 43
44 SQL Trace (Event 10053) ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT OFF'; OU SELECT P.SPID, P.TRACEFILE FROM V$SESSION S, V$PROCESS P WHERE S.PADDR = P.ADDR AND S.USERNAME = 'SCOTT'; oradebug setospid 9999; oradebug tracefile_name; oradebug unlimit; oradebug event trace name context forever, level 1; 44
45 Lab 2 SQL Trace Hands On! 45
46 Lab 2.1: SQL Trace (Event 10046) CONN SCOTT/TIGER SELECT P.SPID, P.TRACEFILE FROM V$SESSION S, V$PROCESS P WHERE S.PADDR = P.ADDR AND S.USERNAME = 'SCOTT'; ALTER SESSION SET EVENTS '10046 TRACE NAME CONTEXT FOREVER, LEVEL 12'; SELECT ENAME FROM EMP WHERE EMPNO = 7369; SELECT * FROM EMP; CREATE TABLE T21 AS SELECT * FROM ALL_OBJECTS; 46
47 Lab 2.2: tkprof (Event 10046) 47

48 Lab 2.3: SQL Trace (Event 10046) 48

49 Lab 2.4: SQL Trace (Event 10053) CONN SCOTT/TIGER SELECT P.SPID, P.TRACEFILE FROM V$SESSION S, V$PROCESS P WHERE S.PADDR = P.ADDR AND S.USERNAME = 'SCOTT'; ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO; 49
50 Lab 2.5: SQL Trace (Event 10053) 50
51 Lab 2.6: SQL Trace (Event 10053) 51
52 Lab 2.7: SQL Trace (Event 10053) 52

53 Lab 2.8: SQL Trace (Event 10053) 53
54 Lab 2.9: SQL Trace (Event 10053) 54
55 Lab 2.10: SQL Trace (Event 10053) 55
56 Lab 2.11: SQL Trace (Event 10053) 56
57 Lab 2.12: SQL Trace (Event 10053) 57
58 Lab 2.13: SQL Trace (Event 10053) 58
59 Lab 2.14: SQL Trace (Event 10053) 59

60 Lab 2.15: SQL Trace (Event 10053) 60
61 SQL Engine 61
 Latch / Mutex Buffer Cache Shared Pool Library")
62 Terminologia Soft Parse / Hard Parse LIO (Logical Input/Output) PIO (Physical Input/Output) Latch / Mutex Buffer Cache Shared Pool Library Cache 62
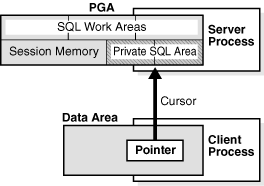
63 PGA 63
64 SELECT 5: SELECT (COLUMN / DISTINCT COLUMN / expression / scalar subquery) 1: FROM / FROM JOIN ON (fontes: TABLE, VIEW, MVIEW, PARTITION, SUBQUERY...) 2: * WHERE (condições: TRUE, FALSE, UNKNOWN) 3: * GROUP BY (opções: ROLLUP / CUBE) 4: * HAVING (condição: TRUE) 6: * ORDER BY (COLUMN) Exemplo: SELECT C.CUSTOMER_ID, COUNT(O.ORDER_ID) AS ORDER_CT FROM OE.CUSTOMERS C JOIN OE.ORDERS O ON C.CUSTOMER_ID = O.CUSTOMER_ID WHERE C.GENDER = 'F' GROUP BY C.CUSTOMER_ID HAVING COUNT(O.ORDER_ID) > 4 ORDER BY ORDERS_CT, C_CUSTOMER_ID; Na fase 2, os dados já foram selecionados (IN MEMORY Column Store). 64
65 Processamento de SQL OPEN CURSOR PARSE BIND EXEC FETCH (ARRAYSIZE, DEFAULT_SDU_SIZE (512 a 32767), RECV_BUF_SIZE, SEND_BUF_SIZE) CLOSE CURSOR SQL*Net PARSE SQL*Net SQL*Net BIND SQL*Net SQL*Net EXEC SQL*Net SQL*Net FETCH SQL*Net SQL*Net FETCH SQL*Net SQL*Net... Message From Client Message To Client Message From Client Message To Client Message From Client Message To Client Message From Client Message To Client Message From Client Message To Client Message From Client Apenas SELECT possui a fase FETCH. 65
66 Processamento de SQL 66

67 PL/SQL Engine 67

68 SQL Recursivos 68
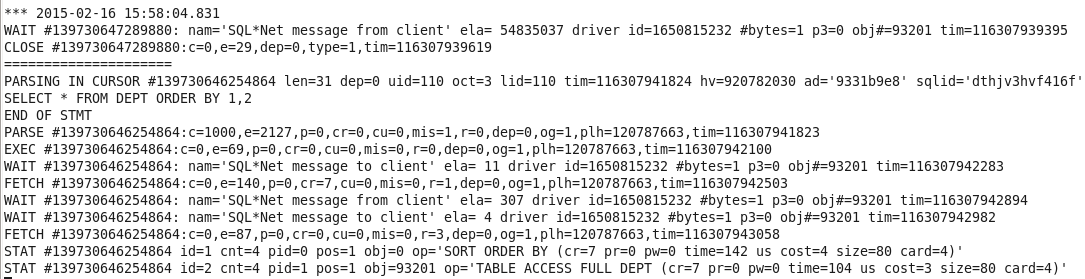
69 SQL Recursivos 69

70 Hard Parse / Soft Parse 70

71 Hard Parse / Soft Parse 71
72 Lab 3 SQL Engine Hands On! 72
73 Lab 3.1: FETCH Execute os comandos abaixo. CONN HR/HR SET AUTOTRACE TRACEONLY STATISTICS SELECT * FROM EMPLOYEES; 107 rows selected. Statistics recursive calls 0 db block gets 15 consistent gets 6 physical reads 0 redo size bytes sent via SQL*Net to client 629 bytes received via SQL*Net from client 9 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 107 rows processed 73
74 Lab 3.2: FETCH Execute os mesmo SELECT anterior, mas com o ARRAYSIZE diferente. HR> SET ARRAYSIZE 100 HR> SELECT * FROM EMPLOYEES; 107 rows selected. Statistics recursive calls 0 db block gets 9 consistent gets 0 physical reads 0 redo size 9335 bytes sent via SQL*Net to client 563 bytes received via SQL*Net from client 3 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 107 rows processed 74
75 Lab 3.3: Shared Pool Reinicie a instância, e execute os comandos abaixo. CONN / AS SYSDBA SHUTDOWN IMMEDIATE STARTUP CONN SCOTT/TIGER SET AUTOTRACE TRACEONLY STATISTICS SELECT ENAME FROM EMP WHERE EMPNO = 7369; 104 recursive calls 0 db block gets 164 consistent gets 7 physical reads 0 redo size 550 bytes sent via SQL*Net to client 551 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 9 sorts (memory) 0 sorts (disk) 1 rows processed 75
76 Lab 3.4: Shared Pool Execute novamente o mesmo SELECT. SELECT ENAME FROM EMP WHERE EMPNO = 7369; 0 recursive calls 0 db block gets 2 consistent gets 0 physical reads 0 redo size 550 bytes sent via SQL*Net to client 551 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed 76
77 Lab 3.5: Shared Pool Execute o mesmo SQL, duas vezes, mas solicitando outro registro. SELECT ENAME FROM EMP WHERE EMPNO = 7499; 36 recursive calls 0 db block gets 53 consistent gets 0 physical reads 0 redo size 550 bytes sent via SQL*Net to client 551 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 5 sorts (memory) 0 sorts (disk) 1 rows processed SELECT ENAME FROM EMP WHERE EMPNO = 7499; 0 recursive calls 0 db block gets 2 consistent gets 0 physical reads 0 redo size 550 bytes sent via SQL*Net to client 551 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed 77
78 Lab 3.6: Shared Pool Execute o mesmo SQL, também duas vezes, mas solicitando outro registro. SELECT ENAME FROM EMP WHERE EMPNO = 7521; 1 recursive calls 0 db block gets 2 consistent gets 0 physical reads 0 redo size 549 bytes sent via SQL*Net to client 551 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SELECT ENAME FROM EMP WHERE EMPNO = 7521; 0 recursive calls 0 db block gets 2 consistent gets 0 physical reads 0 redo size 549 bytes sent via SQL*Net to client 551 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed 78
79 Lab 3.7: Shared Pool Execute o seguinte SQL, também duas vezes. SELECT ENAME FROM EMP WHERE EMPNO IN (7654, 7698, 7782); 5 recursive calls 0 db block gets 13 consistent gets 2 physical reads 0 redo size 619 bytes sent via SQL*Net to client 551 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 3 rows processed SELECT ENAME FROM EMP WHERE EMPNO IN (7654, 7698, 7782); 0 recursive calls 0 db block gets 4 consistent gets 0 physical reads 0 redo size 619 bytes sent via SQL*Net to client 551 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 3 rows processed 79
80 Lab 3.8: Shared Pool Remova as estatísticas da tabela, e execute o primeiro SQL, também duas vezes. EXEC DBMS_STATS.DELETE_TABLE_STATS('SCOTT', 'EMP'); SELECT ENAME FROM EMP WHERE EMPNO = 7369; 0 recursive calls 0 db block gets 2 consistent gets 16 physical reads 0 redo size... 0 sorts (memory) 0 sorts (disk) 1 rows processed SELECT ENAME FROM EMP WHERE EMPNO = 7369; 0 recursive calls 0 db block gets 2 consistent gets 0 physical reads 0 redo size... 0 sorts (memory) 0 sorts (disk) 1 rows processed 80
81 Lab 3.9: Shared Pool Execute o SQL abaixo, que retorna mais dados, também duas vezes. SELECT * FROM DEPT; 40 recursive calls 0 db block gets 88 consistent gets 41 physical reads 0 redo size... 6 sorts (memory) 0 sorts (disk) 4 rows processed SELECT * FROM DEPT; 0 recursive calls 0 db block gets 8 consistent gets 0 physical reads 0 redo size... 0 sorts (memory) 0 sorts (disk) 4 rows processed 81
82 Lab 3.10: Shared Pool Limpe a Shared Pool, e execute novamente o SQL, também duas vezes. ALTER SYSTEM FLUSH SHARED_POOL; SELECT * FROM DEPT; 1a execução: 71 recursive calls 0 db block gets 90 consistent gets 0 physical reads 0 redo size... 6 sorts (memory) 0 sorts (disk) 4 rows processed SELECT * FROM DEPT; 0 recursive calls 0 db block gets 8 consistent gets 0 physical reads 0 redo size... 0 sorts (memory) 0 sorts (disk) 4 rows processed 82
83 Lab 3.11: Shared Pool Execute novamente o primeiro SQL, mas com variáveis Bind, também duas vezes. VARIABLE vempno NUMBER EXEC :vempno := 7369 SELECT ENAME FROM EMP WHERE EMPNO = :vempno; 0 recursive calls 0 db block gets 2 consistent gets 0 physical reads 0 redo size... 1 rows processed EXEC :vempno := 7499 SELECT ENAME FROM EMP WHERE EMPNO = :vempno; 0 recursive calls 0 db block gets 2 consistent gets 0 physical reads 0 redo size... 1 rows processed 83
84 Lab 3.12: Hard Parse / Soft Parse Execute novamente o SELECT na DEPT, verificado os Parses. SET AUTOTRACE OFF SELECT S.NAME, M.VALUE FROM V$STATNAME S, V$MYSTAT M WHERE S.STATISTIC# = M.STATISTIC# AND S.NAME IN ('parse count (total)', 'parse count (hard)'); parse count (total) 30 parse count (hard) 6 SELECT * FROM DEPT;... parse count (total) parse count (hard) 32 6 SELECT * FROM DEPT;... parse count (total) parse count (hard) 34 6 SELECT * FROM DEPT ORDER BY 1;... parse count (total) parse count (hard) 43 7 SELECT * FROM DEPT ORDER BY 1,2;... parse count (total) parse count (hard)
85 Lab 3.13: Buffer Cache Limpe o Buffer Cache, e execute novamente o SQL da DEPT, também duas vezes. ALTER SYSTEM FLUSH BUFFER_CACHE; SET AUTOTRACE TRACEONLY STATISTICS SELECT * FROM DEPT; 1a execução: 0 recursive calls 0 db block gets 8 consistent gets 6 physical reads 0 redo size... 0 sorts (memory) 0 sorts (disk) 4 rows processed 2a execução: 0 recursive calls 0 db block gets 8 consistent gets 0 physical reads 0 redo size... 0 sorts (memory) 0 sorts (disk) 4 rows processed 85
86 Lab 3.14: Connect / Parse / Commit Crie a tabela abaixo com o usuário SCOTT. CREATE TABLE T314 (C1 NUMBER); Observe o conteúdo dos seguintes scripts Perl, os execute, e compare. $ $ $ $ $ $ $ $ $ $ time time time time time time time time time time perl perl perl perl perl perl perl perl perl perl /home/oracle/connectbad_commitbad_bindsbad.pl 5000 /home/oracle/connectbad_commitbad_bindsgood.pl 5000 /home/oracle/connectbad_commitgood_bindsbad.pl 5000 /home/oracle/connectbad_commitgood_bindsgood.pl 5000 /home/oracle/connectgood_commitbad_bindsbad.pl 5000 /home/oracle/connectgood_commitbad_bindsgood.pl 5000 /home/oracle/connectgood_commitgood_bindsbad.pl 5000 /home/oracle/connectgood_commitgood_bindsbad_one.pl 5000 /home/oracle/connectgood_commitgood_bindsgood.pl 5000 /home/oracle/connectgood_commitgood_bindsgood_perfect.pl 5000 Re-execute o ConnectGOOD_CommitGOOD_BindsBAD.pl, mas em sessões concorrentes. 10 x $ time perl /home/oracle/connectgood_commitgood_bindsbad.pl 5000 & Re-execute os testes ConnectGOOD com os parâmetros abaixo alterados. ALTER SYSTEM SET CURSOR_SHARING=FORCE; ALTER SYSTEM SET COMMIT_LOGGING=BATCH; 86
87 Lab 3.15: PL/SQL Engine Crie esta tabela com o usuário SCOTT: CREATE TABLE T315 (C1 NUMBER); Observe o conteúdo dos seguintes scripts Perl, os execute, e compare: $ time perl /home/oracle/semplsql.pl 5000 $ time perl /home/oracle/complsql.pl
88 Access Paths 88
89 Access Paths Full Table Scan (FTS) Table Access by ROWID Index Unique Scan Index Range Scan Index range scan descending Index Skip Scan Full Index Scan (FIS) Fast Full Index Scan (FFIS) 89
; Velocidade de leitura de múltiplos blocos x único bloco (System Statistics); Distribuição das linhas")
90 Full Table Scan Depende de: Percentual de dados que serão acessados; Quantidade de blocos lidos em leituras múltiplas (db_file_multiblock_read_count); Velocidade de leitura de múltiplos blocos x único bloco (System Statistics); Distribuição das linhas nos blocos; HWM. 90
91 MBRC: scatteread / sequential Ocorre db file sequential read quando: - O bloco está no final do Extent; - O bloco já está no cache; - Excede o limite do sistema operacional; - UNDO. 91
92 Lab 4.1: FTS e Clustering Factor Crie as duas tabelas abaixo com o usuário SCOTT, e compare as duas. CONN SCOTT/TIGER CREATE TABLE T1 AS SELECT TRUNC((ROWNUM-1)/100) ID, RPAD(ROWNUM,100) NAME FROM DBA_SOURCE WHERE ROWNUM <= 10000; CREATE INDEX T1_IDX1 ON T1(ID); CREATE TABLE T2 AS SELECT MOD(ROWNUM,100) ID, RPAD(ROWNUM,100) NAME FROM DBA_SOURCE WHERE ROWNUM <= 10000; CREATE INDEX T2_IDX1 ON T2(ID); SELECT SELECT SELECT SELECT SELECT SELECT SELECT SELECT COUNT(*) FROM T1; COUNT(*) FROM T2; MIN(ID) FROM T1; MIN(ID) FROM T2; MAX(ID) FROM T1; MAX(ID) FROM T2; COUNT(*) FROM T1 WHERE ID = 1; COUNT(*) FROM T2 WHERE ID = 1; 92
93 Lab 4.2: FTS e Clustering Factor Compare os planos de execução de SQL iguais para as duas tabelas. SET AUTOTRACE TRACEONLY EXPLAIN SELECT ID, NAME FROM T1 WHERE ID = 1; SELECT ID, NAME FROM T2 WHERE ID = 1; SELECT ID, NAME FROM T1 WHERE ID < 5; SELECT ID, NAME FROM T2 WHERE ID < 5; SELECT ID, NAME FROM T1 WHERE ID < 10; SELECT ID, NAME FROM T2 WHERE ID < 10; Verifique a ordenação física dos dados das tabelas. SET AUTOTRACE OFF SELECT ID, NAME FROM T1; SELECT ID, NAME FROM T2; SELECT ROWID, ID, NAME FROM T1 ORDER BY 2; SELECT ROWID, ID, NAME FROM T2 ORDER BY 2; 93
94 Lab 4.3: FTS e Clustering Factor Compare as estatísticas das duas tabelas. SET AUTOTRACE OFF COL TABLE_NAME FORMAT A20 COL INDEX_NAME FORMAT A20 SELECT T.TABLE_NAME, I.INDEX_NAME, I.CLUSTERING_FACTOR, T.BLOCKS, T.NUM_ROWS FROM DBA_TABLES T, DBA_INDEXES I WHERE T.TABLE_NAME = I.TABLE_NAME AND T.TABLE_NAME IN ('T1', 'T2') AND T.OWNER = 'SCOTT' ORDER BY T.TABLE_NAME, I.INDEX_NAME; 94
95 Lab 4.4: FTS e HWM Compare as estatísticas deste SELECT, antes e depois do DELETE. CREATE TABLE T4 AS SELECT * FROM ALL_OBJECTS; SET AUTOTRACE TRACEONLY SELECT COUNT(*) FROM T4; SELECT COUNT(*) FROM T4; SELECT COUNT(*) FROM T4; DELETE SELECT SELECT SELECT FROM T4; COUNT(*) FROM T4; COUNT(*) FROM T4; COUNT(*) FROM T4; 95
96 Lab 4.5: FTS e HWM Verifique os blocos utilizados pela tabela, antes e depois do DELETE. SET AUTOTRACE OFF DROP TABLE T4; CREATE TABLE T4 AS SELECT * FROM ALL_OBJECTS; SELECT MIN(DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)) MIN_BLK, MAX(DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)) MAX_BLK FROM T4; DELETE FROM T4; SELECT MIN(DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)) MIN_BLK, MAX(DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)) MAX_BLK FROM T4; ROLLBACK; SELECT MIN(DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)) MIN_BLK, MAX(DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)) MAX_BLK FROM T4; 96
97 Index Scan Index Unique Scan Index Range Scan Index Skip Scan Index Full Scan Index Fast Full Scan Por que ler todos blocos de um índice E os da tabela, e não só os da tabela? 97
98 Index Scan B-tree = Árvore Balanceada Root Block / Branch Blocks / Leaf Blocks Height / BEVEL (quando o Height / BLEVEL aumenta?) Average Leaf Blocks per Key / Average Data Blocks per Key Clustering Factor 98
99 Lab 5.1: Index Scan Compare as estatísticas destes SELECTs. SET AUTOTRACE TRACEONLY STATISTICS SELECT NAME FROM T1 WHERE ID = 0 AND NAME = 1; 0 recursive calls 0 db block gets 6 consistent gets 0 physical reads 0 redo size 636 bytes sent via SQL*Net to client 552 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SELECT COUNT(NAME) FROM T1 WHERE ID = 0 AND NAME = 1; 0 recursive calls 0 db block gets 4 consistent gets 0 physical reads 0 redo size 545 bytes sent via SQL*Net to client 552 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed 99
100 Lab 5.2: Index Scan Compare as estatísticas deste SELECTs, com os do Lab 5.1. SELECT NAME FROM T2 WHERE ID = 0 AND NAME = 1; 0 recursive calls 0 db block gets 156 consistent gets 0 physical reads 0 redo size 348 bytes sent via SQL*Net to client 540 bytes received via SQL*Net from client 1 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 0 rows processed SELECT COUNT(NAME) FROM T2 WHERE ID = 0 AND NAME = 1; 0 recursive calls 0 db block gets 156 consistent gets 0 physical reads 0 redo size 552 bytes sent via SQL*Net to client 551 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed 100
101 Lab 5.3: Index Scan Compare as estatísticas deste SELECTs. SELECT NAME FROM T1 WHERE ID = 1; 1 recursive calls 0 db block gets 7 consistent gets 0 physical reads 0 redo size bytes sent via SQL*Net to client 552 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 100 rows processed SELECT NAME FROM T2 WHERE ID = 1; 1 recursive calls 0 db block gets 157 consistent gets 0 physical reads 0 redo size bytes sent via SQL*Net to client 552 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 100 rows processed 101
102 Index Unique Scan 102
103 Index Unique Scan Utilizado com Primary Key ou Unique Key; Consistent Gets mínimo = (Rows x 2) + BLEVEL
104 Index Range Scan 104
105 Index Range Scan Utilizado com Primary Key, Unique Key, ou Non-unique Key; Consistent Gets mínimo = (Rows x 2) + BLEVEL
106 Index Range Scan - Sort 106
107 Index Full Scan 107
108 Index Full Scan Utilizado quando: Não há predicado, mas uma das colunas está indexada; Predicado não é a primeira coluna de um índice; Um índice pode economizar um SORT. 108
109 Index Full Scan Sem predicado, mas uma das colunas está indexada; Predicado não é a primeira coluna de um índice; Um índice pode economizar um SORT. 109
110 Index Full Scan Sem predicado, mas uma das colunas está indexada; Predicado não é a primeira coluna de um índice; Um índice pode economizar um SORT. 110
111 Index Full Scan Sem predicado, mas uma das colunas está indexada; Predicado não é a primeira coluna de um índice; Um índice pode economizar um SORT. 111
112 Index Full Scan 112
113 Index Full Scan 113
114 Index Skip Scan O predicado contém uma condição em uma coluna indexada, mas esta coluna não é a primeira do índice, e as primeiras colunas tem um baixo NDV. 114
115 Index Fast Full Scan Utilizado quando todas as colunas do SELECT estão incluídas no índice; Utiliza MBRC; Não há acesso à tabela; Não pode ser utilizado para evitar um SORT. 115
116 Query Transformation 116
117 Query Rewrite De acordo com a Documentação: OR Expansion View Merging Predicate Pushing Subquery Unnesting In-Memory Aggregation Table Expansion Join Factorization Query Rewrite with Materialized Views Star Transformation 117
118 Query Rewrite Controle: Hints QUERY_TRANSFORMATION / NO_QUERY_TRANSFORMATION FROM CONN HR/HR ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; SELECT * FROM EMPLOYEES WHERE DEPARTMENT_ID IN (SELECT DEPARTMENT_ID DEPARTMENTS); 118
119 View Merging Controle: MERGE / NO_MERGE / Parâmetro _complex_view_merging (TRUE de 9i em diante). Geralmente utilizada quando o Outer Query Block contém: - Uma coluna que pode ser utilizada em um índice com outro Query Block; - Uma coluna que pode ser utilizada para Partition Pruning com outro Query Block; - Uma condição que limita as linhas retornadas de uma das tabelas em uma Joined View. Geralmente não será utilizada se: - Um Query Block contiver uma função de agregação ou analítica; - Um Query Block contiver Set Operations (UNION, INTERSECT, MINUS); - Um Query Block contiver ORDER BY; - Um Query Block contiver ROWNUM. Fomos treinados para entender que estas duas expressões retornam resultados diferentes: 6+4/2=8 (6 + 4) / 2 = 5 119
120 Lab 6.1: View Merging Execute o SELECT abaixo, e encontre no arquivo trace o View Merging. CONN OE/OE ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; SELECT * FROM ORDERS O, (SELECT SALES_REP_ID FROM ORDERS) O_VIEW WHERE O.SALES_REP_ID = O_VIEW.SALES_REP_ID (+) AND O.ORDER_TOTAL > ; Execute o SELECT abaixo, e encontre no arquivo trace o View Merging. CONN OE/OE ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; SELECT * FROM ORDERS O, (SELECT SALES_REP_ID FROM ORDERS ORDER BY SALES_REP_ID) O_VIEW WHERE O.SALES_REP_ID = O_VIEW.SALES_REP_ID (+) AND O.ORDER_TOTAL > AND ROWNUM < 10 ORDER BY ORDER_TOTAL; 120
121 Subquery Unnesting - Controle: HINT NO_UNNEST, unnest_subquery (TRUE de 9i em diante). - Similar a View Merging, ocorre quando a Subquery está localizada na cláusula WHERE; - A transformação mais comum é em um JOIN; FROM CONN HR/HR ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; SELECT * FROM EMPLOYEES WHERE DEPARTMENT_ID IN (SELECT DEPARTMENT_ID DEPARTMENTS); 121

122 Subquery Unnesting + JE O plano de execução utiliza quais tabelas? 122
123 Lab 6.2: Subquery Unnesting Execute o SELECT abaixo, e encontre no arquivo trace o Subquery Unnesting. CONN HR/HR ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; SELECT OUTER.EMPLOYEE_ID, OUTER.LAST_NAME, OUTER.SALARY, OUTER.DEPARTMENT_ID FROM EMPLOYEES OUTER WHERE OUTER.SALARY > (SELECT AVG(INNER.SALARY) FROM EMPLOYEES INNER WHERE INNER.DEPARTMENT_ID = OUTER.DEPARTMENT_ID); 123
124 Lab 6.3: Subquery Unnesting 124
125 Predicate Pushing - Controle: Hints PUSH_PRED / NO_PUSH_PRED. - Geralmente utilizado para aplicar os predicados de um Query Block em outro Query Block, quando não pode ocorrer uma transformação de Merging, para permitir a utilização de um índice e filtrar mais cedo no plano de execução; 125
126 Lab 6.4: Predicate Pushing Execute o SELECT abaixo, e encontre no arquivo trace o Predicate Pushing. CONN HR/HR ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; SELECT E1.LAST_NAME, E1.SALARY, V.AVG_SALARY FROM EMPLOYEES E1, (SELECT DEPARTMENT_ID, AVG(SALARY) AVG_SALARY FROM EMPLOYEES E2 GROUP BY DEPARTMENT_ID) V WHERE E1.DEPARTMENT_ID = V.DEPARTMENT_ID AND E1.SALARY > V.AVG_SALARY AND E1.DEPARTMENT_ID = 60; E com DEPARTMENT_ID IN (10,40,60)? 126
127 Join Methods & Options 127
 / Inner Table (menor):")
128 Join Methods Nested Loops Hash Joins Sort-merge Joins Driving Table (Outer / maior / PK / UNIQUE) / Inner Table (menor): 128
129 Join Options Inner Join Outer Join Cross Join / Cartesian Joins Semi-Join Anti-Join 129
130 Nested Loops É um LOOP dentro de um LOOP. É mais eficiente com pequenos Result Sets; Geralmente ocorre quando há índices nas colunas utilizadas pelo Join; Utiliza pouca memória, pois o Result Set é construído uma linha por vez; HINT: /*+ USE_NL(EMP DEPT) */ SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10); SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10,20); SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO; 130
131 Sort-Merge Joins 131
132 Sort-Merge Joins Lê as duas tabelas de forma independente, ordena, e junta os Result Sets, descartando linhas que não combinam; Geralmente é utilizado para Result Sets maiores, e quando não há índices; Geralmente é utilizado quando é uma operação de desigualdade; O maior custo é a ordenação; Poderá ser utilizada apenas PGA, ou pode ser necessário TEMP; HINTs: USE_MERGE / NO_USE_MERGE SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO NOT IN (10); 132
133 Hash Joins Só ocorre em equi-joins; Geralmente é utilizado para grandes Result Sets; Geralmente é utilizado se o menor Result Set cabe em memória; A tabela com o menor Result Set é lida e armanezada em memória como um HASH; Em seguida a outra tabela (maior Result Set) é lida, é aplicado o HASH, e então comparada com a menor; Poderá ser utilizada apenas PGA, ou pode ser necessário TEMP; 133
134 Hash Joins 134
135 Cartesian Joins / Cross Joins Geralmente trata-se da ausência de condição do Join (DISTINCT!); O tamanho do resultado é o produto dos dois Result Sets; Poderá ser utilizada apenas PGA, ou pode ser necessário TEMP. O BUFFER SORT de um Cartesian Join não é um SORT. 135
136 Cartesian Joins / Cross Joins SELECT T1.ID, T2.NAME FROM T1, T2 WHERE T1.ID = T2.ID; 136
137 Outer Joins Sintaxe Oracle: (+); A sintaxe Oracle não suporta FULL OUTER JOIN; Sintaxe ANSI: LEFT [OUTER] JOIN / RIGHT [OUTER] JOIN; Um OUTER JOIN pode utilizar qualquer método de JOIN; 12c: Multi-table LEFT OUTER JOIN. 137
138 Semi-Joins (IN) Controle: HINTs SEMIJOIN, NO_SEMIJOIN, NL_SJ, MERGE_SJ, HASH_SJ Uma otimização de INNER JOIN, de custo menor; Utilizado em listas IN ou EXISTS; É necessário utilizar uma Subquery; Se for utilizado EXISTS, é necessário utilizar uma Correlated Subquery; As cláusulas IN ou EXISTS não podem estar dentro de um OR. CONN HR/HR SELECT DEPARTMENT_NAME FROM DEPARTMENTS DEPT WHERE DEPARTMENT_ID IN (SELECT DEPARTMENT_ID FROM HR.EMPLOYEES EMP); 138
139 Semi-Joins (EXISTS) CONN HR/HR SELECT DEPARTMENT_NAME FROM DEPARTMENTS DEPT WHERE EXISTS (SELECT NULL FROM HR.EMPLOYEES EMP WHERE EMP.DEPARTMENT_ID = DEPT.DEPARTMENT_ID); 139
140 Anti-Joins (NOT IN) Uma otimização de INNER JOIN, de custo menor; Utilizado em listas NOT IN ou NOT EXISTS; É necessário utilizar uma Subquery; Se for utilizado NOT EXISTS, é necessário utilizar uma Correlated Subquery; As cláusulas NOT IN ou NOT EXISTS não podem estar dentro de um OR; A Subquery não pode retornar NULL (<=10g) (SNA). Controle: HINTs ANTIJOIN, NL_AJ, MERGE_AJ, HASH_AJ Controle: Parâmetros _always_anti, _gs_anti_semi_join_allowed, _optimizer_null_aware_antijoin, _optimizer_outer_to_anti_enabled 140
141 Anti-Joins (NOT IN) SELECT * FROM EMPLOYEES WHERE DEPARTMENT_ID NOT IN (SELECT DEPARTMENT_ID FROM DEPARTMENTS WHERE LOCATION_ID = 1700) ORDER BY LAST_NAME; 141
142 Anti-Joins (NOT EXISTS) SELECT DEPARTMENT_NAME FROM DEPARTMENTS DEPT WHERE NOT EXISTS (SELECT NULL FROM EMPLOYEES EMP WHERE EMP.DEPARTMENT_ID = DEPT.DEPARTMENT_ID); 142
143 Bloom Filters Controle: HINTs PX_JOIN_FILTER, NO_PX_JOIN_FILTER; Utiliza pouca memória para o filtro em relação do conjunto de dados; É mais utilizado quando a maioria das linhas são descartadas em um JOIN; Reduz a quantidade de dados transferidos entre processos paralelos; É mais utilizado se mais partições forem eliminadas por Partition Pruning; Utiliza Result Cache; É utilizado em Exatada, especialmente em JOINs em STAR SCHEMAs. 143
144 Partition-wise Joins No partition-wise join 144


145 Partition-wise Joins Full partition-wise join Partial partition-wise joins 145
146 Índices 146
147 Índices B-tree Bitmap Bitmap Join IOT (Index-Organized Table) Function-Based Invisible Indexes (11g / OPTIMIZER_USE_INVISIBLE_INDEXES) Virtual Indexes Partitioned Indexes Partial Indexes (12c) Domain Indexes Compressed Ascending / Descending Table Clusters 147
148 Índices Bitmap Join CREATE BITMAP INDEX cust_sales_bji ON sales(customers.state) FROM sales, customers WHERE sales.cust_id = customers.cust_id; IOT CREATE TABLE locations (id NUMBER(10) NOT NULL, description VARCHAR2(50) NOT NULL, map BLOB, CONSTRAINT pk_locations PRIMARY KEY (id) ) ORGANIZATION INDEX TAB LESPACE iot_tablespace PCTTHRESHOLD 20 INCLUDING description OVERFLOW TABLESPACE overflow_tablespace; 148
149 Índices Invisible ALTER INDEX IDX_T INVISIBLE; ALTER INDEX IDX_T VISIBLE; Virtual CREATE INDEX IDX_T ON T(OBJECT_NAME) NOSEGMENT; Function Based CREATE INDEX IDX_T ON T(UPPER(OBJECT_NAME)); Partial Index ALTER TABLE T1 MODIFY PARTITION CREATE INDEX T1_IDX ON T1(YEAR) CREATE INDEX T1_IDX ON T1(YEAR) CREATE INDEX T1_IDX ON T1(YEAR) CREATE INDEX T1_IDX ON T1(YEAR) CREATE INDEX T1_IDX ON T1(YEAR) CREATE INDEX T1_IDX ON T1(YEAR) ANO_2014 INDEXING OFF; LOCAL; LOCAL INDEXING FULL; LOCAL INDEXING PARTIAL; GLOBAL; GLOBAL INDEXING FULL; GLOBAL INDEXING PARTIAL; 149
150 Índices - Guidelines Geral Controle: HINTs INDEX, INDEX_COMBINE, NO_INDEX, FULL; Crie índices em colunas utilizadas na cláusula WHERE; Crie índices em colunas utilizadas em JOINs; Crie índices em colunas de alta seletividade; Crie índices em colunas de baixa seletividade mas que contenham dados com seletividades muito distintas; Prefira índices PRIMARY KEY, se o modelo permitir; Prefira índices UNIQUE, se o modelo permitir, mas PRIMARY KEY não é possível; Crie índices compostos em colunas utilizadas frequentemente na mesma cláusula WHERE; Em índices compostos, utilize as colunas com maior seletividade à esquerda; Se um valor de uma coluna indexada não for utilizado em uma cláusula WHERE, verifique se este valor pode ser trocado para NULL; Busque sempre minimizar a quantidade de índices de uma tabela; Considere o espaço utilizado por um índice (60% - 40%). 150
151 Índices - Guidelines DML Crie índices em Foreign Keys (FKs) que sofrem DML de forma concorrente; Evite índices em colunas que sofrem muitos UPDATEs; Evite índices em tabelas que sofrem muitos INSERTs ou DELETEs. Tipos Prefira índices BTREE em colunas de alta seletividade (CPF, NF); Prefira índices BITMAP em colunas de baixa seletividade (ESTADO, CIDADE); Evite índices em colunas utilizadas em cláusula WHERE apenas com funções; Utilize índices de função em colunas utilizadas em cláusula WHERE mais frequentemente com funções; Prefira índices BITMAP para grandes tabelas; Evite índices BITMAP em colunas que sofrem muito DML, principalmente de forma concorrente; Prefira partições HASH em índices pequenos que sofrem DML em alta concorrência; Utilize IOTs em PKs frequentemente utilizadas na cláusula WHERE. 151
152 Índices - Table Clusters Utilize se as tabelas são frequentemente utilizadas em JOINs (NF e ITEM_NF); Utilize se as tabelas sofrem mais JOINs do que operações DML; Evite se é utilizado FTS de apenas uma das tabelas; Evite para linhas largas (PEDIDO_NOTA_FISCAL com OBS); Evite se o número de linhas nas chaves das duas tabelas é muito diferente. 152
153 BITMAP x BTREE SELECT COUNT(*) FROM T4; COUNT(1) Sem índice. SELECT COUNT(DISTINCT(OWNER)) FROM T; - - Sem índice. COUNT(DISTINCT(OWNER)) 28 Decorrido: 00:00:26.75 SELECT COUNT(DISTINCT(OWNER)) FROM T; - - Com índice BTREE. COUNT(DISTINCT(OWNER)) 28 Decorrido: 00:00:05.29 SELECT COUNT(DISTINCT(OWNER)) FROM T; - - Com índice BITMAP. COUNT(DISTINCT(OWNER)) 28 Decorrido: 00:00:
154 BITMAP x BTREE SELECT COUNT(*) FROM T; COUNT(1) SELECT COUNT(DISTINCT(OWNER)) FROM T; COUNT(DISTINCT(OWNER)) 28 SELECT COUNT(DISTINCT(OBJECT_NAME)) FROM T; -- Com índice BTREE COUNT(DISTINCT(OBJECT_NAME)) Decorrido: 00:00:08.95 SELECT COUNT(DISTINCT(OBJECT_NAME)) FROM T; Com índice BITMAP COUNT(DISTINCT(OBJECT_NAME)) Decorrido: 00:00:
155 Índices e Access Paths 155
156 Índices e Access Paths 156
157 Lab 7.1: DML e BITMAP Index 1a Sessão: 2a Sessão: CREATE BITMAP INDEX IDX_BITMAP_T314 ON T314(C1); INSERT INTO T314 VALUES (1); COMMIT; INSERT INTO T314 VALUES (10); COMMIT; INSERT INTO T314 VALUES (1); COMMIT; INSERT INTO T314 VALUES (1); COMMIT; INSERT INTO T314 VALUES (1); INSERT INTO T314 VALUES (10); INSERT INTO T314 VALUES (10); INSERT INTO T314 VALUES (1); 157
158 Lab 7.2: Impacto de Índices Execute novamente o melhor script de INSERT, mas com a adição de índices como abaixo. $ $ $ $ cd /home/oracle time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl DROP INDEX IDX_BITMAP_T314; CREATE INDEX IDX_BTREE_T314 ON T314(C1); $ time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl $ time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl $ time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl DROP INDEX IDX_BTREE_T314; $ time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl $ time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl $ time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl
159 Lab 7.3: Impacto de Índices Com o usuário SCOTT, crie uma tabela de testes, e verifique o tempo de sua duplicação. CREATE TABLE T7 AS SELECT * FROM ALL_OBJECTS; INSERT INTO T7 SELECT * FROM T7; INSERT INTO T7 SELECT * FROM T7; INSERT INTO T7 SELECT * FROM T7; INSERT INTO T7 SELECT * FROM T7; COMMIT; CREATE TABLE T8 AS SELECT * FROM T7 WHERE 1=0; SET TIMING ON INSERT INTO T8 TRUNCATE TABLE INSERT INTO T8 TRUNCATE TABLE INSERT INTO T8 TRUNCATE TABLE SELECT * FROM T7; T8; SELECT * FROM T7; T8; SELECT * FROM T7; T8; 159
160 Lab 7.4: Impacto de Índices Verifique o tempo de sua duplicação, mas com índices. CREATE INDEX T8_IDX_01 ON T8(OWNER); INSERT INTO T8 SELECT * FROM T7; TRUNCATE TABLE T8; INSERT INTO T8 SELECT * FROM T7; TRUNCATE TABLE T8; INSERT INTO T8 SELECT * FROM T7; TRUNCATE TABLE T8; CREATE INDEX T8_IDX_02 ON T8(OBJECT_NAME); INSERT INTO T8 SELECT * FROM T7; TRUNCATE TABLE T8; INSERT INTO T8 SELECT * FROM T7; TRUNCATE TABLE T8; INSERT INTO T8 SELECT * FROM T7; TRUNCATE TABLE T8; 160
161 Lab 7.5: Impacto de Índices Verifique o tempo de sua duplicação, mas um índice composto. DROP INDEX T8_IDX_01; DROP INDEX T8_IDX_02; CREATE INDEX T8_IDX_03 ON T8(OWNER,OBJECT_NAME); INSERT INTO T8 SELECT * FROM T7; TRUNCATE TABLE T8; INSERT INTO T8 SELECT * FROM T7; TRUNCATE TABLE T8; INSERT INTO T8 SELECT * FROM T7; TRUNCATE TABLE T8; 161
162 Lab 7.6: Impacto de Índices Verifique o uso dos índices. CONN SCOTT/TIGER DROP INDEX T8_IDX_03; INSERT INTO T8 SELECT * FROM T7; CREATE INDEX T8_IDX_01 ON T8(OWNER); CREATE INDEX T8_IDX_02 ON T8(OBJECT_NAME); ALTER INDEX T8_IDX_01 MONITORING USAGE; ALTER INDEX T8_IDX_02 MONITORING USAGE; FROM ' COL INDEX_NAME FORMAT A40 SELECT INDEX_NAME, MONITORING, USED FROM V$OBJECT_USAGE; SELECT COUNT(*) FROM T8 WHERE OWNER = 'SCOTT'; SELECT COUNT(*) FROM T8 WHERE OWNER = 'SYS'; SELECT COUNT(*) FROM T8 WHERE OWNER = 'SYSTEM'; SELECT INDEX_NAME, MONITORING, USED, START_MONITORING V$OBJECT_USAGE; 162
163 Estatísticas 163
164 Estatísticas e SQL Engine Optimizer Statistics Table statistics Number of rows Number of blocks Average row length Column statistics Number of distinct values (NDV) in column Number of nulls in column Data distribution (histogram) Extended statistics Index statistics Number of leaf blocks Average data blocks per Key Levels Index clustering factor System Statistics I/O performance and utilization CPU performance and utilization 164
165 Estatísticas - Tabela DBA_TABLES / ALL_TABLES / USER_TABLES 165
166 Estatísticas - Índices DBA_INDEXES / ALL_INDEXES / USER_INDEXES 166
167 Estatísticas - Colunas DBA_TAB_COLUMNS / ALL_TAB_COLUMNS / USER_TAB_COLUMNS 167
168 Estatísticas - Histogramas DBA_TAB_COLUMNS / ALL_TAB_COLUMNS / USER_TAB_COLUMNS DBA_TAB_HISTOGRAMS / ALL_TAB_HISTOGRAMS / USER_TAB_HISTOGRAMS 168
169 Histogramas - Buckets: máximo de 255 ( c); - Frequency Histograms; - Height-Balanced Histograms; - Top Frequency Histograms (12c); - Hybrid Histograms (12c)
170 Frequency Histograms Utilizados se: - Se o NDV é menor ou igual que a quantidade de Buckets indicados na coleta; - É utilizado AUTO_SAMPLE_SIZE na execução da coleta. 170
171 Height Balanced Histograms Utilizados se: - Se o número de Buckets indicados na coleta é menor que o NDV. 171
172 Top Frequency Histograms (12c) Utilizados se: - Se o NDV é maior que a quantidade de Buckets indicados na coleta; - É utilizado AUTO_SAMPLE_SIZE na execução da coleta; - Se o percentual de linhas ocupadas pelos Top Values é igual ou maior que p, sendo que p = (1-(1/Buckets))*
173 Hybrid Histograms (12c) Utilizados se: - Se o número de Buckets indicados na coleta é menor que o NDV; - É utilizado AUTO_SAMPLE_SIZE na execução da coleta; - Se os critétios para Top Frequency Histograms não se aplicam. 173
174 Extended Statistics Column Groups 174
175 Extended Statistics Column Groups CONN SH/SH SELECT DBMS_STATS.CREATE_EXTENDED_STATS(USER, 'CUSTOMERS') FROM DUAL; BEGIN DBMS_STATS.GATHER_TABLE_STATS( 'SH','CUSTOMERS', METHOD_OPT=>'FOR ALL COLUMNS SIZE SKEWONLY ' 'FOR COLUMNS SIZE SKEWONLY (CUST_STATE_PROVINCE,COUNTRY_ID)'); END; / SELECT SYS.DBMS_STATS.SHOW_EXTENDED_STATS_NAME('SH','CUSTOMERS', '(CUST_STATE_PROVINCE,COUNTRY_ID)') COL_GROUP_NAME FROM DUAL; SELECT EXTENSION_NAME, EXTENSION FROM USER_STAT_EXTENSIONS WHERE TABLE_NAME='CUSTOMERS';
176 Extended Statistics Expression 176
177 Extended Statistics Expression CONN SH/SH SELECT DBMS_STATS.CREATE_EXTENDED_STATS(USER, 'CUSTOMERS') FROM DUAL; BEGIN DBMS_STATS.GATHER_TABLE_STATS('SH','CUSTOMERS',METHOD_OPT => 'FOR ALL COLUMNS SIZE SKEWONLY FOR COLUMNS (LOWER(CUST_STATE_PROVINCE)) SIZE SKEWONLY'); END; /

178 Coleta de Estatísticas - ANALYZE ANALYZE TABLE emp VALIDATE STRUCTURE; ANALYZE TABLE emp VALIDATE STRUCTURE CASCADE; ANALYZE TABLE emp VALIDATE STRUCTURE CASCADE FAST; ANALYZE TABLE emp VALIDATE STRUCTURE CASCADE ONLINE; UTLCHAIN.SQL / UTLCHN1.SQL ANALYZE TABLE emp LIST CHAINED ROWS INTO CHAINED_ROWS; 178
179 OPTIMIZER_DYNAMIC_SAMPLING 179
180 OPTIMIZER_DYNAMIC_SAMPLING 180
181 Estatísticas: Coleta Automática Automatic Optimizer Statistics Collection SELECT CLIENT_NAME, STATUS FROM DBA_AUTOTASK_CLIENT; BEGIN DBMS_AUTO_TASK_ADMIN.DISABLE ( CLIENT_NAME => 'AUTO OPTIMIZER STATS COLLECTION',OPERATION => NULL,WINDOW_NAME => NULL ); END; / BEGIN DBMS_AUTO_TASK_ADMIN.ENABLE ( CLIENT_NAME => 'AUTO OPTIMIZER STATS COLLECTION',OPERATION => NULL,WINDOW_NAME => NULL ); END; / 181
182 Estatísticas: Coleta Manual Procedures para coleta DBMS_STATS.GATHER_DATABASE_STATS DBMS_STATS.GATHER_SCHEMA_STATS DBMS_STATS.GATHER_TABLE_STATS DBMS_STATS.GATHER_INDEX_STATS
183 Estatísticas: Opções de Coleta ESTIMATE_PERCENT (Percentual ou DBMS_STATS.AUTO_SAMPLE_SIZE) EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT => 10); EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT => DBMS_STATS.AUTO_SAMPLE_SIZE); DEGREE (Quantidade ou DBMS_STATS.DEFAULT_DEGREE) EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT => 10, DEGREE=>2); EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT => 10, DEGREE=>DBMS_STATS.DEFAULT_DEGREE); CASCADE (TRUE, FALSE, ou AUTO_CASCADE) EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT => 10, DEGREE=>2, CASCADE=>TRUE); EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT => 10, DEGREE=>2, CASCADE=>AUTO_CASCADE);
184 Estatísticas: Opções de Coleta OPTIONS (GATHER, GATHER_STALE, GATHER_EMPTY, GATHER_AUTO) EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT => 10, DEGREE=>2, CASCADE=>TRUE, OPTIONS=>'GATHER_STALE'); EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT => 10, DEGREE=>2, CASCADE=>AUTO_CASCADE OPTIONS=>'GATHER_AUTO); GRANULARITY (ALL, AUTO, DEFAULT, GLOBAL, GLOBAL AND PARTITION, PARTITION, SUBPARTITION) EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT => 10, DEGREE=>2, CASCADE=>AUTO_CASCADE OPTIONS=>'GATHER_AUTO, GRANULARITY=ALL); EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT => 10, DEGREE=>2, CASCADE=>AUTO_CASCADE OPTIONS=>'GATHER_AUTO, GRANULARITY=AUTO);
185 Estatísticas: Opções de Coleta NO_INVALIDATE (TRUE, FALSE, ou DBMS_STATS.AUTO_INVALIDATE) EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT => 10, DEGREE=>2, CASCADE=>AUTO_CASCADE OPTIONS=>'GATHER_AUTO, GRANULARITY=AUTO, NO_INVALIDATE=TRUE); EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT => 10, DEGREE=>2, CASCADE=>AUTO_CASCADE OPTIONS=>'GATHER_AUTO, GRANULARITY=AUTO, NO_INVALIDATE='DBMS_STATS.AUTO_INVALIDATE');
186 Estatísticas: Opções de Coleta METHOD_OPT FOR ALL COLUMNS SIZE 100 FOR ALL COLUMNS SIZE AUTO FOR ALL COLUMNS SIZE REPEAT FOR ALL COLUMNS SIZE SKEWONLY FOR ALL INDEXED COLUMNS SIZE 100 FOR ALL INDEXED COLUMNS SIZE AUTO FOR ALL INDEXED COLUMNS SIZE REPEAT FOR ALL INDEXED COLUMNS SIZE SKEWONLY FOR COLUMNS C1 SIZE 100 FOR COLUMNS C1 SIZE AUTO FOR COLUMNS C1 SIZE REPEAT EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT => DBMS_STATS.AUTO_SAMPLE_SIZE, METHOD_OPT=>'FOR ALL INDEXED COLUMNS SIZE AUTO');
187 Estatísticas: Opções de Coleta Coleta geral EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT => DBMS_STATS.AUTO_SAMPLE_SIZE, DEGREE=>2, CASCADE=>AUTO_CASCADE OPTIONS=>'GATHER_AUTO, GRANULARITY=>AUTO, NO_INVALIDATE=>'DBMS_STATS.AUTO_INVALIDATE', METHOD_OPT=>'FOR ALL INDEXED COLUMNS SIZE 1'); Coleta por exceção EXEC DBMS_STATS.UNLOCK_TABLE_STATS('SCOTT','EMP'); EXEC DBMS_STATS.DELETE_TABLE_STATS('SCOTT','EMP'); EXEC DBMS_STATS.GATHER_TABLE_STATS ('SCOTT', 'EMP', ESTIMATE_PERCENT=>100, DEGREE=>1, CASCADE=>TRUE, OPTIONS=>'GATHER', GRANULARITY=>'ALL',NO_INVALIDATE=>TRUE,METHOD_OPT=>'FOR ALL INDEXED COLUMNS SIZE AUTO'); EXEC DBMS_STATS.LOCK_TABLE_STATS('SCOTT','EMP');
188 Estatísticas: Consulta Tabela SELECT TABLE_NAME, NUM_ROWS, BLOCKS, EMPTY_BLOCKS, AVG_SPACE, CHAIN_CNT, AVG_ROW_LEN, SAMPLE_SIZE, LAST_ANALYZED FROM USER_TABLES ORDER BY 1; Índices SELECT TABLE_NAME, INDEX_NAME, NUM_ROWS, BLEVEL, LEAF_BLOCKS, DISTINCT_KEYS, CLUSTERING_FACTOR, AVG_LEAF_BLOCKS_PER_KEY, AVG_DATA_BLOCKS_PER_KEY, SAMPLE_SIZE, LAST_ANALYZED FROM USER_INDEXES ORDER BY 1,2; Colunas SELECT TABLE_NAME, COLUMN_NAME, NUM_DISTINCT, NUM_NULLS, DENSITY, LOW_VALUE, HIGH_VALUE, DATA_LENGTH, AVG_COL_LEN, SAMPLE_SIZE, LAST_ANALYZED FROM USER_TAB_COLUMNS ORDER BY 1,2; Histogramas SELECT H.TABLE_NAME, H.COLUMN_NAME, C.HISTOGRAM, H.ENDPOINT_NUMBER, H.ENDPOINT_ACTUAL_VALUE, H.ENDPOINT_REPEAT_COUNT FROM USER_TAB_HISTOGRAMS H, USER_TAB_COLUMNS C WHERE H.TABLE_NAME = C.TABLE_NAME AND H.COLUMN_NAME = C.COLUMN_NAME AND HISTOGRAM <> 'NONE' ORDER BY 1,2,4; 188
189 Outras Estatísticas Fixed Objects Statistics (V$SQL, V$SESSION, etc.) EXEC DBMS_STATS.GATHER_FIXED_OBJECTS_STATS; Dictionary Statistics (DBA_SEGMENTS, DBA_TABLES, etc.); EXEC DBMS_STATS.GATHER_DICTIONARY_STATS; 189
190 System Statistics Consulta SELECT PNAME, PVAL1 FROM SYS.AUX_STATS$; Remoção EXEC DBMS_STATS.DELETE_SYSTEM_STATS; Coleta NOWORKLOAD EXEC DBMS_STATS.GATHER_SYSTEM_STATS; Coleta WORKLOAD EXEC DBMS_STATS.GATHER_SYSTEM_STATS('START'); EXEC DBMS_STATS.GATHER_SYSTEM_STATS('STOP'); 190
191 Lab 8.1: System Statistics Verifique e guarde os planos de execução do capítulo de JOINs. Colete as estatísticas de sistema durante uma carga, e verifique sua alteração. SELECT PNAME, PVAL1 FROM SYS.AUX_STATS$; EXEC DBMS_STATS.GATHER_SYSTEM_STATS('START'); $ cd /home/oracle/swingbench/bin/ $./charbench -uc 10 -cs //nerv01/orcl... EXEC DBMS_STATS.GATHER_SYSTEM_STATS('STOP'); SELECT PNAME, PVAL1 FROM SYS.AUX_STATS$; Verifique novamente os planos de execução do capítulo de JOINs. 191
192 Estatísticas Pendentes 192
193 Lab 8.2: Estatísticas Pendentes Colete estatísticas, e verifique-as antes de publica-las. CONN SH/SH EXEC DBMS_STATS.SET_TABLE_PREFS ('SH','CUSTOMERS','PUBLISH','FALSE'); SELECT * FROM USER_TAB_PENDING_STATS; EXEC DBMS_STATS.GATHER_TABLE_STATS('SH','CUSTOMERS'); SELECT * FROM USER_TAB_PENDING_STATS; EXEC DBMS_STATS.PUBLISH_PENDING_STATS('SH','CUSTOMERS'); SELECT * FROM USER_TAB_PENDING_STATS; EXEC DBMS_STATS.SET_TABLE_PREFS ('SH','SALES','PUBLISH','FALSE'); SELECT * FROM USER_TAB_PENDING_STATS; EXEC DBMS_STATS.GATHER_TABLE_STATS('SH','SALES'); SELECT * FROM USER_TAB_PENDING_STATS; EXEC DBMS_STATS.DELETE_PENDING_STATS('SH','SALES'); SELECT * FROM USER_TAB_PENDING_STATS; 193
194 Restore de Estatísticas 194
195 Lab 8.3: Restore de Estatísticas Execute o Restore de uma estatística anterior. CONN OE/OE COL TABLE_NAME FORMAT A10 SELECT TABLE_NAME, TO_CHAR(STATS_UPDATE_TIME,'YYYY-MM-DD:HH24:MI:SS') AS STATS_MOD_TIME FROM DBA_TAB_STATS_HISTORY WHERE TABLE_NAME='ORDERS' AND OWNER='OE' ORDER BY STATS_UPDATE_TIME DESC; EXEC DBMS_STATS.GATHER_TABLE_STATS('OE', 'ORDERS'); EXEC DBMS_STATS.RESTORE_TABLE_STATS( 'OE','ORDERS', TO_TIMESTAMP(' :15:00:00','YYYY-MM-DD:HH24:MI:SS') ); 195
196 Transporte de Estatísticas 196
197 Transporte de Estatísticas Origem EXEC DBMS_STATS.CREATE_STAT_TABLE (ownname => 'HR', stattab => TESTE_STATS')); EXEC DBMS_STATS.GATHER_SCHEMA_STATS ('HR'); BEGIN DBMS_STATS.EXPORT_SCHEMA_STATS (ownname => 'HR', stattab => 'TESTE_STATS' $ expdp HR/HR DIRECTORY=dump_directory DUMPFILE=TESTE_STATS.dmp TABLES=TESTE_STATS Destino: $ impdp PORTILHO DIRECTORY=dump_directory DUMPFILE=TESTE_STATS.dmp TABLES=TESTE_STATS EXEC DBMS_STATS.IMPORT_SCHEMA_STATS(ownname => 'HR', stattab => 'TESTE_STATS'); 197
198 Lab 8.4: Coleta de Estatísticas Verifique os planos de execução dos SQL abaixo. CONN SCOTT/TIGER SET AUTOTRACE ON EXPLAIN SELECT ID, NAME FROM T1 WHERE ID = SELECT ID, NAME FROM T2 WHERE ID = SELECT ID, NAME FROM T1 WHERE ID < SELECT ID, NAME FROM T2 WHERE ID < SELECT ID, NAME FROM T1 WHERE ID < SELECT ID, NAME FROM T2 WHERE ID < 1; 1; 5; 5; 10; 10; Remova as estatísticas e verifique novamente os planos de execução. EXEC DBMS_STATS.DELETE_TABLE_STATS('SCOTT','T1'); EXEC DBMS_STATS.DELETE_TABLE_STATS('SCOTT','T2'); Desabilite as estatísticas dinâmicas, e verifique novamente os planos de execução. ALTER SESSION SET OPTIMIZER_DYNAMIC_SAMPLING=0; Colete as estatísticas com os parâmetros padrão, e verifique novamente os planos de execução. EXEC DBMS_STATS.GATHER_TABLE_STATS('SCOTT','T1'); EXEC DBMS_STATS.GATHER_TABLE_STATS('SCOTT','T2'); 198
199 Lab 8.5: Coleta de Estatísticas Verifique os planos de execução dos SQL abaixo. SELECT COUNT(OBJECT_TYPE), OBJECT_TYPE FROM T7 GROUP BY OBJECT_TYPE ORDER BY 1; CREATE INDEX IND_T7_01 ON T7(OBJECT_TYPE); SET AUTOTRACE ON EXPLAIN SELECT COUNT(OBJECT_NAME) FROM T7 WHERE OBJECT_TYPE = 'SYNONYM'; SELECT COUNT(OBJECT_NAME) FROM T7 WHERE OBJECT_TYPE = 'PACKAGE'; SELECT COUNT(OBJECT_NAME) FROM T7 WHERE OBJECT_TYPE = 'DIRECTORY'; Remova as estatísticas e verifique novamente os planos de execução. EXEC DBMS_STATS.DELETE_TABLE_STATS('SCOTT','T7'); Reabilite as estatísticas dinâmicas, e verifique novamente os planos de execução. ALTER SESSION SET OPTIMIZER_DYNAMIC_SAMPLING=2; ALTER SESSION SET OPTIMIZER_DYNAMIC_SAMPLING=11; Colete as estatísticas com os parâmetros padrão, e verifique novamente os planos de execução. EXEC DBMS_STATS.GATHER_TABLE_STATS('SCOTT','T7'); Colete as estatísticas com Histogramas incorretos para o NDV, e com o tamanho exato do NDV, e verifique novamente os planos de execução. 199
200 Modelagem 200
201 PKs: Surrogate or Natural? Natural Keys (RG, CPF, Nota Fiscal, Matrícula, Apólice...) Naturalidade no entendimento das colunas; Redução da largura da linha; Menor quantidade de JOINs para exibir o resultado final; Validação natural de regras de negócio. Surrogate Keys (SEQUENCE, IDENTITY, MAX + 1 com FOR UPDATE) Alterações com menor impacto; Redução da largura das chaves; Redução da possibilidade de concorrência em alterações de campos; Composição desnecessária; Simplicidade de JOINs. 201
202 Lab 9.1: Data Types Verifique os planos de execução dos SQL abaixo. CONN SCOTT/TIGER CREATE TABLE T91 (ID VARCHAR(255), NAME VARCHAR(255)); CREATE INDEX T91_IDX ON T91(ID); CREATE INDEX T1_IDX ON T1(ID); INSERT INTO T91 SELECT * FROM T1; COMMIT; SET AUTOTRACE ON SELECT COUNT(*) FROM T1 WHERE ID=1; SELECT COUNT(*) FROM T91 WHERE ID=1; SELECT COUNT(*) FROM T91 WHERE ID='1'; 202
203 Extração de Planos de Execução 203
204 Fontes de Planos de Execução - PLAN_TABLE, carregada por EXPLAIN PLAN / DBMS_XPLAN.DISPLAY ou AUTOTRACE (e SQL Developer, Toad, etc.); - VIEWs de planos compilados e armazenados na Library Cache; - Tabelas de AWR / STATSPACK; - Arquivos Trace (10046, 10053, etc.). 204
205 Explain Plan Sintaxe: EXPLAIN PLAN [SET STATEMENT_ID=id] [INTO table] FOR statement; Exemplo: EXPLAIN PLAN SET STATEMENT_ID='TESTE1' FOR SELECT ENAME FROM EMP; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY); Limitações do Explain Plan: - É o Plano, não a Execução; - Não utiliza Bind Peeking / ACS; - Todas Variáveis Bind são consideradas VARCHAR2; - Depende do ambiente de execução (trigger de logon?). 205
206 Views Dynamic Performance Views: - V$SQL_PLAN - V$SQL_PLAN_STATISTICS - V$SQL_WORKAREA - V$SQL_PLAN_STATISTICS_ALL (V$SQL_PLAN_STATISTICS + V$SQL_WORKAREA) Chave < 10g: ADDRESS, HASH_VALUE, CHILD_HUMBER Chave >= 10g: SQL_ID Exemplo: SELECT STATUS, SQL_ID, SQL_CHILD_NUMBER FROM V$SESSION WHERE USERNAME = 'SCOTT'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('a10jnjwd22gs8', 0)); SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('a10jnjwd22gs8')); 206
207 AWR Tabelas: - STATS$SQL_PLAN (STATSPACK) - DBA_HIST_SQL_PLAN - DBA_HIST_SQLTEXT - DBA_HIST_SQLSTAT - DBA_HIST_SQLBIND Exemplo: SELECT SQL_ID, SQL_TEXT FROM DBA_HIST_SQLTEXT WHERE SQL_TEXT LIKE '%SELECT ENAME FROM EMP%'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_AWR('a10jnjwd22gs8')); Requer Licença Diagnostics Pack 207
208 AWR SQL Enter value for report_type: html Enter value for num_days: 1 Enter value for begin_snap: 40 Enter value for end_snap: 41 Enter value for sql_id: 062savj8zgzut Enter value for report_name: AWR_SQL_01.html SQL Statement (Specific Database
209 Execution Plan CONN SCOTT/TIGER EXEC DBMS_STATS.DELETE_TABLE_STATS('SCOTT','T7'); SELECT /*+ GATHER_PLAN_STATISTICS */ COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'SYNONYM'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT OBJECT_TYPE SELECT OBJECT_TYPE /*+ GATHER_PLAN_STATISTICS */ COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE = 'PACKAGE'; /*+ GATHER_PLAN_STATISTICS */ COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE = 'DIRECTORY';
210 Execution Plan CONN SCOTT/TIGER EXEC DBMS_STATS.DELETE_SCHEMA_STATS(USER); SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10); SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10,20); SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT /*+ GATHER_PLAN_STATISTICS */ EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10); SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT /*+ GATHER_PLAN_STATISTICS */ EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10,20); SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT /*+ GATHER_PLAN_STATISTICS */ EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST'));
211 Execution Plan
212 Execution Plan CONN / AS SYSDBA ALTER SYSTEM SET STATISTICS_LEVEL=ALL; CONN SCOTT/TIGER ALTER SESSION SET STATISTICS_LEVEL=ALL; SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'SYNONYM'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'PACKAGE'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'DIRECTORY'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST'));
213 Execution Plan CONN SCOTT/TIGER COL SQL_TEXT FORMAT A150 SELECT SQl_ID, CHILD_NUMBER, SQL_TEXT FROM V$SQL WHERE SQL_TEXT LIKE '%T7%'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('d43dypzv2mdyz', 0, 'ALLSTATS LAST'));
214 Execution Plan
215 Execution Plan CONN SCOTT/TIGER ALTER SESSION SET OPTIMIZER_DYNAMIC_SAMPLING = 0; EXEC DBMS_STATS.DELETE_TABLE_STATS(USER, 'T7'); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, = 'TABLE'; 'ALLSTATS LAST')); = 'DIRECTORY'; 'ALLSTATS LAST')); = 'SYNONYM'; 'ALLSTATS LAST'));
216 Execution Plan EXEC DBMS_STATS.DELETE_TABLE_STATS(USER, 'T7'); EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'T7', ESTIMATE_PERCENT=>100, METHOD_OPT=>'FOR ALL COLUMNS SIZE 1'); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'TABLE'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'DIRECTORY'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'SYNONYM'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST'));
217 Execution Plan EXEC DBMS_STATS.DELETE_TABLE_STATS(USER, 'T7'); EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'T7', ESTIMATE_PERCENT=>100, METHOD_OPT=> 'FOR ALL COLUMNS SIZE 5'); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'TABLE'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'DIRECTORY'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'SYNONYM'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST'));
218 Execution Plan EXEC DBMS_STATS.DELETE_TABLE_STATS(USER, 'T7'); EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'T7'); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, = 'TABLE'; 'ALLSTATS LAST')); = 'DIRECTORY'; 'ALLSTATS LAST')); = 'SYNONYM'; 'ALLSTATS LAST'));
219 Adaptive Plans
220 Lab 10.1: Adaptive Plans Execute o SQL abaixo duas vezes, comparando o Plano Real de Execução. $ sqlplus OE/OE SELECT o.order_id, v.product_name FROM orders o, ( SELECT order_id, product_name FROM order_items o, product_information p WHERE p.product_id = o.product_id AND list_price < 50 AND min_price < 40 ) v WHERE o.order_id = v.order_id; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'+ALLSTATS')); SELECT o.order_id, v.product_name FROM orders o, ( SELECT order_id, product_name FROM order_items o, product_information p WHERE p.product_id = o.product_id AND list_price < 50 AND min_price < 40 ) v WHERE o.order_id = v.order_id; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'+ALLSTATS')); 220
221 Lab 10.2: Adaptive Plans Verifique a diferença entre os dois Cursores. SELECT CHILD_NUMBER, CPU_TIME, ELAPSED_TIME, BUFFER_GETS FROM V$SQL WHERE SQL_ID = 'gm2npz344xqn8'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('gm2npz344xqn8',0)); SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('gm2npz344xqn8',1)); 221
222 Lab 10.3: Adaptive Plans Execute o SQL abaixo duas vezes, comparando o Plano Real de Execução. $ sqlplus OE/OE EXPLAIN PLAN FOR SELECT product_name FROM order_items o, product_information p WHERE o.unit_price = 15 AND quantity > 1 AND p.product_id = o.product_id; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY); SELECT product_name FROM order_items o, product_information p WHERE o.unit_price = 15 AND quantity > 1 AND p.product_id = o.product_id; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'+ALLSTATS LAST')); SELECT product_name FROM order_items o, product_information p WHERE o.unit_price = 15 AND quantity > 1 AND p.product_id = o.product_id; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'+ALLSTATS LAST +ADAPTIVE')); 222
223 Análise de Planos de Execução 223
224 Análise de Plano 224
225 Análise de Plano - Stand-alone Operations: apenas uma operação filho; - Unrelated-combine Operations: operações filho são executadas de forma independente; AND-EQUAL, BITMAP AND, BITMAP MINUS, CONCATENATION, CONNECT BY WITHOUT FILTERING, HASH JOIN, INTERSECTION, MERGE JOIN, MINUS, MULTI_TABLE INSERT, SQL MODEL, TEMP TABLE TRANSFORMATION, UNION-ALL. - Related-combine Operations: a primeira operação filho é executada apenas uma vez, e controla a execução das outras operações filho, de forma intercalada; NESTED LOOPS, UPDATE, CONNECT BY WITH FILTERING, BITMAP KEY ITERATION; - Blocking Operations (SORT) - Nonblocking Operations (FILTER) 225
226 Stand-alone Operation
227 Stand-alone Operation - STOPKEY
228 Stand-alone Operation - STOPKEY
229 Stand-alone Operation - FILTER
230 Unrelated-combine Operation
231 Related-combine Operation
232 Lab 11.1: Análise de Plano Execute o SQL abaixo e analise seu plano de execução. CONN HR/HR SELECT e.employee_id, j.job_title, e.salary, d.department_name FROM employees e, jobs j, departments d WHERE e.employee_id < 103 AND e.job_id = j.job_id AND e.department_id = d.department_id; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR (NULL, NULL, 'ALLSTATS LAST')); 232
233 Lab 11.2: Análise de Plano Execute o SQL abaixo e analise seu plano de execução. CONN SHSB/SHSB SELECT * FROM (SELECT times.calendar_quarter_desc, customers.cust_first_name, customers.cust_last_name, customers.cust_id, SUM(sales.amount_sold), rank() over(partition BY times.calendar_quarter_desc ORDER BY SUM(amount_sold) DESC) AS rank_within_quarter FROM sales, customers, times WHERE sales.cust_id = customers.cust_id AND times.calendar_quarter_desc = '2002-2' AND times.time_id = sales.time_id GROUP BY customers.cust_id, customers.cust_first_name, customers.cust_last_name, customers.cust_id, times.calendar_quarter_desc) WHERE rank_within_quarter < 16; 233
234 Lab 11.3: Análise de Plano Execute o SQL abaixo e analise seu plano de execução. CONN SHSB/SHSB SELECT channel_desc, calendar_week_number, countries.country_iso_code, TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$ FROM sales, customers, times, channels, countries WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND sales.channel_id= channels.channel_id AND customers.country_id = countries.country_id AND channels.channel_desc IN ('Internet','Partners') AND times.calendar_year = '1998' AND times.calendar_week_number IN ('23','24') AND countries.country_iso_code IN ('ES','FR') GROUP BY CUBE(channel_desc, calendar_week_number, countries.country_iso_code); SELECT channel_desc, calendar_week_number, countries.country_iso_code, TO_CHAR(SUM(amount_sold), '9,999,999,999') SALES$ FROM sales, customers, times, channels, countries WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND sales.channel_id= channels.channel_id AND customers.country_id = countries.country_id AND channels.channel_desc IN ('Internet','Partners') AND times.calendar_year = '2010' AND times.calendar_week_number IN ('37','38') AND countries.country_iso_code IN ('US','ZA') GROUP BY CUBE(channel_desc, calendar_week_number, countries.country_iso_code); 234
235 Lab 11.4: Análise de Plano Execute o SQL abaixo e analise seu plano de execução. CONN SHSB/SHSB SELECT SUM(amount_sold), t.calendar_month_desc, t.calendar_week_number, c.country_name FROM sales s, times t, countries c, customers cu WHERE s.time_id = t.time_id AND t.calendar_month_desc = ' ' AND cu.country_id = c.country_id AND s.cust_id = cu.cust_id AND c.country_iso_code = 'DK' group by t.calendar_month_desc, t.calendar_week_number, c.country_name; 235
236 Lab 11.5: Análise de Plano Execute o SQL abaixo e analise seu plano de execução. CONN SHSB/SHSB SELECT t.time_id, to_char(sum(amount_sold), '9,999,999,999') AS sales, to_char(avg(sum(amount_sold)) over(order BY t.time_id range BETWEEN INTERVAL '2' DAY preceding AND INTERVAL '2' DAY following), '9,999,999,999') AS centered_5_day_avg FROM sales s, times t WHERE t.calendar_month_desc IN(' ',' ',' ',' ') AND s.time_id = t.time_id GROUP BY t.time_id ORDER BY t.time_id; SELECT t.time_id, to_char(sum(amount_sold), '9,999,999,999') AS sales, to_char(avg(sum(amount_sold)) over(order BY t.time_id range BETWEEN INTERVAL '2' DAY preceding AND INTERVAL '2' DAY following), '9,999,999,999') AS centered_5_day_avg FROM sales s, times t WHERE t.calendar_month_desc IN(' ',' ',' ',' ') AND s.time_id = t.time_id GROUP BY t.time_id ORDER BY t.time_id; 236
237 Lab 11.6: Análise de Plano Execute o SQL abaixo e analise seu plano de execução. CONN SHSB/SHSB WITH v AS (SELECT p.prod_name Product_Name, t.calendar_year YEAR, t.calendar_week_number Week, SUM(Amount_Sold) Sales FROM Sales s, Times t, Products p WHERE s.time_id = t.time_id AND s.prod_id = p.prod_id AND p.prod_name IN ('Envoy External Keyboard') and T.CALENDAR_YEAR IN (2003,2004) AND t.calendar_week_number = 21 GROUP BY p.prod_name, t.calendar_year, t.calendar_week_number )
238 Lab 11.7: Análise de Plano... SELECT Product_Name Prod, YEAR, Week, Sales, Weekly_ytd_sales, Weekly_ytd_sales_prior_year FROM (SELECT --Start of year_over_year sales Product_Name, YEAR, Week, Sales, Weekly_ytd_sales, LAG(Weekly_ytd_sales, 1) OVER (PARTITION BY Product_Name, Week ORDER BY YEAR) Weekly_ytd_sales_prior_year FROM
239 Lab 11.8: Análise de Plano... (SELECT -- Start of dense_sales v.product_name Product_Name, t.year YEAR, t.week Week, NVL(v.Sales,0) Sales, SUM(NVL(v.Sales,0)) OVER (PARTITION BY v.product_name, t.year ORDER BY t.week) weekly_ytd_sales FROM v PARTITION BY (v.product_name) RIGHT OUTER JOIN (SELECT DISTINCT Calendar_Week_Number Week, Calendar_Year YEAR FROM Times WHERE Calendar_Year IN (2003,2004) ) t ON (v.week = t.week AND v.year = t.year) ) dense_sales ) year_over_year_sales where year = 2004 AND WEEK = 21 ORDER BY 1,2,3; Execute novamente os SQLs do SHSB e analise os planos, mas com o usuário SHSBP. 239
240 Estabilidade de Plano 240
241 Evolução de Shared SQL - Bind Variable - CURSOR_SHARING - Bind Variable Peeking (9i) - Extended Cursor Sharing / Adaptive Cursor Sharing (11gR1) - Cardinality Feedback (11gR2) - Adaptive Optimizer / Automatic Reoptimization / Adaptive Plan (12cR1) 241
242 Estabilidade do Plano HINTs (Session: _OPTIMIZER_IGNORE_HINTS = TRUE) Parâmetros de Controle do CBO Parâmetros ocultos de Controle do CBO Stored Outlines SQL Profiles (DBA_SQL_PROFILES) SQL Plan Baselines 242
243 Baselines 243
244 Baselines Consulta: DBA_SQL_PLAN_BASELINES Carregar Baselines Automaticamente: ALTER SYSTEM SET OPTIMIZER_CAPTURE_SQL_PLAN_BASELINES=TRUE; ALTER SYSTEM SET OPTIMIZER_USE_SQL_PLAN_BASELINES=TRUE; Carregar Baselines manualmente: EXEC DBMS_SPM.LOAD_PLANS_FROM_CURSOR_CACHE(ATTRIBUTE_NAME=>'SQL TEXT', ATTRIBUTE_VALUE=>'%SELECT ID, NAME FROM T1%') EXEC DBMS_SPM.LOAD_PLANS_FROM_CURSOR_CACHE(SQL_ID=>' ', PLAN_HASH_VALUE=>'ABCDEFGH'); Remover Baselines: EXEC DBMS_SPM.DROP_SQL_PLAN_BASELINE(SQL_HANDLE=>'SYS_SQL_ '); 244
245 Baselines CONN / AS SYSDBA ALTER SYSTEM SET OPTIMIZER_CAPTURE_SQL_PLAN_BASELINES=TRUE; ALTER SYSTEM SET OPTIMIZER_USE_SQL_PLAN_BASELINES=TRUE; FROM CONN SCOTT/TIGER CREATE TABLE T AS SELECT * FROM ALL_OBJECTS; SELECT COUNT(DISTINCT(OWNER)) FROM T; SELECT SQL_TEXT, SQL_HANDLE, PLAN_NAME, ENABLED, ACCEPTED, FIXED DBA_SQL_PLAN_BASELINES; CREATE BITMAP INDEX T_INDEX_01 ON T(OWNER); SELECT COUNT(DISTINCT(OWNER)) FROM T; SELECT SQL_TEXT, SQL_HANDLE, PLAN_NAME, ENABLED, ACCEPTED, FIXED FROM DBA_SQL_PLAN_BASELINES; 245
246 Ferramentas Avançadas 246
247 Lab 12.1: SQLT - Instalação MOS Doc ID : SQLT Diagnostic Tool Execute a instalação do SQLT. $ unzip sqlt.zip $ cd sqlt/install $ sqlplus / AS <ENTER> Nerv2015 <ENTER> Nerv2015 <ENTER> USERS <ENTER> TEMP <ENTER> SCOTT <ENTER> T <ENTER> GRANT GRANT GRANT GRANT GRANT SQLT_USER_ROLE SQLT_USER_ROLE SQLT_USER_ROLE SQLT_USER_ROLE SQLT_USER_ROLE TO TO TO TO TO OE; SH; SHSB; SHSBP; HR; 247
248 Lab 12.2: SQLTXPLAIN - Extração Verifique os SQL_ID dos SQL executados pelos dois SCHEMAS. SELECT SQL_ID, SQL_TEXT FROM V$SQL WHERE PARSING_SCHEMA_NAME = 'SHSB'; SELECT * FROM DBA_HIST_SQLTEXT WHERE SQL_ID IN (SELECT SQL_ID FROM DBA_HIST_SQL_PLAN WHERE OBJECT_OWNER = 'SHSBP'); Extraia o Relatório SQL dos SQL_ID executados pelos dois SCHEMAS. $ sqlplus / AS Extraia o Relatório SQLT dos SQL_ID executados pelos dois SCHEMAS. $ cd sqlt/run $ sqlplus 2jb7w23a4ad72 Nerv2015 <ENTER> $ unzip sqlt_s36985_xtract_grgrdq5ja4a1x.zip $ firefox sqlt_s36985_main.html 248
249 SQLHC MOS Doc ID : SQL Tuning Health-Check Script (SQLHC) Verificações: - CBO Object Statistics - CBO Parameters - CBO System Statistics - CBO Data Dictionary Statistics - CBO Fixed-objects Statistics 249
250 Lab 12.3: SQLHC Extraia o SQLHC dos SQLs analizados pelo SQLT. $ cd /home/oracle $ unzip sqlhc.zip $ cd sqlhc $ sqlplus T 2jb7w23a4ad72 250
251 DBMS_SQLTUNE 251
252 Lab 12.4: DBMS_SQLTUNE Execute o SQL_TUNE nos SQLs analizados pelo SQLT. CONN / AS SYSDBa DECLARE RET_VAL VARCHAR2(4000); BEGIN RET_VAL := DBMS_SQLTUNE.CREATE_TUNING_TASK(SQL_ID => '2hr53jd1gg9u2', SCOPE => DBMS_SQLTUNE.SCOPE_COMPREHENSIVE, TIME_LIMIT => 60, TASK_NAME => 'Portilho Tuning Task', DESCRIPTION => 'Portilho Tuning Task'); END; / EXEC DBMS_SQLTUNE.EXECUTE_TUNING_TASK('Portilho Tuning Task'); FROM SET LONG 9000 SELECT DBMS_SQLTUNE.REPORT_TUNING_TASK('Portilho Tuning Task') FROM DUAL; SELECT DBMS_SQLTUNE.SCRIPT_TUNING_TASK('Portilho Tuning Task') RECOMMENTATION DUAL; Remova o SQL_TUNE executado, após executar a correção. EXEC DBMS_SQLTUNE.DROP_TUNING_TASK('Portilho Tuning Task'); 252
253 Rows x Sets 253

254 Rows x Sets Isto não representa uma tabela! 254
255 Rows x Sets Quais os empregados que passaram a mesma quantidade de anos em cada cargo ocupado? Método procedural: - Listar todos os empregados; - Listas todos os cargos, data inicial e final destes empregados, calculando a quantidade de anos; - Armazenar estes dados em formato temporário; - Para cada empregado, verificar se todos as quantidades de anos são iguais; - Descartar os empregados que não possuem todas as quantidade de anos iguais. Método por conjunto: SELECT EMPLOYEE_ID FROM JOB_HISTORY GROUP BY EMPLOYEE_ID HAVING MIN(ROUND(MONTHS_BETWEEN(START_DATE, END_DATE) / 12,0)) = MAX(ROUND(MONTHS_BETWEEN(START_DATE, END_DATE) / 12,0) 255
256 Rows x Sets Qual a quantidade média de dias entre os pedidos de um cliente? Método procedural: - Liste todos os pedidos do cliente X; - Selecione os pedidos e suas datas; - Para cada pedido, selecione a data do pedido anterior; - Calcule qual a quantidade de dias entre a data do pedido e a data anterior; - Calcule a média destas quantidades. Método por conjunto: SELECT (MAX(TRUNC(ORDER_DATE)) - MIN(TRUNC(ORDER_DATE))) / COUNT(ORDER_ID) FROM ORDERS WHERE CUSTOMER_ID = 102 ; 256
257 Rows x Sets Crie uma tabela com os clientes pequenos, outra com os clientes médios, e outra com os clientes grandes. Método procedural: - Selecionar os clientes que compraram menos de 10000; - Inseri-los na tabela SMALL_CUSTOMERS; - Selecionar os clientes que compraram entre e 99999; - Inseri-los na tabela MEDIUM_CUSTOMERS; - Selecionar os clientes que compraram mais de ; - Inseri-los na tabela LARGE_CUSTOMERS; Método por conjunto: INSERT ALL WHEN SUM_ORDERS < THEN INTO SMALL_CUSTOMERS WHEN SUM_ORDERS >= AND SUM_ORDERS < THEN INTO MEDIUM_CUSTOMERS ELSE INTO LARGE_CUSTOMERS SELECT CUSTOMER_ID, SUM(ORDER_TOTAL) SUM_ORDERS FROM OE.ORDERS GROUP BY CUSTOMER_ID; 257
258 Rows x Sets Altere o bônus para 20% de quem é candidato mas ainda não tem bônus, remova de quem ganha mais de 7.500, e marque como 10% o bônus de quem ainda não é candidato mas recebe menos que Método procedural: - Selecione os empregados que devem receber a alteração de 20%; - Faça a alteração dos empregados que devem receber a alteração de 20%; - Selecione os empregados que devem receber a alteração de 10%; - Faça a alteração dos empregados que devem receber a alteração de 10%; - Selecione os empregados que não devem mais ser candidatos a bônus; - Remova os empregados que não devem mais ser candidatos a bônus. Método por conjunto: MERGE INTO BONUS_DEPT60 B USING (SELECT EMPLOYEE_ID, SALARY, DEPARTMENT_ID FROM EMPLOYEES WHERE DEPARTMENT_ID = 60) E ON (B.EMPLOYEE_ID = E.EMPLOYEE_ID) WHEN MATCHED THEN UPDATE SET BONUS = E.SALARY * 0.2 WHERE B.BONUS = 0 DELETE WHERE (E.SALARY > 7500) WHEN NOT MATCHED THEN INSERT (B.EMPLOYEE_ID, B.BONUS) VALUES (E.EMPLOYEE_ID, E.SALARY * 0.1) WHERE (E.SALARY < 7500); 258
259 Otimizações 259
260 Lab 13.1: Append e Redo Crie uma tabela de testes, e execute uma gravação, com parâmetros diferentes. CONN SCOTT/TIGER CREATE TABLE T131 AS SELECT * FROM ALL_OBJECTS WHERE 1=0; SET AUTOTRACE TRACEONLY INSERT INTO T131 SELECT INSERT INTO T131 SELECT INSERT INTO T131 SELECT STATISTICS * FROM ALL_OBJECTS; * FROM ALL_OBJECTS; * FROM ALL_OBJECTS; INSERT /*+ APPEND */ INTO T131 SELECT * FROM ALL_OBJECTS; INSERT /*+ APPEND */ INTO T131 SELECT * FROM ALL_OBJECTS; O que aconteceu? INSERT /*+ APPEND */ INTO T131 SELECT * FROM ALL_OBJECTS; ALTER TABLE T131 NOLOGGING; INSERT /*+ APPEND */ INTO T131 SELECT * FROM ALL_OBJECTS; INSERT /*+ APPEND */ INTO T131 SELECT * FROM ALL_OBJECTS; INSERT /*+ APPEND */ INTO T131 SELECT * FROM ALL_OBJECTS; Qual a diferença exibida pelo SET AUTOTRACE TRACEONLY STATISTICS? 260
261 Paralelismo Permite Query, DML e DDL. Quantos processos de paralelismo utilizar? Um objeto pode ter Parallel permanente, independente do SQL: ALTER TABLE SCOTT.T PARALLEL 4; O Parallel SQL pode ser utilizado diretamente no SQL: SELECT /*+ PARALLEL(T2 4) */ COUNT(*) FROM T2; SELECT /*+ PARALLEL(T2 4,2) */ COUNT(*) FROM T2; 261
262 Paralelismo Parâmetros: PARALLEL_MIN_SERVERS = Número entre 0 e PARALLEL_MAX_SERVERS. PARALLEL_MAX_SERVERS = De 0 a PARALLEL_MIN_PERCENT = De 0 a 100. PARALLEL_DEGREE_POLICY = MANUAL, LIMITED ou AUTO. PARALLEL_MIN_TIME_THRESHOLD = AUTO Segundos. PARALLEL_ADAPTIVE_MULTI_USER = true ou false. PARALLEL_DEGREE_LIMIT = CPU, IO ou Número. PARALLEL_SERVERS_TARGET = Número entre 0 e PARALLEL_MAX_SERVERS. PARALLEL_THREADS_PER_CPU = Qualquer número. PARALLEL_EXECUTION_MESSAGE_SIZE = De 2148 a PARALLEL_FORCE_LOCAL = true ou false. PARALLEL_INSTANCE_GROUP = Oracle RAC service_name ou group_name. PARALLEL_AUTOMATIC_TUNING: Deprecated. PARALLEL_IO_CAP_ENABLED = Deprecated. 262
263 Paralelismo SELECT SID, SERIAL#, QCSID, QCSERIAL# FROM V$PX_SESSION; SID SERIAL# QCSID QCSERIAL#
264 Lab 13.2: Paralelismo Abra a sessão com o SCOTT com SET TIMING ON. Em seguida, faça o teste do PARALLEL. CONN SCOTT/TIGER CREATE TABLE T132 AS SELECT * FROM ALL_OBJECTS; INSERT INTO T132 SELECT * FROM T132; INSERT INTO T132 SELECT * FROM T132; INSERT INTO T132 SELECT * FROM T132; INSERT INTO T132 SELECT * FROM T132; COMMIT; Repita a operação com PARALLEL, e compare. SET TIMING ON SELECT COUNT(*) FROM T132; SELECT /*+ PARALLEL(T132 4) */ COUNT(*) FROM T132; SELECT /*+ PARALLEL(T132 20) */ COUNT(*) FROM T132; SELECT /*+ PARALLEL(T132 40) */ COUNT(*) FROM T132; Qual a diferença exibida pelo SET TIMING ON? 264
265 Lab 13.3: RESULT_CACHE Execute o teste do RESULT_CACHE. CONN SCOTT/TIGER CREATE TABLE T133 AS SELECT * FROM ALL_OBJECTS; INSERT INTO T133 SELECT * FROM T133; INSERT INTO T133 SELECT * FROM T133; INSERT INTO T133 SELECT * FROM T133; INSERT INTO T133 SELECT * FROM T133; COMMIT; SET TIMING ON SET AUTOTRACE ON SELECT COUNT(*) FROM T133; SELECT COUNT(*) FROM T133; SELECT COUNT(*) FROM T133; SELECT /*+ RESULT_CACHE */ COUNT(*) FROM T133; SELECT /*+ RESULT_CACHE */ COUNT(*) FROM T133; SELECT /*+ RESULT_CACHE */ COUNT(*) FROM T133; DELETE FROM T133 WHERE ROWNUM = 1; SELECT /*+ RESULT_CACHE */ COUNT(*) FROM T133; 265

266 Compression 10g OLAP 11g OLTP 12c InMemory 266
Lendas do Oracle. Ricardo Portilho Proni ricardo@nervinformatica.com.br. TITLE Speaker
 TITLE Speaker Lendas do Oracle Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative Commons Atribuição-SemDerivados 3.0 Brasil. Para ver uma cópia desta
TITLE Speaker Lendas do Oracle Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative Commons Atribuição-SemDerivados 3.0 Brasil. Para ver uma cópia desta
Oracle Tuning SQL. Em Oracle Enterprise Edition 18c (RU ) Em CDB Architecture Em Oracle Enterprise Linux 7.5
 Em CDB Architecture Em Oracle Enterprise Linux 7.5") Oracle Tuning SQL Em Oracle Enterprise Edition 18c (RU 18.3.0.0) Em CDB Architecture Em Oracle Enterprise Linux 7.5 Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a
Oracle Tuning SQL Em Oracle Enterprise Edition 18c (RU 18.3.0.0) Em CDB Architecture Em Oracle Enterprise Linux 7.5 Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a
Oracle Tuning SQL. Em Oracle Enterprise Edition 19c Em CDB Architecture Em Oracle Enterprise Linux 7.6
 Oracle Tuning SQL Em Oracle Enterprise Edition 19c Em CDB Architecture Em Oracle Enterprise Linux 7.6 Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative
Oracle Tuning SQL Em Oracle Enterprise Edition 19c Em CDB Architecture Em Oracle Enterprise Linux 7.6 Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative
Oracle Tuning SQL. Em Oracle Enterprise Edition Em Oracle Enterprise Linux 7.3 Modo Texto Inclui CDB Architecture
 Oracle Tuning SQL Em Oracle Enterprise Edition 12.2.0.1 Em Oracle Enterprise Linux 7.3 Modo Texto Inclui CDB Architecture Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada
Oracle Tuning SQL Em Oracle Enterprise Edition 12.2.0.1 Em Oracle Enterprise Linux 7.3 Modo Texto Inclui CDB Architecture Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada
Oracle. Otimizando Comandos SQL. Ricardo Portilho Proni Nerv Informática
 Oracle Otimizando Comandos SQL Ricardo Portilho Proni ricardo@informatica.com.br Nerv Informática 1 SCHEMAs utilizados Desbloqueie os usuários teste do Oracle Database, e dê as permissões abaixo. ALTER
Oracle Otimizando Comandos SQL Ricardo Portilho Proni ricardo@informatica.com.br Nerv Informática 1 SCHEMAs utilizados Desbloqueie os usuários teste do Oracle Database, e dê as permissões abaixo. ALTER
Estatísticas. Quando coletar? Quanto coletar? Como coletar? Ricardo Portilho Proni Nerv Informática
 Estatísticas Quando coletar? Quanto coletar? Como coletar? Ricardo Portilho Proni ricardo@informatica.com.br Nerv Informática Isenção de responsabilidade Não acredite em tudo o que lê. Por algo estar escrito,
Estatísticas Quando coletar? Quanto coletar? Como coletar? Ricardo Portilho Proni ricardo@informatica.com.br Nerv Informática Isenção de responsabilidade Não acredite em tudo o que lê. Por algo estar escrito,
Comandos de Manipulação
 SQL - Avançado Inserção de dados; Atualização de dados; Remoção de dados; Projeção; Seleção; Junções; Operadores: aritméticos, de comparação,de agregação e lógicos; Outros comandos relacionados. SQL SQL
SQL - Avançado Inserção de dados; Atualização de dados; Remoção de dados; Projeção; Seleção; Junções; Operadores: aritméticos, de comparação,de agregação e lógicos; Outros comandos relacionados. SQL SQL
Banco de Dados Oracle 10g: Introdução à Linguagem SQL
 Oracle University Entre em contato: 0800 891 6502 Banco de Dados Oracle 10g: Introdução à Linguagem SQL Duração: 5 Dias Objetivos do Curso Esta classe se aplica aos usuários do Banco de Dados Oracle8i,
Oracle University Entre em contato: 0800 891 6502 Banco de Dados Oracle 10g: Introdução à Linguagem SQL Duração: 5 Dias Objetivos do Curso Esta classe se aplica aos usuários do Banco de Dados Oracle8i,
ORACLE 11 G INTRODUÇÃO AO ORACLE, SQL,PL/SQL. Carga horária: 32 Horas
 ORACLE 11 G INTRODUÇÃO AO ORACLE, SQL,PL/SQL Carga horária: 32 Horas Pré-requisito: Para que os alunos possam aproveitar este treinamento ao máximo, é importante que eles tenham participado dos treinamentos
ORACLE 11 G INTRODUÇÃO AO ORACLE, SQL,PL/SQL Carga horária: 32 Horas Pré-requisito: Para que os alunos possam aproveitar este treinamento ao máximo, é importante que eles tenham participado dos treinamentos
SQL TGD/JMB 1. Projecto de Bases de Dados. Linguagem SQL
 SQL TGD/JMB 1 Projecto de Bases de Dados Linguagem SQL SQL TGD/JMB 2 O que é o SQL? SQL ("ess-que-el") significa Structured Query Language. É uma linguagem standard (universal) para comunicação com sistemas
SQL TGD/JMB 1 Projecto de Bases de Dados Linguagem SQL SQL TGD/JMB 2 O que é o SQL? SQL ("ess-que-el") significa Structured Query Language. É uma linguagem standard (universal) para comunicação com sistemas
Oracle Zero Downtime Migration (com Golden Gate)
") Oracle Zero Downtime Migration (com Golden Gate) Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative Commons Atribuição-SemDerivados 3.0 Brasil. Para
Oracle Zero Downtime Migration (com Golden Gate) Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative Commons Atribuição-SemDerivados 3.0 Brasil. Para
Introdução à Banco de Dados. Nathalia Sautchuk Patrício
 Introdução à Banco de Dados Nathalia Sautchuk Patrício Histórico Início da computação: dados guardados em arquivos de texto Problemas nesse modelo: redundância não-controlada de dados aplicações devem
Introdução à Banco de Dados Nathalia Sautchuk Patrício Histórico Início da computação: dados guardados em arquivos de texto Problemas nesse modelo: redundância não-controlada de dados aplicações devem
EXEMPLOS DE COMANDOS NO SQL SERVER
 EXEMPLOS DE COMANDOS NO SQL SERVER Gerenciando Tabelas: DDL - DATA DEFINITION LANGUAG Criando uma tabela: CREATE TABLE CLIENTES ID VARCHAR4 NOT NULL, NOME VARCHAR30 NOT NULL, PAGAMENTO DECIMAL4,2 NOT NULL;
EXEMPLOS DE COMANDOS NO SQL SERVER Gerenciando Tabelas: DDL - DATA DEFINITION LANGUAG Criando uma tabela: CREATE TABLE CLIENTES ID VARCHAR4 NOT NULL, NOME VARCHAR30 NOT NULL, PAGAMENTO DECIMAL4,2 NOT NULL;
Um objeto de estatística contém informações de distribuição de valores de uma ou mais colunas de uma tabela ou view indexada
 Desvendando Estatísticas do SQL Server Parte 1 Nesta série de artigos vamos dar um mergulho profundo nas Teorias Probabilísticas (mais conhecido como estatísticas) do SQL Server. Introdução Estatísticas
Desvendando Estatísticas do SQL Server Parte 1 Nesta série de artigos vamos dar um mergulho profundo nas Teorias Probabilísticas (mais conhecido como estatísticas) do SQL Server. Introdução Estatísticas
Banco de Dados. Marcio de Carvalho Victorino www.dominandoti.eng.br. Exercícios SQL
 Banco de Dados Exercícios SQL 1 TRF (ESAF 2006) 32. Analise as seguintes afirmações relacionadas a Bancos de Dados e à linguagem SQL: I. A cláusula GROUP BY do comando SELECT é utilizada para dividir colunas
Banco de Dados Exercícios SQL 1 TRF (ESAF 2006) 32. Analise as seguintes afirmações relacionadas a Bancos de Dados e à linguagem SQL: I. A cláusula GROUP BY do comando SELECT é utilizada para dividir colunas
Quando se seleciona os modos OS ou XML, arquivos são criados com os registros de auditoria, eles se localizam parâmetro audit_file_dest.
 Auditoria é a habilidade do banco de dados Oracle poder gerar logs de auditoria (XML, tabelas, arquivos de SO, ) em atividades suspeitas do usuário, como por exemplo: monitorar o que um determinado usuário
Auditoria é a habilidade do banco de dados Oracle poder gerar logs de auditoria (XML, tabelas, arquivos de SO, ) em atividades suspeitas do usuário, como por exemplo: monitorar o que um determinado usuário
Banco de Dados. Prof. Antonio
 Banco de Dados Prof. Antonio SQL - Structured Query Language O que é SQL? A linguagem SQL (Structure query Language - Linguagem de Consulta Estruturada) é a linguagem padrão ANSI (American National Standards
Banco de Dados Prof. Antonio SQL - Structured Query Language O que é SQL? A linguagem SQL (Structure query Language - Linguagem de Consulta Estruturada) é a linguagem padrão ANSI (American National Standards
Oracle 10g: SQL e PL/SQL
 Oracle 10g: SQL e PL/SQL PL/SQL: Visão Geral Enzo Seraphim Visão Geral Vantagens de PL/SQL Suporte total à linguagem SQL Total integração com o Oracle Performance Redução da comunicação entre a aplicação
Oracle 10g: SQL e PL/SQL PL/SQL: Visão Geral Enzo Seraphim Visão Geral Vantagens de PL/SQL Suporte total à linguagem SQL Total integração com o Oracle Performance Redução da comunicação entre a aplicação
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS. Fábio Roberto Octaviano
 DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Controlando Acesso dos Usuários Após o término do Capítulo: Diferenciar privilégios de sistema e privilégios de objetos.
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Controlando Acesso dos Usuários Após o término do Capítulo: Diferenciar privilégios de sistema e privilégios de objetos.
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS. Fábio Roberto Octaviano
 DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Conceitos da arquitetura Oracle e da Linguagem SQL Recuperar dados por meio de SELECT Criar relatórios de dados classificados
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Conceitos da arquitetura Oracle e da Linguagem SQL Recuperar dados por meio de SELECT Criar relatórios de dados classificados
Oracle9i: Tuning de Aplicações. Oracle9i: Tuning de Aplicações
 Oracle9i: Tuning de Aplicações Oracle9i: Tuning de Aplicações I Oracle9i: Tuning de Aplicações Sumário 1. Seguindo uma Metodologia de Tuning... 1-1 Objetivos...1-2 Visão Geral...1-3 Gerenciando a Performance...1-4
Oracle9i: Tuning de Aplicações Oracle9i: Tuning de Aplicações I Oracle9i: Tuning de Aplicações Sumário 1. Seguindo uma Metodologia de Tuning... 1-1 Objetivos...1-2 Visão Geral...1-3 Gerenciando a Performance...1-4
Ex.: INSERT INTO tmpautor (CDAUTOR, NMAUTOR) VALUES (1, Renato Araújo )
 VALUES (1, Renato Araújo )") PRONATEC - Programador de Sistemas Banco de Dados 1) Incluindo linhas nas tabelas a. Para incluir linhas em tabelas utilize o comando INSERT INTO INSERT INTO tabela [ ( coluna [, coluna,...] ) ] VALUES
PRONATEC - Programador de Sistemas Banco de Dados 1) Incluindo linhas nas tabelas a. Para incluir linhas em tabelas utilize o comando INSERT INTO INSERT INTO tabela [ ( coluna [, coluna,...] ) ] VALUES
SQL Structured Query Language
 Janai Maciel SQL Structured Query Language (Banco de Dados) Conceitos de Linguagens de Programação 2013.2 Structured Query Language ( Linguagem de Consulta Estruturada ) Conceito: É a linguagem de pesquisa
Janai Maciel SQL Structured Query Language (Banco de Dados) Conceitos de Linguagens de Programação 2013.2 Structured Query Language ( Linguagem de Consulta Estruturada ) Conceito: É a linguagem de pesquisa
 FAPLAN - Faculdade Anhanguera Passo Fundo Gestão da Tecnologia da Informação Banco de Dados II Prof. Eder Pazinatto Stored Procedures Procedimento armazenados dentro do banco de dados Um Stored Procedure
FAPLAN - Faculdade Anhanguera Passo Fundo Gestão da Tecnologia da Informação Banco de Dados II Prof. Eder Pazinatto Stored Procedures Procedimento armazenados dentro do banco de dados Um Stored Procedure
Sumário 1 0.1 Introdução 1 0.2 Breve História da Linguagem SQL l 0.3 Características da Linguagem SQL 3 0.4 A Composição deste Livro 3
 ÍNDICE o -INTRODUÇÃO Sumário 1 0.1 Introdução 1 0.2 Breve História da Linguagem SQL l 0.3 Características da Linguagem SQL 3 0.4 A Composição deste Livro 3 0.5 Sistemas Utilizados 6 0.5.1 Access 2003 (Microsoft)
ÍNDICE o -INTRODUÇÃO Sumário 1 0.1 Introdução 1 0.2 Breve História da Linguagem SQL l 0.3 Características da Linguagem SQL 3 0.4 A Composição deste Livro 3 0.5 Sistemas Utilizados 6 0.5.1 Access 2003 (Microsoft)
SQL Linguagem de Definição de Dados. Laboratório de Bases de Dados Profa. Dra. Cristina Dutra de Aguiar Ciferri
 SQL Linguagem de Definição de Dados SQL Structured Query Language Uma das mais importantes linguagens relacionais (se não a mais importante) Exemplos de SGBD que utilizam SQL Oracle Informix Ingress SQL
SQL Linguagem de Definição de Dados SQL Structured Query Language Uma das mais importantes linguagens relacionais (se não a mais importante) Exemplos de SGBD que utilizam SQL Oracle Informix Ingress SQL
Oracle PL/SQL Overview
 Faculdades Network Oracle PL/SQL Overview Prof. Edinelson PL/SQL Linguagem de Programação Procedural Language / Structured Query Language Une o estilo modular de linguagens de programação à versatilidade
Faculdades Network Oracle PL/SQL Overview Prof. Edinelson PL/SQL Linguagem de Programação Procedural Language / Structured Query Language Une o estilo modular de linguagens de programação à versatilidade
Prof. Carlos Majer Aplicações Corporativas UNICID
 Este material pertence a Carlos A. Majer, Professor da Unidade Curricular: Aplicações Corporativas da Universidade Cidade de São Paulo UNICID Licença de Uso Este trabalho está licenciado sob uma Licença
Este material pertence a Carlos A. Majer, Professor da Unidade Curricular: Aplicações Corporativas da Universidade Cidade de São Paulo UNICID Licença de Uso Este trabalho está licenciado sob uma Licença
SQL Linguagem de Manipulação de Dados. Banco de Dados Profa. Dra. Cristina Dutra de Aguiar Ciferri
 SQL Linguagem de Manipulação de Dados Banco de Dados SQL DML SELECT... FROM... WHERE... lista atributos de uma ou mais tabelas de acordo com alguma condição INSERT INTO... insere dados em uma tabela DELETE
SQL Linguagem de Manipulação de Dados Banco de Dados SQL DML SELECT... FROM... WHERE... lista atributos de uma ou mais tabelas de acordo com alguma condição INSERT INTO... insere dados em uma tabela DELETE
Sumário. Capítulo 2 Conceitos Importantes... 32 Tópicos Relevantes... 32 Instance... 33 Base de Dados... 36 Conclusão... 37
 7 Sumário Agradecimentos... 6 Sobre o Autor... 6 Prefácio... 13 Capítulo 1 Instalação e Configuração... 15 Instalação em Linux... 15 Instalação e Customização do Red Hat Advanced Server 2.1... 16 Preparativos
7 Sumário Agradecimentos... 6 Sobre o Autor... 6 Prefácio... 13 Capítulo 1 Instalação e Configuração... 15 Instalação em Linux... 15 Instalação e Customização do Red Hat Advanced Server 2.1... 16 Preparativos
Tuning para Desenvolvedores DB2
 Tuning para Desenvolvedores DB2 Perallis IT Innovation Soluções em Armazenamento de dados www.perallis.com contato@perallis.com +55 19 3203-1002 SOBRE ESTE CURSO PÚBLICO-ALVO O curso Tuning para Desenvolvedores
Tuning para Desenvolvedores DB2 Perallis IT Innovation Soluções em Armazenamento de dados www.perallis.com contato@perallis.com +55 19 3203-1002 SOBRE ESTE CURSO PÚBLICO-ALVO O curso Tuning para Desenvolvedores
AULA 2 INTERAÇÃO COM O BANCO DE DADOS
 AULA 2 INTERAÇÃO COM O BANCO DE DADOS BANCO DE DADOS POSTGRESQL O PostgreSQL é um sistema gerenciador de banco de dados dos mais robustos e avançados do mundo. Seu código é aberto e é totalmente gratuito,
AULA 2 INTERAÇÃO COM O BANCO DE DADOS BANCO DE DADOS POSTGRESQL O PostgreSQL é um sistema gerenciador de banco de dados dos mais robustos e avançados do mundo. Seu código é aberto e é totalmente gratuito,
PostgreSQL Performance
 PostgreSQL Performance André Restivo Faculdade de Engenharia da Universidade do Porto February 24, 2012 André Restivo (FEUP) PostgreSQL Performance February 24, 2012 1 / 45 Sumário 1 Armazenamento 2 Índices
PostgreSQL Performance André Restivo Faculdade de Engenharia da Universidade do Porto February 24, 2012 André Restivo (FEUP) PostgreSQL Performance February 24, 2012 1 / 45 Sumário 1 Armazenamento 2 Índices
BANCO DE DADOS. info 3º ano. Prof. Diemesleno Souza Carvalho diemesleno@iftm.edu.br www.diemesleno.com.br
 BANCO DE DADOS info 3º ano Prof. Diemesleno Souza Carvalho diemesleno@iftm.edu.br www.diemesleno.com.br Na última aula estudamos Unidade 4 - Projeto Lógico Normalização; Dicionário de Dados. Arquitetura
BANCO DE DADOS info 3º ano Prof. Diemesleno Souza Carvalho diemesleno@iftm.edu.br www.diemesleno.com.br Na última aula estudamos Unidade 4 - Projeto Lógico Normalização; Dicionário de Dados. Arquitetura
Linguagem SQL. Comandos Básicos
 Linguagem SQL Comandos Básicos Caetano Traina Júnior Grupo de Bases de Dados e Imagens Instituto de Ciências Matemáticas e de Computação Universidade de São Paulo - São Carlos caetano@icmc.sc.usp.br Comando
Linguagem SQL Comandos Básicos Caetano Traina Júnior Grupo de Bases de Dados e Imagens Instituto de Ciências Matemáticas e de Computação Universidade de São Paulo - São Carlos caetano@icmc.sc.usp.br Comando
BANCO DE DADOS II Prof. Ricardo Rodrigues Barcelar http://www.ricardobarcelar.com
 - Aula 11-1. INTRODUÇÃO TRIGGERS (GATILHOS OU AUTOMATISMOS) Desenvolver uma aplicação para gerenciar os dados significa criar uma aplicação que faça o controle sobre todo ambiente desde a interface, passando
- Aula 11-1. INTRODUÇÃO TRIGGERS (GATILHOS OU AUTOMATISMOS) Desenvolver uma aplicação para gerenciar os dados significa criar uma aplicação que faça o controle sobre todo ambiente desde a interface, passando
SQL CREATE DATABASE. MySQL, SQL Server, Access, Oracle, Sybase, DB2, e outras base de dados utilizam o SQL.
 LINGUAGEM SQL SQL CREATE DATABASE MySQL, SQL Server, Access, Oracle, Sybase, DB2, e outras base de dados utilizam o SQL. SQL CREATE TABLE SQL NOT NULL O valor NOT NULL obriga que o campo contenha sempre
LINGUAGEM SQL SQL CREATE DATABASE MySQL, SQL Server, Access, Oracle, Sybase, DB2, e outras base de dados utilizam o SQL. SQL CREATE TABLE SQL NOT NULL O valor NOT NULL obriga que o campo contenha sempre
Comandos DDL. id_modulo = id_m odulo
 Comandos DDL Estudo de Caso Controle Acadêmico Simplificado Uma escola contém vários cursos, onde cada aluno possui uma matricula num determinado curso. Estes cursos, por sua vez, possuem módulos, aos
Comandos DDL Estudo de Caso Controle Acadêmico Simplificado Uma escola contém vários cursos, onde cada aluno possui uma matricula num determinado curso. Estes cursos, por sua vez, possuem módulos, aos
Formação em Banco de Dados
 Formação em Banco de Dados Sobre a KTEC A KTEC Escola de Tecnologia oferece uma série de cursos, para os que procuram uma base sólida no aprendizado, com foco nas boas práticas que fazem a diferença no
Formação em Banco de Dados Sobre a KTEC A KTEC Escola de Tecnologia oferece uma série de cursos, para os que procuram uma base sólida no aprendizado, com foco nas boas práticas que fazem a diferença no
Extend Statistics Multcolumn Statistics
 Extend Statistics Multcolumn Statistics Extendend Statistics é uma feature do 11g que ajuda o otimizador baseado em custo (CBO) tomar melhores decisões utilizando estatisticas em grupo de colunas, quando
Extend Statistics Multcolumn Statistics Extendend Statistics é uma feature do 11g que ajuda o otimizador baseado em custo (CBO) tomar melhores decisões utilizando estatisticas em grupo de colunas, quando
SQL Gatilhos (Triggers)
") SQL Gatilhos (Triggers) Laboratório de Bases de Dados Gatilho (trigger) Bloco PL/SQL que é disparado de forma automática e implícita sempre que ocorrer um evento associado a uma tabela INSERT UPDATE DELETE
SQL Gatilhos (Triggers) Laboratório de Bases de Dados Gatilho (trigger) Bloco PL/SQL que é disparado de forma automática e implícita sempre que ocorrer um evento associado a uma tabela INSERT UPDATE DELETE
SQL (Structured Query Language)
") (Structured Query Language) I DDL (Definição de Esquemas Relacionais)... 2 I.2 Domínios... 2 I.3 Criação de Tabelas... 2 I.4 Triggers... 4 II DML Linguagem para manipulação de dados... 5 II.2 Comando SELECT...
(Structured Query Language) I DDL (Definição de Esquemas Relacionais)... 2 I.2 Domínios... 2 I.3 Criação de Tabelas... 2 I.4 Triggers... 4 II DML Linguagem para manipulação de dados... 5 II.2 Comando SELECT...
Consistem num conjunto de apontadores para instâncias especificas de cada relação.
 Mecanismo usado para mais fácil e rapidamente aceder à informação existente numa base de dados. Bases de Dados de elevadas dimensões. Consistem num conjunto de apontadores para instâncias especificas de
Mecanismo usado para mais fácil e rapidamente aceder à informação existente numa base de dados. Bases de Dados de elevadas dimensões. Consistem num conjunto de apontadores para instâncias especificas de
FEAP - Faculdade de Estudos Avançados do Pará PROFª LENA VEIGA PROJETOS DE BANCO DE DADOS UNIDADE V- SQL
 Quando os Bancos de Dados Relacionais estavam sendo desenvolvidos, foram criadas linguagens destinadas à sua manipulação. O Departamento de Pesquisas da IBM desenvolveu a SQL como forma de interface para
Quando os Bancos de Dados Relacionais estavam sendo desenvolvidos, foram criadas linguagens destinadas à sua manipulação. O Departamento de Pesquisas da IBM desenvolveu a SQL como forma de interface para
Oracle Advanced Compression x External Tables (Armazenamento de dados históricos)
") Oracle Advanced Compression x External Tables (Armazenamento de dados históricos) Agenda Sobre Rodrigo Mufalani Clico de dados Visão Geral Avanced Compression Visão Geral External Tables Performance Disponibilidade
Oracle Advanced Compression x External Tables (Armazenamento de dados históricos) Agenda Sobre Rodrigo Mufalani Clico de dados Visão Geral Avanced Compression Visão Geral External Tables Performance Disponibilidade
Administração de Banco de Dados
 Administração de Banco de Dados Adriano J. Holanda http://holanda.xyz 28/8/2015 Índices Para os testes com os índices criaremos uma tabela chamada tteste com o comando teste=> CREATE TABLE tteste (id int4);
Administração de Banco de Dados Adriano J. Holanda http://holanda.xyz 28/8/2015 Índices Para os testes com os índices criaremos uma tabela chamada tteste com o comando teste=> CREATE TABLE tteste (id int4);
Formação em Banco de Dados. Subtítulo
 Formação em Banco de Dados Subtítulo Sobre a APTECH A Aptech é uma instituição global, modelo em capacitação profissional, que dispõe de diversos cursos com objetivo de preparar seus alunos para carreiras
Formação em Banco de Dados Subtítulo Sobre a APTECH A Aptech é uma instituição global, modelo em capacitação profissional, que dispõe de diversos cursos com objetivo de preparar seus alunos para carreiras
Escrito por Sex, 14 de Outubro de 2011 23:12 - Última atualização Seg, 26 de Março de 2012 03:33
 Preço R$ 129.00 Compre aqui SUPER PACOTÃO 3 EM 1: 186 Vídeoaulas - 3 dvd's - 10.5 Gybabyte. 1) SQL 2) Banco de Dados (Oracle 10g, SQL Server 2005, PostgreSQL 8.2, Firebird 2.0, MySQL5.0) 3) Análise e Modelagem
Preço R$ 129.00 Compre aqui SUPER PACOTÃO 3 EM 1: 186 Vídeoaulas - 3 dvd's - 10.5 Gybabyte. 1) SQL 2) Banco de Dados (Oracle 10g, SQL Server 2005, PostgreSQL 8.2, Firebird 2.0, MySQL5.0) 3) Análise e Modelagem
Linguagem de Consulta Estruturada SQL- DML
 Linguagem de Consulta Estruturada SQL- DML INTRODUÇÃO A SQL - Structured Query Language, foi desenvolvido pela IBM em meados dos anos 70 como uma linguagem de manipulação de dados (DML - Data Manipulation
Linguagem de Consulta Estruturada SQL- DML INTRODUÇÃO A SQL - Structured Query Language, foi desenvolvido pela IBM em meados dos anos 70 como uma linguagem de manipulação de dados (DML - Data Manipulation
EXERCÍCIOS PRÁTICOS. Banco de Dados
 EXERCÍCIOS PRÁTICOS Banco de Dados Introdução ao uso do SQL Structured Query Language, considerando tanto DDL Data Definition Language quanto DML Data Manipulation Language. Banco de Dados selecionado:
EXERCÍCIOS PRÁTICOS Banco de Dados Introdução ao uso do SQL Structured Query Language, considerando tanto DDL Data Definition Language quanto DML Data Manipulation Language. Banco de Dados selecionado:
Crash recovery é similar ao instance recovery, onde o primeiro referencia ambientes de instância exclusiva e o segundo ambientes parallel server.
 Recover no Oracle O backup e recuperação de dados em um SGBD é de grande importância para a manutenção dos dados. Dando continuidade a nossos artigos, apresentamos abaixo formas diferentes de se fazer
Recover no Oracle O backup e recuperação de dados em um SGBD é de grande importância para a manutenção dos dados. Dando continuidade a nossos artigos, apresentamos abaixo formas diferentes de se fazer
BANCO DE DADOS Parte 4
 BANCO DE DADOS Parte 4 A Linguagem SQL Introdução Desenvolvida pelo depto de pesquisa da IBM na década de 1970 (System R) Linguagem padrão de BD Relacionais; Apresenta várias padrões evolutivos: SQL86,
BANCO DE DADOS Parte 4 A Linguagem SQL Introdução Desenvolvida pelo depto de pesquisa da IBM na década de 1970 (System R) Linguagem padrão de BD Relacionais; Apresenta várias padrões evolutivos: SQL86,
AULA 2 INTERAÇÃO COM O BANCO DE DADOS
 AULA 2 INTERAÇÃO COM O BANCO DE DADOS BANCO DE DADOS POSTGRESQL O PostgreSQL é um sistema gerenciador de banco de dados dos mais robustos e avançados do mundo. Seu código é aberto e é totalmente gratuito,
AULA 2 INTERAÇÃO COM O BANCO DE DADOS BANCO DE DADOS POSTGRESQL O PostgreSQL é um sistema gerenciador de banco de dados dos mais robustos e avançados do mundo. Seu código é aberto e é totalmente gratuito,
COMPETÊNCIAS ESPECÍFICAS Compreender e utilizar a linguagem SQL, na construção e manutenção de uma base de dados.
 PLANIFICAÇÃO DA DISCIPLINA DE SISTEMAS DE INFORMAÇÃO 12.ºH CURSO PROFISSIONAL DE TÉCNICO MULTIMÉDIA ANO LECTIVO 2013/2014 6. LINGUAGENS DE PROGRAMAÇÃO IV Pré-requisitos: - Planificar e estruturar bases
PLANIFICAÇÃO DA DISCIPLINA DE SISTEMAS DE INFORMAÇÃO 12.ºH CURSO PROFISSIONAL DE TÉCNICO MULTIMÉDIA ANO LECTIVO 2013/2014 6. LINGUAGENS DE PROGRAMAÇÃO IV Pré-requisitos: - Planificar e estruturar bases
Oracle Tuning Índices
 Oracle Tuning Índices Em Oracle Enterprise Edition 18c (RU 18.3.0.0) Em CDB Architecture Em Oracle Enterprise Linux 7.5 Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob
Oracle Tuning Índices Em Oracle Enterprise Edition 18c (RU 18.3.0.0) Em CDB Architecture Em Oracle Enterprise Linux 7.5 Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob
PHP INTEGRAÇÃO COM MYSQL PARTE 1
 INTRODUÇÃO PHP INTEGRAÇÃO COM MYSQL PARTE 1 Leonardo Pereira leonardo@estudandoti.com.br Facebook: leongamerti http://www.estudandoti.com.br Informações que precisam ser manipuladas com mais segurança
INTRODUÇÃO PHP INTEGRAÇÃO COM MYSQL PARTE 1 Leonardo Pereira leonardo@estudandoti.com.br Facebook: leongamerti http://www.estudandoti.com.br Informações que precisam ser manipuladas com mais segurança
MySQL para DBAs Oracle
 MySQL para DBAs Oracle Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative Commons Atribuição-SemDerivados 3.0 Brasil. Para ver uma cópia desta licença,
MySQL para DBAs Oracle Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative Commons Atribuição-SemDerivados 3.0 Brasil. Para ver uma cópia desta licença,
Treinamento sobre SQL
 Treinamento sobre SQL Como Usar o SQL Os dois programas que você mais utilizara no SQL Server são: Enterprise Manager e Query Analyzer. No Enterprise Manager, você pode visualizar e fazer alterações na
Treinamento sobre SQL Como Usar o SQL Os dois programas que você mais utilizara no SQL Server são: Enterprise Manager e Query Analyzer. No Enterprise Manager, você pode visualizar e fazer alterações na
SQL Server Triggers Aprenda a utilizar triggers em views e auditar as colunas atualizadas em uma tabela
 SQL Server Triggers Aprenda a utilizar triggers em views e auditar as colunas atualizadas em uma tabela Certamente você já ouviu falar muito sobre triggers. Mas o quê são triggers? Quando e como utilizá-las?
SQL Server Triggers Aprenda a utilizar triggers em views e auditar as colunas atualizadas em uma tabela Certamente você já ouviu falar muito sobre triggers. Mas o quê são triggers? Quando e como utilizá-las?
BANCO DE DADOS: SQL. Edson Anibal de Macedo Reis Batista. 27 de janeiro de 2010
 BANCO DE DADOS: SQL UERN - Universidade do Estado do Rio Grande do Norte. Departamento de Ciências da Computação. 27 de janeiro de 2010 índice 1 Introdução 2 3 Introdução SQL - Structured Query Language
BANCO DE DADOS: SQL UERN - Universidade do Estado do Rio Grande do Norte. Departamento de Ciências da Computação. 27 de janeiro de 2010 índice 1 Introdução 2 3 Introdução SQL - Structured Query Language
Oracle Performance Diagnostics & Tuning Ricardo Portilho Proni
 Oracle Performance Diagnostics & Tuning Ricardo Portilho Proni Mitificação Métodos antigos o o o o o o Experiência Intuição Imprecisão Tempo Sorte Recursos Top Tuning Verificar maior consumidor de CPU
Oracle Performance Diagnostics & Tuning Ricardo Portilho Proni Mitificação Métodos antigos o o o o o o Experiência Intuição Imprecisão Tempo Sorte Recursos Top Tuning Verificar maior consumidor de CPU
Controle de transações em SQL
 Transações Controle de transações em SQL Uma transação é implicitamente iniciada quando ocorre uma operação que modifica o banco de dados (INSERT, UPDATE ou DELETE). Uma transação pode terminar normalmente
Transações Controle de transações em SQL Uma transação é implicitamente iniciada quando ocorre uma operação que modifica o banco de dados (INSERT, UPDATE ou DELETE). Uma transação pode terminar normalmente
Novidades Oracle 11g. Rio Grande Energia - RGE
 Novidades Oracle 11g Daniel Güths Rio Grande Energia - RGE 1 Agenda Oracle Database 11g new features SQL e PL/SQL new features Performance e gerenciamento de recursos Gerenciamento de mudanças Gerenciamento
Novidades Oracle 11g Daniel Güths Rio Grande Energia - RGE 1 Agenda Oracle Database 11g new features SQL e PL/SQL new features Performance e gerenciamento de recursos Gerenciamento de mudanças Gerenciamento
SQL BÁSICO. Introdução. Prof. Suelane Garcia. Linguagem SQL (Structured Query Language)
") SQL BÁSICO Prof. Suelane Garcia Introdução 2 Linguagem SQL (Structured Query Language) Linguagem de Consulta Estruturada padrão para acesso a Banco de Dados. Usada em inúmeros Sistemas de Gerenciamento
SQL BÁSICO Prof. Suelane Garcia Introdução 2 Linguagem SQL (Structured Query Language) Linguagem de Consulta Estruturada padrão para acesso a Banco de Dados. Usada em inúmeros Sistemas de Gerenciamento
Transações Seguras em Bancos de Dados (MySQL)
") Transações Seguras em Bancos de Dados (MySQL) Índice Entendendo os storage engines do MySQL 5 1 As ferramentas 1 Mais algumas coisas que você deve saber 1 Com a mão na massa 2 Mais ferramentas Usando o
Transações Seguras em Bancos de Dados (MySQL) Índice Entendendo os storage engines do MySQL 5 1 As ferramentas 1 Mais algumas coisas que você deve saber 1 Com a mão na massa 2 Mais ferramentas Usando o
CURSO DE EXTENSÃO ON-LINE EM Oracle 10g Express Edition XE nível básico. Edital de seleção
 CURSO DE EXTENSÃO ON-LINE EM Oracle 10g Express Edition XE nível básico Edital de seleção Nome: Oracle 10g Express Edition XE nível básico Coordenador Geral: Profº Mestre Luis Naito Mendes Bezerra Área
CURSO DE EXTENSÃO ON-LINE EM Oracle 10g Express Edition XE nível básico Edital de seleção Nome: Oracle 10g Express Edition XE nível básico Coordenador Geral: Profº Mestre Luis Naito Mendes Bezerra Área
In-Memory Database Internals DPB304
 In-Memory Database Internals DPB304 In-Memory Database Internals Alberto Lima Senior Premier Field Engineer-SQL Server allima@microsoft.com Frederico Guimarães Santos Premier Field Engineer SQL Server
In-Memory Database Internals DPB304 In-Memory Database Internals Alberto Lima Senior Premier Field Engineer-SQL Server allima@microsoft.com Frederico Guimarães Santos Premier Field Engineer SQL Server
Structured Query Language (SQL)
") SQL Histórico Structured Query Language (SQL) Foi desenvolvido pela IBM em meados dos anos 70 como uma linguagem de manipulação de dados (DML - Data Manipulation Language) para suas primeiras tentativas
SQL Histórico Structured Query Language (SQL) Foi desenvolvido pela IBM em meados dos anos 70 como uma linguagem de manipulação de dados (DML - Data Manipulation Language) para suas primeiras tentativas
Projeto de Banco de Dados: Empresa X
 Projeto de Banco de Dados: Empresa X Modelo de negócio: Empresa X Competências: Analisar e aplicar o resultado da modelagem de dados; Habilidades: Implementar as estruturas modeladas usando banco de dados;
Projeto de Banco de Dados: Empresa X Modelo de negócio: Empresa X Competências: Analisar e aplicar o resultado da modelagem de dados; Habilidades: Implementar as estruturas modeladas usando banco de dados;
Introdução à linguagem SQL
 Introdução à linguagem SQL 1 Histórico A linguagem de consulta estruturada (SQL - Structured Query Language) foi desenvolvida pela empresa IBM, no final dos anos 70. O primeiro banco de dados comercial
Introdução à linguagem SQL 1 Histórico A linguagem de consulta estruturada (SQL - Structured Query Language) foi desenvolvida pela empresa IBM, no final dos anos 70. O primeiro banco de dados comercial
Bases de Dados 2005/2006. Aula 5
 Bases de Dados 2005/2006 Aula 5 Sumário -1. (T.P.C.) Indique diferenças entre uma tabela e uma relação. 0. A base de dados Projecto 1. SQL Join (variantes) a. Cross Join b. Equi-Join c. Natural Join d.
Bases de Dados 2005/2006 Aula 5 Sumário -1. (T.P.C.) Indique diferenças entre uma tabela e uma relação. 0. A base de dados Projecto 1. SQL Join (variantes) a. Cross Join b. Equi-Join c. Natural Join d.
Treinamento PostgreSQL - Aula 03
 Treinamento PostgreSQL - Aula 03 Eduardo Ferreira dos Santos SparkGroup Treinamento e Capacitação em Tecnologia eduardo.edusantos@gmail.com eduardosan.com 29 de Maio de 2013 Eduardo Ferreira dos Santos
Treinamento PostgreSQL - Aula 03 Eduardo Ferreira dos Santos SparkGroup Treinamento e Capacitação em Tecnologia eduardo.edusantos@gmail.com eduardosan.com 29 de Maio de 2013 Eduardo Ferreira dos Santos
SQL - Structured Query Language, ou Linguagem de Consulta Estruturada ou SQL
 SQL - Structured Query Language, ou Linguagem de Consulta Estruturada ou SQL Criar uma base de dados (criar um banco de dados) No mysql: create database locadora; No postgresql: createdb locadora Criar
SQL - Structured Query Language, ou Linguagem de Consulta Estruturada ou SQL Criar uma base de dados (criar um banco de dados) No mysql: create database locadora; No postgresql: createdb locadora Criar
Operação de União JOIN
 Operação de União JOIN Professor Victor Sotero SGD 1 JOIN O join é uma operação de multi-tabelas Select: o nome da coluna deve ser precedido pelo nome da tabela, se mais de uma coluna na tabela especificada
Operação de União JOIN Professor Victor Sotero SGD 1 JOIN O join é uma operação de multi-tabelas Select: o nome da coluna deve ser precedido pelo nome da tabela, se mais de uma coluna na tabela especificada
Pontifícia Universidade Católica do Rio Grande do Sul FACULDADE DE INFORMÁTICA PROGRAMA DE PÓS-GRADUAÇÃO EM CIÊNCIA DA COMPUTAÇÃO.
 Pontifícia Universidade Católica do Rio Grande do Sul FACULDADE DE INFORMÁTICA PROGRAMA DE PÓS-GRADUAÇÃO EM CIÊNCIA DA COMPUTAÇÃO Curso Oracle 10g Prof. MSc. Luciano Blomberg lblomberg@uol.com.br 2011/1
Pontifícia Universidade Católica do Rio Grande do Sul FACULDADE DE INFORMÁTICA PROGRAMA DE PÓS-GRADUAÇÃO EM CIÊNCIA DA COMPUTAÇÃO Curso Oracle 10g Prof. MSc. Luciano Blomberg lblomberg@uol.com.br 2011/1
Básico da Linguagem SQL. Definição de Esquemas em SQL. SQL(Structured Query Language)
") Básico da Linguagem SQL Definição de Esquemas em SQL SQL(Structured Query Language) Desenvolvida como a linguagem de consulta do protótipo de SGBD Sistema R (IBM, 1976). Adotada como linguagem padrão de
Básico da Linguagem SQL Definição de Esquemas em SQL SQL(Structured Query Language) Desenvolvida como a linguagem de consulta do protótipo de SGBD Sistema R (IBM, 1976). Adotada como linguagem padrão de
SQL comando SELECT. SELECT [DISTINCT] <campos> FROM <tabela> [condição] [ ; ] Paulo Damico - MDK Informática Ltda.
![SQL comando SELECT. SELECT [DISTINCT] <campos> FROM <tabela> [condição] [ ; ] Paulo Damico - MDK Informática Ltda.](/thumbs/24/3147194.jpg "SQL comando SELECT. SELECT [DISTINCT] <campos> FROM <tabela> [condição] [ ; ] Paulo Damico - MDK Informática Ltda.") SQL comando SELECT Uma das tarefas mais requisitadas em qualquer banco de dados é obter uma listagem de registros armazenados. Estas tarefas são executadas pelo comando SELECT Sintaxe: SELECT [DISTINCT]
SQL comando SELECT Uma das tarefas mais requisitadas em qualquer banco de dados é obter uma listagem de registros armazenados. Estas tarefas são executadas pelo comando SELECT Sintaxe: SELECT [DISTINCT]
IF685 Gerenciamento de Dados e Informação - Prof. Robson Fidalgo 1
 IF685 Gerenciamento de Dados e Informação - Prof. Robson Fidalgo 1 Banco de Dados Fundamentos de SQL Structured Query Language Aula2 Apresentado por: Robson do Nascimento Fidalgo rdnf@cin.ufpe.br IF685
IF685 Gerenciamento de Dados e Informação - Prof. Robson Fidalgo 1 Banco de Dados Fundamentos de SQL Structured Query Language Aula2 Apresentado por: Robson do Nascimento Fidalgo rdnf@cin.ufpe.br IF685
CIÊNCIA E TECNOLOGIA DO RIO
 INSTITUTO FEDERAL DE EDUCAÇÃO, CIÊNCIA E TECNOLOGIA DO RIO GRANDE DO NORTE BANCO DE DADOS II Docente: Éberton da Silva Marinho e-mail: ebertonsm@gmail.com eberton.marinho@ifrn.edu.br Curso de Tecnologia
INSTITUTO FEDERAL DE EDUCAÇÃO, CIÊNCIA E TECNOLOGIA DO RIO GRANDE DO NORTE BANCO DE DADOS II Docente: Éberton da Silva Marinho e-mail: ebertonsm@gmail.com eberton.marinho@ifrn.edu.br Curso de Tecnologia
APOSTILA BANCO DE DADOS INTRODUÇÃO A LINGUAGEM SQL
 1. O que é Linguagem SQL 2. Instrução CREATE 3. CONSTRAINT 4. ALTER TABLE 5. RENAME TABLE 6. TRUCANTE TABLE 7. DROP TABLE 8. DROP DATABASE 1 1. O que é Linguagem SQL 2. O SQL (Structured Query Language)
1. O que é Linguagem SQL 2. Instrução CREATE 3. CONSTRAINT 4. ALTER TABLE 5. RENAME TABLE 6. TRUCANTE TABLE 7. DROP TABLE 8. DROP DATABASE 1 1. O que é Linguagem SQL 2. O SQL (Structured Query Language)
SQL. Hélder Antero Amaral Nunes
 SQL Hélder Antero Amaral Nunes 2 Introdução Desenvolvida pelo departamento de pesquisa da IBM na década de 1970 (System R); Linguagem padrão de BD Relacionais; Apresenta várias padrões evolutivos: SQL86,
SQL Hélder Antero Amaral Nunes 2 Introdução Desenvolvida pelo departamento de pesquisa da IBM na década de 1970 (System R); Linguagem padrão de BD Relacionais; Apresenta várias padrões evolutivos: SQL86,
Manter estatísticas atualizadas é uma das regras de ouro na busca por performance.
 Atualização de Estatísticas Um objeto de estatística pode ser atualizado manualmente pelo usuário, através dos comandos SP_UPDATESTATS e/ou UPDATE STATISTICS. Enquanto que a procedure SP_UPDATESTATS atualiza
Atualização de Estatísticas Um objeto de estatística pode ser atualizado manualmente pelo usuário, através dos comandos SP_UPDATESTATS e/ou UPDATE STATISTICS. Enquanto que a procedure SP_UPDATESTATS atualiza
Banco de Dados - Senado
 Banco de Dados - Senado Structured Query Language (SQL) Material preparado :Prof. Marcio Vitorino Ambiente Simplificado de um SGBD 2 Características dos SGBDs Natureza auto-contida de um sistema de banco
Banco de Dados - Senado Structured Query Language (SQL) Material preparado :Prof. Marcio Vitorino Ambiente Simplificado de um SGBD 2 Características dos SGBDs Natureza auto-contida de um sistema de banco
Banco de Dados. Conversão para o Banco de Dados SisMoura
 Banco de Dados Conversão para o Banco de Dados SisMoura Objetivo : Converter as informações contidas em um determinado banco de dados para o banco de dados do Sismoura. Restaurar Banco de Dados em branco
Banco de Dados Conversão para o Banco de Dados SisMoura Objetivo : Converter as informações contidas em um determinado banco de dados para o banco de dados do Sismoura. Restaurar Banco de Dados em branco
 Triggers e mais... Instituto Militar de Engenharia IME 1o. Semestre/2005 Triggers Propósito mais amplo que restrições Restrições onde se explicita o evento Regras event-condition-action (ECA) Eventos:
Triggers e mais... Instituto Militar de Engenharia IME 1o. Semestre/2005 Triggers Propósito mais amplo que restrições Restrições onde se explicita o evento Regras event-condition-action (ECA) Eventos:
3) Palavra-chave distinct (select-from). Obter apenas os pibs distintos entre si.
 Palavra-chave distinct (select-from). Obter apenas os pibs distintos entre si.") NOME: BRUNO BRUNELI BANCO DE DADOS - ADS create database ProducaoMinerais use ProducaoMinerais create table Mineral( nome varchar(15) primary key, preco real) create table Pais( nome varchar(30) primary
NOME: BRUNO BRUNELI BANCO DE DADOS - ADS create database ProducaoMinerais use ProducaoMinerais create table Mineral( nome varchar(15) primary key, preco real) create table Pais( nome varchar(30) primary
Laboratório de Banco de Dados II Aula 04. Prof. Érick de Souza Carvalho
 Laboratório de Banco de Dados II Aula 04 Prof. Érick de Souza Carvalho 1 SQL (Structured Query Language ) Prof. Érick de Souza Carvalho 2 SQL Structured Query Language - Introdução É uma Linguagem para
Laboratório de Banco de Dados II Aula 04 Prof. Érick de Souza Carvalho 1 SQL (Structured Query Language ) Prof. Érick de Souza Carvalho 2 SQL Structured Query Language - Introdução É uma Linguagem para
SQL Linguagem de Definição de Dados. Banco de Dados Profa. Dra. Cristina Dutra de Aguiar Ciferri
 SQL Linguagem de Definição de Dados Banco de Dados SQL Structured Query Language Uma das mais importantes linguagens relacionais (se não a mais importante) Exemplos de SGBD que utilizam SQL Oracle Informix
SQL Linguagem de Definição de Dados Banco de Dados SQL Structured Query Language Uma das mais importantes linguagens relacionais (se não a mais importante) Exemplos de SGBD que utilizam SQL Oracle Informix
ADMINISTRAÇÃO DE BANCO DE DADOS
 ADMINISTRAÇÃO DE BANCO DE DADOS ARTEFATO 02 AT02 Diversos I 1 Indice ESQUEMAS NO BANCO DE DADOS... 3 CRIANDO SCHEMA... 3 CRIANDO TABELA EM DETERMINADO ESQUEMA... 4 NOÇÕES BÁSICAS SOBRE CRIAÇÃO E MODIFICAÇÃO
ADMINISTRAÇÃO DE BANCO DE DADOS ARTEFATO 02 AT02 Diversos I 1 Indice ESQUEMAS NO BANCO DE DADOS... 3 CRIANDO SCHEMA... 3 CRIANDO TABELA EM DETERMINADO ESQUEMA... 4 NOÇÕES BÁSICAS SOBRE CRIAÇÃO E MODIFICAÇÃO
Banco de Dados I. Aula 12 - Prof. Bruno Moreno 04/10/2011
 Banco de Dados I Aula 12 - Prof. Bruno Moreno 04/10/2011 Plano de Aula SQL Definição Histórico SQL e sublinguagens Definição de dados (DDL) CREATE Restrições básicas em SQL ALTER DROP 08:20 Definição de
Banco de Dados I Aula 12 - Prof. Bruno Moreno 04/10/2011 Plano de Aula SQL Definição Histórico SQL e sublinguagens Definição de dados (DDL) CREATE Restrições básicas em SQL ALTER DROP 08:20 Definição de
PROGRAMA. Aquisição dos conceitos teóricos mais importantes sobre bases de dados contextualizados à luz de exemplos da sua aplicação no mundo real.
 PROGRAMA ANO LECTIVO: 2005/2006 CURSO: LICENCIATURA BI-ETÁPICA EM INFORMÁTICA ANO: 2.º DISCIPLINA: BASE DE DADOS DOCENTE RESPONSÁVEL PELA REGÊNCIA: Licenciado Lino Oliveira Objectivos Gerais: Aquisição
PROGRAMA ANO LECTIVO: 2005/2006 CURSO: LICENCIATURA BI-ETÁPICA EM INFORMÁTICA ANO: 2.º DISCIPLINA: BASE DE DADOS DOCENTE RESPONSÁVEL PELA REGÊNCIA: Licenciado Lino Oliveira Objectivos Gerais: Aquisição
Aplicações - SQL. Banco de Dados: Teoria e Prática. André Santanchè e Luiz Celso Gomes Jr Instituto de Computação UNICAMP Agosto de 2013
 Aplicações - SQL Banco de Dados: Teoria e Prática André Santanchè e Luiz Celso Gomes Jr Instituto de Computação UNICAMP Agosto de 2013 Picture by Steve Kelley 2008 SQL SQL Structured Query Language Originalmente:
Aplicações - SQL Banco de Dados: Teoria e Prática André Santanchè e Luiz Celso Gomes Jr Instituto de Computação UNICAMP Agosto de 2013 Picture by Steve Kelley 2008 SQL SQL Structured Query Language Originalmente:
Criando Banco de Dados, Tabelas e Campos através do HeidiSQL. Prof. Vitor H. Migoto de Gouvêa Colégio IDESA 2011
 Criando Banco de Dados, Tabelas e Campos através do HeidiSQL Prof. Vitor H. Migoto de Gouvêa Colégio IDESA 2011 Edição 2 Pedreiros da Informação Criando Banco de Dados, Tabelas e Campos através do HeidiSQL
Criando Banco de Dados, Tabelas e Campos através do HeidiSQL Prof. Vitor H. Migoto de Gouvêa Colégio IDESA 2011 Edição 2 Pedreiros da Informação Criando Banco de Dados, Tabelas e Campos através do HeidiSQL
DML. SQL (Select) Verificando estrutura da tabela
 Verificando estrutura da tabela") SISTEMAS DE INFORMAÇÃO BANCO DE DADOS 2 SQL (Select) PROF: EDSON THIZON DML É a parte mais ampla da SQL. Permite pesquisar, alterar, incluir e deletar dados da base de dados. São quatro as sentenças mais
SISTEMAS DE INFORMAÇÃO BANCO DE DADOS 2 SQL (Select) PROF: EDSON THIZON DML É a parte mais ampla da SQL. Permite pesquisar, alterar, incluir e deletar dados da base de dados. São quatro as sentenças mais
SQL Introdução ao Oracle
 SQL Introdução ao Oracle Estagiários: Daniel Feitosa e Jaqueline J. Brito Sumário Modelo de armazenamento de dados Modelo físico Modelo lógico Utilizando o SQL Developer Consulta de Sintaxe Sumário Modelo
SQL Introdução ao Oracle Estagiários: Daniel Feitosa e Jaqueline J. Brito Sumário Modelo de armazenamento de dados Modelo físico Modelo lógico Utilizando o SQL Developer Consulta de Sintaxe Sumário Modelo
Histórico de revisões
 Apostila 3 Histórico de revisões Data Versão Descrição Autor 30/09/2011 1.0 Criação da primeira versão HEngholmJr CONTEÚDO Exclusão de registros Consultas por Dados de Resumo Group by / Having Funções
Apostila 3 Histórico de revisões Data Versão Descrição Autor 30/09/2011 1.0 Criação da primeira versão HEngholmJr CONTEÚDO Exclusão de registros Consultas por Dados de Resumo Group by / Having Funções
SQL e PL/SQL Oracle Dicas de preparação para certificação
 - 1 - SQL e PL/SQL Oracle Dicas de preparação para certificação Selection: para escolher linhas em uma tabela Projection: para escolher colunas em uma tabela Join: pode trazer simultaneamente dados que
- 1 - SQL e PL/SQL Oracle Dicas de preparação para certificação Selection: para escolher linhas em uma tabela Projection: para escolher colunas em uma tabela Join: pode trazer simultaneamente dados que
BANCO DE DADOS II LINGUAGEM SQL - STRUCTURED QUERY LANGUAGE. Prof.: Elvis Bloemer Meurer
 BANCO DE DADOS II LINGUAGEM SQL - STRUCTURED QUERY LANGUAGE Prof.: Elvis Bloemer Meurer ORLEANS, 2011 1 CAPITULO 6: FUNÇÕES DE GRUPO...4 6.1 OBJETIVOS DESTE CAPÍTULO...4 6.2 FUNÇÕES DISPONÍVEIS...4 6.3
BANCO DE DADOS II LINGUAGEM SQL - STRUCTURED QUERY LANGUAGE Prof.: Elvis Bloemer Meurer ORLEANS, 2011 1 CAPITULO 6: FUNÇÕES DE GRUPO...4 6.1 OBJETIVOS DESTE CAPÍTULO...4 6.2 FUNÇÕES DISPONÍVEIS...4 6.3
BANCO DE DADOS -INTRODUÇÃO AO SQL. Prof. Angelo Augusto Frozza, M.Sc. frozza@ifc-camboriu.edu.br
 BANCO DE DADOS -INTRODUÇÃO AO SQL Prof. Angelo Augusto Frozza, M.Sc. frozza@ifc-camboriu.edu.br Os comandos SQL podem ser agrupados em 3 classes: DDL Data Definition Language Comandos para a Definição
BANCO DE DADOS -INTRODUÇÃO AO SQL Prof. Angelo Augusto Frozza, M.Sc. frozza@ifc-camboriu.edu.br Os comandos SQL podem ser agrupados em 3 classes: DDL Data Definition Language Comandos para a Definição