Oracle. Otimizando Comandos SQL. Ricardo Portilho Proni Nerv Informática
|
|
|
- Natália Raminhos Benevides
- 6 Há anos
- Visualizações:
Transcrição

1 Oracle Otimizando Comandos SQL Ricardo Portilho Proni Nerv Informática 1
2 SCHEMAs utilizados Desbloqueie os usuários teste do Oracle Database, e dê as permissões abaixo. ALTER SYSTEM SET DB_CREATE_FILE_DEST = '/u01/app/oracle/oradata'; SELECT TABLESPACE_NAME FROM DBA_TABLESPACES; CREATE TABLESPACE USERS; CREATE TABLESPACE EXAMPLE; CREATE TABLESPACE SOE; CREATE TABLESPACE SHSB; CREATE TABLESPACE SHSBP; $ impdp SCHEMAS=SCOTT,HR,SH,SHSB,SHSBP,SOE,OE ALTER ALTER ALTER ALTER ALTER ALTER ALTER GRANT GRANT GRANT GRANT GRANT GRANT GRANT USER SCOTT ACCOUNT UNLOCK IDENTIFIED BY TIGER; USER HR ACCOUNT UNLOCK IDENTIFIED BY HR; USER SH ACCOUNT UNLOCK IDENTIFIED BY SH; USER SHSB ACCOUNT UNLOCK IDENTIFIED BY SHSB; USER SHSBP ACCOUNT UNLOCK IDENTIFIED BY SHSBP; USER OE ACCOUNT UNLOCK IDENTIFIED BY OE; USER SOE ACCOUNT UNLOCK IDENTIFIED BY SOE; ALTER SESSION, RESOURCE, SELECT ANY DICTIONARY ALTER SESSION, RESOURCE, SELECT ANY DICTIONARY ALTER SESSION, RESOURCE, SELECT ANY DICTIONARY ALTER SESSION, RESOURCE, SELECT ANY DICTIONARY ALTER SESSION, RESOURCE, SELECT ANY DICTIONARY ALTER SESSION, RESOURCE, SELECT ANY DICTIONARY ALTER SESSION, RESOURCE, SELECT ANY DICTIONARY TO TO TO TO TO TO TO SCOTT; HR; SH; SHSB; SHSBP; OE; SOE; 2
3 Top Ten Mistakes 1 - Bad connection management 2 - Bad use of cursors and the shared pool 3 - Bad SQL 4 - Use of nonstandard initialization parameters 5 - Getting database I/O wrong 6 - Online redo log setup problems 7 - Serialization of data blocks in the buffer cache due to lack of free lists, free list groups, transaction slots (INITRANS), or shortage of rollback segments. 8 - Long full table scans 9 - High amounts of recursive (SYS) SQL 10 - Deployment and migration errors Fonte: Oracle Database Performance Tuning Guide 3 3
4 Ferramentas Básicas 4
5 AUTOTRACE SET AUTOTRACE ON; SELECT ENAME FROM EMP; ENAME SMITH rows selected. Execution Plan Plan hash value: Id Operation Name Rows Bytes Cost (%CPU) Time SELECT STATEMENT (0) 00:00:01 1 TABLE ACCESS FULL EMP (0) 00:00: Statistics recursive calls... 0 sorts (disk) 14 rows processed 5
6 AUTOTRACE SET AUTOTRACE TRACEONLY; SELECT ENAME FROM EMP; 14 rows selected. Execution Plan Plan hash value: Id Operation Name Rows Bytes Cost (%CPU) Time SELECT STATEMENT (0) 00:00:01 1 TABLE ACCESS FULL EMP (0) 00:00: Statistics recursive calls 0 db block gets... 0 sorts (disk) 14 rows processed 6
7 AUTOTRACE SET AUTOTRACE TRACEONLY EXPLAIN; SELECT ENAME FROM EMP; Execution Plan Plan hash value: Id Operation Name Rows Bytes Cost (%CPU) Time SELECT STATEMENT (0) 00:00:01 1 TABLE ACCESS FULL EMP (0) 00:00:
8 AUTOTRACE SET AUTOTRACE TRACEONLY STATISTICS; SELECT ENAME FROM EMP; 14 rows selected. Statistics recursive calls 0 db block gets 8 consistent gets 0 physical reads 0 redo size 731 bytes sent via SQL*Net to client 551 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 14 rows processed 8

9 SQL Developer: Plano de Execução 9
10 SQL Trace (Event 10046): Ativação ALTER SESSION SET EVENTS '10046 TRACE NAME CONTEXT FOREVER, LEVEL 12'; ALTER SESSION SET EVENTS '10046 TRACE NAME CONTEXT OFF'; OU SELECT P.SPID, P.TRACEFILE FROM V$SESSION S, V$PROCESS P WHERE S.PADDR = P.ADDR AND S.USERNAME = 'SCOTT'; oradebug setospid 9999; oradebug tracefile_name; oradebug unlimit; oradebug event trace name context forever, level 12; 10
11 SQL Trace (Event 10046): Ativação CREATE OR REPLACE TRIGGER SET_TRACE AFTER LOGON ON DATABASE BEGIN IF USER IN ('SCOTT') THEN EXECUTE IMMEDIATE 'ALTER SESSION SET TRACEFILE_IDENTIFIER=''SESSAO_RASTREADA_PORTILHO'''; EXECUTE IMMEDIATE 'ALTER SESSION SET TIMED_STATISTICS=TRUE'; EXECUTE IMMEDIATE 'ALTER SESSION SET MAX_DUMP_FILE_SIZE=UNLIMITED'; EXECUTE IMMEDIATE 'ALTER SESSION SET EVENTS ''10046 TRACE NAME CONTEXT FOREVER, LEVEL 12'''; END IF; END; / 11
12 tkprof 12

13 SQL Trace (Event 10046) 13
14 Fontes de Planos de Execução PLAN_TABLE, carregada por EXPLAIN PLAN / DBMS_XPLAN.DISPLAY ou AUTOTRACE (e SQL Developer, Toad, etc.); VIEWs de planos compilados e armazenados na Library Cache; Tabelas de AWR / STATSPACK; Arquivos Trace (10046, 10053, etc.). 14
15 Explain Plan Sintaxe: EXPLAIN PLAN [SET STATEMENT_ID=id] [INTO table] FOR statement; Exemplo: EXPLAIN PLAN SET STATEMENT_ID='TESTE1' FOR SELECT ENAME FROM EMP; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY); Limitações do Explain Plan: - É o Plano, não a Execução; - Não utiliza Bind Peeking / Adaptive Cursor Sharing (ACS); - Todas Variáveis Bind são consideradas VARCHAR2; - Depende do ambiente de execução (parâmetros, trigger de logon?). Recuperação de Ambiente de Execução: SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL,NULL,'OUTLINE PEEKED_BINDS')); SELECT NAME, VALUE FROM V$SQL_OPTIMIZER_ENV WHERE SQL_ID = '6qw0sbyw09ywh' AND CHILD_NUMBER = 0 AND ISDEFAULT = 'NO'; 15
16 Lab: Explain Plan Execute os SQLs abaixo, comparando os Planos de Execução. CONN SCOTT/TIGER CREATE TABLE T15 AS SELECT * FROM ALL_OBJECTS; CREATE INDEX IDX_T15_OBJECT_ID ON T101(OBJECT_ID); SET AUTOTRACE ON EXPLAIN SELECT COUNT(OBJECT_ID) FROM T15 WHERE OBJECT_ID = 1; SELECT COUNT(OBJECT_ID) FROM T15 WHERE OBJECT_ID = '1'; VARIABLE VOBJECT_ID NUMBER; EXEC :VOBJECT_ID := 1; SELECT COUNT(OBJECT_ID) FROM T15 WHERE OBJECT_ID = :VOBJECT_ID; 16
17 Lab: Explain Plan Execute o SQL abaixo duas vezes, comparando o Plano de Execução. $ sqlplus SCOTT/TIGER CREATE TABLE T16_1 AS SELECT * FROM ALL_OBJECTS; CREATE INDEX T16_1_IDX1 ON T16_1(OBJECT_ID); CREATE TABLE T16_2 AS SELECT * FROM ALL_OBJECTS; CREATE INDEX T16_2_IDX1 ON T16_2(OBJECT_ID); EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'T16_1'); EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'T16_2'); SET AUTOTRACE TRACEONLY EXPLAIN SELECT T16_1.OBJECT_ID, T16_2.OBJECT_NAME FROM T16_1, T16_2 WHERE T16_1.OBJECT_ID = T16_2.OBJECT_ID AND T16_2.OBJECT_TYPE = 'SYNONYM' AND T16_1.OBJECT_ID BETWEEN 1000 and 10000; VARIABLE vstart NUMBER VARIABLE vend NUMBER EXEC :vstart := 1000 EXEC :vend := SELECT T16_1.OBJECT_ID, T16_2.OBJECT_NAME FROM T16_1, T16_2 WHERE T16_1.OBJECT_ID = T16_2.OBJECT_ID AND T16_2.OBJECT_TYPE = 'SYNONYM' AND T16_1.OBJECT_ID BETWEEN :vstart and :vend; 17
18 AWR / Statspack Tabelas: - STATS$SQL_PLAN (STATSPACK) - DBA_HIST_SQL_PLAN - DBA_HIST_SQLTEXT - DBA_HIST_SQLSTAT - DBA_HIST_SQLBIND Exemplo: SELECT SQL_ID, SQL_TEXT FROM DBA_HIST_SQLTEXT WHERE SQL_TEXT LIKE '%SELECT ENAME FROM EMP%'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_AWR('a10jnjwd22gs8')); EXEC DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT; EXEC DBMS_WORKLOAD_REPOSITORY.MODIFY_SNAPSHOT_SETTINGS (RETENTION => 43200, INTERVAL => 30, TOPNSQL => 100); EXEC DBMS_WORKLOAD_REPOSITORY.ADD_COLORED_SQL('az9p3ctumhpr8'); EXEC DBMS_WORKLOAD_REPOSITORY.REMOVE_COLORED_SQL('az9p3ctumhpr8'); AWR requer a Option Diagnostics Pack 18
19 AWR / Statspack SQL Enter value for report_type: html Enter value for num_days: 1 Enter value for begin_snap: 40 Enter value for end_snap: 41 Enter value for sql_id: 062savj8zgzut Enter value for report_name: AWR_SQL_01.html SQL Statement (Specific Database

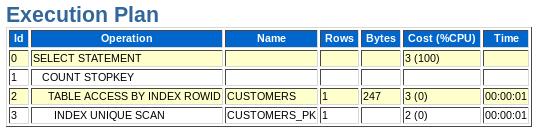
20 SQL Statement 20 20
21 Views Dynamic Performance Views: - V$SQL_PLAN V$SQL_PLAN_STATISTICS V$SQL_WORKAREA V$SQL_PLAN_STATISTICS_ALL (V$SQL_PLAN_STATISTICS + V$SQL_WORKAREA) Chave < 10g: ADDRESS, Chave >= 10g: SQL_ID HASH_VALUE, CHILD_NUMBER Exemplo: SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR); SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL,'OUTLINE PEEKED_BINDS')); SELECT STATUS, SQL_ID, SQL_CHILD_NUMBER FROM V$SESSION WHERE USERNAME = 'SCOTT'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('6qw0sbyw09ywh')); SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('a10jnjwd22gs8', 0)); 21
22 Execution Plan CONN SCOTT/TIGER CREATE TABLE T21 AS SELECT * FROM ALL_OBJECTS; EXEC DBMS_STATS.DELETE_TABLE_STATS('SCOTT','T21'); SELECT /*+ GATHER_PLAN_STATISTICS */ COUNT(OBJECT_NAME) FROM SCOTT.T21 WHERE OBJECT_TYPE = 'SYNONYM'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT OBJECT_TYPE SELECT OBJECT_TYPE /*+ GATHER_PLAN_STATISTICS */ COUNT(OBJECT_NAME) FROM SCOTT.T21 WHERE = 'PACKAGE'; /*+ GATHER_PLAN_STATISTICS */ COUNT(OBJECT_NAME) FROM SCOTT.T21 WHERE = 'DIRECTORY'; 22 22
23 Execution Plan CONN SCOTT/TIGER EXEC DBMS_STATS.DELETE_SCHEMA_STATS(USER); SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10); SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10,20); SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT /*+ GATHER_PLAN_STATISTICS */ EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10); SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT /*+ GATHER_PLAN_STATISTICS */ EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10,20); SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT /*+ GATHER_PLAN_STATISTICS */ EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); 23 23
24 Execution Plan 24 24
25 Execution Plan CONN / AS SYSDBA ALTER SYSTEM SET STATISTICS_LEVEL=ALL; CONN SCOTT/TIGER ALTER SESSION SET STATISTICS_LEVEL=ALL; SELECT COUNT(OBJECT_NAME) FROM SCOTT.T21 WHERE OBJECT_TYPE = 'SYNONYM'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T21 WHERE OBJECT_TYPE = 'PACKAGE'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T21 WHERE OBJECT_TYPE = 'DIRECTORY'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); 25 25
26 Execution Plan CONN SCOTT/TIGER COL SQL_TEXT FORMAT A150 SELECT SQL_ID, CHILD_NUMBER, SQL_TEXT FROM V$SQL WHERE SQL_TEXT LIKE '%T21%'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('d43dypzv2mdyz', 0, 'ALLSTATS LAST')); 26 26
27 SQL ou PL/SQL? Se você pode fazer algo em SQL, faça-o em SQL. Se você não pode faze-lo em SQL, faça em PL/SQL. Se você não pode faze-lo em PL/SQL, faça em Java. Se você não pode faze-lo em Java, faça em C++. Se você não pode fazer em C++, não o faça. Thomas Kyte - O que você aprendeu sobre carros, quando aprendeu a dirigir? - Quanto tempo você levou para aprender SQL? - Utilizamos apenas cerca de 20% das capacidades de um programa ou linguagem
28 Rows x Sets 28

29 Rows x Sets Isto não representa uma tabela! 29
30 Rows x Sets Quais são os funcionários que ganham mais do que a média de seu departamento. Método procedural: - Calcule a média salarial de cada departamento; - Armazene a média de forma temporária; - Liste todos os empregados e seu departamento; - Compare o salário de cada empregado com a média de seu departamento; - Liste todos os empregados que tem o salário acima da média. Método por conjunto: SELECT * FROM EMP EMP1 WHERE SAL > (SELECT AVG(EMP2.SAL) FROM EMP EMP2 WHERE EMP2.DEPTNO = EMP1.DEPTNO); 30
31 Rows x Sets Quais os empregados que passaram a mesma quantidade de anos em cada cargo ocupado? Método procedural: - Listar todos os empregados; - Listas todos os cargos, data inicial e final destes empregados, calculando a quantidade de anos; - Armazenar estes dados em formato temporário; - Para cada empregado, verificar se todos as quantidades de anos são iguais; - Descartar os empregados que não possuem todas as quantidade de anos iguais. Método por conjunto: SELECT EMPLOYEE_ID FROM JOB_HISTORY GROUP BY EMPLOYEE_ID HAVING MIN(ROUND(MONTHS_BETWEEN(START_DATE, END_DATE) / 12,0)) = MAX(ROUND(MONTHS_BETWEEN(START_DATE, END_DATE) / 12,0); 31
32 Rows x Sets Qual a quantidade média de dias entre os pedidos de um cliente? Método procedural: - Liste todos os pedidos do cliente X; - Selecione os pedidos e suas datas; - Para cada pedido, selecione a data do pedido anterior; - Calcule qual a quantidade de dias entre a data do pedido e a data anterior; - Calcule a média destas quantidades. Método por conjunto: SELECT (MAX(TRUNC(ORDER_DATE)) - MIN(TRUNC(ORDER_DATE))) / COUNT(ORDER_ID) FROM ORDERS WHERE CUSTOMER_ID = 102 ; 32
33 Rows x Sets Crie uma tabela com os clientes pequenos, outra com os clientes médios, e outra com os clientes grandes. Método procedural: - Selecionar os clientes que compraram menos de 10000; - Inseri-los na tabela SMALL_CUSTOMERS; - Selecionar os clientes que compraram entre e 99999; - Inseri-los na tabela MEDIUM_CUSTOMERS; - Selecionar os clientes que compraram mais de ; - Inseri-los na tabela LARGE_CUSTOMERS; Método por conjunto: INSERT ALL WHEN SUM_ORDERS < THEN INTO SMALL_CUSTOMERS WHEN SUM_ORDERS >= AND SUM_ORDERS < THEN INTO MEDIUM_CUSTOMERS ELSE INTO LARGE_CUSTOMERS SELECT CUSTOMER_ID, SUM(ORDER_TOTAL) SUM_ORDERS FROM OE.ORDERS GROUP BY CUSTOMER_ID; 33
34 Rows x Sets Altere o bônus para 20% de quem é candidato mas ainda não tem bônus, remova de quem ganh mais de 7.500, e marque como 10% o bônus de quem ainda não é candidato mas recebe menos que Método procedural: - Selecione os empregados que devem receber a alteração de 20%; - Faça a alteração dos empregados que devem receber a alteração de 20%; - Selecione os empregados que devem receber a alteração de 10%; - Faça a alteração dos empregados que devem receber a alteração de 10%; - Selecione os empregados que não devem mais ser candidatos a bônus; - Remova os empregados que não devem mais ser candidatos a bônus. Método por conjunto: MERGE INTO BONUS_DEPT60 B USING (SELECT EMPLOYEE_ID, SALARY, DEPARTMENT_ID FROM EMPLOYEES WHERE DEPARTMENT_ID = 60) E ON (B.EMPLOYEE_ID = E.EMPLOYEE_ID) WHEN MATCHED THEN UPDATE SET BONUS = E.SALARY * 0.2 WHERE B.BONUS = 0 DELETE WHERE (E.SALARY > 7500) WHEN NOT MATCHED THEN INSERT (B.EMPLOYEE_ID, B.BONUS) VALUES (E.EMPLOYEE_ID, E.SALARY * 0.1) WHERE (E.SALARY < 7500); 34
35 Modelagem 35
36 PKs: Surrogate or Natural? Natural Keys (RG, CPF, Nota Fiscal, Matrícula, Apólice...) Naturalidade no entendimento das colunas; Redução da largura da linha; Menor quantidade de JOINs para exibir o resultado final; Validação natural de regras de negócio. Surrogate Keys (SEQUENCE, IDENTITY, MAX + 1 com FOR UPDATE) Alterações com menor impacto; Redução da largura das chaves; Redução da possibilidade de concorrência em alterações de campos; Composição desnecessária; Simplicidade de JOINs. 36
37 Lab: FTS e Clustering Factor Crie as duas tabelas abaixo com o usuário SCOTT, e compare as duas. CONN SCOTT/TIGER CREATE TABLE T1 AS SELECT TRUNC((ROWNUM-1)/100) ID, RPAD(ROWNUM,100) NAME FROM DBA_SOURCE WHERE ROWNUM <= 10000; CREATE INDEX T1_IDX1 ON T1(ID); CREATE TABLE T2 AS SELECT MOD(ROWNUM,100) ID, RPAD(ROWNUM,100) NAME FROM DBA_SOURCE WHERE ROWNUM <= 10000; CREATE INDEX T2_IDX1 ON T2(ID); SELECT SELECT SELECT SELECT SELECT SELECT SELECT SELECT COUNT(*) FROM T1; COUNT(*) FROM T2; MIN(ID) FROM T1; MIN(ID) FROM T2; MAX(ID) FROM T1; MAX(ID) FROM T2; COUNT(*) FROM T1 WHERE ID = 1; COUNT(*) FROM T2 WHERE ID = 1; 37
38 Lab: FTS e Clustering Factor Compare os planos de execução de SQL iguais para as duas tabelas. SET AUTOTRACE TRACEONLY SELECT ID, NAME FROM T1 SELECT ID, NAME FROM T2 SELECT ID, NAME FROM T1 SELECT ID, NAME FROM T2 SELECT ID, NAME FROM T1 SELECT ID, NAME FROM T2 EXPLAIN WHERE ID WHERE ID WHERE ID WHERE ID WHERE ID WHERE ID = = < < < < 1; 1; 5; 5; 10; 10; Verifique a ordenação física dos dados das tabelas. SET AUTOTRACE OFF SELECT ID, NAME FROM T1; SELECT ID, NAME FROM T2; SELECT ROWID, ID, NAME FROM T1 ORDER BY 2; SELECT ROWID, ID, NAME FROM T2 ORDER BY 2; 38
39 Lab: FTS e Clustering Factor Compare as estatísticas das duas tabelas. SET AUTOTRACE OFF COL TABLE_NAME FORMAT A20 COL INDEX_NAME FORMAT A20 SELECT T.TABLE_NAME, I.INDEX_NAME, I.CLUSTERING_FACTOR, T.BLOCKS, T.NUM_ROWS FROM DBA_TABLES T, DBA_INDEXES I WHERE T.TABLE_NAME = I.TABLE_NAME AND T.TABLE_NAME IN ('T1', 'T2') AND T.OWNER = 'SCOTT' ORDER BY T.TABLE_NAME, I.INDEX_NAME; 39
40 Lab: Data Types Verifique os planos de execução dos SQL abaixo. CONN SCOTT/TIGER CREATE TABLE T36 (ID VARCHAR(255), NAME VARCHAR(255)); CREATE INDEX T36_IDX ON T36(ID); INSERT INTO T36 SELECT * FROM T1; COMMIT; SET AUTOTRACE ON SELECT COUNT(*) FROM T1 WHERE ID=1; SELECT COUNT(*) FROM T36 WHERE ID=1; SELECT COUNT(*) FROM T36 WHERE ID='1'; INSERT INTO T36 VALUES ('X', 'X'); SELECT COUNT(*) FROM T36 WHERE ID=1; ROLLBACK; SELECT COUNT(*) FROM T36 WHERE ID=1; 40
41 Lab: Data Types Verifique o plano de execução do SQL abaixo. CONN SCOTT/TIGER CREATE TABLE T37 AS WITH GENERATOR AS ( SELECT --+ materialize ROWNUM ID FROM ALL_OBJECTS WHERE ROWNUM <= 2000) SELECT DECODE( MOD(ROWNUM - 1,1000), 0, TO_DATE('31-Dec-4000'), TO_DATE('01-Jan-2008') + trunc((rownum - 1)/100) ) DATA_PEDIDO FROM GENERATOR V1, GENERATOR V2 WHERE ROWNUM <= 1827 * 100; SELECT COUNT(*) FROM T37; SELECT COUNT(*) FROM T37 WHERE DATA_PEDIDO = TO_DATE('31-Dec-4000'); SET AUTOTRACE TRACEONLY EXPLAIN SELECT COUNT(*) FROM T37 WHERE DATA_PEDIDO BETWEEN TO_DATE('01-Jan2010','dd-mon-yyyy') AND TO_DATE('31-Dec-2010','dd-mon-yyyy'); 41
42 Lab: Data Types Verifique o plano de execução do SQL abaixo. CONN SCOTT/TIGER CREATE TABLE T38 AS SELECT DATA_DATE, TO_NUMBER(TO_CHAR(DATA_DATE,'yyyymmdd')) DATA_NUMBER, TO_CHAR(DATA_DATE,'yyyymmdd') DATA_CHAR FROM (SELECT TO_DATE('31-Dec-2007') + ROWNUM DATA_DATE FROM ALL_OBJECTS WHERE ROWNUM <= 1827); SET AUTOTRACE TRACEONLY EXPLAIN SELECT COUNT(*) FROM T38 WHERE DATA_DATE BETWEEN TO_DATE('01-Jan-2010','dd-mon-yyyy') AND TO_DATE('31-Dec-2010','dd-mon-yyyy'); SELECT COUNT(*) FROM T38 WHERE DATA_NUMBER BETWEEN AND ; SELECT COUNT(*) FROM T38 WHERE DATA_CHAR BETWEEN ' ' AND ' '; 42


43 Dicas de SQL Tuning? Não acredite em tudo o que lê. Por algo estar escrito, não significa que é verdade. O que é verdade aqui, pode não ser verdade lá. O que era verdade ontem, pode não ser verdade hoje. O que é verdade hoje, pode não ser verdade amanhã. Se os fatos não se adequam à teoria, modifique a teoria. Questione, e só acredite em fatos: teste. Quando você mudar algo, pode acontecer 01 de 03 coisas
44 Lendas de SQL O Custo não quer dizer nada? Índice BITMAP em baixa cardinalidade? Sintaxe Oracle ou ANSI? SELECT(1) ou SELECT COUNT(*)? Ordem da cláusula WHERE? Ordem de JOIN? CHAR ou VARCHAR2? Evite Subqueries? Evite VIEWs? Evite EXISTS? Evite Listas IN? NESTED LOOPs é ruim? < > é melhor que BETWEEN? 44
45 Lendas de SQL 45 45
46 Lab: Lendas de SQL - COUNT(*) Execute logon com o usuário SCOTT, e verifique qual é seu arquivo de TRACE: $ sqlplus SCOTT/TIGER COLUMN TRACEFILE FORMAT A100 SELECT P.TRACEFILE FROM V$SESSION S, V$PROCESS P WHERE S.PADDR = P.ADDR AND S.USERNAME = 'SCOTT'; Coloque sua sessão em TRACE 10053, e execute os comandos abaixo. ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; SELECT COUNT(EMPNO) FROM EMP; SELECT COUNT(1) FROM EMP; SELECT COUNT(2) FROM EMP; SELECT COUNT(*) FROM EMP; SELECT COUNT(ROWID) FROM EMP; SELECT COUNT(MGR) FROM EMP; Edite o seu arquivo de TRACE. $ vi /u01/app/oracle/rdbms/orcl/orcl/trace/orcl_ora_1234.trc 46
47 Lab: Lendas de SQL - COUNT(*) No arquivo de Trace, procure pelo texto CNT : Legend The following abbreviations are used by optimizer trace. CBQT - cost-based query transformation JPPD - join predicate push-down OJPPD - old-style (non-cost-based) JPPD FPD - filter push-down PM - predicate move-around CVM - complex view merging SPJ - select-project-join SJC - set join conversion SU - subquery unnesting OBYE - order by elimination OST - old style star transformation ST - new (cbqt) star transformation CNT - count(col) to count(*) transformation JE - Join Elimination JF - join factorization 47
48 Lab: Lendas de SQL - COUNT(*) Procure novamente pelo texto CNT : CNT: Considering count(col) to count(*) on query block SEL$1 (#0) ************************* Count(col) to Count(*) (CNT) ************************* CNT: Converting COUNT(EMPNO) to COUNT(*). CNT: COUNT() to COUNT(*) done. Procure pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT COUNT(*) "COUNT(EMPNO)" FROM "SCOTT"."EMP" "EMP" 48
49 Lab: Lendas de SQL - COUNT(*) Procure novamente pelo texto CNT : CNT: Considering count(col) to count(*) on query block SEL$1 (#0) ************************* Count(col) to Count(*) (CNT) ************************* CNT: COUNT() to COUNT(*) done. Procure novamente pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT COUNT(*) "COUNT(1)" FROM "SCOTT"."EMP" "EMP" 49
50 Lab: Lendas de SQL - COUNT(*) Procure novamente pelo texto CNT : CNT: Considering count(col) to count(*) on query block SEL$1 (#0) ************************* Count(col) to Count(*) (CNT) ************************* CNT: COUNT() to COUNT(*) done. Procure novamente pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT COUNT(*) "COUNT(2)" FROM "SCOTT"."EMP" "EMP" 50
51 Lab: Lendas de SQL - COUNT(*) Procure novamente pelo texto CNT : CNT: Considering count(col) to count(*) on query block SEL$1 (#0) ************************* Count(col) to Count(*) (CNT) ************************* CNT: COUNT() to COUNT(*) not done. Procure novamente pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT COUNT(*) "COUNT(*)" FROM "SCOTT"."EMP" "EMP" 51
52 Lab: Lendas de SQL - COUNT(*) Procure novamente pelo texto CNT : CN T: Considering count(col) to count(*) on query block SEL$1 (# 0) ************************* Count(col) to Count(*) (CN T) ************************* CN T: CO U N T() to CO U N T(*) not done. Procure novamente pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT COUNT("EMP".ROWID) "COUNT(ROWID)" FROM "SCOTT"."EMP" "EMP" 52
53 Lab: Lendas de SQL - ANSI Execute os comandos abaixo. SELECT FROM SELECT FROM E.ENAME, E.JOB, D.DNAME EMP E, DEPT D WHERE E.DEPTNO = D.DEPTNO; E.ENAME, E.JOB, D.DNAME EMP E INNER JOIN DEPT D ON E.DEPTNO = D.DEPTNO; Procure novamente pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT "E"."ENAME" "ENAME","E"."JOB" "JOB","D"."DNAME" "DNAME" FROM "SCOTT"."EMP" "E","SCOTT"."DEPT" "D" WHERE "E"."DEPTNO"="D"."DEPTNO" Procure novamente pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT "E"."ENAME" "ENAME","E"."JOB" "JOB","D"."DNAME" "DNAME" FROM "SCOTT"."EMP" "E","SCOTT"."DEPT" "D" WHERE "E"."DEPTNO"="D"."DEPTNO" 53
54 Lab: Lendas de SQL- Listas IN Execute os comandos abaixo. SELECT E.ENAME, E.JOB, D.DNAME FROM EMP E, DEPT D WHERE E.DEPTNO = D.DEPTNO AND EMPNO IN (7369,7499,7521,7566,7654); Procure novamente pelo texto Final query : Final query after transformations:******* UNPARSED QUERY IS ******* SELECT "E"."ENAME" "ENAME","E"."JOB" "JOB","D"."DNAME" "DNAME" FROM "SCOTT"."EMP" "E","SCOTT"."DEPT" "D" WHERE "E"."DEPTNO"="D"."DEPTNO" AND ("E"."EMPNO"=7369 OR "E"."EMPNO"=7499 OR "E"."EMPNO"=7521 OR "E"."EMPNO"=7566 OR "E"."EMPNO"=7654) 54
55 Query Rewrite De acordo com a Documentação: OR Expansion View Merging Predicate Pushing Subquery Unnesting In-Memory Aggregation Table Expansion Join Factorization Query Rewrite with Materialized Views Star Transformation 55
56 Query Rewrite: Predicate Pushdown Controle: Hints QUERY_TRANSFORMATION / NO_QUERY_TRANSFORMATION FROM CONN HR/HR ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; SELECT * FROM EMPLOYEES WHERE DEPARTMENT_ID IN (SELECT DEPARTMENT_ID DEPARTMENTS); 56
57 Query Rewrite: View Merging Execute o SELECT abaixo, e encontre no arquivo trace o View Merging. CONN OE/OE ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; SELECT * FROM ORDERS O, (SELECT SALES_REP_ID FROM ORDERS) O_VIEW WHERE O.SALES_REP_ID = O_VIEW.SALES_REP_ID (+) AND O.ORDER_TOTAL > ; Execute o SELECT abaixo, e encontre no arquivo trace o View Merging. CONN OE/OE ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; SELECT * FROM ORDERS O, (SELECT SALES_REP_ID FROM ORDERS ORDER BY SALES_REP_ID) O_VIEW WHERE O.SALES_REP_ID = O_VIEW.SALES_REP_ID (+) AND O.ORDER_TOTAL > AND ROWNUM < 10 ORDER BY ORDER_TOTAL; 57
58 Query Rewrite: Subquery Unnesting - Controle: HINT NO_UNNEST, unnest_subquery (TRUE de 9i em diante). - Similar a View Merging, ocorre quando a Subquery está localizada na cláusula WHERE; - A transformação mais comum é em um JOIN; FROM CONN HR/HR ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; SELECT * FROM EMPLOYEES WHERE DEPARTMENT_ID IN (SELECT DEPARTMENT_ID DEPARTMENTS); 58

59 Query Rewrite: Subquery Unnesting + JE O plano de execução utiliza quais tabelas? 59
60 Query Rewrite: Subquery Unnesting Execute o SELECT abaixo, e encontre no arquivo trace o Subquery Unnesting. CONN HR/HR ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; SELECT OUTER.EMPLOYEE_ID, OUTER.LAST_NAME, OUTER.SALARY, OUTER.DEPARTMENT_ID FROM EMPLOYEES OUTER WHERE OUTER.SALARY > (SELECT AVG(INNER.SALARY) FROM EMPLOYEES INNER WHERE INNER.DEPARTMENT_ID = OUTER.DEPARTMENT_ID); 60
61 Query Rewrite: Subquery Unnesting 61
62 Query Rewrite: Predicate Pushing Execute o SELECT abaixo, e encontre no arquivo trace o Predicate Pushing. CONN HR/HR ALTER SESSION SET EVENTS '10053 TRACE NAME CONTEXT FOREVER, LEVEL 1'; SELECT E1.LAST_NAME, E1.SALARY, V.AVG_SALARY FROM EMPLOYEES E1, (SELECT DEPARTMENT_ID, AVG(SALARY) AVG_SALARY FROM EMPLOYEES E2 GROUP BY DEPARTMENT_ID) V WHERE E1.DEPARTMENT_ID = V.DEPARTMENT_ID AND E1.SALARY > V.AVG_SALARY AND E1.DEPARTMENT_ID = 60; E com DEPARTMENT_ID IN (10,40,60)? 62
63 Cost Based Optimizer 63

64 CBO - Cost Based Optimizer: trace
65 CBO - Cost Based Optimizer O que é o custo? Cost = ( #SRds * sreadtim + #MRds * mreadtim + #CPUCycles / cpuspeed ) / sreadtim OU Custo = ( Quantidade de leituras de um único bloco * Tempo de leitura de um único bloco + Quantidade de leituras de múltiplos blocos * Tempo de leitura de múltiplos blocos + Ciclos de CPU / Velocidade da CPU ) / Tempo de leitura de um único bloco O CBO foi lançado no Oracle 7. O RBO foi considerado legado no 10g, mas existe até no
66 Seletividade e Cardinalidade Seletividade É um valor entre 0 e 1 que representa a fração de linhas obtidas por uma operação. Cardinalidade É o número de linhas retornadas por uma operação. Exemplo: SELECT MODELS FROM CARS; 120 rows selected. Cardinalidade = 120. Seletividade = 1.0 (120/120). SELECT COUNT(MODELS) FROM CARS; Cardinalidade = 1. Seletividade = 1.0 (120/120). SELECT MODELS FROM CARS WHERE FAB = 'FORD'; 18 rows selected. Cardinalidade = 18. Seletividade = 0.15 (18/120). 66
67 Configuração do CBO - OLTP OPTIMIZER_MODE (FIRST_ROWS_n / ALL_ROWS) < DB_FILE_MULTIBLOCK_READ_COUNT RESULT_CACHE INMEMORY OPTIMIZER_SECURE_VIEW_MERGING QUERY_REWRITE_ENABLED QUERY_REWRITE_INTEGRITY STAR_TRANSFORMATION_ENABLED GATHER_SYSTEM_STATISTICS GATHER_DATABASE_STATISTICS OPTIMIZER_DYNAMIC_SAMPLING WORKAREA_SIZE_POLICY (AUTO / MANUAL) AUTO: PGA_AGGREGATE_TARGET MANUAL: BITMAP_MERGE_AREA_SIZE HASH_AREA_SIZE SORT_AREA_SIZE SORT_AREA_RETAINED_SIZE > OPTIMIZER_INDEX_CACHING < OPTIMIZER_INDEX_COST_ADJ Histograms Extended Statistics 67
68 Configuração do CBO - OLAP OPTIMIZER_MODE (FIRST_ROWS_n / ALL_ROWS) > DB_FILE_MULTIBLOCK_READ_COUNT RESULT_CACHE INMEMORY OPTIMIZER_SECURE_VIEW_MERGING QUERY_REWRITE_ENABLED QUERY_REWRITE_INTEGRITY STAR_TRANSFORMATION_ENABLED GATHER_SYSTEM_STATISTICS GATHER_DATABASE_STATISTICS OPTIMIZER_DYNAMIC_SAMPLING WORKAREA_SIZE_POLICY (AUTO / MANUAL) AUTO: PGA_AGGREGATE_TARGET MANUAL: BITMAP_MERGE_AREA_SIZE HASH_AREA_SIZE SORT_AREA_SIZE SORT_AREA_RETAINED_SIZE < OPTIMIZER_INDEX_CACHING > OPTIMIZER_INDEX_COST_ADJ Histograms Extended Statistics 68
69 SQL Engine 69
 Latch / Mutex Buffer Cache Shared Pool Library")
70 Terminologia Soft Parse / Hard Parse LIO (Logical Input/Output) PIO (Physical Input/Output) Latch / Mutex Buffer Cache Shared Pool Library Cache 70
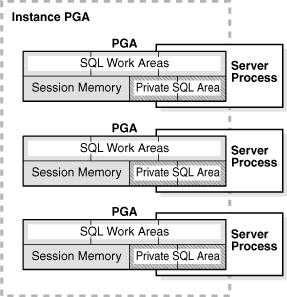
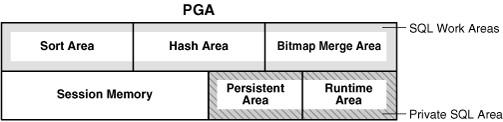
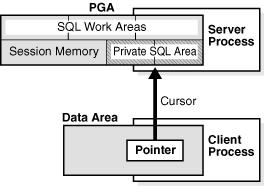
71 PGA 71
72 SELECT 5: SELECT (COLUMN / DISTINCT COLUMN / expression / scalar subquery) 1: FROM / FROM JOIN ON (fontes: TABLE, VIEW, MVIEW, PARTITION, SUBQUERY...) 2: * WHERE (condições: TRUE, FALSE, UNKNOWN) 3: * GROUP BY (opções: ROLLUP / CUBE) 4: * HAVING (condição: TRUE) 6: * ORDER BY (COLUMN) Exemplo: SELECT C.CUSTOMER_ID, COUNT(O.ORDER_ID) AS ORDER_CT FROM OE.CUSTOMERS C JOIN OE.ORDERS O ON C.CUSTOMER_ID = O.CUSTOMER_ID WHERE C.GENDER = 'F' GROUP BY C.CUSTOMER_ID HAVING COUNT(O.ORDER_ID) > 4 ORDER BY ORDERS_CT, C_CUSTOMER_ID; Na fase 2, os dados já foram selecionados (IN MEMORY Column Store). 72
73 Processamento de SQL OPEN CURSOR PARSE BIND EXEC FETCH (ARRAYSIZE, DEFAULT_SDU_SIZE (512 a 32767), RECV_BUF_SIZE, SEND_BUF_SIZE (sqlnet.ora) CLOSE CURSOR SQL*Net PARSE SQL*Net SQL*Net BIND SQL*Net SQL*Net EXEC SQL*Net SQL*Net FETCH SQL*Net SQL*Net FETCH SQL*Net SQL*Net... Message From Client Message To Client Message From Client Message To Client Message From Client Message To Client Message From Client Message To Client Message From Client Message To Client Message From Client Apenas SELECT possui a fase FETCH. 73
74 Processamento de SQL 74

75 PL/SQL Engine 75

76 SQL Recursivos 76
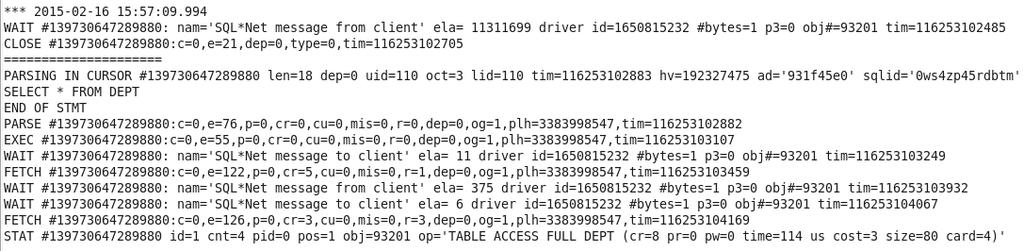
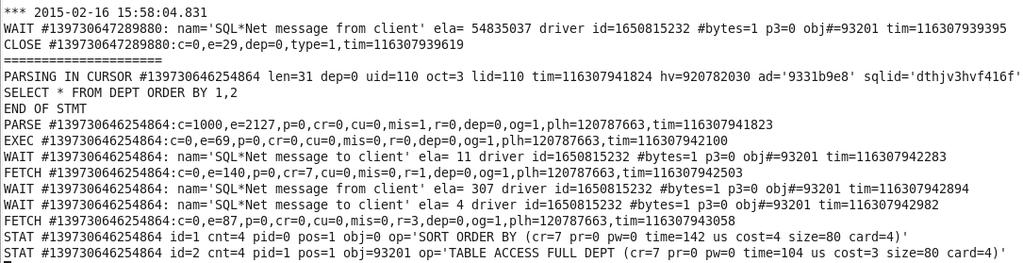
77 SQL Recursivos 77
78 Lab: Connect / Parse / Commit Crie a tabela abaixo com o usuário SCOTT. CREATE TABLE T75 (C1 NUMBER); Observe o conteúdo dos seguintes scripts Perl, os execute, e compare. $ $ $ $ $ $ $ $ $ $ time time time time time time time time time time perl perl perl perl perl perl perl perl perl perl /home/oracle/connectbad_commitbad_bindsbad.pl /home/oracle/connectbad_commitbad_bindsgood.pl /home/oracle/connectbad_commitgood_bindsbad.pl /home/oracle/connectbad_commitgood_bindsgood.pl /home/oracle/connectgood_commitbad_bindsbad.pl /home/oracle/connectgood_commitbad_bindsgood.pl /home/oracle/connectgood_commitgood_bindsbad.pl /home/oracle/connectgood_commitgood_bindsbad_one.pl /home/oracle/connectgood_commitgood_bindsgood.pl /home/oracle/connectgood_commitgood_bindsgood_perfect.pl Re-execute os testes ConnectGOOD com os parâmetros abaixo alterados. ALTER SYSTEM SET CURSOR_SHARING=FORCE; ALTER SYSTEM SET COMMIT_LOGGING=BATCH; 78
79 Lab: PL/SQL Engine Crie esta tabela com o usuário SCOTT: CREATE TABLE T76 (C1 NUMBER); Observe o conteúdo dos seguintes scripts Perl, os execute, e compare: $ time perl /home/oracle/semplsql.pl $ time perl /home/oracle/complsql.pl
80 Access Paths 80
81 Access Paths Full Table Scan (FTS) Table Access by ROWID Index Unique Scan Index Range Scan Index Range Scan descending Index Skip Scan Full Index Scan (FIS) Fast Full Index Scan (FFIS) 81
; Velocidade de leitura de múltiplos blocos x único bloco (System Statistics); Distribuição das linhas")
82 Full Table Scan Depende de: Percentual de dados que serão acessados; Quantidade de blocos lidos em leituras múltiplas (db_file_multiblock_read_count); Velocidade de leitura de múltiplos blocos x único bloco (System Statistics); Distribuição das linhas nos blocos; HWM. 82
83 MBRC: scatteread / sequential Em db file scatteread read ocorre db file sequential read quando: - O bloco está no final do Extent; - O bloco já está no cache; - Excede o limite do sistema operacional; - UNDO. 83
84 Lab: FTS e HWM Compare as estatísticas deste SELECT, antes e depois do DELETE. CREATE TABLE T84 AS SELECT * FROM ALL_OBJECTS; SET AUTOTRACE TRACEONLY SELECT COUNT(*) FROM T84; SELECT COUNT(*) FROM T84; SELECT COUNT(*) FROM T84; DELETE SELECT SELECT SELECT FROM T84; COUNT(*) FROM T84; COUNT(*) FROM T84; COUNT(*) FROM T84; 84
85 Lab: FTS e HWM Verifique os blocos utilizados pela tabela, antes e depois do DELETE. SET AUTOTRACE OFF DROP TABLE T84; CREATE TABLE T84 AS SELECT * FROM ALL_OBJECTS; SELECT MIN(DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)) MIN_BLK, MAX(DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)) MAX_BLK FROM T84; DELETE FROM T84; SELECT MIN(DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)) MIN_BLK, MAX(DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)) MAX_BLK FROM T84; ROLLBACK; SELECT MIN(DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)) MIN_BLK, MAX(DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)) MAX_BLK FROM T84; 85
86 Index Scan Index Unique Scan Index Range Scan Index Skip Scan Index Full Scan Index Fast Full Scan Por que ler todos blocos de um índice E os da tabela, e não só os da tabela? 86
87 Index Scan B-tree = Árvore Balanceada Root Block / Branch Blocks / Leaf Blocks Height / BEVEL (quando o Height / BLEVEL aumenta?) Average Leaf Blocks per Key / Average Data Blocks per Key Clustering Factor 87
88 Index Unique Scan 88
89 Index Unique Scan Utilizado com Primary Key ou Unique Key; Consistent Gets mínimo = (Rows x 2) + BLEVEL
90 Index Range Scan 90
91 Index Range Scan Utilizado com Primary Key, Unique Key, ou Non-unique Key; Consistent Gets mínimo = (Rows x 2) + BLEVEL
92 Index Range Scan - Sort 92
93 Index Full Scan 93
94 Index Full Scan Utilizado quando: Não há predicado, mas uma das colunas está indexada; Predicado não é a primeira coluna de um índice; Um índice pode economizar um SORT. 94
95 Index Full Scan Sem predicado, mas uma das colunas está indexada; Predicado não é a primeira coluna de um índice; Um índice pode economizar um SORT. 95
96 Index Full Scan Sem predicado, mas uma das colunas está indexada; Predicado não é a primeira coluna de um índice; Um índice pode economizar um SORT. 96
97 Index Full Scan Sem predicado, mas uma das colunas está indexada; Predicado não é a primeira coluna de um índice; Um índice pode economizar um SORT. 97
98 Index Full Scan 98
99 Index Full Scan 99
100 Index Skip Scan O predicado contém uma condição em uma coluna indexada, mas esta coluna não é a primeira do índice, e as primeiras colunas tem um baixo NDV. 100
101 Index Fast Full Scan Utilizado quando todas as colunas do SELECT estão incluídas no índice; Utiliza MBRC; Não há acesso à tabela; Não pode ser utilizado para evitar um SORT; Pelo menos uma das colunas do índice deve ser NOT NULL. 101
102 Join Methods & Options 102
103 Join Options Inner Join Outer Join Cross Join / Cartesian Joins Semi-Join Anti-Join 103
 / Probe Table (menor / INNER):")
104 Join Methods Nested Loops Hash Joins Sort-merge Joins Driving Table (maior / OUTER / BUILD / PK / UNIQUE) / Probe Table (menor / INNER): 104
105 Nested Loops É um LOOP dentro de um LOOP. É mais eficiente com pequenos Result Sets; Geralmente ocorre quando há índices nas colunas utilizadas pelo Join; Utiliza pouca memória, pois o Result Set é construído uma linha por vez; HINT: /*+ leading(order_itens ORDERS) use_nl(orders) index(orders(order_id)) */ HINT: /*+ leading(orders ORDER_ITENS) use_nl(order_itens) index(order_lines(order_id)) */ 105
106 Nested Loops SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10); SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10,20); SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO; Por que Rows = 5? SELECT COUNT(*) FROM EMP / SELECT COUNT(DISTINCT(DEPTNO)) FROM EMP; 106
107 Nested Loops CONN SCOTT/TIGER SET AUTOTRACE ON EXPLAIN SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10); SELECT /*+ leading(dept EMP) use_nl(emp) */ EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10); SELECT /*+ leading(emp DEPT) use_nl(dept) */ EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10); SET AUTOTRACE OFF SELECT /*+ GATHER_PLAN_STATISTICS */ EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO IN (10); SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); 107
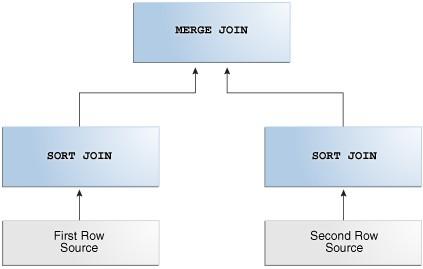
108 Sort-Merge Joins 108
109 Sort-Merge Joins Lê as duas tabelas de forma independente, ordena, e junta os Result Sets, descartando linhas que não combinam; Geralmente é utilizado para Result Sets maiores, e quando não há índices; Geralmente é utilizado quando é uma operação de desigualdade; O maior custo é a ordenação; Poderá ser utilizada apenas PGA, ou pode ser necessário TEMP; HINTs: USE_MERGE / NO_USE_MERGE SELECT EMPNO, ENAME, DNAME, LOC FROM EMP, DEPT WHERE EMP.DEPTNO = DEPT.DEPTNO AND DEPT.DEPTNO NOT IN (10); 109
110 Hash Joins Só ocorre em equi-joins; Geralmente é utilizado para grandes Result Sets; Geralmente é utilizado se o menor Result Set cabe em memória; A tabela com o menor Result Set é lida e armazenada em memória como um HASH; Em seguida a outra tabela (maior Result Set) é lida, é aplicado o HASH, e então comparada com a menor; Poderá ser utilizada apenas PGA, ou pode ser necessário TEMP; 110
111 Hash Joins CONN SCOTT/TIGER SET AUTOTRACE TRACEONLY EXPLAIN SELECT T1.ID, T2.NAME FROM T1, T2 WHERE T1.ID = T2.ID; SELECT /*+ USE_HASH (T1 T2) */ T1.ID, T2.NAME FROM T1, T2 WHERE T1.ID = T2.ID; SELECT /*+ USE_MERGE (T1 T2) */ T1.ID, T2.NAME FROM T1, T2 WHERE T1.ID = T2.ID; SELECT /*+ USE_NL (T1 T2) */ T1.ID, T2.NAME FROM T1, T2 WHERE T1.ID = T2.ID; 111
112 Índices 112
113 Índices B-tree Bitmap Bitmap Join IOT (Index-Organized Table) Function-Based Invisible Indexes (11g / OPTIMIZER_USE_INVISIBLE_INDEXES) Virtual Indexes Partitioned Indexes Partial Indexes (12c) Domain Indexes Compressed Ascending / Descending Table Clusters 113
114 Índices Bitmap Join CREATE BITMAP INDEX cust_sales_bji ON sales(customers.state) FROM sales, customers WHERE sales.cust_id = customers.cust_id; IOT (Index-Organized Table) CREATE TABLE locations (id NUMBER(10) NOT NULL, description VARCHAR2(50) NOT NULL, map BLOB, CONSTRAINT pk_locations PRIMARY KEY (id) ) ORGANIZATION INDEX TAB LESPACE iot_tablespace PCTTHRESHOLD 20 INCLUDING description OVERFLOW TABLESPACE overflow_tablespace; 114
115 Índices Invisible ALTER INDEX IDX_T INVISIBLE; ALTER INDEX IDX_T VISIBLE; Virtual CREATE INDEX IDX_T ON T(OBJECT_NAME) NOSEGMENT; Function Based CREATE INDEX IDX_T ON T(UPPER(OBJECT_NAME)); Partial Index ALTER TABLE T1 MODIFY PARTITION CREATE INDEX T1_IDX ON T1(YEAR) CREATE INDEX T1_IDX ON T1(YEAR) CREATE INDEX T1_IDX ON T1(YEAR) CREATE INDEX T1_IDX ON T1(YEAR) CREATE INDEX T1_IDX ON T1(YEAR) CREATE INDEX T1_IDX ON T1(YEAR) ANO_2014 INDEXING OFF; LOCAL; LOCAL INDEXING FULL; LOCAL INDEXING PARTIAL; GLOBAL; GLOBAL INDEXING FULL; GLOBAL INDEXING PARTIAL; 115
116 Índices - Guidelines Geral Controle: HINTs INDEX, INDEX_COMBINE, NO_INDEX, FULL; Crie índices em colunas utilizadas na cláusula WHERE; Crie índices em colunas utilizadas em JOINs; Crie índices em colunas de alta seletividade; Crie índices em colunas de baixa seletividade mas que contenham dados com seletividades muito distintas; Prefira índices PRIMARY KEY, se o modelo permitir; Prefira índices UNIQUE, se o modelo permitir, mas PRIMARY KEY não é possível; Crie índices compostos em colunas utilizadas frequentemente na mesma cláusula WHERE; Em índices compostos, utilize as colunas com maior seletividade à esquerda; Se um valor de uma coluna indexada não for utilizado em uma cláusula WHERE, verifique se este valor pode ser trocado para NULL; Busque sempre minimizar a quantidade de índices de uma tabela; Considere o espaço utilizado por um índice (60% - 40%). 116
117 Índices - Guidelines DML Crie índices em Foreign Keys (FKs) que sofrem DML de forma concorrente; Evite índices em colunas que sofrem muitos UPDATEs; Evite índices em tabelas que sofrem muitos INSERTs ou DELETEs. Tipos Prefira índices BTREE em colunas de alta seletividade (CPF, NF); Prefira índices BITMAP em colunas de baixa seletividade (ESTADO, CIDADE); Evite índices em colunas utilizadas em cláusula WHERE apenas com funções; Prefira índices BITMAP para grandes tabelas; Evite índices BITMAP em colunas que sofrem muito DML, principalmente de forma concorrente; Prefira partições HASH em índices pequenos que sofrem DML em alta concorrência; Utilize IOTs em PKs frequentemente utilizadas na cláusula WHERE; Utilize Function Based Index em colunas utilizadas em cláusula WHERE mais frequentemente com funções; Se um valor de uma coluna indexada utilizado em uma cláusula WHERE for raro, considere um Function Based Index: CREATE INDEX IDX_ORDER_NEW ON ORDERS(CASE STATUS WHEN 'N' THEN 'N' ELSE NULL END); 117
118 Índices - Table Clusters Utilize se as tabelas são frequentemente utilizadas em JOINs (NF e ITEM_NF); Utilize se as tabelas sofrem mais JOINs do que operações DML; Evite se é utilizado FTS de apenas uma das tabelas; Evite para linhas largas (PEDIDO_NOTA_FISCAL com OBS); Evite se o número de linhas nas chaves das duas tabelas é muito diferente. 118
119 BITMAP x BTREE SELECT COUNT(*) FROM T; COUNT(1) Sem índice. SELECT COUNT(DISTINCT(OWNER)) FROM T; -- Sem índice. COUNT(DISTINCT(OWNER)) 28 Decorrido: 00:00:26.75 SELECT COUNT(DISTINCT(OWNER)) FROM T; -- Com índice BTREE. COUNT(DISTINCT(OWNER)) 28 Decorrido: 00:00:05.29 SELECT COUNT(DISTINCT(OWNER)) FROM T; -- Com índice BITMAP. COUNT(DISTINCT(OWNER)) 28 Decorrido: 00:00:
120 BITMAP x BTREE SELECT COUNT(*) FROM T; COUNT(1) SELECT COUNT(DISTINCT(OWNER)) FROM T; COUNT(DISTINCT(OWNER)) 28 SELECT COUNT(DISTINCT(OBJECT_NAME)) FROM T; -- Com índice BTREE COUNT(DISTINCT(OBJECT_NAME)) Decorrido: 00:00:08.95 SELECT COUNT(DISTINCT(OBJECT_NAME)) FROM T; -- Com índice BITMAP COUNT(DISTINCT(OBJECT_NAME)) Decorrido: 00:00:
121 Lab: DML e BITMAP Index 1a Sessão: 2a Sessão: INSERT INTO T75 VALUES (1); INSERT INTO T75 VALUES (10); COMMIT; COMMIT; INSERT INTO T75 VALUES (1); INSERT INTO T75 VALUES (1); COMMIT; COMMIT; INSERT INTO T75 VALUES (1); INSERT INTO T75 VALUES (10); INSERT INTO T75 VALUES (10); INSERT INTO T75 VALUES (1); CREATE BITMAP INDEX IDX_BITMAP_T75 ON T75(C1); 121
122 Lab: Impacto de Índices Execute novamente o melhor script de INSERT, mas com a adição de índices como abaixo. $ $ $ $ cd /home/oracle time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl DROP INDEX IDX_BITMAP_T314; CREATE INDEX IDX_BTREE_T314 ON T314(C1); $ time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl $ time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl $ time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl DROP INDEX IDX_BTREE_T314; $ time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl $ time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl $ time perl ConnectGOOD_CommitGOOD_BindsGOOD_PERFECT.pl
123 Lab: Impacto de Índices Com o usuário SCOTT, crie uma tabela de testes, e verifique o tempo de sua duplicação. CREATE TABLE T123 AS SELECT * FROM ALL_OBJECTS; INSERT INTO T123 SELECT * FROM T123; INSERT INTO T123 SELECT * FROM T123; INSERT INTO T123 SELECT * FROM T123; INSERT INTO T123 SELECT * FROM T123; COMMIT; CREATE TABLE T123_2 AS SELECT * FROM T123 WHERE 1=0; SET TIMING ON INSERT INTO T123_2 SELECT * FROM T123; TRUNCATE TABLE T123_2; INSERT INTO T123_2 SELECT * FROM T123; TRUNCATE TABLE T123_2; INSERT INTO T123_2 SELECT * FROM T123; TRUNCATE TABLE T123_2; 123
124 Lab: Impacto de Índices Verifique o tempo de sua duplicação, mas com índices. CREATE INDEX T123_2_IDX_01 ON T123_2(OWNER); INSERT INTO T123_2 SELECT * FROM T123; TRUNCATE TABLE T123_2; INSERT INTO T123_2 SELECT * FROM T123; TRUNCATE TABLE T123_2; INSERT INTO T123_2 SELECT * FROM T123; TRUNCATE TABLE T123_2; CREATE INDEX T123_2_IDX_02 ON T8(OBJECT_NAME); INSERT INTO T123_2 SELECT * FROM T123; TRUNCATE TABLE T123_2; INSERT INTO T123_2 SELECT * FROM T123; TRUNCATE TABLE T123_2; INSERT INTO T8 SELECT * FROM T123; TRUNCATE TABLE T123_2; 124
125 Lab: Impacto de Índices Verifique o tempo de sua duplicação, mas um índice composto. DROP INDEX T123_2_IDX_01; DROP INDEX T123_2_IDX_02; CREATE INDEX T123_2_IDX_03 ON T8(OWNER,OBJECT_NAME); INSERT INTO T123_2 SELECT * FROM T123; TRUNCATE TABLE T123_2; INSERT INTO T123_2 SELECT * FROM T123; TRUNCATE TABLE T123_2; INSERT INTO T123_2 SELECT * FROM T123; TRUNCATE TABLE T123_2; 125
126 Lab: Impacto de Índices Verifique o uso dos índices. CONN SCOTT/TIGER DROP INDEX T123_2_IDX_03; INSERT INTO T123_2 SELECT * FROM T123; CREATE INDEX T123_2_IDX_01 ON T123_2(OWNER); CREATE INDEX T123_2_IDX_02 ON T123_2(OBJECT_NAME); ALTER INDEX T123_2_IDX_01 MONITORING USAGE; ALTER INDEX T123_2_IDX_02 MONITORING USAGE; FROM COL INDEX_NAME FORMAT A40 SELECT INDEX_NAME, MONITORING, USED FROM V$OBJECT_USAGE; SELECT COUNT(*) FROM T123_2 WHERE OWNER = 'SCOTT'; SELECT COUNT(*) FROM T123_2 WHERE OWNER = 'SYS'; SELECT COUNT(*) FROM T123_2 WHERE OWNER = 'SYSTEM'; SELECT INDEX_NAME, MONITORING, USED, START_MONITORING V$OBJECT_USAGE; Problemas a se considerar ao remover índices: - Não está utilizando o índice, mas deveria utilizar; - Após o DROP, não é utilizado outro índice; - Uso da seletividade em índices compostos, mesmo sem utilizar a coluna; - FKs (Enqueue TM). 126
127 Estatísticas 127
 Extended statistics Index statistics Number of leaf blocks Average data blocks per Key Levels Index clustering factor System Statistics I/O performance and")
128 Estatísticas e SQL Engine Optimizer Statistics Table statistics Number of rows Number of blocks Average row length Column statistics Number of distinct values (NDV) in column Number of nulls in column Data distribution (histogram) Extended statistics Index statistics Number of leaf blocks Average data blocks per Key Levels Index clustering factor System Statistics I/O performance and utilization CPU performance and utilization 128
129 Estatísticas - Tabela DBA_TABLES / ALL_TABLES / USER_TABLES SELECT TABLE_NAME, NUM_ROWS, BLOCKS, EMPTY_BLOCKS, AVG_SPACE, CHAIN_CNT, AVG_ROW_LEN, SAMPLE_SIZE, LAST_ANALYZED FROM USER_TABLES ORDER BY 1; 129
130 Estatísticas - Índices DBA_INDEXES / ALL_INDEXES / USER_INDEXES SELECT TABLE_NAME, INDEX_NAME, NUM_ROWS, BLEVEL, LEAF_BLOCKS, DISTINCT_KEYS, CLUSTERING_FACTOR, AVG_LEAF_BLOCKS_PER_KEY, AVG_DATA_BLOCKS_PER_KEY, SAMPLE_SIZE, LAST_ANALYZED FROM USER_INDEXES ORDER BY 1,2; 130

131 Estatísticas - Colunas DBA_TAB_COLUMNS / ALL_TAB_COLUMNS / USER_TAB_COLUMNS SELECT TABLE_NAME, COLUMN_NAME, NUM_DISTINCT, NUM_NULLS, DENSITY, LOW_VALUE, HIGH_VALUE, DATA_LENGTH, AVG_COL_LEN, SAMPLE_SIZE, LAST_ANALYZED FROM USER_TAB_COLUMNS ORDER BY 1,2; 131
132 Quando coletar? Coleta automática 132
133 Quando coletar? Coleta automática 133
134 Quando coletar? Coleta automática 134
135 Quando coletar? STALE 135
136 Quando coletar? STALE 136
137 Quando coletar? 137
138 Quando coletar? Coleta manual Coleta completa EXEC EXEC EXEC EXEC DBMS_STATS.GATHER_DATABASE_STATS; DBMS_STATS.GATHER_SCHEMA_STATS('SOE'); DBMS_STATS.GATHER_TABLE_STATS('SOE','CUSTOMERS'); DBMS_STATS.GATHER_INDEX_STATS('SOE','CUSTOMERS_PK'); Coleta de objetos EMPTY e STALE EXEC DBMS_STATS.GATHER_DATABASE_STATS(OPTIONS=>'GATHER EMPTY'); EXEC DBMS_STATS.GATHER_SCHEMA_STATS('SOE',OPTIONS=>'GATHER EMPTY'); EXEC DBMS_STATS.GATHER_DATABASE_STATS(OPTIONS=>'GATHER STALE'); EXEC DBMS_STATS.GATHER_SCHEMA_STATS('SOE',OPTIONS=>'GATHER STALE'); 138
139 Quando coletar? Coleta manual 139
140 Quando coletar? OPTIMIZER_DYNAMIC_SAMPLING Nível 0 = Não há coleta. Nível 1 = Coleta 32 blocos. Se há pelo menos 1 tabela particionada no SQL sem estatísticas. Se esta tabela não tem índices. Se esta tabela tem mais que 64 blocos. Nível 2 = Coleta 64 blocos. Coleta se há pelo menos uma tabela do SQL sem estatísticas. Nível 3 = Coleta 64 blocos. Coleta se o Nível 2 é atendido OU se é utilizada expressão no WHERE. Nível 4 = Coleta 64 blocos. Coleta se o nível 3 é atendido OU se o SQL utiliza AND ou OR entre múltiplos predicados. Nível 5 = Coleta 128 blocos. Coleta se o nível 4 é atendido. Nível 6 = Coleta 256 blocos. Coleta se o nível 4 é atendido. Nível 7 = Coleta 512 blocos. Coleta se o nível 4 é atendido. Nível 8 = Coleta 1024 blocos. Coleta se o nível 4 é atendido. Nível 9 = Coleta 4086 blocos. Coleta se o nível 4 é atendido. Nível 10 = Coleta todos os blocos. Coleta se o nível 4 é atendido. Nível 11 (Adaptive Dynamic Sampling: >= ) = Coleta? Blocos. Coleta quando? 140
141 Quando coletar? OPTIMIZER_DYNAMIC_SAMPLING 141
142 Quando coletar? OPTIMIZER_DYNAMIC_SAMPLING 142

143 Como (não) coletar? ANALYZE ANALYZE ANALYZE ANALYZE ANALYZE TABLE TABLE TABLE TABLE CUSTOMERS CUSTOMERS CUSTOMERS CUSTOMERS VALIDATE VALIDATE VALIDATE VALIDATE STRUCTURE; STRUCTURE CASCADE; STRUCTURE CASCADE FAST; STRUCTURE CASCADE ANALYZE TABLE CUSTOMERS LIST CHAINED ROWS INTO CHAINED_ROWS; 143
144 Como (não) coletar? ANALYZE 144
145 Como (não) coletar? ANALYZE 145
146 Como coletar? Opções ESTIMATE_PERCENT DBMS_STATS.AUTO_SAMPLE_SIZE / N BLOCK_SAMPLE FALSE / TRUE DEGREE NULL / N GRANULARITY AUTO / ALL / DEFAULT / GLOBAL / GLOBAL AND PARTITION / PARTITION / SUBPARTITION CASCADE DBMS_STATS.AUTO_CASCADE / TRUE / FALSE OPTIONS GATHER / GATHER AUTO / GATHER STALE / GATHER EMPTY GATHER_SYS TRUE / FALSE 146
147 Como coletar? Histogramas METHOD_OPT FOR ALL COLUMNS SIZE AUTO FOR ALL [INDEXED HIDDEN] COLUMNS SIZE [N REPEAT AUTO SKEWONLY] FOR COLUMNS column SIZE [N REPEAT AUTO SKEWONLY] Exemplos: FOR ALL COLUMNS SIZE 1 FOR ALL COLUMNS SIZE 100 FOR ALL COLUMNS SIZE AUTO FOR ALL COLUMNS SIZE REPEAT FOR ALL COLUMNS SIZE SKEWONLY FOR ALL INDEXED COLUMNS SIZE 1 FOR ALL INDEXED COLUMNS SIZE 100 FOR ALL INDEXED COLUMNS SIZE AUTO FOR ALL INDEXED COLUMNS SIZE REPEAT FOR ALL INDEXED COLUMNS SIZE SKEWONLY FOR COLUMNS C1 SIZE 1 FOR COLUMNS C1 SIZE 100 FOR COLUMNS C1 SIZE AUTO FOR COLUMNS C1 SIZE REPEAT FOR COLUMNS C1 SIZE SKEWONLY 147

148 Como coletar? Histogramas DBA_TAB_COLUMNS / ALL_TAB_COLUMNS / USER_TAB_COLUMNS DBA_TAB_HISTOGRAMS / ALL_TAB_HISTOGRAMS / USER_TAB_HISTOGRAMS SELECT H.TABLE_NAME, H.COLUMN_NAME, C.HISTOGRAM, H.ENDPOINT_NUMBER, H.ENDPOINT_ACTUAL_VALUE, H.ENDPOINT_REPEAT_COUNT FROM USER_TAB_HISTOGRAMS H, USER_TAB_COLUMNS C WHERE H.TABLE_NAME = C.TABLE_NAME AND H.COLUMN_NAME = C.COLUMN_NAME AND HISTOGRAM <> 'NONE' ORDER BY 1,2,4; 148
149 Como coletar? Histogramas Buckets: máximo de 254 / 127 (2048 no 12c); Frequency Histograms; Height-Balanced Histograms; Top Frequency Histograms (12c); Hybrid Histograms (12c). 149

150 Como coletar? Histogramas - Frequency Utilizados se: - Se o NDV é menor ou igual que a quantidade de Buckets indicados na coleta; - É utilizado AUTO_SAMPLE_SIZE na execução da coleta. 150

151 Como coletar? Histogramas Height Balanced Utilizados se: - Se o número de Buckets indicados na coleta é menor que o NDV. 151

152 Como coletar? Histogramas Top Frequency Utilizados se: - Se o NDV é maior que a quantidade de Buckets indicados na coleta; - É utilizado AUTO_SAMPLE_SIZE na execução da coleta; - Se o percentual de linhas ocupadas pelos Top Values é igual ou maior que p, sendo que p = (1-(1/Buckets))*


153 Como coletar? Histogramas - Hybrid Utilizados se: - Se o número de Buckets indicados na coleta é menor que o NDV; - É utilizado AUTO_SAMPLE_SIZE na execução da coleta; - Se os critétios para Top Frequency Histograms não se aplicam. 153
154 Execution Plan CONN SCOTT/TIGER ALTER SESSION SET OPTIMIZER_DYNAMIC_SAMPLING = 0; EXEC DBMS_STATS.DELETE_TABLE_STATS(USER, 'T7'); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, = 'TABLE'; 'ALLSTATS LAST')); = 'DIRECTORY'; 'ALLSTATS LAST')); = 'SYNONYM'; 'ALLSTATS LAST'));
155 Execution Plan EXEC DBMS_STATS.DELETE_TABLE_STATS(USER, 'T7'); EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'T7', ESTIMATE_PERCENT=>100, METHOD_OPT=>'FOR ALL COLUMNS SIZE 1'); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'TABLE'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'DIRECTORY'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'SYNONYM'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST'));
156 Execution Plan EXEC DBMS_STATS.DELETE_TABLE_STATS(USER, 'T7'); EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'T7', ESTIMATE_PERCENT=>100, METHOD_OPT=> 'FOR ALL COLUMNS SIZE 5'); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'TABLE'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'DIRECTORY'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE = 'SYNONYM'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST'));
157 Execution Plan EXEC DBMS_STATS.DELETE_TABLE_STATS(USER, 'T7'); EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'T7'); SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, SELECT COUNT(OBJECT_NAME) FROM SCOTT.T7 WHERE OBJECT_TYPE SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, = 'TABLE'; 'ALLSTATS LAST')); = 'DIRECTORY'; 'ALLSTATS LAST')); = 'SYNONYM'; 'ALLSTATS LAST'));
158 Quanto coletar? AUTO_SAMPLE ou ESTIMATE_PERCENT 158
159 Quanto coletar? AUTO_SAMPLE ou ESTIMATE_PERCENT 159
160 Outras estatísticas Fixed Objects Statistics (V$SQL, V$SESSION, etc.) EXEC DBMS_STATS.GATHER_FIXED_OBJECTS_STATS; Dictionary Statistics (DBA_SEGMENTS, DBA_TABLES, etc.); EXEC DBMS_STATS.GATHER_DICTIONARY_STATS; System Statistcs (CPU e I/O) EXEC DBMS_STATS.GATHER_SYSTEM_STATS; OU EXEC DBMS_STATS.GATHER_SYSTEM_STATS('START');... EXEC DBMS_STATS.GATHER_SYSTEM_STATS('STOP'); OU EXEC DBMS_STATS.GATHER_SYSTEM_STATS('EXADATA'); 160
161 Como coletar? Controle de Opções EXEC DBMS_STATS.SET_DATABASE_PREFS('DEGREE','2'); EXEC DBMS_STATS.SET_SCHEMA_PREFS('SOE','CASCADE','TRUE'); EXEC DBMS_STATS.SET_TABLE_PREFS('SOE','CUSTOMERS','STALE_PERCENT',5); CASCADE DEGREE ESTIMATE_PERCENT GRANULARITY INCREMENTAL INCREMENTAL_LEVEL INCREMENTAL_STALENESS METHOD_OPT NO_INVALIDATE PUBLISH STALE_PERCENT TABLE_CACHED_BLOCKS OPTIONS 161
162 Como coletar? Coleta geral EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT=>DBMS_STATS.AUTO_SAMPLE_SIZE, BLOCK_SAMPLE=>FALSE, DEGREE=>8, GRANULARITY=>'AUTO', CASCADE=>TRUE, OPTIONS=>'GATHER EMPTY', GATHER_SYS=>FALSE, NO_INVALIDATE=>FALSE, METHOD_OPT=>'FOR ALL COLUMNS SIZE AUTO'); EXEC DBMS_STATS.GATHER_DATABASE_STATS (ESTIMATE_PERCENT=>DBMS_STATS.AUTO_SAMPLE_SIZE, BLOCK_SAMPLE=>FALSE, DEGREE=>8, GRANULARITY=>'AUTO', CASCADE=>TRUE, OPTIONS=>'GATHER STALE', GATHER_SYS=>FALSE, NO_INVALIDATE=>FALSE, METHOD_OPT=>'FOR ALL COLUMNS SIZE AUTO'); 162
163 Como coletar? Coleta por exceção EXEC DBMS_STATS.UNLOCK_TABLE_STATS('SCOTT','EMP'); EXEC DBMS_STATS.GATHER_TABLE_STATS ('SCOTT', 'EMP', ESTIMATE_PERCENT=>DBMS_STATS.AUTO_SAMPLE_SIZE, BLOCK_SAMPLE=>FALSE, DEGREE=>16, GRANULARITY=>'PARTITION', CASCADE=>TRUE, OPTIONS=>'GATHER', NO_INVALIDATE=>FALSE, METHOD_OPT=>'FOR COLUMNS EMPNO SIZE REPEAT'); EXEC DBMS_STATS.LOCK_TABLE_STATS('SCOTT','EMP'); 163
164 Resumo Quando coletar? Quando ocorre uma alteração significativa (%) nos objetos. Na maioria dos casos, isto não ocorre todos os dias. Não espere alguém te avisar: monitore objetos STALE. Não espere alguém te avisar: monitore diferenças entre E-rows e A-rows. Reduza o STALE PERCENT em grandes objetos. Fique atento às alterações que influenciam as Outras Estatísticas. Quanto coletar? Do 11gR1 em diante, o AUTO_SAMPLE faz coletas excelentes na maioria dos casos. Em coleta de exceção, aumente o ESTIMATE_PERCENT em casos onde dados não foram encontrados. O ESTIMATE_PERCENT proíbe os novos tipos de Histogramas do 12c. Como coletar? Cancele a coleta automática. Crie uma coleta manual geral agendada, e a monitore. Se necessário, crie outra coleta manual de exceção agendada, e monitore. Na coleta geral, controle o DEGREE de acordo com seu ambiente. Em coleta de exceção, aumente o DEGREE para grandes objetos. Em coleta de exceção, altere METHOD_OPT para colunas sensíveis. Não colete de objetos altamente voláteis. Use OPTIMIZER_DYNAMIC_SAMPLING. 164
165 Análise de Planos de Execução 165
166 Análise de Plano 166
167 Análise de Plano HINT /*+ GATHER_PLAN_STATISTICS */ Parâmetro STATISTICS_LEVEL = ALL 167

 oratop (MOS")
168 Análise de Plano SQLT (MOS ) oratop (MOS ) 168
169 Estabilidade de Plano 169
170 Evolução de Shared SQL - Bind Variable - CURSOR_SHARING - Bind Variable Peeking (9i) - Extended Cursor Sharing / Adaptive Cursor Sharing (11gR1) - Cardinality Feedback (11gR2) - Adaptive Optimizer / Automatic Reoptimization / Adaptive Plan (12cR1) 170
171 Evolução de Estabilidade do Plano HINTs (Session: _OPTIMIZER_IGNORE_HINTS = TRUE) Parâmetros de Controle do CBO Parâmetros ocultos de Controle do CBO Stored Outlines SQL Profiles (DBA_SQL_PROFILES) (10g) SQL Plan Baselines (11g) SQL Plan Directives (12c) 171

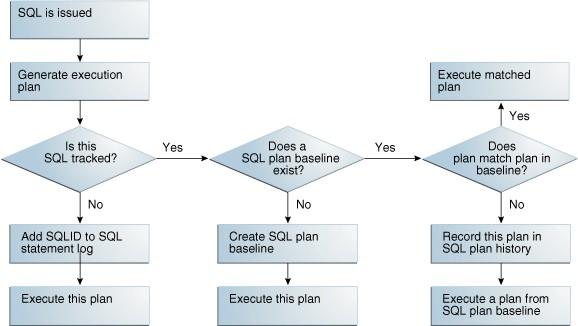
172 Baselines 172
173 Baselines Consulta: DBA_SQL_PLAN_BASELINES Carregar Baselines Automaticamente: ALTER SYSTEM SET OPTIMIZER_CAPTURE_SQL_PLAN_BASELINES=TRUE; ALTER SYSTEM SET OPTIMIZER_USE_SQL_PLAN_BASELINES=TRUE; Carregar Baselines manualmente: EXEC DBMS_SPM.LOAD_PLANS_FROM_CURSOR_CACHE(ATTRIBUTE_NAME=>'SQL TEXT', ATTRIBUTE_VALUE=>'%SELECT ID, NAME FROM T1%') EXEC DBMS_SPM.LOAD_PLANS_FROM_CURSOR_CACHE(SQL_ID=>' ', PLAN_HASH_VALUE=>'ABCDEFGH'); 173
174 Baselines Evoluir Baselines: SET LONG SELECT DBMS_SPM.EVOLVE_SQL_PLAN_BASELINE(sql_handle => 'SYS_SQL_7b76323ad90440b9') FROM DUAL; Remover Baselines: DECLARE i NATURAL; BEGIN i := DBMS_SPM.DROP_SQL_PLAN_BASELINE('SQL_0c a16450'); DBMS_OUTPUT.PUT_LINE(i); END; / 174
175 Baselines CONN / AS SYSDBA ALTER SYSTEM SET OPTIMIZER_CAPTURE_SQL_PLAN_BASELINES=TRUE; ALTER SYSTEM SET OPTIMIZER_USE_SQL_PLAN_BASELINES=TRUE; CONN SCOTT/TIGER CREATE TABLE T AS SELECT * FROM ALL_OBJECTS; SELECT COUNT(DISTINCT(OWNER)) FROM T; SELECT SQL_TEXT, SQL_HANDLE, PLAN_NAME, ENABLED, ACCEPTED FROM DBA_SQL_PLAN_BASELINES; CREATE BITMAP INDEX T_INDEX_01 ON T(OWNER); SET SERVEROUTPUT ON DECLARE EVOLVE_OUT CLOB; BEGIN EVOLVE_OUT := DBMS_SPM.EVOLVE_SQL_PLAN_BASELINE (SQL_HANDLE => 'SQL_0C A16450', COMMIT => 'YES'); DBMS_OUTPUT.PUT_LINE(EVOLVE_OUT); END; / SELECT COUNT(DISTINCT(OWNER)) FROM T; SELECT SQL_TEXT, SQL_HANDLE, PLAN_NAME, ENABLED, ACCEPTED FROM DBA_SQL_PLAN_BASELINES; 175

176 Adaptive Plans
177 Lab: Adaptive Plans Execute o SQL abaixo duas vezes, comparando o Plano Real de Execução. $ sqlplus OE/OE SELECT o.order_id, v.product_name FROM orders o, ( SELECT order_id, product_name FROM order_items o, product_information p WHERE p.product_id = o.product_id AND list_price < 50 AND min_price < 40 ) v WHERE o.order_id = v.order_id; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'+ALLSTATS')); SELECT o.order_id, v.product_name FROM orders o, ( SELECT order_id, product_name FROM order_items o, product_information p WHERE p.product_id = o.product_id AND list_price < 50 AND min_price < 40 ) v WHERE o.order_id = v.order_id; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'+ALLSTATS')); 177
178 Lab: Adaptive Plans Verifique a diferença entre os dois Cursores. SELECT SQL_ID, CHILD_NUMBER, SQL_TEXT FROM V$SQL WHERE SQL_TEXT LIKE '%list_price <%'; SELECT CHILD_NUMBER, CPU_TIME, ELAPSED_TIME, BUFFER_GETS FROM V$SQL WHERE SQL_ID = 'gm2npz344xqn8'; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('gm2npz344xqn8', 0, 'ALLSTATS LAST')); SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('gm2npz344xqn8', 1, 'ALLSTATS LAST')); 178
179 Lab: Adaptive Plans Execute o SQL abaixo duas vezes, comparando o Plano Real de Execução. $ sqlplus OE/OE EXPLAIN PLAN FOR SELECT product_name FROM order_items o, product_information p WHERE o.unit_price = 15 AND quantity > 1 AND p.product_id = o.product_id; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY); SELECT product_name FROM order_items o, product_information p WHERE o.unit_price = 15 AND quantity > 1 AND p.product_id = o.product_id; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'+ALLSTATS LAST')); SELECT product_name FROM order_items o, product_information p WHERE o.unit_price = 15 AND quantity > 1 AND p.product_id = o.product_id; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'+ALLSTATS LAST +ADAPTIVE')); 179
180 Otimizações 180
181 Lab: Append e Redo Crie uma tabela de testes, e execute uma gravação, com parâmetros diferentes. CONN SCOTT/TIGER CREATE TABLE T131 AS SELECT * FROM ALL_OBJECTS WHERE 1=0; SET AUTOTRACE TRACEONLY INSERT INTO T131 SELECT INSERT INTO T131 SELECT INSERT INTO T131 SELECT STATISTICS * FROM ALL_OBJECTS; * FROM ALL_OBJECTS; * FROM ALL_OBJECTS; INSERT /*+ APPEND */ INTO T131 SELECT * FROM ALL_OBJECTS; INSERT /*+ APPEND */ INTO T131 SELECT * FROM ALL_OBJECTS; O que aconteceu? INSERT /*+ APPEND */ INTO T131 SELECT * FROM ALL_OBJECTS; ALTER TABLE T131 NOLOGGING; INSERT /*+ APPEND */ INTO T131 SELECT * FROM ALL_OBJECTS; INSERT /*+ APPEND */ INTO T131 SELECT * FROM ALL_OBJECTS; INSERT /*+ APPEND */ INTO T131 SELECT * FROM ALL_OBJECTS; Qual a diferença exibida pelo SET AUTOTRACE TRACEONLY STATISTICS? 181
182 Paralelismo Permite Query, DML e DDL. Quantos processos de paralelismo utilizar? Um objeto pode ter Parallel permanente, independente do SQL: ALTER TABLE SCOTT.T PARALLEL 4; O Parallel SQL pode ser utilizado diretamente no SQL: SELECT /*+ PARALLEL(T2 4) */ COUNT(*) FROM T2; SELECT /*+ PARALLEL(T2 4,2) */ COUNT(*) FROM T2; 182
183 Paralelismo Parâmetros: PARALLEL_MIN_SERVERS = Número entre 0 e PARALLEL_MAX_SERVERS. PARALLEL_MAX_SERVERS = De 0 a PARALLEL_MIN_PERCENT = De 0 a 100. PARALLEL_DEGREE_POLICY = MANUAL, LIMITED ou AUTO. PARALLEL_MIN_TIME_THRESHOLD = AUTO Segundos. PARALLEL_ADAPTIVE_MULTI_USER = true ou false. PARALLEL_DEGREE_LIMIT = CPU, IO ou Número. PARALLEL_SERVERS_TARGET = Número entre 0 e PARALLEL_MAX_SERVERS. PARALLEL_THREADS_PER_CPU = Qualquer número. PARALLEL_EXECUTION_MESSAGE_SIZE = De 2148 a PARALLEL_FORCE_LOCAL = true ou false. PARALLEL_INSTANCE_GROUP = Oracle RAC service_name ou group_name. PARALLEL_AUTOMATIC_TUNING: Deprecated. PARALLEL_IO_CAP_ENABLED = Deprecated. 183
184 Paralelismo SELECT SID, SERIAL#, QCSID, QCSERIAL# FROM V$PX_SESSION; SID SERIAL# QCSID QCSERIAL#
185 Lab: Paralelismo Abra a sessão com o SCOTT com SET TIMING ON. Em seguida, faça o teste do PARALLEL. CONN SCOTT/TIGER CREATE TABLE T132 AS SELECT * FROM ALL_OBJECTS; 7 x INSERT INTO T132 SELECT * FROM T132; COMMIT; Repita a operação com PARALLEL, e compare. SET TIMING ON SELECT COUNT(*) FROM T132; SELECT /*+ PARALLEL(T132 4) */ COUNT(*) FROM T132; SELECT /*+ PARALLEL(T132 20) */ COUNT(*) FROM T132; SELECT /*+ PARALLEL(T132 40) */ COUNT(*) FROM T132; Qual a diferença exibida pelo SET TIMING ON? 185
186 Lab: RESULT_CACHE Execute o teste do RESULT_CACHE. CONN SCOTT/TIGER CREATE TABLE T133 AS SELECT * FROM ALL_OBJECTS; 7 x INSERT INTO T133 SELECT * FROM T133; COMMIT; SET TIMING ON SET AUTOTRACE ON SELECT COUNT(*) FROM T133; SELECT COUNT(*) FROM T133; SELECT COUNT(*) FROM T133; SELECT /*+ RESULT_CACHE */ COUNT(*) FROM T133; SELECT /*+ RESULT_CACHE */ COUNT(*) FROM T133; SELECT /*+ RESULT_CACHE */ COUNT(*) FROM T133; DELETE FROM T133 WHERE ROWNUM = 1; SELECT /*+ RESULT_CACHE */ COUNT(*) FROM T133; 186


187 Compression 10g OLAP 11g OLTP 12c InMemory 187
188 Lab: Compression Execute o teste do COMPRESSION. CONN SCOTT/TIGER CREATE TABLE T134 AS SELECT * FROM ALL_OBJECTS; 7 x INSERT INTO T134 SELECT * FROM T134; COMMIT; SET TIMING ON SELECT COUNT(*) FROM T134; SELECT COUNT(*) FROM T134; SELECT COUNT(*) FROM T134; ALTER TABLE T134 COMPRESS; ALTER TABLE T134 MOVE; SELECT COUNT(*) FROM T134; SELECT COUNT(*) FROM T134; SELECT COUNT(*) FROM T134; 188
189 Lab: CTAS Execute o teste de DELETE x CTAS (CREATE TABLE AS SELECT). CONN SCOTT/TIGER CREATE TABLE T135 AS 7 x INSERT INTO T135 COMMIT; SELECT COUNT(*) FROM SELECT COUNT(*) FROM SELECT * FROM ALL_OBJECTS; SELECT * FROM T135; T135; T135 WHERE OBJECT_TYPE = 'SYNONYM'; SET TIMING ON DELETE FROM T135 WHERE OBJECT_TYPE = 'SYNONYM'; ROLLBACK; CREATE TABLE T135TEMP AS SELECT * FROM T135 WHERE OBJECT_TYPE!= 'SYNONYM'; DROP TABLE T135; ALTER TABLE T135TEMP RENAME TO T135; 189
190 Ferramentas Avançadas 190

191 DBMS_SQLTUNE 191
192 Lab: DBMS_SQLTUNE CONN SCOTT/TIGER CREATE TABLE T121 AS SELECT * FROM ALL_OBJECTS; SELECT COUNT(DISTINCT(OWNER)) FROM T121; Execute o SQL_TUNE nos SQLs analizados. CONN / AS SYSDBA DECLARE RET_VAL VARCHAR2(4000); BEGIN RET_VAL := DBMS_SQLTUNE.CREATE_TUNING_TASK(SQL_ID => '32c784ar99d68', SCOPE => DBMS_SQLTUNE.SCOPE_COMPREHENSIVE, TIME_LIMIT => 60, TASK_NAME => 'Portilho Tuning Task', DESCRIPTION => 'Portilho Tuning Task'); END; / EXEC DBMS_SQLTUNE.EXECUTE_TUNING_TASK('Portilho Tuning Task'); FROM SET LONG 9000 SELECT DBMS_SQLTUNE.REPORT_TUNING_TASK('Portilho Tuning Task') FROM DUAL; SELECT DBMS_SQLTUNE.SCRIPT_TUNING_TASK('Portilho Tuning Task') RECOMMENTATION DUAL; Remova o SQL_TUNE executado, após executar a correção. EXEC DBMS_SQLTUNE.DROP_TUNING_TASK('Portilho Tuning Task'); O SQL_TUNE requer as Options Diagnostics Pack e Tuning Pack. 192
193 Lab: SQLT - Instalação MOS Doc ID : SQLT Diagnostic Tool Execute a instalação do SQLT. $ unzip sqlt.zip $ cd sqlt/install $ sqlplus / AS <ENTER> Nerv2015 <ENTER> Nerv2015 <ENTER> USERS <ENTER> TEMP <ENTER> SCOTT <ENTER> T <ENTER> GRANT GRANT GRANT GRANT GRANT SQLT_USER_ROLE SQLT_USER_ROLE SQLT_USER_ROLE SQLT_USER_ROLE SQLT_USER_ROLE TO TO TO TO TO OE; SH; SHSB; SHSBP; HR; 193
194 Lab: SQLTXPLAIN - Extração Verifique os SQL_ID dos SQL executados pelos dois SCHEMAS. $ cd /home/oracle CONN / AS SELECT SQL_ID, CHILD_NUMBER, SQL_TEXT FROM V$SQL WHERE PARSING_SCHEMA_NAME = 'SHSB' ORDER BY 2 DESC; Extraia o Relatório SQLT dos SQL_ID executados pelos dois SCHEMAS. $ cd sqlt/run $ sqlplus 2jb7w23a4ad72 Nerv2015 <ENTER> $ unzip sqlt_s36985_xtract_grgrdq5ja4a1x.zip $ firefox sqlt_s36985_main.html 194
195 Documentação - Obrigatória
196 Documentação - Performance


197 Livros - Obrigatórios



198 Livros Intermediário, Avançado, Muito Avançado
Oracle Tuning SQL. Em Oracle Enterprise Edition 18c (RU ) Em CDB Architecture Em Oracle Enterprise Linux 7.5
 Em CDB Architecture Em Oracle Enterprise Linux 7.5") Oracle Tuning SQL Em Oracle Enterprise Edition 18c (RU 18.3.0.0) Em CDB Architecture Em Oracle Enterprise Linux 7.5 Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a
Oracle Tuning SQL Em Oracle Enterprise Edition 18c (RU 18.3.0.0) Em CDB Architecture Em Oracle Enterprise Linux 7.5 Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a
Oracle Tuning SQL. Em Oracle Enterprise Edition 19c Em CDB Architecture Em Oracle Enterprise Linux 7.6
 Oracle Tuning SQL Em Oracle Enterprise Edition 19c Em CDB Architecture Em Oracle Enterprise Linux 7.6 Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative
Oracle Tuning SQL Em Oracle Enterprise Edition 19c Em CDB Architecture Em Oracle Enterprise Linux 7.6 Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative
Oracle Tuning SQL. Em Oracle Enterprise Edition Em Oracle Enterprise Linux 7.3 Modo Texto Inclui CDB Architecture
 Oracle Tuning SQL Em Oracle Enterprise Edition 12.2.0.1 Em Oracle Enterprise Linux 7.3 Modo Texto Inclui CDB Architecture Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada
Oracle Tuning SQL Em Oracle Enterprise Edition 12.2.0.1 Em Oracle Enterprise Linux 7.3 Modo Texto Inclui CDB Architecture Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada
Estatísticas. Quando coletar? Quanto coletar? Como coletar? Ricardo Portilho Proni Nerv Informática
 Estatísticas Quando coletar? Quanto coletar? Como coletar? Ricardo Portilho Proni ricardo@informatica.com.br Nerv Informática Isenção de responsabilidade Não acredite em tudo o que lê. Por algo estar escrito,
Estatísticas Quando coletar? Quanto coletar? Como coletar? Ricardo Portilho Proni ricardo@informatica.com.br Nerv Informática Isenção de responsabilidade Não acredite em tudo o que lê. Por algo estar escrito,
Oracle Tuning: SQL. Ricardo Portilho Proni ricardo@nervinformatica.com.br
 Oracle Tuning: SQL Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative Commons Atribuição-SemDerivados 3.0 Brasil. Para ver uma cópia desta licença, visite
Oracle Tuning: SQL Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative Commons Atribuição-SemDerivados 3.0 Brasil. Para ver uma cópia desta licença, visite
Oracle Tuning Índices
 Oracle Tuning Índices Em Oracle Enterprise Edition 18c (RU 18.3.0.0) Em CDB Architecture Em Oracle Enterprise Linux 7.5 Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob
Oracle Tuning Índices Em Oracle Enterprise Edition 18c (RU 18.3.0.0) Em CDB Architecture Em Oracle Enterprise Linux 7.5 Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob
1) Cópia das tabelas Countries, Customers, Sales e Products em seu esquema (estrutura e dados sem índices).
 Cópia das tabelas Countries, Customers, Sales e Products em seu esquema (estrutura e dados sem índices).") 1) Cópia das tabelas Countries, Customers, Sales e Products em seu esquema (estrutura e dados sem índices). create table Countries as select * from sh.countries; create table Customers as select * from
1) Cópia das tabelas Countries, Customers, Sales e Products em seu esquema (estrutura e dados sem índices). create table Countries as select * from sh.countries; create table Customers as select * from
Administração de Banco de Dados
 Administração de Banco de Dados Aula 6 Prof. Marcos Alexandruk Aula 6 Estruturas lógicas do Oracle: Tabelas tabelas relacionais tabelas temporárias tabelas organizadas por índices tabelas de objetos tabelas
Administração de Banco de Dados Aula 6 Prof. Marcos Alexandruk Aula 6 Estruturas lógicas do Oracle: Tabelas tabelas relacionais tabelas temporárias tabelas organizadas por índices tabelas de objetos tabelas
SQL CREATE DATABASE. MySQL, SQL Server, Access, Oracle, Sybase, DB2, e outras base de dados utilizam o SQL.
 LINGUAGEM SQL SQL CREATE DATABASE MySQL, SQL Server, Access, Oracle, Sybase, DB2, e outras base de dados utilizam o SQL. SQL CREATE TABLE SQL NOT NULL O valor NOT NULL obriga que o campo contenha sempre
LINGUAGEM SQL SQL CREATE DATABASE MySQL, SQL Server, Access, Oracle, Sybase, DB2, e outras base de dados utilizam o SQL. SQL CREATE TABLE SQL NOT NULL O valor NOT NULL obriga que o campo contenha sempre
Laboratório de Banco de Dados II Aula 04. Prof. Érick de Souza Carvalho
 Laboratório de Banco de Dados II Aula 04 Prof. Érick de Souza Carvalho 1 SQL (Structured Query Language ) Prof. Érick de Souza Carvalho 2 SQL Structured Query Language - Introdução É uma Linguagem para
Laboratório de Banco de Dados II Aula 04 Prof. Érick de Souza Carvalho 1 SQL (Structured Query Language ) Prof. Érick de Souza Carvalho 2 SQL Structured Query Language - Introdução É uma Linguagem para
Índices no Oracle Database
 Índices no Oracle Database Tudo o que você precisa saber sobre eles (em 50 minutos) Fábio Prado Apresentação Quem sou eu? Trabalho com TI há 16 anos: 2000/2001: Analista de Suporte; 2001/2007: Analista
Índices no Oracle Database Tudo o que você precisa saber sobre eles (em 50 minutos) Fábio Prado Apresentação Quem sou eu? Trabalho com TI há 16 anos: 2000/2001: Analista de Suporte; 2001/2007: Analista
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS. Fábio Roberto Octaviano
 DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Recuperando Dados com Sub-Consultas Correlacionadas Após o término do Capítulo: Escrever uma sub-consulta de colunas
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Recuperando Dados com Sub-Consultas Correlacionadas Após o término do Capítulo: Escrever uma sub-consulta de colunas
Bancos de Dados IV. Tuning de Bancos de Dados. Rogério Costa
 Bancos de Dados IV Tuning de Bancos de Dados Rogério Costa rogcosta@inf.puc-rio.br 1 Sintonia (Tuning) de Bancos de Dados O que é? Realizar ajustes de forma a obter um melhor tempo de resposta para determinada
Bancos de Dados IV Tuning de Bancos de Dados Rogério Costa rogcosta@inf.puc-rio.br 1 Sintonia (Tuning) de Bancos de Dados O que é? Realizar ajustes de forma a obter um melhor tempo de resposta para determinada
EXEMPLO DE FLASHBACK VERSIONS QUERY E FLASHBACK TRANSACTION QUERY
 EXEMPLO DE FLASHBACK VERSIONS QUERY E FLASHBACK TRANSACTION QUERY A funcionalidade do recurso Flashback Query disponível desde a versão Oracle 9i e abordada também nos artigos de Maio/2007 e Maio/2008,
EXEMPLO DE FLASHBACK VERSIONS QUERY E FLASHBACK TRANSACTION QUERY A funcionalidade do recurso Flashback Query disponível desde a versão Oracle 9i e abordada também nos artigos de Maio/2007 e Maio/2008,
Lendas do Oracle. Ricardo Portilho Proni ricardo@nervinformatica.com.br. TITLE Speaker
 TITLE Speaker Lendas do Oracle Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative Commons Atribuição-SemDerivados 3.0 Brasil. Para ver uma cópia desta
TITLE Speaker Lendas do Oracle Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative Commons Atribuição-SemDerivados 3.0 Brasil. Para ver uma cópia desta
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS. Fábio Roberto Octaviano
 DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Criação de Outros Objetos Após o término do Capítulo: Criar visões simples e complexas. Recuperar dados de visões. Criar,
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Criação de Outros Objetos Após o término do Capítulo: Criar visões simples e complexas. Recuperar dados de visões. Criar,
Rápida revisão do Modelo Relacional
 Rápida revisão do Modelo Relacional Conceito de relação Tuplas e atributos Rápida revisão do Modelo Relacional Regras de integridade Entidade: Deve existir uma chave primária com valor único e não-nulo.
Rápida revisão do Modelo Relacional Conceito de relação Tuplas e atributos Rápida revisão do Modelo Relacional Regras de integridade Entidade: Deve existir uma chave primária com valor único e não-nulo.
Workshop Oracle Tuning
 Workshop Oracle Tuning Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative Commons Atribuição-SemDerivados 3.0 Brasil. Para ver uma cópia desta licença,
Workshop Oracle Tuning Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative Commons Atribuição-SemDerivados 3.0 Brasil. Para ver uma cópia desta licença,
Page 1. Prof. Constantino Jacob
 Tópicos Introdução à SQL Definição Tipos de Operações Instrução SELECT Sintaxe básica Operações relacionais de restrição, projeção e junção Instruções DML Delete, Update e Insert Instruções DDL Create
Tópicos Introdução à SQL Definição Tipos de Operações Instrução SELECT Sintaxe básica Operações relacionais de restrição, projeção e junção Instruções DML Delete, Update e Insert Instruções DDL Create
O projeto físico do bando de dados consiste no mapeamento do projeto lógico para um DBMS real Projeto deve levar em conta fatores como:
 Projeto Físico O projeto físico do bando de dados consiste no mapeamento do projeto lógico para um DBMS real Projeto deve levar em conta fatores como: Desempenho Tempo de resposta das transações Alocação
Projeto Físico O projeto físico do bando de dados consiste no mapeamento do projeto lógico para um DBMS real Projeto deve levar em conta fatores como: Desempenho Tempo de resposta das transações Alocação
Uma solução possível para garantir, em ambiente APEX, a consistência duma estrutura ISA, total e disjuntiva.
 Uma solução possível para garantir, em ambiente APEX, a consistência duma estrutura ISA, total e disjuntiva. Seja então o conjunto de entidades pessoa, com os atributos bi_pessoa, nome_pessoa e morada_pessoa,
Uma solução possível para garantir, em ambiente APEX, a consistência duma estrutura ISA, total e disjuntiva. Seja então o conjunto de entidades pessoa, com os atributos bi_pessoa, nome_pessoa e morada_pessoa,
consistent gets é o número de vezes que uma leitura consistente foi requisitada para um bloco do buffer cache.
 Ajustando o BUFFER CACHE, SHARED POOL e o LOG BUFFER BUFFER CACHE O buffer cache é utilizado para armazenar os blocos lidos a partir dos discos. Significa que um buffer cache pequeno irá fazer com que
Ajustando o BUFFER CACHE, SHARED POOL e o LOG BUFFER BUFFER CACHE O buffer cache é utilizado para armazenar os blocos lidos a partir dos discos. Significa que um buffer cache pequeno irá fazer com que
Oracle Tuning. Este PDF está disponível em Ricardo Portilho Proni Nerv Informática
 Oracle Tuning Este PDF está disponível em http://nervinformatica.com.br/t.pdf Ricardo Portilho Proni ricardo@informatica.com.br Nerv Informática Quem sou eu Ricardo Portilho Proni - Consultor e Instrutor
Oracle Tuning Este PDF está disponível em http://nervinformatica.com.br/t.pdf Ricardo Portilho Proni ricardo@informatica.com.br Nerv Informática Quem sou eu Ricardo Portilho Proni - Consultor e Instrutor
Otimização e Execução de Consultas Caso Centralizado Parse Query
 Bancos de Dados III Processamento de Consultas em Bancos de Dados Distribuídos Rogério Costa rogcosta@inf.puc-rio.br 1 Otimização e Execução de Consultas Caso Centralizado Parse Query Check de Semântica
Bancos de Dados III Processamento de Consultas em Bancos de Dados Distribuídos Rogério Costa rogcosta@inf.puc-rio.br 1 Otimização e Execução de Consultas Caso Centralizado Parse Query Check de Semântica
DDL DML DCL DTL Tipos Numéricos: INT FLOAT DOUBLE Tipos String: CHAR VARCHAR BINARY BLOB TEXT Tipos Data e Hora: DATE TIME TIMESTAMP YEAR
 SQL Structured Query Language, ou Linguagem de Consulta Estruturada, foi desenvolvida pela IBM nos anos 70 para demonstrar a viabilidade do modelo relacional para bancos de dados. No final dos anos 80
SQL Structured Query Language, ou Linguagem de Consulta Estruturada, foi desenvolvida pela IBM nos anos 70 para demonstrar a viabilidade do modelo relacional para bancos de dados. No final dos anos 80
Oracle Performance Diagnostics & Tuning 12cR2 Em Oracle Enterprise Linux 7.3 Modo Texto Inclui CDB Architecture
 Oracle Performance Diagnostics & Tuning 12cR2 Em Oracle Enterprise Linux 7.3 Modo Texto Inclui CDB Architecture Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença
Oracle Performance Diagnostics & Tuning 12cR2 Em Oracle Enterprise Linux 7.3 Modo Texto Inclui CDB Architecture Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença
Planejamento Parte Visão Geral do Ajuste de Desempenho do Banco de Dados 02 - Arquivos de Alert e Trace do Oracle
 Planejamento Parte 1 01 - Visão Geral do Ajuste de Desempenho do Banco de Dados 02 - Arquivos de Alert e Trace do Oracle 03 - Utilitários e Visões Dinâmicas de Performance 04 - Otimizando a Shared Pool
Planejamento Parte 1 01 - Visão Geral do Ajuste de Desempenho do Banco de Dados 02 - Arquivos de Alert e Trace do Oracle 03 - Utilitários e Visões Dinâmicas de Performance 04 - Otimizando a Shared Pool
ACH2025. Laboratório de Bases de Dados. SQL Oracle Visão geral SELECT. Professora: Fátima L. S. Nunes SISTEMAS DE INFORMAÇÃO
 ACH2025 Laboratório de Bases de Dados Aula 6 SQL Oracle Visão geral SELECT Professora: Fátima L. S. Nunes Modelo utilizado nos exemplos a seguir: DEPT deptno: NUMBER(2) dname: VARCHAR2(12) loc: VARCHAR2(12)
ACH2025 Laboratório de Bases de Dados Aula 6 SQL Oracle Visão geral SELECT Professora: Fátima L. S. Nunes Modelo utilizado nos exemplos a seguir: DEPT deptno: NUMBER(2) dname: VARCHAR2(12) loc: VARCHAR2(12)
LogMiner Além do FlashBack Query
 LogMiner Além do FlashBack Query O Oracle LogMiner é uma ferramenta que permite consultas a arquivos de redo log s online e archives através de SQL. Os arquivos de redo contém o histórico da atividades
LogMiner Além do FlashBack Query O Oracle LogMiner é uma ferramenta que permite consultas a arquivos de redo log s online e archives através de SQL. Os arquivos de redo contém o histórico da atividades
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS. Fábio Roberto Octaviano
 DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Utilizando Subqueries para Resolver Queries Após o término do Capítulo: Definir subqueries. Descrever os tipos de problemas
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Utilizando Subqueries para Resolver Queries Após o término do Capítulo: Definir subqueries. Descrever os tipos de problemas
'%'! $!0" $ 8 ' %%! % '! $ $$% + ' %!%$/)!'4!+,"/)!)+,/)% *! +,"0''% * %$!*!$$ #!"%&%'%'%$! "94(# ' %'$%$$$%0%$%' *!% %%%'!**% > %% %%!31?
!'4!+,/)!)+,/)% *! +,0''% * %$!*!$$ #!%&%'%'%$! 94(# ' %'$%$$$%0%$%' *!% %%%'!**% > %% %%!31?") MODELAGEM FÍSICA Capítulo 3! " # $ $!%%%& '$! $% $$%"%' ) ' *'!%'!$ $ $ $% +, %#!!" '$*'#%! $ $$%" % '$%!!% $% * % $ *-! %$% $!* '% $!$$.!'% & $%!% $ $ ' %/!$ 0 $*' $% *0 )#%!$0% 1&$$$%+#!*22,"$% )'%$$%%&
MODELAGEM FÍSICA Capítulo 3! " # $ $!%%%& '$! $% $$%"%' ) ' *'!%'!$ $ $ $% +, %#!!" '$*'#%! $ $$%" % '$%!!% $% * % $ *-! %$% $!* '% $!$$.!'% & $%!% $ $ ' %/!$ 0 $*' $% *0 )#%!$0% 1&$$$%+#!*22,"$% )'%$$%%&
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS. Fábio Roberto Octaviano
 DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Dicas de Ajuste (Tuning) de SQL Após o término do Capítulo: Mostrar algumas dicas de como refinar SQLs, de modo a obter
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Dicas de Ajuste (Tuning) de SQL Após o término do Capítulo: Mostrar algumas dicas de como refinar SQLs, de modo a obter
MySql. Introdução a MySQL. Andréa Garcia Trindade
 MySql Introdução a MySQL Andréa Garcia Trindade Introdução O que é Banco de Dados SGBD MYSQL Tipos de Tabelas Tipos de Dados Linguagem SQL Comandos SQL O que é um Banco de Dados? Conjuntos de dados Grupo
MySql Introdução a MySQL Andréa Garcia Trindade Introdução O que é Banco de Dados SGBD MYSQL Tipos de Tabelas Tipos de Dados Linguagem SQL Comandos SQL O que é um Banco de Dados? Conjuntos de dados Grupo
Uniao Educacional e Tecnologica Impacta- Uni Impacta
 Scripts avançados de gravação Objetivos Após concluir este apêndice, você poderá: Descrever o tipo de problemas que são resolvidos usando SQL para gerar SQL Gravar um script que gera um script de instruções
Scripts avançados de gravação Objetivos Após concluir este apêndice, você poderá: Descrever o tipo de problemas que são resolvidos usando SQL para gerar SQL Gravar um script que gera um script de instruções
IMPLEMENTAÇÃO DE BANCO DE DADOS
 IMPLEMENTAÇÃO DE BANCO DE DADOS MODULO 2 LINGUAGEM SQL CONTEÚDO 2. LINGUAGEM SQL 2.1 Linguagens de Definição de Dados (DDL) 2.1.1 Criação de tabela: CREATE 2.1.2 Alteração de Tabela: ALTER 2.1.3 Exclusão
IMPLEMENTAÇÃO DE BANCO DE DADOS MODULO 2 LINGUAGEM SQL CONTEÚDO 2. LINGUAGEM SQL 2.1 Linguagens de Definição de Dados (DDL) 2.1.1 Criação de tabela: CREATE 2.1.2 Alteração de Tabela: ALTER 2.1.3 Exclusão
SQL (Tópicos) Structured Query Language
 Structured Query Language") SQL (Tópicos) Structured Query Language ISI Introdução aos Sistemas de Informação SQL (Tópicos) 1 SQL: componentes SQL / DDL (Data Definition Language) Permite definir os Esquemas de Relação Permite definir
SQL (Tópicos) Structured Query Language ISI Introdução aos Sistemas de Informação SQL (Tópicos) 1 SQL: componentes SQL / DDL (Data Definition Language) Permite definir os Esquemas de Relação Permite definir
Tabelas. Banco de Dados I MySQL
 FACULDADE ANGLO AMERICANO FOZ DO IGUAÇU Curso de Ciência da Computação 5º Período Disciplina: Banco de Dados I Prof. Erinaldo Sanches Nascimento Tabelas Banco de Dados I MySQL Linguagem de Definição de
FACULDADE ANGLO AMERICANO FOZ DO IGUAÇU Curso de Ciência da Computação 5º Período Disciplina: Banco de Dados I Prof. Erinaldo Sanches Nascimento Tabelas Banco de Dados I MySQL Linguagem de Definição de
SQL - Structured Query Language. Karine Reis Ferreira
 SQL - Structured Query Language Karine Reis Ferreira karine@dpi.inpe.br SQL - Structured Query Language n n Linguagem padrão (ISO) para sistemas de bancos de dados É uma linguagem declarativa de alto nível
SQL - Structured Query Language Karine Reis Ferreira karine@dpi.inpe.br SQL - Structured Query Language n n Linguagem padrão (ISO) para sistemas de bancos de dados É uma linguagem declarativa de alto nível
Introdução ao PostgreSQL
 Introdução ao PostgreSQL Fontes Karine Reis Ferreira karine@dpi.inpe.br Gilberto Câmara gilberto@dpi.inpe.br Gilberto Ribeiro de Queiroz gribeiro@dpi.inpe.br Marcos André Gonçalves - UFMG Parte 3 Aula
Introdução ao PostgreSQL Fontes Karine Reis Ferreira karine@dpi.inpe.br Gilberto Câmara gilberto@dpi.inpe.br Gilberto Ribeiro de Queiroz gribeiro@dpi.inpe.br Marcos André Gonçalves - UFMG Parte 3 Aula
Configurar o ODBC em ISE 2.3 com base de dados Oracle
 Configurar o ODBC em ISE 2.3 com base de dados Oracle Índice Introdução Pré-requisitos Requisitos Componentes Utilizados Configurar Etapa 1. Configuração básica do Oracle Etapa 2. Configuração básica ISE
Configurar o ODBC em ISE 2.3 com base de dados Oracle Índice Introdução Pré-requisitos Requisitos Componentes Utilizados Configurar Etapa 1. Configuração básica do Oracle Etapa 2. Configuração básica ISE
ACH2025. Laboratório de Bases de Dados Aula 5. SQL Oracle Visão geral. Professora: Fátima L. S. Nunes SISTEMAS DE INFORMAÇÃO
 ACH2025 Laboratório de Bases de Dados Aula 5 SQL Oracle Visão geral Professora: Fátima L. S. Nunes Características SQL Os comandos podem ser agrupados em 4 classes: DDL - Comandos para a Definição de Relações
ACH2025 Laboratório de Bases de Dados Aula 5 SQL Oracle Visão geral Professora: Fátima L. S. Nunes Características SQL Os comandos podem ser agrupados em 4 classes: DDL - Comandos para a Definição de Relações
Comandos de Manipulação
 SQL - Avançado Inserção de dados; Atualização de dados; Remoção de dados; Projeção; Seleção; Junções; Operadores: aritméticos, de comparação,de agregação e lógicos; Outros comandos relacionados. SQL SQL
SQL - Avançado Inserção de dados; Atualização de dados; Remoção de dados; Projeção; Seleção; Junções; Operadores: aritméticos, de comparação,de agregação e lógicos; Outros comandos relacionados. SQL SQL
Linguagem SQL. ENG1518 Sistemas de Informação Gerenciais Prof. Marcos Villas
 Linguagem SQL ENG1518 Sistemas de Informação Gerenciais Prof. Marcos Villas villas@puc-rio.br SQL Linguagem padrão de acesso tabelas em um banco de dados relacional Permite definir e manipular dados DML
Linguagem SQL ENG1518 Sistemas de Informação Gerenciais Prof. Marcos Villas villas@puc-rio.br SQL Linguagem padrão de acesso tabelas em um banco de dados relacional Permite definir e manipular dados DML
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS. Fábio Roberto Octaviano
 DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Manipulação de Dados Após o término do Capítulo: Descrever a Linguagem de Manipulação de Dados (DML). Inserts, Updates,
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Manipulação de Dados Após o término do Capítulo: Descrever a Linguagem de Manipulação de Dados (DML). Inserts, Updates,
Introdução à Banco de Dados. Nathalia Sautchuk Patrício
 Introdução à Banco de Dados Nathalia Sautchuk Patrício Histórico Início da computação: dados guardados em arquivos de texto Problemas nesse modelo: redundância não-controlada de dados aplicações devem
Introdução à Banco de Dados Nathalia Sautchuk Patrício Histórico Início da computação: dados guardados em arquivos de texto Problemas nesse modelo: redundância não-controlada de dados aplicações devem
Administração de Banco de Dados
 Administração de Banco de Dados Aula 8 Prof. Marcos Alexandruk Aula 8 Índices (Indexes) Índices únicos Índices não únicos Índices de chave invertida Índices baseados em funções Índices de bitmap Tabelas
Administração de Banco de Dados Aula 8 Prof. Marcos Alexandruk Aula 8 Índices (Indexes) Índices únicos Índices não únicos Índices de chave invertida Índices baseados em funções Índices de bitmap Tabelas
Funções Definidas pelo Usuário
 BD II (SI 587) Funções Definidas pelo Usuário Prof. Josenildo Silva jcsilva@ifma.edu.br Funções definidas pelo usuário Funções precisam obrigatoriamente retornar um valor Somente aceitam parâmetros do
BD II (SI 587) Funções Definidas pelo Usuário Prof. Josenildo Silva jcsilva@ifma.edu.br Funções definidas pelo usuário Funções precisam obrigatoriamente retornar um valor Somente aceitam parâmetros do
saída durante o runtime Usando Functions de uma Única Linha para Personalizar Relatórios Mostrar as diferenças entre as functions SQL de uma única
 Tópicos do Curso: Introdução Listar os principais recursos do Banco de Dados Oracle 10g Apresentar uma visão geral de: componentes, plataforma de internet, servidor de aplicações e suite do desenvolvedor
Tópicos do Curso: Introdução Listar os principais recursos do Banco de Dados Oracle 10g Apresentar uma visão geral de: componentes, plataforma de internet, servidor de aplicações e suite do desenvolvedor
ORACLE 11 G INTRODUÇÃO AO ORACLE, SQL,PL/SQL
 ORACLE 11 G INTRODUÇÃO AO ORACLE, SQL,PL/SQL Objetivo: No curso Oracle 11G Introdução ao Oracle, SQL, PL/SQL será abordado desde a introdução da tecnologia do banco de dados em questão como todos os conceitos
ORACLE 11 G INTRODUÇÃO AO ORACLE, SQL,PL/SQL Objetivo: No curso Oracle 11G Introdução ao Oracle, SQL, PL/SQL será abordado desde a introdução da tecnologia do banco de dados em questão como todos os conceitos
ORACLE IN-MEMORY 12c. Vantagens e Cenários de Utilização do Oracle In-Memory 12c. Willian Frasson
 ORACLE IN-MEMORY 12c Vantagens e Cenários de Utilização do Oracle In-Memory 12c Willian Frasson Apresentação Willian Frasson DBA Oracle Tecnologia em Processamento de dados pela Universidade de Maringá
ORACLE IN-MEMORY 12c Vantagens e Cenários de Utilização do Oracle In-Memory 12c Willian Frasson Apresentação Willian Frasson DBA Oracle Tecnologia em Processamento de dados pela Universidade de Maringá
Linguagem de Consulta Estruturada SQL- DML
 Linguagem de Consulta Estruturada SQL- DML INTRODUÇÃO A SQL - Structured Query Language, foi desenvolvido pela IBM em meados dos anos 70 como uma linguagem de manipulação de dados (DML - Data Manipulation
Linguagem de Consulta Estruturada SQL- DML INTRODUÇÃO A SQL - Structured Query Language, foi desenvolvido pela IBM em meados dos anos 70 como uma linguagem de manipulação de dados (DML - Data Manipulation
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS. Fábio Roberto Octaviano
 DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Controlando Acesso dos Usuários Após o término do Capítulo: Diferenciar privilégios de sistema e privilégios de objetos.
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Controlando Acesso dos Usuários Após o término do Capítulo: Diferenciar privilégios de sistema e privilégios de objetos.
Oracle Database 12c. Novas Características para DBAs e Desenvolvedores
 Oracle Database 12c Novas Características para DBAs e Desenvolvedores Presented by: Alex Zaballa, Oracle DBA Alex Zaballa http://alexzaballa.blogspot.com/ 147 and counting @alexzaballa https://www.linkedin.com/in/alexzaballa
Oracle Database 12c Novas Características para DBAs e Desenvolvedores Presented by: Alex Zaballa, Oracle DBA Alex Zaballa http://alexzaballa.blogspot.com/ 147 and counting @alexzaballa https://www.linkedin.com/in/alexzaballa
f. Exemplo: verificar condição de aprovação de alunos
 Tecnologia em Análise e Desenvolvimento de Sistemas Disciplina: B1SGB - Sistemas Gerenciadores de Banco de Dados Memória de aula Semana 17 1) Expressões CASE a. Tem a mesma finalidade que nas linguagens
Tecnologia em Análise e Desenvolvimento de Sistemas Disciplina: B1SGB - Sistemas Gerenciadores de Banco de Dados Memória de aula Semana 17 1) Expressões CASE a. Tem a mesma finalidade que nas linguagens
Sistemas de Bases de Dados Relacionais Introdução ao SQL. Interrogações diversas sobre a Base de Dados Northwind - Parte II
 SQL (02) Sistemas de Bases de Dados Relacionais Introdução ao SQL Interrogações diversas sobre a Base de Dados Northwind - Parte II /* Introdução ao SQL - Parte II =========================== Folha de
SQL (02) Sistemas de Bases de Dados Relacionais Introdução ao SQL Interrogações diversas sobre a Base de Dados Northwind - Parte II /* Introdução ao SQL - Parte II =========================== Folha de
Análise e otimização de queries no MySQL. Jeronimo Fagundes da Silva
 Análise e otimização de queries no MySQL Jeronimo Fagundes da Silva Jeronimo Fagundes da Silva Líder de Desenvolvimento de Software para Web na KingHost Bacharel em Ciência da Computação pela UFRGS Trabalha
Análise e otimização de queries no MySQL Jeronimo Fagundes da Silva Jeronimo Fagundes da Silva Líder de Desenvolvimento de Software para Web na KingHost Bacharel em Ciência da Computação pela UFRGS Trabalha
Análise de Relatórios AWR / Statspack 9iR2 a 12cR1
 Análise de Relatórios AWR / Statspack 9iR2 a 12cR1 Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative Commons Atribuição-SemDerivados 3.0 Brasil. Para
Análise de Relatórios AWR / Statspack 9iR2 a 12cR1 Ricardo Portilho Proni ricardo@nervinformatica.com.br Esta obra está licenciada sob a licença Creative Commons Atribuição-SemDerivados 3.0 Brasil. Para
MATA60 BANCO DE DADOS Aula 10- Indexação. Prof. Daniela Barreiro Claro
 MATA60 BANCO DE DADOS Aula 10- Indexação Prof. Daniela Barreiro Claro Indexação Indexação em SQL; Vantagens e Custo dos Índices; Indexação no PostgreSQL; FORMAS - UFBA 2 de X; X=23 Indexação Sintaxe: create
MATA60 BANCO DE DADOS Aula 10- Indexação Prof. Daniela Barreiro Claro Indexação Indexação em SQL; Vantagens e Custo dos Índices; Indexação no PostgreSQL; FORMAS - UFBA 2 de X; X=23 Indexação Sintaxe: create
14/9/2009. Banco de Dados
 Banco de Dados Fernando Fonseca & Ana Carolina Salgado Roteiro Analisar Minimundo Criar Esquema no SGBD Oracle Script criacaotabelas.sql em http://www.cin.ufpe.br/~fdfd/dinter/sql Inserir dados no banco
Banco de Dados Fernando Fonseca & Ana Carolina Salgado Roteiro Analisar Minimundo Criar Esquema no SGBD Oracle Script criacaotabelas.sql em http://www.cin.ufpe.br/~fdfd/dinter/sql Inserir dados no banco
SQL Gatilhos (Triggers)
") SQL Gatilhos (Triggers) Laboratório de Bases de Dados Gatilho (trigger) Bloco PL/SQL que é disparado de forma automática e implícita sempre que ocorrer um evento associado a uma tabela INSERT UPDATE DELETE
SQL Gatilhos (Triggers) Laboratório de Bases de Dados Gatilho (trigger) Bloco PL/SQL que é disparado de forma automática e implícita sempre que ocorrer um evento associado a uma tabela INSERT UPDATE DELETE
PROGRAMA. 3.SQL Básico. 3.1 Criação de tabelas 3.2 Queries simples 3.3 Subqueries 3.4 Agregação. Prof. Dr. Marcos Tsuzuki
 PROGRAMA 3.SQL Básico 3.1 Criação de tabelas 3.2 Queries simples 3.3 Subqueries 3.4 Agregação 1 3.SQL Básico A linguagem SQL foi desenvolvida para o ambiente relacional, podendo ser adaptada a ambientes
PROGRAMA 3.SQL Básico 3.1 Criação de tabelas 3.2 Queries simples 3.3 Subqueries 3.4 Agregação 1 3.SQL Básico A linguagem SQL foi desenvolvida para o ambiente relacional, podendo ser adaptada a ambientes
Administração de Banco de Dados
 Administração de Banco de Dados Aula 9 Prof. Marcos Alexandruk Aula 9 Visões (Views) Visões regulares Visões materializadas Visões de objeto Uma visão (view) é uma representação lógica de uma ou mais tabelas.
Administração de Banco de Dados Aula 9 Prof. Marcos Alexandruk Aula 9 Visões (Views) Visões regulares Visões materializadas Visões de objeto Uma visão (view) é uma representação lógica de uma ou mais tabelas.
SQL Factoring. Ajustes de SQL sem acesso aos Fontes. Por : José Laurindo Chiappa
 SQL Factoring Ajustes de SQL sem acesso aos Fontes Por : José Laurindo Chiappa Breve Biografia do Palestrante Atua como DBA Oracle desde 2.000, tendo além disso mais de dez anos como Desenvolvedor em PL/SQL,
SQL Factoring Ajustes de SQL sem acesso aos Fontes Por : José Laurindo Chiappa Breve Biografia do Palestrante Atua como DBA Oracle desde 2.000, tendo além disso mais de dez anos como Desenvolvedor em PL/SQL,
INSTALAÇÃO DO LOGIX COM BANCO ORACLE
 INSTALAÇÃO DO LOGIX COM BANCO ORACLE Passo 1) Baixar instalador do TotvsTec (para instalação em ambiente Linux, necessário baixar os dois instaladores para poder rodar o smartcliente no Windows) Passo
INSTALAÇÃO DO LOGIX COM BANCO ORACLE Passo 1) Baixar instalador do TotvsTec (para instalação em ambiente Linux, necessário baixar os dois instaladores para poder rodar o smartcliente no Windows) Passo
Siga em frente. Análise
 Análise Siga em frente Compreender os planos de execução do banco de dados é a chave para avaliar o potencial máximo de uma query SQL ou estimar com efetividade as necessidades de recursos futuros. por
Análise Siga em frente Compreender os planos de execução do banco de dados é a chave para avaliar o potencial máximo de uma query SQL ou estimar com efetividade as necessidades de recursos futuros. por
Banco de Dados Oracle 10g: Introdução à Linguagem SQL
 Oracle University Entre em contato: 0800 891 6502 Banco de Dados Oracle 10g: Introdução à Linguagem SQL Duração: 5 Dias Objetivos do Curso Esta classe se aplica aos usuários do Banco de Dados Oracle8i,
Oracle University Entre em contato: 0800 891 6502 Banco de Dados Oracle 10g: Introdução à Linguagem SQL Duração: 5 Dias Objetivos do Curso Esta classe se aplica aos usuários do Banco de Dados Oracle8i,
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS. Fábio Roberto Octaviano
 DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Controlando Acesso dos Usuários Após o término do Capítulo: Diferenciar privilégios de sistema e privilégios de objetos.
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Controlando Acesso dos Usuários Após o término do Capítulo: Diferenciar privilégios de sistema e privilégios de objetos.
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS. Fábio Roberto Octaviano
 DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Utilizando DDL para Gerenciar Tabelas Após o término do Capítulo: Categorizar os principais objetos de um BD. Verificar
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Utilizando DDL para Gerenciar Tabelas Após o término do Capítulo: Categorizar os principais objetos de um BD. Verificar
Progress DCA Desenvolvendo Aplicações Caracter Parte 1
 Progress DCA Desenvolvendo Aplicações Caracter Parte 1 Tecnologia 1 Agenda Parte 1 Introdução ao Progress Movimentação dos Dados Manipulando os Dados Blocos Localizando Registros Variáveis Processamento
Progress DCA Desenvolvendo Aplicações Caracter Parte 1 Tecnologia 1 Agenda Parte 1 Introdução ao Progress Movimentação dos Dados Manipulando os Dados Blocos Localizando Registros Variáveis Processamento
Oracle Database 10g: Fundamentos de SQL e PL/SQL
 Oracle University Contact Us: 0-800-167225 Oracle Database 10g: Fundamentos de SQL e PL/SQL Duration: 5 Dias O que é que gostaria de aprender Conheça os fundamentos de SQL e PL/SQL usando o SQL Developer
Oracle University Contact Us: 0-800-167225 Oracle Database 10g: Fundamentos de SQL e PL/SQL Duration: 5 Dias O que é que gostaria de aprender Conheça os fundamentos de SQL e PL/SQL usando o SQL Developer
Banco de Dados. Prof. Antonio
 Banco de Dados Prof. Antonio SQL - Structured Query Language O que é SQL? A linguagem SQL (Structure query Language - Linguagem de Consulta Estruturada) é a linguagem padrão ANSI (American National Standards
Banco de Dados Prof. Antonio SQL - Structured Query Language O que é SQL? A linguagem SQL (Structure query Language - Linguagem de Consulta Estruturada) é a linguagem padrão ANSI (American National Standards
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS. Fábio Roberto Octaviano
 DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Manipulando Grandes Volumes de Dados Após o término do Capítulo: Manipular dados utilizando sub-consultas. Descrever
DO BÁSICO AO AVANÇADO PARA MANIPULAÇÃO E OTIMIZAÇÃO DE DADOS Fábio Roberto Octaviano Manipulando Grandes Volumes de Dados Após o término do Capítulo: Manipular dados utilizando sub-consultas. Descrever
Formação em Banco de Dados. Subtítulo
 Formação em Banco de Dados Subtítulo Sobre a APTECH A Aptech é uma instituição global, modelo em capacitação profissional, que dispõe de diversos cursos com objetivo de preparar seus alunos para carreiras
Formação em Banco de Dados Subtítulo Sobre a APTECH A Aptech é uma instituição global, modelo em capacitação profissional, que dispõe de diversos cursos com objetivo de preparar seus alunos para carreiras
Revisão Banco de Dados
 Revisão Banco de Dados Carlos Henrique - Aula 2 Descoberta de Conhecimento e Mineração de Dados Tópicos Abordados Conceitos Básicos Características Arquitetura Lógica Usuários Finais Modelo E/R Linguagens
Revisão Banco de Dados Carlos Henrique - Aula 2 Descoberta de Conhecimento e Mineração de Dados Tópicos Abordados Conceitos Básicos Características Arquitetura Lógica Usuários Finais Modelo E/R Linguagens
Oracle Database: Fundamentos de SQL e PL/SQL
 Oracle University Contact Us: 0800 891 6502 Oracle Database: Fundamentos de SQL e PL/SQL Duration: 5 Days What you will learn Este curso apresenta os fundamentos de SQL e PL/SQL e as vantagens das linguagens
Oracle University Contact Us: 0800 891 6502 Oracle Database: Fundamentos de SQL e PL/SQL Duration: 5 Days What you will learn Este curso apresenta os fundamentos de SQL e PL/SQL e as vantagens das linguagens
Organização de Arquivos
 Construção de Sistemas de Gerência de Bancos de Dados DI PUC-Rio Prof: Sérgio Lifschitz Organização de Arquivos Organização de Arquivos Tipos básicos de arquivos: heap files (entry sequenced files) sorted
Construção de Sistemas de Gerência de Bancos de Dados DI PUC-Rio Prof: Sérgio Lifschitz Organização de Arquivos Organização de Arquivos Tipos básicos de arquivos: heap files (entry sequenced files) sorted
Professor Leonardo Larback
 Professor Leonardo Larback Engines MySQL Server possui um conceito chamado de Storage Engine ou mecanismos de armazenamento, ou ainda, tipos de tabela. Através da engine selecionada, o servidor sabe como
Professor Leonardo Larback Engines MySQL Server possui um conceito chamado de Storage Engine ou mecanismos de armazenamento, ou ainda, tipos de tabela. Através da engine selecionada, o servidor sabe como
ALTERANDO O NOME DA TABELA ALTER TABLE DEPTO RENAME TO TAB_DEPARTAMENTO
 --CRIACAO DE TABELAS CREATE TABLE TAB_PAIS (COD_PAIS VARCHAR2 (2) NOT NULL, NOME_PAIS VARCHAR2(50) NOT NULL, POP_PAIS NUMBER (12,2), CONSTRAINT PK_PAIS PRIMARY KEY (NOME_PAIS) ); CREATE TABLE TAB_ESTADO
--CRIACAO DE TABELAS CREATE TABLE TAB_PAIS (COD_PAIS VARCHAR2 (2) NOT NULL, NOME_PAIS VARCHAR2(50) NOT NULL, POP_PAIS NUMBER (12,2), CONSTRAINT PK_PAIS PRIMARY KEY (NOME_PAIS) ); CREATE TABLE TAB_ESTADO
Marcos Alexandruk Marcos Alexandruk
 Marcos Alexandruk m.alexandruk@gmail.com Apresentação disponível em: www.dba.net.br/mysql.pdf Parte I: Download e Instalação MySQL - Download www.mysql.com/downloads MySQL - Download MySQL - Download MySQL
Marcos Alexandruk m.alexandruk@gmail.com Apresentação disponível em: www.dba.net.br/mysql.pdf Parte I: Download e Instalação MySQL - Download www.mysql.com/downloads MySQL - Download MySQL - Download MySQL
Sumário 1 0.1 Introdução 1 0.2 Breve História da Linguagem SQL l 0.3 Características da Linguagem SQL 3 0.4 A Composição deste Livro 3
 ÍNDICE o -INTRODUÇÃO Sumário 1 0.1 Introdução 1 0.2 Breve História da Linguagem SQL l 0.3 Características da Linguagem SQL 3 0.4 A Composição deste Livro 3 0.5 Sistemas Utilizados 6 0.5.1 Access 2003 (Microsoft)
ÍNDICE o -INTRODUÇÃO Sumário 1 0.1 Introdução 1 0.2 Breve História da Linguagem SQL l 0.3 Características da Linguagem SQL 3 0.4 A Composição deste Livro 3 0.5 Sistemas Utilizados 6 0.5.1 Access 2003 (Microsoft)
PHP INTEGRAÇÃO COM MYSQL PARTE 1
 INTRODUÇÃO PHP INTEGRAÇÃO COM MYSQL PARTE 1 Leonardo Pereira leonardo@estudandoti.com.br Facebook: leongamerti http://www.estudandoti.com.br Informações que precisam ser manipuladas com mais segurança
INTRODUÇÃO PHP INTEGRAÇÃO COM MYSQL PARTE 1 Leonardo Pereira leonardo@estudandoti.com.br Facebook: leongamerti http://www.estudandoti.com.br Informações que precisam ser manipuladas com mais segurança
SISTEMAS DE INFORMAÇÃO BANCO DE DADOS 2. SQL (Select) PROF: EDSON THIZON
 PROF: EDSON THIZON") SISTEMAS DE INFORMAÇÃO BANCO DE DADOS 2 SQL (Select) PROF: EDSON THIZON DML É a parte mais ampla da SQL. Permite pesquisar, alterar, incluir e deletar dados da base de dados. São quatro as sentenças mais
SISTEMAS DE INFORMAÇÃO BANCO DE DADOS 2 SQL (Select) PROF: EDSON THIZON DML É a parte mais ampla da SQL. Permite pesquisar, alterar, incluir e deletar dados da base de dados. São quatro as sentenças mais
Prof. Josenildo Silva
 BD II (SI 587) Gatilhos (Triggers) Prof. Josenildo Silva jcsilva@ifma.edu.br Motivação Algumas rotinas precisam ser executadas antes ou depois de um determinado evento no banco de dados Motivação Regras
BD II (SI 587) Gatilhos (Triggers) Prof. Josenildo Silva jcsilva@ifma.edu.br Motivação Algumas rotinas precisam ser executadas antes ou depois de um determinado evento no banco de dados Motivação Regras
Configurar ISE 2.2 para a integração com server de MySQL
 Configurar ISE 2.2 para a integração com server de MySQL Índice Introdução Pré-requisitos Requisitos Componentes Utilizados Informações de fundo Configurar Diagrama de Rede Configurações 1. Configurar
Configurar ISE 2.2 para a integração com server de MySQL Índice Introdução Pré-requisitos Requisitos Componentes Utilizados Informações de fundo Configurar Diagrama de Rede Configurações 1. Configurar
Oracle Database 11g: Introdução à Linguagem SQL Novo
 Oracle University Contact Us: 0800 891 6502 Oracle Database 11g: Introdução à Linguagem SQL Novo Duration: 5 Days What you will learn Neste curso, os alunos aprendem os conceitos de bancos de dados relacionais.
Oracle University Contact Us: 0800 891 6502 Oracle Database 11g: Introdução à Linguagem SQL Novo Duration: 5 Days What you will learn Neste curso, os alunos aprendem os conceitos de bancos de dados relacionais.
01 - Visão Geral do Ajuste de Desempenho do Banco de Dados 02 - Arquivos de Alert e Trace do Oracle
 Planejamento Parte 1 01 - Visão Geral do Ajuste de Desempenho do Banco de Dados 02 - Arquivos de Alert e Trace do Oracle 03 - Utilitários e Visões Dinâmicas de Performance 04 - Otimizando a Shared Pool
Planejamento Parte 1 01 - Visão Geral do Ajuste de Desempenho do Banco de Dados 02 - Arquivos de Alert e Trace do Oracle 03 - Utilitários e Visões Dinâmicas de Performance 04 - Otimizando a Shared Pool
Utilizando o Postgres - comandos SQL para a manipulação de dados
 Utilizando o Postgres - comandos SQL para a manipulação de dados SELECT A declaração SELECT é utilizada para selecionar os dados de um banco de dados. SELECT nome FROM clientes WHERE A cláusula WHERE é
Utilizando o Postgres - comandos SQL para a manipulação de dados SELECT A declaração SELECT é utilizada para selecionar os dados de um banco de dados. SELECT nome FROM clientes WHERE A cláusula WHERE é
EXEMPLOS DE COMANDOS NO SQL SERVER
 EXEMPLOS DE COMANDOS NO SQL SERVER Gerenciando Tabelas: DDL - DATA DEFINITION LANGUAG Criando uma tabela: CREATE TABLE CLIENTES ID VARCHAR4 NOT NULL, NOME VARCHAR30 NOT NULL, PAGAMENTO DECIMAL4,2 NOT NULL;
EXEMPLOS DE COMANDOS NO SQL SERVER Gerenciando Tabelas: DDL - DATA DEFINITION LANGUAG Criando uma tabela: CREATE TABLE CLIENTES ID VARCHAR4 NOT NULL, NOME VARCHAR30 NOT NULL, PAGAMENTO DECIMAL4,2 NOT NULL;
SQL. Prof. Roger Cristhian Gomes
 SQL Prof. Roger Cristhian Gomes SQL SQL - Structured Query Language Linguagem de acesso e manipulação de sistemas de base de dados computacionais que segue o padrão ANSI Existem diferenças entre as versões
SQL Prof. Roger Cristhian Gomes SQL SQL - Structured Query Language Linguagem de acesso e manipulação de sistemas de base de dados computacionais que segue o padrão ANSI Existem diferenças entre as versões
Linguagem de pesquisa declarativa para banco de dados relacional; 1ª Versão - Desenvolvida pela IBM no laboratório de pesquisa de San José;
 MySQL SQL (Structured Query Languagem ) Linguagem de pesquisa declarativa para banco de dados relacional; 1ª Versão - Desenvolvida pela IBM no laboratório de pesquisa de San José; Inicialmente - Sequel
MySQL SQL (Structured Query Languagem ) Linguagem de pesquisa declarativa para banco de dados relacional; 1ª Versão - Desenvolvida pela IBM no laboratório de pesquisa de San José; Inicialmente - Sequel
Introdução à linguagem SQL
 Introdução à linguagem SQL 1 Histórico A linguagem de consulta estruturada (SQL - Structured Query Language) foi desenvolvida pela empresa IBM, no final dos anos 70. O primeiro banco de dados comercial
Introdução à linguagem SQL 1 Histórico A linguagem de consulta estruturada (SQL - Structured Query Language) foi desenvolvida pela empresa IBM, no final dos anos 70. O primeiro banco de dados comercial
Quando se seleciona os modos OS ou XML, arquivos são criados com os registros de auditoria, eles se localizam parâmetro audit_file_dest.
 Auditoria é a habilidade do banco de dados Oracle poder gerar logs de auditoria (XML, tabelas, arquivos de SO, ) em atividades suspeitas do usuário, como por exemplo: monitorar o que um determinado usuário
Auditoria é a habilidade do banco de dados Oracle poder gerar logs de auditoria (XML, tabelas, arquivos de SO, ) em atividades suspeitas do usuário, como por exemplo: monitorar o que um determinado usuário
SQL TGD/JMB 1. Projecto de Bases de Dados. Linguagem SQL
 SQL TGD/JMB 1 Projecto de Bases de Dados Linguagem SQL SQL TGD/JMB 2 O que é o SQL? SQL ("ess-que-el") significa Structured Query Language. É uma linguagem standard (universal) para comunicação com sistemas
SQL TGD/JMB 1 Projecto de Bases de Dados Linguagem SQL SQL TGD/JMB 2 O que é o SQL? SQL ("ess-que-el") significa Structured Query Language. É uma linguagem standard (universal) para comunicação com sistemas
Sistemas de Banco de Dados I. Escola Alcides Maya DDL - Introdução
 DDL - Introdução Sumário (4ª aula) DDL (Data Definition Language) Creates Alters Drops Index Unique Keys e Foreign Keys DDL Data Definition Language ou Data Description Language (DDL) É uma linguagem para
DDL - Introdução Sumário (4ª aula) DDL (Data Definition Language) Creates Alters Drops Index Unique Keys e Foreign Keys DDL Data Definition Language ou Data Description Language (DDL) É uma linguagem para
Avisos. Sumário. Atividade em lab Aula 29. Atividade em lab Aula 29. Programando com SQL Triggers EXERCÍCIO LAB SP. Vista da segunda prova
 Ciência da Computação GBC043 Sistemas de Banco de Dados Programando com SQL s Avisos Vista da segunda prova Data: 03/06 das 13:40 às 15:00h Local: sala 1B137 Profa. Maria Camila Nardini Barioni camila.barioni@ufu.br
Ciência da Computação GBC043 Sistemas de Banco de Dados Programando com SQL s Avisos Vista da segunda prova Data: 03/06 das 13:40 às 15:00h Local: sala 1B137 Profa. Maria Camila Nardini Barioni camila.barioni@ufu.br
BD II (SI 587) Procedimentos Armazenados
 Procedimentos Armazenados") BD II (SI 587) Procedimentos Armazenados Josenildo Silva jcsilva@ifma.edu.br MOTIVAÇÃO Contexto: Sistemas em 2 camadas Contexto: Sistemas em 3 camadas Problema 1: Alto volume de dados na rede Como reduzir
BD II (SI 587) Procedimentos Armazenados Josenildo Silva jcsilva@ifma.edu.br MOTIVAÇÃO Contexto: Sistemas em 2 camadas Contexto: Sistemas em 3 camadas Problema 1: Alto volume de dados na rede Como reduzir
BANCO DE DADOS. info 3º ano. Prof. Diemesleno Souza Carvalho diemesleno@iftm.edu.br www.diemesleno.com.br
 BANCO DE DADOS info 3º ano Prof. Diemesleno Souza Carvalho diemesleno@iftm.edu.br www.diemesleno.com.br Na última aula estudamos Unidade 4 - Projeto Lógico Normalização; Dicionário de Dados. Arquitetura
BANCO DE DADOS info 3º ano Prof. Diemesleno Souza Carvalho diemesleno@iftm.edu.br www.diemesleno.com.br Na última aula estudamos Unidade 4 - Projeto Lógico Normalização; Dicionário de Dados. Arquitetura
SQL e PL/SQL Oracle Dicas de preparação para certificação
 - 1 - SQL e PL/SQL Oracle Dicas de preparação para certificação Selection: para escolher linhas em uma tabela Projection: para escolher colunas em uma tabela Join: pode trazer simultaneamente dados que
- 1 - SQL e PL/SQL Oracle Dicas de preparação para certificação Selection: para escolher linhas em uma tabela Projection: para escolher colunas em uma tabela Join: pode trazer simultaneamente dados que
Lista 02 Sistema de Banco de Dados CAP 241 Computação Aplicada I
 Lista 02 Sistema de Banco de Dados CAP 241 Computação Aplicada I Considere o diagrama relacional da Figura 1 e escreva os comandos SQL para executar os exercícios abaixo. Figure 1 Diagrama relacional.
Lista 02 Sistema de Banco de Dados CAP 241 Computação Aplicada I Considere o diagrama relacional da Figura 1 e escreva os comandos SQL para executar os exercícios abaixo. Figure 1 Diagrama relacional.