PBIW-SPARC: Uma Estratégia para Codificação de Instruções em Programas SPARC
|
|
|
- Beatriz Prada Godoi
- 5 Há anos
- Visualizações:
Transcrição
1 PBIW-SPARC: Uma Estratégia para Codificação de Instruções em Programas SPARC Renato Santos* *Instituto Federal de Mato Grosso do Sul Coxim-MS, Brasil Renan Marks e Ricardo Santos Faculdade de Computação Universidade Federal de Mato Grosso do Sul Campo Grande-MS, Brasil renan,ricardo@facom.ufms.br Resumo Esse trabalho apresenta o projeto e desenvolvimento da técnica de codificação de instruções PBIW sobre o conjunto de instruções SPARCv8. A técnica de codificação PBIW foi desenvolvida sobre uma infraestrutura de codificação de instruções em software que mapeia o código gerado pela saída de um compilador no esquema de codificação PBIW projetado para um processador alvo. A adoção da técnica PBIW para codificar programas SPARCv8 é denominada PBIW- SPARC. Instruções PBIW-SPARC possuem tamanho de 16 bits e os padrões codificados possuem tamanho de 24 bits. Experimentos estáticos e dinâmicos foram realizados de forma a caracterizar todos os efeitos da codificação PBIW-SPARC no código gerado e no processador alvo. Os resultados encontrados mostram que a codificação PBIW alcança ganhos na razão de compressão e desempenho: até 38% na redução do tamanho do programa e 1,75 de speedup em comparação aos programas SPARCv8. Palavras-chave Codificação de Instruções, PBIW, Decodificadores de Instrução, SPARCv8. I. INTRODUÇÃO A partir das restrições de espaço em memória e desempenho impostas pelos sistemas embarcados, novas técnicas têm sido apresentadas visando reduzir o tamanho dos programas, de forma a também reduzir o impacto dos mesmos nos acessos à memória e, consequentemente, aumentar o desempenho final do código. Muitas dessas técnicas de redução de programas focaram em novos esquemas de compressão/codificação de instruções. Historicamente, tais técnicas têm sido propostas desde a década de 90 e são aplicadas tanto em arquiteturas de alto desempenho, de propósito geral, quanto em arquiteturas voltadas para domínios específicos de aplicações. Os principais benefícios de um código menor são o menor consumo de energia, maior velocidade de execução e menor uso de memória. Tais características são especialmente desejáveis em sistemas embarcados, devido ao consumo de energia restrito, limitada capacidade de processamento e baixa capacidade de memória. No entanto, há de se considerar também a necessidade de balancear tais ganhos com os impactos gerados na microarquitetura do processador alvo, devido, inevitavelmente, à inclusão de hardware específico para decodificar, em tempo de execução, o programa que foi codificado em tempo de compilação. A técnica de codificação de instruções PBIW [1] foi projetada, inicialmente, para arquiteturas que buscam instruções longas na memória como processadores baseados em arquiteturas EPIC, VLIW, arquiteturas reconfiguráveis com várias unidades funcionais e arquiteturas de alto desempenho baseadas em matrizes de unidades funcionais [2]. A técnica é composta por um algoritmo que realiza a fatoração de operandos [3] e por uma memória cache chamada de P- Cache. Este artigo apresenta a implementação de um codificador de instruções, baseado na técnica PBIW, para o conjunto de instruções SPARC revisão 8 (SPARCv8) [4]. O presente trabalho utiliza uma infraestrutura de codificação flexível para aplicar, validar e avaliar o algoritmo PBIW sobre o conjunto de instruções SPARCv8. A aplicação de PBIW sobre programas SPARC será doravante denominada PBIW- SPARC. Apresenta-se também um conjunto de experimentos visando validar e avaliar a técnica comparando com programas gerados para o conjunto de instruções SPARCv8. Alguns resultados são comparados com outra técnica de codificação de instruções denominada SPARC16 [5]. O intuito principal é mostrar ganhos sobre a área de memória ocupada e desempenho de programas SPARC ao adotar um esquema de codificação como PBIW. Além disso, objetiva-se também mostrar que o projeto e implementação de codificadores de instruções pode ser facilitado com uma infraestrutura de codificação. Neste artigo, a Seção II apresenta trabalhos relacionados com esta proposta; a Seção III detalha a infraestrutura de codificação PBIW e o algoritmo de codificação; a Seção IV apresenta o projeto e implementação da estratégia de codificação PBIW para o conjunto de instruções SPARCv8 e o projeto do decodificador PBIW-SPARC; os experimentos e resultados obtidos são apresentados na Seção V; por fim, as conclusões e propostas de trabalhos futuros estão presentes na Seção VI. II. TRABALHOS RELACIONADOS O intuito de codificar instruções consiste na perspectiva de reduzir o tamanho das instruções, mantendo-as com informações semânticas, com o objetivo de reduzir o espaço ocupado em memória pelo programa e, possibilitando que a instrução possa interagir com os estágios iniciais da via de dados do processador, minimizando os impactos de desempenho oriundos da decodificação. Apresenta-se nos próximos parágrafos, algumas propostas de codificação de instruções e considera-se que taxa de compressão/codificação (TC) é:
2 TC Tamanho Programa Codificado + Overhead Tamanho Programa Não - Codificado O Overhead é devido à criação de palavras de dicionário ou padrões de código. A técnica de codificação Thumb [6] aumenta a densidade de código ARM sem grandes perdas de desempenho. O conjunto de instruções Thumb é um subconjunto das instruções ARM codificado em 16 bits. A codificação Thumb resultou em uma taxa de compressão de 70%. Em 2003 a ARM anunciou a tecnologia Thumb-2 [7], que aumenta a densidade de código misturando instruções de 16 bits e 32 bits, ambas no mesmo fluxo de instruções. Isso foi possível pela incorporação de acessos a endereços não alinhados no projeto da arquitetura. Thumb-2 tem desempenho superior (ou próximo) ao do conjunto de instruções ARM e densidade de código semelhante ao da ISA Thumb original. A codificação Thumb/Thumb-2 necessita de um decodificador na via de dados do processador. A técnica MIPS16 [8] é um mecanismo de codificação para instruções MIPS. Cada instrução MIPS16 corresponde a exatamente uma instrução MIPS. Para reduzir o tamanho da instrução para 16 bits, são utilizados três campos da instrução: opcodes, número de registradores e valores imediatos. Há duplo fluxo de instruções (codificadas e originais) e a necessidade de um decodificador de instruções MIPS16 na via de dados do processador. Em testes realizados pelos autores, a taxa de compressão alcançada foi de 60%. A técnica SPARC16 [5] representa uma escolha entre oportunidade de codificação e impacto do resultado. Para reduzir instruções da ISA SPARCv8 para 16 bits, observou-se que os campos mais importantes para redução, são os de valores imediatos que podem ocupar mais da metade da instrução. A tradução é realizada por meio de um decodificador localizado entre a cache de instruções e o pipeline do SPARCv8. Conforme experimentos realizados pelos autores, a taxa de codificação média obtida foi de 60% em relação ao SPARCv8 nativo. Também, houve redução significativa no número de cache misses para caches de vários tamanhos. A técnica PBIW sobre o processador ρ-vex [9] codifica todas as instruções da ISA VLIW VEX. A codificação PBIW é baseada em padrões de instruções, sendo que o processo de codificação percorre o programa realizando a fatoração de operandos redundantes e opcodes em dois elementos: instruções codificadas e padrões. PBIW explora a sobrejeção entre o conjunto de instruções e o conjunto de padrões. Os padrões são armazenados em uma memória ou tabela de padrões. A reconstituição da instrução original é realizada por um decodificador na via de dados do processador, que recombina campos da instrução codificada e seu padrão correspondente. Conforme experimentos realizados pelos autores, obteve-se taxa de compressão de 60,97% e aumento na taxa de acertos de até 53,93%. As técnicas Thumb/Thumb-2, MIPS16 e SPARC16 são restritas a conjuntos de instruções específico. A técnica PBIW é independente de ISA/processador, podendo ser adequada e (1) aplicada em várias outras ISAs alvo. PBIW realiza o mapeamento de diferentes instruções para um mesmo padrão, como uma função sobrejetora entre o conjunto de instruções codificadas e padrões. III. INFRAESTRUTURA DE CODIFICAÇÃO BASEADA EM PADRÕES A codificação PBIW tem como principal característica ser aplicável em várias Instruction Set Architectures (ISAs) diferentes. Com base nessa premissa, foi desenvolvida uma infraestrutra de software [10], com o intuito de facilitar o uso do algoritmo PBIW em diversos tipos de ISA. Essa infraestrutura agiliza a integração entre o algoritmo PBIW e a ISA alvo da codificação. A. Técnica de Codificação PBIW A técnica de codificação PBIW [1] é focada na exploração da sobrejeção entre conjuntos de instruções codificadas e seus respectivos padrões, com o intuito de reduzir o tamanho do programa em memória. Esta técnica foi inicialmente projetada para atender arquiteturas Very Long Instruction Word (VLIW) [11]. A técnica é composta por um algoritmo baseado em fatoração de operandos [3] e por uma tabela de padrões Pattern cache (P-Cache). O algoritmo percorre as instruções do programa e extrai operandos redundantes. O algoritmo mantém a posição original e o opcode dos operandos em um padrão da instrução. As instruções codificadas são armazenadas como as instruções originais (memória principal ou cache de instruções) enquanto que os padrões são armazenados em uma tabela de padrões (dicionário) junto ao hardware decodificador ou mesmo podem ser armazenados em uma memória cache de padrões. O projeto do formato do padrão e instrução codificada PBIW para uma ISA ou processador específico, devem levar em consideração algumas características da arquitetura alvo [1]: Número de registradores de leitura; Número de registradores de escrita; Número de imediatos; Tamanho do índice (ponteiro) para a tabela de padrões na P-Cache. Ao projetar a instrução codificada, além das características mencionadas, é necessário que os operandos de uma instrução sejam mantidos na instrução codificada, enquanto que os campos que possuem sinais de controles devem ser armazenados no padrão. Isso se justifica pela possibilidade dos operandos serem lidos no banco de registradores, paralelamente ao processo de codificação de instruções. Essa é uma das características que diferenciam PBIW de outras técnicas de codificação uma vez que a instrução PBIW codificada mantém parte da semântica da instrução original e, com isso, pode ser parcialmente executada em paralelo com a decodificação. O padrão é uma estrutura de dados que armazena os campos que, combinados aos operandos armazenados na

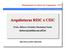
3 instrução codificada, reconstitui a instrução original. Cada operação representada no padrão, contém um opcode e um número fixo de campos que representam os operandos. Os campos que representam os operandos no padrão conservam suas posições originais e armazenam o índice referente ao campo na instrução codificada que armazena seu respectivo operando. B. Infraestrutura de Codificação PBIW Com o intuito de facilitar o uso do algoritmo PBIW, foi desenvolvida uma infraestrutra de software modular e extensível [10] a diversos tipos de ISAs e representações específicas de arquivos de entrada e saída. A infraestrutura de codificação pode ser estendida para suportar alguns tipos de formatos de programas (entradas para a infraestrutura): Texto em linguagem de montagem (.s,.asm, etc.); Estruturas de dados finais providos pelo backend de um compilador; Binários Executable and Linkable Format (ELF). Exemplos de algoritmos PBIW genéricos, especificamente otimizados e inicialmente disponíveis na infraestrutura de codificação incluem: Codificação PBIW genérica: algoritmo parametrizável capaz de se adequar a diversas ISAs de entradas; Codificação VLIW Example (VEX) PBIW [9], [10]. A infraestrutura de codificação PBIW, por padrão, está preparada para realizar a codificação PBIW sobre o conjunto de instruções baseado na ISA VEX [12]. Assim, visando a utilização dessa infraestrutura para prover uma ferramenta de codificação para a ISA SPARCv8 foi necessário estender e implementar interfaces de software dessa infraestrutura para adequá-la às entradas e saídas necessárias para codificação PBIW-SPARC. A arquitetura da infraestrutura é composta por três módulos [10]: o contexto de montagem, o contexto de codificação e o contexto de otimização. O fluxo de dados e controle do processo de codificação PBIW pode ser visto na Figura 1. Figura 1. Fluxo de dados da infraestrutura de codificação PBIW [10]. O programa de entrada é processado pelo contexto de montagem que gera uma representação interna. Esta representação interna é totalmente dependente do montador, tipo de arquitetura e da estrutura de montagem. A infraestrutura de codificação, por meio de interfaces que devem ser implementadas, torna a representação interna acessível ao contexto de codificação. As interfaces fornecem métodos de acesso aos dados internos que estão encapsulados, através de uma camada de abstração entre diferentes implementações possíveis dos contextos de montagem e os algoritmos de codificação PBIW. Após o processo de codificação é possível aplicar otimizações sobre o conjunto de padrões e instruções codificadas resultantes. Depois das etapas de montagem e/ou codificação, pode-se realizar a impressão dos dados gerados, utilizando classes denominadas impressoras. As classes impressoras têm acesso às instruções, padrões e demais dados disponíveis e podem imprimir desde informações de depuração, passando por arquivos de descrição de hardware e até mesmo gerar arquivos binários ELF completos. IV. ESQUEMA DE CODIFICAÇÃO PBIW SOBRE A ARQUITETURA SPARC Apesar da larga utilização do conjunto de instruções SPARC [13] tanto em projetos do meio acadêmico quanto comercial, seja no âmbito de sistemas embarcados quanto alto desempenho, a exploração de técnicas de codificação ainda é limitada [5]. Outra motivação para aplicação de técnicas de codificação é atribuída ao processador Leon3 [14], que implementa a arquitetura SPARCv8 e seu código fonte é disponibilizado completamente sob a licença GNU. A. Arquitetura SPARCv8 A arquitetura Scalable Processor Architecture (SPARC) está publicada como padrão IEEE Ela define registradores de propósito geral, de ponto flutuante, de controle/status e 72 instruções, todas codificadas em formatos de 32 bits. Um processador SPARC, logicamente compreende uma Unidade de Inteiro (UI), uma Unidade de Ponto Flutuante (UPF) e opcionalmente, um coprocessador, cada com seus respectivos registradores. A seguir são listadas algumas características da arquitetura SPARCv8 [4]: 1) Alinhamento: Espaço de endereços linear de 32 bits. 2) Poucos modos de endereçamento: Formados por registrador + registrador ou registrador + imediato. 3) Tríade de endereços de registradores: A maioria das instruções opera em dois ou três operandos e atribui o resultado em um terceiro registrador. 4) Banco de registradores em janelas "windowed": A qualquer instante estão visíveis ao programa oito registradores inteiros globais, mais uma janela de 24 registradores, que podem ser descritos como uma cache de argumentos de procedimentos, valores locais e endereços de retorno. As instruções da ISA SPARCv8 são organizadas em três formatos, conforme apresentado na Figura 2.
![24 bits e 16 bits respectivamente e são mostrados nas Figuras 3 e 4. Figura 2. Formatos de instrução SPARC [4].](/docs-images/83/88488228/images/4-1.jpg "O campo op é o único comum aos três formatos, sendo ele o identificador do formato da instrução.")
4 24 bits e 16 bits respectivamente e são mostrados nas Figuras 3 e 4. Figura 2. Formatos de instrução SPARC [4]. O campo op é o único comum aos três formatos, sendo ele o identificador do formato da instrução. O campo op com valor 1, indica o formato 1, utilizado apenas pela instrução CALL, que além do campo op possui o campo disp30, um imediato de 30 bits. Esse campo é deslocado dois bits à esquerda e somado ao Program Counter (PC) quando a instrução CALL é executada. Dessa forma, todos os endereços de memória podem ser alcançados pela instrução CALL. Quando op é zero, o formato 2 é utilizado. O formato 3 é utilizado, quando op é 3, por instruções de memória ou quando op é igual a 2, por instruções aritméticas, lógicas, de deslocamentos e demais instruções. B. Codificação PBIW-SPARC Seguindo a especificação de projeto baseada no algoritmo PBIW, a técnica PBIW-SPARC permite a codificação de todas as instruções da ISA SPARCv8. Para cada instrução codificada PBIW-SPARC há exatamente uma correspondente SPARCv8. Nenhuma instrução adicional foi criada. A codificação PBIW-SPARC realiza sua codificação sobre um arquivo binário ELF gerado por uma compilador com backend para o conjunto de instruções SPARCv8. Após a codificação são gerados um conjunto de instruções codificadas e um conjunto de padrões, armazenados nas seções.text e.pattern do arquivo binário ELF. O leiaute de padrão e instrução codificada utilizados são armazenados na seção.layout. Para definição do tamanho do padrão e instrução codificada PBIW-SPARC, optou-se por reduzir o tamanho da instrução com relação ao padrão, tendo em vista explorar o reúso de padrões. No entanto, há de se considerar a existência de um campo/ponteiro de índice de padrões junto aos demais campos da instrução codificada. Esse campo indica o endereço/índice de memória em que o respectivo padrão da instrução pode ser encontrado. Pode-se observar no leiaute dos três formatos de instrução da ISA SPARCv8, que a quantidade de bits dos campos de operandos varia de bits, sendo inviável mantê-los integralmente na instrução codificada. Optou-se por armazenar apenas a parte mais significativa dos operandos no padrão e a parte menos significativa e mais susceptível a mudanças, na instrução codificada. A única exceção é o campo rs (utilizado pelo formato 3) que é armazenado totalmente na instrução codificada. O leiaute do padrão e da instrução utilizados pela codificação PBIW-SPARC foram definidos com tamanhos de Figura 3. Leiaute do padrão PBIW-SPARC. Figura 4. Leiaute de instrução PBIW-SPARC. A Figura 3 mostra o leiaute do padrão que possui 24 bits e a oganização lógica dos campos de acordo com cada formato de instrução da ISA SPARCv8. Os campos cujo nome contém o símbolo * armazenam apenas a parte mais significativa do campo. A instrução codificada (Figura 4) tem 16 bits e campos com os símbolos ** no nome armazenam a parte mais significativa do campo. O formato possui um campo de 8 bits para o índice do padrão e mais um ou dois campos nos 8 bits restantes. Por exemplo, nas duas situações possíveis para o Formato 2, além do campo de índice do padrão, a instrução codificada pode armazenar, no primeiro caso, os 3 bits menos significativos do campo rd e os 5 bits menos significativos do imediato imm22. No segundo caso, pode armazenar os 8 bits menos significativos do imediato simm1. A codificação com instruções de 16 bits está limitada a endereçar no máximo 256 padrões (campo de índice de padrão de 8 bits). Para superar essa limitação e permitir a execução de códigos que geram mais que 256 padrões, utilizou-se uma codificação híbrida (parte do programa é codificada e parte permanece original) em alguns programas. Para tanto, utilizou-se o bit 21 da instrução NOP para indicar ao decodificador se a próxima instrução deve ou não ser decodificada.


5 Após o projeto e formato da instrução codificada e padrão PBIW-SPARC, realizou-se a integração dessa especificação junto à infraestrutura de codificação PBIW. Ao incluir esse novo projeto de codificação na infraestrutura PBIW objetivase minimizar o tempo de projeto de um codificador, utilizar mecanismos para validação e avaliação da técnica de codificação e, principalmente, demonstrar a flexibilidade dessa infraestrutura quanto à possibilidade de ser estendida para outros domínios de projetos codificadores. A inclusão do codificador PBIW-SPARC junto à infraestrutura pode ser vista na Figura 5. Na parte superior da Figura 6 há a instrução PBIW que pode se encaixar em qualquer combinação de bits dos 3 formatos. A partir da busca da instrução na cache de instruções, realiza-se a leitura do campo de índice de padrões e então, o padrão endereçado é buscado na tabela de padrões (Pcache). De acordo com o campo op presente no padrão definese o formato da instrução, que em combinação com o campo opcode (exceto o formato 1, que não possui este campo), respectivo ao formato, configura os multiplexadores para selecionar a instrução decodificada. Observe que as entradas de dados dos multiplexadores são oriundas das unidades de reordenação que atuam, paralelamente, reorganizando os dados e sinais de controle de acordo com cada formato específico. Após esse passo, a instrução original já está recomposta e pode ser despachada para o estágio de decode do pipeline. V. EXPERIMENTOS E RESULTADOS Os experimentos visando a validação e avaliação da técnica de codificação PBIW-SPARC foram realizados utilizando programas dos benchmarks MiBench [15] e MediaBench [16]. Todos os programas foram compilados com o cross-compiler GCC para arquitetura SPARCv8, disponibilizado pelo projeto ArchC [17]. Para validação dos resultados e avaliação de desempenho foram utilizados simuladores para o conjunto de instruções SPARCv8 projetados em ArchC. Um desses simuladores SPARCv8, com suporte às instruções codificadas PBIW-SPARC, foi desenvolvido neste trabalho. Figura 5. Infraestrutura de codificação PBIW após contexto de codificação PBIW-SPARC. C. Decodificador PBIW-SPARC Baseando-se na organização da via de dados e controle do processador soft-core Leon3 [14], o circuito decodificador PBIW-SPARC foi implementado no início do estágio de decode do pipeline desse processador. O diagrama de blocos do circuito decodificador PBIW-SPARC é apresentada na Figura 6. A. Experimentos Estáticos As Figuras 7 e 8 mostram a taxa de compressão para cada programa dos benchmarks MiBench e MediaBench, respectivamente. Para os programas desses benchmarks, houve a necessidade de utilizar uma codificação híbrida (parte do código possui instruções codificadas) uma vez que, na codificação total o número de padrões gerados extrapola o alcance do campo de índice de padrões. Figura 6. Diagrama de blocos do decodificador PBIW-SPARC para Leon3. Figura 7. Taxa de compressão para o conjunto de programas do MiBench.

6 SPARCv8. Portanto, o número de ciclos (CP) gastos na execução de um programa é dado por: Se o programa for codificado, o Número de misses deve ser a soma dos misses de instrução e padrão PBIW-SPARC. As Tabelas I e II mostram a análise da quantidade de ciclos de clock para execução e speedup para os benchmarks MiBench e MediaBench. Figura 8. Taxa de compressão para o conjunto de programas do MediaBench. No benchmark Mibench, as taxas de compressão dos programas variaram de 62%-88%. No benchmark MediaBench, as taxas de compressão variaram entre 67%- 72%. Essa pequena variação acontece como consequência imediata da variação nos tamanhos originais dos programas. O maior valor de reúso de padrões TR Número de instruções codificadas ( ) obtido foi de 74 Número de padrões padrões por instrução. Considerando a taxa de compressão realizada apenas pelas instruções codificadas, as taxas de compressão alcançáveis são próximas do limite ótimo de 50%, uma vez que a variação foi de 51%-53% para os programas de ambos os benchmarks. B. Experimentos Dinâmicos O desempenho dos programas foi avaliado com base nas seguintes métricas: quantidade de instruções (e padrões) executadas; quantidade total de misses de instruções e padrões; ciclos totais de execução e speedup PBIW-SPARC sobre SPARC. Para obter o impacto do código sobre as caches de instruções e padrões, utilizou-se o simulador de caches Dinero [18]. Para obter os resultados de ciclos e instruções executadas utilizou-se o simulador SPARCv8 implementado em ArchC [17]. A validação e avaliação de desempenho dos programas codificados PBIW-SPARC também foram realizadas com a adoção de um simulador SPARCv8 implementando em ArchC. Esse simulador foi desenvolvido exclusivamente neste trabalho. Os experimentos foram realizados considerando caches organizadas com conjuntos associativos de 2 vias, blocos de 2 e 4 bytes e tamanho de 1 kbyte. Como a codificação PBIW- SPARC utiliza uma cache para padrões e outra para instruções, projetou-se uma cache de instruções codificadas de 768 bytes e uma cache de padrões de 256 bytes objetivando manter a mesma área de memória dos programas originais. O speedup foi calculado a partir da quantidade de ciclos obtidos pelos programas PBIW-SPARC e SPARC (original). A ocorrência de cache misses é penalizada em 10 ciclos para a instrução PBIW-SPARC, para o padrão e para instrução Tabela 1. Ciclos de execução e desempenho de programas do MiBench. Ciclos de Execução Programa SPARCv8 PBIW-SPARC speedup basicmath_large ,15 basicmath_small ,14 bitcount ,00 crc_ ,00 dijkstra_small ,75 dijkstra_large ,10 fft ,09 lame ,13 patricia ,18 qsort_large ,25 qsort_small ,05 rijndael ,29 sha ,01 susan ,09 Tabela 2. Tempo de execução e desempenho de programas do MediaBench. Tempo de Execução (ciclos) Programa SPARCv8 PBIW-SPARC speedup cjpeg ,95 djpeg ,02 gsm-toast ,17 gsm-untoast ,18 mpeg2decode ,11 mpeg2encode ,96 pegwit ,01 rawcaudio ,00 rawdaudio ,00 timing ,00 Para o benchmark MiBench, o melhor desempenho foi alcançado pelo programa dijkstra, com speedup de 1,75. O pior desempenho foi obtido com os programas crc e bitcounts, com speedup 1,00. O speedup médio para os programas do MiBench foi 1,16. No benchmark MediaBench, o pior desempenho foi do programa cjpeg e o melhor desempenho foi do programa gsm-untoast com 1,18 de speedup. Os programas do MediaBench alcançaram um speedup médio de 1,04 (1,10 com média ponderada). Dentre os programas analisados quanto ao speedup, observa-se que o programa rijndael do benchmark MiBench foi avaliado sob a técnica de codificação SPARC16 [5], obtendo speedup de 1,12 considerando que cada miss na cache de instruções tem penalidade de 10 ciclos e speedup de 1,33 com penalidade de 50 ciclos. A técnica PBIW-SPARC, considerando penalidade de 10 ciclos para instrução ou padrão, obteve speedup de 1,29.
7 VI. COMPARAÇÕES DAS CODIFICAÇÕES PBIW-SPARC E SPARC16 A codificação PBIW-SPARC obteve, para os benchmarks avaliados, taxas de compressão entre 62% e 88%, com média de 65%. Os resultados da compressão de código foram obtidos a partir da codificação de cada programa avaliado. A técnica de codificação SPARC16 apresenta taxa de compressão para os benchmarks MiBench e Mediabench, variando entre 56,4% e 63,9% e, com média de 61,02%. A taxa de compressão apresentada por SPARC16 é uma estimativa e desconsidera a limitação de referenciar apenas 08 registradores assim como a sobrecarga gerada no código devido a trocas de contexto (troca de seções de código de 16 bits para 32 bits). Ao caracterizar os programas gerados pelos benchmarks Mibench e Mediabench com o compilador GCC e sem o uso de otimizações, todos os programas utilizaram os 32 registradores disponíveis. Tal resultado já era esperado uma vez que a manipulação de registradores em janela da arquitetura SPARC estimula a utilização de vários registradores distintos ao longo do código. Na comparação da área ocupada pelos decodificadores PBIW-SPARC e SPARC16, realizada sobre um dispositivo FPGA Altera Cyclone II, o decodificador PBIW-SPARC gerou um aumento de área do processador Leon3 de 6,1% enquanto que o decodificador SPARC16 aumentou a área em 9,4%. O circuito decodificador e a técnica de codificação SPARC16 não oferecem suporte a instruções de ponto flutuante, sendo necessário adaptações em ambos, o que pode aumentar a área e número de elementos lógicos do processador. Mesmo sendo um circuito consideravelmente simples e com pouco impacto na área ocupada pelo processador, o decodificador PBIW-SPARC está apto para realizar a decodificação de qualquer programa codificado com a técnica PBIW-SPARC. VII. CONCLUSÕES E TRABALHOS FUTUROS Este trabalho apresentou o projeto e implementação de um codificador de instruções, baseado na técnica de codificação PBIW, para o conjunto de instruções SPARCv8 (PBIW- SPARC). A aplicação do algoritmo de codificação PBIW- SPARC foi realizada utilizando-se da infraestrutura de codificação PBIW. Devido a limitada capacidade de endereçamento de padrões da instrução codificada de 16 bits, houve a necessidade de projetar mecanismos para codificação híbrida de programas SPARC. Assim, um programa codificado com PBIW-SPARC suporta tanto instruções codificadas de 16 bits quanto instruções originais de 32 bits. Os programas codificados sob a técnica de codificação PBIW-SPARC obtiveram redução de tamanho do código que variaram entre 38%-11% em todos os programas avaliados. Na experimentação dinâmica, foram avaliados a quantidade total de ciclos executados, baseando-se na taxa de cache miss, e desempenho (speedup). A variação de speedup entre os programas avaliados foi de 0,95-1,75. Dentre os trabalhos futuros, apresenta-se a possibilidade de avaliar os efeitos do decodificador PBIW-SPARC quanto à potência dissipada, energia e frequência máxima alcançável pelo processador. VIII. AGRADECIMENTOS Os autores agradecem as agências de fomento de pesquisa CAPES, CNPq e Fundect-MS, além das instituições UFMS e IFMS pelo financiamento de vários projetos de pesquisa desenvolvidos no Laboratório de Sistemas Computacionais de Alto Desempenho (LSCAD) da Faculdade de Computação da UFMS. REFERENCES [1] R. Batistella, PBIW: Um Esquema de Codificacão Baseado em Padrões de Instrucão, Master s thesis, Unicamp, Brazil, Fevereiro [2] R. Santos, R. Batistella, and R. Azevedo, A Pattern Based Instruction Encoding Technique For High Performance Architectures, IJHPSA, vol. 2, no. 2, pp , [3] G. Araujo, P. Centoducatte, M. Cortes, and R. Pannain, Code Compression Based on Operand Factorization, in Proceedings of the 31st Annual ACM/IEEE MICRO. IEEE Computer Society, 1998, pp [4] I. SPARC International, The SPARC Architecture Manual, SPARC International, Inc., Tech. Rep., [5] L. L. Ecco, B. C. Lopes, E. C. Xavier, R. Pannain, P. Centoducatte, and R. J. de Azevedo, SPARC16: A New Compression Approach for the SPARC Architecture, in Proceedings of the 21st SBAC-PAD. Washington, DC, USA: IEEE Computer Society, 2009, pp [6] L. Goundge and S. Segars, Thumb: Reducing the Cost of 32-bit RISC Performance in Portable and Consumer Applications, Proceedings of Computer Society Conference, [7] A. Holdings, ARM1156T2-S Technical Reference Manual, ndex.html, Tech. Rep., , pp [8] K. D. Kissell, Mips16: High-density MIPS for the Embedded Market. Real Time Systems, [9] R. Marks, F. Araújo, R. Santos, F. Yonehara, and R. Santos, Design and Implementation of the PBIW Instruction Decoder in a Softcore Embedded Processor, in 13th WSCAD-SSC. IEEE, 2012, pp [10] R. A. MARKS, Infraestrutura para Codificação de Instrucões Baseada em Fatoracão de Padrões, Master s thesis, UFMS, Brazil, Novembro [11] M. Len and I. Vaitsman, VLIW: Old Architecture of the New Generation, Mar. 2011, [12] J. A. Fisher, P. Faraboschi, and C. Young, Embedded Computing: A VLIW Approach to Architecture, Compilers and Tools. Elsevier, [Online]. Available: [13] SPARC International, Inc., Fevereiro [14] Glaiser, LEON 3 Processor, w\&id=13n&itemid=53, Mar [15] T. M. A. T. M. Matthew R. Guthaus; Jeffrey S. Ringenberg; Dan Ernst, MiBench Version 1.0, [online], 2001, [16] C. Lee, M. Potkonjak, and W. Mangione-Smith, MediaBench Consortium, [online], 1997, [17] L. Computers Systems Laboratory IC UNICAMP, ArchC - Architechture Description Language, [online], [18] J. Edler and M. D. Hill, Dinero IV Trace-Driven Uniprocessor Cache Simulator, [online], 1995,
Projeto e Implementação do Decodificador PBIW em Hardware. Felipe de Oliveira de Araújo Felipe Yonehara
 Projeto e Implementação do Decodificador PBIW em Hardware Felipe de Oliveira de Araújo Felipe Yonehara A técnica de codificação PBIW A técnica PBIW ( Pattern Based Instruction Word) é composta por um algoritmo
Projeto e Implementação do Decodificador PBIW em Hardware Felipe de Oliveira de Araújo Felipe Yonehara A técnica de codificação PBIW A técnica PBIW ( Pattern Based Instruction Word) é composta por um algoritmo
Projeto e Implementação de Decodificadores de Código em Plataformas FPGA
 Projeto e Implementação de Decodificadores de Código em Plataformas FPGA Felipe de Oliveira de Araújo 1, Ricardo Ribeiro dos Santos 2 1 Faculdade de Engenharia (FAENG) Universidade Federal do Mato Grosso
Projeto e Implementação de Decodificadores de Código em Plataformas FPGA Felipe de Oliveira de Araújo 1, Ricardo Ribeiro dos Santos 2 1 Faculdade de Engenharia (FAENG) Universidade Federal do Mato Grosso
CARACTERIZAÇÃO DE DECODIFICADORES DE CÓDIGO SOBRE OS SOFT- CORES ρ-vex E LEON3 EM PLATAFORMAS FPGA
 CARACTERIZAÇÃO DE DECODIFICADORES DE CÓDIGO SOBRE OS SOFT- CORES ρ-vex E LEON3 EM PLATAFORMAS FPGA Márcio Afonso Soleira Grassi 1 & Ricardo Ribeiro dos Santos 2 1 Aluno do Curso de Engenharia Elétrica
CARACTERIZAÇÃO DE DECODIFICADORES DE CÓDIGO SOBRE OS SOFT- CORES ρ-vex E LEON3 EM PLATAFORMAS FPGA Márcio Afonso Soleira Grassi 1 & Ricardo Ribeiro dos Santos 2 1 Aluno do Curso de Engenharia Elétrica
AULA 03: FUNCIONAMENTO DE UM COMPUTADOR
 ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES I AULA 03: FUNCIONAMENTO DE UM COMPUTADOR Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação O QUE É UM COMPUTADOR?
ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES I AULA 03: FUNCIONAMENTO DE UM COMPUTADOR Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação O QUE É UM COMPUTADOR?
ESTUDO SOBRE O IMPACTO DOS PROCESSADORES HOSPEDEIROS SPARC V8 E NIOS II NO DESEMPENHO DA ARQUITETURA RECONFIGURÁVEL HÍBRIDA RoSA
 ESTUDO SOBRE O IMPACTO DOS PROCESSADORES HOSPEDEIROS SPARC V8 E NIOS II NO DESEMPENHO DA ARQUITETURA RECONFIGURÁVEL HÍBRIDA RoSA Alba S. B. Lopes Departamento de Informática e Matemática Aplicada da UFRN
ESTUDO SOBRE O IMPACTO DOS PROCESSADORES HOSPEDEIROS SPARC V8 E NIOS II NO DESEMPENHO DA ARQUITETURA RECONFIGURÁVEL HÍBRIDA RoSA Alba S. B. Lopes Departamento de Informática e Matemática Aplicada da UFRN
1. A pastilha do processador Intel possui uma memória cache única para dados e instruções. Esse processador tem capacidade de 8 Kbytes e é
 1. A pastilha do processador Intel 80486 possui uma memória cache única para dados e instruções. Esse processador tem capacidade de 8 Kbytes e é organizado com mapeamento associativo por conjuntos de quatro
1. A pastilha do processador Intel 80486 possui uma memória cache única para dados e instruções. Esse processador tem capacidade de 8 Kbytes e é organizado com mapeamento associativo por conjuntos de quatro
Code Compression for Embedded Systems
 Daniel Stefani Marcon, Thiago Nunes Kehl 30 de maio de 2008 1 2 3 4 Sistemas Embarcados os sistemas embarcados são dispositivos invisíveis se limitam a executar bem uma única tarefa basicamente qualquer
Daniel Stefani Marcon, Thiago Nunes Kehl 30 de maio de 2008 1 2 3 4 Sistemas Embarcados os sistemas embarcados são dispositivos invisíveis se limitam a executar bem uma única tarefa basicamente qualquer
Tópicos Avançados em Sistemas Computacionais: Infraestrutura de Hardware Aula 10
 Tópicos Avançados em Sistemas Computacionais: Infraestrutura de Hardware Aula 10 Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação QUAL É A INTERFACE ENTRE
Tópicos Avançados em Sistemas Computacionais: Infraestrutura de Hardware Aula 10 Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação QUAL É A INTERFACE ENTRE
Arquitetura de Computadores Aula 11 - Multiprocessamento
 Arquitetura de Computadores Aula 11 - Multiprocessamento Prof. Dr. Eng. Fred Sauer http://www.fredsauer.com.br fsauer@gmail.com 1/28 PROCESSAMENTO PARALELO OBJETIVO: aumentar a capacidade de processamento.
Arquitetura de Computadores Aula 11 - Multiprocessamento Prof. Dr. Eng. Fred Sauer http://www.fredsauer.com.br fsauer@gmail.com 1/28 PROCESSAMENTO PARALELO OBJETIVO: aumentar a capacidade de processamento.
Organização de Sistemas de Computadores
 Organização de Sistemas de Computadores Cap. 2 (Tanenbaum), Cap. 3 (Weber) 2.1 Processadores 1 CPU UC = buscar instruções na memória principal e determinar o seu tipo ULA = adição e AND Registradores =
Organização de Sistemas de Computadores Cap. 2 (Tanenbaum), Cap. 3 (Weber) 2.1 Processadores 1 CPU UC = buscar instruções na memória principal e determinar o seu tipo ULA = adição e AND Registradores =
Infraestrutura de Hardware. Instruindo um Computador
 Infraestrutura de Hardware Instruindo um Computador Componentes de um Computador Unid. Controle Controle Memória Registradores PC MAR IR AC Programa + Dados Instrução Endereço Operando ALU Temp Datapath
Infraestrutura de Hardware Instruindo um Computador Componentes de um Computador Unid. Controle Controle Memória Registradores PC MAR IR AC Programa + Dados Instrução Endereço Operando ALU Temp Datapath
SSC510 Arquitetura de Computadores 1ª AULA
 SSC510 Arquitetura de Computadores 1ª AULA REVISÃO DE ORGANIZAÇÃO DE COMPUTADORES Arquitetura X Organização Arquitetura - Atributos de um Sistema Computacional como visto pelo programador, isto é a estrutura
SSC510 Arquitetura de Computadores 1ª AULA REVISÃO DE ORGANIZAÇÃO DE COMPUTADORES Arquitetura X Organização Arquitetura - Atributos de um Sistema Computacional como visto pelo programador, isto é a estrutura
3. DESCRIÇÃO DO SPARC Histórico
 20 3. DESCRIÇÃO DO SPARC 3.1 - Histórico O SPARC, acrossemia para Scalable Processor ARChitecture, originou-se nos projetos pioneiros de Berkeley, desenvolvidos a partir de 1981 por alunos de graduação
20 3. DESCRIÇÃO DO SPARC 3.1 - Histórico O SPARC, acrossemia para Scalable Processor ARChitecture, originou-se nos projetos pioneiros de Berkeley, desenvolvidos a partir de 1981 por alunos de graduação
FERRAMENTA DE PROFILING PARA PROCESSADORES SCHNEIDER, R. C. 1, NEVES, B. S. 1
 FERRAMENTA DE PROFILING PARA PROCESSADORES SCHNEIDER, R. C. 1, NEVES, B. S. 1 1 Universidade Federal do Pampa (UNIPAMPA) Bagé RS Brasil RESUMO O aumento da complexidade dos processadores e de suas etapas
FERRAMENTA DE PROFILING PARA PROCESSADORES SCHNEIDER, R. C. 1, NEVES, B. S. 1 1 Universidade Federal do Pampa (UNIPAMPA) Bagé RS Brasil RESUMO O aumento da complexidade dos processadores e de suas etapas
Universidade Federal do Rio de Janeiro Bacharelado de Ciência da Computação. Arquitetura de Computadores I. RISC versus CISC
 Universidade Federal do Rio de Janeiro Bacharelado de Ciência da Computação Arquitetura de Computadores I RISC versus CISC Gabriel P. Silva 04.11.2014 Introdução Um dos objetivos de uma arquitetura de
Universidade Federal do Rio de Janeiro Bacharelado de Ciência da Computação Arquitetura de Computadores I RISC versus CISC Gabriel P. Silva 04.11.2014 Introdução Um dos objetivos de uma arquitetura de
Introdução à Computação: Máquinas Multiníveis
 Introdução à Computação: Máquinas Multiníveis Beatriz F. M. Souza (bfmartins@inf.ufes.br) http://inf.ufes.br/~bfmartins/ Computer Science Department Federal University of Espírito Santo (Ufes), Vitória,
Introdução à Computação: Máquinas Multiníveis Beatriz F. M. Souza (bfmartins@inf.ufes.br) http://inf.ufes.br/~bfmartins/ Computer Science Department Federal University of Espírito Santo (Ufes), Vitória,
Microprocessadores CPU. Unidade de Controle. Prof. Henrique
 Microprocessadores CPU Unidade de Controle Prof. Henrique Roteiro Registradores; Unidade de Controle Níveis de Complexidade Introdução Um sistema microprocessado conta com diversos dispositivos para um
Microprocessadores CPU Unidade de Controle Prof. Henrique Roteiro Registradores; Unidade de Controle Níveis de Complexidade Introdução Um sistema microprocessado conta com diversos dispositivos para um
INTRODUÇÃO À TECNOLOGIA DA INFORMAÇÃO ORGANIZAÇÃO COMPUTACIONAL
 INTRODUÇÃO À TECNOLOGIA DA ORGANIZAÇÃO COMPUTACIONAL PROFESSOR CARLOS MUNIZ ORGANIZAÇÃO DE UM COMPUTADOR TÍPICO Memória: Armazena dados e programas Processador (CPU - Central Processing Unit): Executa
INTRODUÇÃO À TECNOLOGIA DA ORGANIZAÇÃO COMPUTACIONAL PROFESSOR CARLOS MUNIZ ORGANIZAÇÃO DE UM COMPUTADOR TÍPICO Memória: Armazena dados e programas Processador (CPU - Central Processing Unit): Executa
Nível do Conjunto de Instruções Prof. Edson Pedro Ferlin
 1 Definições Nível ISA (Instruction Set Architecture). Está posicionado entre o nível da microarquitetura e o nível do sistema operacional. É a interface entre o software e o hardware. Nesse nível está
1 Definições Nível ISA (Instruction Set Architecture). Está posicionado entre o nível da microarquitetura e o nível do sistema operacional. É a interface entre o software e o hardware. Nesse nível está
Arquitetura de Computadores. Conjunto de Instruções
 Arquitetura de Computadores Conjunto de Instruções Arquitetura do Conjunto das Instruções ISA (Instruction Set Architecture) Traduz para uma linguagem intermediária (ISA) os vários programas em diversas
Arquitetura de Computadores Conjunto de Instruções Arquitetura do Conjunto das Instruções ISA (Instruction Set Architecture) Traduz para uma linguagem intermediária (ISA) os vários programas em diversas
Arquitetura e Organização de Processadores. Aula 1. Introdução Arquitetura e Organização
 Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 1 Introdução Arquitetura e Organização 1. Arquitetura
Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 1 Introdução Arquitetura e Organização 1. Arquitetura
Microarquiteturas Avançadas
 Universidade Federal do Rio de Janeiro Arquitetura de Computadores I Microarquiteturas Avançadas Gabriel P. Silva Introdução As arquiteturas dos processadores têm evoluído ao longo dos anos, e junto com
Universidade Federal do Rio de Janeiro Arquitetura de Computadores I Microarquiteturas Avançadas Gabriel P. Silva Introdução As arquiteturas dos processadores têm evoluído ao longo dos anos, e junto com
4. Modelo de Programação do DLX Introdução
 4. Modelo de Programação do DLX Quero que o matemático Beremiz Samir nos conte uma lenda, ou uma simples fábula, na qual apareça uma divisão de 3 por 3 indicada, mas não efetuada, e outra de 3 por 2, indicada
4. Modelo de Programação do DLX Quero que o matemático Beremiz Samir nos conte uma lenda, ou uma simples fábula, na qual apareça uma divisão de 3 por 3 indicada, mas não efetuada, e outra de 3 por 2, indicada
Sistemas Operacionais. Conceitos de Hardware
 Sistemas Operacionais Conceitos de Hardware Sumário 1. Introdução 7. RISC e CISC 2. Processador 1. Operações de Processamento 2. Unidade de Controle 3. Ciclos de uma Instrução 3. Memória 1. Memória Principal
Sistemas Operacionais Conceitos de Hardware Sumário 1. Introdução 7. RISC e CISC 2. Processador 1. Operações de Processamento 2. Unidade de Controle 3. Ciclos de uma Instrução 3. Memória 1. Memória Principal
Universidade Federal do Rio de Janeiro Pós-Graduação em Informática. Introdução. Gabriel P. Silva. Gabriel P. Silva
 Universidade Federal do Rio de Janeiro Pós-Graduação em Informática Microarquiteturas de Alto Desempenho Introdução Introdução Bibliografia: Computer Architecture: A Quantitative Approach. John L. Hennesy,
Universidade Federal do Rio de Janeiro Pós-Graduação em Informática Microarquiteturas de Alto Desempenho Introdução Introdução Bibliografia: Computer Architecture: A Quantitative Approach. John L. Hennesy,
Microcontrolador FemtoJava Pipeline (Low Power)
") Microcontrolador FemtoJava Pipeline (Low Power) UFRGS Programa de Pós graduação em Computação CMP 237 Arquitetura e Organização de Processadores Prof. Dr. Flávio Rech Wagner Aluno: Paulo Roberto Miranda
Microcontrolador FemtoJava Pipeline (Low Power) UFRGS Programa de Pós graduação em Computação CMP 237 Arquitetura e Organização de Processadores Prof. Dr. Flávio Rech Wagner Aluno: Paulo Roberto Miranda
Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação
 Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Relatório do Trabalho da Disciplina de Arquitetura e Organização de Processadores CMP- 237 Marcelo
Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Relatório do Trabalho da Disciplina de Arquitetura e Organização de Processadores CMP- 237 Marcelo
Processador: Conceitos Básicos e Componentes
 Processador: Conceitos Básicos e Componentes Cristina Boeres Instituto de Computação (UFF) Fundamentos de Arquiteturas de Computadores Material baseado nos slides de Fernanda Passos Cristina Boeres (IC/UFF)
Processador: Conceitos Básicos e Componentes Cristina Boeres Instituto de Computação (UFF) Fundamentos de Arquiteturas de Computadores Material baseado nos slides de Fernanda Passos Cristina Boeres (IC/UFF)
2. A influência do tamanho da palavra
 1. Introdução O processador é o componente vital do sistema de computação, responsável pela realização das operações de processamento (os cálculos matemáticos etc.) e de controle, durante a execução de
1. Introdução O processador é o componente vital do sistema de computação, responsável pela realização das operações de processamento (os cálculos matemáticos etc.) e de controle, durante a execução de
Notas de Aula Guilherme Sipahi Arquitetura de Computadores
 Notas de Aula Guilherme Sipahi Arquitetura de Computadores Endereçamento O Campo de endereço em uma instrução é pequeno. Para referenciar uma faixa de endereços maior na memória principal, ou em alguns
Notas de Aula Guilherme Sipahi Arquitetura de Computadores Endereçamento O Campo de endereço em uma instrução é pequeno. Para referenciar uma faixa de endereços maior na memória principal, ou em alguns
UMA HIERARQUIA DE MEMÓRIA PARA UM MODELO RTL DO PROCESSADOR RISC-V SINTETISÁVEL EM FPGA
 UNIVERSIDADE FEDERAL DE PERNAMBUCO CENTRO DE INFORMÁTICA GRADUAÇÃO EM ENGENHARIA DA COMPUTAÇÃO UMA HIERARQUIA DE MEMÓRIA PARA UM MODELO RTL DO PROCESSADOR RISC-V SINTETISÁVEL EM FPGA PROPOSTA DE TRABALHO
UNIVERSIDADE FEDERAL DE PERNAMBUCO CENTRO DE INFORMÁTICA GRADUAÇÃO EM ENGENHARIA DA COMPUTAÇÃO UMA HIERARQUIA DE MEMÓRIA PARA UM MODELO RTL DO PROCESSADOR RISC-V SINTETISÁVEL EM FPGA PROPOSTA DE TRABALHO
ARQUITETURA DE COMPUTADORES
 RCM00014 Haswell wafer ARQUITETURA DE COMPUTADORES Prof. Luciano Bertini Site: http://www.professores.uff.br/lbertini/ Objetivos do Curso Entendimento mais aprofundado do funcionamento
RCM00014 Haswell wafer ARQUITETURA DE COMPUTADORES Prof. Luciano Bertini Site: http://www.professores.uff.br/lbertini/ Objetivos do Curso Entendimento mais aprofundado do funcionamento
Infraestrutura de Hardware. Funcionamento de um Computador
 Infraestrutura de Hardware Funcionamento de um Computador Computador: Hardware + Software Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é
Infraestrutura de Hardware Funcionamento de um Computador Computador: Hardware + Software Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é
Organização e Arquitetura de Computadores I
 Organização e Arquitetura de Computadores I Linguagem de Montagem Slide 1 CISC RISC MIPS Organização e Arquitetura de Computadores I Sumário Representação de instruções Slide 2 CISC O CISC (Complex Instruction
Organização e Arquitetura de Computadores I Linguagem de Montagem Slide 1 CISC RISC MIPS Organização e Arquitetura de Computadores I Sumário Representação de instruções Slide 2 CISC O CISC (Complex Instruction
Infraestrutura de Hardware. Implementação Multiciclo de um Processador Simples
 Infraestrutura de Hardware Implementação Multiciclo de um Processador Simples Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é entendido e
Infraestrutura de Hardware Implementação Multiciclo de um Processador Simples Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é entendido e
CPU. Funções: Componentes: Processamento; Controle. UC (Unidade de Controle); Registradores; ALU s, FPU s etc. Arquitetura de Computadores 3
; Registradores; ALU s, FPU s etc. Arquitetura de Computadores 3") CPU CPU Funções: Processamento; Controle Componentes: UC (Unidade de Controle); Registradores; ALU s, FPU s etc. Arquitetura de Computadores 3 Processador A função de um computador é executar tarefas
CPU CPU Funções: Processamento; Controle Componentes: UC (Unidade de Controle); Registradores; ALU s, FPU s etc. Arquitetura de Computadores 3 Processador A função de um computador é executar tarefas
Arquitetura e Organização de Processadores. Aula 08. Arquiteturas VLIW
 Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 08 Arquiteturas VLIW 1. Introdução VLIW é Very
Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 08 Arquiteturas VLIW 1. Introdução VLIW é Very
Estudo do impacto de consumo de potência e desempenho na inserção de um Array Reconfigurável na arquitetura Femtojava Multiciclo
 Estudo do impacto de consumo de potência e desempenho na inserção de um Array Reconfigurável na arquitetura Femtojava Mateus Beck Rutzig mbrutzig@inf.ufrgs.br OUTLINE 1. Conceitos 1.1.Sistemas Embarcados
Estudo do impacto de consumo de potência e desempenho na inserção de um Array Reconfigurável na arquitetura Femtojava Mateus Beck Rutzig mbrutzig@inf.ufrgs.br OUTLINE 1. Conceitos 1.1.Sistemas Embarcados
SSC0114 Arquitetura de Computadores
 SSC0114 Arquitetura de Computadores 3ª Aula Arquitetura MIPS: ISA, Formato das instruções e Modos de endereçamento MIPS Monociclo: Caminho de Dados e Unidade de Controle Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br
SSC0114 Arquitetura de Computadores 3ª Aula Arquitetura MIPS: ISA, Formato das instruções e Modos de endereçamento MIPS Monociclo: Caminho de Dados e Unidade de Controle Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br
ADLs. Exploração de Arquitetura. Aula 05
 ADLs Exploração de Arquitetura Aula 05 Nível de Abstração (+) Simulador.c Mips.c cache.c MEM.c Rapidez nas análises Análise prévia da arquitetura µp Dado Instr MEM (-) Abstração board Desenvolver sistemas
ADLs Exploração de Arquitetura Aula 05 Nível de Abstração (+) Simulador.c Mips.c cache.c MEM.c Rapidez nas análises Análise prévia da arquitetura µp Dado Instr MEM (-) Abstração board Desenvolver sistemas
Aula 16: UCP: Conceitos Básicos e Componentes
 Aula 16: UCP: Conceitos Básicos e Componentes Diego Passos Universidade Federal Fluminense Fundamentos de Arquiteturas de Computadores Diego Passos (UFF) UCP: Conceitos Básicos e Componentes FAC 1 / 34
Aula 16: UCP: Conceitos Básicos e Componentes Diego Passos Universidade Federal Fluminense Fundamentos de Arquiteturas de Computadores Diego Passos (UFF) UCP: Conceitos Básicos e Componentes FAC 1 / 34
Unidade de Controle. UC - Introdução
 Unidade de Controle Prof. Alexandre Beletti (Cap. 3 Weber, Cap.8 Monteiro, Cap. 10,11 Stallings) UC - Introdução Para gerenciar o fluxo interno de dados e o instante em que ocorrem as transferências entre
Unidade de Controle Prof. Alexandre Beletti (Cap. 3 Weber, Cap.8 Monteiro, Cap. 10,11 Stallings) UC - Introdução Para gerenciar o fluxo interno de dados e o instante em que ocorrem as transferências entre
Arquitetura de Computadores Unidade Central de Processamento CPU
 Arquitetura de Computadores Unidade Central de Processamento CPU CPU Funções realizadas pelo processador: Função controle Responsável pela busca, interpretação e controle da execução das instruções, bem
Arquitetura de Computadores Unidade Central de Processamento CPU CPU Funções realizadas pelo processador: Função controle Responsável pela busca, interpretação e controle da execução das instruções, bem
Conjunto de Instruções e Modelos de Arquiteturas
 Departamento de Engenharia Elétrica e de Computação EESC-USP SEL-0415 Introdução à Organização de Computadores Conjunto de Instruções e Modelos de Arquiteturas Aula 7 Prof. Marcelo Andrade da Costa Vieira
Departamento de Engenharia Elétrica e de Computação EESC-USP SEL-0415 Introdução à Organização de Computadores Conjunto de Instruções e Modelos de Arquiteturas Aula 7 Prof. Marcelo Andrade da Costa Vieira
Linguagem de Maquina II. Visão Geral
 Linguagem de Maquina II Visão Geral Revisão A linguagem de máquina é composta de seqüências binárias (1's e 0's) São interpretadas como instruções pelo hardware A linguagem de montagem e a linguagem de
Linguagem de Maquina II Visão Geral Revisão A linguagem de máquina é composta de seqüências binárias (1's e 0's) São interpretadas como instruções pelo hardware A linguagem de montagem e a linguagem de
Arquitetura e Organização de Processadores. Aula 4. Pipelines
 Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 4 Pipelines 1. Introdução Objetivo: aumento de
Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 4 Pipelines 1. Introdução Objetivo: aumento de
Um Exemplo de Nível ISA: o IJVM. Pilhas. Pilhas. O Modelo de Memória da IJVM. Pilhas de Operandos. Nível ISA
 Ciência da Computação Arq. e Org. de Computadores Nível ISA Prof. Sergio Ribeiro Um Exemplo de Nível ISA: o IJVM Objetivo: Introduzir um nível ISA (Instruction Set Architecture), a ser interpretado pelo
Ciência da Computação Arq. e Org. de Computadores Nível ISA Prof. Sergio Ribeiro Um Exemplo de Nível ISA: o IJVM Objetivo: Introduzir um nível ISA (Instruction Set Architecture), a ser interpretado pelo
Universidade Federal do Rio de Janeiro Bacharelado em Ciência da Computação. Arquitetura de Computadores I. Organização Básica do Computador
 Universidade Federal do Rio de Janeiro Bacharelado em Ciência da Computação Arquitetura de Computadores I Organização Básica do Computador Gabriel P. Silva Ementa Unidade 2: Organização Lógica e Funcional
Universidade Federal do Rio de Janeiro Bacharelado em Ciência da Computação Arquitetura de Computadores I Organização Básica do Computador Gabriel P. Silva Ementa Unidade 2: Organização Lógica e Funcional
Arquitetura de Computadores
 Arquitetura de Computadores Prof. Eduardo Simões de Albuquerque Instituto de Informática UFG 1o. Semestre / 2006 Adaptado do material do prof. Fábio Moreira Costa Programa e Introdução Assunto do curso
Arquitetura de Computadores Prof. Eduardo Simões de Albuquerque Instituto de Informática UFG 1o. Semestre / 2006 Adaptado do material do prof. Fábio Moreira Costa Programa e Introdução Assunto do curso
Processador. Processador
 Departamento de Ciência da Computação - UFF Processador Processador Prof. Prof.Marcos MarcosGuerine Guerine mguerine@ic.uff.br mguerine@ic.uff.br 1 Processador Organização básica de um computador: 2 Processador
Departamento de Ciência da Computação - UFF Processador Processador Prof. Prof.Marcos MarcosGuerine Guerine mguerine@ic.uff.br mguerine@ic.uff.br 1 Processador Organização básica de um computador: 2 Processador
ORGANIZAÇÃO DE COMPUTADORES CAPÍTULO 6: PROCESSADORES. Prof. Juliana Santiago Teixeira
 ORGANIZAÇÃO DE COMPUTADORES CAPÍTULO 6: PROCESSADORES Prof. Juliana Santiago Teixeira julianasteixeira@hotmail.com INTRODUÇÃO INTRODUÇÃO O processador é o componente vital do sistema de computação, responsável
ORGANIZAÇÃO DE COMPUTADORES CAPÍTULO 6: PROCESSADORES Prof. Juliana Santiago Teixeira julianasteixeira@hotmail.com INTRODUÇÃO INTRODUÇÃO O processador é o componente vital do sistema de computação, responsável
COMPUTADORES COM UM CONJUNTO REDUZIDO DE INSTRUÇÕES. Adão de Melo Neto
 COMPUTADORES COM UM CONJUNTO REDUZIDO DE INSTRUÇÕES Adão de Melo Neto 1 INTRODUÇÃO Desde 1950, houveram poucas inovações significativas nas áreas de arquitetura e organização de computadores. As principais
COMPUTADORES COM UM CONJUNTO REDUZIDO DE INSTRUÇÕES Adão de Melo Neto 1 INTRODUÇÃO Desde 1950, houveram poucas inovações significativas nas áreas de arquitetura e organização de computadores. As principais
Projeto e Implementação de um Fatorial em Hardware para Dispositivos Reconfiguráveis
 Projeto e Implementação de um Fatorial em Hardware para Dispositivos Reconfiguráveis Álamo G. Silva, Leonardo A. Casillo Departamento de Ciências Exatas e Naturais Universidade Federal Rural do Semi- Árido
Projeto e Implementação de um Fatorial em Hardware para Dispositivos Reconfiguráveis Álamo G. Silva, Leonardo A. Casillo Departamento de Ciências Exatas e Naturais Universidade Federal Rural do Semi- Árido
Processadores. Principal função é executar programas armazenados na memória principal.
 Processadores Principal função é executar programas armazenados na memória principal. Registradores São memórias pequenas de alta velocidade, usada para armazenar resultados temporários e certas informações
Processadores Principal função é executar programas armazenados na memória principal. Registradores São memórias pequenas de alta velocidade, usada para armazenar resultados temporários e certas informações
ENDEREÇAMENTO DE INSTRUÇÕES. Adão de Melo Neto
 ENDEREÇAMENTO DE INSTRUÇÕES Adão de Melo Neto 1 TIPOS DE OPERAÇÕES 2 TIPOS DE OPERAÇÕES TIPOS DE INSTRUÇÕES/OPERAÇÕES (RELEMBRANDO) 3 INTRODUÇÃO TIPOS DE INSTRUÇÕES/OPERAÇÕES (RELEMBRANDO) 4 INTRODUÇÃO
ENDEREÇAMENTO DE INSTRUÇÕES Adão de Melo Neto 1 TIPOS DE OPERAÇÕES 2 TIPOS DE OPERAÇÕES TIPOS DE INSTRUÇÕES/OPERAÇÕES (RELEMBRANDO) 3 INTRODUÇÃO TIPOS DE INSTRUÇÕES/OPERAÇÕES (RELEMBRANDO) 4 INTRODUÇÃO
Organização de Computadores μarquitetura. Na Aula Anterior... Introdução. Nesta Aula. MIPS-Monociclo. Formas de Organização 17/10/2016
 GBC06 Arq. e Org. de Computadores I 17/10/2016 Organização de Computadores μarquitetura Universidade Federal de Uberlândia Faculdade de Computação Prof. Dr. rer. nat. Daniel D. Abdala Na Aula Anterior...
GBC06 Arq. e Org. de Computadores I 17/10/2016 Organização de Computadores μarquitetura Universidade Federal de Uberlândia Faculdade de Computação Prof. Dr. rer. nat. Daniel D. Abdala Na Aula Anterior...
Introdução à Organização de Computadores. Aula 8
 SEL-0415 Introdução à Organização de Computadores Set de Instruções Modelos de Arquiteturas Aula 8 Prof. Dr. Marcelo Andrade da Costa Vieira INSTRUÇÕES n Padrão de código binário armazenado em um dispositivo
SEL-0415 Introdução à Organização de Computadores Set de Instruções Modelos de Arquiteturas Aula 8 Prof. Dr. Marcelo Andrade da Costa Vieira INSTRUÇÕES n Padrão de código binário armazenado em um dispositivo
Organização de Computadores
 Organização do Processador - Parte A Capítulo 5 Patterson & Hennessy Prof. Fábio M. Costa Instituto de Informática Universidade Federal de Goiás Conteúdo Caminho de dados Caminho de controle Implementação
Organização do Processador - Parte A Capítulo 5 Patterson & Hennessy Prof. Fábio M. Costa Instituto de Informática Universidade Federal de Goiás Conteúdo Caminho de dados Caminho de controle Implementação
INTRODUÇÃO À ARQUITETURA E ORGANIZAÇÃO DE COMPUTADORES. Função e Estrutura. Introdução Organização e Arquitetura. Organização e Arquitetura
 Introdução Organização e Arquitetura INTRODUÇÃO À ARQUITETURA E ORGANIZAÇÃO DE COMPUTADORES Eduardo Max Amaro Amaral Arquitetura são os atributos visíveis ao programador. Conjunto de instruções, número
Introdução Organização e Arquitetura INTRODUÇÃO À ARQUITETURA E ORGANIZAÇÃO DE COMPUTADORES Eduardo Max Amaro Amaral Arquitetura são os atributos visíveis ao programador. Conjunto de instruções, número
UCP: Caminho de Dados (Parte II)
") UCP: Caminho de Dados (Parte II) Cristina Boeres Instituto de Computação (UFF) Fundamentos de Arquiteturas de Computadores Material baseado nos slides de Fernanda Passos Cristina Boeres (IC/UFF) UCP: Caminho
UCP: Caminho de Dados (Parte II) Cristina Boeres Instituto de Computação (UFF) Fundamentos de Arquiteturas de Computadores Material baseado nos slides de Fernanda Passos Cristina Boeres (IC/UFF) UCP: Caminho
Solução Lista de Exercícios Processadores
 Solução Lista de Exercícios Processadores Questão 1 A ULA é o dispositivo da CPU que executa operações tais como : Adição Subtração Multiplicação Divisão Incremento Decremento Operação lógica AND Operação
Solução Lista de Exercícios Processadores Questão 1 A ULA é o dispositivo da CPU que executa operações tais como : Adição Subtração Multiplicação Divisão Incremento Decremento Operação lógica AND Operação
Otimização de Execução em Processadores Modernos. William Stallings - Computer Organization and Architecture, Chapter 12 [Trad. E.Simões / F.
 Prefetch & Pipeline Otimização de Execução em Processadores Modernos Ciclos de Operação da CPU Estágios do Pipeline Previsão de Desvio William Stallings - Computer Organization and Architecture, Chapter
Prefetch & Pipeline Otimização de Execução em Processadores Modernos Ciclos de Operação da CPU Estágios do Pipeline Previsão de Desvio William Stallings - Computer Organization and Architecture, Chapter
SSC304 Introdução à Programação Para Engenharias
 Universidade de São Paulo Instituto de Ciências Matemáticas e de Computação Departamento de Sistemas de Computação Introdução à Para Engenharias Estrutura de um Computador GE4 Bio GE4Bio Grupo de Estudos
Universidade de São Paulo Instituto de Ciências Matemáticas e de Computação Departamento de Sistemas de Computação Introdução à Para Engenharias Estrutura de um Computador GE4 Bio GE4Bio Grupo de Estudos
 http://www.ic.uff.br/~debora/fac! 1 Conceito de família IBM System/360 1964 DEC PDP-8 Separa arquitetura de implementação Unidade de controle microprogramada Idéia de Wilkes 1951 Produzida pela IBM S/360
http://www.ic.uff.br/~debora/fac! 1 Conceito de família IBM System/360 1964 DEC PDP-8 Separa arquitetura de implementação Unidade de controle microprogramada Idéia de Wilkes 1951 Produzida pela IBM S/360
2. Descrição do Trabalho. Figura 1. Datapath do MIPS Superescalar CES SE
 Especificação do Projeto Simulador MIPS Superescalar CES- 25 Arquiteturas para Alto Desempenho Prof. Paulo André Castro Equipe: até três alunos Última atualização: 5/junho/2018 1. Objetivo Exercitar e
Especificação do Projeto Simulador MIPS Superescalar CES- 25 Arquiteturas para Alto Desempenho Prof. Paulo André Castro Equipe: até três alunos Última atualização: 5/junho/2018 1. Objetivo Exercitar e
Arquiteturas RISC e CISC. Adão de Melo Neto
 Arquiteturas RISC e CISC Adão de Melo Neto 1 Arquitetura RISC Arquitetura RISC. É um das inovações mais importantes e interessantes. RISC significa uma arquitetura com um conjunto reduzido de instruções
Arquiteturas RISC e CISC Adão de Melo Neto 1 Arquitetura RISC Arquitetura RISC. É um das inovações mais importantes e interessantes. RISC significa uma arquitetura com um conjunto reduzido de instruções
SSC0902 Organização e Arquitetura de Computadores
 SSC0902 Organização e Arquitetura de Computadores 13ª Aula Definição de Pipeline e Pipeline da arquitetura MIPS Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Arquitetura CISC CISC Complex Instruction
SSC0902 Organização e Arquitetura de Computadores 13ª Aula Definição de Pipeline e Pipeline da arquitetura MIPS Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Arquitetura CISC CISC Complex Instruction
Computadores e Programação (DCC/UFRJ)
") Computadores e Programação (DCC/UFRJ) Aula 3: 1 2 3 Abstrações do Sistema Operacional Memória virtual Abstração que dá a cada processo a ilusão de que ele possui uso exclusivo da memória principal Todo
Computadores e Programação (DCC/UFRJ) Aula 3: 1 2 3 Abstrações do Sistema Operacional Memória virtual Abstração que dá a cada processo a ilusão de que ele possui uso exclusivo da memória principal Todo
Disciplina: Arquitetura de Computadores
 Disciplina: Arquitetura de Computadores Estrutura e Funcionamento da CPU Prof a. Carla Katarina de Monteiro Marques UERN Introdução Responsável por: Processamento e execução de programas armazenados na
Disciplina: Arquitetura de Computadores Estrutura e Funcionamento da CPU Prof a. Carla Katarina de Monteiro Marques UERN Introdução Responsável por: Processamento e execução de programas armazenados na
Infraestrutura de Hardware. Melhorando Desempenho de Pipeline Processadores Superpipeline, Superescalares, VLIW
 Infraestrutura de Hardware Melhorando Desempenho de Pipeline Processadores Superpipeline, Superescalares, VLIW Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem
Infraestrutura de Hardware Melhorando Desempenho de Pipeline Processadores Superpipeline, Superescalares, VLIW Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem
ULA. Combina uma variedade de operações lógicas e matemáticas dentro de uma única unidade.
 PROCESSADOR ULA Combina uma variedade de operações lógicas e matemáticas dentro de uma única unidade. ULA Uma ULA típica pode realizar as operações artiméticas: - adição; - subtração; E lógicas: - comparação
PROCESSADOR ULA Combina uma variedade de operações lógicas e matemáticas dentro de uma única unidade. ULA Uma ULA típica pode realizar as operações artiméticas: - adição; - subtração; E lógicas: - comparação
Aula 17: Organização de Computadores
 Aula 17: Organização de Computadores Introdução à Organização de Computadores Rodrigo Hausen hausen@usp.br 07 de outubro de 2011 http://cuco.pro.br/ach2034 Rodrigo Hausen (hausen@usp.br) Aula 17: Organização
Aula 17: Organização de Computadores Introdução à Organização de Computadores Rodrigo Hausen hausen@usp.br 07 de outubro de 2011 http://cuco.pro.br/ach2034 Rodrigo Hausen (hausen@usp.br) Aula 17: Organização
PROGRAMAÇÃO I. Introdução
 PROGRAMAÇÃO I Introdução Introdução 2 Princípios da Solução de Problemas Problema 1 Fase de Resolução do Problema Solução na forma de Algoritmo Solução como um programa de computador 2 Fase de Implementação
PROGRAMAÇÃO I Introdução Introdução 2 Princípios da Solução de Problemas Problema 1 Fase de Resolução do Problema Solução na forma de Algoritmo Solução como um programa de computador 2 Fase de Implementação
Infraestrutura de Hardware. Implementação Monociclo de um Processador Simples
 Infraestrutura de Hardware Implementação Monociclo de um Processador Simples Componentes de um Computador Unid. Controle Controle Memória Registradores PC MAR IR AC Programa + Dados Instrução Endereço
Infraestrutura de Hardware Implementação Monociclo de um Processador Simples Componentes de um Computador Unid. Controle Controle Memória Registradores PC MAR IR AC Programa + Dados Instrução Endereço
Uma Arquitetura para Compressão de Código em Processadores Embarcados
 Uma Arquitetura para Compressão de Código em Processadores Embarcados André B. R. Silva CEFET Campos UNED Macaé Macaé, RJ, Brasil abellieny@cefetcampos.br Gabriel P. Silva DCC/IM Universidade Federal do
Uma Arquitetura para Compressão de Código em Processadores Embarcados André B. R. Silva CEFET Campos UNED Macaé Macaé, RJ, Brasil abellieny@cefetcampos.br Gabriel P. Silva DCC/IM Universidade Federal do
EA876 - Introdução a Software de Sistema
 A876 - Introdução a Software de Sistema Software de Sistema: conjunto de programas utilizados para tornar o hardware transparente para o desenvolvedor ou usuário. Preenche um gap de abstração. algoritmos
A876 - Introdução a Software de Sistema Software de Sistema: conjunto de programas utilizados para tornar o hardware transparente para o desenvolvedor ou usuário. Preenche um gap de abstração. algoritmos
SSC0611 Arquitetura de Computadores
 SSC0611 Arquitetura de Computadores 7ª Aula Pipeline Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Arquitetura CISC CISC Complex Instruction Set Computer Computadores complexos devido a: Instruções
SSC0611 Arquitetura de Computadores 7ª Aula Pipeline Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Arquitetura CISC CISC Complex Instruction Set Computer Computadores complexos devido a: Instruções
Organização e Arquitetura de Computadores I
 Universidade Federal de Campina Grande Departamento de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de Computadores I Organização e Arquitetura Básicas
Universidade Federal de Campina Grande Departamento de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de Computadores I Organização e Arquitetura Básicas
Tópicos Avançados em Sistemas Computacionais: Infraestrutura de Hardware Aula 06
 Tópicos Avançados em Sistemas Computacionais: Infraestrutura de Hardware Aula 06 Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação COMO UM PROGRAMA ESCRITO
Tópicos Avançados em Sistemas Computacionais: Infraestrutura de Hardware Aula 06 Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação COMO UM PROGRAMA ESCRITO
Organização Básica de Computadores. Organização Básica de Computadores. Organização Básica de Computadores. Organização Básica de Computadores
 Ciência da Computação Arq. e Org. de Computadores Processadores Prof. Sergio Ribeiro Composição básica de um computador eletrônico digital: Processador Memória Memória Principal Memória Secundária Dispositivos
Ciência da Computação Arq. e Org. de Computadores Processadores Prof. Sergio Ribeiro Composição básica de um computador eletrônico digital: Processador Memória Memória Principal Memória Secundária Dispositivos
PSI3441 Arquitetura de Sistemas Embarcados
 PSI31 Arquitetura de Sistemas Embarcados - Arquitetura do µprocessador Escola Politécnica da Universidade de São Paulo Prof. Gustavo Rehder grehder@lme.usp.br Prof. Sergio Takeo kofuji@usp.br Prof. Antonio
PSI31 Arquitetura de Sistemas Embarcados - Arquitetura do µprocessador Escola Politécnica da Universidade de São Paulo Prof. Gustavo Rehder grehder@lme.usp.br Prof. Sergio Takeo kofuji@usp.br Prof. Antonio
ORGANIZAÇÃO DE COMPUTADORES
 Organização de Computadores ORGANIZAÇÃO DE COMPUTADORES Curso: Tecnologia em Gestão da Tecnologia da Informação Ano: 2011 Conhecida como Processador ou é o cerebro do computador Unifica todo sistema e
Organização de Computadores ORGANIZAÇÃO DE COMPUTADORES Curso: Tecnologia em Gestão da Tecnologia da Informação Ano: 2011 Conhecida como Processador ou é o cerebro do computador Unifica todo sistema e
Introdução. (Aula 2) Organização Estruturada de Computadores
 Organização Estruturada de Computadores") Introdução (Aula 2) Organização Estruturada de Computadores Introdução Arquitetura de Hardware 01- Monitor 02- Placa-Mãe 03- Processador 04- Memória RAM 05- Placas de Rede, Som, Vídeo, Fax... 06- Fonte
Introdução (Aula 2) Organização Estruturada de Computadores Introdução Arquitetura de Hardware 01- Monitor 02- Placa-Mãe 03- Processador 04- Memória RAM 05- Placas de Rede, Som, Vídeo, Fax... 06- Fonte
2ª Lista de Exercícios de Arquitetura de Computadores
 2ª Lista de Exercícios de Arquitetura de Computadores 1. Descreva as funções desempenhadas pelos escalonadores de curto, médio e longo prazo em um SO. 2. Cite três motivos pelos quais o controle do processador
2ª Lista de Exercícios de Arquitetura de Computadores 1. Descreva as funções desempenhadas pelos escalonadores de curto, médio e longo prazo em um SO. 2. Cite três motivos pelos quais o controle do processador
Universidade Federal de Campina Grande Departamento de Sistemas e Computação Curso de Bacharelado em Ciência da Computação.
 Universidade Federal de Campina Grande Departamento de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de Computadores I Organização e Arquitetura Básicas
Universidade Federal de Campina Grande Departamento de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de Computadores I Organização e Arquitetura Básicas
Figura 1. Datapath do MIPS Superescalar Especulativo CES SE
 Especificação do Projeto Simulador MIPS Superescalar Especulativo CES- 25 Arquiteturas para Alto Desempenho Prof. Paulo André Castro Equipe: até quatro alunos 1. Objetivo Exercitar e fixar conhecimentos
Especificação do Projeto Simulador MIPS Superescalar Especulativo CES- 25 Arquiteturas para Alto Desempenho Prof. Paulo André Castro Equipe: até quatro alunos 1. Objetivo Exercitar e fixar conhecimentos
4. O SIMULADOR SIMUS Descrição
 27 4. O SIMULADOR SIMUS 4.1 - Descrição A partir da escolha da arquitetura SPARC, foi desenvolvido um estudo minucioso de sua arquitetura e do funcionamento de suas instruções. Este estudo detalhou as
27 4. O SIMULADOR SIMUS 4.1 - Descrição A partir da escolha da arquitetura SPARC, foi desenvolvido um estudo minucioso de sua arquitetura e do funcionamento de suas instruções. Este estudo detalhou as
UM MÉTODO PARA COMPARAÇÃO ENTRE HARDWARE E SOFTWARE DAS FUNÇÕES CRC-16 E FDCT SCHNEIDER, R. F. ¹, RAMOS, F. L. L.¹
 UM MÉTODO PARA COMPARAÇÃO ENTRE HARDWARE E SOFTWARE DAS FUNÇÕES CRC-16 E FDCT SCHNEIDER, R. F. ¹, RAMOS, F. L. L.¹ ¹ ³ Universidade Federal do Pampa (UNIPAMPA) Bagé RS Brasil RESUMO A execução de funções
UM MÉTODO PARA COMPARAÇÃO ENTRE HARDWARE E SOFTWARE DAS FUNÇÕES CRC-16 E FDCT SCHNEIDER, R. F. ¹, RAMOS, F. L. L.¹ ¹ ³ Universidade Federal do Pampa (UNIPAMPA) Bagé RS Brasil RESUMO A execução de funções
Arquitetura de Computadores Aula 10 - Processadores
 Arquitetura de Computadores Aula 10 - Processadores Prof. Dr. Eng. Fred Sauer http://www.fredsauer.com.br fsauer@gmail.com 1/21 TÓPICOS ORGANIZAÇÃO COMPONENTES BÁSICOS INSTRUÇÃO DE MÁQUINA CICLO DE INSTRUÇÃO
Arquitetura de Computadores Aula 10 - Processadores Prof. Dr. Eng. Fred Sauer http://www.fredsauer.com.br fsauer@gmail.com 1/21 TÓPICOS ORGANIZAÇÃO COMPONENTES BÁSICOS INSTRUÇÃO DE MÁQUINA CICLO DE INSTRUÇÃO
2. A influência do tamanho da palavra
 PROCESSAMENTO 1. Introdução O processador é o componente vital do sistema de computação, responsável pela realização das operações de processamento (os cálculos matemáticos etc.) e de controle, durante
PROCESSAMENTO 1. Introdução O processador é o componente vital do sistema de computação, responsável pela realização das operações de processamento (os cálculos matemáticos etc.) e de controle, durante
Tecnólogo em Análise e Desenvolvimento de Sistemas. Sistemas Operacionais (SOP A2)
") Tecnólogo em Análise e Desenvolvimento de Sistemas Sistemas Operacionais (SOP A2) Conceitos de Hardware e Software Referências: Arquitetura de Sistemas Operacionais. F. B. Machado, L. P. Maia. Editora
Tecnólogo em Análise e Desenvolvimento de Sistemas Sistemas Operacionais (SOP A2) Conceitos de Hardware e Software Referências: Arquitetura de Sistemas Operacionais. F. B. Machado, L. P. Maia. Editora
Introdução à Computação: Arquitetura von Neumann
 Introdução à Computação: Arquitetura von Neumann Beatriz F. M. Souza (bfmartins@inf.ufes.br) http://inf.ufes.br/~bfmartins/ Computer Science Department Federal University of Espírito Santo (Ufes), Vitória,
Introdução à Computação: Arquitetura von Neumann Beatriz F. M. Souza (bfmartins@inf.ufes.br) http://inf.ufes.br/~bfmartins/ Computer Science Department Federal University of Espírito Santo (Ufes), Vitória,
SSC0112 Organização de Computadores Digitais I
 SSC0112 Organização de Computadores Digitais I 18ª Aula Hierarquia de memória Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br 1 Memória Cache Método de Acesso: Associativo Localização de dados na memória
SSC0112 Organização de Computadores Digitais I 18ª Aula Hierarquia de memória Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br 1 Memória Cache Método de Acesso: Associativo Localização de dados na memória
Micro-Arquiteturas de Alto Desempenho. Introdução. Ementa
 DCC-IM/NCE UFRJ Pós-Graduação em Informática Micro-Arquiteturas de Alto Desempenho Introdução Gabriel P. Silva Ementa Revisão de Organização de Computadores Hierarquia de Memória Memória Virtual Memória
DCC-IM/NCE UFRJ Pós-Graduação em Informática Micro-Arquiteturas de Alto Desempenho Introdução Gabriel P. Silva Ementa Revisão de Organização de Computadores Hierarquia de Memória Memória Virtual Memória
PARTE II - CONJUNTO DE INSTRUÇÕES ARQUITETURA DE COMPUTADORES ANTONIO RAMOS DE CARVALHO JÚNIOR
 PARTE II - CONJUNTO DE INSTRUÇÕES ARQUITETURA DE COMPUTADORES ANTONIO RAMOS DE CARVALHO JÚNIOR Introdução Instruções são representadas em linguagem de máquina (binário) E x i s t e m l i n g u a g e n
PARTE II - CONJUNTO DE INSTRUÇÕES ARQUITETURA DE COMPUTADORES ANTONIO RAMOS DE CARVALHO JÚNIOR Introdução Instruções são representadas em linguagem de máquina (binário) E x i s t e m l i n g u a g e n
Introdução (Aula 2) Introdução Arquitetura de Hardware. Organização Estruturada de Computadores. Introdução Conceitos (2) Introdução Conceitos (1)
 Introdução Arquitetura de Hardware. Organização Estruturada de Computadores. Introdução Conceitos (2) Introdução Conceitos (1)") Introdução Arquitetura de Hardware Introdução (Aula 2) Organização Estruturada de Computadores 01- Monitor 02- Placa-Mãe 03- Processador 04- Memória RAM 05- Placas de Rede, Som, Vídeo, Fax... 06- Fonte
Introdução Arquitetura de Hardware Introdução (Aula 2) Organização Estruturada de Computadores 01- Monitor 02- Placa-Mãe 03- Processador 04- Memória RAM 05- Placas de Rede, Som, Vídeo, Fax... 06- Fonte
Conjunto de Instruções. Alisson Brito
 Conjunto de Instruções Alisson Brito 1 1 O que é o Conjunto de Instruções? Instruction Set Architecture (ISA) Interface entre Programas e CPU A coleção completa de instruções reconhecidas pela CPU Programas
Conjunto de Instruções Alisson Brito 1 1 O que é o Conjunto de Instruções? Instruction Set Architecture (ISA) Interface entre Programas e CPU A coleção completa de instruções reconhecidas pela CPU Programas
PROJETO CONCEITUAL DE UM ASIP PARA PROCESSAMENTO DIGITAL DE ÁUDIO
 UNIVERSIDADE FEDERAL DE SANTA CATARINA DEPARTAMENTO DE INFORMÁTICA E ESTATÍSTICA Eduardo D avila Koerich Vinicius Almeida Carlos PROJETO CONCEITUAL DE UM ASIP PARA PROCESSAMENTO DIGITAL DE ÁUDIO Florianópolis,
UNIVERSIDADE FEDERAL DE SANTA CATARINA DEPARTAMENTO DE INFORMÁTICA E ESTATÍSTICA Eduardo D avila Koerich Vinicius Almeida Carlos PROJETO CONCEITUAL DE UM ASIP PARA PROCESSAMENTO DIGITAL DE ÁUDIO Florianópolis,
Capítulo 5. Parte de Controle
 Capítulo 5 Parte de Controle 5.1. Introdução Partes de controle de computadores podem ser implementadas de duas formas principais, a saber: através de lógica aleatória ou de lógica regular (ROM ou PLA
Capítulo 5 Parte de Controle 5.1. Introdução Partes de controle de computadores podem ser implementadas de duas formas principais, a saber: através de lógica aleatória ou de lógica regular (ROM ou PLA