Microarquiteturas Modernas x86
|
|
|
- Nathan Vidal Macedo
- 8 Há anos
- Visualizações:
Transcrição
1 Microarquiteturas Modernas x86 Para aproveitar as otimizações existentes nos processadores x86 atuais, é preciso conhecer algumas características relevantes das microarquiteturas modernas Microarquiteturas Modernas x86 (Intel) Pentium M Sandy Bridge Intel Core Nehalem Netburst Cada arquitetura tem um conjunto de objetivos específicos Exemplo: Intel Core - alta performance com eficiência energética; Pentium M - eficiência energética com performance razoável

2 Características Relevantes para Otimização de Software Microarquiteturas que permitem execução com alta vazão (throughput) em clocks elevados, com hierarquia de cache de alta velocidade e barramentos muito rápidos Arquiteturas multicore Suporte a tecnologia Hyper-Threading Suporte a 64 bit Extensões SIMD MMX, SSE (Streaming SIMD Extensions), SSE2, SSE3, SSSE3 (Supplemental SSE3), SSE4.1, SSE4.2 AVX (Advanced Vector Extensions)
, SSE2, SSE3, SSSE3 (Supplemental SSE3), SSE4.1, SSE4.")
3 Características Relevantes para Otimização de Software Microarquiteturas que permitem execução com alta vazão (throughput) em clocks elevados, com hierarquia de cache de alta velocidade e barramentos muito rápidos Arquiteturas multicore Suporte a tecnologia Hyper-Threading Suporte a 64 bit Extensões SIMD MMX, SSE (Streaming SIMD Extensions), SSE2, SSE3, SSSE3 (Supplemental SSE3), SSE4.1, SSE4.2 AVX (Advanced Vector Extensions)
, SSE2, SSE3, SSSE3 (Supplemental SSE3), SSE4.1, SSE4.")
4 MicroArquitetura x86 Sandy Bridge

5 Microarquitetura Sandy Bridge Evolução das microarquiteturas Intel Core e Nehalem Exemplos: processadores Core i7 2xxx Algumas Características: Suporte a Advanced Vector Extensions (AVX) Extensão 256-bit ponto flutuante às instruções SIMD 128-bits, oferecendo até 2x a performance de código baseado em SIMD 128-bit Melhoras na execução de instruções Exemplo: branch prediction mais eficiente

6 Microarquitetura Sandy Bridge Algumas Características (cont.): Hierarquia de cache melhorada, aumentando a banda Suporte a SoC (system on a chip) Processador gráfico integrado Controlador PCIE integrado Controlador de memória integrado Turbo Boost Technology melhorada Gerenciamento automático do clock dos cores do processador para mantê-lo sempre a uma temperatura adequada

7 Sandy Bridge: Pipeline
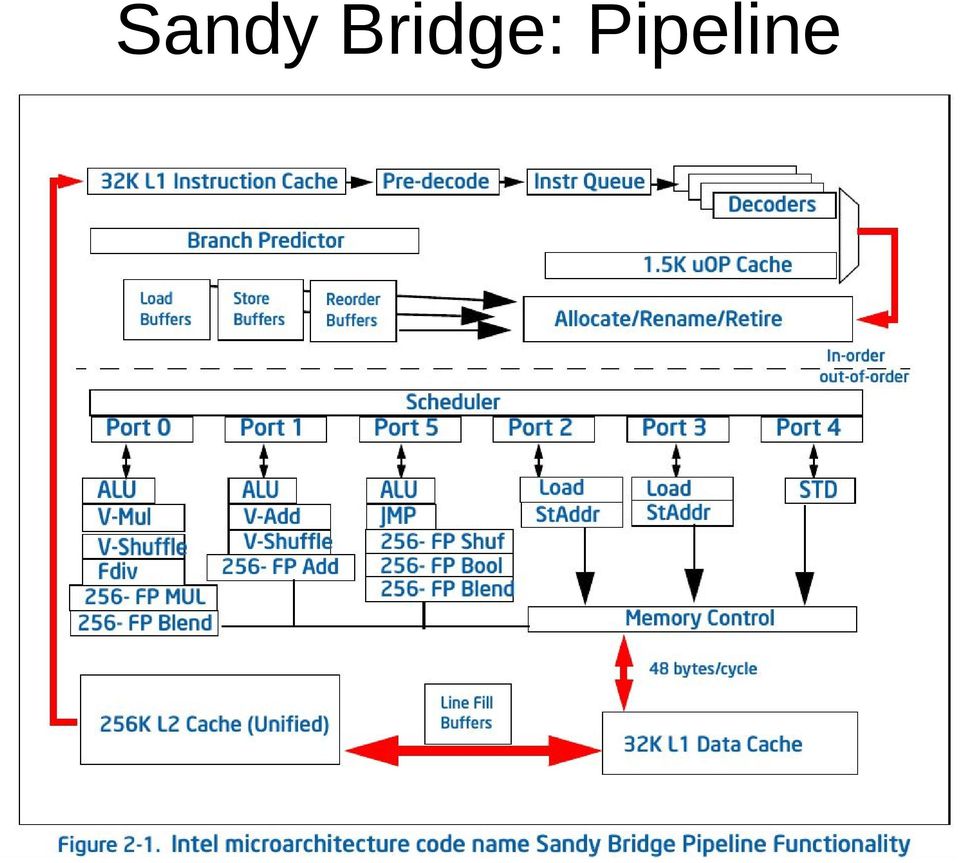
8 Sandy Bridge: Pipeline Front-end in-order. Busca instruções e as decodifica em micro-ops. Mantém os próximos estágios alimentados com um fluxo contínuo de micro-ops, na ordem mais provável que elas serão executadas

9 Sandy Bridge: Pipeline Execution engine, out-of order, superescalar. Despacha até seis micro-ops por ciclo. O bloco allocate/rename reordena as micro-ops usando análise de fluxo de dados (dataflow), para que elas executem assim que os dados e os recursos de execução estiverem disponíveis.
, para que elas executem assim que os dados e os")
10 Sandy Bridge: Pipeline A unidade de retirement, em ordem, garante que os resultados da execução das micro-ops, inclusive de quaisquer exceções que possam ter ocorrido, são visíveis de acordo com a ordem original do programa

11 Sandy Bridge: fluxo de uma instrução, resumo (1)A unidade de branch prediction escolhe o próximo bloco de código do programa a ser executado (2)As micro-ops correspondentes a esse código são enviadas para o bloco Rename/retirement. Elas entram no Scheduler na ordem do programa, mas são executadas em ordem de dataflow. Para micro-ops que estejam prontas simultaneamente, quase sempre é respeitada a ordem FIFO. As micro-ops são executadas usando recursos de execução organizados em três pilhas. (detalhes no próximo slide) (3)Operações em memória são reordenadas para alcançar paralelismo e performance máxima. Caches misses no L1 data cache vão para o L2 Cache (4)Exceções são sinalizadas no retirement da instrução que o causou. Observação: cada core de um processador Sandy Bridge pode suportar 2 processadores lógicos se o HyperThreading for habilitado.
 (3)Operações em memória são reordenadas para alcançar paralelismo e performance máxima.")
12 Sandy Bridge: pilhas de execução de micro-ops Pilha Inteiros uso geral SIMD Porta 0 Porta 1 ALU, Shift ALU, Fast LEA, Slow LEA, MUL Porta 2 Porta 3 Porta 4 Load_Add r, Store_ad dr Load_Add Store_dat r, a Store_ad dr Porta 5 ALU, Shift, Branch, Fast LEA Inteiro (SSE-Int, AVX-Int, MMX) Mul, Shift, STTNI, Int-Div, 128b-Mov ALU, Shuf, Blend, 128b-Mov Store_dat a ALU, Shuf, Shift, Blend, 128b-Mov Pontoflutuante (SSE-FP, AVXFP_low) Mul, Div, Blend, 256b-Mov Add, CVT Store_dat a Shuf, Blend, 256b-Mov Mul, Div, Blend, 256b-Mov Add, CVT Store_dat a Shuf, Blend, 256b-Mov X87, AVX-FP_High

13 Sandy Bridge: hierarquias de cache First level instruction cache First level data cache (L1 Dcache) Pode ser compartilhado entre dois processadores lógicos se o processador suportar HyperThreading Second level (unified: data/instruction) cache (L2) Todos os cores em um processador físico compartilham um shared last level cache (LLC) A coerência de dados em todos os níveis de cache é mantida usando o protocolo MESI
 A coerência de dados em todos os níveis de cache é mantida usando o protocolo")
14 Protocolo MESI: Visão Geral Protocolo de coerência de Cache MESI o bloco endereçado é válido na cache e apenas nessa cache. O bloco foi modificado em relação à memória do sistema isto é, os dados modificados do bloco não foram ainda escritos na memória. Modified Exclusive o bloco endereçado está somente nessa cache. Os dados desse bloco estão consistentes com a memória do sistema. Shared o bloco endereçado é válido nesta cache e em pelo menos uma outra cache. Invalid o bloco endereçado está inválido (não está presente na cache ou os dados contidos não podem ser usados).

15 Protocolo MESI: Visão Geral Protocolo MESI requer a monitoração de todos os acessos a memória em sistema multiprocessado Adota bus snooping p3 P1 X=7 I cache I cache D cache D cache Barramento P2 I cache D cache X=10 p4 I cache D cache X=30

16 Relação entre estados MESI

17 MicroArquitetura x86 Pentium M

18 MicroArquitetura Pentium M Foco em eficiência energética Baseado na arquitetura de sexta geração da Intel, conhecida como P6, usada em: Pentium Pro, Pentium II, Pentium III Pipeline mais curto do que outras arquiteturas Como Pentium 4 A Intel não costuma mais divulgar o tamanho do pipeline

19 Evolução das MicroArquiteturas PX Geração X P6 P7 (Netburst) Pentium M Intel Core Nehalem Sandy Bridge Tempo Grosso modo: P6: Pentium Pro, Pentium II, Pentium III P7: Pentium 4 Pentium M: Notebooks chamados Centrino = Pentium M + chipsets/wi-fi Intel Intel Core: Core 2 processor series (Core 2 Duo, Core 2 Quad etc.) Nehalem: primeiros Core i3, i5 e i7 Sandy Bridge: Core i3, i5, i7 mais recentes

20 Pentium M: Características Four data transferred per clock cycle. This technique is called QDR (Quad Data Rate) and makes the local bus to have a performance four times its actual clock rate, see table below. Real Clock Performance Trnasfer Rate 100 MHz 400 MHz 3.2 GB/s 133 MHz 533 MHz 4.2 GB/s L1 memory cache: two 32 KB L1 memory caches, one for data and another for instructions (Pentium III had two 16 KB L1 memory caches). L2 memory cache: 1 MB on 130 nm models ( Banias core) or 2 MB on 90 nm models ( Dothan core). Pentium III had up to 512 KB. Celeron M, which is a low-cost version of Pentium M, has a 512 KB L2 memory cache. Support for SSE2 instructions. Advanced branch prediction: branch prediction circuit was redesigned (and based on Pentium 4 s branch prediction circuit) to improve performance. Micro-ops fusion: The instruction decoder fuses two micro-ops into one micro-op in order to save energy and improve performance. We ll talk more about this later. Enhanced SpeedStep Technology, which allows the CPU to reduce its clock while idle in order to save battery life. Several other battery-saving features were added to Pentium M s microarchitecture, since this CPU was originally designed for mobile computers.
 or 2 MB on 90 nm models ( Dothan core). Pentium III had up to 512 KB.")
21 MicroArquitetura Pentium M
22 Pentium M: Pipeline Baseado na arquitetura P6, provavelmente com mais estágios Para comparação: Pentium III (P6): 11 estágios Pentium 4 (P7 inicial): 20 estágios Pentium 4 (Prescott): 31 estágios!
23 Pipeline: estágios do Pentium III IFU1: Loads one line (32 bytes, i.e., 256 bits) from L1 instruction cache and stores it in the Instruction Streaming Buffer. IFU2: Identifies the instructions boundaries within 16 bytes (128 bits). Since x86 instructions don t have a fixed length this stage marks where each instruction starts and ends within the loaded 16 bytes. If there is any branch instruction within these 16 bytes, its address is stored at the Branch Target Buffer (BTB), so the CPU can later use this information on its branch prediction circuit. IFU3: Marks to which instruction decoder unit each instruction must be sent. There are three different instruction decoder units, as we will explain later. DEC1: Decodes the x86 instruction into a RISC microinstruction (a.k.a. micro-op). Since the CPU has three instructions decode units, it is possible to decode up to three instructions at the same time. Fonte:
24 Pipeline: estágios do Pentium III DEC2: Sends the micro-ops to the Decoded Instruction Queue, which is capable to store up to six micro-ops. If the instruction was converted in more than six micro-ops, this stage must be repeated in order to catch the missing micro-ops. RAT: Since P6 microarchitecture implements outof-order execution (OOO), the value of a given register could be altered by an instruction executed before its correct (i.e., original) place in the program flow, corrupting the data needed by another instruction. So, to solve this kind of conflict, at this stage the original register used by the instruction is changed to one of the 40 internal registers that P6 microarchitecture has. ROB: At this stage three micro-ops are loaded into the Reorder Buffer (ROB). If all data necessary for the execution of a micro-op are available and if there is an open slot at the Reservation Station micro-op queue, then the micro-op is moved to this queue.

25 Pipeline: estágios do Pentium III DIS: If the micro-op wasn t sent to the Reservation Station micro-op queue, this is done at this stage. The micro-op is sent to the proper execution unit. EX: The micro-op is executed at the proper execution unit. Usually each micro-op needs only one clock cycle to be executed. RET1: Checks at the Reorder Buffer if there is any micro-op that can be flagged as executed. RET2: When all micro-ops related to the previous x86 instruction were already removed from the Reorder Buffer and all micro-ops related to the current x86 instruction were executed, these micro-ops are removed from the Reorder Buffer and the x86 registers are updated (the inverse process done at RAT stage). The retirement process must be done in order. Up to three micro-ops can be removed from the Reorder Buffer per clock cycle.

26 Fetch Unit: Detalhes
27 Micro-ops A partir da arquitetura P6 (desde o Pentium Pro), os processadores x86 usam arquiteturas híbridas CISC/RISC O processador aceita apenas instruções CISC (x86) no seu frontend Internamente as instruções são convertidas em instruções RISC, chamadas de micro-ops por uma unidade chamada Instruction Decoder Essas micro-ops não podem ser acessadas, e cada CPU usa seu próprio conjunto de micro-ops, que não são documentadas e são provavelmente incompatíveis com micro-ops de outras CPUs (ex. Micro-ops do PentiumM são diferentes das do Pentium 4, que são diferentes do Athlon64) Dependendo da complexidade de uma instrução x86, ela pode ser convertida em várias micro-ops RISC
28 Pentium M: Instruction Decoder As you can see, there are three decoders and a Micro Instruction Sequencer (MIS). Two decoders are optimized for simple instructions, which are the most used ones. This kind of instruction is converted in just one micro-op. One decoder is optimized for complex x86 instructions, which can be converted in up to four micro-ops. If the x86 instruction is too complex, i.e., it converts into more than four micro-ops, it is sent to the Micro Instruction Sequencer, which is a ROM memory containing a list of micro-ops that should replace the given x86 instruction.
29 Pentium M: Instruction Decoder The instruction decoder can convert up to three x86 instructions per clock cycle, one complex at Decoder 0 and two simple at decoders 1 and 2
30 Pentium M: Instruction Decoder The Decoded Instruction Queue can be feeded with up to six micro-ops per clock cycle, scenario that is reached when Decoder 0 sends four micro-ops and the other two decoders send one micro-op each or when the MIS is used
31 Dealing with Very complex x86 Micro Instruction Sequencer Very complex x86 instructions that use the Micro Instruction Sequencer can delay several clock cycles to be decoded, depending on how many micro-ops will be generated from the conversion. Keep in mind that the Decoded Instruction Queue can hold only up to six microops, so if more than six micro-ops are generated by the decoder plus MIS, another clock cycle is needed to send the current micro-ops present in the queue to the Register Allocation Table (RAT), empty the queue and accept the micro-ops that didn t fit before.
32 Micro-op fusion Pentium M uses a new concept to the P6 architecture that is called micro-op fusion. On Pentium M the decoder unit fuses two micro-ops into one. They will be de-fused only to be executed, at the execution stage. On P6 architecture, each microinstruction is 118-bit long. Pentium M instead of working with 118-bit micro-ops works with 236-bit long micro-ops that are in fact two 118-bit micro-ops. Keep in mind that the micro-ops continue to be 118-bit long; what changed is that they are transported in groups of two. This idea behind this approach was to save energy and increase performance. It is faster to send one 236-bit micro-op than two 118-bit micro-ops. Also the CPU will consume less power, since less micro-ops will be circulating inside of it.
33 Register Allocation Table (RAT) Fused micro-ops are then sent to the Register Allocation Table (RAT). CISC x86 architecture has only eight 32-bit registers (EAX, EBX, ECX, EDX, EBP, ESI, EDI and ESP). This number is simply too low, especially because modern CPUs can execute code out-of-order, what would kill the contents of a given register, crashing the program. So, at this stage, the processor changes the name and contents of the registers used by the program into one of the 40 internal registers available (each one of them is 80-bit wide, thus accepting both integer and floating-point data), allowing the instruction to run at the same time of another instruction that uses the exact same standard register, or even out-of-order, i.e., this allows the second instruction to run before the first instruction even if they mess with the same register.

34 The Reorder Buffer So far the x86 instructions and the microops resulted from them are transferred between the CPU stages in the same order they appear on the program being run. Arriving at the ROB, micro-ops can be loaded and executed out-of-order by the execution units. After being executed, the instructions are sent back to the Reorder Buffer. Then at the Retirement stage, executed micro-ops are pulled out of the Reorder Buffer at the same order they entered it, i.e., they are removed in order. Pentium M uses fused micro-ops (i.e., carries two micro-ops together) from the Decode Unit up to the dispatch ports located on the Reservation Station. The Reservation Station dispatches each micro-op individually (defused).
35 Dispatch ports and Execution Units Pentium M has five dispatch ports numbered 0 through 4 located on its Reservation Station. Each port is connected to one or more execution units, as seen in the picture
36 Execution Units: Explanation Keep in mind that complex instructions may take several clock cycles to be processed. Let s take an example of port 0, where the floating point unit (FPU) is located. While this unit is processing a very complex instruction that takes several clock ticks to be executed, port 0 won t stall: it will keep sending simple instructions to the IEU while the FPU is busy.
37 Execution Units: Explanation So, even thought the maximum dispatch rate is five microinstructions per clock cycle, actually the CPU can have up to twelve microinstructions being processed at the same time.

38 Execution Units: Explanation On data instructions, the Store Address Unit and the Store Data Unit are generally both used, one for calculating the address and the other for accessing the data.
39 Retirement After each micro-op is executed, it returns to the Reorder Buffer, where its flag is set to executed. Then at the Retirement Stage the micro-ops that have their executed flag on are removed from the Reorder Buffer on its original order (i.e., the order they were decoded) and then the x86 registers are updated (the inverse step of register renaming stage). Up to three micro-ops can be removed from the Reorder Buffer per clock cycle. After this the instruction was fully executed.
40 PentiumM: Enhanced SpeedStep SpeedStep Technology was created to increase battery life and was first introduced with Pentium III M processor. This first version of SpeedStep Technology allowed the CPU to switch between two clock frequencies on the fly: Low Frequency Mode (LFM), which maximized battery life, and High Frequency Mode (HFM), which allowed you to run your CPU at its maximum speed. The CPU had two clock multiplier ratios and what it did was to change the ratio it was using. The LFM ratio was factory-lock and you couldn t change it. Pentium M introduced Enhanced SpeedStep Technology, which goes beyond that, by having several other clock and voltage configurations between LFM (which is fixed at 600 MHz) and HFM (which is the CPU full clock). Example Voltage Clock 1.484V 1,6GHz 1,42 1,4 1,276 1,2 1, , MHz 0,
41 PentiumM: Enhanced SpeedStep Each Pentium M model has its own voltage/clock table. It is very interesting to notice that it is not only about lowering the clock rate when you don t need so much processing power from your laptop, but also about lowering its voltage, which helps a lot to lower battery consumption. Enhanced SpeedStep Technology works by monitoring specific MSRs (Model Specific Registers) from the CPU called Performance Counters. With this information, the CPU can lower or raise its clock/voltage depending on CPU usage. Simply put, if you increase CPU usage, it will increase its voltage/clock, if you lower the CPU usage, it will lower its voltage/clock. Enhanced SpeedStep was just one of the several enhancements done on Pentium M microarchitecture in order to increase battery life. A good example was done on the execution units. On other processors, the same power line feeds all execution units. So it is not possible to turn off an idle execution unit on Pentium 4, for example. On Pentium M execution units have different power lines, making the CPU capable of turning off idle execution units. For example, Pentium M detects in advance if a given instruction is an integer one ( regular instruction ), disabling the units and datapaths not needed to process that instruction, if they are idle, of course.
42 MicroArquitetura x86 Intel Core
43 MicroArquitetura IntelCore Exemplos: 2 Cores: Intel Core 2 Extreme X6800 Intel Core 2 Duo Intel Xeon Séries 3000, cores: Intel Core 2 Extreme quad-core Intel Core 2 Quad Intel Xeon Séries 3200, 5300
44 Características Evolução da arquitetura Pentium M Pensada desde o início para múltiplos cores Cache L2 compartilhado entre os cores:
45 Vantagens L2 compartilhado The problem with separate L2 caches is that is that at some moment one core may run out of cache while the other may have unused parts on its own L2 memory cache. When this happens, the first core must grab data from the main RAM memory, even though there was empty space on the L2 memory cache of the second core that could be used to store data and prevent that core from accessing the main RAM memory. On Core microarchitecture this problem was solved. The L2 memory cache is shared, meaning that both cores use the same L2 memory cache, dynamically configuring how much cache each core will take. On a CPU with 2 MB L2 cache, one core may be using 1.5 MB while the other 512 KB (0.5 MB), contrasted to the fixed 50%-50% division used on previous dual-core CPUs. It is not only that. Prefetches are shared between the cores, i.e., if the memory cache system loaded a block of data to be used by the first core, the second core can also use the data already loaded on the cache. On the previous architecture, if the second core needed a data that was located on the cache of the first core, it had to access it through the external bus (which works under the CPU external clock, which is far lower than the CPU internal clock) or even grab the required data directly from the system RAM.
46 Melhoras na Prefetch Unit Intel also has improved the CPU prefetch unit, which watches for patterns in the way the CPU is currently grabbing data from memory, in order to try to guess which data the CPU will try to load next and load it to the memory cache before the CPU requires it. For example, if the CPU has just loaded data from address 1, then asked for data located on address 3, and then asked for data located on address 5, the CPU prefetch unit will guess that the program running will load data from address 7 and will load data from this address before the CPU asks for it. Actually this idea isn t new and all CPUs since the Pentium Pro use some kind of predicting to feed the L2 memory cache. On Core microarchitecture Intel has just enhanced this feature by making the prefetch unit look for patterns in data fetching instead of just static indicators of what data the CPU would ask next.
47 Melhoras nos Instruction Decoder Macro-Fusion: quando micro-ops ficam maiores que instruções x86... Macro-fusion is the ability of joining two x86 instructions together into a single micro-op Improves the CPU performance and lowers the CPU power consumption, since it will execute only one micro-op instead of two. Used in compare and conditional branching instructions (CMP, TEST and Jcc)
48 Macro-fusion: exemplo load eax, [mem1] cmp eax, [mem2] jne target What this does is to load the 32-bit register EAX with data contained in memory position 1, compare its value with data contained in memory position 2 and, if they are different (jne = jump if not equal), the program goes to address target, if they are equal, the program continues on the current position.
49 Macro-fusion: exemplo load eax, [mem1] cmp eax, [mem2] jne target Micro-op1 (load eax with contents at mem1 addr) Micro -op2 (compare eax with contents at mem2 addr and jump to target if equals) With macro-fusion the comparison (cmp) and branching (jne) instructions will be merged into a single micro-op. As we can see, we saved one instruction. The less instructions there are to be executed, the faster the computer will finish the execution of the task and also less power is generated.
50 Macro-fusion: exemplo load eax, [mem1] cmp eax, [mem2] jne target Micro-op1 (load eax with contents at mem1 addr) Micro -op2 (compare eax with contents at mem2 addr and jump to target if equals) With macro-fusion the comparison (cmp) and branching (jne) instructions will be merged into a single micro-op. As we can see, we saved one instruction. The less instructions there are to be executed, the faster the computer will finish the execution of the task and also less power is generated.
51 Mais instructions decoders 4 ao invés de 3 (Pentium M) 5 instruções fetched da fila de instruções por vez (por causa da macro-fusion) Because of macro-fusion, the Core microarchitecture instruction decoder pulls five instructions per time for the instruction queue, even though it can only decode four instructions per clock cycle. This is done so if two of these five instructions are fused into one, the decoder can still decode four instructions per clock cycle. Otherwise it would be partially idle whenever a macro-fusion took place, i.e., it would deliver only three micro-ops on its output while it is capable of delivering up to four.
52 Execution Units O Pentium M tinha 5 portas de execução, mas só 2 eram ligadas a unidades de execução (ver slide acima), sendo 3 delas ocupadas com unidades de operações de memória Arquitetura Core também tem 5 portas, mas 3 são ligadas a unidades de execução, uma vez que a unidade de geração de endereço não existe mais (funcionalidade incorporada nas unidades Load-Store)
53 Execution Units Intel Core
54 Execution Units Intel Core IEU: Instruction Execution Unit is where regular instructions are executed. Also known as ALU (Arithmetic and Logic Unit). Regular instructions are also known as integer instructions. JEU: Jump Execution Unit processes branches and is also known as Branch Unit. FPU: Floating-Point Unit. Is responsible for executing floating-point math operation and also MMX and SSE instructions. In this CPU the FPUs aren t complete, as some instruction types (FPmov, FPadd and FPmul) can only be executed on certain FPUs: FPadd: Only this FPU can process floating-point addition instructions, like ADDPS (which, by the way, is a SSE instruction). FPmul: Only this FPU can process floating-point multiplication instructions, like MULPS (which, by the way, is a SSE instruction). FPmov: Instructions for loading or copying a FPU register, like MOVAPS (which transfers data to a SSE 128-bit XMM register). This kind of instruction can be executed on any FPU, but on the second and on the third FPUs only if FPadd- or FPmul-like instructions aren t available in the Reservation Station to be dispatched. Load: Unit to process instructions that ask a data to be read from the RAM memory. Store Data: Unit to process instructions that ask a data to be written at the RAM memory.
55 128-Bit Internal Datapath Another new feature found on Core microarchitecture is a true 128bit internal datapath. On previous CPUs, the internal datapath was of 64 bits only. This was a problem for SSE instructions, since SSE registers, called XMM, are 128-bit long. So, when executing an instruction that manipulated a 128-bit data, this operation had to be broke down into two 64-bit operations. The new 128-bit datapath makes Core microarchitecture faster to process SSE instructions that manipulate 128-bit data. Intel is calling this new feature Advanced Digital Media Boost.
56 Memory Disambiguation (Dataflow Analysis) Memory disambiguation is a technique to accelerate the execution of memoryrelated instructions. All Intel CPUs since Pentium Pro have an out-of-order engine, which allows the CPU to execute non-dependant instructions in any order. What happens is that memory-related instructions are traditionally executed in the same order they appear on the program, otherwise data inconsistency could appear. For example, if the original program has an instruction like store 10 at address 5555 and then a load data stored at 5555, they cannot be reversed (i.e., executed out of order) or the second instruction would get wrong data, as the data of address 5555 was changed by the first instruction. What the memory disambiguation engine does is locate and execute memoryrelated instructions that can be executed out of order, accelerating the execution of the program (we will explain how this is accomplished in a minute). In the following slide you have an example of a CPU without memory disambiguation (i.e., all CPUs not based on Core microarchitecture). As you can see, the CPU has to execute the instructions as they appear on the original program. For example, Load4 isn t related to any other memory-related instruction and could be executed first, however it has to wait all other instructions to be executed first.
57 Memory Disambiguation (Dataflow Analysis)
58 Memory Disambiguation (Dataflow Analysis) In the next slide you see how the program shown in Figure 3 works on a CPU based on Core microarchitecture. It knows that Load4 isn t related to the other instructions and can be executed first. This improves the CPU performance because now that Load4 is executed, the CPU has the data required for executing other instructions that need the value of X to be executed. On a regular CPU, if after this Load4 we had an Add 50, this Add 50 (and all other instructions thatdepend on that result) would have to wait all other instructions shown in Figure 3 to be executed. With memory disambiguation, these instructions can be executed early, since the CPU will now have the value of X early.
59 Memory Disambiguation (Dataflow Analysis)
60 Advanced Power Gating With advanced power gating, Core microarchitecture brought CPU power saving to a totally new level. This feature enables the CPU to shut down units that aren t being used at the moment. This idea goes even further, as the CPU can shut down specific parts inside each CPU unit in order to save energy, to dissipate less power and to provide a greater battery life (in the case of mobile CPUs). Another power-saving capability of Core microarchitecture is to turn on only the necessary bits in the CPU internal busses. Many of the CPU internal busses are sized for the worst-case scenario i.e., the largest x86 instruction that exists, which is a 15-byte wide instruction (480 bits)*. So, instead turning on all the 480 data lanes of this particular bus, the CPU can turn on only 32 of its data lanes, all that is necessary for transferring a 32-bit instruction, for example. * You can find yourself quite lost by this statement, since you were always told that Intel architecture uses 32-bits instructions, so further explanation is necessary in order to clarify this affirmation. Inside the CPU what is considered an instruction is the instruction opcode (the machine language equivalent of the assembly language instruction) plus all its required data. This is because in order to be executed, the instruction must enter the execution engine completed, i.e., together with all its required data. Also, the size of each x86 instruction opcode is variable and not fixed at 32 bits, as you may think. For example, an instruction like mov eax, (32-bit data), which stores the (32-bit data) into the CPU s EAX register is considered internally as a 40-bit length instruction (mov eax translates into a 8-bit opcode plus the 32 bits from its data). Actually, having instruction with several different lengths is what characterizes a CISC (Complex Instruction Set Computing) instruction set.
61 Intel Core: Overview
62 MicroArquitetura x86 Nehalem
63 Arquitetura tradicional x86
64 Arquitetura x86 Nehalem em diante
65 Arquitetura x86 Nehalem em diante A AMD que introduziu o controlador de memória integrado ao processador, com a arquitetura AMD64 O barramento equivalente ao QuickPath Interconnect da AMD é o HyperTransport Arquitetura AMD64 Implementada inicialmente no Opteron, em Arquitetura Intel Nehalem Implementada inicialmente no Core i7, em 2008.
66 Nehalem Cache No Nehalem os cores voltarem a ter um cache L2 exclusivo Mas foi introduzido um cache L3 (maior), compartilhado Essa solução também já era usada pela AMD, nas suas CPUs Phenom

67 Arquiteturas de Cache

68 Arquiteturas de Cache
69 Macro-fusion: melhorias Fusão de novas instruções de branch que não eram fundidas na arquitetura Core Macro-fusion em modo 64 bits Na arquitetura Core, somente em modo 32 bits
70 Loop Stream Detector: Melhorias Na arquitetura Core foi introduzido o Loop Stream Detector (LSD) Um cache de 18 instruções entre as unidades de fetch e decode da CPU Quando a CPU está rodando um Loop pequeno, ela não precisa buscar as instruções novamente no Cache L1, elas já estão próximas dos decodificadores de instruções no LSD Além disso a CPU desliga as unidades de fetch e branch prediction enquanto está rodando um loop detectado, para economizar energia LSD na arquitetura Intel Core
 LSD na")
71 Loop Stream Detector: Melhorias Na arquitetura Nehalem O LSD foi movido para depois das unidades de Decode Com isso é feito cache de micro-ops (até 28 micro-ops) Melhora de performance: não é preciso mais decodificar as instruções no loop Economia de energia: a CPU também desliga as unidades de Decode enquanto está rodando um Loop detectado (além das unidades de branch prediction e fetch) LSD na arquitetura Nehalem
Microprocessadores II - ELE 1084
 Microprocessadores II - ELE 1084 CAPÍTULO III PROCESSADORES P5 3.1 Gerações de Processadores 3.1 Gerações de Processadores Quinta Geração (P5) Pentium (586) 32 bits; Instruções MMX; Concorrente K5 (AMD).
Microprocessadores II - ELE 1084 CAPÍTULO III PROCESSADORES P5 3.1 Gerações de Processadores 3.1 Gerações de Processadores Quinta Geração (P5) Pentium (586) 32 bits; Instruções MMX; Concorrente K5 (AMD).
Manutenção de Computadores Montagem de microcomputadores: Entendendo melhor os processadores. Professor: Francisco Ary
 Manutenção de Computadores Montagem de microcomputadores: Entendendo melhor os processadores Professor: Francisco Ary Introdução O processador é um dos componentes mais importantes (e geralmente o mais
Manutenção de Computadores Montagem de microcomputadores: Entendendo melhor os processadores Professor: Francisco Ary Introdução O processador é um dos componentes mais importantes (e geralmente o mais
Hardware - Microprocessador
 Introdução Um microprocessador é um circuito integrado encarregue de executar as instruções de todos os programas armazenados na memória. É o motor que põe tudo a trabalhar desde o momento em que se liga
Introdução Um microprocessador é um circuito integrado encarregue de executar as instruções de todos os programas armazenados na memória. É o motor que põe tudo a trabalhar desde o momento em que se liga
Evolução das CPUs: Dual e Quad Core
 Evolução das CPUs: Dual e Quad Core Cesar Sposito Mário J. Filho Rodrigo Ferrassa... os computadores sequenciais estão se aproximando do limite físico fundamental em sua energia potencial computacional.
Evolução das CPUs: Dual e Quad Core Cesar Sposito Mário J. Filho Rodrigo Ferrassa... os computadores sequenciais estão se aproximando do limite físico fundamental em sua energia potencial computacional.
Bits internos e bits externos. Barramentos. Processadores Atuais. Conceitos Básicos Microprocessadores. Sumário. Introdução.
 Processadores Atuais Eduardo Amaral Sumário Introdução Conceitos Básicos Microprocessadores Barramentos Bits internos e bits externos Clock interno e clock externo Memória cache Co-processador aritmético
Processadores Atuais Eduardo Amaral Sumário Introdução Conceitos Básicos Microprocessadores Barramentos Bits internos e bits externos Clock interno e clock externo Memória cache Co-processador aritmético
29/3/2011. Primeira unidade de execução (pipe U): unidade de processamento completa, capaz de processar qualquer instrução;
: unidade de processamento completa, capaz de processar qualquer instrução;") Em 1993, foi lançada a primeira versão do processador Pentium, que operava a 60 MHz Além do uso otimizado da memória cache (tecnologia já amadurecida) e da multiplicação do clock, o Pentium passou a utilizar
Em 1993, foi lançada a primeira versão do processador Pentium, que operava a 60 MHz Além do uso otimizado da memória cache (tecnologia já amadurecida) e da multiplicação do clock, o Pentium passou a utilizar
SSC510 Arquitetura de Computadores. 12ª aula
 SSC510 Arquitetura de Computadores 12ª aula EVOLUÇÃO DA ARQUITETURA INTEL PROFA. SARITA MAZZINI BRUSCHI 1 Pentium - Modelos 2 Pentium - Arquiteturas Netburst P7 Sétima geração dos processadores da arquitetura
SSC510 Arquitetura de Computadores 12ª aula EVOLUÇÃO DA ARQUITETURA INTEL PROFA. SARITA MAZZINI BRUSCHI 1 Pentium - Modelos 2 Pentium - Arquiteturas Netburst P7 Sétima geração dos processadores da arquitetura
Organização de Computadores 2005/2006 Processadores Intel
 GoBack Organização de Computadores 2005/2006 Processadores Intel Paulo Ferreira paf a dei.isep.ipp.pt Março de 2006 ORGC Processadores Intel slide 1 Pré 8080 8086 80286 Pré ORGC Processadores Intel slide
GoBack Organização de Computadores 2005/2006 Processadores Intel Paulo Ferreira paf a dei.isep.ipp.pt Março de 2006 ORGC Processadores Intel slide 1 Pré 8080 8086 80286 Pré ORGC Processadores Intel slide
Universidade Federal da Bahia Instituto de Matemática Departamento de Ciência da Computação MATA49 Programação de software básico Arquitetura Intel
 Universidade Federal da Bahia Instituto de Matemática Departamento de Ciência da Computação MATA49 Programação de software básico Arquitetura Intel Processadores 8086 Registradores: 16 bits 1978 Data bus:
Universidade Federal da Bahia Instituto de Matemática Departamento de Ciência da Computação MATA49 Programação de software básico Arquitetura Intel Processadores 8086 Registradores: 16 bits 1978 Data bus:
Organização de Computadores 2005/2006 Processadores Intel
 Organização de Computadores 2005/2006 Processadores Intel Paulo Ferreira paf a dei.isep.ipp.pt Março de 2006 Pré História 2 8080.............................................................................................
Organização de Computadores 2005/2006 Processadores Intel Paulo Ferreira paf a dei.isep.ipp.pt Março de 2006 Pré História 2 8080.............................................................................................
Evolução dos Processadores
 Evolução dos Processadores Arquitetura Intel Arquitetura x86 Micro Arquitetura P5 P6 NetBurst Core Processador Pentium Pentium Pro Pentium II Pentium III Pentium 4 Pentium D Xeon Xeon Sequence Core 2 Duo
Evolução dos Processadores Arquitetura Intel Arquitetura x86 Micro Arquitetura P5 P6 NetBurst Core Processador Pentium Pentium Pro Pentium II Pentium III Pentium 4 Pentium D Xeon Xeon Sequence Core 2 Duo
Capítulo Sistemas de Memória Memória Virtual. Ch7b 1
 Capítulo Sistemas de Memória Memória Virtual Ch7b Memória Virtual Memória principal funciona como uma cache para o armazenamento secundário (disco) Virtual addresses Physical addresses Address translation
Capítulo Sistemas de Memória Memória Virtual Ch7b Memória Virtual Memória principal funciona como uma cache para o armazenamento secundário (disco) Virtual addresses Physical addresses Address translation
periféricos: interfaces humano-computador (HCI) arquivo de informação comunicações
 arquivo de informação comunicações") Introdução aos Sistemas de Computação (6) Análise de componentes num computador Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3.
Introdução aos Sistemas de Computação (6) Análise de componentes num computador Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3.
Organização de Computadores
 Capítulo 2 - A Organização de Computadores Orlando Loques setembro 2006 Referências: principal: Capítulo 2, Structured Computer Organization, A.S. Tanenbaum, (c) 2006 Pearson Education Inc Computer Organization
Capítulo 2 - A Organização de Computadores Orlando Loques setembro 2006 Referências: principal: Capítulo 2, Structured Computer Organization, A.S. Tanenbaum, (c) 2006 Pearson Education Inc Computer Organization
Microprocessadores. Família x86 - Evolução
 Família x86 - Evolução António M. Gonçalves Pinheiro Departamento de Física Covilhã - Portugal pinheiro@ubi.pt i8086 16 bits de dados 20 bits de endereços 1MByte Clock 2 [4,8] MHz i80286 24 bits de endereço
Família x86 - Evolução António M. Gonçalves Pinheiro Departamento de Física Covilhã - Portugal pinheiro@ubi.pt i8086 16 bits de dados 20 bits de endereços 1MByte Clock 2 [4,8] MHz i80286 24 bits de endereço
User Guide Manual de Utilizador
 2400 DPI OPTICAL GAMING MOUSE User Guide Manual de Utilizador 2014 1Life Simplify it All rights reserved. www.1-life.eu 2 2400 DPI OPTICAL GAMING MOUSE ENGLISH USER GUIDE...4 MANUAL DE UTILIZADOR PORTUGUÊS...18
2400 DPI OPTICAL GAMING MOUSE User Guide Manual de Utilizador 2014 1Life Simplify it All rights reserved. www.1-life.eu 2 2400 DPI OPTICAL GAMING MOUSE ENGLISH USER GUIDE...4 MANUAL DE UTILIZADOR PORTUGUÊS...18
Microprocessadores II - ELE 1084
 Microprocessadores II - ELE 1084 CAPÍTULO III OS PROCESSADORES 3.1 Gerações de Processadores 3.1 Gerações de Processadores Primeira Geração (P1) Início da arquitetura de 16 bits CPU 8086 e 8088; 20 bits
Microprocessadores II - ELE 1084 CAPÍTULO III OS PROCESSADORES 3.1 Gerações de Processadores 3.1 Gerações de Processadores Primeira Geração (P1) Início da arquitetura de 16 bits CPU 8086 e 8088; 20 bits
Grupo B: Andre Adelino Elaine Rodrigues Claudenice Lopes Temonji Lira
 PROCESSADORES INTEL PARA NOTEBOOKS Grupo B: Andre Adelino Elaine Rodrigues Claudenice Lopes Temonji Lira Introdução Celeron M Elaine Rodrigues - elainedsr@gmail.com Séries: 300 400 500 700 900 T1000 T3000
PROCESSADORES INTEL PARA NOTEBOOKS Grupo B: Andre Adelino Elaine Rodrigues Claudenice Lopes Temonji Lira Introdução Celeron M Elaine Rodrigues - elainedsr@gmail.com Séries: 300 400 500 700 900 T1000 T3000
Arquitetura e Organização de Computadores. Capítulo 0 - Introdução
 Arquitetura e Organização de Computadores Capítulo 0 - Introdução POR QUE ESTUDAR ARQUITETURA DE COMPUTADORES? 2 https://www.cis.upenn.edu/~milom/cis501-fall12/ Entender para onde os computadores estão
Arquitetura e Organização de Computadores Capítulo 0 - Introdução POR QUE ESTUDAR ARQUITETURA DE COMPUTADORES? 2 https://www.cis.upenn.edu/~milom/cis501-fall12/ Entender para onde os computadores estão
SSC0611 Arquitetura de Computadores
 SSC0611 Arquitetura de Computadores 14ª Aula Evolução Arquitetura Intel Parte 1 Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Conhecida como arquitetura x86 ou 8086 devido ao fato dos primeiros processadores
SSC0611 Arquitetura de Computadores 14ª Aula Evolução Arquitetura Intel Parte 1 Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Conhecida como arquitetura x86 ou 8086 devido ao fato dos primeiros processadores
Welcome to Lesson A of Story Time for Portuguese
 Portuguese Lesson A Welcome to Lesson A of Story Time for Portuguese Story Time is a program designed for students who have already taken high school or college courses or students who have completed other
Portuguese Lesson A Welcome to Lesson A of Story Time for Portuguese Story Time is a program designed for students who have already taken high school or college courses or students who have completed other
Hardware. Objetivos da aula. Fornecer exemplos de processadores Intel. Esclarecer as diferenças e as tecnologias embutidas nos processadores Intel.
 Hardware UCP Unidade Central de Processamento Características dos processadores Intel Disciplina: Organização e Arquitetura de Computadores Prof. Luiz Antonio do Nascimento Faculdade Nossa Cidade Objetivos
Hardware UCP Unidade Central de Processamento Características dos processadores Intel Disciplina: Organização e Arquitetura de Computadores Prof. Luiz Antonio do Nascimento Faculdade Nossa Cidade Objetivos
Organização e Arquitetura de Computadores I. de Computadores
 Universidade Federal de Campina Grande Departamento de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de I Organização Básica B de (Parte V, Complementar)
Universidade Federal de Campina Grande Departamento de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de I Organização Básica B de (Parte V, Complementar)
Accessing the contents of the Moodle Acessando o conteúdo do Moodle
 Accessing the contents of the Moodle Acessando o conteúdo do Moodle So that all the available files in the Moodle can be opened without problems, we recommend some software that will have to be installed
Accessing the contents of the Moodle Acessando o conteúdo do Moodle So that all the available files in the Moodle can be opened without problems, we recommend some software that will have to be installed
Serviços: API REST. URL - Recurso
 Serviços: API REST URL - Recurso URLs reflectem recursos Cada entidade principal deve corresponder a um recurso Cada recurso deve ter um único URL Os URLs referem em geral substantivos URLs podem reflectir
Serviços: API REST URL - Recurso URLs reflectem recursos Cada entidade principal deve corresponder a um recurso Cada recurso deve ter um único URL Os URLs referem em geral substantivos URLs podem reflectir
O hardware é a parte física do computador, como o processador, memória, placamãe, entre outras. Figura 2.1 Sistema Computacional Hardware
 1 2 Revisão de Hardware 2.1 Hardware O hardware é a parte física do computador, como o processador, memória, placamãe, entre outras. Figura 2.1 Sistema Computacional Hardware 2.1.1 Processador O Processador
1 2 Revisão de Hardware 2.1 Hardware O hardware é a parte física do computador, como o processador, memória, placamãe, entre outras. Figura 2.1 Sistema Computacional Hardware 2.1.1 Processador O Processador
Guião M. Descrição das actividades
 Proposta de Guião para uma Prova Grupo: Inovação Disciplina: Inglês, Nível de Continuação, 11.º ano Domínio de Referência: O Mundo do trabalho Duração da prova: 15 a 20 minutos 1.º MOMENTO Guião M Intervenientes
Proposta de Guião para uma Prova Grupo: Inovação Disciplina: Inglês, Nível de Continuação, 11.º ano Domínio de Referência: O Mundo do trabalho Duração da prova: 15 a 20 minutos 1.º MOMENTO Guião M Intervenientes
Guião A. Descrição das actividades
 Proposta de Guião para uma Prova Grupo: Ponto de Encontro Disciplina: Inglês, Nível de Continuação, 11.º ano Domínio de Referência: Um Mundo de Muitas Culturas Duração da prova: 15 a 20 minutos 1.º MOMENTO
Proposta de Guião para uma Prova Grupo: Ponto de Encontro Disciplina: Inglês, Nível de Continuação, 11.º ano Domínio de Referência: Um Mundo de Muitas Culturas Duração da prova: 15 a 20 minutos 1.º MOMENTO
FACULDADE PITÁGORAS PRONATEC
 FACULDADE PITÁGORAS PRONATEC DISCIPLINA: ARQUITETURA DE COMPUTADORES Prof. Ms. Carlos José Giudice dos Santos carlos@oficinadapesquisa.com.br www.oficinadapesquisa.com.br Objetivos Ao final desta apostila,
FACULDADE PITÁGORAS PRONATEC DISCIPLINA: ARQUITETURA DE COMPUTADORES Prof. Ms. Carlos José Giudice dos Santos carlos@oficinadapesquisa.com.br www.oficinadapesquisa.com.br Objetivos Ao final desta apostila,
Técnicas de Manutenção de Computadores
 Técnicas de Manutenção de Computadores Professor: Luiz Claudio Ferreira de Souza Processadores É indispensável em qualquer computador, tem a função de gerenciamento, controlando todas as informações de
Técnicas de Manutenção de Computadores Professor: Luiz Claudio Ferreira de Souza Processadores É indispensável em qualquer computador, tem a função de gerenciamento, controlando todas as informações de
 HARDWARE Montagem e Manutenção de Computadores Instrutor: Luiz Henrique Goulart 15ª AULA OBJETIVOS: PROCESSADORES EVOLUÇÃO / GERAÇÕES BARRAMENTO (BITS) FREQÜÊNCIA (MHZ) OVERCLOCK ENCAPSULAMENTO APOSTILA
HARDWARE Montagem e Manutenção de Computadores Instrutor: Luiz Henrique Goulart 15ª AULA OBJETIVOS: PROCESSADORES EVOLUÇÃO / GERAÇÕES BARRAMENTO (BITS) FREQÜÊNCIA (MHZ) OVERCLOCK ENCAPSULAMENTO APOSTILA
Unidade 4 Paralelismo em Nível de Instrução. Filipe Moura de Lima Gutenberg Pessoa Botelho Neto Thiago Vinícius Freire de Araújo Ribeiro
 Unidade 4 Paralelismo em Nível de Instrução Filipe Moura de Lima Gutenberg Pessoa Botelho Neto Thiago Vinícius Freire de Araújo Ribeiro Sumário Introdução O Pipeline Pipeline em diferentes CPUs ARM Cortex-A9
Unidade 4 Paralelismo em Nível de Instrução Filipe Moura de Lima Gutenberg Pessoa Botelho Neto Thiago Vinícius Freire de Araújo Ribeiro Sumário Introdução O Pipeline Pipeline em diferentes CPUs ARM Cortex-A9
IDENTIFICAÇÃO MANUTENÇÃO
 IDENTIFICAÇÃO MANUTENÇÃO ESTRUTURA DOS MICROS PADRÃO PC AULA 01 Sobre aula 1 Números binários e hexadecimais Dispositivos digitais e analógicos Circuitos integrados Estrutura dos micros padrão PC Micros
IDENTIFICAÇÃO MANUTENÇÃO ESTRUTURA DOS MICROS PADRÃO PC AULA 01 Sobre aula 1 Números binários e hexadecimais Dispositivos digitais e analógicos Circuitos integrados Estrutura dos micros padrão PC Micros
Microprocessadores II - ELE 1084
 Microprocessadores II - ELE 1084 CAPÍTULO III OS PROCESSADORES 3.1 Gerações de Processadores 3.1 Gerações de Processadores Primeira Geração (P1) Início da arquitetura de 16 bits CPU 8086 e 8088; Arquiteturas
Microprocessadores II - ELE 1084 CAPÍTULO III OS PROCESSADORES 3.1 Gerações de Processadores 3.1 Gerações de Processadores Primeira Geração (P1) Início da arquitetura de 16 bits CPU 8086 e 8088; Arquiteturas
Strings. COM10615-Tópicos Especiais em Programação I edmar.kampke@ufes.br 2014-II
 Strings COM10615-Tópicos Especiais em Programação I edmar.kampke@ufes.br Introdução Uma estrutura de dados fundamental Crescente Importância Aplicações: Busca do Google Genoma Humano 2 Caracteres Codificação
Strings COM10615-Tópicos Especiais em Programação I edmar.kampke@ufes.br Introdução Uma estrutura de dados fundamental Crescente Importância Aplicações: Busca do Google Genoma Humano 2 Caracteres Codificação
A história do Processadores O que é o processador Características dos Processadores Vários tipos de Processadores
 A história do Processadores O que é o processador Características dos Processadores Vários tipos de Processadores As empresas mais antigas e ainda hoje no mercado que fabricam CPUs é a Intel, AMD e Cyrix.
A história do Processadores O que é o processador Características dos Processadores Vários tipos de Processadores As empresas mais antigas e ainda hoje no mercado que fabricam CPUs é a Intel, AMD e Cyrix.
Hardware de Computadores
 Placa Mãe Hardware de Computadores Introdução Placa-mãe, também denominada mainboard ou motherboard, é uma placa de circuito impresso eletrônico. É considerado o elemento mais importante de um computador,
Placa Mãe Hardware de Computadores Introdução Placa-mãe, também denominada mainboard ou motherboard, é uma placa de circuito impresso eletrônico. É considerado o elemento mais importante de um computador,
GUIÃO A. Ano: 9º Domínio de Referência: O Mundo do Trabalho. 1º Momento. Intervenientes e Tempos. Descrição das actividades
 Ano: 9º Domínio de Referência: O Mundo do Trabalho GUIÃO A 1º Momento Intervenientes e Tempos Descrição das actividades Good morning / afternoon / evening, A and B. For about three minutes, I would like
Ano: 9º Domínio de Referência: O Mundo do Trabalho GUIÃO A 1º Momento Intervenientes e Tempos Descrição das actividades Good morning / afternoon / evening, A and B. For about three minutes, I would like
Arquitetura de Von Neumann e os Computadores Modernos
 Arquitetura de Von Neumann e os Computadores Modernos Arquitetura de Computadores e Software Básico Aula 5 Flávia Maristela (flaviamsn@ifba.edu.br) Arquitetura de Von Neumann e as máquinas modernas Onde
Arquitetura de Von Neumann e os Computadores Modernos Arquitetura de Computadores e Software Básico Aula 5 Flávia Maristela (flaviamsn@ifba.edu.br) Arquitetura de Von Neumann e as máquinas modernas Onde
Arquitetura e Organização de Computadores. Capítulo 0 - Introdução
 Arquitetura e Organização de Computadores Capítulo 0 - Introdução POR QUE ESTUDAR ARQUITETURA DE COMPUTADORES? 2 https://www.cis.upenn.edu/~milom/cis501-fall12/ Entender para onde os computadores estão
Arquitetura e Organização de Computadores Capítulo 0 - Introdução POR QUE ESTUDAR ARQUITETURA DE COMPUTADORES? 2 https://www.cis.upenn.edu/~milom/cis501-fall12/ Entender para onde os computadores estão
Plataforma Centrino: Plataforma de Marketing, que especifica o CPU, Chipset e Interface Wireless.
 1 2 Micro Arquitecturas INTEL: x86 microarchitectures: i386, i486, P5, P6, NetBurst, Pentium M, Core, Nehalem (under development), Sandy Bridge (2010) Itanium microarchitectures Segmento de servidores
1 2 Micro Arquitecturas INTEL: x86 microarchitectures: i386, i486, P5, P6, NetBurst, Pentium M, Core, Nehalem (under development), Sandy Bridge (2010) Itanium microarchitectures Segmento de servidores
Arquitetura de Computadores
 Arquitetura de Computadores Apresentação do curso Ronaldo de Freitas Zampolo zampolo@ieee.org, zampolo@ufpa.br Tópicos Como iremos trabalhar Atendimento, avaliação, etc. Introdução e conceitos básicos
Arquitetura de Computadores Apresentação do curso Ronaldo de Freitas Zampolo zampolo@ieee.org, zampolo@ufpa.br Tópicos Como iremos trabalhar Atendimento, avaliação, etc. Introdução e conceitos básicos
Conjunto de instruções do CPU. Arquitectura de um computador. Definição das instruções (1) Definição das instruções (2)
 Definição das instruções (2)") Arquitectura de um computador Caracterizada por: Conjunto de instruções do processador (ISA Estrutura interna do processador (que registadores existem, etc Modelo de memória (dimensão endereçável, alcance
Arquitectura de um computador Caracterizada por: Conjunto de instruções do processador (ISA Estrutura interna do processador (que registadores existem, etc Modelo de memória (dimensão endereçável, alcance
Intel Atom. Arquitetura do processador para dispositivos móveis. Fabrício Rodrigues / Fernando Rodrigues
 UNISUAM CENTRO UNIVERSITÁRIO AUGUSTO MOTTA Graduação em Ciência da Computação Trabalho da disciplina: Tópicos Especiais em Arquitetura de Computadores Professor: Charles Bastos Intel Atom Arquitetura do
UNISUAM CENTRO UNIVERSITÁRIO AUGUSTO MOTTA Graduação em Ciência da Computação Trabalho da disciplina: Tópicos Especiais em Arquitetura de Computadores Professor: Charles Bastos Intel Atom Arquitetura do
Capítulo 4. MARIE (Machine Architecture Really Intuitive and Easy)
") Capítulo 4 João Lourenço Joao.Lourenco@di.fct.unl.pt Faculdade de Ciências e Tecnologia Universidade Nova de Lisboa 2007-2008 MARIE (Machine Architecture Really Intuitive and Easy) Adaptado dos transparentes
Capítulo 4 João Lourenço Joao.Lourenco@di.fct.unl.pt Faculdade de Ciências e Tecnologia Universidade Nova de Lisboa 2007-2008 MARIE (Machine Architecture Really Intuitive and Easy) Adaptado dos transparentes
Microprocessadores. Prof. Leonardo Barreto Campos 1
 Microprocessadores Prof. Leonardo Barreto Campos 1 Sumário Introdução; Arquitetura de Microprocessadores; Unidade de Controle UC; Unidade Lógica Aritméticas ULA; Arquitetura de von Neumann; Execução de
Microprocessadores Prof. Leonardo Barreto Campos 1 Sumário Introdução; Arquitetura de Microprocessadores; Unidade de Controle UC; Unidade Lógica Aritméticas ULA; Arquitetura de von Neumann; Execução de
Ataques Polimorficos
 Ataques Polimorficos Rodrigo Rubira Branco rodrigo@firewalls.com.br bsdaemon@bsdaemon.org - Resumo: Ha alguns anos, uma nova ideia foi inserida no mundo dos virus: Codigos polimorficos. Esta ideia consistia
Ataques Polimorficos Rodrigo Rubira Branco rodrigo@firewalls.com.br bsdaemon@bsdaemon.org - Resumo: Ha alguns anos, uma nova ideia foi inserida no mundo dos virus: Codigos polimorficos. Esta ideia consistia
Hardware Avançado. Laércio Vasconcelos Rio Branco, mar/2007 www.laercio.com.br
 Hardware Avançado Laércio Vasconcelos Rio Branco, mar/2007 www.laercio.com.br Avanços recentes em Processadores Chipsets Memórias Discos rígidos Microeletrônica Um processador moderno é formado por mais
Hardware Avançado Laércio Vasconcelos Rio Branco, mar/2007 www.laercio.com.br Avanços recentes em Processadores Chipsets Memórias Discos rígidos Microeletrônica Um processador moderno é formado por mais
Arquitetura e Organização de Computadores 2
 Arquitetura e Organização de Computadores 2 Escalonamento Estático e Arquiteturas VLIW Dynamic Scheduling, Multiple Issue, and Speculation Modern microarchitectures: Dynamic scheduling + multiple issue
Arquitetura e Organização de Computadores 2 Escalonamento Estático e Arquiteturas VLIW Dynamic Scheduling, Multiple Issue, and Speculation Modern microarchitectures: Dynamic scheduling + multiple issue
Arquitetura de processadores: RISC e CISC
 Arquitetura de processadores: RISC e CISC A arquitetura de processador descreve o processador que foi usado em um computador. Grande parte dos computadores vêm com identificação e literatura descrevendo
Arquitetura de processadores: RISC e CISC A arquitetura de processador descreve o processador que foi usado em um computador. Grande parte dos computadores vêm com identificação e literatura descrevendo
Processador ARM Cortex-A9
 Erick Nogueira Nascimento (032483) Franz Pietz (076673) Lucas Watanabe (134068) 11 de junho de 2012 Introdução Alto desempenho e economia de energia Arquitetura ARMv7-A Características do processador super-escalável
Erick Nogueira Nascimento (032483) Franz Pietz (076673) Lucas Watanabe (134068) 11 de junho de 2012 Introdução Alto desempenho e economia de energia Arquitetura ARMv7-A Características do processador super-escalável
Unidade Central de Processamento (CPU) Processador. Renan Manola Introdução ao Computador 2010/01
 Processador. Renan Manola Introdução ao Computador 2010/01") Unidade Central de Processamento (CPU) Processador Renan Manola Introdução ao Computador 2010/01 Componentes de um Computador (1) Computador Eletrônico Digital É um sistema composto por: Memória Principal
Unidade Central de Processamento (CPU) Processador Renan Manola Introdução ao Computador 2010/01 Componentes de um Computador (1) Computador Eletrônico Digital É um sistema composto por: Memória Principal
 CISC RISC Introdução A CISC (em inglês: Complex Instruction Set Computing, Computador com um Conjunto Complexo de Instruções), usada em processadores Intel e AMD; suporta mais instruções no entanto, com
CISC RISC Introdução A CISC (em inglês: Complex Instruction Set Computing, Computador com um Conjunto Complexo de Instruções), usada em processadores Intel e AMD; suporta mais instruções no entanto, com
História. Pioneiros AMD
 História Pioneiros AMD Marco na História 1969 AMD estabelece sede em Sunnyvale, Califórnia. 1970 AMD lança seu primeiro contador Lógico. 1982 A pedido da IBM, AMD assina um acordo para servir como uma
História Pioneiros AMD Marco na História 1969 AMD estabelece sede em Sunnyvale, Califórnia. 1970 AMD lança seu primeiro contador Lógico. 1982 A pedido da IBM, AMD assina um acordo para servir como uma
Frederico Tavares - MICEI 06/07. Frederico Tavares
 ICCA 07 8th Internal Conference on Computer Architecture FAQ - 05 Ao nível das últimas gerações do IA32 (Pentium III e ) quais as principais diferenças entre os processadores da Intel e da AMD? "IA32 processors:
ICCA 07 8th Internal Conference on Computer Architecture FAQ - 05 Ao nível das últimas gerações do IA32 (Pentium III e ) quais as principais diferenças entre os processadores da Intel e da AMD? "IA32 processors:
Processador ( CPU ) E/S. Memória. Sistema composto por Processador, Memória e dispositivos de E/S, interligados por um barramento
 E/S. Memória. Sistema composto por Processador, Memória e dispositivos de E/S, interligados por um barramento") 1 Processadores Computador Processador ( CPU ) Memória E/S Sistema composto por Processador, Memória e dispositivos de E/S, interligados por um barramento 2 Pastilha 3 Processadores (CPU,, Microcontroladores)
1 Processadores Computador Processador ( CPU ) Memória E/S Sistema composto por Processador, Memória e dispositivos de E/S, interligados por um barramento 2 Pastilha 3 Processadores (CPU,, Microcontroladores)
Curso EFA Técnico/a de Informática - Sistemas. Óbidos
 Curso EFA Técnico/a de Informática - Sistemas Óbidos MÓDULO 769 Arquitectura interna do computador Carga horária 25 2. PROCESSADOR (UNIDADE CENTRAL DE PROCESSAMENTO CPU) Formadora: Vanda Martins 3 O processador
Curso EFA Técnico/a de Informática - Sistemas Óbidos MÓDULO 769 Arquitectura interna do computador Carga horária 25 2. PROCESSADOR (UNIDADE CENTRAL DE PROCESSAMENTO CPU) Formadora: Vanda Martins 3 O processador
Placa de vídeo em CUDA
 Placa de vídeo em CUDA Matheus Costa Leone de Souza Krystian Aparacido Resumo Quando você tem um cálculo que possa ser grande demais para você realizar a mão, a primeira solução que lhe vem a cabeça é
Placa de vídeo em CUDA Matheus Costa Leone de Souza Krystian Aparacido Resumo Quando você tem um cálculo que possa ser grande demais para você realizar a mão, a primeira solução que lhe vem a cabeça é
Sistemas Computacionais II Professor Frederico Sauer
 Sistemas Computacionais II Professor Frederico Sauer Livro-texto: Introdução à Organização de Computadores 4ª edição Mário A. Monteiro Livros Técnicos e Científicos Editora. Atenção: Este material não
Sistemas Computacionais II Professor Frederico Sauer Livro-texto: Introdução à Organização de Computadores 4ª edição Mário A. Monteiro Livros Técnicos e Científicos Editora. Atenção: Este material não
ARQUITETURA DE COMPUTADORES - 1866
 7 Unidade Central de Processamento (UCP): O processador é o componente vital do sistema de computação, responsável pela realização das operações de processamento e de controle, durante a execução de um
7 Unidade Central de Processamento (UCP): O processador é o componente vital do sistema de computação, responsável pela realização das operações de processamento e de controle, durante a execução de um
Tecnologias de Construção de Memórias e Memórias RAM, entrelaçada e Virtual
 Tecnologias de Construção de Memórias e Memórias RAM, entrelaçada e Virtual Arquiteturas para Alto Desmpenho Prof. pauloac@ita.br Sala 110 Prédio da Computação www.comp.ita.br/~pauloac Tempos de Acesso
Tecnologias de Construção de Memórias e Memórias RAM, entrelaçada e Virtual Arquiteturas para Alto Desmpenho Prof. pauloac@ita.br Sala 110 Prédio da Computação www.comp.ita.br/~pauloac Tempos de Acesso
ANHANGUERA EDUCACIONAL. Capítulo 2. Conceitos de Hardware e Software
 ANHANGUERA EDUCACIONAL Capítulo 2 Conceitos de Hardware e Software Hardware Um sistema computacional é um conjunto de de circuitos eletronicos. Unidade funcionais: processador, memória principal, dispositivo
ANHANGUERA EDUCACIONAL Capítulo 2 Conceitos de Hardware e Software Hardware Um sistema computacional é um conjunto de de circuitos eletronicos. Unidade funcionais: processador, memória principal, dispositivo
Capítulo 1 Introdução
 Capítulo 1 Introdução Programa: Seqüência de instruções descrevendo como executar uma determinada tarefa. Computador: Conjunto do hardware + Software Os circuitos eletrônicos de um determinado computador
Capítulo 1 Introdução Programa: Seqüência de instruções descrevendo como executar uma determinada tarefa. Computador: Conjunto do hardware + Software Os circuitos eletrônicos de um determinado computador
Introdução à Arquitetura de Computadores
 1 Introdução à Arquitetura de Computadores Hardware e software Organização de um computador: Processador: registradores, ALU, unidade de controle Memórias Dispositivos de E/S Barramentos Linguagens de
1 Introdução à Arquitetura de Computadores Hardware e software Organização de um computador: Processador: registradores, ALU, unidade de controle Memórias Dispositivos de E/S Barramentos Linguagens de
Diminui o gargalo existente entre processador e memória principal; 5 a 10 vezes mais rápidas que a memória principal; Ligada diretamente à MP;
 Diminui o gargalo existente entre processador e memória principal; Diferença de velocidade 5 a 10 vezes mais rápidas que a memória principal; Ligada diretamente à MP; Tecnologia semelhante à da CPU e,
Diminui o gargalo existente entre processador e memória principal; Diferença de velocidade 5 a 10 vezes mais rápidas que a memória principal; Ligada diretamente à MP; Tecnologia semelhante à da CPU e,
Introdução a Informática. Prof.: Roberto Franciscatto
 Introdução a Informática Prof.: Roberto Franciscatto 3.1 EXECUÇÃO DAS INSTRUÇÕES A UCP tem duas seções: Unidade de Controle Unidade Lógica e Aritmética Um programa se caracteriza por: uma série de instruções
Introdução a Informática Prof.: Roberto Franciscatto 3.1 EXECUÇÃO DAS INSTRUÇÕES A UCP tem duas seções: Unidade de Controle Unidade Lógica e Aritmética Um programa se caracteriza por: uma série de instruções
CPU Unidade Central de Processamento. História e progresso
 CPU Unidade Central de Processamento História e progresso O microprocessador, ou CPU, como é mais conhecido, é o cérebro do computador e é ele que executa todos os cálculos e processamentos necessários,
CPU Unidade Central de Processamento História e progresso O microprocessador, ou CPU, como é mais conhecido, é o cérebro do computador e é ele que executa todos os cálculos e processamentos necessários,
Tais operações podem utilizar um (operações unárias) ou dois (operações binárias) valores.
 ou dois (operações binárias) valores.") Tais operações podem utilizar um (operações unárias) ou dois (operações binárias) valores. 7.3.1.2 Registradores: São pequenas unidades de memória, implementadas na CPU, com as seguintes características:
Tais operações podem utilizar um (operações unárias) ou dois (operações binárias) valores. 7.3.1.2 Registradores: São pequenas unidades de memória, implementadas na CPU, com as seguintes características:
Introdução à Organização de Computadores. Sistemas da Computação Prof. Rossano Pablo Pinto, Msc. rossano at gmail com 2 semestre 2007
 Introdução à Organização de Computadores Sistemas da Computação Prof. Rossano Pablo Pinto, Msc. rossano at gmail com 2 semestre 2007 Tópicos Processadores Memória Principal Memória Secundária Entrada e
Introdução à Organização de Computadores Sistemas da Computação Prof. Rossano Pablo Pinto, Msc. rossano at gmail com 2 semestre 2007 Tópicos Processadores Memória Principal Memória Secundária Entrada e
Intel Pentium 4 vs Intel Itanium
 Intel Pentium 4 vs Intel Itanium Tiago Manuel da Cruz Luís Instituto Superior Técnico Grupo 10 53871 tmcl@mega.ist.utl.pt João Miguel Coelho Rosado Instituto Superior Técnico Grupo 10 53929 jmcro@mega.ist.utl.pt
Intel Pentium 4 vs Intel Itanium Tiago Manuel da Cruz Luís Instituto Superior Técnico Grupo 10 53871 tmcl@mega.ist.utl.pt João Miguel Coelho Rosado Instituto Superior Técnico Grupo 10 53929 jmcro@mega.ist.utl.pt
Como Falar no Rádio - Prática de Locução Am e Fm (Portuguese Edition)
") Como Falar no Rádio - Prática de Locução Am e Fm (Portuguese Edition) Cyro César Click here if your download doesn"t start automatically Como Falar no Rádio - Prática de Locução Am e Fm (Portuguese Edition)
Como Falar no Rádio - Prática de Locução Am e Fm (Portuguese Edition) Cyro César Click here if your download doesn"t start automatically Como Falar no Rádio - Prática de Locução Am e Fm (Portuguese Edition)
Programação de Sistemas
 Programação de Sistemas Introdução à gestão de memória Programação de Sistemas Gestão de memória : 1/16 Introdução (1) A memória central de um computador é escassa. [1981] IBM PC lançado com 64KB na motherboard,
Programação de Sistemas Introdução à gestão de memória Programação de Sistemas Gestão de memória : 1/16 Introdução (1) A memória central de um computador é escassa. [1981] IBM PC lançado com 64KB na motherboard,
Biscuit - potes (Coleção Artesanato) (Portuguese Edition)
 (Portuguese Edition)") Biscuit - potes (Coleção Artesanato) (Portuguese Edition) Regina Panzoldo Click here if your download doesn"t start automatically Biscuit - potes (Coleção Artesanato) (Portuguese Edition) Regina Panzoldo
Biscuit - potes (Coleção Artesanato) (Portuguese Edition) Regina Panzoldo Click here if your download doesn"t start automatically Biscuit - potes (Coleção Artesanato) (Portuguese Edition) Regina Panzoldo
Contil Informática. Curso Técnico em Informática Processadores Core
 Contil Informática Curso Técnico em Informática Processadores Core Quais as diferenças entre os processadores Intel Core i3, i5 e i7? A tecnologia avançada na área de hardware possibilita um avanço desenfreado
Contil Informática Curso Técnico em Informática Processadores Core Quais as diferenças entre os processadores Intel Core i3, i5 e i7? A tecnologia avançada na área de hardware possibilita um avanço desenfreado
Cap. 5 - Microprocessadores
 Cap. 5 - Microprocessadores Arquitectura de Computadores 2010/2011 Licenciatura em Informática de Gestão Dora Melo (Responsável) Originais cedidos gentilmente por António Trigo (2009/2010) Instituto Superior
Cap. 5 - Microprocessadores Arquitectura de Computadores 2010/2011 Licenciatura em Informática de Gestão Dora Melo (Responsável) Originais cedidos gentilmente por António Trigo (2009/2010) Instituto Superior
:: COMO ESCOLHER UMA ESCOLA IDIOMAS PDF ::
 :: COMO ESCOLHER UMA ESCOLA IDIOMAS PDF :: [Download] COMO ESCOLHER UMA ESCOLA IDIOMAS PDF COMO ESCOLHER UMA ESCOLA IDIOMAS PDF - Are you looking for Como Escolher Uma Escola Idiomas Books? Now, you will
:: COMO ESCOLHER UMA ESCOLA IDIOMAS PDF :: [Download] COMO ESCOLHER UMA ESCOLA IDIOMAS PDF COMO ESCOLHER UMA ESCOLA IDIOMAS PDF - Are you looking for Como Escolher Uma Escola Idiomas Books? Now, you will
Solutions. Adição de Ingredientes. TC=0.5m TC=2m TC=1m TC=3m TC=10m. O Tempo de Ciclo do Processo é determinado pelo TC da operação mais lenta.
 Operations Management Homework 1 Solutions Question 1 Encomenda Preparação da Massa Amassar Adição de Ingredientes Espera Forno Entrega TC=0.5m TC=2m TC=1m TC=3m TC=10m TC=1.5m (se mesmo operador) O Tempo
Operations Management Homework 1 Solutions Question 1 Encomenda Preparação da Massa Amassar Adição de Ingredientes Espera Forno Entrega TC=0.5m TC=2m TC=1m TC=3m TC=10m TC=1.5m (se mesmo operador) O Tempo
Universidade Federal de Campina Grande Unidade Acadêmica de Sistemas e Computação Curso de Bacharelado em Ciência da Computação.
 Universidade Federal de Campina Grande Unidade cadêmica de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e rquitetura de Computadores I Organização e rquitetura Básicas
Universidade Federal de Campina Grande Unidade cadêmica de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e rquitetura de Computadores I Organização e rquitetura Básicas
SSC0510 Arquitetura de Computadores
 SSC0510 Arquitetura de Computadores 10ª Aula Evolução Arquitetura Intel Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Conhecida como arquitetura x86 ou 8086 devido ao fato dos primeiros processadores
SSC0510 Arquitetura de Computadores 10ª Aula Evolução Arquitetura Intel Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Conhecida como arquitetura x86 ou 8086 devido ao fato dos primeiros processadores
hdd enclosure caixa externa para disco rígido
 hdd enclosure caixa externa para disco rígido USER S GUIDE SPECIFICATONS HDD Support: SATA 2.5 Material: Aluminium and plastics Input connections: SATA HDD Output connections: USB 3.0 (up to 5.0Gbps)
hdd enclosure caixa externa para disco rígido USER S GUIDE SPECIFICATONS HDD Support: SATA 2.5 Material: Aluminium and plastics Input connections: SATA HDD Output connections: USB 3.0 (up to 5.0Gbps)
Arquitecturas Alternativas. Pipelining Super-escalar VLIW IA-64
 Arquitecturas Alternativas Pipelining Super-escalar VLIW IA-64 Pipeline de execução A execução de uma instrução passa por várias fases: Vimos o ciclo: fetch, decode, execute fetch decode execute instrução
Arquitecturas Alternativas Pipelining Super-escalar VLIW IA-64 Pipeline de execução A execução de uma instrução passa por várias fases: Vimos o ciclo: fetch, decode, execute fetch decode execute instrução
Organização e Arquitetura de Computadores I
 Universidade Federal de Campina Grande Unidade cadêmica de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e rquitetura de Computadores I Nível da Microarquitetura (Parte
Universidade Federal de Campina Grande Unidade cadêmica de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e rquitetura de Computadores I Nível da Microarquitetura (Parte
Pipelining - analogia
 PIPELINE Pipelining - analogia Pipelining OBJECTIVO: Aumentar o desempenho pelo aumento do fluxo de instruções Program execution Time order (in instructions) lw $1, 100($0) Instruction fetch ALU Data access
PIPELINE Pipelining - analogia Pipelining OBJECTIVO: Aumentar o desempenho pelo aumento do fluxo de instruções Program execution Time order (in instructions) lw $1, 100($0) Instruction fetch ALU Data access
Capítulo 4 Livro do Mário Monteiro Introdução Hierarquia de memória Memória Principal. Memória principal
 Capítulo 4 Livro do Mário Monteiro Introdução Hierarquia de memória Memória Principal Organização Operações de leitura e escrita Capacidade http://www.ic.uff.br/~debora/fac! 1 2 Componente de um sistema
Capítulo 4 Livro do Mário Monteiro Introdução Hierarquia de memória Memória Principal Organização Operações de leitura e escrita Capacidade http://www.ic.uff.br/~debora/fac! 1 2 Componente de um sistema
DIBELS TM. Portuguese Translations of Administration Directions
 DIBELS TM Portuguese Translations of Administration Directions Note: These translations can be used with students having limited English proficiency and who would be able to understand the DIBELS tasks
DIBELS TM Portuguese Translations of Administration Directions Note: These translations can be used with students having limited English proficiency and who would be able to understand the DIBELS tasks
Sistema de Computação
 Sistema de Computação Máquinas multinível Nível 0 verdadeiro hardware da máquina, executando os programas em linguagem de máquina de nível 1 (portas lógicas); Nível 1 Composto por registrados e pela ALU
Sistema de Computação Máquinas multinível Nível 0 verdadeiro hardware da máquina, executando os programas em linguagem de máquina de nível 1 (portas lógicas); Nível 1 Composto por registrados e pela ALU
CPU - Significado CPU. Central Processing Unit. Unidade Central de Processamento
 CPU - Significado CPU Central Processing Unit Unidade Central de Processamento CPU - Função Na CPU são executadas as instruções Instrução: comando que define integralmente uma operação a ser executada
CPU - Significado CPU Central Processing Unit Unidade Central de Processamento CPU - Função Na CPU são executadas as instruções Instrução: comando que define integralmente uma operação a ser executada
Contil Informática. Curso Tecnico em Informatica Rafael Barros Sales Tecnologo em Redes de Computadores Tecnico em Informatica CREA/AC
 Contil Informática Curso Tecnico em Informatica Rafael Barros Sales Tecnologo em Redes de Computadores Tecnico em Informatica CREA/AC Processadores O processador é o cérebro do micro, encarregado de processar
Contil Informática Curso Tecnico em Informatica Rafael Barros Sales Tecnologo em Redes de Computadores Tecnico em Informatica CREA/AC Processadores O processador é o cérebro do micro, encarregado de processar
:: FERRAMENTAS MRP APLICADAS PDF ::
 :: FERRAMENTAS MRP APLICADAS PDF :: [Download] FERRAMENTAS MRP APLICADAS PDF FERRAMENTAS MRP APLICADAS PDF - Looking for Ferramentas Mrp Aplicadas Books? Now, you will be thankful that at this time Ferramentas
:: FERRAMENTAS MRP APLICADAS PDF :: [Download] FERRAMENTAS MRP APLICADAS PDF FERRAMENTAS MRP APLICADAS PDF - Looking for Ferramentas Mrp Aplicadas Books? Now, you will be thankful that at this time Ferramentas
NOTAS DE AULA Prof. Antonio Carlos Schneider Beck Filho (UFSM) Prof. Júlio Carlos Balzano de Mattos (UFPel) Arquitetura de Von Neumann
 Prof. Júlio Carlos Balzano de Mattos (UFPel) Arquitetura de Von Neumann") Universidade Federal de Santa Maria NOTAS DE AULA Prof. Antonio Carlos Schneider Beck Filho (UFSM) Prof. Júlio Carlos Balzano de Mattos (UFPel) Arquitetura de Von Neumann O modelo (ou arquitetura) de von
Universidade Federal de Santa Maria NOTAS DE AULA Prof. Antonio Carlos Schneider Beck Filho (UFSM) Prof. Júlio Carlos Balzano de Mattos (UFPel) Arquitetura de Von Neumann O modelo (ou arquitetura) de von
Memória cache. Prof. Francisco Adelton
 Memória cache Prof. Francisco Adelton Memória Cache Seu uso visa obter uma velocidade de acesso à memória próxima da velocidade das memórias mais rápidas e, ao mesmo tempo, disponibilizar no sistema uma
Memória cache Prof. Francisco Adelton Memória Cache Seu uso visa obter uma velocidade de acesso à memória próxima da velocidade das memórias mais rápidas e, ao mesmo tempo, disponibilizar no sistema uma
Arquiteturas RISC. (Reduced Instructions Set Computers)
") Arquiteturas RISC (Reduced Instructions Set Computers) 1 INOVAÇÕES DESDE O SURGIMENTO DO COMPU- TADOR DE PROGRAMA ARMAZENADO (1950)! O conceito de família: desacoplamento da arquitetura de uma máquina
Arquiteturas RISC (Reduced Instructions Set Computers) 1 INOVAÇÕES DESDE O SURGIMENTO DO COMPU- TADOR DE PROGRAMA ARMAZENADO (1950)! O conceito de família: desacoplamento da arquitetura de uma máquina
Processadores. Guilherme Pontes
 Processadores Guilherme Pontes Já sabemos o básico! Como já sabemos, o processador exerce uma das mais importantes funções do computador. Vamos agora nos aprofundar em especificações mais técnicas sobre
Processadores Guilherme Pontes Já sabemos o básico! Como já sabemos, o processador exerce uma das mais importantes funções do computador. Vamos agora nos aprofundar em especificações mais técnicas sobre
GUIÃO A. What about school? What s it like to be there/here? Have you got any foreign friends? How did you get to know them?
 GUIÃO A Prova construída pelos formandos e validada pelo GAVE, 1/7 Grupo: Chocolate Disciplina: Inglês, Nível de Continuação 11.º ano Domínio de Referência: Um Mundo de Muitas Culturas 1º Momento Intervenientes
GUIÃO A Prova construída pelos formandos e validada pelo GAVE, 1/7 Grupo: Chocolate Disciplina: Inglês, Nível de Continuação 11.º ano Domínio de Referência: Um Mundo de Muitas Culturas 1º Momento Intervenientes
 Gerência de Memória RAM em Computadores com Mais de 4GB O sistema Windows x86 (32bits) não tem capacidade de reconhecer, fisicamente, mais que 3,X GB de RAM, a não ser que seja ativado, manualmente, o
Gerência de Memória RAM em Computadores com Mais de 4GB O sistema Windows x86 (32bits) não tem capacidade de reconhecer, fisicamente, mais que 3,X GB de RAM, a não ser que seja ativado, manualmente, o
INSTITUTO DE EMPREGO E FORMAÇÃO PROFISSIONAL, I.P.
 INSTITUTO DE EMPREGO E FORMAÇÃO PROFISSIONAL, I.P. Centro de Emprego e Formação Profissional da Guarda Curso: Técnico de Informática Sistemas (EFA-S4A)-NS Trabalho Realizado Por: Igor_Saraiva nº 7 Com
INSTITUTO DE EMPREGO E FORMAÇÃO PROFISSIONAL, I.P. Centro de Emprego e Formação Profissional da Guarda Curso: Técnico de Informática Sistemas (EFA-S4A)-NS Trabalho Realizado Por: Igor_Saraiva nº 7 Com
Tabelas de Processadores INTEL
 Tabelas de Processadores INTEL Fonte: www.intel.com Atualização: setembro de 2008 Tabelas para consulta técnica de CPUs, analizando freqüência, modelo, código e dissipação de calor, etc. Por: José Luís
Tabelas de Processadores INTEL Fonte: www.intel.com Atualização: setembro de 2008 Tabelas para consulta técnica de CPUs, analizando freqüência, modelo, código e dissipação de calor, etc. Por: José Luís