Boas Maneiras Aprendizado Não Supervisionado Regressão
|
|
|
- Vítor de Sintra
- 5 Há anos
- Visualizações:
Transcrição
1 Universidade Federal do Paraná (UFPR) Especialização em Engenharia Industrial 4.0 Boas Maneiras Aprendizado Não Supervisionado Regressão David Menotti
2 Hoje Boas Maneiras Métricas de Avaliação & Téc. de Validação Avaliação & Comparação de Classificação Aprendizado não supervisionado (Clustering) k-means DBScan Regressão Linear ( e Múltipla ) Não-Linear ( Exponencial / Logística ) 2
3 Boas Maneiras Agenda Introdução Métricas de Avaliação Técnicas de Validação Avaliação de Classificadores Comparando Classificadores 3
4 Introdução Considere por exemplo, um problema de classificação binário com 99 exemplos na classe positiva e 1 exemplo na classe negativa. Considere que o classificador classificou corretamente todos os exemplos da classe positiva e errou somente o exemplo da classe negativa. Nesse caso temos uma acurácia de 99%. Atenção: Acurácia de um classificador nem sempre é a melhor medida para se avaliar um classificador, principalmente em problemas desbalanceados. 4
5 Avaliação Dado um classificador binário, as saídas possíveis são as seguintes: 5
6 Avaliação 6
7 Tipos de Erro Erro Tipo I (α-erro, falso positivo): Aceita-se como genuíno algo que é falso - FP Erro Tipo II (β-erro, falso negativo): Rejeita-se algo que deveria ter sido aceito - FN 7
8 Métricas FP Rate FP / N Precision (Pr) TP / ( TP + FP ) Tende a 1 se FP tende a 0 TP Rate ou hit rate TP / P Accuracy (TP + TN) / (P + N) P = TP + FN N = TN + FP Recall (R) (revogação) TPR = TP / ( TP + FN ) Tende a 1 se FN tende a 0 F-Measure 2 / ( 1 / Pr + 1 / R ) 2 Pr. R / (Pr + R) Média harmônica de Pr e R, tendo em vista que são grandezas inversamente proporcionais 8

9 Métricas No scikit-learn, essas métricas estão implementadas no método classification_report (classe metrics) 9
10 Métricas Espeficidade / Specificity TN / N Sensitividade / Sensitivity TP / P * Recall P = TP + FN N = TN + FP 10

11 Métricas Espeficidade / Specificity TN / N Sensibilidade / Sensibility TP / P * Recall P = TP + FN N = TN + FP 11
12 Técnicas de Validação Resubstitution Hold-out K-fold cross-validation LOOCV Random subsampling Bootstrapping 12
13 Resubstitution Se todos os dados forem usados para treinar o modelo e a taxa de erro for avaliada com base no resultado versus valor real do mesmo conjunto de dados de treinamento, esse erro será chamado de erro de resubstituição (resubstitution error validation). Por exemplo: Análise de Malware Aplicações onde necessitam de: Black list White list 13
14 Hold-out Para evitar o erro de resubstituição, os dados são divididos em dois conjuntos de dados diferentes rotulados como um conjunto de treinamento e de teste. A divisão pode ser: 60% / 40% ou 70% / 30% ou 80% / 20%, etc. Avaliar classificador em diferentes cenários: 5% de train? ou 90% de train? Muito provavelmente haverá distribuição desigual das classes (alvos/metas) nos conjunto de dados de treinamento e teste. os conjuntos de dados de treinamento e teste são criados com distribuição igual de diferentes classes de dados. Esse processo é chamado de estratificação. 14
15 K-fold cross-validation Nesta técnica, k-1 folds são usadas para treinamento e o restante (1 fold) é usado para teste. A vantagem é que todos os dados são usados para treinamento. Cada amostra é usada apenas uma vez para teste. A taxa de erro do modelo é a média Pode-se ver esta técnica como um hold-out repetido 15
16 Leave-One-Out Cross-Validation (LOOCV) Todos os dados, exceto um registro, são usados para treinamento Um registro é usado para teste. Processo é repetido por N vezes se houver registros N. A vantagem é que (N-1)/ são usados para treinamento Desvantagem: custo computacional: N rodadas 16
17 Random subsampling Amostras são escolhidos aleatoriamente para formar o test set. Os dados restantes formam o train set Bem utilizada na prática: pelo menos 30 execuções/rodadas 17

18 Bootstrapping Train set é selecionado aleatoriamente com substituição / repetição. Os exemplos restantes que não foram selecionados para treinamento são usados para teste. Diferente da validação cruzada de K-fold, é provável que o valor mude de fold para fold. 18
19 Avaliação de Classificadores 19
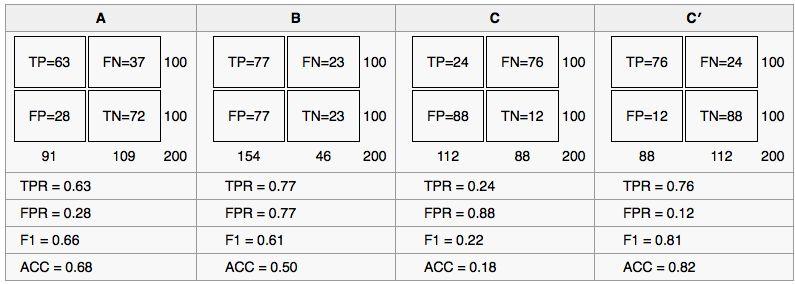
20 Exemplos de Classificadores 20
21 Espaço ROC ROC (Receiver Operating Characteristic) é uma representação gráfica que ilustra o desempenho de um classificador binário em um determinado ponto de operação. Classificadores do exemplo anterior no espaço ROC. 21
22 Curva ROC A curva ROC mostra todos os pontos de operação do classificador (relação entre TP e FP) Para cada ponto, existe um limiar associado. EER (Equal Error Rate): Ponto no gráfico no qual FPR é igual a 1-TPR Quando não existe um ponto operacional específico, usamos EER. 22
23 Curva ROC Considere 20 amostras, 10 classificadas corretamente (+) e 10 classificadas incorretamente (-) com suas respectivas probabilidades. 23
24 Curva ROC Exemplo Considere 20 amostras, 10 classificadas corretamente (+) e 10 classificadas incorretamente (-) com suas respectivas probabilidades. 24
25 Curva ROC Exemplo Após ordenar os dados usando as probabilidades, temos a seguinte curva ROC 25
26 Curva ROC Exemplo Suponha que a especificação do seu sistema diga que o máximo FPR permitido é de 10% Qual seria o ponto de operação do sistema (limiar)? [0,7 ; 0,54] Para esse limiar, qual seria a taxa de acerto do sistema? (Pos x TPR) + (Neg - (FPR x Neg) N 70% para um limiar de 0,54 26
27 Curva ROC Classes desbalanceadas Curvas ROC têm uma propriedade interessante: não são sensíveis a mudanças de distribuição das classes Se a proporção de instâncias negativas e positivas na base de teste muda, a curva continua a mesma. A curva é baseada em TP e FP. Isso permite uma fácil visualização do desempenho dos classificadores independentemente da distribuição das classes. 27
28 Comparando Classificadores Qual seria o melhor classificador? 28

29 AUC Area Under the Curve 29
30 Comparando Classificadores 30
31 Comparando Classificadores Suponha que você tenha dois classificadores que produziram as seguintes taxas de erro nos 10 folds de validação da sua base de dados. C1 = [10,15,7,6,13,11,12,9,17,14] e C2 = [17,14,12,16,23,18,10,8,19,22] O erro médio de C1 = 11,4% enquanto o erro médio de C2 = 15,9% Podemos afirmar que C1 é melhor do que o C2? A média é bastante sensível a outliers. O desempenho muito bom em um fold pode compensar o desempenho ruim em outro. 31
32 Comparando Classificadores Uma ferramenta bastante útil nesses casos é o teste de hipóteses. t-teste Requer que as diferenças entre as duas variáveis comparadas sejam distribuídas normalmente. Tamanho das amostras seja grande o suficiente (~30). A natureza do nosso problema não atende nenhum dos critério acima. Alternativa é o Wilcoxon signed-rank test 32
33 Wilcoxon Signed-Rank test Teste não paramétrico que ordena as diferenças de desempenho de dois classificadores, ignorando os sinais, e compara a posição das diferenças (positivas e negativa). O teste consiste em: Definir as hipóteses (H0 - Não existe diferença e H1 - Existe diferença) Calcular as estatísticas do teste Definir o nível de significância do teste ( α ) Rejeitar ou aceitar H0, comparando o valor da estatística calculada com o valor crítico tabelado. Nível de significância: Em aprendizagem de máquina, α = 0,05 é um valor bastante utilizado. Isso quer dizer que existe 5 chances em 100 da hipótese ser rejeitada quando deveria ter sido aceita, ou seja, uma probabilidade de erro de 0,05 = 5%. 33
34 Wilcoxon Signed-Rank test Considere o exemplo anterior dos classificadores C1 e C2 Estatísticas: N = 10, W+ = 6,5 (Soma das posições com sinal +) W+ = 48,5 (Soma das posições com sinal -) Comparar os valores das estatísticas calculadas com os valores tabelados. 34
35 Wilcoxon Signed-Rank test Comparar os valores das estatísticas calculadas (W+ = 6,5 e W- = 48,5) com os valores tabelados. Os valores críticos de W para N=10 e α = 0,05 são 8 e 47. Como os valores calculados estão fora do intervalo crítico, rejeita-se a hipótese que não há diferença (H0), ou seja, aceita-se H1 (existe diferença estatística entre os dois classificadores). 35
 Python Scipy (from scipy import")
36 Wilcoxon Signed-Rank test O teste de Wilcoxon pode ser encontrado em diversas ferramentas Matlab (signedrank) Python Scipy (from scipy import stats) 36
37 Wilcoxon Signed-Rank test Um teste não paramétrico utilizado para comparar diversos classificadores é o teste de Friedman Semelhante ao ANOVA 37
38 Aprendizado Não Supervisionado
39 Agenda Aprendizado não supervisionado Clustering Particionamento: k-means Densidade: DBScan 39
40 Aprendizagem Não Supervisionada Em problemas de aprendizagem supervisionada, contamos como a tupla [X,y], em que o objetivo é classificar y usando o vetor de características X. Na aprendizagem não supervisionada, temos somente o vetor X. Nesse caso, o objetivo é descobrir alguma coisa a respeito dos dados Por exemplo, como eles estão agrupados. Mais subjetiva que a aprendizagem supervisionada uma vez que não existe um objetivo simples como a classificação. Dados não rotulados: Obtenção de dados não rotulados não é custosa! 40
41 Noção de Grupos pode ser Ambígua 41
42 Clustering Refere-se a um conjunto de técnicas utilizada para encontrar grupos (ou clusters) em um conjunto de dados. Cluster: Uma coleção de objetos similares entre si e diferentes dos objetos pertencentes a outros clusters. Métodos de clustering podem ser divididos em: Particionamento Hierárquico Densidade 42
43 Particionamento k-means Separar os dados em um número pré-determinado de clusters k-means Clustering Algoritmo Entrada: k, dados (X) Saída: dados agrupados em k grupos Determinar os k centróides Atribuir a cada objeto do grupo o centróide mais próximo. Após atribuir um centróide a cada objeto, recalcular os centróides Repetir os passos 2 e 3 até que os centróides não sejam modificados 43
44 k-means Dados em duas dimensões 44
45 k-means Passo 1: Centróides definidos aleatoriamente 45
46 k-means Passo 2: Atribuir a cada objeto o centróide mais próximo 46
47 k-means Passo 3: Recalcular os centróides 47
48 k-means Obsevações Relativamente eficiente (escalável) Necessidade de definir o número de clusters a priori. Ineficiente para lidar com ruídos e/ou outliers. Todo ponto será atribuído a um cluster mesmo que ele não pertença a nenhum. Em alguns domínios de aplicação (detecção de anomalias) isso causa problemas. Inadequado para descobrir clusters com formato não convexo. 48
49 Métodos baseados em Densidade Diferentemente do k-means, os métodos baseados em densidade identificam regiões densas, permitindo a formação de clusters com diferentes formatos. Resistentes a presença de ruídos. Baseado no conceito de ε-vizinhança. Em um espaço bi-dimensional, a ε-vizinhança de um ponto p is o conjunto de pontos contido num círculo de raio ε, centrado em p. 49
")
50 ε-vizinhança Exemplo 100 pontos no intervalo [1,3] x [2,4] e p = (3,2) 50
51 ε-vizinhança Exemplo Vizinha de p com raio 0,5 (ε = 0,5) e 31 pontos de
 e apenas 3 vizinhos.")
52 ε-vizinhança Exemplo Vizinha de p com raio 0,15 (ε = 0,15) e apenas 3 vizinhos. 52
2 = π/4.")
53 Densidade Densidade = Massa / Volume Para o caso de ε = 0,15, temos o volume como a área do círculo, logo π(0,5)2 = π/4. Desta forma, massa/volume = 31 pontos / (π/4) 39,5 53
54 Densidade A ideia é usar o valor de densidade para agrupar aqueles pontos que possuem valores similares Identificar vizinhanças densas nas quais a maioria dos pontos está contida. Essa é a ideia do algoritmo DBSCAN 54

55 DBSCAN Possui dois parâmetros: ε: Raio da vizinhança MinPts: Número mínimo de pontos na vizinhança para definir um cluster. Com bases nesses dois parâmetros, DBSCAN classifica os pontos em três categorias: core point: Se a vizinhança de p com raio ε contém pelo menos MinPts. border point: Se a vizinhança de q com raio ε contém menos de MinPts, mas pode ser alcançado por um core point p. outlier: Nenhum dos casos acima. 55
56 DBSCAN Selecione um ponto aleatoriamente que não tenha sido atribuído a nenhum cluster e que não seja um outlier. Calcule sua ε-vizinhança e determine se ele é um core point. Se sim, comece um cluster ao redor desse ponto. Senão, rotule como outlier. 2. Depois de ter encontrado core point, expanda-o adicionando todos os pontos alcançáveis. 3. Repita os dois passos acima até que todos os pontos sejam atribuídos a um cluster ou sejam rotulados como outliers
57 DBSCAN Exemplo Outliers marcados em vermelho 57
58 Avaliação em Aprendizagem Não Supervisionada Diferentemente da aprendizagem supervisionada, na qual podemos utilizar diferentes métricas de avaliação objetivas, a avaliação em aprendizagem não supervisionada é mais subjetiva. Porque é importante avaliar clusters? Comparar algoritmos de clustering. Comparar clusters gerados por mais de um algoritmo. 58
 de cada cluster Di Erro2 Outliers podem afetar bastante os vetores médios.")
59 Avaliação em Aprendizagem Não Supervisionada O que é um bom cluster? x Coesão e separação. A média (centróide) de cada cluster Di Erro2 Outliers podem afetar bastante os vetores médios. 59
60 Avaliação em Aprendizagem Não Supervisionada A coesão (within-cluster) pode ser medida pela soma dos erros quadrados dentro de cada cluster A separação (between-cluster) é medida pela soma dos quadrados entre clusters Em que m é o vetor médio total (centróide geral) 60
61 Avaliação em Aprendizagem Não Supervisionada Coeficiente Silhouete O coeficiente Silhouette combina coesão e separação e pode ser calculado seguindo quatro passos: a. Para um dado objeto do cluster i, calcule a distância média (ai) para todos os outros objetos de i. b. Seja bi a menor distância média de i para todos os outros clusters, dos quais i não seja membro. c. d. O coeficiente sk para todos os objetos I numa partição de k clusters é dados por 61
 o que indica clusters")
62 Avaliação em Aprendizagem Não Supervisionada Coeficiente Silhouete Coesão e separação O valor do coeficiente pode variar entre -1 e 1. Um valor negativo não é desejável pois nesse caso o valor de ai seria maior do que bi É desejável que o coeficiente seja positivo ( ai < bi ) o que indica clusters compactos (ai próximo de zero). 62
63 Avaliação em Aprendizagem Não Supervisionada Coeficiente Silhouete 63
64 Avaliação em Aprendizagem Não Supervisionada Coeficiente Silhouete Prática comum: Utilize mais de um índice de clustering Voto entre os índices pode ser um bom indicativo de qual número de clusters você deve escolher. 64
65 Regressão
66 Agenda Regressão Correlação Análise de Regressão Linear Não-linear 66
67 Correlação Indica a força e a direção do relacionamento linear entre dois atributos. Trata-se de uma medida de relação entre dois atributos, embora correlação não implique causalidade Duas variáveis podem estar altamente correlacionadas e não existir relação de causa e efeito entre elas. Em muitas aplicações duas ou mais variáveis estão relacionadas, sendo necessário explorar a natureza desta relação Correlação muito próxima de 1 ou de -1 indica relação linear entre dois atributos. Nesse caso é possível ajustar um modelo que expresse tal relação Esse é o objetivo da análise de regressão. 67
68 Correlação 68
69 Análise da Regressão Objetivo: Determinar o modelo que expressa esta relação (modelo de regressão) a qual é ajustada aos dados Permite construir um modelo matemático que representa dois atributos ( x e y ) y = f(x), em que f(.) é a função que relaciona x e y x é a variável independente da equação y é a variável dependente das variações de $x$ 69

70 Análise da Regressão Esse modelo pode ser usado para predizer o valor de y para um dado valor de x Realizar previsões sobre um comportamento futuro de algum fenômeno da realidade. Extrapolar para o futuro relações de causa-efeito entre as variáveis, já observadas no passado. Cuidado com a extrapolação 70
71 Análise da Regressão A análise de regressão compreende dois tipos básicos: Linear Linear Múltipla Não Linear Modelos exponenciais Modelos logísticos 71
72 Regressão Linear Considera que a relação da resposta às variáveis é uma função linear de alguns parâmetros Modelos de regressão linear são frequentemente ajustados usando a abordagem dos mínimos quadrados. 72
73 Método dos Mínimos Quadrados Seja a equação da reta y = ax + b (ou y = α + β x) que modela a relação entre uma variável independente e uma variável dependente. Seja um conjunto de n pontos de dados conhecidos: O objetivo é encontrar os coeficientes a e b para o modelo que minimizem a medida de erro quadrático RSS (Residual Sum of Squares) 73
74 Regressão Linear 74

75 Método dos Mínimos Quadrados Os parâmetros da reta podem ser estimados através do conjunto de dados D usando as seguintes equações: 75





76 Método dos Mínimos Quadrados Exemplo Considere os dados da tabela abaixo. Encontre os coeficientes a e b e calcule a posição (y) no tempo x = 0,6 Da tabela acima temos, Usando as equações anteriores, temos a = 1,08 e b = 0,38 Desta forma, temos o modelo de regressão y = 1,08x + 0,38 76
77 Método dos Mínimos Quadrados Exemplo Respondendo a questão anterior, para x = 0,6, y = 1,02 77

78 Método dos Mínimos Quadrados Modelos de regressão linear não costumam ser válidos para fins de extrapolação, ou seja, predizer um valor fora do domínio dos dados 78

79 Análise de resíduos Como avaliar a qualidade do modelo? Os erros têm distribuição normal? Existem outliers' no conjunto de dados? O modelo gerado é adequado? Podemos responder essas perguntas analisando os resíduos, o qual é dado pela diferença entre o yi e sua estimativa ŷi 79

80 Análise de resíduos Outliers Construir um histograma de frequência dos resíduos Normalizar de modo a ter média zero e desvio 1 O histograma de resíduos deve ser semelhante a uma normal. 80
81 Análise de resíduos Outliers Se os erros tiverem uma distribuição normal, Aproximadamente, 95% dos resíduos estarão no intervalo de um desvio padrão da média Caso contrário, deve existir a presença de outlier, ou seja, valores atípicos ao restante dos dados. O que fazer com os outliers? 81

82 Coeficiente de Determinação ( R2 ) Uma forma de avaliar a qualidade de ajuste do modelo. Indica a quantidade de variabilidade dos dados que o modelo de regressão é capaz de explicar. Varia entre 0 e 1, indicando quanto o modelo consegue explicar os valores observados. 82


83 Coeficiente de Determinação ( R2 ) 83


84 Regressão Linear Exercício Programa exemplo de regressão usando scikit-learn: Linear Regression Example 84
85 Regressão Linear Exercício 85
86 Regressão Linear Múltipla A regressão múltipla funciona de forma parecida com a regressão simples Leva em consideração diversas variáveis de entrada xi, i = 1,..., p, influenciando ao mesmo tempo uma única variável de saída, y 86

87 Regressão Linear Múltipla Exemplo: A função de regressão na regressão múltipla é chamada de superfície de resposta Descreve um hiperplano no espaço p-dimensional das variáveis de entrada x 87

88 Regressão Linear Múltipla Como calcular a superfície de regressão? Usar o método dos mínimos quadrados como feito na regressão linear simples A diferença é que agora temos um elevado número de parâmetros na forma Solução: Expressar as operações matemáticas utilizando notação matricial 88

89 Regressão Não Linear Em alguns casos o modelo linear pode não ser o mais adequado. Muitas aplicações biológicas são modeladas por meio de relações não lineares. Por exemplo, padrões de crescimento podem seguir modelos: Exponenciais: onde a população aumenta sem limites Logísticos: onde a população cresce rapidamente no início, desacelera e se mantém estável. 89




90 Método dos Mínimos Quadrados Caso Exponencial O método dos mínimos quadrados pode ser facilmente adaptado para o caso exponencial, usando logaritmos neperianos. Nesse caso, A equação que modela a relação entre uma variável independente e uma variável dependente é dada por 90

91 Método dos Mínimos Quadrados Caso Exponencial Exemplo 91
92 Regressão Logística Exemplo Considere que alguém queira comprar uma casa e está na busca por um financiamento. Os bancos mantém para cada cliente um score, que varia de 300 a 850 Suponha que um dado cliente tem um score de 720 e gostaria de saber qual é a probabilidade de ter seu crédito aprovado pela instituição financeira. Esse cliente encontrou ainda dados de 1000 clientes com seus respectivos escores, que tiveram seus pedidos aprovados ou não. Notem que nesse caso a variável y é dicotômica Aprovado (1) Negado (0) 92

93 Regressão Logística Exemplo Note que a distribuição dos dados é diferente (binomial). O modelos de regressão vistos até então não funcionam nesse caso. Solução: Regressão Logística 93
94 Regressão Logística A regressão logística tem como objetivo: Modelar a probabilidade de um evento ocorrer dependendo dos valores das variáveis independentes. Estimar a probabilidade de um evento ocorrer (e também de não ocorrer) para uma dada observação. Pode ser usada como um classificador, atribuindo uma classe ao padrão de entrada. No nosso exemplo, crédito aprovado ou reprovado. 94
95 Regressão Logística A variável dependente na regressão logística segue a distribuição de Bernoulli. Distribuição discreta de espaço amostral {0,1} que tem probabilidade de sucesso p e falha q = 1 - p Na regressão logística estimamos p para qualquer combinação linear das variáveis independentes. 95
 MLE (Maximum Likehood Estimation) é usada para estimar os coeficiente do")
96 Regressão Logística Isso pode ser alcançado ajustando o seguinte modelo (função logística) MLE (Maximum Likehood Estimation) é usada para estimar os coeficiente do modelo. 96

97 Regressão Logística Esse modelo diz basicamente que a probabilidade de conseguir crédito sobre em função do score 97

98 Regressão Logística Exercício Programa exemplo de regressão usando scikit-learn: Logistic Function 98
99 Regressão Logística Exercício Programa exemplo de regressão usando scikit-learn: Logistic Function 99
100 100
101 Referências - J. Demsar, Statistical Comparisons of Classifiers over Multiple Data Sets, J. of M. Learning Research, 7:1-20, S. Salzberg, On Comparing Classifiers: Pitfalls to avoid and recommended approach, Data Mining and Knowledge Discovery, 1: , Luiz E. S. Oliveira, Avaliando Classificadores, Notas de Aulas, DInf / UFPR,
102 Referências Charrad et al., NbClust: An R Package for Determining the Relevant Number of Clusters in a Data Set, Journal of Statistical Software, 61, Luiz E. S. Oliviera, Aprendizado Não-supervisionado, Notas de Aulas, DInf / UFPR, Luiz E. S. Oliviera, Regressão, Notas de Aulas, DInf / UFPR,
103 Referências - Wikipedia, Sensitivity & Specificity - DZone - Ai Zone Machine Learning: Validation Techniques 103
Boas Maneiras em Aprendizado de Máquinas
 Universidade Federal do Paraná (UFPR) Bacharelado em Informática Biomédica Boas Maneiras em Aprendizado de Máquinas David Menotti www.inf.ufpr.br/menotti/ci171-182 Boas Maneiras Agenda Introdução Métricas
Universidade Federal do Paraná (UFPR) Bacharelado em Informática Biomédica Boas Maneiras em Aprendizado de Máquinas David Menotti www.inf.ufpr.br/menotti/ci171-182 Boas Maneiras Agenda Introdução Métricas
Universidade Federal do Paraná (UFPR) Bacharelado em Informática Biomédica. Regressão. David Menotti.
 Bacharelado em Informática Biomédica. Regressão. David Menotti.") Universidade Federal do Paraná (UFPR) Bacharelado em Informática Biomédica Regressão David Menotti www.inf.ufpr.br/menotti/ci171-182 Hoje Regressão Linear ( e Múltipla ) Não-Linear ( Exponencial / Logística
Universidade Federal do Paraná (UFPR) Bacharelado em Informática Biomédica Regressão David Menotti www.inf.ufpr.br/menotti/ci171-182 Hoje Regressão Linear ( e Múltipla ) Não-Linear ( Exponencial / Logística
Avaliando Hipóteses. George Darmiton da Cunha Cavalcanti Tsang Ing Ren CIn/UFPE
 Avaliando Hipóteses George Darmiton da Cunha Cavalcanti Tsang Ing Ren CIn/UFPE Pontos importantes Erro da Amostra e Erro Real Como Calcular Intervalo de Confiança Erros de hipóteses Estimadores Comparando
Avaliando Hipóteses George Darmiton da Cunha Cavalcanti Tsang Ing Ren CIn/UFPE Pontos importantes Erro da Amostra e Erro Real Como Calcular Intervalo de Confiança Erros de hipóteses Estimadores Comparando
Aula 9. Prof. Adilson Gonzaga
 Aula 9 Prof. Adilson Gonzaga Mapeamento Atribuir uma Instância a uma classe. Cada Instância é mapeada para um elemento do conjunto de Rótulos de Classe {p,n} p positivo n negativo Atribui uma Instância
Aula 9 Prof. Adilson Gonzaga Mapeamento Atribuir uma Instância a uma classe. Cada Instância é mapeada para um elemento do conjunto de Rótulos de Classe {p,n} p positivo n negativo Atribui uma Instância
Roteiro. PCC142 / BCC444 - Mineração de Dados Avaliação de Classicadores. Estimativa da Acurácia. Introdução. Estimativa da Acurácia
 Roteiro PCC142 / BCC444 - Mineração de Dados Avaliação de Classicadores Introdução Luiz Henrique de Campos Merschmann Departamento de Computação Universidade Federal de Ouro Preto luizhenrique@iceb.ufop.br
Roteiro PCC142 / BCC444 - Mineração de Dados Avaliação de Classicadores Introdução Luiz Henrique de Campos Merschmann Departamento de Computação Universidade Federal de Ouro Preto luizhenrique@iceb.ufop.br
Créditos. SCC0173 Mineração de Dados Biológicos. Aula de Hoje. Desempenho de Classificação. Classificação IV: Avaliação de Classificadores
 SCC0173 Mineração de Dados Biológicos Classificação IV: Avaliação de Classificadores Créditos O material a seguir consiste de adaptações e extensões dos originais: gentilmente cedidos pelo rof. André C..
SCC0173 Mineração de Dados Biológicos Classificação IV: Avaliação de Classificadores Créditos O material a seguir consiste de adaptações e extensões dos originais: gentilmente cedidos pelo rof. André C..
Aprendizado de Máquinas. Introdução à Aprendizado Não- Supervisionado
 Universidade Federal do Paraná (UFPR) Departamento de Informática (DInf) Aprendizado de Máquinas Introdução à Aprendizado Não- Supervisionado David Menotti, Ph.D. http://web.inf.ufpr.br/menotti Objetivos
Universidade Federal do Paraná (UFPR) Departamento de Informática (DInf) Aprendizado de Máquinas Introdução à Aprendizado Não- Supervisionado David Menotti, Ph.D. http://web.inf.ufpr.br/menotti Objetivos
Mineração de Dados em Biologia Molecular
 Mineração de Dados em Biologia Molecular André C.. L. F. de Carvalho Monitor: Valéria Carvalho lanejamento e Análise de Experimentos rincipais tópicos Estimativa do erro artição dos dados Reamostragem
Mineração de Dados em Biologia Molecular André C.. L. F. de Carvalho Monitor: Valéria Carvalho lanejamento e Análise de Experimentos rincipais tópicos Estimativa do erro artição dos dados Reamostragem
Curso de Data Mining
 Curso de Data Mining Sandra de Amo Curvas Roc Uma curva ROC (Receiver Operating Characteristic) é um enfoque gráfico que permite visualizar os trade-offs entre as taxas de positivos verdadeiros e positivos
Curso de Data Mining Sandra de Amo Curvas Roc Uma curva ROC (Receiver Operating Characteristic) é um enfoque gráfico que permite visualizar os trade-offs entre as taxas de positivos verdadeiros e positivos
DCBD. Avaliação de modelos. Métricas para avaliação de desempenho. Avaliação de modelos. Métricas para avaliação de desempenho...
 DCBD Métricas para avaliação de desempenho Como avaliar o desempenho de um modelo? Métodos para avaliação de desempenho Como obter estimativas confiáveis? Métodos para comparação de modelos Como comparar
DCBD Métricas para avaliação de desempenho Como avaliar o desempenho de um modelo? Métodos para avaliação de desempenho Como obter estimativas confiáveis? Métodos para comparação de modelos Como comparar
Regressão Linear. Fabrício Olivetti de França. Universidade Federal do ABC
 Regressão Linear Fabrício Olivetti de França Universidade Federal do ABC Tópicos 1. Overfitting 2. Treino e Validação 3. Baseline dos modelos 1 Overfitting Overfit Em muitos casos, a amostra de dados coletada
Regressão Linear Fabrício Olivetti de França Universidade Federal do ABC Tópicos 1. Overfitting 2. Treino e Validação 3. Baseline dos modelos 1 Overfitting Overfit Em muitos casos, a amostra de dados coletada
Universidade Federal do Paraná Departamento de Informática. Reconhecimento de Padrões. Tipos de Aprendizagem. Luiz Eduardo S. Oliveira, Ph.D.
 Universidade Federal do Paraná Departamento de Informática Reconhecimento de Padrões Tipos de Aprendizagem Luiz Eduardo S. Oliveira, Ph.D. http://lesoliveira.net Objetivos Introduzir diferentes tipos de
Universidade Federal do Paraná Departamento de Informática Reconhecimento de Padrões Tipos de Aprendizagem Luiz Eduardo S. Oliveira, Ph.D. http://lesoliveira.net Objetivos Introduzir diferentes tipos de
HP UFCG Analytics Abril-Maio Um curso sobre Reconhecimento de Padrões e Redes Neurais. Por Herman Martins Gomes.
 HP UFCG Analytics Abril-Maio 2012 Um curso sobre Reconhecimento de Padrões e Redes Neurais Por Herman Martins Gomes hmg@dsc.ufcg.edu.br Programa Visão Geral (2H) Reconhecimento Estatístico de Padrões (3H)
HP UFCG Analytics Abril-Maio 2012 Um curso sobre Reconhecimento de Padrões e Redes Neurais Por Herman Martins Gomes hmg@dsc.ufcg.edu.br Programa Visão Geral (2H) Reconhecimento Estatístico de Padrões (3H)
Universidade de São Paulo Instituto de Ciências Matemáticas e de Computação
 Universidade de São Paulo Instituto de Ciências Matemáticas e de Computação Francisco A. Rodrigues Departamento de Matemática Aplicada e Estatística - SME Conceitos básicos Classificação não-supervisionada:
Universidade de São Paulo Instituto de Ciências Matemáticas e de Computação Francisco A. Rodrigues Departamento de Matemática Aplicada e Estatística - SME Conceitos básicos Classificação não-supervisionada:
REGRESSÃO E CORRELAÇÃO
 REGRESSÃO E CORRELAÇÃO A interpretação moderna da regressão A análise de regressão diz respeito ao estudo da dependência de uma variável, a variável dependente, em relação a uma ou mais variáveis explanatórias,
REGRESSÃO E CORRELAÇÃO A interpretação moderna da regressão A análise de regressão diz respeito ao estudo da dependência de uma variável, a variável dependente, em relação a uma ou mais variáveis explanatórias,
AULA 09 Regressão. Ernesto F. L. Amaral. 17 de setembro de 2012
 1 AULA 09 Regressão Ernesto F. L. Amaral 17 de setembro de 2012 Faculdade de Filosofia e Ciências Humanas (FAFICH) Universidade Federal de Minas Gerais (UFMG) Fonte: Triola, Mario F. 2008. Introdução à
1 AULA 09 Regressão Ernesto F. L. Amaral 17 de setembro de 2012 Faculdade de Filosofia e Ciências Humanas (FAFICH) Universidade Federal de Minas Gerais (UFMG) Fonte: Triola, Mario F. 2008. Introdução à
Métodos de reamostragem
 Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Métodos de reamostragem Eduardo Vargas Ferreira Função custo 2 Função custo Matriz de confusão: é um layout de tabela que
Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Métodos de reamostragem Eduardo Vargas Ferreira Função custo 2 Função custo Matriz de confusão: é um layout de tabela que
Aprendizagem de Máquina
 Aprendizagem de Máquina Avaliação de Paradigmas Alessandro L. Koerich Mestrado/Doutorado em Informática Pontifícia Universidade Católica do Paraná (PUCPR) Mestrado/Doutorado em Informática Aprendizagem
Aprendizagem de Máquina Avaliação de Paradigmas Alessandro L. Koerich Mestrado/Doutorado em Informática Pontifícia Universidade Católica do Paraná (PUCPR) Mestrado/Doutorado em Informática Aprendizagem
Aprendizagem de Máquina
 Aprendizagem de Máquina Alessandro L. Koerich Programa de Pós-Graduação em Informática Pontifícia Universidade Católica do Paraná (PUCPR) Rejeição Introdução Em aplicações reais, sistemas de reconhecimento
Aprendizagem de Máquina Alessandro L. Koerich Programa de Pós-Graduação em Informática Pontifícia Universidade Católica do Paraná (PUCPR) Rejeição Introdução Em aplicações reais, sistemas de reconhecimento
Correlação e Regressão
 Correlação e Regressão Vamos começar com um exemplo: Temos abaixo uma amostra do tempo de serviço de 10 funcionários de uma companhia de seguros e o número de clientes que cada um possui. Será que existe
Correlação e Regressão Vamos começar com um exemplo: Temos abaixo uma amostra do tempo de serviço de 10 funcionários de uma companhia de seguros e o número de clientes que cada um possui. Será que existe
ANÁLISE DE BIG DATA E INTELIGÊNCIA ARTIFICIAL PARA A ÁREA MÉDICA
 CURTA DURAÇÃO ANÁLISE DE BIG DATA E INTELIGÊNCIA ARTIFICIAL PARA A ÁREA MÉDICA CARGA HORÁRIA: 80 horas COORDENAÇÃO: Prof.ª Dr.ª Alessandra de Ávila Montini OBJETIVOS Introduzir o conceito de Big Data,
CURTA DURAÇÃO ANÁLISE DE BIG DATA E INTELIGÊNCIA ARTIFICIAL PARA A ÁREA MÉDICA CARGA HORÁRIA: 80 horas COORDENAÇÃO: Prof.ª Dr.ª Alessandra de Ávila Montini OBJETIVOS Introduzir o conceito de Big Data,
Análise Multivariada Aplicada à Contabilidade
 Mestrado e Doutorado em Controladoria e Contabilidade Análise Multivariada Aplicada à Contabilidade Prof. Dr. Marcelo Botelho da Costa Moraes www.marcelobotelho.com mbotelho@usp.br Turma: 2º / 2016 1 Agenda
Mestrado e Doutorado em Controladoria e Contabilidade Análise Multivariada Aplicada à Contabilidade Prof. Dr. Marcelo Botelho da Costa Moraes www.marcelobotelho.com mbotelho@usp.br Turma: 2º / 2016 1 Agenda
Conceitos de Aprendizagem de Máquina e Experimentos. Visão Computacional
 Conceitos de Aprendizagem de Máquina e Experimentos Visão Computacional O que você vê? 2 Pergunta: Essa imagem tem um prédio? Classificação 3 Pergunta: Essa imagem possui carro(s)? Detecção de Objetos
Conceitos de Aprendizagem de Máquina e Experimentos Visão Computacional O que você vê? 2 Pergunta: Essa imagem tem um prédio? Classificação 3 Pergunta: Essa imagem possui carro(s)? Detecção de Objetos
Mais Informações sobre Itens do Relatório
 Mais Informações sobre Itens do Relatório Amostra Tabela contendo os valores amostrados a serem utilizados pelo método comparativo (estatística descritiva ou inferencial) Modelos Pesquisados Tabela contendo
Mais Informações sobre Itens do Relatório Amostra Tabela contendo os valores amostrados a serem utilizados pelo método comparativo (estatística descritiva ou inferencial) Modelos Pesquisados Tabela contendo
CÁLCULO NUMÉRICO. Profa. Dra. Yara de Souza Tadano
 CÁLCULO NUMÉRICO Profa. Dra. Yara de Souza Tadano yaratadano@utfpr.edu.br Aula 4 Ajuste de Curvas AJUSTE DE CURVAS Cálculo Numérico 3/55 Introdução Em geral, experimentos geram uma gama de dados que devem
CÁLCULO NUMÉRICO Profa. Dra. Yara de Souza Tadano yaratadano@utfpr.edu.br Aula 4 Ajuste de Curvas AJUSTE DE CURVAS Cálculo Numérico 3/55 Introdução Em geral, experimentos geram uma gama de dados que devem
Aula 2 Uma breve revisão sobre modelos lineares
 Aula Uma breve revisão sobre modelos lineares Processo de ajuste de um modelo de regressão O ajuste de modelos de regressão tem como principais objetivos descrever relações entre variáveis, estimar e testar
Aula Uma breve revisão sobre modelos lineares Processo de ajuste de um modelo de regressão O ajuste de modelos de regressão tem como principais objetivos descrever relações entre variáveis, estimar e testar
Universidade Federal do Paraná Departamento de Informática. Reconhecimento de Padrões. Segmentação. Luiz Eduardo S. Oliveira, Ph.D.
 Universidade Federal do Paraná Departamento de Informática Reconhecimento de Padrões Segmentação Luiz Eduardo S. Oliveira, Ph.D. http://lesoliveira.net Objetivos Introduzir os conceitos básicos de segmentação
Universidade Federal do Paraná Departamento de Informática Reconhecimento de Padrões Segmentação Luiz Eduardo S. Oliveira, Ph.D. http://lesoliveira.net Objetivos Introduzir os conceitos básicos de segmentação
UNIVERSIDADE DO ESTADO DE MATO GROSSO - UNEMAT. Faculdade de Ciências Exatas e Tecnológicas FACET / Sinop Curso de Bacharelado em Engenharia Elétrica
 REDES NEURAIS ARTIFICIAIS AULA 03 Prof. Dr. André A. P. Biscaro 1º Semestre de 2017 INTRODUÇÃO Aprendizagem é um processo pelo qual os parâmetros livres de uma rede neural são adaptados através de um processo
REDES NEURAIS ARTIFICIAIS AULA 03 Prof. Dr. André A. P. Biscaro 1º Semestre de 2017 INTRODUÇÃO Aprendizagem é um processo pelo qual os parâmetros livres de uma rede neural são adaptados através de um processo
Exame de Aprendizagem Automática
 Exame de Aprendizagem Automática 2 páginas com 11 perguntas e 3 folhas de resposta. Duração: 2 horas e 30 minutos DI, FCT/UNL, 5 de Janeiro de 2016 Nota: O exame está cotado para 40 valores. Os 20 valores
Exame de Aprendizagem Automática 2 páginas com 11 perguntas e 3 folhas de resposta. Duração: 2 horas e 30 minutos DI, FCT/UNL, 5 de Janeiro de 2016 Nota: O exame está cotado para 40 valores. Os 20 valores
Organização. 1. Introdução 2. Medidas de Similaridade. hierárquicos, de partição) 4. Critérios numéricos para definir o número de clusters
 4. Critérios numéricos para definir o número de clusters") Organização. Introdução 2. Medidas de Similaridade 3. Métodos de Agrupamento (métodos hierárquicos, de partição) 4. Critérios numéricos para definir o número de clusters Métodos de Partição Cada exemplo
Organização. Introdução 2. Medidas de Similaridade 3. Métodos de Agrupamento (métodos hierárquicos, de partição) 4. Critérios numéricos para definir o número de clusters Métodos de Partição Cada exemplo
Aprendizado por Instâncias Janelas de Parzen & Knn
 Universidade Federal do Paraná (UFPR) Especialização em Engenharia Industrial 4.0 Aprendizado por Instâncias Janelas de Parzen & Knn David Menotti www.inf.ufpr.br/menotti/ci171-182 Hoje Aprendizado por
Universidade Federal do Paraná (UFPR) Especialização em Engenharia Industrial 4.0 Aprendizado por Instâncias Janelas de Parzen & Knn David Menotti www.inf.ufpr.br/menotti/ci171-182 Hoje Aprendizado por
Aprendizagem de Máquina
 Aprendizagem de Máquina Modelos preditivos A tarefa de classificação Modelos Preditivos A tarefa de geração de um modelo preditivo consiste em aprender um mapeamento de entrada para a saída. Neste caso,
Aprendizagem de Máquina Modelos preditivos A tarefa de classificação Modelos Preditivos A tarefa de geração de um modelo preditivo consiste em aprender um mapeamento de entrada para a saída. Neste caso,
3.33pt. AIC Introdução
 1 3.33pt 1 Modelos Lineares Generalizados - Regressão Logística Erica Castilho Rodrigues 01 de Julho de 2016 2 3.33pt 3 Vamos ver um critério para comparação de modelos. É muito utilizado para vários tipos
1 3.33pt 1 Modelos Lineares Generalizados - Regressão Logística Erica Castilho Rodrigues 01 de Julho de 2016 2 3.33pt 3 Vamos ver um critério para comparação de modelos. É muito utilizado para vários tipos
Prof. Lorí Viali, Dr.
 Prof. Lorí Viali, Dr. viali@mat.ufrgs.br http://www.mat.ufrgs.br/~viali/ Em muitas situações duas ou mais variáveis estão relacionadas e surge então a necessidade de determinar a natureza deste relacionamento.
Prof. Lorí Viali, Dr. viali@mat.ufrgs.br http://www.mat.ufrgs.br/~viali/ Em muitas situações duas ou mais variáveis estão relacionadas e surge então a necessidade de determinar a natureza deste relacionamento.
Análise da Regressão. Prof. Dr. Alberto Franke (48)
") Análise da Regressão Prof. Dr. Alberto Franke (48) 91471041 O que é Análise da Regressão? Análise da regressão é uma metodologia estatística que utiliza a relação entre duas ou mais variáveis quantitativas
Análise da Regressão Prof. Dr. Alberto Franke (48) 91471041 O que é Análise da Regressão? Análise da regressão é uma metodologia estatística que utiliza a relação entre duas ou mais variáveis quantitativas
Inteligência Artificial. Raimundo Osvaldo Vieira [DComp IFMA Campus Monte Castelo]
![Inteligência Artificial. Raimundo Osvaldo Vieira [DComp IFMA Campus Monte Castelo]](/thumbs/73/68656289.jpg "Inteligência Artificial. Raimundo Osvaldo Vieira [DComp IFMA Campus Monte Castelo]") Inteligência Artificial Raimundo Osvaldo Vieira [DComp IFMA Campus Monte Castelo] Aprendizagem de Máquina Área da Inteligência Artificial cujo objetivo é o desenvolvimento de técnicas computacionais sobre
Inteligência Artificial Raimundo Osvaldo Vieira [DComp IFMA Campus Monte Castelo] Aprendizagem de Máquina Área da Inteligência Artificial cujo objetivo é o desenvolvimento de técnicas computacionais sobre
2COP229 Inteligência Computacional. Aula 3. Clusterização.
 Aula 3 Clusterização Sumário (Clusterização) - Introdução - Aprendizado Não Supervisionado - Aprendizado Supervisionado - Introdução: Clusterização - Etapas para o processo de Clusterização - Distância
Aula 3 Clusterização Sumário (Clusterização) - Introdução - Aprendizado Não Supervisionado - Aprendizado Supervisionado - Introdução: Clusterização - Etapas para o processo de Clusterização - Distância
Aprendizagem de Máquina - 2. Prof. Júlio Cesar Nievola PPGIa - PUCPR
 Aprendizagem de Máquina - 2 Prof. Júlio Cesar Nievola PPGIa - PUCPR Inteligência versus Aprendizado Aprendizado é a chave da superioridade da Inteligência Humana Para que uma máquina tenha Comportamento
Aprendizagem de Máquina - 2 Prof. Júlio Cesar Nievola PPGIa - PUCPR Inteligência versus Aprendizado Aprendizado é a chave da superioridade da Inteligência Humana Para que uma máquina tenha Comportamento
Redes Neurais e Sistemas Fuzzy
 Redes Neurais e Sistemas Fuzzy O ADALINE e o algoritmo LMS O ADALINE No contexto de classificação, o ADALINE [B. Widrow 1960] pode ser visto como um perceptron com algoritmo de treinamento baseado em minimização
Redes Neurais e Sistemas Fuzzy O ADALINE e o algoritmo LMS O ADALINE No contexto de classificação, o ADALINE [B. Widrow 1960] pode ser visto como um perceptron com algoritmo de treinamento baseado em minimização
Ajustar Técnica usada na análise dos dados para controlar ou considerar possíveis variáveis de confusão.
 Glossário Ajustar Técnica usada na análise dos dados para controlar ou considerar possíveis variáveis de confusão. Análise de co-variância: Procedimento estatístico utilizado para análise de dados que
Glossário Ajustar Técnica usada na análise dos dados para controlar ou considerar possíveis variáveis de confusão. Análise de co-variância: Procedimento estatístico utilizado para análise de dados que
AULA 07 Regressão. Ernesto F. L. Amaral. 05 de outubro de 2013
 1 AULA 07 Regressão Ernesto F. L. Amaral 05 de outubro de 2013 Centro de Pesquisas Quantitativas em Ciências Sociais (CPEQS) Faculdade de Filosofia e Ciências Humanas (FAFICH) Universidade Federal de Minas
1 AULA 07 Regressão Ernesto F. L. Amaral 05 de outubro de 2013 Centro de Pesquisas Quantitativas em Ciências Sociais (CPEQS) Faculdade de Filosofia e Ciências Humanas (FAFICH) Universidade Federal de Minas
PROVAS Ciência da Computação. 2 a Prova: 13/02/2014 (Quinta) Reavaliação: 20/02/2014 (Quinta)
 Reavaliação: 20/02/2014 (Quinta)") PROVAS Ciência da Computação 2 a Prova: 13/02/2014 (Quinta) Reavaliação: 20/02/2014 (Quinta) Ajuste de Curvas Objetivo Ajustar curvas pelo método dos mínimos quadrados 1 - INTRODUÇÃO Em geral, experimentos
PROVAS Ciência da Computação 2 a Prova: 13/02/2014 (Quinta) Reavaliação: 20/02/2014 (Quinta) Ajuste de Curvas Objetivo Ajustar curvas pelo método dos mínimos quadrados 1 - INTRODUÇÃO Em geral, experimentos
Classificadores Lineares
 Universidade Federal do Paraná (UFPR) Bacharelado em Informática Biomédica Classificadores Lineares David Menotti www.inf.ufpr.br/menotti/ci171-182 Hoje Funções Discriminantes Lineares Perceptron Support
Universidade Federal do Paraná (UFPR) Bacharelado em Informática Biomédica Classificadores Lineares David Menotti www.inf.ufpr.br/menotti/ci171-182 Hoje Funções Discriminantes Lineares Perceptron Support
Por que atributos irrelevantes são um problema Quais tipos de algoritmos de aprendizado são afetados Abordagens automáticas
 Por que atributos irrelevantes são um problema Quais tipos de algoritmos de aprendizado são afetados Abordagens automáticas Wrapper Filtros Muitos algoritmos de AM são projetados de modo a selecionar os
Por que atributos irrelevantes são um problema Quais tipos de algoritmos de aprendizado são afetados Abordagens automáticas Wrapper Filtros Muitos algoritmos de AM são projetados de modo a selecionar os
Descoberta de Conhecimento em Bancos de Dados - KDD
 Descoberta de Conhecimento em Bancos de Dados - KDD Professor: Rosalvo Ferreira de Oliveira Neto Disciplina: Inteligência Artificial Tópicos 1. Definições 2. Fases do processo 3. Exemplo do DMC 4. Avaliação
Descoberta de Conhecimento em Bancos de Dados - KDD Professor: Rosalvo Ferreira de Oliveira Neto Disciplina: Inteligência Artificial Tópicos 1. Definições 2. Fases do processo 3. Exemplo do DMC 4. Avaliação
Estatística Descritiva
 C E N T R O D E M A T E M Á T I C A, C O M P U T A Ç Ã O E C O G N I Ç Ã O UFABC Estatística Descritiva Centro de Matemática, Computação e Cognição March 17, 2013 Slide 1/52 1 Definições Básicas Estatística
C E N T R O D E M A T E M Á T I C A, C O M P U T A Ç Ã O E C O G N I Ç Ã O UFABC Estatística Descritiva Centro de Matemática, Computação e Cognição March 17, 2013 Slide 1/52 1 Definições Básicas Estatística
Reconhecimento de Padrões
 Reconhecimento de Padrões André Tavares da Silva andre.silva@udesc.br Duda e Hart Capítulo 1 Reconhecimento de Padrões (imagem) Objetivo: Interpretar um conjunto de dados através de um mapeamento (classificação)
Reconhecimento de Padrões André Tavares da Silva andre.silva@udesc.br Duda e Hart Capítulo 1 Reconhecimento de Padrões (imagem) Objetivo: Interpretar um conjunto de dados através de um mapeamento (classificação)
Análise de Regressão EST036
 Análise de Regressão EST036 Michel Helcias Montoril Instituto de Ciências Exatas Universidade Federal de Juiz de Fora Regressão sem intercepto; Formas alternativas do modelo de regressão Regressão sem
Análise de Regressão EST036 Michel Helcias Montoril Instituto de Ciências Exatas Universidade Federal de Juiz de Fora Regressão sem intercepto; Formas alternativas do modelo de regressão Regressão sem
Modelos Lineares Generalizados - Regressão Logística
 Modelos Lineares Generalizados - Regressão Logística Erica Castilho Rodrigues 26 de Maio de 2014 AIC 3 Vamos ver um critério para comparação de modelos. É muito utilizado para vários tipos de modelo. Mede
Modelos Lineares Generalizados - Regressão Logística Erica Castilho Rodrigues 26 de Maio de 2014 AIC 3 Vamos ver um critério para comparação de modelos. É muito utilizado para vários tipos de modelo. Mede
Delineamento e Análise Experimental Aula 4
 Aula 4 Castro Soares de Oliveira ANOVA Significativa Quando a aplicação da análise de variância conduz à rejeição da hipótese nula, temos evidência de que existem diferenças entre as médias populacionais.
Aula 4 Castro Soares de Oliveira ANOVA Significativa Quando a aplicação da análise de variância conduz à rejeição da hipótese nula, temos evidência de que existem diferenças entre as médias populacionais.
Análise de Regressão Linear Simples e
 Análise de Regressão Linear Simples e Múltipla Carla Henriques Departamento de Matemática Escola Superior de Tecnologia de Viseu Introdução A análise de regressão estuda o relacionamento entre uma variável
Análise de Regressão Linear Simples e Múltipla Carla Henriques Departamento de Matemática Escola Superior de Tecnologia de Viseu Introdução A análise de regressão estuda o relacionamento entre uma variável
Profs.: Eduardo Vargas Ferreira Walmes Marques Zeviani
 Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Regularização Profs.: Eduardo Vargas Ferreira Walmes Marques Zeviani Introdução: Regressão Linear Considere o exemplo referente
Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Regularização Profs.: Eduardo Vargas Ferreira Walmes Marques Zeviani Introdução: Regressão Linear Considere o exemplo referente
Disciplina de Modelos Lineares Professora Ariane Ferreira
 Disciplina de Modelos Lineares 2012-2 Regressão Logística Professora Ariane Ferreira O modelo de regressão logístico é semelhante ao modelo de regressão linear. No entanto, no modelo logístico a variável
Disciplina de Modelos Lineares 2012-2 Regressão Logística Professora Ariane Ferreira O modelo de regressão logístico é semelhante ao modelo de regressão linear. No entanto, no modelo logístico a variável
Classificação e Predição de Dados - Profits Consulting - Consultoria Empresarial - Serviços SAP- CRM Si
 Classificação e Predição de Dados - Profits Consulting - Consultoria Empresarial - Serviços SAP- CRM Si Classificação de Dados Os modelos de classificação de dados são preditivos, pois desempenham inferências
Classificação e Predição de Dados - Profits Consulting - Consultoria Empresarial - Serviços SAP- CRM Si Classificação de Dados Os modelos de classificação de dados são preditivos, pois desempenham inferências
Correlação e Regressão Linear
 Correlação e Regressão Linear Prof. Marcos Vinicius Pó Métodos Quantitativos para Ciências Sociais CORRELAÇÃO LINEAR Coeficiente de correlação linear r Mede o grau de relacionamento linear entre valores
Correlação e Regressão Linear Prof. Marcos Vinicius Pó Métodos Quantitativos para Ciências Sociais CORRELAÇÃO LINEAR Coeficiente de correlação linear r Mede o grau de relacionamento linear entre valores
Regressão linear simples
 Regressão linear simples Universidade Estadual de Santa Cruz Ivan Bezerra Allaman Introdução Foi visto na aula anterior que o coeficiente de correlação de Pearson é utilizado para mensurar o grau de associação
Regressão linear simples Universidade Estadual de Santa Cruz Ivan Bezerra Allaman Introdução Foi visto na aula anterior que o coeficiente de correlação de Pearson é utilizado para mensurar o grau de associação
2. Redes Neurais Artificiais
 Computação Bioinspirada - 5955010-1 2. Redes Neurais Artificiais Prof. Renato Tinós Depto. de Computação e Matemática (FFCLRP/USP) 1 2.4. Outras Redes Neurais Artificiais 2.4.1. Redes RBF 2.4.2. Mapas
Computação Bioinspirada - 5955010-1 2. Redes Neurais Artificiais Prof. Renato Tinós Depto. de Computação e Matemática (FFCLRP/USP) 1 2.4. Outras Redes Neurais Artificiais 2.4.1. Redes RBF 2.4.2. Mapas
Contabilometria. Aula 9 Regressão Linear Inferências e Grau de Ajustamento
 Contabilometria Aula 9 Regressão Linear Inferências e Grau de Ajustamento Interpretação do Intercepto e da Inclinação b 0 é o valor estimado da média de Y quando o valor de X é zero b 1 é a mudança estimada
Contabilometria Aula 9 Regressão Linear Inferências e Grau de Ajustamento Interpretação do Intercepto e da Inclinação b 0 é o valor estimado da média de Y quando o valor de X é zero b 1 é a mudança estimada
Métodos de Amostragem. Métodos de Amostragem e Avaliação de Algoritmos. Métodos de Amostragem. Métodos de Amostragem. Métodos de Amostragem
 e Avaliação de s José Augusto Baranauskas Departamento de Física e Matemática FFCLRP-USP AM é uma ferramenta poderosa, mas não existe um único algoritmo que apresente o melhor desempenho para todos os
e Avaliação de s José Augusto Baranauskas Departamento de Física e Matemática FFCLRP-USP AM é uma ferramenta poderosa, mas não existe um único algoritmo que apresente o melhor desempenho para todos os
9 Correlação e Regressão. 9-1 Aspectos Gerais 9-2 Correlação 9-3 Regressão 9-4 Intervalos de Variação e Predição 9-5 Regressão Múltipla
 9 Correlação e Regressão 9-1 Aspectos Gerais 9-2 Correlação 9-3 Regressão 9-4 Intervalos de Variação e Predição 9-5 Regressão Múltipla 1 9-1 Aspectos Gerais Dados Emparelhados há uma relação? se há, qual
9 Correlação e Regressão 9-1 Aspectos Gerais 9-2 Correlação 9-3 Regressão 9-4 Intervalos de Variação e Predição 9-5 Regressão Múltipla 1 9-1 Aspectos Gerais Dados Emparelhados há uma relação? se há, qual
2284-ELE/5, 3316-IE/3
 INTELIGÊNCIA ARTIFICIAL 2284-ELE/5, 3316-IE/3 Universidade da Beira Interior, Departamento de Informática Hugo Pedro Proença, 2007/2008 Aprendizagem Supervisionada 2 Os vários algoritmos de Aprendizagem
INTELIGÊNCIA ARTIFICIAL 2284-ELE/5, 3316-IE/3 Universidade da Beira Interior, Departamento de Informática Hugo Pedro Proença, 2007/2008 Aprendizagem Supervisionada 2 Os vários algoritmos de Aprendizagem
Inteligência nos Negócios (Business Inteligente)
") Inteligência nos Negócios (Business Inteligente) Sistemas de Informação Sistemas de Apoio a Decisão Aran Bey Tcholakian Morales, Dr. Eng. (Apostila 6) Fundamentação da disciplina Analise de dados Decisões
Inteligência nos Negócios (Business Inteligente) Sistemas de Informação Sistemas de Apoio a Decisão Aran Bey Tcholakian Morales, Dr. Eng. (Apostila 6) Fundamentação da disciplina Analise de dados Decisões
Métodos para Classificação: - Naïve Bayes.
 Métodos para Classificação: - 1R; - Naïve Bayes. Visão Geral: Simplicidade em primeiro lugar: 1R; Naïve Bayes. 2 Classificação: Tarefa: Dado um conjunto de exemplos préclassificados, construir um modelo
Métodos para Classificação: - 1R; - Naïve Bayes. Visão Geral: Simplicidade em primeiro lugar: 1R; Naïve Bayes. 2 Classificação: Tarefa: Dado um conjunto de exemplos préclassificados, construir um modelo
Classificação de dados em modelos com resposta binária via algoritmo boosting e regressão logística
 Classificação de dados em modelos com resposta binária via algoritmo boosting e regressão logística Gilberto Rodrigues Liska 1 5 Fortunato Silva de Menezes 2 5 Marcelo Ângelo Cirillo 3 5 Mario Javier Ferrua
Classificação de dados em modelos com resposta binária via algoritmo boosting e regressão logística Gilberto Rodrigues Liska 1 5 Fortunato Silva de Menezes 2 5 Marcelo Ângelo Cirillo 3 5 Mario Javier Ferrua
1. Avaliação de impacto de programas sociais: por que, para que e quando fazer? (Cap. 1 do livro) 2. Estatística e Planilhas Eletrônicas 3.
 2. Estatística e Planilhas Eletrônicas 3.") 1 1. Avaliação de impacto de programas sociais: por que, para que e quando fazer? (Cap. 1 do livro) 2. Estatística e Planilhas Eletrônicas 3. Modelo de Resultados Potenciais e Aleatorização (Cap. 2 e 3
1 1. Avaliação de impacto de programas sociais: por que, para que e quando fazer? (Cap. 1 do livro) 2. Estatística e Planilhas Eletrônicas 3. Modelo de Resultados Potenciais e Aleatorização (Cap. 2 e 3
SCC Capítulo 10 Métodos de Amostragem e Avaliação de Algoritmos
 Métodos de Amostragem e Avaliação de Algoritmos SCC-630 - Capítulo 10 Métodos de Amostragem e Avaliação de Algoritmos João Luís Garcia Rosa 1 1 Departamento de Ciências de Computação Instituto de Ciências
Métodos de Amostragem e Avaliação de Algoritmos SCC-630 - Capítulo 10 Métodos de Amostragem e Avaliação de Algoritmos João Luís Garcia Rosa 1 1 Departamento de Ciências de Computação Instituto de Ciências
Implementação de um sistema de validação estatística configurável de dados
 Implementação de um sistema de validação estatística configurável de dados Eduardo Dias Filho Supervisores: João Eduardo Ferreira e Pedro Losco Takecian 16 de novembro de 2014 Introdução Table of Contents
Implementação de um sistema de validação estatística configurável de dados Eduardo Dias Filho Supervisores: João Eduardo Ferreira e Pedro Losco Takecian 16 de novembro de 2014 Introdução Table of Contents
Aprendizado de Máquina (Machine Learning)
") Ciência da Computação (Machine Learning) Aula 01 Motivação, áreas de aplicação e fundamentos Max Pereira Nem todo conhecimento tem o mesmo valor. O que torna determinado conhecimento mais importante que
Ciência da Computação (Machine Learning) Aula 01 Motivação, áreas de aplicação e fundamentos Max Pereira Nem todo conhecimento tem o mesmo valor. O que torna determinado conhecimento mais importante que
Múltiplos Classificadores
 Universidade Federal do Paraná (UFPR) Bacharelado em Informátia Biomédica Múltiplos Classificadores David Menotti www.inf.ufpr.br/menotti/ci171-182 Hoje Múltiplos classificadores Combinação de classificadores
Universidade Federal do Paraná (UFPR) Bacharelado em Informátia Biomédica Múltiplos Classificadores David Menotti www.inf.ufpr.br/menotti/ci171-182 Hoje Múltiplos classificadores Combinação de classificadores
variável dependente natureza dicotômica ou binária independentes, tanto podem ser categóricas ou não estimar a probabilidade associada à ocorrência
 REGRESSÃO LOGÍSTICA É uma técnica recomendada para situações em que a variável dependente é de natureza dicotômica ou binária. Quanto às independentes, tanto podem ser categóricas ou não. A regressão logística
REGRESSÃO LOGÍSTICA É uma técnica recomendada para situações em que a variável dependente é de natureza dicotômica ou binária. Quanto às independentes, tanto podem ser categóricas ou não. A regressão logística
Mineração de Dados - II
 Tópicos Especiais: INTELIGÊNCIA DE NEGÓCIOS II Mineração de Dados - II Sylvio Barbon Junior barbon@uel.br 10 de julho de 2015 DC-UEL Sylvio Barbon Jr 1 Sumário Etapa II Algoritmos Básicos Weka: Framework
Tópicos Especiais: INTELIGÊNCIA DE NEGÓCIOS II Mineração de Dados - II Sylvio Barbon Junior barbon@uel.br 10 de julho de 2015 DC-UEL Sylvio Barbon Jr 1 Sumário Etapa II Algoritmos Básicos Weka: Framework
PÓS-GRADUAÇÃO ANÁLISE DE DATA MINING
 PÓS-GRADUAÇÃO ANÁLISE DE DATA MINING OBJETIVOS Na era da informação, as empresas capturam e armazenam muitos dados, e existe a real necessidade da aplicação de técnicas adequadas para a rápida tomada de
PÓS-GRADUAÇÃO ANÁLISE DE DATA MINING OBJETIVOS Na era da informação, as empresas capturam e armazenam muitos dados, e existe a real necessidade da aplicação de técnicas adequadas para a rápida tomada de
AULA 06 Correlação. Ernesto F. L. Amaral. 04 de outubro de 2013
 1 AULA 06 Correlação Ernesto F. L. Amaral 04 de outubro de 2013 Centro de Pesquisas Quantitativas em Ciências Sociais (CPEQS) Faculdade de Filosofia e Ciências Humanas (FAFICH) Universidade Federal de
1 AULA 06 Correlação Ernesto F. L. Amaral 04 de outubro de 2013 Centro de Pesquisas Quantitativas em Ciências Sociais (CPEQS) Faculdade de Filosofia e Ciências Humanas (FAFICH) Universidade Federal de
i j i i Y X X X i j i i i
 Mario de Andrade Lira Junior lira.pro.br\wordpress lira.pro.br\wordpress Diferença Regressão - equação ligando duas ou mais variáveis Correlação medida do grau de ligação entre duas variáveis Usos Regressão
Mario de Andrade Lira Junior lira.pro.br\wordpress lira.pro.br\wordpress Diferença Regressão - equação ligando duas ou mais variáveis Correlação medida do grau de ligação entre duas variáveis Usos Regressão
Regressão Linear. Prof. Dr. Leandro Balby Marinho. Análise de Dados II. Introdução Regressão Linear Regressão Múltipla
 Regressão Linear Prof. Dr. Leandro Balby Marinho Análise de Dados II Prof. Leandro Balby Marinho 1 / 36 UFCG DSC Roteiro 1. Introdução 2. Regressão Linear 3. Regressão Múltipla Prof. Leandro Balby Marinho
Regressão Linear Prof. Dr. Leandro Balby Marinho Análise de Dados II Prof. Leandro Balby Marinho 1 / 36 UFCG DSC Roteiro 1. Introdução 2. Regressão Linear 3. Regressão Múltipla Prof. Leandro Balby Marinho
SCC0173 Mineração de Dados Biológicos
 SCC0173 Mineração de Dados Biológicos Classificação I: Algoritmos 1Rule e KNN Prof. Ricardo J. G. B. Campello SCC / ICMC / USP 1 Créditos O material a seguir consiste de adaptações e extensões dos originais:
SCC0173 Mineração de Dados Biológicos Classificação I: Algoritmos 1Rule e KNN Prof. Ricardo J. G. B. Campello SCC / ICMC / USP 1 Créditos O material a seguir consiste de adaptações e extensões dos originais:
Rafael Izbicki 1 / 38
 Mineração de Dados Aula 7: Classificação Rafael Izbicki 1 / 38 Revisão Um problema de classificação é um problema de predição em que Y é qualitativo. Em um problema de classificação, é comum se usar R(g)
Mineração de Dados Aula 7: Classificação Rafael Izbicki 1 / 38 Revisão Um problema de classificação é um problema de predição em que Y é qualitativo. Em um problema de classificação, é comum se usar R(g)
Universidade Federal do Paraná Departamento de Informática. Reconhecimento de Padrões. Introdução
 Universidade Federal do Paraná Departamento de Informática Reconhecimento de Padrões Introdução Luiz Eduardo S. Oliveira, Ph.D. http://lesoliveira.net Objetivos Introduzir os conceito básicos de reconhecimento
Universidade Federal do Paraná Departamento de Informática Reconhecimento de Padrões Introdução Luiz Eduardo S. Oliveira, Ph.D. http://lesoliveira.net Objetivos Introduzir os conceito básicos de reconhecimento
APRENDIZAGEM DE MÁQUINA
 APRENDIZAGEM DE MÁQUINA (usando Python) Thiago Marzagão ÁRVORE DE DECISÃO & VALIDAÇÃO Thiago Marzagão APRENDIZAGEM DE MÁQUINA 1 / 20 árvore de decisão Aulas passadas: queríamos prever variáveis quantitativas.
APRENDIZAGEM DE MÁQUINA (usando Python) Thiago Marzagão ÁRVORE DE DECISÃO & VALIDAÇÃO Thiago Marzagão APRENDIZAGEM DE MÁQUINA 1 / 20 árvore de decisão Aulas passadas: queríamos prever variáveis quantitativas.
Estatística e Modelos Probabilísticos - COE241
 Estatística e Modelos Probabilísticos - COE241 Aula passada Variância amostral Método de Replicações Independentes Aula de hoje Para que serve a inferência estatística? Método dos Momentos Maximum Likehood
Estatística e Modelos Probabilísticos - COE241 Aula passada Variância amostral Método de Replicações Independentes Aula de hoje Para que serve a inferência estatística? Método dos Momentos Maximum Likehood
Aprendizado de Máquinas. Classificadores Lineares
 Universidade Federal do Paraná (UFPR) Departamento de Informática Aprendizado de Máquinas Classificadores Lineares David Menotti, Ph.D. web.inf.ufpr.br/menotti Objetivos Introduzir o conceito de classificação
Universidade Federal do Paraná (UFPR) Departamento de Informática Aprendizado de Máquinas Classificadores Lineares David Menotti, Ph.D. web.inf.ufpr.br/menotti Objetivos Introduzir o conceito de classificação
Redes Neurais e Sistemas Fuzzy
 Redes Neurais e Sistemas Fuzzy Redes de uma única camada O Perceptron elementar Classificação de padrões por um perceptron A tarefa de classificação consiste em aprender a atribuir rótulos a dados que
Redes Neurais e Sistemas Fuzzy Redes de uma única camada O Perceptron elementar Classificação de padrões por um perceptron A tarefa de classificação consiste em aprender a atribuir rótulos a dados que
Regression and Clinical prediction models
 Regression and Clinical prediction models Session 6 Introducing statistical modeling Part 2 (Correlation and Linear regression) Pedro E A A do Brasil pedro.brasil@ini.fiocruz.br 2018 Objetivos Continuar
Regression and Clinical prediction models Session 6 Introducing statistical modeling Part 2 (Correlation and Linear regression) Pedro E A A do Brasil pedro.brasil@ini.fiocruz.br 2018 Objetivos Continuar
INF 1771 Inteligência Artificial
 Edirlei Soares de Lima INF 1771 Inteligência Artificial Aula 18 Aprendizado Não-Supervisionado Formas de Aprendizado Aprendizado Supervisionado Árvores de Decisão. K-Nearest Neighbor
Edirlei Soares de Lima INF 1771 Inteligência Artificial Aula 18 Aprendizado Não-Supervisionado Formas de Aprendizado Aprendizado Supervisionado Árvores de Decisão. K-Nearest Neighbor
SCC Capítulo 10 Métodos de Amostragem e Avaliação de Algoritmos
 Métodos de Amostragem e Avaliação de Algoritmos SCC-630 - Capítulo 10 Métodos de Amostragem e Avaliação de Algoritmos João Luís Garcia Rosa 1 1 Departamento de Ciências de Computação Instituto de Ciências
Métodos de Amostragem e Avaliação de Algoritmos SCC-630 - Capítulo 10 Métodos de Amostragem e Avaliação de Algoritmos João Luís Garcia Rosa 1 1 Departamento de Ciências de Computação Instituto de Ciências
Virgílio A. F. Almeida DCC-UFMG 2005
 Virgílio A. F. Almeida DCC-UFMG 005 O que é um bom modelo? Como estimar os parâmetros do modelo Como alocar variações Intervalos de Confiança para Regressões Inspeção Visual ! "# Para dados correlacionados,
Virgílio A. F. Almeida DCC-UFMG 005 O que é um bom modelo? Como estimar os parâmetros do modelo Como alocar variações Intervalos de Confiança para Regressões Inspeção Visual ! "# Para dados correlacionados,
Redes Neurais (Inteligência Artificial)
") Redes Neurais (Inteligência Artificial) Aula 16 Aprendizado Não-Supervisionado Edirlei Soares de Lima Formas de Aprendizado Aprendizado Supervisionado Árvores de Decisão. K-Nearest
Redes Neurais (Inteligência Artificial) Aula 16 Aprendizado Não-Supervisionado Edirlei Soares de Lima Formas de Aprendizado Aprendizado Supervisionado Árvores de Decisão. K-Nearest
Análise de Regressão Prof. MSc. Danilo Scorzoni Ré FMU Estatística Aplicada
 Aula 2 Regressão Linear Simples Análise de Regressão Prof. MSc. Danilo Scorzoni Ré FMU Estatística Aplicada Conceitos Gerais A análise de regressão é utilizada para explicar ou modelar a relação entre
Aula 2 Regressão Linear Simples Análise de Regressão Prof. MSc. Danilo Scorzoni Ré FMU Estatística Aplicada Conceitos Gerais A análise de regressão é utilizada para explicar ou modelar a relação entre
à Análise de Padrões
 CC-226 Introdução à Análise de Padrões Prof. Carlos Henrique Q. Forster Visão Geral do Curso e Introdução a Classificadores Padrões São apresentados como tuplas de variáveis aleatórias O conjunto amostra
CC-226 Introdução à Análise de Padrões Prof. Carlos Henrique Q. Forster Visão Geral do Curso e Introdução a Classificadores Padrões São apresentados como tuplas de variáveis aleatórias O conjunto amostra
Aprendizado de Máquina (Machine Learning)
") Ciência da Computação Aprendizado de Máquina (Machine Learning) Aula 09 Árvores de Decisão Max Pereira Classificação É a tarefa de organizar objetos em uma entre diversas categorias pré-definidas. Exemplos
Ciência da Computação Aprendizado de Máquina (Machine Learning) Aula 09 Árvores de Decisão Max Pereira Classificação É a tarefa de organizar objetos em uma entre diversas categorias pré-definidas. Exemplos
Aprendizado de Máquina (Machine Learning)
") Ciência da Computação (Machine Learning) Aula 07 Classificação com o algoritmo knn Max Pereira Classificação com o algoritmo k-nearest Neighbors (knn) Como os filmes são categorizados em gêneros? O que
Ciência da Computação (Machine Learning) Aula 07 Classificação com o algoritmo knn Max Pereira Classificação com o algoritmo k-nearest Neighbors (knn) Como os filmes são categorizados em gêneros? O que
Variância pop. * conhecida Teste t Paramétrico Quantitativa Distribuição normal Wilcoxon (teste dos sinais, Wilcoxon p/ 1 amostra)
") Testes de Tendência Central (média, mediana, proporção) Classificação Variável 1 Variável 2 Núm ero Gru pos Dependência Teste Z Paramétrico Quantitativa - 1 - Premissas Variância pop. * conhecida Teste
Testes de Tendência Central (média, mediana, proporção) Classificação Variável 1 Variável 2 Núm ero Gru pos Dependência Teste Z Paramétrico Quantitativa - 1 - Premissas Variância pop. * conhecida Teste
REGRESSÃO LINEAR SIMPLES E MÚLTIPLA
 REGRESSÃO LINEAR SIMPLES E MÚLTIPLA Curso: Agronomia Matéria: Metodologia e Estatística Experimental Docente: José Cláudio Faria Discente: Michelle Alcântara e João Nascimento UNIVERSIDADE ESTADUAL DE
REGRESSÃO LINEAR SIMPLES E MÚLTIPLA Curso: Agronomia Matéria: Metodologia e Estatística Experimental Docente: José Cláudio Faria Discente: Michelle Alcântara e João Nascimento UNIVERSIDADE ESTADUAL DE
Esse material foi extraído de Barbetta (2007 cap 13)
") Esse material foi extraído de Barbetta (2007 cap 13) - Predizer valores de uma variável dependente (Y) em função de uma variável independente (X). - Conhecer o quanto variações de X podem afetar Y. Exemplos
Esse material foi extraído de Barbetta (2007 cap 13) - Predizer valores de uma variável dependente (Y) em função de uma variável independente (X). - Conhecer o quanto variações de X podem afetar Y. Exemplos
Inteligência Artificial
 Inteligência Artificial Aula 14 Aprendizado de Máquina Avaliação de s Preditivos (Classificação) Hold-out K-fold Leave-one-out Prof. Ricardo M. Marcacini ricardo.marcacini@ufms.br Curso: Sistemas de Informação
Inteligência Artificial Aula 14 Aprendizado de Máquina Avaliação de s Preditivos (Classificação) Hold-out K-fold Leave-one-out Prof. Ricardo M. Marcacini ricardo.marcacini@ufms.br Curso: Sistemas de Informação
Conceitos centrais em análise de dados
 Conceitos centrais em análise de dados Conceitos básicos em Estatística Estatística Ciência que tem por objetivo orientar a coleta, o resumo, a apresentação, a análise e a interpretação dos dados. Divide-se
Conceitos centrais em análise de dados Conceitos básicos em Estatística Estatística Ciência que tem por objetivo orientar a coleta, o resumo, a apresentação, a análise e a interpretação dos dados. Divide-se
1 Que é Estatística?, 1. 2 Séries Estatísticas, 9. 3 Medidas Descritivas, 27
 Prefácio, xiii 1 Que é Estatística?, 1 1.1 Introdução, 1 1.2 Desenvolvimento da estatística, 1 1.2.1 Estatística descritiva, 2 1.2.2 Estatística inferencial, 2 1.3 Sobre os softwares estatísticos, 2 1.4
Prefácio, xiii 1 Que é Estatística?, 1 1.1 Introdução, 1 1.2 Desenvolvimento da estatística, 1 1.2.1 Estatística descritiva, 2 1.2.2 Estatística inferencial, 2 1.3 Sobre os softwares estatísticos, 2 1.4
ESTATÍSTICA EXPERIMENTAL. ANOVA. Aula 05
 ESTATÍSTICA EXPERIMENTAL ANOVA. Aula 05 Introdução A ANOVA ou Análise de Variância é um procedimento usado para comparar a distribuição de três ou mais grupos em amostras independentes. A análise de variância
ESTATÍSTICA EXPERIMENTAL ANOVA. Aula 05 Introdução A ANOVA ou Análise de Variância é um procedimento usado para comparar a distribuição de três ou mais grupos em amostras independentes. A análise de variância
Instituto Nacional de Pesquisas Espaciais - INPE. Divisão de Processamento de Imagens - DPI
 1 Sumário 2 Introdução Técnicas de ESDA Matrizes de Proximidade Espacial Média Espacial Móvel (m i ) Indicadores Globais de Autocorrelação Espacial Índices Globais de Moran (I), Geary (C) e Getis e Ord
1 Sumário 2 Introdução Técnicas de ESDA Matrizes de Proximidade Espacial Média Espacial Móvel (m i ) Indicadores Globais de Autocorrelação Espacial Índices Globais de Moran (I), Geary (C) e Getis e Ord