Aula 9. Prof. Adilson Gonzaga
|
|
|
- Júlio César Schmidt Vidal
- 6 Há anos
- Visualizações:
Transcrição
1 Aula 9 Prof. Adilson Gonzaga

2 Mapeamento Atribuir uma Instância a uma classe. Cada Instância é mapeada para um elemento do conjunto de Rótulos de Classe {p,n} p positivo n negativo
3 Atribui uma Instância a uma classe.
4 Classificador Discreto Atribui a classe diretamente. Classificador Contínuo Atribui uma probabilidade do elemento ser membro de uma Classe. Um Threshold determina a Classe.

5 Saída: Positivo O classificador classifica a amostra como pertencente à classe. Saída: Negativo O classificador classifica a amostra como não pertencente à classe.
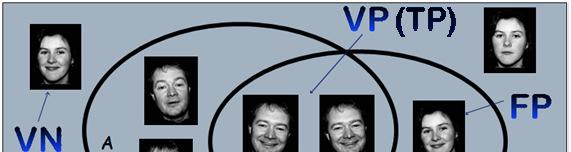
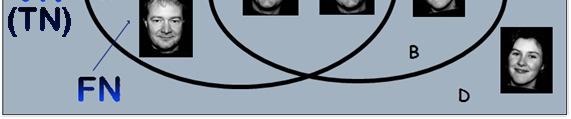
6 VP(TP) VERDADEIRO POSITIVO (TruePositive, Hit) O elemento de entrada é Genuíno (Positivo) e o Classificador o classifica como Positivo. VN (TN) VERDADEIRO NEGATIVO (True Negative, Correct Rejection) O elemento de entrada é Impostor (Negativo) e o Classificador o classifica como Negativo. FP FALSO POSITIVO (FalsePositive, FalseAlarm, TypeI error) O elemento de entrada é Impostor (Negativo) e o Classificador o classifica como Positivo. FN FALSO NEGATIVO (FalseNegative, TypeII error) O elemento de entrada é Genuíno (Positivo) e o classificador o classifica como Negativo.
7 TG Total de Genuínos (Total de elementos de uma classe) TI Total de Impostores TSP Total de Saídas Positivas TSN Total de Saídas Negativas TCC Total de Classificações Corretas TCI Total de Classificações Incorretas TS Total de Saídas. Total de elementos classificados
8 SENSIBILIDADE: Proporção de Verdadeiros Positivos classificados corretamente como Genuínos (True Positive Rate -TPR, Hit Rate, Recall). Proporção de Genuínos de uma classe que foram classificados como Genuínos.
9 RAZÃO DE FALSOS POSITIVOS: Proporção de Falsos Positivos classificados relativamente ao Total de Impostores Existentes (False Positive Rate - FPR, False AlarmRate, Fall-out). Proporção de Impostores erroneamente classificados como Genuínos.
10 RAZÃO DE FALSOS NEGATIVOS: Proporção de Falsos Negativos classificados relativamente ao Total de Genuínos Existentes( FalseNegativeRate - FNR). Proporção de amostras Genuínas erroneamente classificadas como Impostoras.
11 ESPECIFICIDADE: Proporção de Verdadeiros Negativos classificados corretamente como Impostores (True Negative Rate - TNR) Proporção de Impostores que foram classificados como Impostores.
12 VALOR PREVISTO DA SAÍDA POSITIVA (PRECISÃO): Proporção de Verdadeiros Positivos classificados. VALOR PREVISTO DA SAÍDA NEGATIVA: Proporção de Verdadeiros Negativos classificados.
13 ACURÁCIA (EXATIDÃO): Proporção de Classificações Corretas para o total de elementos classificados (Genuínos e Impostores). ERRO: Proporção de Classificações Incorretas para o total de elementos (Genuínos e Impostores). Err= 1 -A


14 O conjunto A é uma classe, ou melhor, o Total de Genuínos TG = 4 O conjunto D é o conjunto dos Impostores, ou seja, o Total de Impostores TI = 4 O conjunto B é o conjunto de elementos mais semelhantes retornados pelo classificador, ou seja, O Total de Saídas Positivas TSP=3
15
16 Se o Classificador tiver um alto valor para Falsos Negativos (FN), ele não classifica corretamente quem deveria ser classificado, ou seja, sua SENSIBILIDADE é baixa. Se o Classificador tiver um alto valor de Falsos Positivos (FP), ele classifica elementos que não deveriam ser classificados, ou seja, sua ESPECIFICIDADE e sua PRECISÃO são baixas.
17 Avaliação de Classificadores
18 ROC (Receiver Operating Characteristics) é uma técnica para visualizar, organizar e selecionar classificadores baseado em seus desempenhos. Teoria de Detecção de Sinais Visualisaçãoe Análise do comportamento em sistemas de auxílio ao diagnóstico. Avaliação e comparação de Algoritmos.
19 Expressa a relação entre Benefício (TP) e Custo (FP) de um Classificador. Um Classificador Discreto gera como saída apenas um Rótulo de Classe dado pelo par (FPR,TPR) (FalsePositive Rate, True Positive Rate) (0,1) Classificador perfeito. Nenhum Falso Positivo e todos os Verdadeiros Positivos são classificados. (x,0) Pior caso O classificador não apresenta nenhum Verdadeiro Positivo. Em (0,0) o classificador não apresenta nenhuma saída...
20 Classificador Liberal: Boa classificação de Verdadeiros Positivos, mas, com muitos Falsos Positivos. Classificador Conservador: Boa classificação de Verdadeiros Positivos e com poucos Falsos Positivos. Classificador Aleatório (RandomGuessing) : Apresenta resultados sobre a Diagonal do Espaço ROC (Na figura, o Classificador B). Não tem nenhuma informação sobre a Classe. O Classificador não discrimina as Classes. Classificador Invertido: Apresenta resultados abaixo da Diagonal do Espaço ROC (Classificador C). Contém informação sobre a Classe, mas de forma errada. Se a saída for Negada, o ponto passa para a metade superior do Espaço ROC (Classificador C ).


21 Quanto menor for o threshold mais elementos são classificados como Genuínos, o Classificador é mais tolerante ou Liberal. Quanto maior for o threshold menos elementos são classificados como Genuínos, o Classificador é mais rígido ou Conservador.
22 Variando-se o raio r q (threshold) classificam-se como mais semelhantes (Classificados como Genuínos TP + FP) ao elemento O q os Elementos mais próximos a O q, ou seja, os que estão dentro do círculo definido pelo raio r q. Quanto maior for o raio (menor é o threshold), mais elementos são classificados como Genuínos, o Classificador é mais tolerante ou Liberal. Quanto menor for o raio (maior é o threshold), menos elementos são classificados como Genuínos, o Classificador é mais rígido ou Conservador.
23 1) Se o Classificador não consegue discriminar entre Impostores e Genuínos, qualquer ponto cai sobre a diagonal da Curva ROC (Random Guessing).


24 2) Quanto mais discriminante é o Classificador, mais afastadas são as distribuições e a Curva ROC afasta-se da diagonal.
 e Falsos Negativos (FN). Calcula-se a TPR (TruePositive Rate) e a FPR (False Positive Rate) e constrói-se a Curva ROC.")
25 3) Para cada threshold, calcula-se a quantidade de Verdadeiros Positivos (TP), Falsos Positivos (FP), Verdadeiros Negativos (TN) e Falsos Negativos (FN). Calcula-se a TPR (TruePositive Rate) e a FPR (False Positive Rate) e constrói-se a Curva ROC.
26 O cálculo da área sob a curva ROC (AUC) permite comparar classificadores. O pior caso é AUC=0,5 para o Classificador Aleatório (RandomGuessing). Quanto melhor o classificador AUC 1.
 ou FalseMatch Rate (FMR) é a Razão de Falsos Positivos (FPR), ou melhor, a Probabilidade de ocorrência de Erro do Tipo I.")
27 A área de Biometria costuma gerar a curva ROC considerando a Taxa de Falsa Aceitação (FalseAccepting Rate - FAR) versus a Taxa de Falsa Rejeição (FalseRejectionRate - FRR) de um sistema Biométrico. A Taxa de Falsa Aceitação (FAR) ou FalseMatch Rate (FMR) é a Razão de Falsos Positivos (FPR), ou melhor, a Probabilidade de ocorrência de Erro do Tipo I. Erro do Tipo I é o Erro de Falsos Positivos, ou melhor, é o erro por excesso de Credulidade. FAR=FMR=FPR É a probabilidade do classificador aceitar Impostores como se fossem Genuínos.

28 A Taxa de Falsa Rejeição (FRR) ou FalseNon-Match Rate (FNMR) é a Razão de Falsos Negativos, ou melhor, a Probabilidade de ocorrência de Erro do Tipo II. Erro do Tipo II é o Erro de Falsos Negativos, ou melhor, é o erro por excesso de Ceticismo. FRR=FNMR=FNR É a probabilidade do classificador rejeitar Genuínos como se fossem Impostores.
29 EER = Equal ErrorRate denota o valor do threshold onde FNMR=FMR, ou seja, a quantidade de Falsos Positivos é igual à de Falsos Negativos (FPR=FNR). Quanto menor for EER, ou seja, mais próximo da origem estará a curva ROC, melhor será o classificador Biométrico.
30
31 Os K elementos mais semelhantes ao elemento O q, são classificados como Genuínos (TP + FP). Variando-se o valor de K (threshold), controla-se o número de Genuínos classificados. Quanto menor o valor de K (maior threshold) mais rígido, ou Conservador, é o classificador e quanto maior é o valor de K, mais elementos são classificados como Genuínos (menor é o threshold) e o classificador é dito mais tolerante ou Liberal.
32 Avaliação de classificadores baseado na Relevância.
33 A Uma Classe de Elementos. (Genuínos) Verdadeiros Negativos D B K-NN K elementos mais similares. (Total de Saídas Positivas)


34 Recall: Probabilidade de uma Amostra relevante ser recuperada. recall = A B TP = A TP + FN precision = A B B = TP TP + FP Precision: Probabilidade de uma Amostra recuperada ser relevante


35 Seja A = a classe de Elementos representada pelas imagens: Figura 1 Figura 2 Figura 3 Figura 4 A E o conjunto de Imagens da Base = 8 Elementos
36 Seja a imagem a ser classificada (Imagem de busca) a Figura 1: Para K=1, ou seja, a 1ª imagem mais similar à Figura 1, retornada é: B
: recall")
 = = =")
37 Para K=1, o classificador retornou uma imagem mais similar (conjunto B): recall A B TP TP + FN 1 4 ( 1 ) = = = = 0, 25 A precision A B TP TP + FP 1 1 ( 1 ) = = = = 1 B
:")
 =")
38 Para K=2, o classificador retornou duas imagens mais similares (conjunto B): recall A B TP TP + FN ( 2 ) = = = = 0, 50 A 2 4 precision A B TP TP + FP 2 2 ( 2 ) = = = = 1 B
: recall")
 = = = = 0,")
39 Para K=3, o classificador retornou três imagens mais similares (conjunto B): recall A B TP TP + FN ( 3 ) = = = = 0, 50 A 2 4 precision A B TP TP + FP ( 3 ) = = = = 0, 67 B 2 3
: recall")
 = = = = 0, 75")
40 Para K= 4, o classificador retornou quatro imagens mais similares (conjunto B): recall A B TP TP + FN ( 4 ) = = = = 0, 75 A 3 4 precision A B TP TP + FP ( 4 ) = = = = 0, 75 B 3 4
41 Busca K=1 K=2 K=3 K=4 Recall Precision Recall Precision Recall Precision Recall Precision Fig. 1 0,25 1,00 0,50 1,00 0,50 0,67 0,75 0,75 Fig. 2 0,25 1,00 0,50 1,00 0,75 1,00 1,00 1,00 Fig. 3 0,25 1,00 0,50 1,00 0,75 1,00 0,75 0,75 Fig. 4 0,25 1,00 0,50 1,00 0,50 0,67 0,75 0,75 Fig. 5 0,25 1,00 0,50 1,00 0,75 1,00 1,00 1,00 Fig. 6 0,25 1,00 0,50 1,00 0,75 1,00 0,75 0,75 Fig. 7 0,25 1,00 0,25 0,50 0,50 0,67 0,75 0,75 Fig. 8 0,25 1,00 0,50 1,00 0,50 0,67 0,75 0,75 Média 0,25 1,00 0,47 0,94 0,62 0,83 0,82 0,82
42 Quanto mais próximo do topo do gráfico, melhor é o desempenho do classificador. precision Gráfico Recall x Precision Histograma - banco faces recall Para se comparar dois gráficos de classificadores (ou algoritmos) diferentes, alinham-se os pontos recuperados (mesmo valor de K) verticalmente, adotando-se o mesmo Recall para os dois e calculando-se as diferentes Precisões.
43 Avaliação das Classificações em diferentes Classes
44 Utilizada para Classificador Discreto. Quando um conjunto de dados é não balanceado, ou seja, o número de elementos de cada classe é diferente, o resultado é melhor analisado através de uma Matriz de Confusão. Uma Matriz de Confusão mostra com mais detalhes a operação do classificador. É possível verificar quais as classes que o classificador confunde mais e tomar decisões que otimizem sua saída.
45 Matriz de Confusão é uma matriz quadrada n x n onde as colunas representam as n classes reais de entrada e as n linhas as n classes de saída do classificador. Cada célula fornece o número de elementos classificados. Se a busca for por Abrangência toma-se apenas o elemento mais similar. Se a busca for por K-NN, calcula-se apenas para K=1.
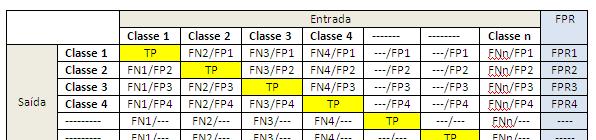
46




47 4 Classes: Classe 1 = 100 cachorros Classe 2 = 50 coelhos Classe 3 = 80 gatos Classe 4 = 120 lobos
48 Total de Genuínos (Total de Elementos) = = 350 Verdadeiros Negativos TN 1 = Todos os que NÃO são cachorros = 250 TN 2 = Todos os que NÃO são coelhos = 300 TN 3 = Todos os que NÃO são gatos = 270 TN 4 = Todos os que NÃO são lobos = 230
49 Para a Classe 1 Razão de elementos que foram classificados como cachorro sem ser. Para a Classe 2 Razão de elementos que foram classificados como coelho sem ser.
50 Para a Classe 3 Razão de elementos que foram classificados como gato sem ser. Para a Classe 4 Razão de elementos que foram classificados como lobo sem ser.
51 Para a Classe 1 Razão de cachorros não classificados como cachorros. Para a Classe 2 Razão de coelhos não classificados como coelhos.
52 Para a Classe 3 Razão de gatos não classificados como gatos. Para a Classe 4 Razão de lobos não classificados como lobos.
53 SENSIBILIDADE Recall Probabilidade de uma Amostra relevante ser classificada corretamente. PRECISÃO Probabilidade de uma Amostra classificada ser relevante.
54 Diz-se, então que este classificador tem Precisão, ou Índice de Classificações Corretas de 85,7 %. Erro: Taxa de elementos classificados erroneamente.
55 Método de Seleção dos conjuntos de treinamento e teste
56 É uma técnica para avaliar como o resultado de uma análise estatística generalizará para um conjunto independente de dados. É usado para estimar o quão preciso um classificador será na prática. Uma etapa do Cross-validation envolve a partição do conjunto de dados em sub-conjuntos complementares. A análise é realizada em um subconjunto (conjunto de treinamento) e a validação da análise no outro subconjunto (conjunto de teste ou de validação).


57 1. Sub-amostragem aleatória repetitiva Este método divide aleatoriamente o conjunto de dados em treinamento e validação. Em cada divisão, o classificador é definido usando o conjunto de treinamento e sua precisão é avaliada usando os dados do conjunto de validação. O resultado final é a média do resultado de cada divisão. A proporção da divisão treinamento/validação não é dependente do número de iterações.

58 2. K-fold O conjunto de dados original é subdividido em K subconjuntos. Dos K subconjuntos, toma-se um como o conjunto de validação e os restantes K-1 subconjuntos são usados como conjunto de treinamento. O processo de cross-validationé então repetido K vezes usando cada um dos subconjuntos como conjunto de validação. Calcula-se, então, a média dos K resultados para gerar a estimação.

59 3. Leave-one-out Utiliza-se um único elemento do conjunto original como conjunto de validação e o restante como conjunto de treinamento. O procedimento é repetido até que cada elemento do conjunto original seja usado uma vez.
60 Cumulative Match Score
61 Universo Fechado (ClosedUniverse):Todos os elementos do Conjunto de Teste podem ser mapeados a uma Classe dentro do Conjunto de Treinamento. Universo Aberto (Open Universe): Algum elemento do Conjunto de Teste não pertence a nenhuma Classe do Conjunto de Treinamento.
62 Os resultados de um modelo de Universo Aberto podem ser avaliados através da Curva ROC. Exemplo: Dentre os usuários de um sistema de reconhecimento de faces, podem existir elementos não cadastrados. Duas classes de elementos no Conjunto de Teste: 1. Elementos que não possuem classes no Conjunto de Treinamento Geram Falsos Positivos (FP) 2. Elementos que podem ser mapeados em classes no Conjunto de Treinamento Geram Falsos Negativos (FN)
63 O modelo de Universo Fechado permite-nos avaliar quão bom um classificador é para identificar uma imagem do Conjunto de Teste. Questão envolvida: A resposta correta está dentro dos R elementos retornados? (Top R) Isso permite-nos saber quantas imagens devem ser avaliadas para se obter o nível desejado de desempenho.
64 Também conhecido como Protocolo FERET. É definido como a probabilidade acumulativa p(r) de uma classe verdadeira de um objeto do Conjunto de Teste pertencer ao topo de R acertos. O gráfico CMS relata para que fração de exemplares do Conjunto de Teste as respostas corretas estão no topo de R; Usa o Modelo de Universo Fechado.

")











65 T P Si P= conjunto de Teste (Probes) utilizar Cross-validation K-folds T = Conjunto de Treinamento (Target) Si = Medida de similaridade entre uma imagem em P com todas as de T.
66 Para cada exemplar do Conjunto de Teste p i, calculase a similaridade S i (.) para todas as imagens de T. A maior medida de similaridade implica em um acerto mais correto e à menor pontuação. Um elemento p i está no topo R se possui uma das R th menores pontuações para o conjunto T.
67 20 classes; Cada Classe com 72 imagens; Utilizando-se k-folds com k=10. Para Rank R=1 Das 72 imagens pertencentes à classe 1, 70 possuem a menor pontuação, ou seja, a maior similaridade com elementos do conjunto de Teste. Das 72 imagens pertencentes a classe 2, 63 fornecem a menor pontuação, ou seja, são as mais similares a algum elemento do conjunto de Teste. Probabilidade de Identificação Correta para R=1: CMS = *72 = = 93,75%
68 Para Rank R=5 Das 72 imagens pertencentes as classe 1, 2, 3 e 4, todas estão entre as 5 menores pontuações. Das 72 imagens pertencentes a classe 5, apenas 71 estão entre as 5 menores pontuações e para a classe 14 são 69 que estão entre as menores pontuações. Probabilidade de Identificação Correta para R=5: CMS = = 20* = 99,7%

69 Para Rank R=10 Para Rank R=20 Todas os exemplares estão entre as 10 menores pontuações. Probabilidade de Identificação Correta para R=10 e para R=20 CMS 1440 = = 100% 1440

70 Se o algoritmo buscar apenas UMA imagem mais similar, seu desempenho global será de 93,7% de Precisão. Para se conseguir 100% de Precisão, ou seja, tal que em cada busca o elemento esteja entre os R retornados, R deve ser igual a DEZ no mínimo. Se, no entanto, o algoritmo classificar as 5 imagens mais similares em cada classe, a Precisão global chega a 97,7 %.
Boas Maneiras em Aprendizado de Máquinas
 Universidade Federal do Paraná (UFPR) Bacharelado em Informática Biomédica Boas Maneiras em Aprendizado de Máquinas David Menotti www.inf.ufpr.br/menotti/ci171-182 Boas Maneiras Agenda Introdução Métricas
Universidade Federal do Paraná (UFPR) Bacharelado em Informática Biomédica Boas Maneiras em Aprendizado de Máquinas David Menotti www.inf.ufpr.br/menotti/ci171-182 Boas Maneiras Agenda Introdução Métricas
Curso de Data Mining
 Curso de Data Mining Sandra de Amo Curvas Roc Uma curva ROC (Receiver Operating Characteristic) é um enfoque gráfico que permite visualizar os trade-offs entre as taxas de positivos verdadeiros e positivos
Curso de Data Mining Sandra de Amo Curvas Roc Uma curva ROC (Receiver Operating Characteristic) é um enfoque gráfico que permite visualizar os trade-offs entre as taxas de positivos verdadeiros e positivos
Roteiro. PCC142 / BCC444 - Mineração de Dados Avaliação de Classicadores. Estimativa da Acurácia. Introdução. Estimativa da Acurácia
 Roteiro PCC142 / BCC444 - Mineração de Dados Avaliação de Classicadores Introdução Luiz Henrique de Campos Merschmann Departamento de Computação Universidade Federal de Ouro Preto luizhenrique@iceb.ufop.br
Roteiro PCC142 / BCC444 - Mineração de Dados Avaliação de Classicadores Introdução Luiz Henrique de Campos Merschmann Departamento de Computação Universidade Federal de Ouro Preto luizhenrique@iceb.ufop.br
DCBD. Avaliação de modelos. Métricas para avaliação de desempenho. Avaliação de modelos. Métricas para avaliação de desempenho...
 DCBD Métricas para avaliação de desempenho Como avaliar o desempenho de um modelo? Métodos para avaliação de desempenho Como obter estimativas confiáveis? Métodos para comparação de modelos Como comparar
DCBD Métricas para avaliação de desempenho Como avaliar o desempenho de um modelo? Métodos para avaliação de desempenho Como obter estimativas confiáveis? Métodos para comparação de modelos Como comparar
Créditos. SCC0173 Mineração de Dados Biológicos. Aula de Hoje. Desempenho de Classificação. Classificação IV: Avaliação de Classificadores
 SCC0173 Mineração de Dados Biológicos Classificação IV: Avaliação de Classificadores Créditos O material a seguir consiste de adaptações e extensões dos originais: gentilmente cedidos pelo rof. André C..
SCC0173 Mineração de Dados Biológicos Classificação IV: Avaliação de Classificadores Créditos O material a seguir consiste de adaptações e extensões dos originais: gentilmente cedidos pelo rof. André C..
Mineração de Dados em Biologia Molecular
 Mineração de Dados em Biologia Molecular André C.. L. F. de Carvalho Monitor: Valéria Carvalho lanejamento e Análise de Experimentos rincipais tópicos Estimativa do erro artição dos dados Reamostragem
Mineração de Dados em Biologia Molecular André C.. L. F. de Carvalho Monitor: Valéria Carvalho lanejamento e Análise de Experimentos rincipais tópicos Estimativa do erro artição dos dados Reamostragem
Aprendizagem de Máquina
 Aprendizagem de Máquina Alessandro L. Koerich Programa de Pós-Graduação em Informática Pontifícia Universidade Católica do Paraná (PUCPR) Rejeição Introdução Em aplicações reais, sistemas de reconhecimento
Aprendizagem de Máquina Alessandro L. Koerich Programa de Pós-Graduação em Informática Pontifícia Universidade Católica do Paraná (PUCPR) Rejeição Introdução Em aplicações reais, sistemas de reconhecimento
Avaliação de Descritores de Imagem
 Avaliação de Descritores de Imagem André Tavares da Silva andre.silva@udesc.br Descritor O par descritor de imagem e função de distância descreve como as imagens de uma coleção estão distribuídas no espaço
Avaliação de Descritores de Imagem André Tavares da Silva andre.silva@udesc.br Descritor O par descritor de imagem e função de distância descreve como as imagens de uma coleção estão distribuídas no espaço
Aprendizagem de Máquina
 Aprendizagem de Máquina Modelos preditivos A tarefa de classificação Modelos Preditivos A tarefa de geração de um modelo preditivo consiste em aprender um mapeamento de entrada para a saída. Neste caso,
Aprendizagem de Máquina Modelos preditivos A tarefa de classificação Modelos Preditivos A tarefa de geração de um modelo preditivo consiste em aprender um mapeamento de entrada para a saída. Neste caso,
Inteligência Artificial
 Inteligência Artificial Aula 14 Aprendizado de Máquina Avaliação de s Preditivos (Classificação) Hold-out K-fold Leave-one-out Prof. Ricardo M. Marcacini ricardo.marcacini@ufms.br Curso: Sistemas de Informação
Inteligência Artificial Aula 14 Aprendizado de Máquina Avaliação de s Preditivos (Classificação) Hold-out K-fold Leave-one-out Prof. Ricardo M. Marcacini ricardo.marcacini@ufms.br Curso: Sistemas de Informação
Reconhecimento de Padrões
 Reconhecimento de Padrões André Tavares da Silva andre.silva@udesc.br Kuncheva pg. 8 a 25 (seções 1.3 e 1.4) Roteiro da aula Cálculo do erro de um classificador Técnicas de treinamento, avaliação e teste
Reconhecimento de Padrões André Tavares da Silva andre.silva@udesc.br Kuncheva pg. 8 a 25 (seções 1.3 e 1.4) Roteiro da aula Cálculo do erro de um classificador Técnicas de treinamento, avaliação e teste
Avaliando Hipóteses. George Darmiton da Cunha Cavalcanti Tsang Ing Ren CIn/UFPE
 Avaliando Hipóteses George Darmiton da Cunha Cavalcanti Tsang Ing Ren CIn/UFPE Pontos importantes Erro da Amostra e Erro Real Como Calcular Intervalo de Confiança Erros de hipóteses Estimadores Comparando
Avaliando Hipóteses George Darmiton da Cunha Cavalcanti Tsang Ing Ren CIn/UFPE Pontos importantes Erro da Amostra e Erro Real Como Calcular Intervalo de Confiança Erros de hipóteses Estimadores Comparando
Inteligência Artificial. Raimundo Osvaldo Vieira [DComp IFMA Campus Monte Castelo]
![Inteligência Artificial. Raimundo Osvaldo Vieira [DComp IFMA Campus Monte Castelo]](/thumbs/73/68656289.jpg "Inteligência Artificial. Raimundo Osvaldo Vieira [DComp IFMA Campus Monte Castelo]") Inteligência Artificial Raimundo Osvaldo Vieira [DComp IFMA Campus Monte Castelo] Aprendizagem de Máquina Área da Inteligência Artificial cujo objetivo é o desenvolvimento de técnicas computacionais sobre
Inteligência Artificial Raimundo Osvaldo Vieira [DComp IFMA Campus Monte Castelo] Aprendizagem de Máquina Área da Inteligência Artificial cujo objetivo é o desenvolvimento de técnicas computacionais sobre
à Análise de Padrões
 CC-226 Introdução à Análise de Padrões Prof. Carlos Henrique Q. Forster Visão Geral do Curso e Introdução a Classificadores Padrões São apresentados como tuplas de variáveis aleatórias O conjunto amostra
CC-226 Introdução à Análise de Padrões Prof. Carlos Henrique Q. Forster Visão Geral do Curso e Introdução a Classificadores Padrões São apresentados como tuplas de variáveis aleatórias O conjunto amostra
Thiago Marzagão 1. 1 Thiago Marzagão (Universidade de Brasília) MINERAÇÃO DE DADOS 1 / 21
 MINERAÇÃO DE DADOS 1 / 21") MINERAÇÃO DE DADOS Thiago Marzagão 1 1 marzagao.1@osu.edu ÁRVORE DE DECISÃO & VALIDAÇÃO Thiago Marzagão (Universidade de Brasília) MINERAÇÃO DE DADOS 1 / 21 árvore de decisão Aulas passadas: queríamos
MINERAÇÃO DE DADOS Thiago Marzagão 1 1 marzagao.1@osu.edu ÁRVORE DE DECISÃO & VALIDAÇÃO Thiago Marzagão (Universidade de Brasília) MINERAÇÃO DE DADOS 1 / 21 árvore de decisão Aulas passadas: queríamos
HP UFCG Analytics Abril-Maio Um curso sobre Reconhecimento de Padrões e Redes Neurais. Por Herman Martins Gomes.
 HP UFCG Analytics Abril-Maio 2012 Um curso sobre Reconhecimento de Padrões e Redes Neurais Por Herman Martins Gomes hmg@dsc.ufcg.edu.br Programa Visão Geral (2H) Reconhecimento Estatístico de Padrões (3H)
HP UFCG Analytics Abril-Maio 2012 Um curso sobre Reconhecimento de Padrões e Redes Neurais Por Herman Martins Gomes hmg@dsc.ufcg.edu.br Programa Visão Geral (2H) Reconhecimento Estatístico de Padrões (3H)
Boas Maneiras Aprendizado Não Supervisionado Regressão
 Universidade Federal do Paraná (UFPR) Especialização em Engenharia Industrial 4.0 Boas Maneiras Aprendizado Não Supervisionado Regressão David Menotti www.inf.ufpr.br/menotti/am-18b Hoje Boas Maneiras
Universidade Federal do Paraná (UFPR) Especialização em Engenharia Industrial 4.0 Boas Maneiras Aprendizado Não Supervisionado Regressão David Menotti www.inf.ufpr.br/menotti/am-18b Hoje Boas Maneiras
Combinação de Classificadores (fusão)
") Combinação de Classificadores (fusão) André Tavares da Silva andre.silva@udesc.br Livro da Kuncheva Roteiro Sistemas com múltiplos classificadores Fusão por voto majoritário voto majoritário ponderado
Combinação de Classificadores (fusão) André Tavares da Silva andre.silva@udesc.br Livro da Kuncheva Roteiro Sistemas com múltiplos classificadores Fusão por voto majoritário voto majoritário ponderado
Validade interna e externa em estudos epidemiológicos. Sensibilidade; Especificidade; Valor Preditivo Positivo; Valor Preditivo Negativo
 Validade interna e externa em estudos epidemiológicos Sensibilidade; Especificidade; Valor Preditivo Positivo; Valor Preditivo Negativo Qualidade da Informação Existem dois conceitos fundamentais, em termos
Validade interna e externa em estudos epidemiológicos Sensibilidade; Especificidade; Valor Preditivo Positivo; Valor Preditivo Negativo Qualidade da Informação Existem dois conceitos fundamentais, em termos
UNIVERSIDADE TECNOLÓGICA FEDERAL DO PARANÁ (UTFPR) 2016/ PPGCA PPGCA/UTFPR -- CAIA003
 2016/ PPGCA PPGCA/UTFPR -- CAIA003") UNIVERSIDADE TECNOLÓGICA FEDERAL DO PARANÁ (UTFPR) Mineração de Dados 2016/3 Professores Celso e Heitor Jean Avila Rangel 1801317 - PPGCA PPGCA/UTFPR câmpus Curitiba -- CAIA003 - Mineração de Dados --
UNIVERSIDADE TECNOLÓGICA FEDERAL DO PARANÁ (UTFPR) Mineração de Dados 2016/3 Professores Celso e Heitor Jean Avila Rangel 1801317 - PPGCA PPGCA/UTFPR câmpus Curitiba -- CAIA003 - Mineração de Dados --
5 Experimentos Corpus
 5 Experimentos 5.1. Corpus A palavra corpus significa corpo em latim. No contexto de Aprendizado de Máquina, corpus se refere a um conjunto de dados utilizados para experimentação e validação de modelos.
5 Experimentos 5.1. Corpus A palavra corpus significa corpo em latim. No contexto de Aprendizado de Máquina, corpus se refere a um conjunto de dados utilizados para experimentação e validação de modelos.
Aprendizagem de Máquina
 Aprendizagem de Máquina Avaliação de Paradigmas Alessandro L. Koerich Mestrado/Doutorado em Informática Pontifícia Universidade Católica do Paraná (PUCPR) Mestrado/Doutorado em Informática Aprendizagem
Aprendizagem de Máquina Avaliação de Paradigmas Alessandro L. Koerich Mestrado/Doutorado em Informática Pontifícia Universidade Católica do Paraná (PUCPR) Mestrado/Doutorado em Informática Aprendizagem
Universidade Federal do Paraná Departamento de Informática. Reconhecimento de Padrões. Introdução
 Universidade Federal do Paraná Departamento de Informática Reconhecimento de Padrões Introdução Luiz Eduardo S. Oliveira, Ph.D. http://lesoliveira.net Objetivos Introduzir os conceito básicos de reconhecimento
Universidade Federal do Paraná Departamento de Informática Reconhecimento de Padrões Introdução Luiz Eduardo S. Oliveira, Ph.D. http://lesoliveira.net Objetivos Introduzir os conceito básicos de reconhecimento
APRENDIZAGEM DE MÁQUINA
 APRENDIZAGEM DE MÁQUINA (usando Python) Thiago Marzagão ÁRVORE DE DECISÃO & VALIDAÇÃO Thiago Marzagão APRENDIZAGEM DE MÁQUINA 1 / 20 árvore de decisão Aulas passadas: queríamos prever variáveis quantitativas.
APRENDIZAGEM DE MÁQUINA (usando Python) Thiago Marzagão ÁRVORE DE DECISÃO & VALIDAÇÃO Thiago Marzagão APRENDIZAGEM DE MÁQUINA 1 / 20 árvore de decisão Aulas passadas: queríamos prever variáveis quantitativas.
Análise ROC. 1 Introdução. 2 Performance dos Classicadores. Felipe Castro da Silva São José dos Campos, 6 de Dezembro de 2006
 Análise ROC Felipe Castro da Silva felipe@dpi.inpe.br São José dos Campos, 6 de Dezembro de 2006 1 Introdução ROC 1 é uma técnica para visualizar, avaliar, organizar e selecionar classicadores baseado
Análise ROC Felipe Castro da Silva felipe@dpi.inpe.br São José dos Campos, 6 de Dezembro de 2006 1 Introdução ROC 1 é uma técnica para visualizar, avaliar, organizar e selecionar classicadores baseado
Inteligência nos Negócios (Business Inteligente)
") Inteligência nos Negócios (Business Inteligente) Sistemas de Informação Sistemas de Apoio a Decisão Aran Bey Tcholakian Morales, Dr. Eng. (Apostila 6) Fundamentação da disciplina Analise de dados Decisões
Inteligência nos Negócios (Business Inteligente) Sistemas de Informação Sistemas de Apoio a Decisão Aran Bey Tcholakian Morales, Dr. Eng. (Apostila 6) Fundamentação da disciplina Analise de dados Decisões
2. Redes Neurais Artificiais
 Computação Bioinspirada - 5955010-1 2. Redes Neurais Artificiais Prof. Renato Tinós Depto. de Computação e Matemática (FFCLRP/USP) 1 2.4. Outras Redes Neurais Artificiais 2.4.1. Redes RBF 2.4.2. Mapas
Computação Bioinspirada - 5955010-1 2. Redes Neurais Artificiais Prof. Renato Tinós Depto. de Computação e Matemática (FFCLRP/USP) 1 2.4. Outras Redes Neurais Artificiais 2.4.1. Redes RBF 2.4.2. Mapas
Descoberta de Conhecimento em Bancos de Dados - KDD
 Descoberta de Conhecimento em Bancos de Dados - KDD Professor: Rosalvo Ferreira de Oliveira Neto Disciplina: Inteligência Artificial Tópicos 1. Definições 2. Fases do processo 3. Exemplo do DMC 4. Avaliação
Descoberta de Conhecimento em Bancos de Dados - KDD Professor: Rosalvo Ferreira de Oliveira Neto Disciplina: Inteligência Artificial Tópicos 1. Definições 2. Fases do processo 3. Exemplo do DMC 4. Avaliação
Regressão Linear. Fabrício Olivetti de França. Universidade Federal do ABC
 Regressão Linear Fabrício Olivetti de França Universidade Federal do ABC Tópicos 1. Overfitting 2. Treino e Validação 3. Baseline dos modelos 1 Overfitting Overfit Em muitos casos, a amostra de dados coletada
Regressão Linear Fabrício Olivetti de França Universidade Federal do ABC Tópicos 1. Overfitting 2. Treino e Validação 3. Baseline dos modelos 1 Overfitting Overfit Em muitos casos, a amostra de dados coletada
Brilliant Solutions for a Safe World
 TESTES DE CONFIABILIDADE A confiabilidade da identificação é importante para sistemas de grande escala. O SDK MegaMatcher inclui um algoritmo mesclado para identificação rápida e confiável usando vários
TESTES DE CONFIABILIDADE A confiabilidade da identificação é importante para sistemas de grande escala. O SDK MegaMatcher inclui um algoritmo mesclado para identificação rápida e confiável usando vários
Implementação de um sistema de validação estatística configurável de dados
 Implementação de um sistema de validação estatística configurável de dados Eduardo Dias Filho Supervisores: João Eduardo Ferreira e Pedro Losco Takecian 16 de novembro de 2014 Introdução Table of Contents
Implementação de um sistema de validação estatística configurável de dados Eduardo Dias Filho Supervisores: João Eduardo Ferreira e Pedro Losco Takecian 16 de novembro de 2014 Introdução Table of Contents
Estatística: Aplicação ao Sensoriamento Remoto SER ANO Avaliação de Classificação
 Estatística: Aplicação ao Sensoriamento Remoto SER 204 - ANO 2018 Avaliação de Classificação Camilo Daleles Rennó camilo@dpi.inpe.br http://www.dpi.inpe.br/~camilo/estatistica/ Classificação e Incerteza
Estatística: Aplicação ao Sensoriamento Remoto SER 204 - ANO 2018 Avaliação de Classificação Camilo Daleles Rennó camilo@dpi.inpe.br http://www.dpi.inpe.br/~camilo/estatistica/ Classificação e Incerteza
Métodos de Amostragem. Métodos de Amostragem e Avaliação de Algoritmos. Métodos de Amostragem. Métodos de Amostragem. Métodos de Amostragem
 e Avaliação de s José Augusto Baranauskas Departamento de Física e Matemática FFCLRP-USP AM é uma ferramenta poderosa, mas não existe um único algoritmo que apresente o melhor desempenho para todos os
e Avaliação de s José Augusto Baranauskas Departamento de Física e Matemática FFCLRP-USP AM é uma ferramenta poderosa, mas não existe um único algoritmo que apresente o melhor desempenho para todos os
Aprendizado de Máquina (Machine Learning)
") Ciência da Computação Aprendizado de Máquina (Machine Learning) Aula 09 Árvores de Decisão Max Pereira Classificação É a tarefa de organizar objetos em uma entre diversas categorias pré-definidas. Exemplos
Ciência da Computação Aprendizado de Máquina (Machine Learning) Aula 09 Árvores de Decisão Max Pereira Classificação É a tarefa de organizar objetos em uma entre diversas categorias pré-definidas. Exemplos
SCC Capítulo 10 Métodos de Amostragem e Avaliação de Algoritmos
 Métodos de Amostragem e Avaliação de Algoritmos SCC-630 - Capítulo 10 Métodos de Amostragem e Avaliação de Algoritmos João Luís Garcia Rosa 1 1 Departamento de Ciências de Computação Instituto de Ciências
Métodos de Amostragem e Avaliação de Algoritmos SCC-630 - Capítulo 10 Métodos de Amostragem e Avaliação de Algoritmos João Luís Garcia Rosa 1 1 Departamento de Ciências de Computação Instituto de Ciências
Tutorial básico de classificação em RapidMiner
 Tutorial básico de classificação em RapidMiner Mineração de dados biológicos Ciências físicas e biomoleculares Neste tutorial, aprenderemos a utilizar as funcionalidades básicas para classificação em Rapidminer.
Tutorial básico de classificação em RapidMiner Mineração de dados biológicos Ciências físicas e biomoleculares Neste tutorial, aprenderemos a utilizar as funcionalidades básicas para classificação em Rapidminer.
TÉCNICAS DE VALIDAÇÃO DE DADOS PARA SISTEMAS INTELIGENTES: UMA ABORDAGEM DO SOFTWARE SDBAYES
 TÉCNICAS DE VALIDAÇÃO DE DADOS PARA SISTEMAS INTELIGENTES: UMA ABORDAGEM DO SOFTWARE SDBAYES JACQUES NELSON CORLETA SCHREIBER Universidade de Santa Cruz do Sul jacques@unisc.br ALVIN LAURO BESKOW Universidade
TÉCNICAS DE VALIDAÇÃO DE DADOS PARA SISTEMAS INTELIGENTES: UMA ABORDAGEM DO SOFTWARE SDBAYES JACQUES NELSON CORLETA SCHREIBER Universidade de Santa Cruz do Sul jacques@unisc.br ALVIN LAURO BESKOW Universidade
Métodos de reamostragem
 Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Métodos de reamostragem Eduardo Vargas Ferreira Função custo 2 Função custo Matriz de confusão: é um layout de tabela que
Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Métodos de reamostragem Eduardo Vargas Ferreira Função custo 2 Função custo Matriz de confusão: é um layout de tabela que
Princípios de Bioestatística
 Universidade Federal de Minas Gerais Instituto de Ciências Exatas Departamento de Estatística Princípios de Bioestatística Aula 6: Avaliação da Qualidade de Testes de Diagnóstico PARTE 1: Avaliando um
Universidade Federal de Minas Gerais Instituto de Ciências Exatas Departamento de Estatística Princípios de Bioestatística Aula 6: Avaliação da Qualidade de Testes de Diagnóstico PARTE 1: Avaliando um
2284-ELE/5, 3316-IE/3
 INTELIGÊNCIA ARTIFICIAL 2284-ELE/5, 3316-IE/3 Universidade da Beira Interior, Departamento de Informática Hugo Pedro Proença, 2007/2008 Aprendizagem Supervisionada 2 Os vários algoritmos de Aprendizagem
INTELIGÊNCIA ARTIFICIAL 2284-ELE/5, 3316-IE/3 Universidade da Beira Interior, Departamento de Informática Hugo Pedro Proença, 2007/2008 Aprendizagem Supervisionada 2 Os vários algoritmos de Aprendizagem
Ap A r p e r n e d n i d z i a z ge g m e m Es E t s a t tí t s í t s i t c i a c de d e Dado d s Francisco Carvalho
 Apredizagem Estatística de Dados Fracisco Carvalho Avaliação e Comparação de Classificadores Existem poucos estudos aalíticos sobre o comportameto de algoritmos de apredizagem. A aálise de classificadores
Apredizagem Estatística de Dados Fracisco Carvalho Avaliação e Comparação de Classificadores Existem poucos estudos aalíticos sobre o comportameto de algoritmos de apredizagem. A aálise de classificadores
Conceitos de Aprendizagem de Máquina e Experimentos. Visão Computacional
 Conceitos de Aprendizagem de Máquina e Experimentos Visão Computacional O que você vê? 2 Pergunta: Essa imagem tem um prédio? Classificação 3 Pergunta: Essa imagem possui carro(s)? Detecção de Objetos
Conceitos de Aprendizagem de Máquina e Experimentos Visão Computacional O que você vê? 2 Pergunta: Essa imagem tem um prédio? Classificação 3 Pergunta: Essa imagem possui carro(s)? Detecção de Objetos
Aprendizado de Máquinas
 Aprendizado de Máquinas Objetivo A área de aprendizado de máquina preocupa-se em construir programas que automaticamente melhorem seu desempenho com a experiência. Conceito AM estuda métodos computacionais
Aprendizado de Máquinas Objetivo A área de aprendizado de máquina preocupa-se em construir programas que automaticamente melhorem seu desempenho com a experiência. Conceito AM estuda métodos computacionais
SCC Capítulo 10 Métodos de Amostragem e Avaliação de Algoritmos
 Métodos de Amostragem e Avaliação de Algoritmos SCC-630 - Capítulo 10 Métodos de Amostragem e Avaliação de Algoritmos João Luís Garcia Rosa 1 1 Departamento de Ciências de Computação Instituto de Ciências
Métodos de Amostragem e Avaliação de Algoritmos SCC-630 - Capítulo 10 Métodos de Amostragem e Avaliação de Algoritmos João Luís Garcia Rosa 1 1 Departamento de Ciências de Computação Instituto de Ciências
Rafael Izbicki 1 / 38
 Mineração de Dados Aula 7: Classificação Rafael Izbicki 1 / 38 Revisão Um problema de classificação é um problema de predição em que Y é qualitativo. Em um problema de classificação, é comum se usar R(g)
Mineração de Dados Aula 7: Classificação Rafael Izbicki 1 / 38 Revisão Um problema de classificação é um problema de predição em que Y é qualitativo. Em um problema de classificação, é comum se usar R(g)
Redes Perceptron e Multilayer Perceptron aplicadas a base de dados IRIS
 Universidade de São Paulo Instituto de Ciências Matemáticas e de Computação Redes Perceptron e Multilayer Perceptron aplicadas a base de dados IRIS Aluno: Fabricio Aparecido Breve Prof.: Dr. André Ponce
Universidade de São Paulo Instituto de Ciências Matemáticas e de Computação Redes Perceptron e Multilayer Perceptron aplicadas a base de dados IRIS Aluno: Fabricio Aparecido Breve Prof.: Dr. André Ponce
Lista de Exercícios - Capítulo 8 [1] SCC Inteligência Artificial 1o. Semestre de Prof. João Luís
![Lista de Exercícios - Capítulo 8 [1] SCC Inteligência Artificial 1o. Semestre de Prof. João Luís](/thumbs/94/119577614.jpg "Lista de Exercícios - Capítulo 8 [1] SCC Inteligência Artificial 1o. Semestre de Prof. João Luís") ICMC-USP Lista de Exercícios - Capítulo 8 [1] SCC-630 - Inteligência Artificial 1o. Semestre de 2011 - Prof. João Luís 1. Seja breve na resposta às seguintes questões: (a) o que você entende por Aprendizado
ICMC-USP Lista de Exercícios - Capítulo 8 [1] SCC-630 - Inteligência Artificial 1o. Semestre de 2011 - Prof. João Luís 1. Seja breve na resposta às seguintes questões: (a) o que você entende por Aprendizado
Mineração em Data Streams - Avaliação. Profa. Elaine Faria UFU
 Mineração em Data Streams - Avaliação Profa. Elaine Faria UFU - 2018 Avaliação em Agrupamento Validação de Agrupamento Em tarefas de classificação A avaliação dos resultados do modelo de classificação
Mineração em Data Streams - Avaliação Profa. Elaine Faria UFU - 2018 Avaliação em Agrupamento Validação de Agrupamento Em tarefas de classificação A avaliação dos resultados do modelo de classificação
Introdução Trabalhos Relacionados Metodologia Resultados Considerações Finais. Aluna: Aline Dartora Orientador: Prof. Dr. Lucas Ferrari de Oliveira
 Análise de Extratores de Características para a Classificação de Tecidos Pulmonares e Não-Pulmonares em Imagens de Tomografia Computadorizada de Alta Resolução Aluna: Aline Dartora Orientador: Prof. Dr.
Análise de Extratores de Características para a Classificação de Tecidos Pulmonares e Não-Pulmonares em Imagens de Tomografia Computadorizada de Alta Resolução Aluna: Aline Dartora Orientador: Prof. Dr.
CLASSIFICADORES ELEMENTARES
 CLASSIFICADORES ELEMENTARES Classificação 2 Consiste em tentar discriminar em diferentes classes um conjunto de objetos com características mensuráveis Exemplo: classificação de frutas Forma, cor, sabor,
CLASSIFICADORES ELEMENTARES Classificação 2 Consiste em tentar discriminar em diferentes classes um conjunto de objetos com características mensuráveis Exemplo: classificação de frutas Forma, cor, sabor,
Aprendizado de Máquina. Combinando Classificadores
 Universidade Federal do Paraná (UFPR) Departamento de Informática (DInf) Aprendizado de Máquina Combinando Classificadores David Menotti, Ph.D. web.inf.ufpr.br/menotti Introdução O uso de vários classificadores
Universidade Federal do Paraná (UFPR) Departamento de Informática (DInf) Aprendizado de Máquina Combinando Classificadores David Menotti, Ph.D. web.inf.ufpr.br/menotti Introdução O uso de vários classificadores
Classificação de dados em modelos com resposta binária via algoritmo boosting e regressão logística
 Classificação de dados em modelos com resposta binária via algoritmo boosting e regressão logística Gilberto Rodrigues Liska 1 5 Fortunato Silva de Menezes 2 5 Marcelo Ângelo Cirillo 3 5 Mario Javier Ferrua
Classificação de dados em modelos com resposta binária via algoritmo boosting e regressão logística Gilberto Rodrigues Liska 1 5 Fortunato Silva de Menezes 2 5 Marcelo Ângelo Cirillo 3 5 Mario Javier Ferrua
Reconhecimento de Faces Utilizando Análise de Componentes Principais e a Transformada Census
 Reconhecimento de Faces Utilizando Análise de Componentes Principais e a Transformada Census Ícaro Ribeiro, Giovani Chiachia, Aparecido Nilceu Marana Universidade Estadual Paulista - UNESP (Campus de Bauru)
Reconhecimento de Faces Utilizando Análise de Componentes Principais e a Transformada Census Ícaro Ribeiro, Giovani Chiachia, Aparecido Nilceu Marana Universidade Estadual Paulista - UNESP (Campus de Bauru)
Aprendizado de Máquina (Machine Learning)
") Ciência da Computação Aprendizado de Máquina (Machine Learning) Aula 07 Classificação com o algoritmo knn Max Pereira Classificação com o algoritmo (knn) Um algoritmo supervisionado usado para classificar
Ciência da Computação Aprendizado de Máquina (Machine Learning) Aula 07 Classificação com o algoritmo knn Max Pereira Classificação com o algoritmo (knn) Um algoritmo supervisionado usado para classificar
Universidade de São Paulo Faculdade de Saúde Pública Departamento de Epidemiologia. Testes Diagnósticos ANA PAULA SAYURI SATO
 Universidade de São Paulo Faculdade de Saúde Pública Departamento de Epidemiologia Testes Diagnósticos ANA PAULA SAYURI SATO Objetivos da aula Definir validade de testes de rastreamento (screening) e diagnóstico
Universidade de São Paulo Faculdade de Saúde Pública Departamento de Epidemiologia Testes Diagnósticos ANA PAULA SAYURI SATO Objetivos da aula Definir validade de testes de rastreamento (screening) e diagnóstico
Aprendizagem de Máquina
 Aprendizagem de Máquina Árvores de Decisão Poda e extensões Prof. Paulo Martins Engel UFRGS 2 Questões sobre Árvores de Decisão Questões práticas do aprendizado de AD incluem: Determinar até quando se
Aprendizagem de Máquina Árvores de Decisão Poda e extensões Prof. Paulo Martins Engel UFRGS 2 Questões sobre Árvores de Decisão Questões práticas do aprendizado de AD incluem: Determinar até quando se
Modelos Lineares Generalizados - Regressão Logística
 Modelos Lineares Generalizados - Regressão Logística Erica Castilho Rodrigues 26 de Maio de 2014 AIC 3 Vamos ver um critério para comparação de modelos. É muito utilizado para vários tipos de modelo. Mede
Modelos Lineares Generalizados - Regressão Logística Erica Castilho Rodrigues 26 de Maio de 2014 AIC 3 Vamos ver um critério para comparação de modelos. É muito utilizado para vários tipos de modelo. Mede
Classificação e Predição de Dados - Profits Consulting - Consultoria Empresarial - Serviços SAP- CRM Si
 Classificação e Predição de Dados - Profits Consulting - Consultoria Empresarial - Serviços SAP- CRM Si Classificação de Dados Os modelos de classificação de dados são preditivos, pois desempenham inferências
Classificação e Predição de Dados - Profits Consulting - Consultoria Empresarial - Serviços SAP- CRM Si Classificação de Dados Os modelos de classificação de dados são preditivos, pois desempenham inferências
Aula 8: Árvores. Rafael Izbicki 1 / 33
 Mineração de Dados Aula 8: Árvores Rafael Izbicki 1 / 33 Revisão Vimos que a função de risco é dada por R(g) := E[I(Y g(x))] = P (Y g(x)), Nem sempre tal função nos traz toda informação sobre g. É comum
Mineração de Dados Aula 8: Árvores Rafael Izbicki 1 / 33 Revisão Vimos que a função de risco é dada por R(g) := E[I(Y g(x))] = P (Y g(x)), Nem sempre tal função nos traz toda informação sobre g. É comum
3.33pt. AIC Introdução
 1 3.33pt 1 Modelos Lineares Generalizados - Regressão Logística Erica Castilho Rodrigues 01 de Julho de 2016 2 3.33pt 3 Vamos ver um critério para comparação de modelos. É muito utilizado para vários tipos
1 3.33pt 1 Modelos Lineares Generalizados - Regressão Logística Erica Castilho Rodrigues 01 de Julho de 2016 2 3.33pt 3 Vamos ver um critério para comparação de modelos. É muito utilizado para vários tipos
Seleção de Atributos 1
 Seleção de Atributos 1 Tópicos Por que atributos irrelevantes são um problema Quais tipos de algoritmos de aprendizado são afetados Seleção de atributos antes do aprendizado Benefícios Abordagens automáticas
Seleção de Atributos 1 Tópicos Por que atributos irrelevantes são um problema Quais tipos de algoritmos de aprendizado são afetados Seleção de atributos antes do aprendizado Benefícios Abordagens automáticas
Mapeamento do uso do solo para manejo de propriedades rurais
 1/28 Mapeamento do uso do solo para manejo de propriedades rurais Teoria Eng. Allan Saddi Arnesen Eng. Frederico Genofre Eng. Marcelo Pedroso Curtarelli 2/28 Conteúdo programático: Capitulo 1: Conceitos
1/28 Mapeamento do uso do solo para manejo de propriedades rurais Teoria Eng. Allan Saddi Arnesen Eng. Frederico Genofre Eng. Marcelo Pedroso Curtarelli 2/28 Conteúdo programático: Capitulo 1: Conceitos
Árvore de Decisão. George Darmiton da Cunha Cavalcanti Tsang Ing Ren CIn/UFPE
 Árvore de Decisão George Darmiton da Cunha Cavalcanti Tsang Ing Ren CIn/UFPE Tópicos Introdução Representando Árvores de Decisão O algoritmo ID3 Definições Entropia Ganho de Informação Overfitting Objetivo
Árvore de Decisão George Darmiton da Cunha Cavalcanti Tsang Ing Ren CIn/UFPE Tópicos Introdução Representando Árvores de Decisão O algoritmo ID3 Definições Entropia Ganho de Informação Overfitting Objetivo
MESTRADO EM INFORMÁTICA MÉDICA UNIDADE CURRICULAR DE SISTEMAS DE ESTUDO COMPARATIVO O DE 2009
 FACULDADE DE MEDICINA DA UNIVERSIDADEE DO PORTOO M MESTRADO EM INFORMÁTICA MÉDICA UNIDADE CURRICULAR DE SISTEMAS DE APOIO À DECISÃO CLÍNICA ESTUDO COMPARATIVO DE TRÊS ALGORITMOS DE MACHINE LEARNING NA
FACULDADE DE MEDICINA DA UNIVERSIDADEE DO PORTOO M MESTRADO EM INFORMÁTICA MÉDICA UNIDADE CURRICULAR DE SISTEMAS DE APOIO À DECISÃO CLÍNICA ESTUDO COMPARATIVO DE TRÊS ALGORITMOS DE MACHINE LEARNING NA
K-Nearest Neighbours & RSTUDIO
 K-Nearest Neighbours & RSTUDIO Rodrigo Augusto Igawa Universidade Estadual de Londrina igawa@uel.br 17 de novembro de 2015 Rodrigo Augusto Igawa (UEL) KNN PARTE 2 17 de novembro de 2015 1 / 16 Sumário
K-Nearest Neighbours & RSTUDIO Rodrigo Augusto Igawa Universidade Estadual de Londrina igawa@uel.br 17 de novembro de 2015 Rodrigo Augusto Igawa (UEL) KNN PARTE 2 17 de novembro de 2015 1 / 16 Sumário
Combinação de Classificadores (seleção)
") Combinação de Classificadores (seleção) André Tavares da Silva andre.silva@udesc.br Livro da Kuncheva Roteiro Seleção de classificadores Estimativa independente de decisão Estimativa dependente de decisão
Combinação de Classificadores (seleção) André Tavares da Silva andre.silva@udesc.br Livro da Kuncheva Roteiro Seleção de classificadores Estimativa independente de decisão Estimativa dependente de decisão
Projeto da Disciplina
 Projeto da Disciplina Germano C. Vasconcelos Centro de Informática - UFPE Germano C.Vasconcelos 1 Objetivo Realizar um estudo experimental sobre a aplicação de modelos de redes neurais em um problema do
Projeto da Disciplina Germano C. Vasconcelos Centro de Informática - UFPE Germano C.Vasconcelos 1 Objetivo Realizar um estudo experimental sobre a aplicação de modelos de redes neurais em um problema do
Múltiplos Classificadores
 Universidade Federal do Paraná (UFPR) Bacharelado em Informátia Biomédica Múltiplos Classificadores David Menotti www.inf.ufpr.br/menotti/ci171-182 Hoje Múltiplos classificadores Combinação de classificadores
Universidade Federal do Paraná (UFPR) Bacharelado em Informátia Biomédica Múltiplos Classificadores David Menotti www.inf.ufpr.br/menotti/ci171-182 Hoje Múltiplos classificadores Combinação de classificadores
Rickson Guidolini Orientador: Nivio Ziviani Co-orientador: Adriano Veloso
 Detecção de Réplicas de Sítios Web em Máquinas de Busca Usando Aprendizado de Máquina Rickson Guidolini Orientador: Nivio Ziviani Co-orientador: Adriano Veloso Universidade Federal de Minas Gerais LATIN
Detecção de Réplicas de Sítios Web em Máquinas de Busca Usando Aprendizado de Máquina Rickson Guidolini Orientador: Nivio Ziviani Co-orientador: Adriano Veloso Universidade Federal de Minas Gerais LATIN
Por que atributos irrelevantes são um problema Quais tipos de algoritmos de aprendizado são afetados Abordagens automáticas
 Por que atributos irrelevantes são um problema Quais tipos de algoritmos de aprendizado são afetados Abordagens automáticas Wrapper Filtros Muitos algoritmos de AM são projetados de modo a selecionar os
Por que atributos irrelevantes são um problema Quais tipos de algoritmos de aprendizado são afetados Abordagens automáticas Wrapper Filtros Muitos algoritmos de AM são projetados de modo a selecionar os
Métodos para Classificação: - Naïve Bayes.
 Métodos para Classificação: - 1R; - Naïve Bayes. Visão Geral: Simplicidade em primeiro lugar: 1R; Naïve Bayes. 2 Classificação: Tarefa: Dado um conjunto de exemplos préclassificados, construir um modelo
Métodos para Classificação: - 1R; - Naïve Bayes. Visão Geral: Simplicidade em primeiro lugar: 1R; Naïve Bayes. 2 Classificação: Tarefa: Dado um conjunto de exemplos préclassificados, construir um modelo
24/11/13. Aprendendo pelas observações. PCS 2428 / PCS 2059 lnteligência Ar9ficial. Prof. Dr. Jaime Simão Sichman Prof. Dra. Anna Helena Reali Costa
 PCS 2428 / PCS 2059 lnteligência Ar9ficial Prof. Dr. Jaime Simão Sichman Prof. Dra. Anna Helena Reali Costa Aprendizagem Indu9va Aprendendo pelas observações Idéia: percepção deve ser usada não somente
PCS 2428 / PCS 2059 lnteligência Ar9ficial Prof. Dr. Jaime Simão Sichman Prof. Dra. Anna Helena Reali Costa Aprendizagem Indu9va Aprendendo pelas observações Idéia: percepção deve ser usada não somente
Aula 3: Random Forests
 Aula 3: Random Forests Paulo C. Marques F. Aula ministrada no Insper 26 de Fevereiro de 2016 Insper Random Forests 26 de Fevereiro de 2016 1 / 18 Árvores de classificação Estamos no mesmo contexto de aprendizagem
Aula 3: Random Forests Paulo C. Marques F. Aula ministrada no Insper 26 de Fevereiro de 2016 Insper Random Forests 26 de Fevereiro de 2016 1 / 18 Árvores de classificação Estamos no mesmo contexto de aprendizagem
Análise de Imagens. Aula 20: Sistemas com Múltiplos Classificadores. Prof. Alexandre Xavier Falcão.
 A.X. Falcão p.1/17 Análise de Imagens Aula 20: Sistemas com Múltiplos Classificadores (Fusão) Prof. Alexandre Xavier Falcão afalcao@ic.unicamp.br. IC - UNICAMP A.X. Falcão p.2/17 Roteiro da Aula Sistemas
A.X. Falcão p.1/17 Análise de Imagens Aula 20: Sistemas com Múltiplos Classificadores (Fusão) Prof. Alexandre Xavier Falcão afalcao@ic.unicamp.br. IC - UNICAMP A.X. Falcão p.2/17 Roteiro da Aula Sistemas
Aprendizado de Máquina (Machine Learning)
") Ciência da Computação (Machine Learning) Aula 07 Classificação com o algoritmo knn Max Pereira Classificação com o algoritmo k-nearest Neighbors (knn) Como os filmes são categorizados em gêneros? O que
Ciência da Computação (Machine Learning) Aula 07 Classificação com o algoritmo knn Max Pereira Classificação com o algoritmo k-nearest Neighbors (knn) Como os filmes são categorizados em gêneros? O que
Sistema Adaptativo de Reconhecimento Biométrico por Impressão Digital
 Sistema Adaptativo de Reconhecimento Biométrico por Impressão Digital Fernanda Baumgarten Ribeiro do Val e Priscila Ribeiro Marcelino Orientador: João José Neto Introdução Identificação biométrica, em
Sistema Adaptativo de Reconhecimento Biométrico por Impressão Digital Fernanda Baumgarten Ribeiro do Val e Priscila Ribeiro Marcelino Orientador: João José Neto Introdução Identificação biométrica, em
SEL-0339 Introdução à Visão Computacional. Aula 5 Segmentação de Imagens
 Departamento de Engenharia Elétrica - EESC-USP SEL-0339 Introdução à Visão Computacional Aula 5 Segmentação de Imagens Prof. Dr. Marcelo Andrade da Costa Vieira Prof. Dr. Adilson Gonzaga Segmentação de
Departamento de Engenharia Elétrica - EESC-USP SEL-0339 Introdução à Visão Computacional Aula 5 Segmentação de Imagens Prof. Dr. Marcelo Andrade da Costa Vieira Prof. Dr. Adilson Gonzaga Segmentação de
MODELO DE AVALIAÇÃO DO RISCO DE FAILURE INFORMA D&B
 MODELO DE AVALIAÇÃO DO RISCO DE FAILURE INFORMA D&B BROCHURA TÉCNICA WORLDWIDE NETWORK INTRODUÇÃO O Failure Score da Informa D&B consiste na pontuação gerada por um modelo desenvolvido pela Informa D&B
MODELO DE AVALIAÇÃO DO RISCO DE FAILURE INFORMA D&B BROCHURA TÉCNICA WORLDWIDE NETWORK INTRODUÇÃO O Failure Score da Informa D&B consiste na pontuação gerada por um modelo desenvolvido pela Informa D&B
FERRAMENTAS ESTATÍSTICAS PARA ANÁLISE DA CLASSIFICAÇÃO
 Objetivos: - QUANTIFICAR OS ERROS COMETIDOS NA CLASSIFICAÇÃO - MEDIR A QUALIDADE DO TRABALHO FINAL - AVALIAR A APLICABILIDADE OPERACIONAL DA CLASSIFICAÇÃO Fontes de erro das classificações temáticas Os
Objetivos: - QUANTIFICAR OS ERROS COMETIDOS NA CLASSIFICAÇÃO - MEDIR A QUALIDADE DO TRABALHO FINAL - AVALIAR A APLICABILIDADE OPERACIONAL DA CLASSIFICAÇÃO Fontes de erro das classificações temáticas Os
21/02/17. Aprendendo pelas observações. PCS 5869 lnteligência Ar9ficial. Prof. Dr. Jaime Simão Sichman Prof. Dra. Anna Helena Reali Costa
 PCS 5869 lnteligência Ar9ficial Prof. Dr. Jaime Simão Sichman Prof. Dra. Anna Helena Reali Costa Aprendizagem Indu9va Aprendendo pelas observações Idéia: percepção deve ser usada não somente para a atuação
PCS 5869 lnteligência Ar9ficial Prof. Dr. Jaime Simão Sichman Prof. Dra. Anna Helena Reali Costa Aprendizagem Indu9va Aprendendo pelas observações Idéia: percepção deve ser usada não somente para a atuação
Reconhecimento de Padrões. Reconhecimento de Padrões
 Reconhecimento de Padrões 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Escola Superior de Tecnologia Engenharia Informática Reconhecimento de Padrões Prof. João Ascenso e Prof.
Reconhecimento de Padrões 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Escola Superior de Tecnologia Engenharia Informática Reconhecimento de Padrões Prof. João Ascenso e Prof.
SCC0173 Mineração de Dados Biológicos
 SCC0173 Mineração de Dados Biológicos Classificação I: Algoritmos 1Rule e KNN Prof. Ricardo J. G. B. Campello SCC / ICMC / USP 1 Créditos O material a seguir consiste de adaptações e extensões dos originais:
SCC0173 Mineração de Dados Biológicos Classificação I: Algoritmos 1Rule e KNN Prof. Ricardo J. G. B. Campello SCC / ICMC / USP 1 Créditos O material a seguir consiste de adaptações e extensões dos originais:
2 Uma Proposta para Seleção de Dados em Modelos LVQ
 2 Uma Proposta para Seleção de Dados em Modelos LVQ Abordagens diferentes têm sido encontradas na literatura para seleção de dados. Entretanto, todas as técnicas buscam de fato o mesmo objetivo, seleção
2 Uma Proposta para Seleção de Dados em Modelos LVQ Abordagens diferentes têm sido encontradas na literatura para seleção de dados. Entretanto, todas as técnicas buscam de fato o mesmo objetivo, seleção
Créditos. SCC0173 Mineração de Dados Biológicos. Aula de Hoje. Introdução. Classificação III: Árvores de Decisão
 SCC073 Mineração de Dados Biológicos Classificação III: Árvores de Decisão Créditos O material a seguir consiste de adaptações e extensões dos originais: gentilmente cedidos pelo Prof. André C. P. L. F.
SCC073 Mineração de Dados Biológicos Classificação III: Árvores de Decisão Créditos O material a seguir consiste de adaptações e extensões dos originais: gentilmente cedidos pelo Prof. André C. P. L. F.
Técnicas de classificação Análise discriminante & Regressão logística. Abraham Laredo Sicsú
 Técnicas de classificação Análise discriminante & Regressão logística Abraham Laredo Sicsú Leituras (ênfase em REGRESSÃO LOGÍSTICA) http://www.uk.sagepub.com/burns/website%20mat erial/chapter%2024%20-
Técnicas de classificação Análise discriminante & Regressão logística Abraham Laredo Sicsú Leituras (ênfase em REGRESSÃO LOGÍSTICA) http://www.uk.sagepub.com/burns/website%20mat erial/chapter%2024%20-
Reconhecimento de Imagens de Faces Humanas
 Capítulo 3 Reconhecimento de Imagens de Faces Humanas 3.1 Introdução Um sistema de reconhecimento de faces é um sistema biométrico que identifica ou verifica seres humanos através de uma característica
Capítulo 3 Reconhecimento de Imagens de Faces Humanas 3.1 Introdução Um sistema de reconhecimento de faces é um sistema biométrico que identifica ou verifica seres humanos através de uma característica
5 ESTUDO DE CASOS 5.1 CATEGORIZAÇÃO
 102 5 ESTUDO DE CASOS 5.1 CATEGORIZAÇÃO Conforme detalhado na seção 4.3, foram criados três conjuntos de dados: clientes BT com 382 padrões, clientes comerciais MT com 866 padrões e clientes industriais
102 5 ESTUDO DE CASOS 5.1 CATEGORIZAÇÃO Conforme detalhado na seção 4.3, foram criados três conjuntos de dados: clientes BT com 382 padrões, clientes comerciais MT com 866 padrões e clientes industriais
GE-814: Introdução à Avaliação Operacional
 GE-814: Introdução à Avaliação Operacional Objetivo Que a audiência se familiarize com os testes estatísticos que visam estabelecer a garantia da performance de um sistema específico e comparações entre
GE-814: Introdução à Avaliação Operacional Objetivo Que a audiência se familiarize com os testes estatísticos que visam estabelecer a garantia da performance de um sistema específico e comparações entre
AULA 03 Estimativas e tamanhos amostrais
 1 AULA 03 Estimativas e tamanhos amostrais Ernesto F. L. Amaral 03 de outubro de 2013 Centro de Pesquisas Quantitativas em Ciências Sociais (CPEQS) Faculdade de Filosofia e Ciências Humanas (FAFICH) Universidade
1 AULA 03 Estimativas e tamanhos amostrais Ernesto F. L. Amaral 03 de outubro de 2013 Centro de Pesquisas Quantitativas em Ciências Sociais (CPEQS) Faculdade de Filosofia e Ciências Humanas (FAFICH) Universidade
Trabalho de IA - Redes Neurais: Multilayer Perceptron e16 Learning de março Vector de 2015 Quantization 1 / 28
 Trabalho de IA - Redes Neurais: Multilayer Perceptron e Learning Vector Quantization 16 de março de 2015 Material baseado em: HAN, J. & KAMBER, M. Data Mining: Concepts and Techniques. 2nd. 2006 FAUSETT,
Trabalho de IA - Redes Neurais: Multilayer Perceptron e Learning Vector Quantization 16 de março de 2015 Material baseado em: HAN, J. & KAMBER, M. Data Mining: Concepts and Techniques. 2nd. 2006 FAUSETT,
Lip Recognition. Victor Mocelin
 Lip Recognition Victor Mocelin Sumário 1. Introdução do problema 2. Por que usar os lábios? 3. Dificuldades 4. Artigos relacionados 5. Referências 2 Introdução do problema Entradas Credencial Imagem dos
Lip Recognition Victor Mocelin Sumário 1. Introdução do problema 2. Por que usar os lábios? 3. Dificuldades 4. Artigos relacionados 5. Referências 2 Introdução do problema Entradas Credencial Imagem dos
Disciplina: Processamento Estatístico de Sinais (ENGA83) - Aula 03 / Detecção de Sinais
 - Aula 03 / Detecção de Sinais") Disciplina: Processamento Estatístico de Sinais (ENGA83) - Aula 03 / Detecção de Sinais Prof. Eduardo Simas (eduardo.simas@ufba.br) Programa de Pós-Graduação em Engenharia Elétrica/PPGEE Universidade Federal
Disciplina: Processamento Estatístico de Sinais (ENGA83) - Aula 03 / Detecção de Sinais Prof. Eduardo Simas (eduardo.simas@ufba.br) Programa de Pós-Graduação em Engenharia Elétrica/PPGEE Universidade Federal
Estimação parâmetros e teste de hipóteses. Prof. Dr. Alberto Franke (48)
") Estimação parâmetros e teste de hipóteses Prof. Dr. Alberto Franke (48) 91471041 Intervalo de confiança para média É um intervalo em que haja probabilidade do verdadeiro valor desconhecido do parâmetro
Estimação parâmetros e teste de hipóteses Prof. Dr. Alberto Franke (48) 91471041 Intervalo de confiança para média É um intervalo em que haja probabilidade do verdadeiro valor desconhecido do parâmetro
Seleção de Atributos FSS. Relevância de Atributos. Relevância de Atributos. Seleção de Atributos - FSS. FSS como Busca no Espaço de Estados
 Seleção FSS Alguns indutores geralmente degradam seu desempenho quando são fornecidos muitos atributos irrelevantes para o conceito a ser aprendido Feature Subset Selection (FSS) é o processo de selecionar
Seleção FSS Alguns indutores geralmente degradam seu desempenho quando são fornecidos muitos atributos irrelevantes para o conceito a ser aprendido Feature Subset Selection (FSS) é o processo de selecionar
MÉTODOS ESTATÍSTICOS PARA EXATIDÃO DE MAPEAMENTO E AVALIAÇÃO DE MODELOS
 MÉTODOS ESTATÍSTICOS PARA EXATIDÃO DE MAPEAMENTO E AVALIAÇÃO DE MODELOS Camilo Daleles Rennó Referata Biodiversidade 8 novembro 2007 Modelagem lençol freático rocha de origem Modelagem O que faz uma planta
MÉTODOS ESTATÍSTICOS PARA EXATIDÃO DE MAPEAMENTO E AVALIAÇÃO DE MODELOS Camilo Daleles Rennó Referata Biodiversidade 8 novembro 2007 Modelagem lençol freático rocha de origem Modelagem O que faz uma planta
Testes de software - Teste funcional
 Testes de software - Teste funcional Vitor Alcântara de Almeida Universidade Federal do Rio Grande do Norte Natal, Brasil 30 de outubro de 2014 Alcântara (UFRN) Testes de software - Testes funcionais 30
Testes de software - Teste funcional Vitor Alcântara de Almeida Universidade Federal do Rio Grande do Norte Natal, Brasil 30 de outubro de 2014 Alcântara (UFRN) Testes de software - Testes funcionais 30
4 Análise dos dados Perfil dos participantes
 4 Análise dos dados 4.1. Perfil dos participantes A Tabela 1 apresenta a distribuição dos participantes do experimento por grau de escolaridade, curso, gênero e faixa etária. Os participantes foram predominantemente
4 Análise dos dados 4.1. Perfil dos participantes A Tabela 1 apresenta a distribuição dos participantes do experimento por grau de escolaridade, curso, gênero e faixa etária. Os participantes foram predominantemente