paralelismo redundante (hierarquia de memória) paralelismo desfasado (interleaving) paralelismo "real" (maior largura do bus)
|
|
|
- Mariana Ruth Godoi
- 5 Há anos
- Visualizações:
Transcrição
1 Sistemas de Computação e Desempenho Mestrado em Informática 2007/08 A.J.Proença Tema Revisitando os Sistemas de Computação (2) AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 1 Paralelismo no processador Exemplo 1 Exemplo de pipeline AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 3 Análise do desempenho em Sistemas de Computação: oportunidades para optimizar na arquitectura Optimização do desempenho (no CPU) com introdução de paralelismo ao nível do processo (sistemas paralelos/distribuídos) só fio de execução (multi-core...) processo (memória partilhada/distribuída) ao nível da instrução (Instruction Level Parallelism) só nos dados (processadores vectoriais) paralelismo desfasado (pipeline) paralelismo "real" (superescalar) no acesso à memória paralelismo desfasado (interleaving) paralelismo "real" (maior largura do bus) paralelismo redundante (hierarquia de memória)» análise de processadores da Intel AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 2 Paralelismo no processador Exemplo 2 Exemplo de superescalaridade (nível 2) AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 4
 Instruction Control Unit Retirement Unit Register File Fetch Control Instruction Decode Address Instrs.")

2 A introdução de cache na arquitectura Intel P6 Nota: "Intel P6" é a designação comum da microarquitectura de PentiumPro, Pentium II e Pentium III AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 5 A arquitectura interna dos processadores Intel P6 (1) Instruction Control Unit Retirement Unit Register File Fetch Control Instruction Decode Address Instrs. Operações Instruction Cache Previsão OK? Integer/ Branch General Integer FP Add FP Mult/Div Load Store Unidades Funcionais Operation Results Addr. Addr. Data Data Execution Unit Data Cache AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 7 Para onde vão os processadores? Intel marketing states that Core is a blend of P-M techniques and NetBurst architecture. However, Core is clearly a descendant of the Pentium Pro, or the P6 architecture. It is very hard to find anything "Pentium 4" or "NetBurst" in the Core architecture (...) it became clear that only the prefetching was inspired by experiences with the Pentium 4. Everything else is an evolution of "Yonah" (Core Duo), which was itself an improvement of Dothan and Banias. Those CPUs inherited the bus of the Pentium 4, but are still clearly children of the hugely successful P6 architecture. In a sense, you could call Core the "P8" architecture, with Banias/Dothan being based on the "P7" architecture. AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 6 Algumas potencialidades do Intel P6 (1) de 4-níveis de pipeline... para vários níveis de pipeline... AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 8
 faster than the base clock of the RAM (200 MHz). (...) The result is that wait times of 200 to 300 cycles are not uncommon on the Pentium 4. The goal of CPU cache is to avoid accessing RAM, but (.")
3 Como estão a evoluir as memórias? The main challenge for the CPU designer today is the average memory latency the CPU sees. A Pentium GHz with DDR-400 runs (...) faster than the base clock of the RAM (200 MHz). (...) The result is that wait times of 200 to 300 cycles are not uncommon on the Pentium 4. The goal of CPU cache is to avoid accessing RAM, but (...) AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 9 Algumas potencialidades do Intel P6 (2) Execução paralela de várias instruções 2 integer (1 pode ser branch) 1 FP Add 1 FP Multiply ou Divide 1 1 store Integer/ Branch General Integer FP Add Operation Results Execution Unit FP Mult/Div Load Store Addr. Addr. Data Data Cache Data U. Func. Algumas instruções requerem > 1 ciclo, mas podem ser encadeadas Instrução Latência Ciclos/Emissão Load / Store 3 1 Integer Multiply 4 1 Integer Divide Double/Single FP Multiply 5 2 Double/Single FP Add 3 1 Double/Single FP Divide AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 11 Evolução das caches nos x86 AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 10 A unidade de controlo de instruções do Intel P6 Papel da ICU: Lê instruções da InstCache baseado no IP + previsão de saltos antecipa dinamicamente (por h/w) se salta/não_salta e (possível) endereço de salto Instruction Control Unit Retirement Unit Register File Fetch Control Instruction Decode Address Instrs. Operations Instruction Cache Traduz instruções em Operações Operações: designação da Intel para instruções tipo-risc instrução típica requer 1 3 operações Converte referências a Registos em Tags Tags: identificador abstracto que liga o resultado de uma operação com operandos-fonte de operações futuras AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 12
4 Algumas limitações do pipeline: dependências de dados e saltos condicionais %edx %esi,%edx.l24 Ver exemplo nos slides seguintes... AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 13 Conversão de instruções com registos para operações com tags Versão de combine4 tipo de dados: inteiro ; operação: multiplicação.l24: # Loop: (%eax,%edx,4),%ecx # t = data[i] %edx # i++ %esi,%edx # i:length.l24 # if < goto Loop Tradução da 1ª iteração.l24: (%eax,%edx,4),%ecx %edx %esi,%edx.l24 (%eax,,4) t.1 t.1, %esi, -taken AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 15 Análise detalhada do exemplo: forma genérica e abstracta de combine void abstract_combine4(vec_ptr v, data_t dest) void combine4(vec_ptr v, int dest) { int i; int length = vec_length(v); int data = get_vec_start(v); data_t data = get_vec_start(v); int data_t sum t = = 0; IDENT; for (i = 0; i < length; i++) t sum = t += OP data[i]; dest = t; sum; Procedimento calcula a soma de todos os elementos do vector guarda o resultado numa localização destino estrutura e operações do vector definidos via ADT AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 14 Análise visual da execução de instruções no P6: 1 iteração do ciclo de produtos em combine Time t.1 (%eax,,4) t.1 t.1, %esi, -taken Operações a posição vertical dá uma indicação do tempo em que é executada uma operação não pode iniciar-se sem os seus operandos a altura traduz a latência Operandos os arcos apenas são representados para os operandos que são usados no contexto da execution unit AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 16
5 Cycle t.1 Iteration 1 %ecx.2 i=1 cc.2 Iteration 2 t.2 %ecx.3 i=2 cc.3 Iteration 3 t.3 %edx.2 i=3 cc.4 +1 Iteration 4 %ecx.4 t.4 i=4 Iteration 5 %ecx.5 +1 t.5 cc.5 %edx.4 i=5 cc.6 cc.6 Iteration 6 %ecx.6 t.6 %edx.5 AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 CPE expectável: 2.0 Desempenho 17 i=6 cc.7 Iteration 7 %ecx.7 t.7 %edx.6 i=7 Iteration 8 %ecx.8 +1 t.8 cc.8 %edx.7 19 %edx.8 As iterações do ciclo de somas: análise com recursos limitados apenas unid funcionais de inteiros 16 2 Cycle algumas operações têm de ser 17 atrasadas, mesmo existindo operandos 18 prioridade: ordem de exec do programa %ecx %edx.3 CPE: 4.0 Desempenho factor limitativo: latência da multipl. de inteiros Análise com recursos ilimitados execução paralela e encadeada de operações na EU execução out-oforder e especulativa %edx.3 Análise visual da execução de instruções no P6: 3 iterações do ciclo de produtos em combine AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/ i=0 t t.1 i=0 +1 Iteration 1 Cycle i=1 +1 cc.2 Iteration 2 %ecx.2 t.2 i=2 +1 cc.3 Iteration 3 %ecx.3 t.3 %edx.2 i=3 +1 cc.4 %edx.4 4 ops inteiro juntar várias (3) iterações num simples ciclo amortiza overhead dos ciclos em várias iterações termina extras no fim CPE: 1.33 Optimização 4: AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 void combine5(vec_ptr v, int dest) { int length = vec_length(v); int limit = length-2; int data = get_vec_start(v); int sum = 0; int i; / junta 3 elem's no mesmo ciclo / for (i = 0; i < limit; i+=3) { sum += data[i] + data[i+1] + data[i+2]; / completa os restantes elem's / for (; i < length; i++) { sum += data[i]; dest = sum; loop unroll (1) AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 pode começar uma nova iteração em cada ciclo de clock valor teórico de CPE: 1.0 requer a execução de 4 operações c/ inteiros em paralelo Iteration 4 %ecx.4 t.4 %edx.3 Análise com recursos ilimitados Desempenho Análise visual da execução de instruções no P6: 4 iterações do ciclo de somas em combine
6 loop unroll (2) s podem encadear, uma vez que não há dependências apenas um conjunto de instruções de controlo de ciclo c (%eax,,4) t.1a i t.1a, c a 4(%eax,,4) t.1b i t.1b, a b 8(%eax,,4) t.1c i t.1c, b c i $3, %esi, -taken t.1a a t.1b b t.1c +1 c Time AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 21 loop unroll (4) Valor do CPE para várias situações de loop unroll: Grau de Unroll Inteiro Soma Inteiro Produto 4.00 fp fp Soma Produto apenas melhora nas somas de inteiros restantes casos há restrições com a latência da unidade efeito não é linear com o grau de unroll há efeitos subtis que determinam a atribuição exacta das operações + AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 23 loop unroll (3) %edx %edx %ecx.2c i=6 t.3a %ecx.3a t.3b %ecx.3b 14 Cycle Desempenho estimado 15 Iteration 3 t.3c +1 cc.3 %ecx.3c pode completar iteração em 3 ciclos deveria dar CPE de 1.0 Desempenho medido CPE: iteração em cada 4 ciclos i=9 t.4a %ecx.4a t.4b %ecx.4b Iteration 4 t.4c +1 %ecx.4c cc.4 %edx.4 AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/ x 0 x 1 computação sequencial versus x 2 x 3 x 4 Computação sequencial versus... x 5 a computação x 6 ((((((((((((1 x 0 ) x 1 ) x 2 ) x 3 ) x 4 ) x 5 ) x 6 ) x 7 ) x 8 ) x 9 ) x 10 ) x 11 ) x 7 x 8 o desempenho N elementos, D ciclos/operação ND ciclos x 9 x 10 x 11 AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 24
7 versus computação paralela 1x 0 Computação sequencial... versus paralela! x 2 1x 1 x 4 x 6 x 3 o desempenho N elementos, D ciclos/op (N/2+1)D ciclos melhoria de ~2x x 8 x 5 a computação ((((((1 x 0 ) x 2 ) x 4 ) x 6 ) x 8 ) x 10 ) ((((((1 x 1 ) x 3 ) x 5 ) x 10 x 7 x 9 x 7 ) x 9 ) x 11 ) x 11 AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 25 loop unroll com paralelismo (2) os dois produtos no interior do ciclo não dependem um do outro e é possível encadeá-los iteration splitting, na literatura %ebx.0 t.1a t.1b (%eax,,4) t.1a t.1a, 4(%eax,,4) t.1b t.1b, %ebx.0 %ebx.1 i $2, %esi, -taken %ebx.1 Time AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 27 loop unroll com paralelismo (1) Computação sequencial... versus paralela! void combine6(vec_ptr v, int dest) { int length = vec_length(v); int limit = length-1; int data = get_vec_start(v); int x0 = 1; int x1 = 1; int i; / junta 2 elem's de cada vez / for (i = 0; i < limit; i+=2) { x0 = data[i]; x1 = data[i+1]; / completa os restantes elem's / for (; i < length; i++) { x0 = data[i]; dest = x0 x1; Optimização 5: acumular em 2 produtos diferentes pode ser feito em paralelo, se OP fôr associativa! juntar no fim Desempenho CPE: 2.0 melhoria de 2x AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/ loop unroll com paralelismo (3) %ebx.0 Cycle t.1a i=0 Iteration 1 11 Desempenho 12 estimado ocupado 14 com 2 op s em %edx.2 %edx.3 cc.2 t.1b cc.3 %ebx.1 13 mantém-se o multiplicador simultâneo 15 CPE: i=2 Iteration 2 Iteration 3 AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 28 t.2a t.2b %ecx.2 t.3a %ebx.2 i=4 t.3b %ecx.3 %ebx.3
8 Técnicas de optimização de código: análise comparativa de combine Método Inteiro Real (precisão simples) + + Abstract -g Abstract -O Move vec_length Acesso aos dados Acum. em temp Unroll 4x Unroll 16x Unroll 2x, paral. 2x Unroll 4x, paral. 4x Unroll 8x, paral. 4x Optimização Teórica Pior : Melhor AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 29 Limitações do paralelismo: a insuficiência de registos combine produto de inteiros unroll 8x e paralelismo 8x 7 variáveis locais partilham 1 registo (%edi) observar os acessos à stack melhoria desempenho é comprometida... register spilling na literatura.l165: (%eax),%ecx movl -4(%ebp),%edi 4(%eax),%edi movl %edi,-4(%ebp) movl -8(%ebp),%edi 8(%eax),%edi movl %edi,-8(%ebp) movl -12(%ebp),%edi 12(%eax),%edi movl %edi,-12(%ebp) movl -16(%ebp),%edi 16(%eax),%edi movl %edi,-16(%ebp) $32,%eax $8,%edx -32(%ebp),%edx.L165 AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 31 Optimização de código: limitações do paralelismo ao nível da instrução Precisa de muitos registos! para guardar somas/produtos apenas 6 registos (p/ inteiros) disponíveis no IA32 tb usados como apontadores, controlo de ciclos, 8 registos de fp quando os registos são insuficientes, temp's vão para a stack elimina ganhos de desempenho (ver assembly em produto inteiro com unroll 8x e paralelismo 8x) re-nomeação de registos não chega não é possível referenciar mais operandos que aqueles que o instruction set permite principal inconveniente do instruction set do IA32 Operações a paralelizar têm de ser associativas a soma e multipl de fp num computador não é associativa! (3.14+1e20)-1e20 nem sempre é igual a 3.14+(1e20-1e20) AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 30 A arquitectura interna dos processadores Pentium 4 AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 32



9 Percurso crítico no pipeline de instruções: o P6 e o Pentium 4 P6 Pentium 4 AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 33 AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 34 Níveis de pipeline em 3 gerações de Pentium O pipeline no Pentium 4: níveis 1-5 AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 35 AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 36


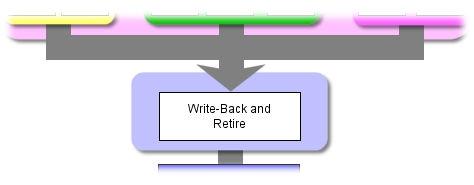
10 O pipeline no Pentium 4: níveis 6-12 AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 37 O pipeline no Pentium 4: níveis AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 39 O pipeline no Pentium 4: níveis AJProença, Sistemas de Computação e Desempenho, MInf, UMinho, 2007/08 38
Mestrado em Informática. Curso de Especialização em Informática. Optimização do desempenho (no CPU) com introdução de paralelismo
 com introdução de paralelismo") Arquitectura de Computadores Análise do desempenho em Sistemas de Computação: oportunidades para optimizar na arquitectura Mestrado em Informática & Curso de Especialização em Informática 2003/04 A.J.Proença
Arquitectura de Computadores Análise do desempenho em Sistemas de Computação: oportunidades para optimizar na arquitectura Mestrado em Informática & Curso de Especialização em Informática 2003/04 A.J.Proença
Optimização do desempenho (no h/w)
") Avaliação de Desempenho no IA3 (3) Análise do desempenho em Sistemas de Computação: oportunidades para optimizar na arquitectura Estrutura do tema Avaliação de Desempenho (IA3). A avaliação de sistemas
Avaliação de Desempenho no IA3 (3) Análise do desempenho em Sistemas de Computação: oportunidades para optimizar na arquitectura Estrutura do tema Avaliação de Desempenho (IA3). A avaliação de sistemas
Determine number of machine instructions executed. Determine how fast instructions are executed. Processor and memory system
 Sistemas de Computação e Desempenho Mestrado em Informática 2009/10 A.J.Proença Tema Revisitando os Sistemas de Computação (2) 1 Análise do desempenho em Sistemas de Computação: oportunidades para optimizar
Sistemas de Computação e Desempenho Mestrado em Informática 2009/10 A.J.Proença Tema Revisitando os Sistemas de Computação (2) 1 Análise do desempenho em Sistemas de Computação: oportunidades para optimizar
Estrutura do tema Avaliação de Desempenho (IA-32)
") Avaliação de Desempenho no IA-32 (4) Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação 2. Técnicas de otimização de código (IM) 3. Técnicas de otimização de hardware
Avaliação de Desempenho no IA-32 (4) Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação 2. Técnicas de otimização de código (IM) 3. Técnicas de otimização de hardware
Optimização do desempenho (no h/w) Objectivo. Problemas: Estrutura do tema Avaliação de Desempenho (IA-32) com introdução de paralelismo
 Objectivo. Problemas: Estrutura do tema Avaliação de Desempenho (IA-32) com introdução de paralelismo") Avaliação de Desempenho no IA-32 (3) Análise do desempenho em Sistemas de Computação: oportunidades para optimizar na arquitectura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas
Avaliação de Desempenho no IA-32 (3) Análise do desempenho em Sistemas de Computação: oportunidades para optimizar na arquitectura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas
Estrutura do tema Avaliação de Desempenho (IA-32)
") Avaliação de Desempenho no IA-32 (3) Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação 2. Técnicas de otimização de código (IM) 3. Técnicas de otimização de hardware
Avaliação de Desempenho no IA-32 (3) Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação 2. Técnicas de otimização de código (IM) 3. Técnicas de otimização de hardware
Otimização do desempenho (no h/w) Objetivo
 Objetivo") Avaliação de Desempenho no IA-32 (3) Eficiência em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação
Avaliação de Desempenho no IA-32 (3) Eficiência em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação
Otimização do desempenho (no h/w) Objectivo
 Objectivo") Avaliação de Desempenho no IA-32 (3) Eficiência em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação
Avaliação de Desempenho no IA-32 (3) Eficiência em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação
Mestrado em Informática
 Sistemas de Computação e Desempenho Understanding Performance Mestrado em Informática 2010/11 A.J.Proença Tema Revisitando os Sistemas de Computação (2) Algorithm Determines number of operations executed
Sistemas de Computação e Desempenho Understanding Performance Mestrado em Informática 2010/11 A.J.Proença Tema Revisitando os Sistemas de Computação (2) Algorithm Determines number of operations executed
Otimização do desempenho (no h/w) Objectivo. Problemas: Estrutura do tema Avaliação de Desempenho (IA-32)
 Objectivo. Problemas: Estrutura do tema Avaliação de Desempenho (IA-32)") Avaliação de Desempenho no IA-32 (3) Análise do desempenho em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas
Avaliação de Desempenho no IA-32 (3) Análise do desempenho em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas
Movimentação de código
 Avaliação de Desempenho no IA-32 (2) Otimização de código: técnicas independentes da máquina Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação 2. Técnicas de otimização
Avaliação de Desempenho no IA-32 (2) Otimização de código: técnicas independentes da máquina Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação 2. Técnicas de otimização
Estrutura do tema Avaliação de Desempenho (IA-32)
") Avaliação de Desempenho no IA-32 (2) Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação 2. Técnicas de otimização de código (IM) 3. Técnicas de otimização de hardware
Avaliação de Desempenho no IA-32 (2) Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação 2. Técnicas de otimização de código (IM) 3. Técnicas de otimização de hardware
Movimentação de código
 Avaliação de Desempenho no IA-32 (2) Otimização de código: técnicas independentes da máquina Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação 2. Técnicas de otimização
Avaliação de Desempenho no IA-32 (2) Otimização de código: técnicas independentes da máquina Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação 2. Técnicas de otimização
Mestr. Integr. Engª Informática. "Análise do desempenho": para quê? Estrutura do tema Avaliação de Desempenho (IA-32)
") Sistemas de Computação Avaliação de Desempenho no IA-32 (1) Mestr. Integr. Engª Informática Estrutura do tema Avaliação de Desempenho (IA-32) 1º ano 2015/16 A.J.Proença Tema Avaliação de Desempenho (IA-32)
Sistemas de Computação Avaliação de Desempenho no IA-32 (1) Mestr. Integr. Engª Informática Estrutura do tema Avaliação de Desempenho (IA-32) 1º ano 2015/16 A.J.Proença Tema Avaliação de Desempenho (IA-32)
Microprocessadores. Família x86 - Evolução
 Família x86 - Evolução António M. Gonçalves Pinheiro Departamento de Física Covilhã - Portugal pinheiro@ubi.pt i8086 16 bits de dados 20 bits de endereços 1MByte Clock 2 [4,8] MHz i80286 24 bits de endereço
Família x86 - Evolução António M. Gonçalves Pinheiro Departamento de Física Covilhã - Portugal pinheiro@ubi.pt i8086 16 bits de dados 20 bits de endereços 1MByte Clock 2 [4,8] MHz i80286 24 bits de endereço
Universidade Federal da Bahia Instituto de Matemática Departamento de Ciência da Computação MATA49 Programação de software básico Arquitetura Intel
 Universidade Federal da Bahia Instituto de Matemática Departamento de Ciência da Computação MATA49 Programação de software básico Arquitetura Intel Processadores 8086 Registradores: 16 bits 1978 Data bus:
Universidade Federal da Bahia Instituto de Matemática Departamento de Ciência da Computação MATA49 Programação de software básico Arquitetura Intel Processadores 8086 Registradores: 16 bits 1978 Data bus:
periféricos: interfaces humano-computador (HCI) arquivo de informação comunicações
 arquivo de informação comunicações") Introdução aos Sistemas de Computação (6) Análise de componentes num computador Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3.
Introdução aos Sistemas de Computação (6) Análise de componentes num computador Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3.
Estrutura do tema ISC
 Introdução aos Sistemas de Computação(4) Análise de componentes num computador Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3. Execução
Introdução aos Sistemas de Computação(4) Análise de componentes num computador Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3. Execução
AJProença, Sistemas de Computação, UMinho, 2017/18 1. Componentes (físicos) a analisar: a unidade de processamento / o processador:
 a analisar: a unidade de processamento / o processador:") Introdução aos Sistemas de Computação (4) Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3. Execução de programas num computador 4.
Introdução aos Sistemas de Computação (4) Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3. Execução de programas num computador 4.
Organização ou MicroArquitectura
 Organização ou MicroArquitectura DataPath MIPS32 AC Micro-Arquitectura: DataPath do MIPS Datapath e Controlpath Datapath circuito percorrido pelas instruções, endereços e ados IP Inst. Mem. Register File
Organização ou MicroArquitectura DataPath MIPS32 AC Micro-Arquitectura: DataPath do MIPS Datapath e Controlpath Datapath circuito percorrido pelas instruções, endereços e ados IP Inst. Mem. Register File
Estrutura do tema ISC
 Introdução aos Sistemas de Computação (3) num computador (1) Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3. num computador 4. O
Introdução aos Sistemas de Computação (3) num computador (1) Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3. num computador 4. O
Estrutura do tema ISA do IA-32
 Análise do Instruction Set Architecture (2) Acesso a operandos no IA-32: sua localização e modos de acesso Estrutura do tema ISA do IA-32 1. Desenvolvimento de programas no IA-32 em Linux 2. Acesso a operandos
Análise do Instruction Set Architecture (2) Acesso a operandos no IA-32: sua localização e modos de acesso Estrutura do tema ISA do IA-32 1. Desenvolvimento de programas no IA-32 em Linux 2. Acesso a operandos
Lic. Eng.ª Informática
 Arquitectura de Computadores Análise do Instruction Set Architecture (1) Lic. Eng.ª Informática 1º ano 2009/10 A.J.Proença Tema ISA do IA-32 Estrutura do tema ISA do IA-32 1. Desenvolvimento de programas
Arquitectura de Computadores Análise do Instruction Set Architecture (1) Lic. Eng.ª Informática 1º ano 2009/10 A.J.Proença Tema ISA do IA-32 Estrutura do tema ISA do IA-32 1. Desenvolvimento de programas
Paralelismo ao Nível das Instruções p. 1
 Paralelismo ao Nível das Instruções Luís Nogueira luis@dei.isep.ipp.pt Departamento Engenharia Informática Instituto Superior de Engenharia do Porto Paralelismo ao Nível das Instruções p. 1 Como melhorar
Paralelismo ao Nível das Instruções Luís Nogueira luis@dei.isep.ipp.pt Departamento Engenharia Informática Instituto Superior de Engenharia do Porto Paralelismo ao Nível das Instruções p. 1 Como melhorar
Estrutura do tema ISA do IA-32
 Análise do Instruction Set Architecture (2) Acesso a operandos no IA-32: sua localização e modos de acesso Estrutura do tema ISA do IA-32 1. Desenvolvimento de programas no IA-32 em Linux 2. Acesso a operandos
Análise do Instruction Set Architecture (2) Acesso a operandos no IA-32: sua localização e modos de acesso Estrutura do tema ISA do IA-32 1. Desenvolvimento de programas no IA-32 em Linux 2. Acesso a operandos
Arquitecturas Alternativas. Arquitectura X86-64 Arquitecturas RISC Exemplo: MIPS Desempenho de sistemas Pipelining
 Arquitecturas Alternativas Arquitectura X86-64 Arquitecturas RISC Exemplo: MIPS Desempenho de sistemas Pipelining X86-64 Qual é o ISA que temos nas máquinas Intel actuais? O x86-64 que é uma extensão para
Arquitecturas Alternativas Arquitectura X86-64 Arquitecturas RISC Exemplo: MIPS Desempenho de sistemas Pipelining X86-64 Qual é o ISA que temos nas máquinas Intel actuais? O x86-64 que é uma extensão para
Organização e Arquitetura de Computadores I
 Universidade Federal de Campina Grande Departamento de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de Computadores I Organização e Arquitetura Básicas
Universidade Federal de Campina Grande Departamento de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de Computadores I Organização e Arquitetura Básicas
Arquitetura e Organização de Processadores. Aulas 06 e 07. Superescalaridade
 Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aulas 06 e 07 Superescalaridade 1. Introdução princípios
Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aulas 06 e 07 Superescalaridade 1. Introdução princípios
Estrutura de uma função ( / procedimento )
") Análise do Instruction Set Architecture (4) Estrutura do tema ISA do IA-32 1. Desenvolvimento de programas no IA-32 em Linux 2. Acesso a operandos e operações 3. Suporte a estruturas de controlo 4. Suporte
Análise do Instruction Set Architecture (4) Estrutura do tema ISA do IA-32 1. Desenvolvimento de programas no IA-32 em Linux 2. Acesso a operandos e operações 3. Suporte a estruturas de controlo 4. Suporte
Estruturas de controlo do C if-else statement
 Análise do Instruction Set Architecture (3) Alteração do fluxo de execução de instruções Estrutura do tema ISA do IA-32 1. Desenvolvimento de programas no IA-32 em Linux 2. Acesso a operandos e operações
Análise do Instruction Set Architecture (3) Alteração do fluxo de execução de instruções Estrutura do tema ISA do IA-32 1. Desenvolvimento de programas no IA-32 em Linux 2. Acesso a operandos e operações
Microprocessadores. Execução em Paralelo Pipelines
 Execução em Paralelo Pipelines António M. Gonçalves Pinheiro Departamento de Física Covilhã - Portugal pinheiro@ubi.pt Pipelines de Instrucções Instrucções são divididas em diferentes Estágios Pipelines
Execução em Paralelo Pipelines António M. Gonçalves Pinheiro Departamento de Física Covilhã - Portugal pinheiro@ubi.pt Pipelines de Instrucções Instrucções são divididas em diferentes Estágios Pipelines
Lic. Ciências da Computação
 Arquitectura de Computadores Análise do Instruction Set Architecture (1) Lic. Ciências da Computação 1º ano 2007/08 A.J.Proença Tema Estrutura do tema ISA do IA32 1. Desenvolvimento de programas no IA32
Arquitectura de Computadores Análise do Instruction Set Architecture (1) Lic. Ciências da Computação 1º ano 2007/08 A.J.Proença Tema Estrutura do tema ISA do IA32 1. Desenvolvimento de programas no IA32
Organização Básica de Computadores. Organização Básica de Computadores. Organização Básica de Computadores. Organização Básica de Computadores
 Ciência da Computação Arq. e Org. de Computadores Processadores Prof. Sergio Ribeiro Composição básica de um computador eletrônico digital: Processador Memória Memória Principal Memória Secundária Dispositivos
Ciência da Computação Arq. e Org. de Computadores Processadores Prof. Sergio Ribeiro Composição básica de um computador eletrônico digital: Processador Memória Memória Principal Memória Secundária Dispositivos
Programação em Assembly Optimização do código
 Programação em Assembly Optimização do código IA32 AC1 IA32: Optimização do código 1 Optimização do desempenho A optimização decorre ao longo de 2 eixos: escolha cuidada dos algoritmos e estruturas de
Programação em Assembly Optimização do código IA32 AC1 IA32: Optimização do código 1 Optimização do desempenho A optimização decorre ao longo de 2 eixos: escolha cuidada dos algoritmos e estruturas de
PARTE II - CONJUNTO DE INSTRUÇÕES ARQUITETURA DE COMPUTADORES ANTONIO RAMOS DE CARVALHO JÚNIOR
 PARTE II - CONJUNTO DE INSTRUÇÕES ARQUITETURA DE COMPUTADORES ANTONIO RAMOS DE CARVALHO JÚNIOR Introdução Instruções são representadas em linguagem de máquina (binário) E x i s t e m l i n g u a g e n
PARTE II - CONJUNTO DE INSTRUÇÕES ARQUITETURA DE COMPUTADORES ANTONIO RAMOS DE CARVALHO JÚNIOR Introdução Instruções são representadas em linguagem de máquina (binário) E x i s t e m l i n g u a g e n
Curso: LMCC Exame 1ª Chamada 14/Jun/06 Disciplina: Arquitectura de Computadores Duração: 2h30m
 MCC Arquitectura de Computadores 2005/2006 Curso: LMCC Exame 1ª Chamada 14/Jun/06 Disciplina: Arquitectura de Computadores Duração: 2h30m Nota: Apresente sempre o raciocínio ou os cálculos que efectuar;
MCC Arquitectura de Computadores 2005/2006 Curso: LMCC Exame 1ª Chamada 14/Jun/06 Disciplina: Arquitectura de Computadores Duração: 2h30m Nota: Apresente sempre o raciocínio ou os cálculos que efectuar;
Resolva as seguintes alíneas fazendo todas as simplificações que considerar convenientes, anotando-as junto da resposta.
 1. Considere um processador com ISA compatível com o MIPS64 e com funcionamento superpelining (Fetch, Decode, Issue, Execute, Write-back), com mecanismos de forwarding de dados, sendo o estágio de Execute
1. Considere um processador com ISA compatível com o MIPS64 e com funcionamento superpelining (Fetch, Decode, Issue, Execute, Write-back), com mecanismos de forwarding de dados, sendo o estágio de Execute
AJProença, Sistemas de Computação, UMinho, 2017/ ou + Unidades (Centrais) de Processamento (CPU)
 de Processamento (CPU)") Introdução aos Sistemas de Computação (2) Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3. Execução de programas num computador 4.
Introdução aos Sistemas de Computação (2) Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3. Execução de programas num computador 4.
Tecnologia dos Microprocessadores. António M. G. Pinheiro Universidade da Beira Interior Covilhã - Portugal
 Tecnologia dos Microprocessadores António M. G. Pinheiro Covilhã - Portugal pinheiro@ubi.pt PIPELINES; SUPERESCALARIDADE. MEMÓRIAS CACHE. MICROPROCESSADORES RISC VERSUS CISC. PIPELINES CONSISTE NA SUBDIVISÃO
Tecnologia dos Microprocessadores António M. G. Pinheiro Covilhã - Portugal pinheiro@ubi.pt PIPELINES; SUPERESCALARIDADE. MEMÓRIAS CACHE. MICROPROCESSADORES RISC VERSUS CISC. PIPELINES CONSISTE NA SUBDIVISÃO
AJProença, Sistemas de Computação, UMinho, 2017/18 1
 Introdução aos Sistemas de Computação (3) Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3. Execução de programas num computador 4.
Introdução aos Sistemas de Computação (3) Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3. Execução de programas num computador 4.
Arquitectura e Organização de Computadores
 Arquitectura e Organização de Computadores (micro-arquitectura) atributos visíveis ao programador: I.S.A. tamanho da palavra (bits) registos Componentes que realizam a arquitectura: organização do CPU
Arquitectura e Organização de Computadores (micro-arquitectura) atributos visíveis ao programador: I.S.A. tamanho da palavra (bits) registos Componentes que realizam a arquitectura: organização do CPU
TEÓRICA. lb $t0, 1($t1)
") T1: T2: T3: T4: T5: T6: T7: T: P: TEÓRICA As questões devem ser respondidas na própria folha do enunciado. As questões 1 a 4 são de escolha múltipla, e apenas uma das respostas está correcta, valendo 1
T1: T2: T3: T4: T5: T6: T7: T: P: TEÓRICA As questões devem ser respondidas na própria folha do enunciado. As questões 1 a 4 são de escolha múltipla, e apenas uma das respostas está correcta, valendo 1
Infraestrutura de Hardware. Melhorando Desempenho de Pipeline Processadores Superpipeline, Superescalares, VLIW
 Infraestrutura de Hardware Melhorando Desempenho de Pipeline Processadores Superpipeline, Superescalares, VLIW Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem
Infraestrutura de Hardware Melhorando Desempenho de Pipeline Processadores Superpipeline, Superescalares, VLIW Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem
ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 02: PROCESSAMENTO PARALELO: PROCESSADORES VETORIAIS
 ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 02: PROCESSAMENTO PARALELO: PROCESSADORES VETORIAIS Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação
ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 02: PROCESSAMENTO PARALELO: PROCESSADORES VETORIAIS Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação
lw, sw add, sub, and, or, slt beq, j
 Datapath and Control Queremos implementar o MIPS Instruções de referência à memória: lw, sw Instruções aritméticas e lógicas: add, sub, and, or, slt Controle de fluxo: beq, j Cinco passos de execução Busca
Datapath and Control Queremos implementar o MIPS Instruções de referência à memória: lw, sw Instruções aritméticas e lógicas: add, sub, and, or, slt Controle de fluxo: beq, j Cinco passos de execução Busca
MIPS Implementação. sw) or, slt. Vamos examinar uma implementação que inclui um subconjunto de instruções do MIPS
 or, slt. Vamos examinar uma implementação que inclui um subconjunto de instruções do MIPS") Datapath do MIPS MIPS Implementação Vamos examinar uma implementação que inclui um subconjunto de instruções do MIPS Instruções de leitura (load lw) e de escrita (store sw) Instruções aritméticas e lógicas
Datapath do MIPS MIPS Implementação Vamos examinar uma implementação que inclui um subconjunto de instruções do MIPS Instruções de leitura (load lw) e de escrita (store sw) Instruções aritméticas e lógicas
Arquitectura e Organização de Computadores
 Arquitectura e Organização de Computadores (micro-arquitectura) atributos visíveis ao programador: I.S.A. tamanho da palavra (bits) registos Componentes que realizam a arquitectura: organização do CPU
Arquitectura e Organização de Computadores (micro-arquitectura) atributos visíveis ao programador: I.S.A. tamanho da palavra (bits) registos Componentes que realizam a arquitectura: organização do CPU
Introdução à Computação: Arquitetura von Neumann
 Introdução à Computação: Arquitetura von Neumann Beatriz F. M. Souza (bfmartins@inf.ufes.br) http://inf.ufes.br/~bfmartins/ Computer Science Department Federal University of Espírito Santo (Ufes), Vitória,
Introdução à Computação: Arquitetura von Neumann Beatriz F. M. Souza (bfmartins@inf.ufes.br) http://inf.ufes.br/~bfmartins/ Computer Science Department Federal University of Espírito Santo (Ufes), Vitória,
1. Considere a execução do seguinte troço de código num processador com ISA compatível
 1. Considere a execução do seguinte troço de código num processador com ISA compatível com o MIPS64. loop: L.D F0,0(R1) ; F0 M[R1+0] L.D F2,8(R1) ; F2 M[R1+8] L.D F4,0(R2) ; F4 M[R2+0] SUB.D F0,F0,F2 ;
1. Considere a execução do seguinte troço de código num processador com ISA compatível com o MIPS64. loop: L.D F0,0(R1) ; F0 M[R1+0] L.D F2,8(R1) ; F2 M[R1+8] L.D F4,0(R2) ; F4 M[R2+0] SUB.D F0,F0,F2 ;
Arquitetura de Computadores Trabalhos Práticos
 Arquitetura de Computadores Trabalhos Práticos Trabalhos Práticos 1. Bloco de memória em Verilog 2. Y86 1 instrução 5 ciclos 3. Y86 pipeline 4. Y86 dual core com cache 5. Trabalho no CUDA 3 pontos 7 pontos
Arquitetura de Computadores Trabalhos Práticos Trabalhos Práticos 1. Bloco de memória em Verilog 2. Y86 1 instrução 5 ciclos 3. Y86 pipeline 4. Y86 dual core com cache 5. Trabalho no CUDA 3 pontos 7 pontos
PSI3441 Arquitetura de Sistemas Embarcados
 PSI31 Arquitetura de Sistemas Embarcados - Arquitetura do µprocessador Escola Politécnica da Universidade de São Paulo Prof. Gustavo Rehder grehder@lme.usp.br Prof. Sergio Takeo kofuji@usp.br Prof. Antonio
PSI31 Arquitetura de Sistemas Embarcados - Arquitetura do µprocessador Escola Politécnica da Universidade de São Paulo Prof. Gustavo Rehder grehder@lme.usp.br Prof. Sergio Takeo kofuji@usp.br Prof. Antonio
Arquitetura e Organização de Processadores. Aula 08. Arquiteturas VLIW
 Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 08 Arquiteturas VLIW 1. Introdução VLIW é Very
Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 08 Arquiteturas VLIW 1. Introdução VLIW é Very
SSC0611 Arquitetura de Computadores
 SSC0611 Arquitetura de Computadores 14ª Aula Evolução Arquitetura Intel Parte 1 Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Conhecida como arquitetura x86 ou 8086 devido ao fato dos primeiros processadores
SSC0611 Arquitetura de Computadores 14ª Aula Evolução Arquitetura Intel Parte 1 Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Conhecida como arquitetura x86 ou 8086 devido ao fato dos primeiros processadores
Sistemas Operacionais. Conceitos de Hardware
 Sistemas Operacionais Conceitos de Hardware Sumário 1. Introdução 7. RISC e CISC 2. Processador 1. Operações de Processamento 2. Unidade de Controle 3. Ciclos de uma Instrução 3. Memória 1. Memória Principal
Sistemas Operacionais Conceitos de Hardware Sumário 1. Introdução 7. RISC e CISC 2. Processador 1. Operações de Processamento 2. Unidade de Controle 3. Ciclos de uma Instrução 3. Memória 1. Memória Principal
Arquiteturas de Computadores
 Arquiteturas de Computadores Computadores vetoriais Fontes dos slides: Livro Patterson e Hennessy, Quantitative Approach Introdução Arquiteturas Single Instruction Multiple Data podem explorar paralelismo
Arquiteturas de Computadores Computadores vetoriais Fontes dos slides: Livro Patterson e Hennessy, Quantitative Approach Introdução Arquiteturas Single Instruction Multiple Data podem explorar paralelismo
Pipeline. Ciclos de Operação da CPU Estágios do Pipeline Previsão de Desvio. Estrutura da CPU. Em cada ciclo, a CPU deve:
 Pipeline Ciclos de Operação da CPU Estágios do Pipeline Previsão de Desvio William Stallings - Computer Organization and Architecture, Chapter 12 [Trad. E.Simões / F.Osório] Estrutura da CPU Em cada ciclo,
Pipeline Ciclos de Operação da CPU Estágios do Pipeline Previsão de Desvio William Stallings - Computer Organization and Architecture, Chapter 12 [Trad. E.Simões / F.Osório] Estrutura da CPU Em cada ciclo,
Arquitetura e Organização de Processadores. Aula 1. Introdução Arquitetura e Organização
 Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 1 Introdução Arquitetura e Organização 1. Arquitetura
Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 1 Introdução Arquitetura e Organização 1. Arquitetura
Lic. Engenharia de Sistemas e Informática
 Conceitos de Sistemas Informáticos Lic. Engenharia de Sistemas e Informática 1º ano 2004/05 Luís Paulo Santos Módulo Arquitectura de Computadores Execução de Programas LPSantos, CSI: Arquitectura de Computadores,
Conceitos de Sistemas Informáticos Lic. Engenharia de Sistemas e Informática 1º ano 2004/05 Luís Paulo Santos Módulo Arquitectura de Computadores Execução de Programas LPSantos, CSI: Arquitectura de Computadores,
Estrutura do tema ISA do IA-32
 Análise do Instruction Set Architecture (5) x86-64: 64-bit extension to Intel 64: Intel implementation of x86-64 Estrutura do tema ISA do 1. Desenvolvimento de programas no em Linux 2. Acesso a operandos
Análise do Instruction Set Architecture (5) x86-64: 64-bit extension to Intel 64: Intel implementation of x86-64 Estrutura do tema ISA do 1. Desenvolvimento de programas no em Linux 2. Acesso a operandos
Arquiteturas de Sistemas de Processamento Paralelo. Arquiteturas SIMD
 Universidade Federal do Rio de Janeiro Pós-Graduação em Informática DCC/IM - NCE/UFRJ Arquiteturas de Sistemas de Processamento Paralelo Arquiteturas SIMD Arquiteturas SIMD Processadores Vetoriais Arquiteturas
Universidade Federal do Rio de Janeiro Pós-Graduação em Informática DCC/IM - NCE/UFRJ Arquiteturas de Sistemas de Processamento Paralelo Arquiteturas SIMD Arquiteturas SIMD Processadores Vetoriais Arquiteturas
Organização de Computadores
 Organização de Computadores Aula 25 Conjunto de Instruções: Características e Funções Rodrigo Hausen 10 de novembro de 2011 http://cuco.pro.br/ach2034 1/92 Apresentação 1. Bases Teóricas 2. Organização
Organização de Computadores Aula 25 Conjunto de Instruções: Características e Funções Rodrigo Hausen 10 de novembro de 2011 http://cuco.pro.br/ach2034 1/92 Apresentação 1. Bases Teóricas 2. Organização
18/08/2015. Capítulo 2: Manipulação de dados. Arquitetura de Computadores. Capítulo 2: Manipulação de Dados
 Capítulo 2: Manipulação de Dados Ciência da Computação: Uma visão abrangente 11a Edition Autor J. Glenn Brookshear Editora Bookman Copyright 2012 Pearson Education, Inc. Capítulo 2: Manipulação de dados
Capítulo 2: Manipulação de Dados Ciência da Computação: Uma visão abrangente 11a Edition Autor J. Glenn Brookshear Editora Bookman Copyright 2012 Pearson Education, Inc. Capítulo 2: Manipulação de dados
Arquitectura de Computadores II. Introdução
 Arquitectura de Computadores II LESI - 3º Ano Introdução João Luís Ferreira Sobral Departamento do Informática Universidade do Minho Janeiro 2002 Objectivos da disciplina e relação com outras disciplinas
Arquitectura de Computadores II LESI - 3º Ano Introdução João Luís Ferreira Sobral Departamento do Informática Universidade do Minho Janeiro 2002 Objectivos da disciplina e relação com outras disciplinas
UNIDADE CENTRAL DE PROCESSAMENTO FELIPE G. TORRES
 Tecnologia da informação e comunicação UNIDADE CENTRAL DE PROCESSAMENTO FELIPE G. TORRES CICLO DE INSTRUÇÕES OU DE EXECUÇÃO Arquitetura de computadores 2 CICLO DE EXECUÇÃO No inicio de cada ciclo de instrução,
Tecnologia da informação e comunicação UNIDADE CENTRAL DE PROCESSAMENTO FELIPE G. TORRES CICLO DE INSTRUÇÕES OU DE EXECUÇÃO Arquitetura de computadores 2 CICLO DE EXECUÇÃO No inicio de cada ciclo de instrução,
Arquitetura e Organização de Processadores. Aula 4. Pipelines
 Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 4 Pipelines 1. Introdução Objetivo: aumento de
Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 4 Pipelines 1. Introdução Objetivo: aumento de
Arquitecturas Alternativas. Pipelining Super-escalar VLIW IA-64
 Arquitecturas Alternativas Pipelining Super-escalar VLIW IA-64 Pipeline de execução A execução de uma instrução passa por várias fases: Vimos o ciclo: fetch, decode, execute fetch decode execute instrução
Arquitecturas Alternativas Pipelining Super-escalar VLIW IA-64 Pipeline de execução A execução de uma instrução passa por várias fases: Vimos o ciclo: fetch, decode, execute fetch decode execute instrução
O estudo da arquitectura de computadores efectua-se com recurso à Abstracção
 ARQUITECTURA DE COMPUTADORES O estudo da arquitectura de computadores efectua-se com recurso à Abstracção Podemos ver um computador de várias formas. Para um utilizador normalmente o computador é a aplicação
ARQUITECTURA DE COMPUTADORES O estudo da arquitectura de computadores efectua-se com recurso à Abstracção Podemos ver um computador de várias formas. Para um utilizador normalmente o computador é a aplicação
Arquitetura de Computadores I. Prof. Ricardo Santos (Cap 2)
") Arquitetura de Computadores I Prof. Ricardo Santos ricr.santos@gmail.com (Cap 2) Fluxo de Controle Vimos até agora: beq, bne Uma nova instrução: slt $t0, $s1, $s2 if $s1 < $s2 then $t0 = 1 else $t0 = 0
Arquitetura de Computadores I Prof. Ricardo Santos ricr.santos@gmail.com (Cap 2) Fluxo de Controle Vimos até agora: beq, bne Uma nova instrução: slt $t0, $s1, $s2 if $s1 < $s2 then $t0 = 1 else $t0 = 0
MO401. Arquitetura de Computadores I
 Arquitetura de Computadores I 2006 Prof. Paulo Cesar Centoducatte ducatte@ic.unicamp.br www.ic.unicamp.br/~ducatte 4.1 Arquitetura de Computadores I Paralelismo em Nível de Instruções Exploração Dinâmica
Arquitetura de Computadores I 2006 Prof. Paulo Cesar Centoducatte ducatte@ic.unicamp.br www.ic.unicamp.br/~ducatte 4.1 Arquitetura de Computadores I Paralelismo em Nível de Instruções Exploração Dinâmica
Nível da Arquitetura do Conjunto de Instruções. Ronaldo de Freitas Zampolo
 Nível da Arquitetura do Conjunto de Instruções Ronaldo de Freitas Zampolo Tópicos Introdução Visão geral do nível ISA Tipos de dados Formatos de instruções Endereçamento Tipos de instruções Fluxo de controle
Nível da Arquitetura do Conjunto de Instruções Ronaldo de Freitas Zampolo Tópicos Introdução Visão geral do nível ISA Tipos de dados Formatos de instruções Endereçamento Tipos de instruções Fluxo de controle
Programação ao nível da máquina
 Programação ao nível da máquina Ponto de vista do programador O nível Assembly Modelo de programação Assembler (processo de compilação da linguagem C) Que assembly para AC? Introdução ao assembly NASM
Programação ao nível da máquina Ponto de vista do programador O nível Assembly Modelo de programação Assembler (processo de compilação da linguagem C) Que assembly para AC? Introdução ao assembly NASM
CPU. Funções: Componentes: Processamento; Controle. UC (Unidade de Controle); Registradores; ALU s, FPU s etc. Arquitetura de Computadores 3
; Registradores; ALU s, FPU s etc. Arquitetura de Computadores 3") CPU CPU Funções: Processamento; Controle Componentes: UC (Unidade de Controle); Registradores; ALU s, FPU s etc. Arquitetura de Computadores 3 Processador A função de um computador é executar tarefas
CPU CPU Funções: Processamento; Controle Componentes: UC (Unidade de Controle); Registradores; ALU s, FPU s etc. Arquitetura de Computadores 3 Processador A função de um computador é executar tarefas
Arquitetura do SET de instruções Instruction SET. CISC vs RISC. What s assembly as to do with it?
 Arquitetura do SET de instruções Instruction SET CISC vs RISC What s assembly as to do with it? Low-level - high-level programming language Assambley CODE section.text global _start ;must be declared for
Arquitetura do SET de instruções Instruction SET CISC vs RISC What s assembly as to do with it? Low-level - high-level programming language Assambley CODE section.text global _start ;must be declared for
2. Relativamente ao datapath de ciclo único do MIPS podemos dizer que:
 Preencher na correcção 1: 2: 3: 4: 5: 6: 7: 8: F: Estas questões devem ser respondidas na própria folha do enunciado. As questões 1 a 4 são de escolha múltipla, e apenas uma das respostas está correcta,
Preencher na correcção 1: 2: 3: 4: 5: 6: 7: 8: F: Estas questões devem ser respondidas na própria folha do enunciado. As questões 1 a 4 são de escolha múltipla, e apenas uma das respostas está correcta,
A arquitectura IA32. A arquitectura de um processador é caracterizada pelo conjunto de atributos que são visíveis ao programador.
 A arquitectura IA32 A arquitectura de um processador é caracterizada pelo conjunto de atributos que são visíveis ao programador. Tamanho da palavra Número de registos visíveis Número de operandos Endereçamento
A arquitectura IA32 A arquitectura de um processador é caracterizada pelo conjunto de atributos que são visíveis ao programador. Tamanho da palavra Número de registos visíveis Número de operandos Endereçamento
Arquitetura e Organização de Computadores
 Arquitetura e Organização de Computadores Unidade Central de Processamento (CPU) Givanaldo Rocha de Souza http://docente.ifrn.edu.br/givanaldorocha givanaldo.rocha@ifrn.edu.br Baseado nos slides do capítulo
Arquitetura e Organização de Computadores Unidade Central de Processamento (CPU) Givanaldo Rocha de Souza http://docente.ifrn.edu.br/givanaldorocha givanaldo.rocha@ifrn.edu.br Baseado nos slides do capítulo
Capítulo 6 Pipeline Morgan Kaufmann Publishers
 Capítulo 6 Pipeline 998 organ Kaufmann Publishers Pipeline: analogia com linha de produção tempo carro Chassi ec Carroc. Pint. Acab. carro2 Chassi ec Carroc. Pint. Acab. carro3 Chassi ec Carroc. Pint.
Capítulo 6 Pipeline 998 organ Kaufmann Publishers Pipeline: analogia com linha de produção tempo carro Chassi ec Carroc. Pint. Acab. carro2 Chassi ec Carroc. Pint. Acab. carro3 Chassi ec Carroc. Pint.
Faculdade de Computação Arquitetura e Organização de Computadores 2 3 a Lista de Exercícios Prof. Cláudio C. Rodrigues Data de Entrega: 22/11/2018
 Problemas: Faculdade de Computação Arquitetura e Organização de Computadores 2 3 a Lista de Exercícios Prof. Cláudio C. Rodrigues Data de Entrega: 22/11/2018 P1) Qual é o propósito do instruction pipelining?
Problemas: Faculdade de Computação Arquitetura e Organização de Computadores 2 3 a Lista de Exercícios Prof. Cláudio C. Rodrigues Data de Entrega: 22/11/2018 P1) Qual é o propósito do instruction pipelining?
Assembly IA32 Procedimentos
 1 Procedimentos Assembly IA32 Procedimentos Uma chamada a um procedimento implica a transferência de dados (na forma de parâmetros do procedimento e na forma de valores retornados pelo procedimento) e
1 Procedimentos Assembly IA32 Procedimentos Uma chamada a um procedimento implica a transferência de dados (na forma de parâmetros do procedimento e na forma de valores retornados pelo procedimento) e
O Nível ISA. Modelo de programação Arquitecturas CISC e RISC Introdução ao IA-32 da Intel
 O Nível ISA Modelo de programação Arquitecturas CISC e RISC Introdução ao IA-32 da Intel Nível ISA (Instruction Set Architecture) Tipos de dados Inteiros (1, 2, 4 ou 8 bytes) Servem também para representar
O Nível ISA Modelo de programação Arquitecturas CISC e RISC Introdução ao IA-32 da Intel Nível ISA (Instruction Set Architecture) Tipos de dados Inteiros (1, 2, 4 ou 8 bytes) Servem também para representar
Organização Básica de Computadores (Parte I)
") Instituto Federal de Educação, Ciência e Tecnologia Paraíba Unidade Acadêmica de Informação e Comunicação Curso Superior de Tecnologia em Redes de Computadores Organização Básica de Computadores (Parte
Instituto Federal de Educação, Ciência e Tecnologia Paraíba Unidade Acadêmica de Informação e Comunicação Curso Superior de Tecnologia em Redes de Computadores Organização Básica de Computadores (Parte
Taxonomia de Flynn. Procura classificar todas as arquitecturas de computadores com base no processamento das instruções e dos dado.
 Multi-processamento Taxonomia de Flynn Arquitecturas SIMD Instruções vectoriais Arquitecturas MIMD Tipos de arquitectura MIMD Memória partilhada Multi-cores Taxonomia de Flynn Procura classificar todas
Multi-processamento Taxonomia de Flynn Arquitecturas SIMD Instruções vectoriais Arquitecturas MIMD Tipos de arquitectura MIMD Memória partilhada Multi-cores Taxonomia de Flynn Procura classificar todas
ORGANIZAÇÃO DE COMPUTADORES
 ORGANIZAÇÃO DE COMPUTADORES TECNOLOGIAS EM REDES DE COMPUTADORES Semestre 2015.2 Prof. Dsc. Jean Galdino As principais arquiteturas de processadores são: Von Neumann; Harvard. ARQUITETURAS AULA 06 28/10/2015
ORGANIZAÇÃO DE COMPUTADORES TECNOLOGIAS EM REDES DE COMPUTADORES Semestre 2015.2 Prof. Dsc. Jean Galdino As principais arquiteturas de processadores são: Von Neumann; Harvard. ARQUITETURAS AULA 06 28/10/2015
Pipelining. Luís Nogueira. Departamento Engenharia Informática Instituto Superior de Engenharia do Porto. Pipelining p.
 Pipelining Luís Nogueira luis@dei.isep.ipp.pt Departamento Engenharia Informática Instituto Superior de Engenharia do Porto Pipelining p. Análise de performance Desenho ciclo único de relógio é ineficiente
Pipelining Luís Nogueira luis@dei.isep.ipp.pt Departamento Engenharia Informática Instituto Superior de Engenharia do Porto Pipelining p. Análise de performance Desenho ciclo único de relógio é ineficiente
Unidade Central de Processamento UCP (CPU)
") Unidade Central de Processamento UCP (CPU)! Arquitetura Convencional (Von Neumann) UCP BARRAMENTO MEMÓRIA PRINCIPAL ENTRADA E SAÍDA ! Visão geral da CPU UC - UNIDADE DE CONTROLE REGISTRADORES A B C D ALU
Unidade Central de Processamento UCP (CPU)! Arquitetura Convencional (Von Neumann) UCP BARRAMENTO MEMÓRIA PRINCIPAL ENTRADA E SAÍDA ! Visão geral da CPU UC - UNIDADE DE CONTROLE REGISTRADORES A B C D ALU
1.0 val. (b) Determine o CPI do processador na execução do código indicado. Num.: Nome: Pág. 1. Arquitecturas Avançadas de Computadores (AAC)
 Determine o CPI do processador na execução do código indicado. Num.: Nome: Pág. 1. Arquitecturas Avançadas de Computadores (AAC)") 1. Considere um processador in-order com 5 estágios (IF, ID, EX1, EX2, WB) sem qualquer mecanismo de forwarding de dados, e o seguinte troço de código. Memória de instruções Operação MOV R1,R0 ; R1 R0
1. Considere um processador in-order com 5 estágios (IF, ID, EX1, EX2, WB) sem qualquer mecanismo de forwarding de dados, e o seguinte troço de código. Memória de instruções Operação MOV R1,R0 ; R1 R0
I. Considere os seguintes processadores A e B, ambos com arquitectura em pipeline, conforme ilustrado
 Arquitectura de Computadores 2 o Semestre (2013/2014) MEAer 2 o Teste - 19 de Junho de 2014 Duração: 1h30 + 0h15 Regras: Otesteésemconsulta, apenas tem disponível o anexo que lhe deverá ter sido entregue
Arquitectura de Computadores 2 o Semestre (2013/2014) MEAer 2 o Teste - 19 de Junho de 2014 Duração: 1h30 + 0h15 Regras: Otesteésemconsulta, apenas tem disponível o anexo que lhe deverá ter sido entregue
ARQUITETURA E ORGANIZAÇÃO DE COMPUTADORES A UNIDADE DE CONTROLE E A INTERPRETAÇÃO DE INSTRUÇÕES. Prof. Dr. Daniel Caetano
 ARQUITETURA E ORGANIZAÇÃO DE COMPUTADORES A UNIDADE DE CONTROLE E A INTERPRETAÇÃO DE INSTRUÇÕES Prof. Dr. Daniel Caetano 2011-2 Lembretes Compreender a função da unidade de controle Apresentar o ciclo
ARQUITETURA E ORGANIZAÇÃO DE COMPUTADORES A UNIDADE DE CONTROLE E A INTERPRETAÇÃO DE INSTRUÇÕES Prof. Dr. Daniel Caetano 2011-2 Lembretes Compreender a função da unidade de controle Apresentar o ciclo
Infra-estrutura de Hardware
 CPU: Estrutura e Funcionalidade Roteiro da Aula Ciclo de Instrução Projeto de uma CPU simples: conceitos Componentes básicos Leitura da instrução Operação entre registradores Acesso à memória Implementação
CPU: Estrutura e Funcionalidade Roteiro da Aula Ciclo de Instrução Projeto de uma CPU simples: conceitos Componentes básicos Leitura da instrução Operação entre registradores Acesso à memória Implementação
Otimização de Execução em Processadores Modernos. William Stallings - Computer Organization and Architecture, Chapter 12 [Trad. E.Simões / F.
 Prefetch & Pipeline Otimização de Execução em Processadores Modernos Ciclos de Operação da CPU Estágios do Pipeline Previsão de Desvio William Stallings - Computer Organization and Architecture, Chapter
Prefetch & Pipeline Otimização de Execução em Processadores Modernos Ciclos de Operação da CPU Estágios do Pipeline Previsão de Desvio William Stallings - Computer Organization and Architecture, Chapter
Arquitetura de Computadores Aula 11 - Multiprocessamento
 Arquitetura de Computadores Aula 11 - Multiprocessamento Prof. Dr. Eng. Fred Sauer http://www.fredsauer.com.br fsauer@gmail.com 1/28 PROCESSAMENTO PARALELO OBJETIVO: aumentar a capacidade de processamento.
Arquitetura de Computadores Aula 11 - Multiprocessamento Prof. Dr. Eng. Fred Sauer http://www.fredsauer.com.br fsauer@gmail.com 1/28 PROCESSAMENTO PARALELO OBJETIVO: aumentar a capacidade de processamento.
28 de Abril de Aula 14
 28 de Abril de 2005 1 Arquitecturas superescalares Aula 14 Estrutura desta aula Arquitecturas VLIW e superescalares Emissão de instruções Emissão de 2 vias Superescalares com agendamento dinâmico Exemplo
28 de Abril de 2005 1 Arquitecturas superescalares Aula 14 Estrutura desta aula Arquitecturas VLIW e superescalares Emissão de instruções Emissão de 2 vias Superescalares com agendamento dinâmico Exemplo
Arquitetura de Computadores II
 Universidade Estadual de Maringá Centro de Tecnologia Departamento de Informática Arquitetura de Computadores II Prof. Flávio Rogério Uber Informações Úteis Professor: Flávio Rogério Uber Bloco C-56 Sala
Universidade Estadual de Maringá Centro de Tecnologia Departamento de Informática Arquitetura de Computadores II Prof. Flávio Rogério Uber Informações Úteis Professor: Flávio Rogério Uber Bloco C-56 Sala
Nível da Arquitetura do Conjunto das Instruções
 Nível da Arquitetura do Conjunto das Instruções (Aula 11) Visão Geral do Nível ISA Antes de deixarmos o hardware (1) 8 2 Antes de deixarmos o hardware (2) 3 ISA (Instruction Set Architecture) Arquitetura
Nível da Arquitetura do Conjunto das Instruções (Aula 11) Visão Geral do Nível ISA Antes de deixarmos o hardware (1) 8 2 Antes de deixarmos o hardware (2) 3 ISA (Instruction Set Architecture) Arquitetura