Paralelização do Detector de Bordas Canny para a Biblioteca ITK usando CUDA
|
|
|
- Ana Sofia Bugalho Pinto
- 5 Há anos
- Visualizações:
Transcrição
1 Paralelização do Detector de Bordas Canny para a Biblioteca ITK usando CUDA Luis Henrique Alves Lourenço Grupo de Visão, Robótica e Imagens Universidade Federal do Paraná 7 de abril de 2011
2 Sumário 1 Introdução 2 Insight Toolkit 3 CUDA 4 ITK e CUDA 5 Desenvolvimento 6 Resultados Experimentais 7 Conclusão
3 Introdução O ITK é uma biblioteca de Processamento de Imagens que se destaca no uso médico O Processamento de Imagens pode exigir alto poder Computacional GPGPU representa um novo potencial para aplicações de alto desempenho O ITK ainda não aproveita o paralelismo das GPUs
4 Objetivos 1 Implementar o filtro de detecção de bordas Canny usando CUDA de forma integrada ao ITK 2 Propor técnicas de programação eficientes para o processamento de imagens com ITK e CUDA 3 Avaliar o desempenho do filtro implementado em comparação com a implementação do Canny encontrada no ITK
5 Insight Toolkit (ITK) Criado em 1999, Código aberto (licensa BSD), Multiplataforma, Orientado a Objetos, Comunidade Ativa, Insight Journal, Boa Documentação Figura: Fluxo de Processamento
6 ITK - Exemplo 1 #i n c l u d e itkimage. h 2 #i n c l u d e itkimagefilereader. h 3 #i n c l u d e i t k I m a g e F i l e W r i t e r. h 4 #i n c l u d e itkcannyedgedetectionimagefilter. h 5 6 typedef i t k : : Image<float,2> ImageType ; 7 t y p e d e f i t k : : ImageFileReader< ImageType > ReaderType ; 8 t y p e d e f i t k : : ImageFileWriter< ImageType > WriterType ; 9 t y p e d e f i t k : : CannyEdgeDetectionImageFilter< ImageType, ImageType > CannyFilter ; i n t main ( i n t argc, char a r g v ){ ReaderType : : Pointer reader = ReaderType : : New ( ) ; 14 reader >SetFileName ( argv [ 1 ] ) ; 15 reader >Update ( ) ; CannyFilter : : Pointer canny = CannyFilter : : New ( ) ; 18 canny >S e t I n p u t ( r e a d e r >GetOutput ( ) ) ; 19 canny >SetVariance ( atof ( argv [ 3 ] ) ) ; 20 canny >S e t U p p e r T h r e s h o l d ( a t o i ( a r g v [ 4 ] ) ) ; 21 canny >S e t L o w e r T h r e s h o l d ( a t o i ( a r g v [ 5 ] ) ) ; 22 canny >Update ( ) ; WriterType : : P o i n t e r w r i t e r = WriterType : : New ( ) ; 25 writer >SetFileName ( argv [ 2 ] ) ; 26 w r i t e r >S e t I n p u t ( canny >GetOutput ( ) ) ; 27 writer >Update ( ) ; r e t u r n EXIT SUCCESS ; 30 }

7 Compute Unified Device Architecture (CUDA) Objetivos: Permitir o uso de centenas de núcleos e milhares de threads Focar no paralelismo Programação Heterogênea Multiprocessadores, Threads leves, Warp, Kernel

8 CUDA: Modelo de Memória Figura: Disposição Física da Memória
9 CUDA - Exemplo 1 #i n c l u d e <s t d i o. h> 2 #i n c l u d e <a s s e r t. h> 3 #i n c l u d e <cuda. h> 4 v o i d incrementarrayonhost ( f l o a t a, i n t N) 5 { 6 i n t i ; 7 f o r ( i =0; i < N; i ++) a [ i ] = a [ i ]+1. f ; 8 } 9 g l o b a l v o i d i n c r e m e n t A r r a y O n D e v i c e ( f l o a t a, i n t N) 10 { 11 i n t idx = blockidx. x blockdim. x + threadidx. x ; 12 i f ( idx<n) a [ i d x ] = a [ i d x ]+1. f ; 13 } 14 i n t main ( v o i d ) 15 { 16 f l o a t a h, b h ; // p o i n t e r s to h o s t memory 17 f l o a t a d ; // p o i n t e r to d e v i c e memory 18 i n t i, N = ; 19 s i z e t s i z e = N s i z e o f ( f l o a t ) ; 20 a h = ( f l o a t ) m a l l o c ( s i z e ) ; 21 b h = ( f l o a t ) m a l l o c ( s i z e ) ; 22 cudamalloc ( ( v o i d ) &a d, s i z e ) ; 23 f o r ( i =0; i<n; i ++) a h [ i ] = ( f l o a t ) i ; 24 cudamemcpy ( a d, a h, s i z e o f ( f l o a t ) N, cudamemcpyhosttodevice ) ; 25 incrementarrayonhost ( a h, N) ; 26 i n t b l o c k S i z e = ; 27 i n t nblocks = N/ blocksize + (N%blockSize == 0? 0 : 1 ) ; 28 incrementarrayondevice <<< nblocks, blocksize >>> ( a d, N) ; 29 cudamemcpy ( b h, a d, s i z e o f ( f l o a t ) N, cudamemcpydevicetohost ) ; 30 f r e e ( a h ) ; f r e e ( b h ) ; cudafree ( a d ) ; 31 }
10 Integrando Filtros implementados em CUDA em Fluxos do ITK O uso de placas gráficas pode acelerar a execução de alguns filtros Metodologia Sugerida pela Comunidade ITK: Utilizar o mecanismo de fatoração para criar versões especializadas de filtros
11 Cuda Insight Toolkit (CITK) Alteração leve da arquitetura: CudaImportImageContainer Compatível com as classes ITK existentes Copia dados apenas se necessário Encadeamento de filtros Não altera o modo de programar
12 CudaCanny itkcudacannyedgedetectionimagefilter Algorithm 1 Detector de Bordas Canny Suavização Gaussiana Detecção por Geometria Diferencial Non-Maximum Supression Histerese { L vv = 0 L vvv 0 (1)
13 CudaSobel itkcudasobeledgedetectionimagefilter (a) Sobel X (b) Sobel Y L v = L 2 x + L 2 y (2) ( ) Ly θ = arctan L x (3)
14 itkcudainterface Unificar o gerenciamento de configurações de kernel Estrutura do ITK Armazenar Configurações CUDA: Blocos e Grid Textura, Memória compartilhada, Cache Multi-GPU, Streams
15 Otimização em CUDA As principais estratégias de otimização incluem técnicas de: Otimização de Acesso à Memória Maximização do Paralelismo Maximização do uso de Instruções
16 Metodologia Hardware utilizado: Servidor: CPU: 4x AMD Opteron(tm) Processor ,4GHz com 8 núcleos cada com 512 KB de cache e 126GB de RAM GPU1: NVidia Tesla C2050 com 448 núcleos de 1,15GHz e 3GB de RAM. GPU2: NVidia Tesla C1060 com 240 núcleos de 1,3GHz e 4GB de RAM. Desktop: CPU: Intel R Core(TM)2 Duo E7400 2,80GHz com 3072 KB de cache e 2GB de RAM GPU: NVidia GeForce 8800 GT com 112 núcleos de 1,5GHz e 512MB de RAM.
17 Metodologia Bases criadas a partir da Berkeley Segmentation Dataset Base Resolução das imagens em pixels Quantidade de imagens B e B e B e B e
18 Testes de Qualidade Base P co P nd P fa B B B B
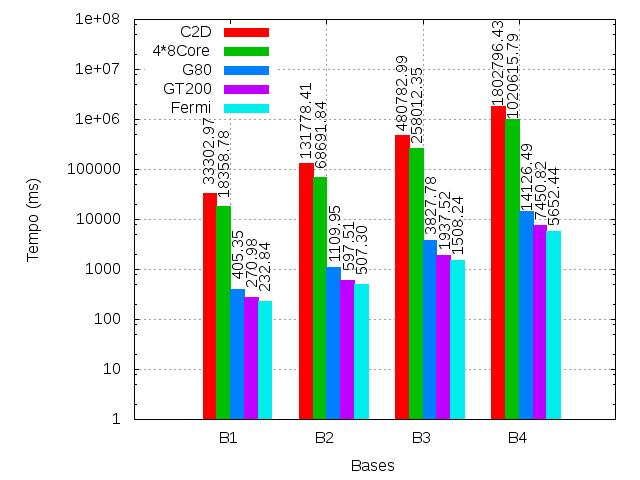

19 Testes de Desempenho

20 Testes de Desempenho
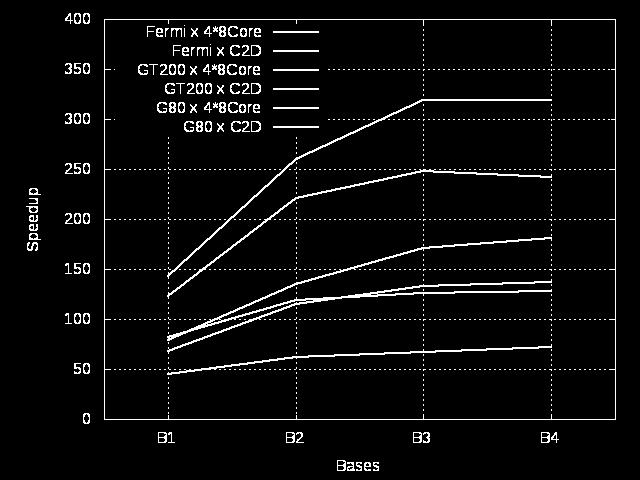
21 Testes de Desempenho
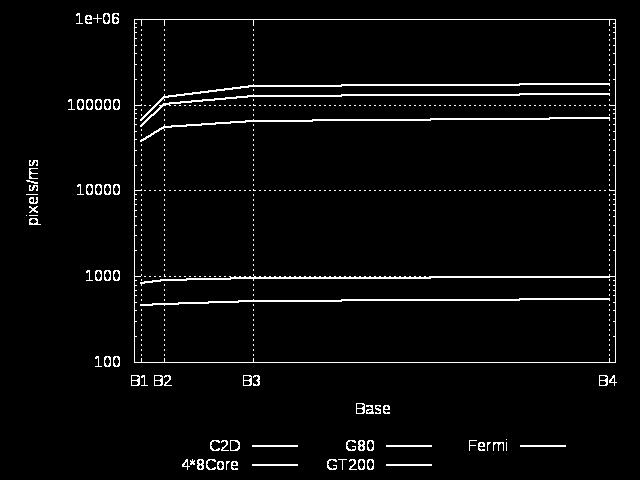
22 Testes de Desempenho
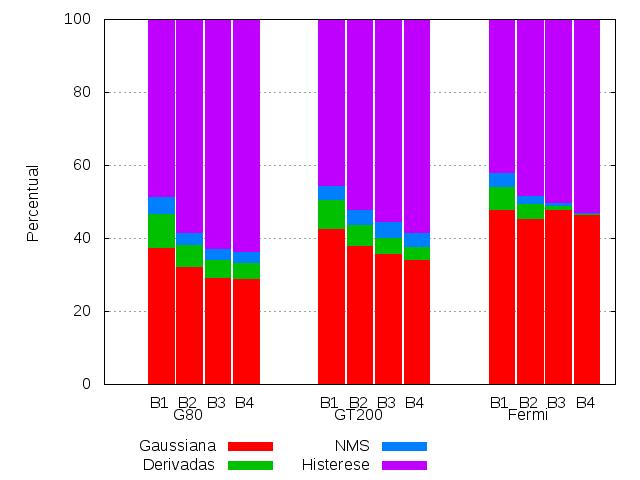

23 Testes de Desempenho
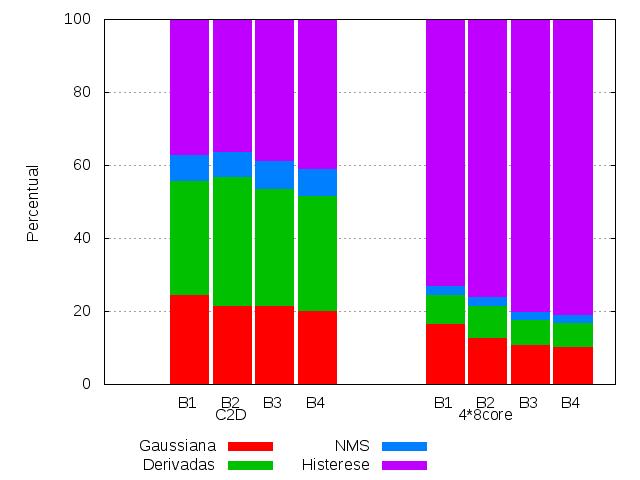

24 Testes de Desempenho
 1.06 (0.3%) 0.77 (0.1%) 1.B) Troca as posições durante a leitura e não na escrita. 7.88 (0.4%) 1.07 (0.5) 0.8 (0.2%) 1.C) Uso de cache de Textura. 0.88 (0.7%) 0.60 (1.1%) 0.")
25 Teste de Algoritmo: Acessos à Memória Descrição/Implementações Tempo de Exec. em ms (desvio padrão) G80 GT200 Fermi 1.A) Troca elementos de um vetor a cada 2 posições (0.2%) 1.06 (0.3%) 0.77 (0.1%) 1.B) Troca as posições durante a leitura e não na escrita (0.4%) 1.07 (0.5) 0.8 (0.2%) 1.C) Uso de cache de Textura (0.7%) 0.60 (1.1%) 0.48 (0.4%)
![Teste de Algoritmo: Serialização de Warps e Acessos à Memória Descrição/Implementações 2.A) Calcula 2 in[i 1] + in[i+1] Tempo de Exec. em ms (desvio padrão) G80 GT200 Fermi 2 14.](/docs-images/82/86801936/images/26-1.jpg "86 (0.2%) 2.3 (0.1%) 0.95 (2.8%) 2.B) Uso de cache de Textura. 2.21 (0.3%) 1.19 (1%) 0.99 (0.4%) 2.C) Calcula posições com expressões lógicas. 1.69 (0.4%) 1.08 (0.2%) 0.95 (0.")
26 Teste de Algoritmo: Serialização de Warps e Acessos à Memória Descrição/Implementações 2.A) Calcula 2 in[i 1] + in[i+1] Tempo de Exec. em ms (desvio padrão) G80 GT200 Fermi (0.2%) 2.3 (0.1%) 0.95 (2.8%) 2.B) Uso de cache de Textura (0.3%) 1.19 (1%) 0.99 (0.4%) 2.C) Calcula posições com expressões lógicas (0.4%) 1.08 (0.2%) 0.95 (0.1%)
 G80 GT200 Fermi 3.A) Calcula dir.x+dir.y 2.56 (0.1%) 1.25 (0.8%) 1.05 (0.09%) 3.")
27 Teste de Algoritmo: Serialização de Warps e Expressões Lógicas Descrição/Implementações Tempo de Exec. em ms (desvio padrão) G80 GT200 Fermi 3.A) Calcula dir.x+dir.y 2.56 (0.1%) 1.25 (0.8%) 1.05 (0.09%) 3.B) Calcula valores com expressões lógicas (0.2%) 1.07 (0.5%) 0.83 (0.5%)
 G80 GT200 Fermi out[idx] in[idx] + 1 4.A) N Th = 5, N Bl = 20000 0.17 (0.9%) 0.14 (1.5%) 0.17 (0.6%) 4.")
28 Teste de Algoritmo: Configuração de Blocos e Grid Descrição/Implementações Tempo de Exec. em ms (desvio padrão) G80 GT200 Fermi out[idx] in[idx] A) N Th = 5, N Bl = (0.9%) 0.14 (1.5%) 0.17 (0.6%) 4.B) N Th = 256, N Bl = (3.0%) 0.04 (8.2%) 0.03 (3.5%)
29 Conclusão CudaCanny, CudaDiscreteGaussian, CudaZeroCrossing, CudaSobel, itkcudainterface É possivel reduzir o tempo de execução de filtros de processamento de imagens do ITK usando CUDA Qualidade e Desempenho do CudaCanny Dificuldade de implementar operações globais Transferências entre as memórias O paralelismo das placas gráficas deve ser implementado no ITK4
30 Trabalhos Futuros Reimplementar o CudaCanny tornando-o mais genérico Novas funcionalidades para o itkcudainterface Comparação com outras abordagens (OpenMP, SSE, OpenCL, FPGA) Comparação entre modelos de programação distintos
Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot
 Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Tomás Evalero Orellana Universidade Estadual de Santa Cruz Roteiro Breve introdução
Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Tomás Evalero Orellana Universidade Estadual de Santa Cruz Roteiro Breve introdução
Aplicações em CUDA. Medialab Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center
 Aplicações em CUDA Medialab Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center Roteiro l Introdução l Eventos l Aspectos históricos l Operações atômicas l Introdução sobre
Aplicações em CUDA Medialab Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center Roteiro l Introdução l Eventos l Aspectos históricos l Operações atômicas l Introdução sobre
Introdução a CUDA. Esteban Walter Gonzalez Clua. Medialab - Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center START
 Introdução a CUDA START Esteban Walter Gonzalez Clua Medialab - Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center 1536 cores Dynamic Parallelism Hyper - Q Pipeline
Introdução a CUDA START Esteban Walter Gonzalez Clua Medialab - Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center 1536 cores Dynamic Parallelism Hyper - Q Pipeline
Paradigmas de Processamento Paralelo na Resolução do Fractal de Mandelbrot
 Paradigmas de Processamento Paralelo na Resolução do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Universidade Estadual de Santa Cruz Cronograma Introdução Serial vs Processamento
Paradigmas de Processamento Paralelo na Resolução do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Universidade Estadual de Santa Cruz Cronograma Introdução Serial vs Processamento
Computação Paralela (CUDA)
") Universidade Federal do Amazonas Faculdade de Tecnologia Departamento de Eletrônica e Computação Computação Paralela (CUDA) Hussama Ibrahim hussamaibrahim@ufam.edu.br Notas de Aula Baseado nas Notas de
Universidade Federal do Amazonas Faculdade de Tecnologia Departamento de Eletrônica e Computação Computação Paralela (CUDA) Hussama Ibrahim hussamaibrahim@ufam.edu.br Notas de Aula Baseado nas Notas de
5 Unidades de Processamento Gráfico GPUs
 5 Unidades de Processamento Gráfico GPUs As GPUs são processadores maciçamente paralelos, com múltiplos elementos de processamento, tipicamente utilizadas como aceleradores de computação. Elas fornecem
5 Unidades de Processamento Gráfico GPUs As GPUs são processadores maciçamente paralelos, com múltiplos elementos de processamento, tipicamente utilizadas como aceleradores de computação. Elas fornecem
Fabrício Gomes Vilasbôas
 Fabrício Gomes Vilasbôas Apresentação Placas Arquitetura Toolkit e Ferramentas de Debug Pensando em CUDA Programação CUDA Python Programação PyCUDA 1) Grids( padrão Globus) 2) Clusters ( padrão MPI) 3)
Fabrício Gomes Vilasbôas Apresentação Placas Arquitetura Toolkit e Ferramentas de Debug Pensando em CUDA Programação CUDA Python Programação PyCUDA 1) Grids( padrão Globus) 2) Clusters ( padrão MPI) 3)
Sparse Matrix-Vector Multiplication on GPU: When Is Rows Reordering Worthwhile?
 Sparse Matrix-Vector Multiplication on GPU: When Is Rows Reordering Worthwhile? Paula Prata João Muranho Instituto de Telecomunicações Departamento de Informática Universidade da Beira Interior Instituto
Sparse Matrix-Vector Multiplication on GPU: When Is Rows Reordering Worthwhile? Paula Prata João Muranho Instituto de Telecomunicações Departamento de Informática Universidade da Beira Interior Instituto
Processamento Paralelo Utilizando GPU
 Processamento Paralelo Utilizando GPU Universidade Estadual de Santa Cruz Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Evalero Orellana Cronograma Breve introdução sobre processamento paralelo
Processamento Paralelo Utilizando GPU Universidade Estadual de Santa Cruz Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Evalero Orellana Cronograma Breve introdução sobre processamento paralelo
Introdução ao CUDA. Material elaborado por Davi Conte.
 Introdução ao CUDA Material elaborado por Davi Conte. O objetivo deste material é que o aluno possa iniciar seus conhecimentos em programação paralela, entendendo a diferença da execução de forma sequencial
Introdução ao CUDA Material elaborado por Davi Conte. O objetivo deste material é que o aluno possa iniciar seus conhecimentos em programação paralela, entendendo a diferença da execução de forma sequencial
UNIVERSIDADE FEDERAL DO PARANÁ LUIS HENRIQUE ALVES LOURENÇO PARALELIZAÇÃO DO DETECTOR DE BORDAS CANNY PARA A BIBLIOTECA ITK UTILIZANDO CUDA
 UNIVERSIDADE FEDERAL DO PARANÁ LUIS HENRIQUE ALVES LOURENÇO PARALELIZAÇÃO DO DETECTOR DE BORDAS CANNY PARA A BIBLIOTECA ITK UTILIZANDO CUDA CURITIBA 2011 LUIS HENRIQUE ALVES LOURENÇO PARALELIZAÇÃO DO DETECTOR
UNIVERSIDADE FEDERAL DO PARANÁ LUIS HENRIQUE ALVES LOURENÇO PARALELIZAÇÃO DO DETECTOR DE BORDAS CANNY PARA A BIBLIOTECA ITK UTILIZANDO CUDA CURITIBA 2011 LUIS HENRIQUE ALVES LOURENÇO PARALELIZAÇÃO DO DETECTOR
Eng. Thársis T. P. Souza
 Introdução à Computação de Alto Desempenho Utilizando GPU Seminário de Programação em GPGPU Eng. Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo Introdução
Introdução à Computação de Alto Desempenho Utilizando GPU Seminário de Programação em GPGPU Eng. Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo Introdução
3 Computação de Propósito Geral em Unidades de Processamento Gráfico
 3 Computação de Propósito Geral em Unidades de Processamento Gráfico As Unidades de Processamento Gráfico (GPUs) foram originalmente desenvolvidas para o processamento de gráficos e eram difíceis de programar.
3 Computação de Propósito Geral em Unidades de Processamento Gráfico As Unidades de Processamento Gráfico (GPUs) foram originalmente desenvolvidas para o processamento de gráficos e eram difíceis de programar.
Processamento Sísmico de Alto Desempenho na Petrobras
 Processamento Sísmico de Alto Desempenho na Petrobras Thiago Teixeira E&P-Exp/Geof/Tecnologia Geofísica Julho/2011 Processamento Sísmico e Interpretação 2 Aquisição Sísmica Linhas Sísmicas Volumes de dados
Processamento Sísmico de Alto Desempenho na Petrobras Thiago Teixeira E&P-Exp/Geof/Tecnologia Geofísica Julho/2011 Processamento Sísmico e Interpretação 2 Aquisição Sísmica Linhas Sísmicas Volumes de dados
Celso L. Mendes LAC /INPE
 Arquiteturas para Processamento de Alto Desempenho (PAD) Aula 9 Celso L. Mendes LAC /INPE Email: celso.mendes@inpe.br Aula 9 (3/5): E. Aceleradores Estrutura Planejada i. Estruturas mais Populares ii.
Arquiteturas para Processamento de Alto Desempenho (PAD) Aula 9 Celso L. Mendes LAC /INPE Email: celso.mendes@inpe.br Aula 9 (3/5): E. Aceleradores Estrutura Planejada i. Estruturas mais Populares ii.
Comparação de eficiência entre OpenCL e CUDA
 Aluno: Thiago de Gouveia Nunes Orientador: Prof. Marcel P. Jackowski GPGPU O que é GPGPU? É programação de propósito geral em GPUs. =D GPGPU Existem 2 linguagens populares no mercado para GPGPU, o CUDA
Aluno: Thiago de Gouveia Nunes Orientador: Prof. Marcel P. Jackowski GPGPU O que é GPGPU? É programação de propósito geral em GPUs. =D GPGPU Existem 2 linguagens populares no mercado para GPGPU, o CUDA
Hierarquia de memória:
 INE5645 Programação Paralela e Distribuída Aluno Modelo de Execução CUDA - A execução do programa controlado pela CPU pode lançar kernels, que são trechos de código executados em paralelo por múltiplas
INE5645 Programação Paralela e Distribuída Aluno Modelo de Execução CUDA - A execução do programa controlado pela CPU pode lançar kernels, que são trechos de código executados em paralelo por múltiplas
Arquiteturas de Computadores
 Arquiteturas de Computadores Computadores vetoriais Fontes dos slides: Livro Patterson e Hennessy, Quantitative Approach e site do curso EE 7722, GPU Microarchitecture do Prof. David Koppelman Graphical
Arquiteturas de Computadores Computadores vetoriais Fontes dos slides: Livro Patterson e Hennessy, Quantitative Approach e site do curso EE 7722, GPU Microarchitecture do Prof. David Koppelman Graphical
Memory-level and Thread-level Parallelism Aware GPU Architecture Performance Analytical Model
 Memory-level and Thread-level Parallelism Aware GPU Architecture Performance Analytical Model Sunpyo Hong Hyesoon Kim ECE School of Computer Science Georgia Institute of Technology April 6, 2011 Visão
Memory-level and Thread-level Parallelism Aware GPU Architecture Performance Analytical Model Sunpyo Hong Hyesoon Kim ECE School of Computer Science Georgia Institute of Technology April 6, 2011 Visão
Aplicação de Processamento Paralelo com GPU a Problemas de Escoamento Monofásico em Meios Porosos. Bruno Pereira dos Santos Dany Sanchez Dominguez
 Aplicação de Processamento Paralelo com GPU a Problemas de Escoamento Monofásico em Meios Porosos Bruno Pereira dos Santos Dany Sanchez Dominguez 1 Roteiro 1. Introdução 2. Five-Spot Problem 3. Modelagem
Aplicação de Processamento Paralelo com GPU a Problemas de Escoamento Monofásico em Meios Porosos Bruno Pereira dos Santos Dany Sanchez Dominguez 1 Roteiro 1. Introdução 2. Five-Spot Problem 3. Modelagem
de petróleo. Um novo domínio chamado computação de propósito geral em processadores gráficos (GPGPU) surgiu quando os pipelines de gráficos de
 surgiu quando os pipelines de gráficos de") 12 1 1.1. Motivações Dentre os tipos de técnicas de Inteligência Artificial existentes, as técnicas de Programação Genética (PG) continuam mudando rapidamente conforme os pesquisadores e profissionais
12 1 1.1. Motivações Dentre os tipos de técnicas de Inteligência Artificial existentes, as técnicas de Programação Genética (PG) continuam mudando rapidamente conforme os pesquisadores e profissionais
Processamento de áudio em tempo real utilizando dispositivos não convencionais:
 Processamento de áudio em tempo real utilizando dispositivos não convencionais: Processamento paralelo com Pure Data e GPU. André Jucovsky Bianchi ajb@ime.usp.br Departamento de Ciência da Computação Instituto
Processamento de áudio em tempo real utilizando dispositivos não convencionais: Processamento paralelo com Pure Data e GPU. André Jucovsky Bianchi ajb@ime.usp.br Departamento de Ciência da Computação Instituto
Clusterização K-Means Paralelo Aplicado na Classificação de Alvos em Imagens de Alta Resolução
 Clusterização K-Means Paralelo Aplicado na Classificação de Alvos em Imagens de Alta Resolução Luís Paulo Manfré Ribeiro luis.ribeiro@inpe.br Instituto Nacional de Pesquisas Espaciais - INPE São José dos
Clusterização K-Means Paralelo Aplicado na Classificação de Alvos em Imagens de Alta Resolução Luís Paulo Manfré Ribeiro luis.ribeiro@inpe.br Instituto Nacional de Pesquisas Espaciais - INPE São José dos
CUDA: Compute Unified Device Architecture. Marco Antonio Simões Teixeira
 CUDA: Compute Unified Device Architecture Marco Antonio Simões Teixeira Sumário Introdução; CUDA: História; CUDA: programando; CUDA e deep learning; Links úteis; Considerações finais. 2 INTRODUÇÃO 3 O
CUDA: Compute Unified Device Architecture Marco Antonio Simões Teixeira Sumário Introdução; CUDA: História; CUDA: programando; CUDA e deep learning; Links úteis; Considerações finais. 2 INTRODUÇÃO 3 O
Introdução à Programação Paralela através de Padrões. Denise Stringhini Calebe Bianchini Luciano Silva
 Introdução à Programação Paralela através de Padrões Denise Stringhini Calebe Bianchini Luciano Silva Sumário Introdução: conceitos de paralelismo Conceitos básicos sobre padrões de programação paralela
Introdução à Programação Paralela através de Padrões Denise Stringhini Calebe Bianchini Luciano Silva Sumário Introdução: conceitos de paralelismo Conceitos básicos sobre padrões de programação paralela
Programação em Paralelo. N. Cardoso & P. Bicudo. Física Computacional - MEFT 2010/2011
 Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 11 CUDA Parte 2 N. Cardoso & P. Bicudo Programação em
Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 11 CUDA Parte 2 N. Cardoso & P. Bicudo Programação em
What is? Eduardo Viola Nicola Disciplina de IPPD
 What is? Eduardo Viola Nicola evnicola@inf.ufpel.edu.br Disciplina de IPPD Sumário 1)Introdução 2)Princípio Geral de Funcionamento 3)Exemplos de Aplicações 4)Modelo de Programação 5)Linguagens Suportadas
What is? Eduardo Viola Nicola evnicola@inf.ufpel.edu.br Disciplina de IPPD Sumário 1)Introdução 2)Princípio Geral de Funcionamento 3)Exemplos de Aplicações 4)Modelo de Programação 5)Linguagens Suportadas
Arquitetura e Programação de GPU. Leandro Zanotto RA: 001962 Anselmo Ferreira RA: 023169 Marcelo Matsumoto RA: 085973
 Arquitetura e Programação de GPU Leandro Zanotto RA: 001962 Anselmo Ferreira RA: 023169 Marcelo Matsumoto RA: 085973 Agenda Primeiras Placas de Vídeo Primeira GPU Arquitetura da GPU NVIDIA Arquitetura
Arquitetura e Programação de GPU Leandro Zanotto RA: 001962 Anselmo Ferreira RA: 023169 Marcelo Matsumoto RA: 085973 Agenda Primeiras Placas de Vídeo Primeira GPU Arquitetura da GPU NVIDIA Arquitetura
Thársis T. P. Souza
 Computação em Finanças em Hardware Gráfico SEMAC 2012 - UNESP Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo GPU Computing CUDA Aplicações em Finanças
Computação em Finanças em Hardware Gráfico SEMAC 2012 - UNESP Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo GPU Computing CUDA Aplicações em Finanças
Jônatas Lopes de Paiva Instituto de Matemática e Estatística Universidade de São Paulo. 06 de maio de 2011
 Jônatas Lopes de Paiva jlp@ime.usp.br Instituto de Matemática e Estatística Universidade de São Paulo 06 de maio de 2011 Introdução String-matching O que é? Em que é utilizado Tipos GPU GPGPU String-matching
Jônatas Lopes de Paiva jlp@ime.usp.br Instituto de Matemática e Estatística Universidade de São Paulo 06 de maio de 2011 Introdução String-matching O que é? Em que é utilizado Tipos GPU GPGPU String-matching
Patrício Domingues Dep. Eng. Informática ESTG Instituto Politécnico de Leiria Leiria, Maio Programação Genérica de GPUs
 Patrício Domingues Dep. Eng. Informática ESTG Instituto Politécnico de Leiria Leiria, Maio 2012 http://bit.ly/patricio Programação Genérica de GPUs 1 CUDA Teaching Center A ESTG/IPLeiria é um CUDA Teaching
Patrício Domingues Dep. Eng. Informática ESTG Instituto Politécnico de Leiria Leiria, Maio 2012 http://bit.ly/patricio Programação Genérica de GPUs 1 CUDA Teaching Center A ESTG/IPLeiria é um CUDA Teaching
Análise de Desempenho da Paralelização do Problema de Caixeiro Viajante
 Análise de Desempenho da Paralelização do Problema de Caixeiro Viajante Gabriel Freytag Guilherme Arruda Rogério S. M. Martins Edson L. Padoin Universidade Regional do Noroeste do Estado do Rio Grande
Análise de Desempenho da Paralelização do Problema de Caixeiro Viajante Gabriel Freytag Guilherme Arruda Rogério S. M. Martins Edson L. Padoin Universidade Regional do Noroeste do Estado do Rio Grande
MC4: Introdução à Programação Paralela em GPU para a Implementação de Métodos Numéricos
 MC4: Introdução à Programação Paralela em GPU para a Implementação de Métodos Numéricos Aula 1: Introdução à programação paralela e ao ambiente de programação CUDA Profs.: Daniel Alfaro e Silvana Rossetto
MC4: Introdução à Programação Paralela em GPU para a Implementação de Métodos Numéricos Aula 1: Introdução à programação paralela e ao ambiente de programação CUDA Profs.: Daniel Alfaro e Silvana Rossetto
Programação em Paralelo. N. Cardoso & P. Bicudo. Física Computacional - MEFT 2010/2011
 Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 12 CUDA Parte 3 N. Cardoso & P. Bicudo Programação em
Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 12 CUDA Parte 3 N. Cardoso & P. Bicudo Programação em
Proposta de Melhoria de uma Implementação Paralela para GPUs Usando CUDA - Estudo de Caso em Modelo Atmosférico
 Proposta de Melhoria de uma Implementação Paralela para GPUs Usando CUDA - Estudo de Caso em Modelo Atmosférico Fabiano Cassol de Vargas, Matheus Beniz Bieger, Claudio Schepke 1 Laboratório de Estudos
Proposta de Melhoria de uma Implementação Paralela para GPUs Usando CUDA - Estudo de Caso em Modelo Atmosférico Fabiano Cassol de Vargas, Matheus Beniz Bieger, Claudio Schepke 1 Laboratório de Estudos
GPU (Graphics Processing Unit) Bruno Padilha Gregory De Bonis Luciana Kayo
 Bruno Padilha Gregory De Bonis Luciana Kayo") GPU (Graphics Processing Unit) Bruno Padilha - 5745282 Gregory De Bonis - 6431180 Luciana Kayo - 6430992 O que é? O que é? - Processador auxiliar responsável principalmente por operações de ponto flutuante
GPU (Graphics Processing Unit) Bruno Padilha - 5745282 Gregory De Bonis - 6431180 Luciana Kayo - 6430992 O que é? O que é? - Processador auxiliar responsável principalmente por operações de ponto flutuante
COMPUTAÇÃO PARALELA COM ACELERADORES GPGPU 1. Emilio Hoffmann De Oliveira 2, Edson Luiz Padoin 3.
 COMPUTAÇÃO PARALELA COM ACELERADORES GPGPU 1 Emilio Hoffmann De Oliveira 2, Edson Luiz Padoin 3. 1 Trabalho de Conclusão de Curso 2 Aluno do Curso de Ciência da Computação - emiliohoffmann@hotmail.com
COMPUTAÇÃO PARALELA COM ACELERADORES GPGPU 1 Emilio Hoffmann De Oliveira 2, Edson Luiz Padoin 3. 1 Trabalho de Conclusão de Curso 2 Aluno do Curso de Ciência da Computação - emiliohoffmann@hotmail.com
Conversão de algoritmos de processamento e análise de dados atmosféricos da linguagem C para CUDA
 Conversão de algoritmos de processamento e análise de dados atmosféricos da linguagem C para CUDA Bruno Nocera Zanette - brunonzanette@gmail.com Prof. Fabiano Silva - fabiano@inf.ufpr.br Uma análise do
Conversão de algoritmos de processamento e análise de dados atmosféricos da linguagem C para CUDA Bruno Nocera Zanette - brunonzanette@gmail.com Prof. Fabiano Silva - fabiano@inf.ufpr.br Uma análise do
DESENVOLVIMENTO DE UM ALGORITMO PARALELO PARA APLICAÇÃO EM CLUSTER DE COMPUTADORES
 DESENVOLVIMENTO DE UM ALGORITMO PARALELO PARA APLICAÇÃO EM CLUSTER DE COMPUTADORES João Ricardo Kohler Abramoski (PAIC/FUNDAÇÃO ARAUCÁRIA), Sandra Mara Guse Scós Venske (Orientadora), e-mail: ssvenske@unicentro.br
DESENVOLVIMENTO DE UM ALGORITMO PARALELO PARA APLICAÇÃO EM CLUSTER DE COMPUTADORES João Ricardo Kohler Abramoski (PAIC/FUNDAÇÃO ARAUCÁRIA), Sandra Mara Guse Scós Venske (Orientadora), e-mail: ssvenske@unicentro.br
Tópicos em Física Computacional: Introdução a Linguagem CUDA
 Tópicos em Física Computacional: Introdução a Linguagem CUDA Aula 06: Introdução a Linguagem CUDA Otimização do Código Carine P. Beatrici IF UFRGS 1 Da Aula Passada... Programa que soma matrizes linearizadas;
Tópicos em Física Computacional: Introdução a Linguagem CUDA Aula 06: Introdução a Linguagem CUDA Otimização do Código Carine P. Beatrici IF UFRGS 1 Da Aula Passada... Programa que soma matrizes linearizadas;
Brilliant Solutions for a Safe World
 IDENTIFICAÇÃO DE FACE E RASTREAMENTO DE MOVIMENTO PARA SISTEMAS DE GERENCIAMENTO DE VÍDEO (VMS) SentiVeillance Server é um software de identificação biométrica de faces e rastreamento de movimento pronto
IDENTIFICAÇÃO DE FACE E RASTREAMENTO DE MOVIMENTO PARA SISTEMAS DE GERENCIAMENTO DE VÍDEO (VMS) SentiVeillance Server é um software de identificação biométrica de faces e rastreamento de movimento pronto
Comparação das Características de Simuladores de Arquiteturas Heterogêneas
 Comparação das Características de Simuladores de Arquiteturas Heterogêneas Felipe Leivas Teixeira Andrei Silva Carlos Vinícius Rasch Alves Vinícius Krolow da Silva Prof. Dr. Maurício Lima Pilla (Orientador)
Comparação das Características de Simuladores de Arquiteturas Heterogêneas Felipe Leivas Teixeira Andrei Silva Carlos Vinícius Rasch Alves Vinícius Krolow da Silva Prof. Dr. Maurício Lima Pilla (Orientador)
Implementação de um escalonador de processos em GPU
 Implementação de um escalonador de processos em GPU Guilherme Martins guilhermemartins@usp.br 6 de abril de 2017 Guilherme Martins (guilhermemartins@usp.br) Implementação de um escalonador de processos
Implementação de um escalonador de processos em GPU Guilherme Martins guilhermemartins@usp.br 6 de abril de 2017 Guilherme Martins (guilhermemartins@usp.br) Implementação de um escalonador de processos
PARALELIZAÇÃO DO ALGORITMO AES E ANÁLISE SOBRE GPGPU 1 PARALLELIZATION OF AES ALGORITHM AND GPU ANALYSIS
 Disciplinarum Scientia. Série: Naturais e Tecnológicas, Santa Maria, v. 16, n. 1, p. 83-94, 2015. Recebido em: 11.04.2015. Aprovado em: 30.06.2015. ISSN 2176-462X PARALELIZAÇÃO DO ALGORITMO AES E ANÁLISE
Disciplinarum Scientia. Série: Naturais e Tecnológicas, Santa Maria, v. 16, n. 1, p. 83-94, 2015. Recebido em: 11.04.2015. Aprovado em: 30.06.2015. ISSN 2176-462X PARALELIZAÇÃO DO ALGORITMO AES E ANÁLISE
Bacharelado em Sistemas de Informação Sistemas Operacionais. Prof. Filipo Mór
 Bacharelado em Sistemas de Informação Sistemas Operacionais Prof. Filipo Mór WWW.FILIPOMOR.COM - REVISÃO ARQUITETURAS PARALELAS Evolução das Arquiteturas Evolução das Arquiteturas Entrada CPU Saída von
Bacharelado em Sistemas de Informação Sistemas Operacionais Prof. Filipo Mór WWW.FILIPOMOR.COM - REVISÃO ARQUITETURAS PARALELAS Evolução das Arquiteturas Evolução das Arquiteturas Entrada CPU Saída von
API para transformação de imagem em cartum utilizando plataforma ios. Acadêmico Christian Hess Orientador Dalton Solano dos Reis
 API para transformação de imagem em cartum utilizando plataforma ios Acadêmico Christian Hess Orientador Dalton Solano dos Reis Roteiro da apresentação Introdução Fundamentação teórica Desenvolvimento
API para transformação de imagem em cartum utilizando plataforma ios Acadêmico Christian Hess Orientador Dalton Solano dos Reis Roteiro da apresentação Introdução Fundamentação teórica Desenvolvimento
ANÁLISE DE DESEMPENHO COM A PARALELIZAÇÃO DO CÁLCULO DE NÚMEROS PERFEITOS 1
 ANÁLISE DE DESEMPENHO COM A PARALELIZAÇÃO DO CÁLCULO DE NÚMEROS PERFEITOS 1 Éder Paulo Pereira 2, Gilberto Przygoda Marmitt 3, Emilio Hoffmann De Oliveira 4, Edson Luiz Padoin 5, Carlos Eduardo Das Chagas
ANÁLISE DE DESEMPENHO COM A PARALELIZAÇÃO DO CÁLCULO DE NÚMEROS PERFEITOS 1 Éder Paulo Pereira 2, Gilberto Przygoda Marmitt 3, Emilio Hoffmann De Oliveira 4, Edson Luiz Padoin 5, Carlos Eduardo Das Chagas
A IMPORTÂNCIA DE THREADS NO DESEMPENHO DE APLICAÇÕES
 A IMPORTÂNCIA DE THREADS NO DESEMPENHO DE APLICAÇÕES Euzébio da Costa Silva 1, Victor Pereira Ribeiro 2, Susana Brunoro Costa de Oliveira 3 1 29520-000, euzebioprogramacao@gmail.com 2 29520-000, victor3ifes@gmail.com
A IMPORTÂNCIA DE THREADS NO DESEMPENHO DE APLICAÇÕES Euzébio da Costa Silva 1, Victor Pereira Ribeiro 2, Susana Brunoro Costa de Oliveira 3 1 29520-000, euzebioprogramacao@gmail.com 2 29520-000, victor3ifes@gmail.com
PARALELIZAÇÃO DE APLICAÇÕES NA ARQUITETURA CUDA: UM ESTUDO SOBRE VETORES 1
 PARALELIZAÇÃO DE APLICAÇÕES NA ARQUITETURA CUDA: UM ESTUDO SOBRE VETORES 1 DUTRA, Evandro Rogério Fruhling 2 ; VARINI, Andre Luis 2 ; CANAL, Ana Paula 2 1 Trabalho de Iniciação Científica _UNIFRA 2 Ciência
PARALELIZAÇÃO DE APLICAÇÕES NA ARQUITETURA CUDA: UM ESTUDO SOBRE VETORES 1 DUTRA, Evandro Rogério Fruhling 2 ; VARINI, Andre Luis 2 ; CANAL, Ana Paula 2 1 Trabalho de Iniciação Científica _UNIFRA 2 Ciência
INE 5645 PROGRAMAÇÃO PARALELA E DISTRIBUIDA PROVA 2 13/11/2017 ALUNO
 INE 5645 PROGRAMAÇÃO PARALELA E DISTRIBUIDA PROVA 2 13/11/2017 ALUNO 1. Sockets - Indicar (Verdade/Falso): (2.0) (a) (Verdade/Falso) A comunicação entre processos consiste em transmitir uma mensagem entre
INE 5645 PROGRAMAÇÃO PARALELA E DISTRIBUIDA PROVA 2 13/11/2017 ALUNO 1. Sockets - Indicar (Verdade/Falso): (2.0) (a) (Verdade/Falso) A comunicação entre processos consiste em transmitir uma mensagem entre
AGA 511. Métodos Computacionais em Astronomia. Segundo semestre de 2017
 AGA 511 Métodos Computacionais em Astronomia Segundo semestre de 2017 Informações gerais Prof. Alex Cavaliéri Carciofi Email: carciofi@usp.br Ramal: 2712 Colaborador: Carlos Eduardo Paladini Email: carlos.paladini@iag.usp.br
AGA 511 Métodos Computacionais em Astronomia Segundo semestre de 2017 Informações gerais Prof. Alex Cavaliéri Carciofi Email: carciofi@usp.br Ramal: 2712 Colaborador: Carlos Eduardo Paladini Email: carlos.paladini@iag.usp.br
Aplicando Processamento Paralelo com GPU ao Problema do Fractal de Mandelbrot
 Aplicando Processamento Paralelo com GPU ao Problema do Fractal de Mandelbrot Bruno Pereira dos Santos¹, Dany Sanchez Dominguez¹, Esbel Valero Orellana¹. 1 Departamento de Ciências Exatas e Tecnológicas
Aplicando Processamento Paralelo com GPU ao Problema do Fractal de Mandelbrot Bruno Pereira dos Santos¹, Dany Sanchez Dominguez¹, Esbel Valero Orellana¹. 1 Departamento de Ciências Exatas e Tecnológicas
Patricia Akemi Ikeda
 Um estudo do uso eficiente de programas em placas gráficas Patricia Akemi Ikeda Dissertação apresentada ao Instituto de Matemática e Estatística da Universidade de São Paulo para obtenção do título de
Um estudo do uso eficiente de programas em placas gráficas Patricia Akemi Ikeda Dissertação apresentada ao Instituto de Matemática e Estatística da Universidade de São Paulo para obtenção do título de
Computação científica utilizando placas gráficas
 Brasília, dezembro de 2008 Universidade de Brasília - Faculdade do Gama Sumário Introdução Sumário Introdução Arquitetura da GPU Sumário Introdução Arquitetura da GPU Modelo de programação Sumário Introdução
Brasília, dezembro de 2008 Universidade de Brasília - Faculdade do Gama Sumário Introdução Sumário Introdução Arquitetura da GPU Sumário Introdução Arquitetura da GPU Modelo de programação Sumário Introdução
Relatório de Atividades Desenvolvidas. Uso de GPU para Aceleração de Simulações Atmosféricas com o Modelo CCATT BRAMS.
 Relatório de Atividades Desenvolvidas Uso de GPU para Aceleração de Simulações Atmosféricas com o Modelo CCATT BRAMS. 1 Cezar Augusto Contini Bernardi 2 Haroldo Fraga de Campos Velho Coordenador Bolsista
Relatório de Atividades Desenvolvidas Uso de GPU para Aceleração de Simulações Atmosféricas com o Modelo CCATT BRAMS. 1 Cezar Augusto Contini Bernardi 2 Haroldo Fraga de Campos Velho Coordenador Bolsista
XV ESCOLA REGIONAL DE ALTO DESEMPENHO ERAD 2015
 XV ESCOLA REGIONAL DE ALTO DESEMPENHO ERAD 2015 Impacto das Interfaces de Programação Paralela e do Grau de Paralelismo no Consumo Energético de uma Aplicação Thayson R. Karlinski, Arthur F. Lorenzon,
XV ESCOLA REGIONAL DE ALTO DESEMPENHO ERAD 2015 Impacto das Interfaces de Programação Paralela e do Grau de Paralelismo no Consumo Energético de uma Aplicação Thayson R. Karlinski, Arthur F. Lorenzon,
Infraestrutura de Hardware. Processamento Paralelo Multicores, Multi-Threading e GPUs
 Infraestrutura de Hardware Processamento Paralelo Multicores, Multi-Threading e GPUs Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é entendido
Infraestrutura de Hardware Processamento Paralelo Multicores, Multi-Threading e GPUs Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é entendido
Ambientes e Ferramentas de Programação para GPU. Denise Stringhini (Mackenzie) Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP)
 Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP)") Ambientes e Ferramentas de Programação para GPU Denise Stringhini (Mackenzie) Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP) Conteúdo Conceitos de paralelismo Arquitetura de GPU CUDA OpenCL
Ambientes e Ferramentas de Programação para GPU Denise Stringhini (Mackenzie) Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP) Conteúdo Conceitos de paralelismo Arquitetura de GPU CUDA OpenCL
A Utilização da Tecnologia CUDA para Processamento Paralelo de Algoritmos Genéticos
 A Utilização da Tecnologia CUDA para Processamento Paralelo de Algoritmos Genéticos Allan Ariel Leite Menezes Santos 1 1 Universidade do Estado da Bahia (UNEB) allan.ariel1987@gmail.com Abstract. The problem
A Utilização da Tecnologia CUDA para Processamento Paralelo de Algoritmos Genéticos Allan Ariel Leite Menezes Santos 1 1 Universidade do Estado da Bahia (UNEB) allan.ariel1987@gmail.com Abstract. The problem
Estudo de Técnicas de Otimização de Desempenho para GPUs Utilizando CUDA Aplicado a um Modelo Meteorológico
 Fabiano Cassol de Vargas Estudo de Técnicas de Otimização de Desempenho para GPUs Utilizando CUDA Aplicado a um Modelo Meteorológico Alegrete RS 08/2014 Fabiano Cassol de Vargas Estudo de Técnicas de
Fabiano Cassol de Vargas Estudo de Técnicas de Otimização de Desempenho para GPUs Utilizando CUDA Aplicado a um Modelo Meteorológico Alegrete RS 08/2014 Fabiano Cassol de Vargas Estudo de Técnicas de
5.1. Caso 1 Cálculo da Energia e Estrutura de Bandas de Nanotubos
 5 Estudo de Casos Neste capítulo, serão descritos os sistemas físicos e as suas propriedades calculadas com o objetivo comparar o desempenho computacional de uma GPU com o desempenho obtido com uma CPU.
5 Estudo de Casos Neste capítulo, serão descritos os sistemas físicos e as suas propriedades calculadas com o objetivo comparar o desempenho computacional de uma GPU com o desempenho obtido com uma CPU.
ARQUITETURA DE COMPUTADORES
 RCM00014 Haswell wafer ARQUITETURA DE COMPUTADORES Prof. Luciano Bertini Site: http://www.professores.uff.br/lbertini/ Objetivos do Curso Entendimento mais aprofundado do funcionamento
RCM00014 Haswell wafer ARQUITETURA DE COMPUTADORES Prof. Luciano Bertini Site: http://www.professores.uff.br/lbertini/ Objetivos do Curso Entendimento mais aprofundado do funcionamento
Implementação e investigação de algoritmos computacionais paralelos para caracterização de imagens radiológicas de mamografias
 Implementação e investigação de algoritmos computacionais paralelos para caracterização de imagens radiológicas de mamografias Matheu A. Batista dos Santos, Pedro Lima Oliveira, Marcelo Ossamu Honda Departamento
Implementação e investigação de algoritmos computacionais paralelos para caracterização de imagens radiológicas de mamografias Matheu A. Batista dos Santos, Pedro Lima Oliveira, Marcelo Ossamu Honda Departamento
Trabalho Obrigatório 2: Comparação de Mecanismos de Comunicação
 Kauê Soares da Silveira 171671 Trabalho Obrigatório 2: Comparação de Mecanismos de Comunicação INF01151 - Sistemas Operacionais II N Professor: Alexandre Carissimi UNIVERSIDADE FEDERAL DO RIO GRANDE DO
Kauê Soares da Silveira 171671 Trabalho Obrigatório 2: Comparação de Mecanismos de Comunicação INF01151 - Sistemas Operacionais II N Professor: Alexandre Carissimi UNIVERSIDADE FEDERAL DO RIO GRANDE DO
3 Fundamentos teóricos
 3 Fundamentos teóricos Este capítulo aborda os fundamentos teóricos importantes para o entendimento do algoritmo de segmentação desenvolvido nesta dissertação e exposto no capítulo 4. São apresentados
3 Fundamentos teóricos Este capítulo aborda os fundamentos teóricos importantes para o entendimento do algoritmo de segmentação desenvolvido nesta dissertação e exposto no capítulo 4. São apresentados
6 Resultados Estratégias Consideradas
 Resultados 38 6 Resultados Este capítulo mostra algumas estratégias consideradas antes de chegarmos ao sistema proposto, mostra também os resultados obtidos ilustrados por diversos experimentos computacionais,
Resultados 38 6 Resultados Este capítulo mostra algumas estratégias consideradas antes de chegarmos ao sistema proposto, mostra também os resultados obtidos ilustrados por diversos experimentos computacionais,
Auditoria de senhas em hardware paralelo com o John the Ripper O impacto das tecnologias de processamento paralelo na quebra de senhas
 Auditoria de senhas em hardware paralelo com o John the Ripper O impacto das tecnologias de processamento paralelo na quebra de senhas Claudio André claudio.andre@correios.net.br Motivação Seu computador
Auditoria de senhas em hardware paralelo com o John the Ripper O impacto das tecnologias de processamento paralelo na quebra de senhas Claudio André claudio.andre@correios.net.br Motivação Seu computador
1.1 Descrição do problema A programação genética (PG) é uma meta-heurística utilizada para gerar programas de computadores, de modo que o computador
 é uma meta-heurística utilizada para gerar programas de computadores, de modo que o computador") 1 Introdução 1.1 Descrição do problema A programação genética (PG) é uma meta-heurística utilizada para gerar programas de computadores, de modo que o computador possa resolver problemas de forma automática
1 Introdução 1.1 Descrição do problema A programação genética (PG) é uma meta-heurística utilizada para gerar programas de computadores, de modo que o computador possa resolver problemas de forma automática
Uma introdução para computação paralela de modelos massivos. Adriano Brito Pereira inf.puc-rio.br
 Uma introdução para computação paralela de modelos massivos Adriano Brito Pereira 1021752 apereira @ inf.puc-rio.br Departamento de Informática Novembro / 2010 1 Resultados obtivos com Manta Framework
Uma introdução para computação paralela de modelos massivos Adriano Brito Pereira 1021752 apereira @ inf.puc-rio.br Departamento de Informática Novembro / 2010 1 Resultados obtivos com Manta Framework
LEAPFROG EDGE Página 1
 LEAPFROG EDGE Página 1 Este documento descreve as melhorias e os principais novos recursos inseridos no Leapfrog EDGE 2.0. Para mais informações, contate sua equipe local da Leapfrog.. Índice Página 2
LEAPFROG EDGE Página 1 Este documento descreve as melhorias e os principais novos recursos inseridos no Leapfrog EDGE 2.0. Para mais informações, contate sua equipe local da Leapfrog.. Índice Página 2
FACULDADE FARIAS BRITO
 FACULDADE FARIAS BRITO CIÊNCIA DA COMPUTAÇÃO ALBERTO ANTUNES BEZERRA MARTINS TECNOLOGIAS DE PROCESSAMENTO PARALELO GPGPU: UM ESTUDO DE CASO USANDO O ALGORITMO DE CONVOLUÇÃO Fortaleza 2013 ALBERTO ANTUNES
FACULDADE FARIAS BRITO CIÊNCIA DA COMPUTAÇÃO ALBERTO ANTUNES BEZERRA MARTINS TECNOLOGIAS DE PROCESSAMENTO PARALELO GPGPU: UM ESTUDO DE CASO USANDO O ALGORITMO DE CONVOLUÇÃO Fortaleza 2013 ALBERTO ANTUNES
Processamento de áudio em tempo real em dispositivos computacionais de alta disponibilidade e baixo custo
 Processamento de áudio em tempo real em dispositivos computacionais de alta disponibilidade e baixo custo André J. Bianchi 21/10/2013 1 / 33 1 Introdução 2 Metodologia 3 Arduino 4 GPU 5 Android 6 Conclusão
Processamento de áudio em tempo real em dispositivos computacionais de alta disponibilidade e baixo custo André J. Bianchi 21/10/2013 1 / 33 1 Introdução 2 Metodologia 3 Arduino 4 GPU 5 Android 6 Conclusão
GPU Computing: Implementação do método do Gradiente Conjugado utilizando CUDA
 UNIVERSIDADE DE CAXIAS DO SUL CENTRO DE COMPUTAÇÃO E TECNOLOGIA DA INFORMAÇÃO CURSO DE BACHARELADO EM CIÊNCIA DA COMPUTAÇÃO MAURÍCIO GRISA GPU Computing: Implementação do método do Gradiente Conjugado
UNIVERSIDADE DE CAXIAS DO SUL CENTRO DE COMPUTAÇÃO E TECNOLOGIA DA INFORMAÇÃO CURSO DE BACHARELADO EM CIÊNCIA DA COMPUTAÇÃO MAURÍCIO GRISA GPU Computing: Implementação do método do Gradiente Conjugado
Uma Proposta de Aumento de Desempenho na Simulação de Árvores Trinomiais para Precificação de Opções
 Uma Proposta de Aumento de Desempenho na Simulação de Árvores Trinomiais para Precificação de Opções Marcelo Lisboa Rocha Curso de Ciência da Computação UFT 109 Norte, Av. NS 15, ALCNO 14. Bloco II, Sala
Uma Proposta de Aumento de Desempenho na Simulação de Árvores Trinomiais para Precificação de Opções Marcelo Lisboa Rocha Curso de Ciência da Computação UFT 109 Norte, Av. NS 15, ALCNO 14. Bloco II, Sala
Microprocessadores II - ELE 1084
 Microprocessadores II - ELE 1084 CAPÍTULO III PROCESSADORES P5 3.1 Gerações de Processadores 3.1 Gerações de Processadores Quinta Geração (P5) Pentium (586) 32 bits; Instruções MMX; Concorrente K5 (AMD).
Microprocessadores II - ELE 1084 CAPÍTULO III PROCESSADORES P5 3.1 Gerações de Processadores 3.1 Gerações de Processadores Quinta Geração (P5) Pentium (586) 32 bits; Instruções MMX; Concorrente K5 (AMD).
Monografia de Conclusão do Curso de Graduação em Ciência da Computação. 2
 APLICAÇÃO DE BALANCEAMENTO DE CARGA COM CHARM++ NA PARALELIZANDO DE UM SIMULADOR DO MOVIMENTO DA ÁGUA NO SOLO 1 LOAD BALANCING APLICATION WITH CHARM++ IN THE PARALELIZATION OF A WATER MOVEMENT SIMULATOR
APLICAÇÃO DE BALANCEAMENTO DE CARGA COM CHARM++ NA PARALELIZANDO DE UM SIMULADOR DO MOVIMENTO DA ÁGUA NO SOLO 1 LOAD BALANCING APLICATION WITH CHARM++ IN THE PARALELIZATION OF A WATER MOVEMENT SIMULATOR
Leapfrog Geo 3.1. Notas técnicas da versão
 Página 1 Leapfrog Geo 3.1 Notas técnicas da versão Este documento descreve os principais novos recursos e melhorias que estão no Leapfrog Geo 3.1. Por favor, contate sua equipe local de suporte para uma
Página 1 Leapfrog Geo 3.1 Notas técnicas da versão Este documento descreve os principais novos recursos e melhorias que estão no Leapfrog Geo 3.1. Por favor, contate sua equipe local de suporte para uma
UNIVERSIDADE ESTADUAL PAULISTA Júlio de Mesquita Filho Pós-Graduação em Ciência da Computação
 UNIVERSIDADE ESTADUAL PAULISTA Júlio de Mesquita Filho Pós-Graduação em Ciência da Computação Thiago Alexandre Domingues de Souza Uma Solução Paralela de Agrupamento de Dados em GPU UNESP 2017 Souza, Thiago
UNIVERSIDADE ESTADUAL PAULISTA Júlio de Mesquita Filho Pós-Graduação em Ciência da Computação Thiago Alexandre Domingues de Souza Uma Solução Paralela de Agrupamento de Dados em GPU UNESP 2017 Souza, Thiago
Computadores e Programação (DCC/UFRJ)
") Computadores e Programação (DCC/UFRJ) Aula 3: 1 2 3 Abstrações do Sistema Operacional Memória virtual Abstração que dá a cada processo a ilusão de que ele possui uso exclusivo da memória principal Todo
Computadores e Programação (DCC/UFRJ) Aula 3: 1 2 3 Abstrações do Sistema Operacional Memória virtual Abstração que dá a cada processo a ilusão de que ele possui uso exclusivo da memória principal Todo
Workshop de Informática Biomédica (WIBm)
") 42 UTILIZAÇÃO DE UNIDADES DE PROCESSAMENTO GRÁFICO EM SIMULAÇÕES DO PROBLEMA DE PONTOS ALEATÓRIOS Cristiano Roberto Fabri Granzotti 1, Alexandre Souto Martinez 1 1 Laboratório de Simulação em Sistemas
42 UTILIZAÇÃO DE UNIDADES DE PROCESSAMENTO GRÁFICO EM SIMULAÇÕES DO PROBLEMA DE PONTOS ALEATÓRIOS Cristiano Roberto Fabri Granzotti 1, Alexandre Souto Martinez 1 1 Laboratório de Simulação em Sistemas
Modelos de Computadores
 Modelos de Computadores Computadores para uso mais básico: Office, editores de texto, etc. INSPIRON SMALL DESKTOP (FABRICANTE DELL) Componentes Configuração de R$2.854,00 Configuração de R$2.626,00 Processador
Modelos de Computadores Computadores para uso mais básico: Office, editores de texto, etc. INSPIRON SMALL DESKTOP (FABRICANTE DELL) Componentes Configuração de R$2.854,00 Configuração de R$2.626,00 Processador
Paralelização de Algoritmos de Busca baseados em Cardumes para Plataformas de Processamento Gráfico
 Paralelização de Algoritmos de Busca baseados em Cardumes para Plataformas de Processamento Gráfico Anthony José da Cunha Carneiro Lins, Fernando Buarque Lima Neto, Carmelo José Albanez Bastos Filho Escola
Paralelização de Algoritmos de Busca baseados em Cardumes para Plataformas de Processamento Gráfico Anthony José da Cunha Carneiro Lins, Fernando Buarque Lima Neto, Carmelo José Albanez Bastos Filho Escola
Conversão Semi-automática de Algoritmos Sequenciais de Processamento Digital de Imagens para Algoritmos Paralelos em CUDA
 REVISTA DE EMPREENDEDORISMO, INOVAÇÃO E TECNOLOGIA Conversão Semi-automática de Algoritmos Sequenciais de Processamento Digital de Imagens para Algoritmos Paralelos em CUDA Semi-Automatic Conversion of
REVISTA DE EMPREENDEDORISMO, INOVAÇÃO E TECNOLOGIA Conversão Semi-automática de Algoritmos Sequenciais de Processamento Digital de Imagens para Algoritmos Paralelos em CUDA Semi-Automatic Conversion of
Hardware. Organização Funcional de um. Computador. Arquitetura de Multiprocessadores. UCP Unidade Central de Processamento AMD. Sistema Central CPU
 Hardware UCP Unidade Central de Processamento AMD Disciplina: Organização e Arquitetura de Computadores Prof. Luiz Antonio do Nascimento Faculdade Nossa Cidade Organização Funcional de um Computador Unidade
Hardware UCP Unidade Central de Processamento AMD Disciplina: Organização e Arquitetura de Computadores Prof. Luiz Antonio do Nascimento Faculdade Nossa Cidade Organização Funcional de um Computador Unidade
ARQUITETURA DE COMPUTADORES
 RCM00014 Haswell wafer ARQUITETURA DE COMPUTADORES Prof. Luciano Bertini Site: http://www.professores.uff.br/lbertini/ Objetivos do Curso Entendimento mais aprofundado do funcionamento
RCM00014 Haswell wafer ARQUITETURA DE COMPUTADORES Prof. Luciano Bertini Site: http://www.professores.uff.br/lbertini/ Objetivos do Curso Entendimento mais aprofundado do funcionamento
Hardware Conceitos Básicos. Introdução*à*Informática 14
 Hardware Conceitos Básicos Introdução*à*Informática 14 Hardware Conceitos Básicos Componentes principais de um computador Introdução*à*Informática 15 Hardware Conceitos Básicos CPU (Unidade Central de
Hardware Conceitos Básicos Introdução*à*Informática 14 Hardware Conceitos Básicos Componentes principais de um computador Introdução*à*Informática 15 Hardware Conceitos Básicos CPU (Unidade Central de
PARALELIZAÇÃO DE ALGORITMO DE INSPEÇÃO DE ROTAS UTILIZANDO PERMUTAÇÃO LEXICOGRÁFICA 1
 PARALELIZAÇÃO DE ALGORITMO DE INSPEÇÃO DE ROTAS UTILIZANDO PERMUTAÇÃO LEXICOGRÁFICA 1 Jessica De Almeida Berlezi 2, Janiel Ceretta Foletto 3, Edson Luiz Padoin 4, Rogério S. M. Martins 5. 1 Trabalho realizado
PARALELIZAÇÃO DE ALGORITMO DE INSPEÇÃO DE ROTAS UTILIZANDO PERMUTAÇÃO LEXICOGRÁFICA 1 Jessica De Almeida Berlezi 2, Janiel Ceretta Foletto 3, Edson Luiz Padoin 4, Rogério S. M. Martins 5. 1 Trabalho realizado
Arquitetura de computadores
 Arquitetura de computadores Arquitetura de Microprocessadores Curso Profissional de Técnico de Gestão e Programação de Sistemas O Computador Hardware Unidades Funcionais de um Sistema Informático Dispositivos
Arquitetura de computadores Arquitetura de Microprocessadores Curso Profissional de Técnico de Gestão e Programação de Sistemas O Computador Hardware Unidades Funcionais de um Sistema Informático Dispositivos
Ambientes de computação de alto desempenho no LNCC
 Ambientes de computação de alto desempenho no LNCC Roberto Pinto Souto MCTI/LNCC/CSR - CENAPAD-RJ rpsouto@lncc.br 24 de Março de 2014 (Seminário da Pós-graduaçao) 24 de Março de 2014 1 / 78 Roteiro 1 Introdução
Ambientes de computação de alto desempenho no LNCC Roberto Pinto Souto MCTI/LNCC/CSR - CENAPAD-RJ rpsouto@lncc.br 24 de Março de 2014 (Seminário da Pós-graduaçao) 24 de Março de 2014 1 / 78 Roteiro 1 Introdução
TEMA DE CAPA. Introdução à Programação em CUDA
 TEMA DE CAPA Introdução à Programação em CUDA Introdução à Programação em CUDA Nos últimos anos, as placas gráficas (GPU Graphical Processing Unit) ganharam relevância no âmbito da computação paralela.
TEMA DE CAPA Introdução à Programação em CUDA Introdução à Programação em CUDA Nos últimos anos, as placas gráficas (GPU Graphical Processing Unit) ganharam relevância no âmbito da computação paralela.
Usando o benchmark Rodinia para comparação de OpenCL e OpenMP em aplicações paralelas no coprocessador Intel Xeon Phi
 Usando o benchmark Rodinia para comparação de OpenCL e OpenMP em aplicações paralelas no coprocessador Intel Xeon Phi Leonardo Tavares Oliveira 1, Ricardo Menotti 1 1 Departamento de Computação Universidade
Usando o benchmark Rodinia para comparação de OpenCL e OpenMP em aplicações paralelas no coprocessador Intel Xeon Phi Leonardo Tavares Oliveira 1, Ricardo Menotti 1 1 Departamento de Computação Universidade
ARQUITETURA E ORGANIZAÇÃO DE COMPUTADORES PARALELISMO: SMP E PROCESSAMENTO VETORIAL. Prof. Dr. Daniel Caetano
 ARQUITETURA E ORGANIZAÇÃO DE COMPUTADORES PARALELISMO: SMP E PROCESSAMENTO VETORIAL Prof. Dr. Daniel Caetano 2012-2 Objetivos Compreender a Arquitetura SMP Conhecer a Organização SMP Apresentar o Conceito
ARQUITETURA E ORGANIZAÇÃO DE COMPUTADORES PARALELISMO: SMP E PROCESSAMENTO VETORIAL Prof. Dr. Daniel Caetano 2012-2 Objetivos Compreender a Arquitetura SMP Conhecer a Organização SMP Apresentar o Conceito
Universidade Federal do Pampa Matheus da Silva Serpa. Análise de Desempenho de Aplicações Paralelas em Arquiteturas multi-core e many-core
 Universidade Federal do Pampa Matheus da Silva Serpa Análise de Desempenho de Aplicações Paralelas em Arquiteturas multi-core e many-core Alegrete 2015 Matheus da Silva Serpa Análise de Desempenho de
Universidade Federal do Pampa Matheus da Silva Serpa Análise de Desempenho de Aplicações Paralelas em Arquiteturas multi-core e many-core Alegrete 2015 Matheus da Silva Serpa Análise de Desempenho de
Programação em Paralelo OpenMP
 Programação em Paralelo OpenMP N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: OpenMP 1 / 15 Introdução Potencial do GPU vs CPU Cálculo: 367
Programação em Paralelo OpenMP N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: OpenMP 1 / 15 Introdução Potencial do GPU vs CPU Cálculo: 367
Sob medida para seu sistema de segurança!
 Surveillance servers, workstations & storages. Inpex WST200 G2 Sob medida para seu sistema de segurança! Concebidos por engenheiros e cientistas da computação, oriundos dos segmentos de videosurveillance
Surveillance servers, workstations & storages. Inpex WST200 G2 Sob medida para seu sistema de segurança! Concebidos por engenheiros e cientistas da computação, oriundos dos segmentos de videosurveillance
Intel Thread Building Blocks (TBB)
") Intel Thread Building Blocks (TBB) MCZA020-13 - Programação Paralela Emilio Francesquini e.francesquini@ufabc.edu.br 2019.Q1 Centro de Matemática, Computação e Cognição Universidade Federal do ABC Disclaimer
Intel Thread Building Blocks (TBB) MCZA020-13 - Programação Paralela Emilio Francesquini e.francesquini@ufabc.edu.br 2019.Q1 Centro de Matemática, Computação e Cognição Universidade Federal do ABC Disclaimer
é a saida do melhor individuo. A configuração de parâmetros da
 61 4 4.1. Configuração Neste capítulo, comparam-se os resultados e o desempenho obtidos pela PGLIQ com a extensão do modelo proposto GPU-PGLIQ-I que foi desenvolvido nesta dissertação. Apresentam-se dois
61 4 4.1. Configuração Neste capítulo, comparam-se os resultados e o desempenho obtidos pela PGLIQ com a extensão do modelo proposto GPU-PGLIQ-I que foi desenvolvido nesta dissertação. Apresentam-se dois
GPU Computing. GeForce and Radeon OpenCL Test. OpenCL
 GPU Computing GeForce and Radeon OpenCL Test Publicado em 15.jan.2010 em www.geeks3d.com - Tradução por Luiz Gustavo TURATTI http://www.geeks3d.com/20100115/gpu-computing-geforce-and-radeon-opencl-test-part-1/
GPU Computing GeForce and Radeon OpenCL Test Publicado em 15.jan.2010 em www.geeks3d.com - Tradução por Luiz Gustavo TURATTI http://www.geeks3d.com/20100115/gpu-computing-geforce-and-radeon-opencl-test-part-1/