Arquitetura e Programação de GPU. Leandro Zanotto RA: Anselmo Ferreira RA: Marcelo Matsumoto RA:
|
|
|
- Márcio Castilhos Flores
- 8 Há anos
- Visualizações:
Transcrição
1 Arquitetura e Programação de GPU Leandro Zanotto RA: Anselmo Ferreira RA: Marcelo Matsumoto RA:

2 Agenda Primeiras Placas de Vídeo Primeira GPU Arquitetura da GPU NVIDIA Arquitetura FERMI Arquitetura KEPLER Programação com CUDA

3 Primeira Geração Wireframe Vértices: transformação, recorte e projeto Rasterização: somente linhas Pixel: sem pixels! Framebuffers com poucos bit por pixel em uma pequena resolução Datas: antes de 1987

4 Segunda Geração Sólidos Sombreados Vértice: iluminação Rasterização: polígonos preenchidos Pixel: buffer maior, mistura e cores Datas: Terceira Geração Mapeamento de Texturas Vértices e Rasterização: mais e mais rápidos Pixel: filtro de texturas, antialiasing Datas:

5 História da GPU Produto Processo Transistores MHz GFLOPS (MUL) Aug-02 GeForce FX M Jan-03 GeForce FX M Dec-03 GeForce M As GPUs já estavam com bom poder de processamento, mas ainda não eram programáveis Primeira GPGPU foi lançada em 2002

6 Arquitetura de uma GPU

7 Arquitetura de GPU (cont...) CUDA Core (Stream Processor) e uma unidade programável Não existe Coerência de Cache L1 Os CUDA Cores são organizados em blocos, cada bloco tem muitas threads. Os blocos podem ser organizados em grids. As threads podem ser sincronizadas A progamação é altamente paralela O desempenho é grande comparado com as CPUs atuais

8 Arquitetura Fermi Melhoria do desempenho na precisão dupla Suporte a ECC Hierarquia de Memória Verdadeira Maior memória compartilhada Troca de contexto mais rápida Operações Atômicas mais Rápidas

9 Arquitetura Fermi (cont)... Terceira Geração de Streaming Multiprocessor (SM) 32 CUDA cores por SM, 4x sobre GT200 8x o pico de precisão dupla em ponto flutuante sobre GT200 Warp Scheduler duplo, schedules simultâneos e instruções de despacho de dois warps independentes 64 KB de RAM com particionamento configurável da memória compartilhada e cache L1 Segunda Geração de execução de threads paralelas ISA Espaço de endereço unificado com suporte completo a C++ Otimizado para OpenCL e DirectCompute Total IEEE de precisão de 32-bit e 64-bit Caminho inteiro total de 32 bits com extensões de 64-bits Acesso às instruções de memória e suporte de transição a endereços de 64-bit Melhoria do desempenho através de predição

10 Arquitetura Fermi Melhorada a memória do subsistema Hierarquia NVIDIA Parallel DataCacheTM com L1 configurável e L2 unificado Caches Primeira GPU com ECC Melhoria no desempenho das operações atômicas NVIDIA GigaThreadTM Engine Troca de contexto 10x mais rápida Execução de kernel concorrente Execução do bloco de thread fora de ordem Transferência de memória dupla

")
11 Arquitetura Kepler Streaming Multiprocessor (SMX) Architecture

12 Arquitetura Kepler Quad Warp Scheduler Performance per Watt Dynamic Parallelism Hyper-Q Grid Management Unit NVIDIA GPUDirect

13 Arquitetura Kepler

14 Arquitetura Kepler

15 Arquitetura Kepler
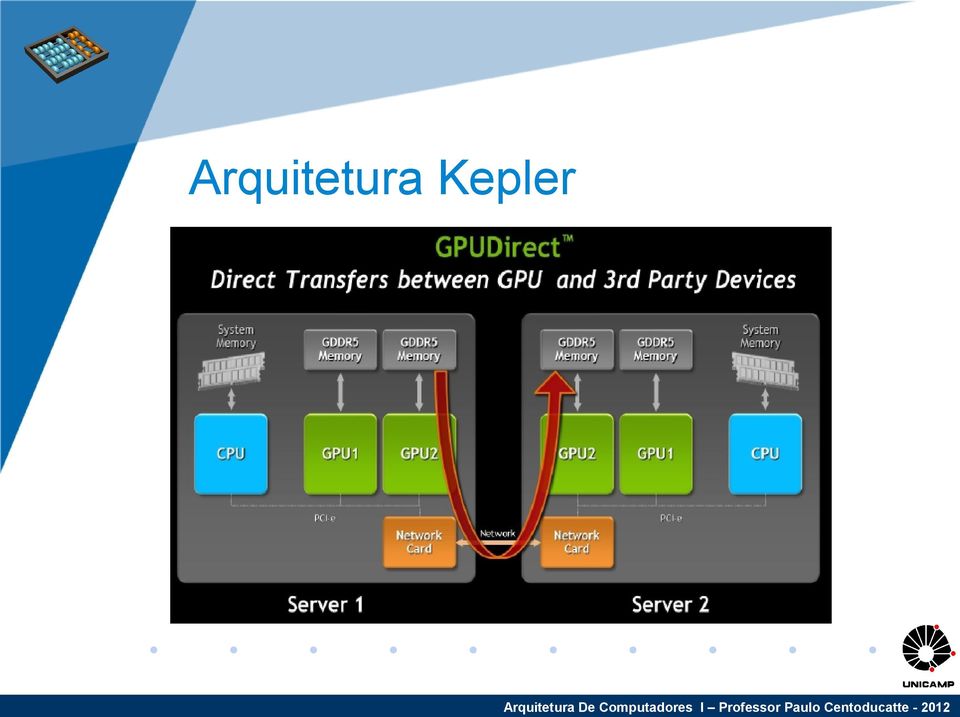

16 Arquitetura Kepler

17 O que é CUDA? Arquitetura do CUDA (Compute Unified Device Architecture) Expõe à GPU a capacidade de ser programada para propósitos gerais Retém o desempenho dos tradicionais DirectX/OpenGL CUDA C Baseado nos padrões do C Uma linguagem útil para as extensões que permitem fazer programas heterogêneos API direta para gerenciar dispositivos, memória, etc. Só funciona com as GPUs da nvidia Existe no mercado o OpenCL

18 CUDA - Terminologia Host A CPU e sua memória (memória do host) Device A GPU e sua memória (memória do device)
")
19 Hello, World! int main( void) { printf( "Hello, World!\n" ); return 0; } Este programa simples em C é executado no host O compilador da nvidia (nvcc) não irá reclamar se o programa não tiver código no device CUDA é simples como C

20 Hello, World! no device global void kernel( void) { } int main( void) { kernel<<<1,1>>>(); printf( "Exemplo 1!\n" ); return 0; }
; printf(")
21 Hello, World! no device global void kernel( void) { } A palvra chave do CUDA global indica que a função É executada no device É chamado do host nvcc divide o código fonte em componentes de host e device o nvcc manipula as funções do device como kernel() o compilador padrão do host manipula funções como main() Pode-se usar: gcc para Linux Microsoft Visual C++
22 Hello, World! Com o código no device int main( void) { kernel<<< 1, 1 >>>(); printf( "Hello, World!\n" ); return 0; } Os <<< >>> são chamadas de kernel através do host
23 Um outro exemplo Um kernel que adiciona dois inteiros global void add( int*a, int*b, int*c ) { *c = *a + *b; } global é um palavra chave de CUDA que siginfica: - add() será executado no device - add() será chamado pelo host
24 Um outro exemplo Perceba que usamos ponteiros em nossas variáveis global void add( int*a, int*b, int*c ) { *c = *a + *b; } Add() é executado no device, então a,b e c devem apontar para a memória do device
25 Gerenciamento de Memória A memória do Host e do device são entidades distintas Ponteiros do Device apontam para a memória da GPU Pode ser passado do código do host Ponteiros do Host apontam para a memória da CPU Pode ser passado para o código do dispositivo Comandos básicos para manipular a memória com CUDA cudamalloc(), cudafree(), cudamemcpy() Similar em C temos malloc(), free(), memcpy()
26 Exemplo com gerenciamento de memória int main( void ) { int a, b, c; // host copia de a, b, c int*dev_a, *dev_b, *dev_c; // device copia de a, b, c int size = sizeof( int); // precisamos de um espaço para um inteiro // aloca no device cópias de a, b, c cudamalloc( (void**)&dev_a, size ); cudamalloc( (void**)&dev_b, size ); cudamalloc( (void**)&dev_c, size ); a = 2; b = 7;
27 Exemplo com gerenciamento de memória (cont) // copia a entrada para o device cudamemcpy( dev_a, &a, size, cudamemcpyhosttodevice); cudamemcpy( dev_b, &b, size, cudamemcpyhosttodevice); // executa add() kernel na GPU, passando parâmetros add<<< 1, 1 >>>( dev_a, dev_b, dev_c); // copia o resultado do device de volta para o host a cópia de c cudamemcpy( &c, dev_c, size, cudamemcpydevicetohost); cudafree( dev_a); cudafree( dev_b); cudafree( dev_c);
28 Programação Paralela com CUDA A computação de GPU é a massiva paralela Para executarmos o programa anterior em paralelo temos que fazer uma pequena mudança add<<< 1, 1 >>>( dev_a, dev_b, dev_c); add<<< N, 1 >>>( dev_a, dev_b, dev_c); Feito isso o add() será executado N vezes em paralelo
29 Programação Paralela com CUDA Cada invocação do add() se refere como um bloco Kernel pode se referir ao índice do bloco com a variável blockidx.x Para a soma de um vetor, cada bloco adiciona o valor de a[] e b[] tendo seu resultado em c[]: global void add( int*a, int*b, int*c ) { c[blockidx.x] = a[blockidx.x] + b[blockidx.x]; } Utilizando blockidx.x para os índices dos arrays, cada bloco manipula índices diferentes

30 Programação Paralela com CUDA O código anterior: global void add( int*a, int*b, int*c ) { c[blockidx.x] = a[blockidx.x] + b[blockidx.x]; } Este código será executado no device assim:
31 Adição em Paralelo: add() Usando nos kernel paralelizado add(): global void add( int*a, int*b, int*c ) { c[blockidx.x] = a[blockidx.x] + b[blockidx.x]; }
32 Adição em Paralelo: main() #define N 512 int main( void ) { int a, b, c; // cópias de a,b, c no host int*dev_a, *dev_b, *dev_c; // cópias de a,b, c no device int size = N * sizeof( int); // precisa-se do espaço para N inteiros // aloca a cópias de a, b, c no device cudamalloc( (void**)&dev_a, size ); cudamalloc( (void**)&dev_b, size ); cudamalloc( (void**)&dev_c, size ); a = 2; b = 7; // copia a entrada para o device cudamemcpy( dev_a, &a, size, cudamemcpyhosttodevice); cudamemcpy( dev_b, &b, size, cudamemcpyhosttodevice); // executa o add() kernel na GPU, passando parametros add<<< N, 1 >>>( dev_a, dev_b, dev_c); // copia o resultado do device de volta para o host com a cópia e c e libera a memória alocada na GPU cudamemcpy( &c, dev_c, size, cudamemcpydevicetohost); cudafree( dev_a); cudafree( dev_b); cudafree( dev_c); return 0; }
33 Threads Um bloco pode ser dividido em threads paralelas Mudando a adição do vetor para usar threads paralelas: Bloco Thread global void add( int*a, int*b, int*c ) { c[blockidx.x] = a[blockidx.x] + b[blockidx.x]; } global void add( int*a, int*b, int*c ) { c[threadidx.x] = a[threadidx.x] + b[threadidx.x]; }
34 Adição Paralela com Threads #define N 512 int main( void ) { int*a, *b, *c; // cópias de a,b, c no host int*dev_a, *dev_b, *dev_c; // cópias de a,b, c no device int size = N * sizeof( int); // precisa-se do espaço para 512 inteiros // aloca a cópias de a, b, c no device cudamalloc( (void**)&dev_a, size ); cudamalloc( (void**)&dev_b, size ); cudamalloc( (void**)&dev_c, size ); a = (int*)malloc( size ); b = (int*)malloc( size ); c = (int*)malloc( size ); random_ints( a, N ); random_ints( b, N );
35 Adição Paralela com Threads (cont) // copia a entrada para o device cudamemcpy( dev_a, a, size, cudamemcpyhosttodevice); cudamemcpy( dev_b, b, size, cudamemcpyhosttodevice); // executa o add() kernel com N threads add<<<n, N>>>( dev_a, dev_b, dev_c); // copia o resultado do device para o host a cópia de c cudamemcpy( c, dev_c, size, cudamemcpydevicetohost); free( a ); free( b ); free( c ); cudafree( dev_a); cudafree( dev_b); cudafree( dev_c); return 0; }
36 Indexando Arrays com Threads e Blocos Não basta usar threadidx.x ou blockidx.x Para indexar um array com 1 thread por entrada (8 threads por bloco) Se nós temos M threads/blocos, um único índice do array para cada entrada é dado por

37 Indexando Arrays - Exemplo Para a entrada em vermelho temos o índice 21:
38 Adição com Threads e Blocos Temos uma variável feita para utilizar threads / blocos (blockdim.x) int index= threadidx.x + blockidx.x * blockdim.x; Uma versão da adição de vertor utilizando blocos e threads: global void add( int*a, int*b, int*c ) { int index = threadidx.x + blockidx.x * blockdim.x; c[index] = a[index] + b[index]; }
39 Adição Paralela com Threads e Blocos #define N (2048*2048) #define THREADS_PER_BLOCK 512 int main( void ) { int*a, *b, *c; // cópias de a,b, c no host int*dev_a, *dev_b, *dev_c; // cópias de a,b, c no device int size = N * sizeof( int); // precisa-se do espaço para N inteiros // aloca a cópias de a, b, c no device cudamalloc( (void**)&dev_a, size ); cudamalloc( (void**)&dev_b, size ); cudamalloc( (void**)&dev_c, size ); a = (int*)malloc( size ); b = (int*)malloc( size ); c = (int*)malloc( size ); random_ints( a, N ); random_ints( b, N );
40 Adição Paralela com Threads e Blocos (cont) // copia a entrada para o device cudamemcpy( dev_a, a, size, cudamemcpyhosttodevice); cudamemcpy( dev_b, b, size, cudamemcpyhosttodevice); // executa o kernel add() com blocos e threads add<<< N/THREADS_PER_BLOCK, THREADS_PER_BLOCK >>>( dev_a, dev_b, dev_c); // copia o resultado do device para o host com o a cópia de c cudamemcpy( c, dev_c, size, cudamemcpydevicetohost); free( a ); free( b ); free( c ); cudafree( dev_a); cudafree( dev_b); cudafree( dev_c); Return 0; }

41 Compartilhando dados entre Threads Um bloco de Threads compartilha a memória chamada de shared memory Extremamente rápida, construída no próprio chip Declarada com a palavra chave do CUDA shared Somente visível para as threads do mesmo bloco
42 Sincronização de Threads Precisamos que as threads aguardem entre as seções do Produto Escalar Sincronizamos as threads utilizando a função syncthreads() As threads do bloco esperam até que todas elas alcancem o syncthreads() As threads são somente sincronizadas com um bloco global void dot( int*a, int*b, int*c ) { shared int temp[n]; temp[threadidx.x] = a[threadidx.x] * b[threadidx.x]; syncthreads(); // Aqui ocorre a sincronização das threads, elas vão esperar até todas alcançarem este ponto if( 0 == threadidx.x ) { int sum = 0; for( int i= 0; i< N; i++ ) sum += temp[i]; *c = sum; } }
43 Operações Atômicas CUDA suporta operações atômicas como: atomicadd() atomicsub() atomicmin() atomicmax() atomicinc() atomicdec() atomicexch() atomiccas() Utilizado para executar um read-modify-write sem interrupção
44 Perguntas
Processamento de Alto Desempenho utilizando Unidade de Processamento Gráfico - GPU
 Processamento de Alto Desempenho utilizando Unidade de Processamento Gráfico - GPU Francisco Ribacionka e Ettore Enrico (STI ) USP/STI/InterNuvem internuvem@usp.br Março -2016 Processamento de Alto Desempenho
Processamento de Alto Desempenho utilizando Unidade de Processamento Gráfico - GPU Francisco Ribacionka e Ettore Enrico (STI ) USP/STI/InterNuvem internuvem@usp.br Março -2016 Processamento de Alto Desempenho
Aula 10 - Streams (Parte I)
") Disciplina de TICs 1 - Introdução a Programação em GPGPU Aula 10 - Streams (Parte I) Introdução Até então foi visto como engenho de processamento paralelo massivo de dados nas GPUs pode aumentar assombrosamente
Disciplina de TICs 1 - Introdução a Programação em GPGPU Aula 10 - Streams (Parte I) Introdução Até então foi visto como engenho de processamento paralelo massivo de dados nas GPUs pode aumentar assombrosamente
Introdução a CUDA. Esteban Walter Gonzalez Clua. Medialab - Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center START
 Introdução a CUDA START Esteban Walter Gonzalez Clua Medialab - Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center 1536 cores Dynamic Parallelism Hyper - Q Pipeline
Introdução a CUDA START Esteban Walter Gonzalez Clua Medialab - Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center 1536 cores Dynamic Parallelism Hyper - Q Pipeline
Programação em Paralelo. N. Cardoso & P. Bicudo. Física Computacional - MEFT 2010/2011
 Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 11 CUDA Parte 2 N. Cardoso & P. Bicudo Programação em
Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 11 CUDA Parte 2 N. Cardoso & P. Bicudo Programação em
Programação em Paralelo. N. Cardoso & P. Bicudo. Física Computacional - MEFT 2010/2011
 Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 12 CUDA Parte 3 N. Cardoso & P. Bicudo Programação em
Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 12 CUDA Parte 3 N. Cardoso & P. Bicudo Programação em
PARALELIZAÇÃO DE APLICAÇÕES NA ARQUITETURA CUDA: UM ESTUDO SOBRE VETORES 1
 PARALELIZAÇÃO DE APLICAÇÕES NA ARQUITETURA CUDA: UM ESTUDO SOBRE VETORES 1 DUTRA, Evandro Rogério Fruhling 2 ; VARINI, Andre Luis 2 ; CANAL, Ana Paula 2 1 Trabalho de Iniciação Científica _UNIFRA 2 Ciência
PARALELIZAÇÃO DE APLICAÇÕES NA ARQUITETURA CUDA: UM ESTUDO SOBRE VETORES 1 DUTRA, Evandro Rogério Fruhling 2 ; VARINI, Andre Luis 2 ; CANAL, Ana Paula 2 1 Trabalho de Iniciação Científica _UNIFRA 2 Ciência
Fabrício Gomes Vilasbôas
 Fabrício Gomes Vilasbôas Apresentação Placas Arquitetura Toolkit e Ferramentas de Debug Pensando em CUDA Programação CUDA Python Programação PyCUDA 1) Grids( padrão Globus) 2) Clusters ( padrão MPI) 3)
Fabrício Gomes Vilasbôas Apresentação Placas Arquitetura Toolkit e Ferramentas de Debug Pensando em CUDA Programação CUDA Python Programação PyCUDA 1) Grids( padrão Globus) 2) Clusters ( padrão MPI) 3)
Auditoria de senhas em hardware paralelo com o John the Ripper O impacto das tecnologias de processamento paralelo na quebra de senhas
 Auditoria de senhas em hardware paralelo com o John the Ripper O impacto das tecnologias de processamento paralelo na quebra de senhas Claudio André claudio.andre@correios.net.br Motivação Seu computador
Auditoria de senhas em hardware paralelo com o John the Ripper O impacto das tecnologias de processamento paralelo na quebra de senhas Claudio André claudio.andre@correios.net.br Motivação Seu computador
Waldemar Celes. 25 de Agosto de 2014
 Introdução a CUDA INF2062 Tópicos em Simulação e Visualização Waldemar Celes celes@inf.puc-rio.br Tecgraf, DI/PUC-Rio 25 de Agosto de 2014 W. Celes Introdução a CUDA 1 GPGPU Programação de propósito geral
Introdução a CUDA INF2062 Tópicos em Simulação e Visualização Waldemar Celes celes@inf.puc-rio.br Tecgraf, DI/PUC-Rio 25 de Agosto de 2014 W. Celes Introdução a CUDA 1 GPGPU Programação de propósito geral
Programação em Paralelo. N. Cardoso & P. Bicudo. Física Computacional - MEFT 2012/2013
 Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 23 CUDA "Compute Unified Device Architecture" Parte 2
Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 23 CUDA "Compute Unified Device Architecture" Parte 2
Computação Heterogênea Programação paralela, clusters e GPUs
 Computação Heterogênea Programação paralela, clusters e GPUs Profa. Dra. Denise Stringhini (ICT- Unifesp) Primeiro Encontro do Khronos Chapters Brasil Belo Horizonte, 20/09/2013 Conteúdo Computação heterogênea:
Computação Heterogênea Programação paralela, clusters e GPUs Profa. Dra. Denise Stringhini (ICT- Unifesp) Primeiro Encontro do Khronos Chapters Brasil Belo Horizonte, 20/09/2013 Conteúdo Computação heterogênea:
Alcides Carneiro de Araújo Neto. Comparação Sequência-Família em GPU
 Alcides Carneiro de Araújo Neto Comparação Sequência-Família em GPU Campo Grande MS 2014 Alcides Carneiro de Araújo Neto Comparação Sequência-Família em GPU Dissertação de Mestrado apresentada à Faculdade
Alcides Carneiro de Araújo Neto Comparação Sequência-Família em GPU Campo Grande MS 2014 Alcides Carneiro de Araújo Neto Comparação Sequência-Família em GPU Dissertação de Mestrado apresentada à Faculdade
Hierarquia de memória:
 INE5645 Programação Paralela e Distribuída Aluno Modelo de Execução CUDA - A execução do programa controlado pela CPU pode lançar kernels, que são trechos de código executados em paralelo por múltiplas
INE5645 Programação Paralela e Distribuída Aluno Modelo de Execução CUDA - A execução do programa controlado pela CPU pode lançar kernels, que são trechos de código executados em paralelo por múltiplas
Aplicações em CUDA. Medialab Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center
 Aplicações em CUDA Medialab Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center Roteiro l Introdução l Eventos l Aspectos históricos l Operações atômicas l Introdução sobre
Aplicações em CUDA Medialab Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center Roteiro l Introdução l Eventos l Aspectos históricos l Operações atômicas l Introdução sobre
5 Unidades de Processamento Gráfico GPUs
 5 Unidades de Processamento Gráfico GPUs As GPUs são processadores maciçamente paralelos, com múltiplos elementos de processamento, tipicamente utilizadas como aceleradores de computação. Elas fornecem
5 Unidades de Processamento Gráfico GPUs As GPUs são processadores maciçamente paralelos, com múltiplos elementos de processamento, tipicamente utilizadas como aceleradores de computação. Elas fornecem
UNIVERSIDADE FEDERAL DO RIO GRANDE DO SUL INSTITUTO DE INFORMÁTICA INFORMÁTICA APLICADA
 Responda 1) Quem desenvolveu a linguagem C? Quando? 2) Existe alguma norma sobre a sintaxe da linguagem C? 3) Quais são os tipos básicos de dados disponíveis na linguagem C? 4) Quais são as principais
Responda 1) Quem desenvolveu a linguagem C? Quando? 2) Existe alguma norma sobre a sintaxe da linguagem C? 3) Quais são os tipos básicos de dados disponíveis na linguagem C? 4) Quais são as principais
Edison Gustavo Muenz. Estudo e implementação de um algoritmo de processamento de imagens com técnicas GPGPU
 Edison Gustavo Muenz Estudo e implementação de um algoritmo de processamento de imagens com técnicas GPGPU Florianópolis SC Agosto / 2008 Edison Gustavo Muenz Estudo e implementação de um algoritmo de
Edison Gustavo Muenz Estudo e implementação de um algoritmo de processamento de imagens com técnicas GPGPU Florianópolis SC Agosto / 2008 Edison Gustavo Muenz Estudo e implementação de um algoritmo de
Universidade Federal do ABC. Dissertação de Mestrado. Aderbal de Morais Junior
 Universidade Federal do ABC Curso de Pós Graduação em Ciência da Computação Dissertação de Mestrado Aderbal de Morais Junior UMA BIBLIOTECA PARA DESENVOLVIMENTO DE APLICAÇÕES CUDA EM AGLOMERADOS DE GPUS
Universidade Federal do ABC Curso de Pós Graduação em Ciência da Computação Dissertação de Mestrado Aderbal de Morais Junior UMA BIBLIOTECA PARA DESENVOLVIMENTO DE APLICAÇÕES CUDA EM AGLOMERADOS DE GPUS
Processos e Threads (partes I e II)
") Processos e Threads (partes I e II) 1) O que é um processo? É qualquer aplicação executada no processador. Exe: Bloco de notas, ler um dado de um disco, mostrar um texto na tela. Um processo é um programa
Processos e Threads (partes I e II) 1) O que é um processo? É qualquer aplicação executada no processador. Exe: Bloco de notas, ler um dado de um disco, mostrar um texto na tela. Um processo é um programa
Programação em Paralelo. N. Cardoso & P. Bicudo. Física Computacional - MEFT 2012/2013
 Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 19 CUDA "Compute Unified Device Architecture" Parte 1
Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 19 CUDA "Compute Unified Device Architecture" Parte 1
Paralelização do Detector de Bordas Canny para a Biblioteca ITK usando CUDA
 Paralelização do Detector de Bordas Canny para a Biblioteca ITK usando CUDA Luis Henrique Alves Lourenço Grupo de Visão, Robótica e Imagens Universidade Federal do Paraná 7 de abril de 2011 Sumário 1 Introdução
Paralelização do Detector de Bordas Canny para a Biblioteca ITK usando CUDA Luis Henrique Alves Lourenço Grupo de Visão, Robótica e Imagens Universidade Federal do Paraná 7 de abril de 2011 Sumário 1 Introdução
29/3/2011. Primeira unidade de execução (pipe U): unidade de processamento completa, capaz de processar qualquer instrução;
: unidade de processamento completa, capaz de processar qualquer instrução;") Em 1993, foi lançada a primeira versão do processador Pentium, que operava a 60 MHz Além do uso otimizado da memória cache (tecnologia já amadurecida) e da multiplicação do clock, o Pentium passou a utilizar
Em 1993, foi lançada a primeira versão do processador Pentium, que operava a 60 MHz Além do uso otimizado da memória cache (tecnologia já amadurecida) e da multiplicação do clock, o Pentium passou a utilizar
Aula 3. Sistemas Operacionais. Prof: Carlos Eduardo de Carvalho Dantas (carloseduardoxpto@gmail.com) http://carloseduardoxp.wordpress.
 http://carloseduardoxp.wordpress.") Sistemas Operacionais Aula 3 Prof: Carlos Eduardo de Carvalho Dantas (carloseduardoxpto@gmail.com) http://carloseduardoxp.wordpress.com Nunca cone em um computador que você não pode jogar pela janela.
Sistemas Operacionais Aula 3 Prof: Carlos Eduardo de Carvalho Dantas (carloseduardoxpto@gmail.com) http://carloseduardoxp.wordpress.com Nunca cone em um computador que você não pode jogar pela janela.
Introdução ao CUDA. Material elaborado por Davi Conte.
 Introdução ao CUDA Material elaborado por Davi Conte. O objetivo deste material é que o aluno possa iniciar seus conhecimentos em programação paralela, entendendo a diferença da execução de forma sequencial
Introdução ao CUDA Material elaborado por Davi Conte. O objetivo deste material é que o aluno possa iniciar seus conhecimentos em programação paralela, entendendo a diferença da execução de forma sequencial
Arquitetura de Von Neumann e os Computadores Modernos
 Arquitetura de Von Neumann e os Computadores Modernos Arquitetura de Computadores e Software Básico Aula 5 Flávia Maristela (flaviamsn@ifba.edu.br) Arquitetura de Von Neumann e as máquinas modernas Onde
Arquitetura de Von Neumann e os Computadores Modernos Arquitetura de Computadores e Software Básico Aula 5 Flávia Maristela (flaviamsn@ifba.edu.br) Arquitetura de Von Neumann e as máquinas modernas Onde
Tópicos em Física Computacional: Introdução a Linguagem CUDA
 Tópicos em Física Computacional: Introdução a Linguagem CUDA Aula 06: Introdução a Linguagem CUDA Otimização do Código Carine P. Beatrici IF UFRGS 1 Da Aula Passada... Programa que soma matrizes linearizadas;
Tópicos em Física Computacional: Introdução a Linguagem CUDA Aula 06: Introdução a Linguagem CUDA Otimização do Código Carine P. Beatrici IF UFRGS 1 Da Aula Passada... Programa que soma matrizes linearizadas;
Programação Paralela em Ambientes Computacionais Heterogêneos com OpenCL
 Programação Paralela em Ambientes Computacionais Heterogêneos com OpenCL César L. B. Silveira Prof. Dr. Luiz G. da Silveira Jr. Prof. Dr. Gerson Geraldo H. Cavalheiro 28 de outubro de 2010 contato@v3d.com.br
Programação Paralela em Ambientes Computacionais Heterogêneos com OpenCL César L. B. Silveira Prof. Dr. Luiz G. da Silveira Jr. Prof. Dr. Gerson Geraldo H. Cavalheiro 28 de outubro de 2010 contato@v3d.com.br
Capítulo 8 Arquitetura de Computadores Paralelos
 Capítulo 8 Arquitetura de Computadores Paralelos Necessidade de máquinas com alta capacidade de computação Aumento do clock => alta dissipação de calor Velocidade limitada dos circuitos => velocidade da
Capítulo 8 Arquitetura de Computadores Paralelos Necessidade de máquinas com alta capacidade de computação Aumento do clock => alta dissipação de calor Velocidade limitada dos circuitos => velocidade da
Placa de vídeo em CUDA
 Placa de vídeo em CUDA Matheus Costa Leone de Souza Krystian Aparacido Resumo Quando você tem um cálculo que possa ser grande demais para você realizar a mão, a primeira solução que lhe vem a cabeça é
Placa de vídeo em CUDA Matheus Costa Leone de Souza Krystian Aparacido Resumo Quando você tem um cálculo que possa ser grande demais para você realizar a mão, a primeira solução que lhe vem a cabeça é
1 Padrões de Implementação em Processamento de Imagens. 2 Resumo. 4 Computação paralela. 1.1 Relátório final para PIBIC/CNPq
 1 Padrões de Implementação em Processamento de Imagens 1.1 Relátório final para PIBIC/CNPq Victor M. de A. Oliveira, Rubens Campos Machado Centro de Tecnologia da Informação Renato Archer CTI Divisão de
1 Padrões de Implementação em Processamento de Imagens 1.1 Relátório final para PIBIC/CNPq Victor M. de A. Oliveira, Rubens Campos Machado Centro de Tecnologia da Informação Renato Archer CTI Divisão de
Eng. Thársis T. P. Souza
 Introdução à Computação de Alto Desempenho Utilizando GPU Seminário de Programação em GPGPU Eng. Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo Introdução
Introdução à Computação de Alto Desempenho Utilizando GPU Seminário de Programação em GPGPU Eng. Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo Introdução
CUDA. José Ricardo da Silva Jr.
 CUDA José Ricardo da Silva Jr. Medialab Ins1tuto de Computação Universidade Federal Fluminense CUDA Research Center & CUDA Teaching Center Centro de excelência da NVIDIA desde julho 2012 Perfil Bacharel
CUDA José Ricardo da Silva Jr. Medialab Ins1tuto de Computação Universidade Federal Fluminense CUDA Research Center & CUDA Teaching Center Centro de excelência da NVIDIA desde julho 2012 Perfil Bacharel
Notas da Aula 4 - Fundamentos de Sistemas Operacionais
 Notas da Aula 4 - Fundamentos de Sistemas Operacionais 1. Threads Threads são linhas de execução dentro de um processo. Quando um processo é criado, ele tem uma única linha de execução, ou thread. Esta
Notas da Aula 4 - Fundamentos de Sistemas Operacionais 1. Threads Threads são linhas de execução dentro de um processo. Quando um processo é criado, ele tem uma única linha de execução, ou thread. Esta
Programação Paralela e Distribuída (DCC/UFRJ)
") Programação Paralela e Distribuída (DCC/UFRJ) Aula 7: Programação com memória compartilhada usando OpenMP 1, 8, 10 e 15 de abril de 2015 OpenMP (Open MultiProcessing) Projetado para sistemas de memória
Programação Paralela e Distribuída (DCC/UFRJ) Aula 7: Programação com memória compartilhada usando OpenMP 1, 8, 10 e 15 de abril de 2015 OpenMP (Open MultiProcessing) Projetado para sistemas de memória
O Problema do Fractal de Mandelbrot como Comparativo de Arquiteturas de Memória Compartilhada GPU vs OpenMP
 O Problema do Fractal de Mandelbrot como Comparativo de Arquiteturas de Memória Compartilhada GPU vs OpenMP Bruno P. dos Santos, Dany S. Dominguez, Esbel V. Orellana Departamento de Ciências Exatas e Tecnológicas
O Problema do Fractal de Mandelbrot como Comparativo de Arquiteturas de Memória Compartilhada GPU vs OpenMP Bruno P. dos Santos, Dany S. Dominguez, Esbel V. Orellana Departamento de Ciências Exatas e Tecnológicas
SSC510 Arquitetura de Computadores. 12ª aula
 SSC510 Arquitetura de Computadores 12ª aula EVOLUÇÃO DA ARQUITETURA INTEL PROFA. SARITA MAZZINI BRUSCHI 1 Pentium - Modelos 2 Pentium - Arquiteturas Netburst P7 Sétima geração dos processadores da arquitetura
SSC510 Arquitetura de Computadores 12ª aula EVOLUÇÃO DA ARQUITETURA INTEL PROFA. SARITA MAZZINI BRUSCHI 1 Pentium - Modelos 2 Pentium - Arquiteturas Netburst P7 Sétima geração dos processadores da arquitetura
Análise de desempenho e eficiência energética de aceleradores NVIDIA Kepler
 Análise de desempenho e eficiência energética de aceleradores NVIDIA Kepler Emilio Hoffmann, Bruno M. Muenchen, Taís T. Siqueira, Edson L. Padoin e Philippe O. A. Navaux Universidade Regional do Noroeste
Análise de desempenho e eficiência energética de aceleradores NVIDIA Kepler Emilio Hoffmann, Bruno M. Muenchen, Taís T. Siqueira, Edson L. Padoin e Philippe O. A. Navaux Universidade Regional do Noroeste
Cálculo Aproximado do número PI utilizando Programação Paralela
 Universidade de São Paulo Instituto de Ciências Matemáticas e de Computação Cálculo Aproximado do número PI utilizando Programação Paralela Grupo 17 Raphael Ferras Renan Pagaiane Yule Vaz SSC-0143 Programação
Universidade de São Paulo Instituto de Ciências Matemáticas e de Computação Cálculo Aproximado do número PI utilizando Programação Paralela Grupo 17 Raphael Ferras Renan Pagaiane Yule Vaz SSC-0143 Programação
Programação Engenharia Informática (11543) 1º ano, 1º semestre Tecnologias e Sistemas de Informação (6619) 1º ano, 1º semestre
 1º ano, 1º semestre Tecnologias e Sistemas de Informação (6619) 1º ano, 1º semestre") Programação Engenharia Informática (11543) 1º ano, 1º semestre Tecnologias e Sistemas de Informação (6619) 1º ano, 1º semestre Cap. 01 Fundamentos de Computadores Sumário : Conceitos básicos: computador,
Programação Engenharia Informática (11543) 1º ano, 1º semestre Tecnologias e Sistemas de Informação (6619) 1º ano, 1º semestre Cap. 01 Fundamentos de Computadores Sumário : Conceitos básicos: computador,
Experimentos com a memória cache do CPU
 Experimentos com a memória cache do CPU Alberto Bueno Júnior & Andre Henrique Serafim Casimiro Setembro de 2010 1 Contents 1 Introdução 3 2 Desvendando o cache 3 2.1 Para que serve o cache?.....................
Experimentos com a memória cache do CPU Alberto Bueno Júnior & Andre Henrique Serafim Casimiro Setembro de 2010 1 Contents 1 Introdução 3 2 Desvendando o cache 3 2.1 Para que serve o cache?.....................
Comparativo de desempenho do Pervasive PSQL v11
 Comparativo de desempenho do Pervasive PSQL v11 Um artigo Pervasive PSQL Setembro de 2010 Conteúdo Resumo executivo... 3 O impacto das novas arquiteturas de hardware nos aplicativos... 3 O projeto do Pervasive
Comparativo de desempenho do Pervasive PSQL v11 Um artigo Pervasive PSQL Setembro de 2010 Conteúdo Resumo executivo... 3 O impacto das novas arquiteturas de hardware nos aplicativos... 3 O projeto do Pervasive
UNIVERSIDADE ESTADUAL DE CAMPINAS FACULDADE DE ENGENHARIA MECÂNICA
 UNIVERSIDADE ESTADUAL DE CAMPINAS FACULDADE DE ENGENHARIA MECÂNICA Relatório Final Trabalho de Conclusão de Curso Partição de Domínios para Processamento em Cluster de GPUs Autor: Lucas Monteiro Volpe
UNIVERSIDADE ESTADUAL DE CAMPINAS FACULDADE DE ENGENHARIA MECÂNICA Relatório Final Trabalho de Conclusão de Curso Partição de Domínios para Processamento em Cluster de GPUs Autor: Lucas Monteiro Volpe
Arquitetura de Computadores - Revisão -
 Arquitetura de Computadores - Revisão - Principais funções de um Sistema Operacional Componentes básicos da Arquitetura Barramentos Registradores da CPU Ciclo de Instruções Interrupções Técnicas de E/S
Arquitetura de Computadores - Revisão - Principais funções de um Sistema Operacional Componentes básicos da Arquitetura Barramentos Registradores da CPU Ciclo de Instruções Interrupções Técnicas de E/S
Processamento de Sinal através do GPU
 Processamento de Sinal através do GPU Relatório Final do Projecto Informático n.º 15/ 2007-8, ei15888 Relatório final submetido para avaliação parcial da unidade curricular de Projecto Informático, do
Processamento de Sinal através do GPU Relatório Final do Projecto Informático n.º 15/ 2007-8, ei15888 Relatório final submetido para avaliação parcial da unidade curricular de Projecto Informático, do
Patrício Domingues Dep. Eng. Informática ESTG Instituto Politécnico de Leiria Leiria, Maio Programação Genérica de GPUs
 Patrício Domingues Dep. Eng. Informática ESTG Instituto Politécnico de Leiria Leiria, Maio 2012 http://bit.ly/patricio Programação Genérica de GPUs 1 CUDA Teaching Center A ESTG/IPLeiria é um CUDA Teaching
Patrício Domingues Dep. Eng. Informática ESTG Instituto Politécnico de Leiria Leiria, Maio 2012 http://bit.ly/patricio Programação Genérica de GPUs 1 CUDA Teaching Center A ESTG/IPLeiria é um CUDA Teaching
O hardware é a parte física do computador, como o processador, memória, placamãe, entre outras. Figura 2.1 Sistema Computacional Hardware
 1 2 Revisão de Hardware 2.1 Hardware O hardware é a parte física do computador, como o processador, memória, placamãe, entre outras. Figura 2.1 Sistema Computacional Hardware 2.1.1 Processador O Processador
1 2 Revisão de Hardware 2.1 Hardware O hardware é a parte física do computador, como o processador, memória, placamãe, entre outras. Figura 2.1 Sistema Computacional Hardware 2.1.1 Processador O Processador
Computação Paralela (CUDA)
") Universidade Federal do Amazonas Faculdade de Tecnologia Departamento de Eletrônica e Computação Computação Paralela (CUDA) Hussama Ibrahim hussamaibrahim@ufam.edu.br Notas de Aula Baseado nas Notas de
Universidade Federal do Amazonas Faculdade de Tecnologia Departamento de Eletrônica e Computação Computação Paralela (CUDA) Hussama Ibrahim hussamaibrahim@ufam.edu.br Notas de Aula Baseado nas Notas de
Hardware de Computadores
 Placa Mãe Hardware de Computadores Introdução Placa-mãe, também denominada mainboard ou motherboard, é uma placa de circuito impresso eletrônico. É considerado o elemento mais importante de um computador,
Placa Mãe Hardware de Computadores Introdução Placa-mãe, também denominada mainboard ou motherboard, é uma placa de circuito impresso eletrônico. É considerado o elemento mais importante de um computador,
Visão Geral da Arquitetura de Computadores. Prof. Elthon Scariel Dias
 Visão Geral da Arquitetura de Computadores Prof. Elthon Scariel Dias O que é Arquitetura de Computadores? Há várias definições para o termo arquitetura de computadores : É a estrutura e comportamento de
Visão Geral da Arquitetura de Computadores Prof. Elthon Scariel Dias O que é Arquitetura de Computadores? Há várias definições para o termo arquitetura de computadores : É a estrutura e comportamento de
PIP/CA - Programa Interdisciplinar de Pós-Graduação em Computação Aplicada da UNISINOS ALGORITMOS & ESTRUTURAS DE DADOS
 PIP/CA - Programa Interdisciplinar de Pós-Graduação em Computação Aplicada da UNISINOS Disciplina de Nivelamento - 2000/1: ALGORITMOS & ESTRUTURAS DE DADOS Professor Responsável: Prof. Fernando Santos
PIP/CA - Programa Interdisciplinar de Pós-Graduação em Computação Aplicada da UNISINOS Disciplina de Nivelamento - 2000/1: ALGORITMOS & ESTRUTURAS DE DADOS Professor Responsável: Prof. Fernando Santos
Introdução à Arquitetura de Computadores
 1 Introdução à Arquitetura de Computadores Hardware e software Organização de um computador: Processador: registradores, ALU, unidade de controle Memórias Dispositivos de E/S Barramentos Linguagens de
1 Introdução à Arquitetura de Computadores Hardware e software Organização de um computador: Processador: registradores, ALU, unidade de controle Memórias Dispositivos de E/S Barramentos Linguagens de
Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot
 Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Tomás Evalero Orellana Universidade Estadual de Santa Cruz Roteiro Breve introdução
Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Tomás Evalero Orellana Universidade Estadual de Santa Cruz Roteiro Breve introdução
ENTRADA E SAÍDA DE DADOS
 ENTRADA E SAÍDA DE DADOS Os dispositivos de um computador compartilham uma única via de comunicação BARRAMENTO. BARRAMENTO Elétrica/Mecânica + Protocolo. GERENCIAMENTO DE E/S O controle da troca de dados
ENTRADA E SAÍDA DE DADOS Os dispositivos de um computador compartilham uma única via de comunicação BARRAMENTO. BARRAMENTO Elétrica/Mecânica + Protocolo. GERENCIAMENTO DE E/S O controle da troca de dados
COMPUTAÇÃO PARALELA. uma visão geral. Guilherme Galante. v.2.0
 COMPUTAÇÃO PARALELA uma visão geral Guilherme Galante v.2.0 Guilherme Galante Bacharel em Informática Unioeste (2003) Mestre em Ciência da Computação UFRGS (2006) Professor Assistente do curso de Informática/Ciência
COMPUTAÇÃO PARALELA uma visão geral Guilherme Galante v.2.0 Guilherme Galante Bacharel em Informática Unioeste (2003) Mestre em Ciência da Computação UFRGS (2006) Professor Assistente do curso de Informática/Ciência
Introdução a Informática. Prof.: Roberto Franciscatto
 Introdução a Informática Prof.: Roberto Franciscatto 3.1 EXECUÇÃO DAS INSTRUÇÕES A UCP tem duas seções: Unidade de Controle Unidade Lógica e Aritmética Um programa se caracteriza por: uma série de instruções
Introdução a Informática Prof.: Roberto Franciscatto 3.1 EXECUÇÃO DAS INSTRUÇÕES A UCP tem duas seções: Unidade de Controle Unidade Lógica e Aritmética Um programa se caracteriza por: uma série de instruções
Estruturas do Sistema de Computação
 Estruturas do Sistema de Computação Prof. Dr. José Luís Zem Prof. Dr. Renato Kraide Soffner Prof. Ms. Rossano Pablo Pinto Faculdade de Tecnologia de Americana Centro Paula Souza Estruturas do Sistema de
Estruturas do Sistema de Computação Prof. Dr. José Luís Zem Prof. Dr. Renato Kraide Soffner Prof. Ms. Rossano Pablo Pinto Faculdade de Tecnologia de Americana Centro Paula Souza Estruturas do Sistema de
Visão Geral de Sistemas Operacionais
 Visão Geral de Sistemas Operacionais Sumário Um sistema operacional é um intermediário entre usuários e o hardware do computador. Desta forma, o usuário pode executar programas de forma conveniente e eficiente.
Visão Geral de Sistemas Operacionais Sumário Um sistema operacional é um intermediário entre usuários e o hardware do computador. Desta forma, o usuário pode executar programas de forma conveniente e eficiente.
O que veremos nesta aula? Principais Aspectos de Sistemas Operacionais. Visão geral de um sistema computacional
 O que veremos nesta aula? Principais Aspectos de Sistemas Operacionais Laboratório de Sistemas Operacionais Aula 1 Flávia Maristela (flavia@flaviamaristela.com) Tudo o que já vimos antes... Introdução
O que veremos nesta aula? Principais Aspectos de Sistemas Operacionais Laboratório de Sistemas Operacionais Aula 1 Flávia Maristela (flavia@flaviamaristela.com) Tudo o que já vimos antes... Introdução
Capítulo 4 Livro do Mário Monteiro Introdução Hierarquia de memória Memória Principal. Memória principal
 Capítulo 4 Livro do Mário Monteiro Introdução Hierarquia de memória Memória Principal Organização Operações de leitura e escrita Capacidade http://www.ic.uff.br/~debora/fac! 1 2 Componente de um sistema
Capítulo 4 Livro do Mário Monteiro Introdução Hierarquia de memória Memória Principal Organização Operações de leitura e escrita Capacidade http://www.ic.uff.br/~debora/fac! 1 2 Componente de um sistema
MC-102 Aula 01. Instituto de Computação Unicamp
 MC-102 Aula 01 Introdução à Programação de Computadores Instituto de Computação Unicamp 2015 Roteiro 1 Por que aprender a programar? 2 Hardware e Software 3 Organização de um ambiente computacional 4 Algoritmos
MC-102 Aula 01 Introdução à Programação de Computadores Instituto de Computação Unicamp 2015 Roteiro 1 Por que aprender a programar? 2 Hardware e Software 3 Organização de um ambiente computacional 4 Algoritmos
CP C U P U - Un U i n da d d a e d e Ce C n e t n ral a de d e Pr P oc o es e sam a e m n e t n o o Pr P oc o es e sad a o d r o Aula 03
 CPU - Unidade Central de Processamento Processador Aula 03 A CPU (Unid. Central de Processamento A unidade Central de Processamento, a CPU (Central Processing Unit), atua como o cérebro do sistema, processando
CPU - Unidade Central de Processamento Processador Aula 03 A CPU (Unid. Central de Processamento A unidade Central de Processamento, a CPU (Central Processing Unit), atua como o cérebro do sistema, processando
Arquitetura e Organização de Computadores. Capítulo 0 - Introdução
 Arquitetura e Organização de Computadores Capítulo 0 - Introdução POR QUE ESTUDAR ARQUITETURA DE COMPUTADORES? 2 https://www.cis.upenn.edu/~milom/cis501-fall12/ Entender para onde os computadores estão
Arquitetura e Organização de Computadores Capítulo 0 - Introdução POR QUE ESTUDAR ARQUITETURA DE COMPUTADORES? 2 https://www.cis.upenn.edu/~milom/cis501-fall12/ Entender para onde os computadores estão
Comparação de eficiência entre OpenCL e CUDA
 Aluno: Thiago de Gouveia Nunes Orientador: Prof. Marcel P. Jackowski GPGPU O que é GPGPU? É programação de propósito geral em GPUs. =D GPGPU Existem 2 linguagens populares no mercado para GPGPU, o CUDA
Aluno: Thiago de Gouveia Nunes Orientador: Prof. Marcel P. Jackowski GPGPU O que é GPGPU? É programação de propósito geral em GPUs. =D GPGPU Existem 2 linguagens populares no mercado para GPGPU, o CUDA
Sistemas Operacionais. Roteiro. Hardware. Marcos Laureano
 Sistemas Operacionais Marcos Laureano 1/25 Roteiro Estrutura de um sistema operacional Interrupções Proteção do núcleo Níveis de privilégio Chamadas de sistema 2/25 Mono-processadores atuais seguem um
Sistemas Operacionais Marcos Laureano 1/25 Roteiro Estrutura de um sistema operacional Interrupções Proteção do núcleo Níveis de privilégio Chamadas de sistema 2/25 Mono-processadores atuais seguem um
Windows NT 4.0. Centro de Computação
 Windows NT 4.0 Centro de Computação Tópicos Introdução Instalação Configuração Organização da rede Administração Usuários Servidores Domínios Segurança Tópicos È O sistema operacional Windows NT È Características:
Windows NT 4.0 Centro de Computação Tópicos Introdução Instalação Configuração Organização da rede Administração Usuários Servidores Domínios Segurança Tópicos È O sistema operacional Windows NT È Características:
Arquitetura e Organização de Computadores. Capítulo 0 - Introdução
 Arquitetura e Organização de Computadores Capítulo 0 - Introdução POR QUE ESTUDAR ARQUITETURA DE COMPUTADORES? 2 https://www.cis.upenn.edu/~milom/cis501-fall12/ Entender para onde os computadores estão
Arquitetura e Organização de Computadores Capítulo 0 - Introdução POR QUE ESTUDAR ARQUITETURA DE COMPUTADORES? 2 https://www.cis.upenn.edu/~milom/cis501-fall12/ Entender para onde os computadores estão
Processador ( CPU ) E/S. Memória. Sistema composto por Processador, Memória e dispositivos de E/S, interligados por um barramento
 E/S. Memória. Sistema composto por Processador, Memória e dispositivos de E/S, interligados por um barramento") 1 Processadores Computador Processador ( CPU ) Memória E/S Sistema composto por Processador, Memória e dispositivos de E/S, interligados por um barramento 2 Pastilha 3 Processadores (CPU,, Microcontroladores)
1 Processadores Computador Processador ( CPU ) Memória E/S Sistema composto por Processador, Memória e dispositivos de E/S, interligados por um barramento 2 Pastilha 3 Processadores (CPU,, Microcontroladores)
Infraestrutura de Hardware. Memória Virtual
 Infraestrutura de Hardware Memória Virtual Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é entendido e executado pelo HW? Qual é a interface
Infraestrutura de Hardware Memória Virtual Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é entendido e executado pelo HW? Qual é a interface
Introdução ao Processador CELL BE
 1 Introdução ao Processador CELL BE por: José Ricardo de Oliveira Damico 17 / Maio / 2007 São Paulo SP 2 SUMÁRIO LISTA DE FIGURAS 3 RESUMO 4 1.) INTRODUÇÃO 5 1.1) O que é? 5 2.) Utilização 5 3.) FUNCIONAMENTO
1 Introdução ao Processador CELL BE por: José Ricardo de Oliveira Damico 17 / Maio / 2007 São Paulo SP 2 SUMÁRIO LISTA DE FIGURAS 3 RESUMO 4 1.) INTRODUÇÃO 5 1.1) O que é? 5 2.) Utilização 5 3.) FUNCIONAMENTO
LICENCIATURA EM COMPUTAÇÃO PROCESSADOR TEGRA 2
 LICENCIATURA EM COMPUTAÇÃO PROCESSADOR TEGRA 2 SANTO AMARO 2011 ANGELO RAMOS JACKELINE BARBOSA JEANDERVAL SANTOS PROCESSADOR TEGRA 2 Trabalho apresentado ao Instituto Federal de Ciências e Tecnologia da
LICENCIATURA EM COMPUTAÇÃO PROCESSADOR TEGRA 2 SANTO AMARO 2011 ANGELO RAMOS JACKELINE BARBOSA JEANDERVAL SANTOS PROCESSADOR TEGRA 2 Trabalho apresentado ao Instituto Federal de Ciências e Tecnologia da
Sistemas Operacionais Gerência de Dispositivos
 Universidade Estadual de Mato Grosso do Sul UEMS Curso de Licenciatura em Computação Sistemas Operacionais Gerência de Dispositivos Prof. José Gonçalves Dias Neto profneto_ti@hotmail.com Introdução A gerência
Universidade Estadual de Mato Grosso do Sul UEMS Curso de Licenciatura em Computação Sistemas Operacionais Gerência de Dispositivos Prof. José Gonçalves Dias Neto profneto_ti@hotmail.com Introdução A gerência
TEMA DE CAPA. Introdução à Programação em CUDA
 TEMA DE CAPA Introdução à Programação em CUDA Introdução à Programação em CUDA Nos últimos anos, as placas gráficas (GPU Graphical Processing Unit) ganharam relevância no âmbito da computação paralela.
TEMA DE CAPA Introdução à Programação em CUDA Introdução à Programação em CUDA Nos últimos anos, as placas gráficas (GPU Graphical Processing Unit) ganharam relevância no âmbito da computação paralela.
Sistemas Operacionais I
 UFRJ IM - DCC Sistemas Operacionais I Unidade II - Threads 24/04/2014 Prof. Valeria M. Bastos 1 ORGANIZAÇÃO DA UNIDADE Threads Processos Threads Conceituação Descrição e Imagem de uma Thread Tipos de thread
UFRJ IM - DCC Sistemas Operacionais I Unidade II - Threads 24/04/2014 Prof. Valeria M. Bastos 1 ORGANIZAÇÃO DA UNIDADE Threads Processos Threads Conceituação Descrição e Imagem de uma Thread Tipos de thread
Processadores. Prof. Alexandre Beletti Ferreira
 Processadores Prof. Alexandre Beletti Ferreira Introdução O processador é um circuito integrado de controle das funções de cálculos e tomadas de decisão de um computador. Também é chamado de cérebro do
Processadores Prof. Alexandre Beletti Ferreira Introdução O processador é um circuito integrado de controle das funções de cálculos e tomadas de decisão de um computador. Também é chamado de cérebro do
Celso L. Mendes LAC /INPE
 Arquiteturas para Processamento de Alto Desempenho (PAD) Aula 9 Celso L. Mendes LAC /INPE Email: celso.mendes@inpe.br Aula 9 (3/5): E. Aceleradores Estrutura Planejada i. Estruturas mais Populares ii.
Arquiteturas para Processamento de Alto Desempenho (PAD) Aula 9 Celso L. Mendes LAC /INPE Email: celso.mendes@inpe.br Aula 9 (3/5): E. Aceleradores Estrutura Planejada i. Estruturas mais Populares ii.
Capítulo 1 Introdução
 Capítulo 1 Introdução Programa: Seqüência de instruções descrevendo como executar uma determinada tarefa. Computador: Conjunto do hardware + Software Os circuitos eletrônicos de um determinado computador
Capítulo 1 Introdução Programa: Seqüência de instruções descrevendo como executar uma determinada tarefa. Computador: Conjunto do hardware + Software Os circuitos eletrônicos de um determinado computador
Processador ARM Cortex-A9
 Erick Nogueira Nascimento (032483) Franz Pietz (076673) Lucas Watanabe (134068) 11 de junho de 2012 Introdução Alto desempenho e economia de energia Arquitetura ARMv7-A Características do processador super-escalável
Erick Nogueira Nascimento (032483) Franz Pietz (076673) Lucas Watanabe (134068) 11 de junho de 2012 Introdução Alto desempenho e economia de energia Arquitetura ARMv7-A Características do processador super-escalável
JOSÉ HENRIQUE MADEIRA CIMINO ANÁLISE DE PARALELISMO EM ARQUITETURA MULTICORE COM USO DE UNIDADE DE PROCESSAMENTO GRÁFICO
 1 FUNDAÇÃO DE ENSINO EURÍPIDES SOARES DA ROCHA CENTRO UNIVERSITÁRIO EURÍPIDES DE MARÍLIA UNIVEM CURSO DE CIÊNCIA DA COMPUTAÇÃO JOSÉ HENRIQUE MADEIRA CIMINO ANÁLISE DE PARALELISMO EM ARQUITETURA MULTICORE
1 FUNDAÇÃO DE ENSINO EURÍPIDES SOARES DA ROCHA CENTRO UNIVERSITÁRIO EURÍPIDES DE MARÍLIA UNIVEM CURSO DE CIÊNCIA DA COMPUTAÇÃO JOSÉ HENRIQUE MADEIRA CIMINO ANÁLISE DE PARALELISMO EM ARQUITETURA MULTICORE
Introdução aos Computadores
 Os Computadores revolucionaram as formas de processamento de Informação pela sua capacidade de tratar grandes quantidades de dados em curto espaço de tempo. Nos anos 60-80 os computadores eram máquinas
Os Computadores revolucionaram as formas de processamento de Informação pela sua capacidade de tratar grandes quantidades de dados em curto espaço de tempo. Nos anos 60-80 os computadores eram máquinas
Primeiro Curso de Programação em C 3 a Edição
 Edson Luiz França Senne Primeiro Curso de Programação em C 3 a Edição Visual Books Sumário Prefácio da Terceira Edição 9 Prefácio da Primeira Edição 11 Aula 1 13 Regras de sintaxe de uma linguagem de programação...
Edson Luiz França Senne Primeiro Curso de Programação em C 3 a Edição Visual Books Sumário Prefácio da Terceira Edição 9 Prefácio da Primeira Edição 11 Aula 1 13 Regras de sintaxe de uma linguagem de programação...
MC4: Introdução à Programação Paralela em GPU para a Implementação de Métodos Numéricos
 MC4: Introdução à Programação Paralela em GPU para a Implementação de Métodos Numéricos Aula 1: Introdução à programação paralela e ao ambiente de programação CUDA Profs.: Daniel Alfaro e Silvana Rossetto
MC4: Introdução à Programação Paralela em GPU para a Implementação de Métodos Numéricos Aula 1: Introdução à programação paralela e ao ambiente de programação CUDA Profs.: Daniel Alfaro e Silvana Rossetto
Sistemas Operacionais
 Sistemas Operacionais Aula 5 Estrutura de Sistemas de Computação Prof.: Edilberto M. Silva http://www.edilms.eti.br Baseado no material disponibilizado por: SO - Prof. Edilberto Silva Prof. José Juan Espantoso
Sistemas Operacionais Aula 5 Estrutura de Sistemas de Computação Prof.: Edilberto M. Silva http://www.edilms.eti.br Baseado no material disponibilizado por: SO - Prof. Edilberto Silva Prof. José Juan Espantoso
Introdução à Linguagem C/C++ Parte I
 Linguagem de Programação I Introdução à Linguagem C/C++ Parte I Professor Mestre Ricardo Alexandre Carmona SÃO PAULO - 2014 Introdução à Linguagem C/C++ - Parte I 1 - HISTÓRICO A Linguagem de Programação
Linguagem de Programação I Introdução à Linguagem C/C++ Parte I Professor Mestre Ricardo Alexandre Carmona SÃO PAULO - 2014 Introdução à Linguagem C/C++ - Parte I 1 - HISTÓRICO A Linguagem de Programação
Hardware (Nível 0) Organização. Interface de Máquina (IM) Interface Interna de Microprogramação (IIMP)
 Organização. Interface de Máquina (IM) Interface Interna de Microprogramação (IIMP)") Hardware (Nível 0) Organização O AS/400 isola os usuários das características do hardware através de uma arquitetura de camadas. Vários modelos da família AS/400 de computadores de médio porte estão disponíveis,
Hardware (Nível 0) Organização O AS/400 isola os usuários das características do hardware através de uma arquitetura de camadas. Vários modelos da família AS/400 de computadores de médio porte estão disponíveis,
Introdução. Sistemas Operacionais
 FATEC SENAC Introdução à Sistemas Operacionais Rodrigo W. Fonseca Sumário Definição de um S.O. Características de um S.O. História (evolução dos S.O.s) Estruturas de S.O.s Tipos de Sistemas Operacionais
FATEC SENAC Introdução à Sistemas Operacionais Rodrigo W. Fonseca Sumário Definição de um S.O. Características de um S.O. História (evolução dos S.O.s) Estruturas de S.O.s Tipos de Sistemas Operacionais
Sistemas Operacionais
 Sistemas Operacionais SISTEMAS COM MÚLTIPLOS PROCESSADORES LIVRO TEXTO: CAPÍTULO 13, PÁGINA 243 Prof. Pedro Luís Antonelli Anhanguera Educacional INTRODUÇÃO Arquiteturas que possuem duas ou mais CPUs interligadas
Sistemas Operacionais SISTEMAS COM MÚLTIPLOS PROCESSADORES LIVRO TEXTO: CAPÍTULO 13, PÁGINA 243 Prof. Pedro Luís Antonelli Anhanguera Educacional INTRODUÇÃO Arquiteturas que possuem duas ou mais CPUs interligadas
ARQUITETURA DE COMPUTADORES - 1866
 7 Unidade Central de Processamento (UCP): O processador é o componente vital do sistema de computação, responsável pela realização das operações de processamento e de controle, durante a execução de um
7 Unidade Central de Processamento (UCP): O processador é o componente vital do sistema de computação, responsável pela realização das operações de processamento e de controle, durante a execução de um
Processamento Paralelo Utilizando GPU
 Processamento Paralelo Utilizando GPU Universidade Estadual de Santa Cruz Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Evalero Orellana Cronograma Breve introdução sobre processamento paralelo
Processamento Paralelo Utilizando GPU Universidade Estadual de Santa Cruz Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Evalero Orellana Cronograma Breve introdução sobre processamento paralelo
Tais operações podem utilizar um (operações unárias) ou dois (operações binárias) valores.
 ou dois (operações binárias) valores.") Tais operações podem utilizar um (operações unárias) ou dois (operações binárias) valores. 7.3.1.2 Registradores: São pequenas unidades de memória, implementadas na CPU, com as seguintes características:
Tais operações podem utilizar um (operações unárias) ou dois (operações binárias) valores. 7.3.1.2 Registradores: São pequenas unidades de memória, implementadas na CPU, com as seguintes características:
Análises Geração RI (representação intermediária) Código Intermediário
 Código Intermediário") Front-end Análises Geração RI (representação intermediária) Código Intermediário Back-End Geração de código de máquina Sistema Operacional? Conjunto de Instruções do processador? Ambiente de Execução O
Front-end Análises Geração RI (representação intermediária) Código Intermediário Back-End Geração de código de máquina Sistema Operacional? Conjunto de Instruções do processador? Ambiente de Execução O
Sistema Operacional Correção - Exercício de Revisão
 Prof. Kleber Rovai 1º TSI 22/03/2012 Sistema Operacional Correção - Exercício de Revisão 1. Como seria utilizar um computador sem um sistema operacional? Quais são suas duas principais funções? Não funcionaria.
Prof. Kleber Rovai 1º TSI 22/03/2012 Sistema Operacional Correção - Exercício de Revisão 1. Como seria utilizar um computador sem um sistema operacional? Quais são suas duas principais funções? Não funcionaria.
ALP Algoritmos e Programação. . Linguagens para Computadores
 ALP Algoritmos e Programação Iniciação aos computadores. Linguagens para Computadores. Compiladores, Interpretadores. Ambientes de Programação 1 Linguagens para Computadores. Linguagem binária: Dispositivos
ALP Algoritmos e Programação Iniciação aos computadores. Linguagens para Computadores. Compiladores, Interpretadores. Ambientes de Programação 1 Linguagens para Computadores. Linguagem binária: Dispositivos
CPU Unidade Central de Processamento. História e progresso
 CPU Unidade Central de Processamento História e progresso O microprocessador, ou CPU, como é mais conhecido, é o cérebro do computador e é ele que executa todos os cálculos e processamentos necessários,
CPU Unidade Central de Processamento História e progresso O microprocessador, ou CPU, como é mais conhecido, é o cérebro do computador e é ele que executa todos os cálculos e processamentos necessários,
 Gerência de Memória RAM em Computadores com Mais de 4GB O sistema Windows x86 (32bits) não tem capacidade de reconhecer, fisicamente, mais que 3,X GB de RAM, a não ser que seja ativado, manualmente, o
Gerência de Memória RAM em Computadores com Mais de 4GB O sistema Windows x86 (32bits) não tem capacidade de reconhecer, fisicamente, mais que 3,X GB de RAM, a não ser que seja ativado, manualmente, o
Estrutura de um Computador
 SEL-0415 Introdução à Organização de Computadores Estrutura de um Computador Aula 7 Prof. Dr. Marcelo Andrade da Costa Vieira MODELO DE VON NEUMANN PRINCÍPIOS A arquitetura de um computador consiste de
SEL-0415 Introdução à Organização de Computadores Estrutura de um Computador Aula 7 Prof. Dr. Marcelo Andrade da Costa Vieira MODELO DE VON NEUMANN PRINCÍPIOS A arquitetura de um computador consiste de
5 Entrada e Saída de Dados:
 5 Entrada e Saída de Dados: 5.1 - Arquitetura de Entrada e Saída: O sistema de entrada e saída de dados é o responsável pela ligação do sistema computacional com o mundo externo. Através de dispositivos
5 Entrada e Saída de Dados: 5.1 - Arquitetura de Entrada e Saída: O sistema de entrada e saída de dados é o responsável pela ligação do sistema computacional com o mundo externo. Através de dispositivos
O processador é composto por: Unidade de controlo - Interpreta as instruções armazenadas; - Dá comandos a todos os elementos do sistema.
 O processador é composto por: Unidade de controlo - Interpreta as instruções armazenadas; - Dá comandos a todos os elementos do sistema. Unidade aritmética e lógica - Executa operações aritméticas (cálculos);
O processador é composto por: Unidade de controlo - Interpreta as instruções armazenadas; - Dá comandos a todos os elementos do sistema. Unidade aritmética e lógica - Executa operações aritméticas (cálculos);
3/9/2010. Ligação da UCP com o barramento do. sistema. As funções básicas dos registradores nos permitem classificá-los em duas categorias:
 Arquitetura de Computadores Estrutura e Funcionamento da CPU Prof. Marcos Quinet Universidade Federal Fluminense P.U.R.O. Revisão dos conceitos básicos O processador é o componente vital do sistema de
Arquitetura de Computadores Estrutura e Funcionamento da CPU Prof. Marcos Quinet Universidade Federal Fluminense P.U.R.O. Revisão dos conceitos básicos O processador é o componente vital do sistema de