Tópicos em Física Computacional: Introdução a Linguagem CUDA
|
|
|
- Daniel Fernandes Sequeira
- 6 Há anos
- Visualizações:
Transcrição
1 Tópicos em Física Computacional: Introdução a Linguagem CUDA Aula 06: Introdução a Linguagem CUDA Otimização do Código Carine P. Beatrici IF UFRGS 1
2 Da Aula Passada... Programa que soma matrizes linearizadas; Numero de blocos por grid: dim3 gridsize(ceil(float(n*n)/float(blocksize.x)), ceil(float(n*n)/float(blocksize.y))); Numero de threads por bloco: dim3 blocksize(16,16); 2
3 #include<stdio.h> #include<stdlib.h> void global soma(int *a, int *b, int *s, int n); int main(void) { int *a,*b, *c; int *Ga,*Gb,*Gc; int n, i;; printf("\n Entre com a dimensao da matriz \n\n"); scanf("%d",&n); dim3 blocksize(16,16); dim3 gridsize(ceil(float(n*n)/float(blocksize.x)),ceil(float (n*n)/float(blocksize.x))); // Alocacao de memoria para as matrizes a,b,c a=(int *)malloc(n*n*sizeof(int)); b=(int *)malloc(n*n*sizeof(int)); c=(int *)malloc(n*n*sizeof(int)); cudamalloc((void **)&Ga,n*n*sizeof(int )); cudamalloc((void **)&Gb,n*n*sizeof(int )); cudamalloc((void **)&Gc,n*n*sizeof(int )); // Atribuindo valores para a e b for (i=0;i<n*n;i++) { a[i]=i; b[i]=n*n-1;} cudamemcpy( Ga,a,n*n*sizeof(int),cudaMemcpyHostTo Device); cudamemcpy( Gb,b,n*n*sizeof(int),cudaMemcpyHostTo Device); soma<<<gridsize,blocksize>>>(ga,gb,gc,n); cudamemcpy( c, Gc, n*n*sizeof(int), cudamemcpydevicetohost); printf("c[%d]= %d a+b= %d\n",n-1,c[n*n-1],a[n*n- 1]+b[n*n-1]); } free(a); free(b); free(c); cudafree(ga); cudafree(gb); cudafree(gc); void global soma(int *a,int *b,int *s, int n) { } int i,j; i = blockidx.x * blockdim.x + threadidx.x; j = blockidx.y * blockdim.y + threadidx.y; int tid = i*n + j; if (tid < n*n) { } s[tid] = a[tid] + b[tid]; 3
4 Escolha Eficiente Com aquela definição criamos muitos blocos desnecessários Consequentemente muitas threads desnecessárias; Podemos melhorar a definição para: dim3 gridsize(ceil(float(n)/float(blocksize.x)), ceil(float(n)/float(blocksize.y))); É possível melhorar a definição do numero de threads por bloco? 4
5 Escolha do Blocksize Número de threads por bloco depende do modelo da GPU; Para ver a especificação da placa usa-se o programa devicequery; 5
6 O devicequery É um programa de amostras do SDK da Nvidia; Mostra as características da GPU; Pode-se usar para testar se o CUDA esta corretamente instalado; Para executa-lo, na linha de comando:./devicequery 6
7 O devicequery Device 0: "GeForce GTX 560" CUDA Driver Version / Runtime Version 4.2 / 4.2 CUDA Capability Major/Minor version number: 2.1 Total amount of global memory: 2048 MBytes ( bytes) ( 7) Multiprocessors x ( 48) CUDA Cores/MP: 336 CUDA Cores GPU Clock rate: 1620 MHz (1.62 GHz) Memory Clock rate: 2004 Mhz Memory Bus Width: 256-bit L2 Cache Size: bytes Max Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536,65535), 3D=(2048,2048,2048) Max Layered Texture Size (dim) x layers 1D=(16384) x 2048, 2D=(16384,16384) x 2048 Total amount of constant memory: bytes Total amount of shared memory per block: bytes Total number of registers available per block: Warp size: 32 Maximum number of threads per multiprocessor: 1536 Maximum number of threads per block:

8 8


9 9
10 Maximum sizes of each dimension of a block: 1024 x 1024 x 64 Maximum sizes of each dimension of a grid: x x Maximum memory pitch: bytes Texture alignment: 512 bytes Concurrent copy and execution: Yes with 1 copy engine(s) Run time limit on kernels: No Integrated GPU sharing Host Memory: No Support host page-locked memory mapping: Yes Concurrent kernel execution: Yes Alignment requirement for Surfaces: Yes Device has ECC support enabled: No Device is using TCC driver mode: No Device supports Unified Addressing (UVA): Yes Device PCI Bus ID / PCI location ID: 2 / 0 10
11 Como Otimizar a Execução Em alguns casos é melhor preencher todas as threads por bloco; Em outros casos é melhor distribuir as threads em todo o grid, criando mais blocos com menos threads; Existem situações onde ter dois blocos por multiprocessor pode ser melhor, devido a troca de threads; É necessário estudar o problema; 11
12 Compilando nvcc -arch sm_xx nome.cu -o gpu-exec Onde XX <= CUDA Capability visto no devicequery 12
13 Medindo o Tempo de Execução Podemos fazer isso: dentro do programa; Por linha de comando; 13
14 Medindo o Tempo de Execução Em C: Inclui a biblioteca: #include <time.h> Declara variáveis de tempo: clock_t tini,tfin; Valor de inicio da contagem do tempo: tini = clock(); Valor de término da contagem do tempo: tfin = clock(); Intervalo de tempo em segundos: dt = (float)(tfin - tini) / CLOCKS_PER_SEC; 14
15 Medindo o Tempo de Execução Em CUDA: Declara variáveis de tempo: cudaevent_t start, stop; float time; Valor de inicio da contagem do tempo: cudaeventcreate(&start); cudaeventcreate(&stop); cudaeventrecord( start, 0 ); Valor de término da contagem do tempo: cudaeventrecord( stop, 0 ); cudaeventsynchronize( stop ); Intervalo de tempo em milissegundos: cudaeventelapsedtime( &time, start, stop ); cudaeventdestroy( start ); cudaeventdestroy( stop ); Intervalo de tempo em segundos: time/=1000.0; 15
16 Medindo o Tempo de Execução Podemos fazer a medida de tempo de forma mais simples fora do código, em tempo de execução; Para programas em CPU usamos o comando time: time./executavel Para as funções da GPU temos o nvprof: nvprof./gpu-executavel Não esta instalado nos nodes da ada. 16
17 Regras de Programação em GPGPU Coloque os dados na GPGPU e os mantenha lá; De bastante trabalho para a GPGPU fazer; Foque no reuso dos dados dentro da GPGPU para evitar as limitações da banda de memoria. 17
18 Otimizando o Código Otimizar o código é a parte mais difícil do desenvolvimento de um programa CUDA. Hoje este processo ainda é artesanal, dependente do problema e da placa utilizada; Alguns pontos importantes a considerar são: Divergência do controle de fluxo Ocupação dos processadores Acesso combinado (coalesced) à memória global Conflitos de bancos da memória compartilhada Chamada do Kernel 18
19 Divergência do Controle de Fluxo As thread de cada bloco são divididas em warps, contendo 16 ou 32 threads, GPUs permitem a execução simultânea de todas as threads do warp, desde que todas executem o mesmo código Quando threads executam códigos diferentes, dizemos que houve uma divergência na execução do código.. Exemplos: comandos if, else, while, for, etc. global void VecAdd(float* A, float* B, float* C, int n) { int i =threadidx.x; if (i < n) C[i] = A[i] + B[i]; } 19
20 Ocupação dos Multiprocessadores O segredo para obter um bom desempenho é manter os processadores da GPU sempre ocupados (há discussões). Para tal: Os blocos devem ter tamanhos múltiplos do warp; Usar o menor número possível de registradores por thread O número de blocos por multiprocessador será maior Com mais blocos por multiprocessador, temos mais opções de threads para execução; Especialmente quando as threads estiverem esperando por dados da memória global; Melhor otimização depende do problema. 20
21 21
22 Acesso Combinado (Coalesced) Acesso a Matrizes por linhas ou colunas: O principio é o mesmo; Se acessar a memoria em sequencia será mais rápido do que fora de sequencia; Quando as threads de um warp acessam a memória ao mesmo tempo, o CUDA combina os acessos em uma única requisição; Para tal, todas os endereços devem estar localizados em um único intervalo de 128B; 22
23 23

24 24
25 25
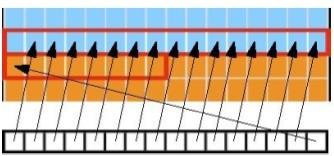
26 26
27 Acesso não sequencial Stride = separação entre os acessos; Bandwidth = banda de transmição; 27
28 Links úteis CUDA Nvidia 28
29 29
Fabrício Gomes Vilasbôas
 Fabrício Gomes Vilasbôas Apresentação Placas Arquitetura Toolkit e Ferramentas de Debug Pensando em CUDA Programação CUDA Python Programação PyCUDA 1) Grids( padrão Globus) 2) Clusters ( padrão MPI) 3)
Fabrício Gomes Vilasbôas Apresentação Placas Arquitetura Toolkit e Ferramentas de Debug Pensando em CUDA Programação CUDA Python Programação PyCUDA 1) Grids( padrão Globus) 2) Clusters ( padrão MPI) 3)
Eng. Thársis T. P. Souza
 Introdução à Computação de Alto Desempenho Utilizando GPU Seminário de Programação em GPGPU Eng. Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo Introdução
Introdução à Computação de Alto Desempenho Utilizando GPU Seminário de Programação em GPGPU Eng. Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo Introdução
Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot
 Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Tomás Evalero Orellana Universidade Estadual de Santa Cruz Roteiro Breve introdução
Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Tomás Evalero Orellana Universidade Estadual de Santa Cruz Roteiro Breve introdução
Processamento de Alto Desempenho utilizando Unidade de Processamento Gráfico - GPU
 Processamento de Alto Desempenho utilizando Unidade de Processamento Gráfico - GPU Francisco Ribacionka e Ettore Enrico (STI ) USP/STI/InterNuvem internuvem@usp.br Março -2016 Processamento de Alto Desempenho
Processamento de Alto Desempenho utilizando Unidade de Processamento Gráfico - GPU Francisco Ribacionka e Ettore Enrico (STI ) USP/STI/InterNuvem internuvem@usp.br Março -2016 Processamento de Alto Desempenho
5 Unidades de Processamento Gráfico GPUs
 5 Unidades de Processamento Gráfico GPUs As GPUs são processadores maciçamente paralelos, com múltiplos elementos de processamento, tipicamente utilizadas como aceleradores de computação. Elas fornecem
5 Unidades de Processamento Gráfico GPUs As GPUs são processadores maciçamente paralelos, com múltiplos elementos de processamento, tipicamente utilizadas como aceleradores de computação. Elas fornecem
Aplicações em CUDA. Medialab Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center
 Aplicações em CUDA Medialab Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center Roteiro l Introdução l Eventos l Aspectos históricos l Operações atômicas l Introdução sobre
Aplicações em CUDA Medialab Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center Roteiro l Introdução l Eventos l Aspectos históricos l Operações atômicas l Introdução sobre
Aula 10 - Streams (Parte I)
") Disciplina de TICs 1 - Introdução a Programação em GPGPU Aula 10 - Streams (Parte I) Introdução Até então foi visto como engenho de processamento paralelo massivo de dados nas GPUs pode aumentar assombrosamente
Disciplina de TICs 1 - Introdução a Programação em GPGPU Aula 10 - Streams (Parte I) Introdução Até então foi visto como engenho de processamento paralelo massivo de dados nas GPUs pode aumentar assombrosamente
Thársis T. P. Souza
 Computação em Finanças em Hardware Gráfico SEMAC 2012 - UNESP Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo GPU Computing CUDA Aplicações em Finanças
Computação em Finanças em Hardware Gráfico SEMAC 2012 - UNESP Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo GPU Computing CUDA Aplicações em Finanças
Waldemar Celes. 25 de Agosto de 2014
 Introdução a CUDA INF2062 Tópicos em Simulação e Visualização Waldemar Celes celes@inf.puc-rio.br Tecgraf, DI/PUC-Rio 25 de Agosto de 2014 W. Celes Introdução a CUDA 1 GPGPU Programação de propósito geral
Introdução a CUDA INF2062 Tópicos em Simulação e Visualização Waldemar Celes celes@inf.puc-rio.br Tecgraf, DI/PUC-Rio 25 de Agosto de 2014 W. Celes Introdução a CUDA 1 GPGPU Programação de propósito geral
Patrício Domingues Dep. Eng. Informática ESTG Instituto Politécnico de Leiria Leiria, Maio Programação Genérica de GPUs
 Patrício Domingues Dep. Eng. Informática ESTG Instituto Politécnico de Leiria Leiria, Maio 2012 http://bit.ly/patricio Programação Genérica de GPUs 1 CUDA Teaching Center A ESTG/IPLeiria é um CUDA Teaching
Patrício Domingues Dep. Eng. Informática ESTG Instituto Politécnico de Leiria Leiria, Maio 2012 http://bit.ly/patricio Programação Genérica de GPUs 1 CUDA Teaching Center A ESTG/IPLeiria é um CUDA Teaching
Sparse Matrix-Vector Multiplication on GPU: When Is Rows Reordering Worthwhile?
 Sparse Matrix-Vector Multiplication on GPU: When Is Rows Reordering Worthwhile? Paula Prata João Muranho Instituto de Telecomunicações Departamento de Informática Universidade da Beira Interior Instituto
Sparse Matrix-Vector Multiplication on GPU: When Is Rows Reordering Worthwhile? Paula Prata João Muranho Instituto de Telecomunicações Departamento de Informática Universidade da Beira Interior Instituto
TEMA DE CAPA. Introdução à Programação em CUDA
 TEMA DE CAPA Introdução à Programação em CUDA Introdução à Programação em CUDA Nos últimos anos, as placas gráficas (GPU Graphical Processing Unit) ganharam relevância no âmbito da computação paralela.
TEMA DE CAPA Introdução à Programação em CUDA Introdução à Programação em CUDA Nos últimos anos, as placas gráficas (GPU Graphical Processing Unit) ganharam relevância no âmbito da computação paralela.
Arquitetura e Programação de GPU. Leandro Zanotto RA: 001962 Anselmo Ferreira RA: 023169 Marcelo Matsumoto RA: 085973
 Arquitetura e Programação de GPU Leandro Zanotto RA: 001962 Anselmo Ferreira RA: 023169 Marcelo Matsumoto RA: 085973 Agenda Primeiras Placas de Vídeo Primeira GPU Arquitetura da GPU NVIDIA Arquitetura
Arquitetura e Programação de GPU Leandro Zanotto RA: 001962 Anselmo Ferreira RA: 023169 Marcelo Matsumoto RA: 085973 Agenda Primeiras Placas de Vídeo Primeira GPU Arquitetura da GPU NVIDIA Arquitetura
Celso L. Mendes LAC /INPE
 Arquiteturas para Processamento de Alto Desempenho (PAD) Aula 9 Celso L. Mendes LAC /INPE Email: celso.mendes@inpe.br Aula 9 (3/5): E. Aceleradores Estrutura Planejada i. Estruturas mais Populares ii.
Arquiteturas para Processamento de Alto Desempenho (PAD) Aula 9 Celso L. Mendes LAC /INPE Email: celso.mendes@inpe.br Aula 9 (3/5): E. Aceleradores Estrutura Planejada i. Estruturas mais Populares ii.
PARALELIZAÇÃO DE APLICAÇÕES NA ARQUITETURA CUDA: UM ESTUDO SOBRE VETORES 1
 PARALELIZAÇÃO DE APLICAÇÕES NA ARQUITETURA CUDA: UM ESTUDO SOBRE VETORES 1 DUTRA, Evandro Rogério Fruhling 2 ; VARINI, Andre Luis 2 ; CANAL, Ana Paula 2 1 Trabalho de Iniciação Científica _UNIFRA 2 Ciência
PARALELIZAÇÃO DE APLICAÇÕES NA ARQUITETURA CUDA: UM ESTUDO SOBRE VETORES 1 DUTRA, Evandro Rogério Fruhling 2 ; VARINI, Andre Luis 2 ; CANAL, Ana Paula 2 1 Trabalho de Iniciação Científica _UNIFRA 2 Ciência
Aplicando Processamento Paralelo com GPU ao Problema do Fractal de Mandelbrot
 Aplicando Processamento Paralelo com GPU ao Problema do Fractal de Mandelbrot Bruno Pereira dos Santos¹, Dany Sanchez Dominguez¹, Esbel Valero Orellana¹. 1 Departamento de Ciências Exatas e Tecnológicas
Aplicando Processamento Paralelo com GPU ao Problema do Fractal de Mandelbrot Bruno Pereira dos Santos¹, Dany Sanchez Dominguez¹, Esbel Valero Orellana¹. 1 Departamento de Ciências Exatas e Tecnológicas
Prinfor - A sua loja de confiança
 Produto Nome: Intel Pentium G4400 3,3 GHZ, 3MB Cache, LG BX80662G4400 Fabricante: Intel Preço: 64,35 Descrição Detalhes técnicos Memória da placa de vídeo do subsistema 1740 MB de gráfico Cache do processador
Produto Nome: Intel Pentium G4400 3,3 GHZ, 3MB Cache, LG BX80662G4400 Fabricante: Intel Preço: 64,35 Descrição Detalhes técnicos Memória da placa de vídeo do subsistema 1740 MB de gráfico Cache do processador
Programação em Paralelo. N. Cardoso & P. Bicudo. Física Computacional - MEFT 2012/2013
 Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 23 CUDA "Compute Unified Device Architecture" Parte 2
Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 23 CUDA "Compute Unified Device Architecture" Parte 2
Universidade Federal do ABC. Dissertação de Mestrado. Aderbal de Morais Junior
 Universidade Federal do ABC Curso de Pós Graduação em Ciência da Computação Dissertação de Mestrado Aderbal de Morais Junior UMA BIBLIOTECA PARA DESENVOLVIMENTO DE APLICAÇÕES CUDA EM AGLOMERADOS DE GPUS
Universidade Federal do ABC Curso de Pós Graduação em Ciência da Computação Dissertação de Mestrado Aderbal de Morais Junior UMA BIBLIOTECA PARA DESENVOLVIMENTO DE APLICAÇÕES CUDA EM AGLOMERADOS DE GPUS
Programação em Paralelo. N. Cardoso & P. Bicudo. Física Computacional - MEFT 2010/2011
 Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 11 CUDA Parte 2 N. Cardoso & P. Bicudo Programação em
Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 11 CUDA Parte 2 N. Cardoso & P. Bicudo Programação em
Organização de Computadores II
 Universidade Estácio de Sá Curso de Informática Organização de Computadores II Entrada e Saída Prof. Gabriel P. Silva 24.11.2004 Comunicação com o Processador A comunicação dos periféricos com o processador
Universidade Estácio de Sá Curso de Informática Organização de Computadores II Entrada e Saída Prof. Gabriel P. Silva 24.11.2004 Comunicação com o Processador A comunicação dos periféricos com o processador
Patricia Akemi Ikeda
 Um estudo do uso eficiente de programas em placas gráficas Patricia Akemi Ikeda Dissertação apresentada ao Instituto de Matemática e Estatística da Universidade de São Paulo para obtenção do título de
Um estudo do uso eficiente de programas em placas gráficas Patricia Akemi Ikeda Dissertação apresentada ao Instituto de Matemática e Estatística da Universidade de São Paulo para obtenção do título de
Universidade Federal de Minas Gerais. Sistemas Operacionais. Aula 19. Sistema de Entrada/Saída
 Aula 19 Sistema de Entrada/Saída Sistema de E/S Por que estudar? Essenciais! Muitos tipos: - mouse - discos - impressora - scanner - rede - modem Cada fabricante complica de um jeito diferente. Tempos
Aula 19 Sistema de Entrada/Saída Sistema de E/S Por que estudar? Essenciais! Muitos tipos: - mouse - discos - impressora - scanner - rede - modem Cada fabricante complica de um jeito diferente. Tempos
UNIVERSIDADE FEDERAL DO RIO GRANDE DO SUL INSTITUTO DE INFORMÁTICA. INF Benchmark de Memória e Chipset
 UNIVERSIDADE FEDERAL DO RIO GRANDE DO SUL INSTITUTO DE INFORMÁTICA INF01 112 2010 Benchmark de Memória e Chipset me: Samuel Salamon Identificação: 173255 Turma: C Passo 1 Executeo programa SiSoftware Sandra
UNIVERSIDADE FEDERAL DO RIO GRANDE DO SUL INSTITUTO DE INFORMÁTICA INF01 112 2010 Benchmark de Memória e Chipset me: Samuel Salamon Identificação: 173255 Turma: C Passo 1 Executeo programa SiSoftware Sandra
Computadores e Programação (DCC/UFRJ)
") Computadores e Programação (DCC/UFRJ) Aula 3: 1 2 3 Abstrações do Sistema Operacional Memória virtual Abstração que dá a cada processo a ilusão de que ele possui uso exclusivo da memória principal Todo
Computadores e Programação (DCC/UFRJ) Aula 3: 1 2 3 Abstrações do Sistema Operacional Memória virtual Abstração que dá a cada processo a ilusão de que ele possui uso exclusivo da memória principal Todo
INF Programação Distribuída e Paralela
 INF01008 - Programação Distribuída e Paralela Trabalho Final Multiplicação de Matrizes com APIs de Programação Paralela Cristiano Medeiros Dalbem John Gamboa Introdução Neste trabalho comparamos diferentes
INF01008 - Programação Distribuída e Paralela Trabalho Final Multiplicação de Matrizes com APIs de Programação Paralela Cristiano Medeiros Dalbem John Gamboa Introdução Neste trabalho comparamos diferentes
Programação em Paralelo. N. Cardoso & P. Bicudo. Física Computacional - MEFT 2010/2011
 Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 12 CUDA Parte 3 N. Cardoso & P. Bicudo Programação em
Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 12 CUDA Parte 3 N. Cardoso & P. Bicudo Programação em
Gerência de Dispositivos. Adão de Melo Neto
 Gerência de Dispositivos Adão de Melo Neto 1 Gerência de Dispositivos Gerência de Dispositivos Dispositivos de E/S Device Drivers Controladores Subsistema de E/S 2 Gerência de Dispositivos A gerência de
Gerência de Dispositivos Adão de Melo Neto 1 Gerência de Dispositivos Gerência de Dispositivos Dispositivos de E/S Device Drivers Controladores Subsistema de E/S 2 Gerência de Dispositivos A gerência de
PARALELIZAÇÃO DO ALGORITMO AES E ANÁLISE SOBRE GPGPU 1 PARALLELIZATION OF AES ALGORITHM AND GPU ANALYSIS
 Disciplinarum Scientia. Série: Naturais e Tecnológicas, Santa Maria, v. 16, n. 1, p. 83-94, 2015. Recebido em: 11.04.2015. Aprovado em: 30.06.2015. ISSN 2176-462X PARALELIZAÇÃO DO ALGORITMO AES E ANÁLISE
Disciplinarum Scientia. Série: Naturais e Tecnológicas, Santa Maria, v. 16, n. 1, p. 83-94, 2015. Recebido em: 11.04.2015. Aprovado em: 30.06.2015. ISSN 2176-462X PARALELIZAÇÃO DO ALGORITMO AES E ANÁLISE
Exercícios de Sistemas Operacionais 3 B (1) Gerência de Dispositivos de Entrada e Saída
 Gerência de Dispositivos de Entrada e Saída") Nome: Exercícios de Sistemas Operacionais 3 B (1) Gerência de Dispositivos de Entrada e Saída 1. A gerência de dispositivos de entrada e saída é uma das principais e mais complexas funções de um sistema
Nome: Exercícios de Sistemas Operacionais 3 B (1) Gerência de Dispositivos de Entrada e Saída 1. A gerência de dispositivos de entrada e saída é uma das principais e mais complexas funções de um sistema
ALOCAÇÃO DINÂMICA DE MEMORIA Lista 10. A linguagem C/C++ possui recursos para alocação dinâmica de memoria.
 ALOCAÇÃO DINÂMICA DE MEMORIA Lista 10 A linguagem C/C++ possui recursos para alocação dinâmica de memoria. As funções que trabalham com alocação de memoria se encontram na biblioteca void *calloc(int
ALOCAÇÃO DINÂMICA DE MEMORIA Lista 10 A linguagem C/C++ possui recursos para alocação dinâmica de memoria. As funções que trabalham com alocação de memoria se encontram na biblioteca void *calloc(int
Linguagem C: Ponteiros - Alocação Dinâmica
 Prof. Paulo R. S. L. Coelho paulo@facom.ufu.br Faculdade de Computação Universidade Federal de Uberlândia GEQ007 Organização 1 Ponteiros Alocação Dinâmica de Memória 2 3 4 Organização Ponteiros Alocação
Prof. Paulo R. S. L. Coelho paulo@facom.ufu.br Faculdade de Computação Universidade Federal de Uberlândia GEQ007 Organização 1 Ponteiros Alocação Dinâmica de Memória 2 3 4 Organização Ponteiros Alocação
Uma introdução para computação paralela de modelos massivos. Adriano Brito Pereira inf.puc-rio.br
 Uma introdução para computação paralela de modelos massivos Adriano Brito Pereira 1021752 apereira @ inf.puc-rio.br Departamento de Informática Novembro / 2010 1 Resultados obtivos com Manta Framework
Uma introdução para computação paralela de modelos massivos Adriano Brito Pereira 1021752 apereira @ inf.puc-rio.br Departamento de Informática Novembro / 2010 1 Resultados obtivos com Manta Framework
Aula 16: Memória Principal e Memória Virtual
 Aula 16: Memória Principal e Memória Virtual Memória Principal Performance na memória principal: Latência: Miss Penalty na Cache Access Time: tempo entre requisição e retorno de palavra Cycle Time:
Aula 16: Memória Principal e Memória Virtual Memória Principal Performance na memória principal: Latência: Miss Penalty na Cache Access Time: tempo entre requisição e retorno de palavra Cycle Time:
Análise de desempenho da paralelização do cálculo da matriz de correlação com tamanho arbitrário, utilizando GPU
 Análise de desempenho da paralelização do cálculo da matriz de correlação com tamanho arbitrário, utilizando GPU Íris A. Santos 1, Chaina S. Oliveira 1, Carlos A. Estombelo-Montesco 1 1 Departamento de
Análise de desempenho da paralelização do cálculo da matriz de correlação com tamanho arbitrário, utilizando GPU Íris A. Santos 1, Chaina S. Oliveira 1, Carlos A. Estombelo-Montesco 1 1 Departamento de
Estudo de Técnicas de Otimização de Desempenho para GPUs Utilizando CUDA Aplicado a um Modelo Meteorológico
 Fabiano Cassol de Vargas Estudo de Técnicas de Otimização de Desempenho para GPUs Utilizando CUDA Aplicado a um Modelo Meteorológico Alegrete RS 08/2014 Fabiano Cassol de Vargas Estudo de Técnicas de
Fabiano Cassol de Vargas Estudo de Técnicas de Otimização de Desempenho para GPUs Utilizando CUDA Aplicado a um Modelo Meteorológico Alegrete RS 08/2014 Fabiano Cassol de Vargas Estudo de Técnicas de
Processamento de Sinal através do GPU
 Processamento de Sinal através do GPU Relatório Final do Projecto Informático n.º 15/ 2007-8, ei15888 Relatório final submetido para avaliação parcial da unidade curricular de Projecto Informático, do
Processamento de Sinal através do GPU Relatório Final do Projecto Informático n.º 15/ 2007-8, ei15888 Relatório final submetido para avaliação parcial da unidade curricular de Projecto Informático, do
Aula 16: Memória Principal e Memória Virtual
 Aula 16: Memória Principal e Memória Virtual Memória Principal Performance na memória principal: Latência: Miss Penalty na Cache Access Time: tempo entre requisição e retorno de palavra Cycle Time: tempo
Aula 16: Memória Principal e Memória Virtual Memória Principal Performance na memória principal: Latência: Miss Penalty na Cache Access Time: tempo entre requisição e retorno de palavra Cycle Time: tempo
Aula 12. Gerência de Memória - Paginação
 Aula 12 Gerência de Memória - Paginação 11 Gerência de memória- o contexto da paginação 12 O que é a paginação 13 Implementação 14 Referências: Capítulo 9 (94) O contexto da paginação Revisão de gerência
Aula 12 Gerência de Memória - Paginação 11 Gerência de memória- o contexto da paginação 12 O que é a paginação 13 Implementação 14 Referências: Capítulo 9 (94) O contexto da paginação Revisão de gerência
Memória Cache. Aula 24
 Memória Cache Aula 24 Introdução Objetivo: oferecer o máximo de memória disponível na tecnologia mais barata, enquanto se fornece acesso na velocidade oferecida pela memória mais rápida Velocidade CPU
Memória Cache Aula 24 Introdução Objetivo: oferecer o máximo de memória disponível na tecnologia mais barata, enquanto se fornece acesso na velocidade oferecida pela memória mais rápida Velocidade CPU
Gerenciamento de Memória. Memória Principal
 Gerenciamento de Memória Memória Principal Principais tópicos: Aspectos Básicos Alocação de Memória Paginação Segmentação Com a possibilidade de executar mais do que um processo simultaneamente, surgiu
Gerenciamento de Memória Memória Principal Principais tópicos: Aspectos Básicos Alocação de Memória Paginação Segmentação Com a possibilidade de executar mais do que um processo simultaneamente, surgiu
Edison Gustavo Muenz. Estudo e implementação de um algoritmo de processamento de imagens com técnicas GPGPU
 Edison Gustavo Muenz Estudo e implementação de um algoritmo de processamento de imagens com técnicas GPGPU Florianópolis SC Agosto / 2008 Edison Gustavo Muenz Estudo e implementação de um algoritmo de
Edison Gustavo Muenz Estudo e implementação de um algoritmo de processamento de imagens com técnicas GPGPU Florianópolis SC Agosto / 2008 Edison Gustavo Muenz Estudo e implementação de um algoritmo de
Alocação dinâmica de Memória
 Alocação dinâmica de Memória Vetores e Arrays A variável vetor é uma variável que armazena outras variáveis, no caso tem que ser do mesmo tipo. Exemplo Criar um cont Declarar um vet com o tamanho Laço
Alocação dinâmica de Memória Vetores e Arrays A variável vetor é uma variável que armazena outras variáveis, no caso tem que ser do mesmo tipo. Exemplo Criar um cont Declarar um vet com o tamanho Laço
Introdução à Computação Heterogênea
 Capítulo 7 Introdução à Computação Heterogênea Denise Stringhini, Rogério A. Gonçalves, Alfredo Goldman Resumo Diversos tipos de coprocessadores tem sido utilizados a fim de acelerar a execução de aplicações
Capítulo 7 Introdução à Computação Heterogênea Denise Stringhini, Rogério A. Gonçalves, Alfredo Goldman Resumo Diversos tipos de coprocessadores tem sido utilizados a fim de acelerar a execução de aplicações
SSC0112 Organização de Computadores Digitais I
 SSC0112 Organização de Computadores Digitais I 23ª Aula Hierarquia de memória Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br 1 Memória Memória Todo componente capaz de armazenar bits de informação Características
SSC0112 Organização de Computadores Digitais I 23ª Aula Hierarquia de memória Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br 1 Memória Memória Todo componente capaz de armazenar bits de informação Características
Programação em Paralelo. N. Cardoso & P. Bicudo. Física Computacional - MEFT 2012/2013
 Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 19 CUDA "Compute Unified Device Architecture" Parte 1
Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 19 CUDA "Compute Unified Device Architecture" Parte 1
Funções Vetores Matrizes
 Funções Vetores Matrizes Além dos tipos elementares (float, double, char, etc.), é possível também passar um vetor ou uma matriz como parâmetro de funções. Quando um vetor é passado como parâmetro, o que
Funções Vetores Matrizes Além dos tipos elementares (float, double, char, etc.), é possível também passar um vetor ou uma matriz como parâmetro de funções. Quando um vetor é passado como parâmetro, o que
Computação científica utilizando placas gráficas
 Brasília, dezembro de 2008 Universidade de Brasília - Faculdade do Gama Sumário Introdução Sumário Introdução Arquitetura da GPU Sumário Introdução Arquitetura da GPU Modelo de programação Sumário Introdução
Brasília, dezembro de 2008 Universidade de Brasília - Faculdade do Gama Sumário Introdução Sumário Introdução Arquitetura da GPU Sumário Introdução Arquitetura da GPU Modelo de programação Sumário Introdução
Gerência de Dispositivos. Adão de Melo Neto
 Gerência de Dispositivos Adão de Melo Neto 1 Gerência de Dispositivos Introdução Acesso ao Subsistema de E/S Subsistema de E/S Device Drivers Controladores Dispositivos de E/S Discos Magnéticos Desempenho,
Gerência de Dispositivos Adão de Melo Neto 1 Gerência de Dispositivos Introdução Acesso ao Subsistema de E/S Subsistema de E/S Device Drivers Controladores Dispositivos de E/S Discos Magnéticos Desempenho,
Impacto da Arquitetura de Memória de GPGPUs na Velocidade da Computação de Estênceis
 Impacto da Arquitetura de Memória de GPGPUs na Velocidade da Computação de Estênceis Thiago C. Nasciutti 1, Jairo Panetta 1 1 Divisão de Ciência da Computação Instituto Tecnológico de Aeronáutica (ITA)
Impacto da Arquitetura de Memória de GPGPUs na Velocidade da Computação de Estênceis Thiago C. Nasciutti 1, Jairo Panetta 1 1 Divisão de Ciência da Computação Instituto Tecnológico de Aeronáutica (ITA)
Soluções em GPU para o Problema do Alinhamento Spliced
 Soluções em GPU para o Problema do Alinhamento Spliced Anisio Vitorino Nolasco Dissertação de Mestrado apresentada à Faculdade de Computação da Universidade Federal de Mato Grosso do Sul Orientadora: Profa.
Soluções em GPU para o Problema do Alinhamento Spliced Anisio Vitorino Nolasco Dissertação de Mestrado apresentada à Faculdade de Computação da Universidade Federal de Mato Grosso do Sul Orientadora: Profa.
MINI-CURSO: Introdução à Programação em CUDA
 I Escola Regional de Alto Desempenho de SP ERAD-2010 MINI-CURSO: Introdução à Programação em CUDA Prof. Raphael Y. de Camargo Centro de Matemática, Computação e Cognição Universidade Federal do ABC (UFABC)
I Escola Regional de Alto Desempenho de SP ERAD-2010 MINI-CURSO: Introdução à Programação em CUDA Prof. Raphael Y. de Camargo Centro de Matemática, Computação e Cognição Universidade Federal do ABC (UFABC)
Universidade Federal de Uberlândia Faculdade de Computação. Linguagem C: ponteiros e alocação dinâmica
 Universidade Federal de Uberlândia Faculdade de Computação Linguagem C: ponteiros e alocação dinâmica Prof. Renato Pimentel 1 Ponteiros 2 Prof. Renato Pimentel 1 Ponteiros: introdução Toda a informação
Universidade Federal de Uberlândia Faculdade de Computação Linguagem C: ponteiros e alocação dinâmica Prof. Renato Pimentel 1 Ponteiros 2 Prof. Renato Pimentel 1 Ponteiros: introdução Toda a informação
GPU Computing: Implementação do método do Gradiente Conjugado utilizando CUDA
 UNIVERSIDADE DE CAXIAS DO SUL CENTRO DE COMPUTAÇÃO E TECNOLOGIA DA INFORMAÇÃO CURSO DE BACHARELADO EM CIÊNCIA DA COMPUTAÇÃO MAURÍCIO GRISA GPU Computing: Implementação do método do Gradiente Conjugado
UNIVERSIDADE DE CAXIAS DO SUL CENTRO DE COMPUTAÇÃO E TECNOLOGIA DA INFORMAÇÃO CURSO DE BACHARELADO EM CIÊNCIA DA COMPUTAÇÃO MAURÍCIO GRISA GPU Computing: Implementação do método do Gradiente Conjugado
Métodos Computacionais. Funções, Escopo de Variáveis e Ponteiros
 Métodos Computacionais Funções, Escopo de Variáveis e Ponteiros Tópicos da Aula Hoje vamos detalhar funções em C Escrevendo funções Comando return Passagem de argumentos por valor Execução de uma função
Métodos Computacionais Funções, Escopo de Variáveis e Ponteiros Tópicos da Aula Hoje vamos detalhar funções em C Escrevendo funções Comando return Passagem de argumentos por valor Execução de uma função
A Utilização da Tecnologia CUDA para Processamento Paralelo de Algoritmos Genéticos
 A Utilização da Tecnologia CUDA para Processamento Paralelo de Algoritmos Genéticos Allan Ariel Leite Menezes Santos 1 1 Universidade do Estado da Bahia (UNEB) allan.ariel1987@gmail.com Abstract. The problem
A Utilização da Tecnologia CUDA para Processamento Paralelo de Algoritmos Genéticos Allan Ariel Leite Menezes Santos 1 1 Universidade do Estado da Bahia (UNEB) allan.ariel1987@gmail.com Abstract. The problem
Ambientes e Ferramentas de Programação para GPU. Denise Stringhini (Mackenzie) Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP)
 Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP)") Ambientes e Ferramentas de Programação para GPU Denise Stringhini (Mackenzie) Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP) Conteúdo Conceitos de paralelismo Arquitetura de GPU CUDA OpenCL
Ambientes e Ferramentas de Programação para GPU Denise Stringhini (Mackenzie) Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP) Conteúdo Conceitos de paralelismo Arquitetura de GPU CUDA OpenCL
Agenda. O que é OpenMP? Regiões Paralelas Construtores para Compartilhamento de
 Programando OpenMP Agenda O que é OpenMP? Regiões Paralelas Construtores para Compartilhamento de Trabalho Montando um escopo de dados para proteger de condições de corrida Cláusulas de agendamento O que
Programando OpenMP Agenda O que é OpenMP? Regiões Paralelas Construtores para Compartilhamento de Trabalho Montando um escopo de dados para proteger de condições de corrida Cláusulas de agendamento O que
DEPARTAMENTO DE CIÊNCIA DA COMPUTAÇÃO BACHARELADO EM INFORMÁTICA SISTEMAS OPERACIONAIS I 1 0 SEM/05 Teste 1 Unidade I DURAÇÃO: 50 MINUTOS
 DEPARTAMENTO DE CIÊNCIA DA COMPUTAÇÃO BACHARELADO EM INFORMÁTICA SISTEMAS OPERACIONAIS I 1 0 SEM/05 Teste 1 Unidade I DURAÇÃO: 50 MINUTOS Aluno: GABARITO Escore: 1 a Questão (30) Assinale a(s) resposta(s)
DEPARTAMENTO DE CIÊNCIA DA COMPUTAÇÃO BACHARELADO EM INFORMÁTICA SISTEMAS OPERACIONAIS I 1 0 SEM/05 Teste 1 Unidade I DURAÇÃO: 50 MINUTOS Aluno: GABARITO Escore: 1 a Questão (30) Assinale a(s) resposta(s)
INF1007: Programação 2. 2 Alocação Dinâmica. 17/02/2014 (c) Dept. Informática - PUC-Rio 1
 Dept. Informática - PUC-Rio 1") INF1007: Programação 2 2 Alocação Dinâmica 17/02/2014 (c) Dept. Informática - PUC-Rio 1 Tópicos Alocação dinâmica Vetores locais e funções 17/02/2014 (c) Dept. Informática - PUC-Rio 2 Alocação Dinâmica
INF1007: Programação 2 2 Alocação Dinâmica 17/02/2014 (c) Dept. Informática - PUC-Rio 1 Tópicos Alocação dinâmica Vetores locais e funções 17/02/2014 (c) Dept. Informática - PUC-Rio 2 Alocação Dinâmica
GPU (Graphics Processing Unit) Bruno Padilha Gregory De Bonis Luciana Kayo
 Bruno Padilha Gregory De Bonis Luciana Kayo") GPU (Graphics Processing Unit) Bruno Padilha - 5745282 Gregory De Bonis - 6431180 Luciana Kayo - 6430992 O que é? O que é? - Processador auxiliar responsável principalmente por operações de ponto flutuante
GPU (Graphics Processing Unit) Bruno Padilha - 5745282 Gregory De Bonis - 6431180 Luciana Kayo - 6430992 O que é? O que é? - Processador auxiliar responsável principalmente por operações de ponto flutuante
Tipos Básicos. Operadores de Incremento e Decremento. Operador Sizeof. Estruturas de Dados Aula 2: Estruturas Estáticas
 Tipos Básicos Quantos valores distintos podemos representar com o tipo char? Estruturas de Dados Aula 2: Estruturas Estáticas 03/03/2010 Operadores de Incremento e Decremento ++ e -- Incrementa ou decrementa
Tipos Básicos Quantos valores distintos podemos representar com o tipo char? Estruturas de Dados Aula 2: Estruturas Estáticas 03/03/2010 Operadores de Incremento e Decremento ++ e -- Incrementa ou decrementa
Linguagens de Programação Classificação
 Classificação Classificação A proximidade que a linguagem de programação tem com a humana determina sua classe (o nível): Linguagem de máquina (primeira geração) Linguagem assembly - de montagem (segunda
Classificação Classificação A proximidade que a linguagem de programação tem com a humana determina sua classe (o nível): Linguagem de máquina (primeira geração) Linguagem assembly - de montagem (segunda
1 Padrões de Implementação em Processamento de Imagens. 2 Resumo. 4 Computação paralela. 1.1 Relátório final para PIBIC/CNPq
 1 Padrões de Implementação em Processamento de Imagens 1.1 Relátório final para PIBIC/CNPq Victor M. de A. Oliveira, Rubens Campos Machado Centro de Tecnologia da Informação Renato Archer CTI Divisão de
1 Padrões de Implementação em Processamento de Imagens 1.1 Relátório final para PIBIC/CNPq Victor M. de A. Oliveira, Rubens Campos Machado Centro de Tecnologia da Informação Renato Archer CTI Divisão de
Estruturas de Dados Aula 2: Estruturas Estáticas 02/03/2011
 Estruturas de Dados Aula 2: Estruturas Estáticas 02/03/2011 Tipos Básicos Quantos valores distintos podemos representar com o tipo char? Operadores de Incremento e Decremento ++ e -- Incrementa ou decrementa
Estruturas de Dados Aula 2: Estruturas Estáticas 02/03/2011 Tipos Básicos Quantos valores distintos podemos representar com o tipo char? Operadores de Incremento e Decremento ++ e -- Incrementa ou decrementa
Introdução à linguagem C++
 Estrutura de Dados e Algoritmos e Programação e Computadores II Aula 2: Introdução à linguagem C++ Introdução à linguagem C++ Conceitos básicos: variáveis, tipos de dados, constantes, I/O, etc. Estruturas
Estrutura de Dados e Algoritmos e Programação e Computadores II Aula 2: Introdução à linguagem C++ Introdução à linguagem C++ Conceitos básicos: variáveis, tipos de dados, constantes, I/O, etc. Estruturas
O Problema do Fractal de Mandelbrot como Comparativo de Arquiteturas de Memória Compartilhada GPU vs OpenMP
 O Problema do Fractal de Mandelbrot como Comparativo de Arquiteturas de Memória Compartilhada GPU vs OpenMP Bruno P. dos Santos, Dany S. Dominguez, Esbel V. Orellana Departamento de Ciências Exatas e Tecnológicas
O Problema do Fractal de Mandelbrot como Comparativo de Arquiteturas de Memória Compartilhada GPU vs OpenMP Bruno P. dos Santos, Dany S. Dominguez, Esbel V. Orellana Departamento de Ciências Exatas e Tecnológicas
Conceitos básicos de programação
 Para aprender uma linguagem de programação podemos começar por conhecer os vocábulos ou símbolos que formam o seu léxico e depois aprender como esses vocábulos integram as instruções (frases) que compõe
Para aprender uma linguagem de programação podemos começar por conhecer os vocábulos ou símbolos que formam o seu léxico e depois aprender como esses vocábulos integram as instruções (frases) que compõe
Microprocessadores. Família x86 - Evolução
 Família x86 - Evolução António M. Gonçalves Pinheiro Departamento de Física Covilhã - Portugal pinheiro@ubi.pt i8086 16 bits de dados 20 bits de endereços 1MByte Clock 2 [4,8] MHz i80286 24 bits de endereço
Família x86 - Evolução António M. Gonçalves Pinheiro Departamento de Física Covilhã - Portugal pinheiro@ubi.pt i8086 16 bits de dados 20 bits de endereços 1MByte Clock 2 [4,8] MHz i80286 24 bits de endereço
Computação de alto desempenho utilizando CUDA
 Computação de alto desempenho utilizando CUDA Bruno Cardoso Lopes, Rodolfo Jardim de Azevedo 1 Instituto de Computação Universidade Estadual de Campinas (Unicamp) Caixa Postal 6176 13083-970 Campinas SP
Computação de alto desempenho utilizando CUDA Bruno Cardoso Lopes, Rodolfo Jardim de Azevedo 1 Instituto de Computação Universidade Estadual de Campinas (Unicamp) Caixa Postal 6176 13083-970 Campinas SP
Aula 15 Variáveis Indexadas (vetores)
") Aula 15 Variáveis Indexadas (vetores) Além das variáveis normais já conhecidas, podemos ter também variáveis indexadas. Tais variáveis são referenciadas por um nome e um índice. Especialmente úteis para
Aula 15 Variáveis Indexadas (vetores) Além das variáveis normais já conhecidas, podemos ter também variáveis indexadas. Tais variáveis são referenciadas por um nome e um índice. Especialmente úteis para
ESTRATÉGIAS DE ALOCAÇÃO AULA 11 Sistemas Operacionais Gil Eduardo de Andrade
 ESTRATÉGIAS DE ALOCAÇÃO AULA 11 Sistemas Operacionais Gil Eduardo de Andrade O conteúdo deste documento é baseado no livro do Prof. Dr. Carlos Alberto Maziero, disponível no link: http://dainf.ct.utfpr.edu.br/~maziero
ESTRATÉGIAS DE ALOCAÇÃO AULA 11 Sistemas Operacionais Gil Eduardo de Andrade O conteúdo deste documento é baseado no livro do Prof. Dr. Carlos Alberto Maziero, disponível no link: http://dainf.ct.utfpr.edu.br/~maziero
SSC510 Arquitetura de Computadores. 6ª aula
 SSC510 Arquitetura de Computadores 6ª aula PARALELISMO EM NÍVEL DE PROCESSOS PROFA. SARITA MAZZINI BRUSCHI Tipos de Paralelismo Instrução (granulosidade fina) Paralelismo entre as instruções Arquiteturas
SSC510 Arquitetura de Computadores 6ª aula PARALELISMO EM NÍVEL DE PROCESSOS PROFA. SARITA MAZZINI BRUSCHI Tipos de Paralelismo Instrução (granulosidade fina) Paralelismo entre as instruções Arquiteturas
Linguagem C Variáveis Indexadas ( vetores e Matrizes) Lógica de Programação
 Lógica de Programação") Linguagem C Variáveis Indexadas ( vetores e Matrizes) Lógica de Programação Caro(a) aluno(a), Começaremos agora a montar vetores e matrizes na linguagem de programação. Bom trabalho!!! Variáveis Indexadas
Linguagem C Variáveis Indexadas ( vetores e Matrizes) Lógica de Programação Caro(a) aluno(a), Começaremos agora a montar vetores e matrizes na linguagem de programação. Bom trabalho!!! Variáveis Indexadas
INF 1007 Programação II
 INF 1007 Programação II Aula 04 Alocação Dinâmica Edirlei Soares de Lima Vetores - Declaração e Inicialização Declaração de um vetor: int meu_vetor[10]; Reserva um espaço de memória
INF 1007 Programação II Aula 04 Alocação Dinâmica Edirlei Soares de Lima Vetores - Declaração e Inicialização Declaração de um vetor: int meu_vetor[10]; Reserva um espaço de memória
Sistemas Operacionais. Universidade Federal de Minas Gerais. Aula 2. Gerência de Processos
 Aula 2 Gerência de Processos Gerência de Processos O que são Processos e Threads? Porque são necessários? Como são implementados? Como são controlados? Escalonamento Referências: Capítulo 4: 4.1 a 4.5
Aula 2 Gerência de Processos Gerência de Processos O que são Processos e Threads? Porque são necessários? Como são implementados? Como são controlados? Escalonamento Referências: Capítulo 4: 4.1 a 4.5
What is? Eduardo Viola Nicola Disciplina de IPPD
 What is? Eduardo Viola Nicola evnicola@inf.ufpel.edu.br Disciplina de IPPD Sumário 1)Introdução 2)Princípio Geral de Funcionamento 3)Exemplos de Aplicações 4)Modelo de Programação 5)Linguagens Suportadas
What is? Eduardo Viola Nicola evnicola@inf.ufpel.edu.br Disciplina de IPPD Sumário 1)Introdução 2)Princípio Geral de Funcionamento 3)Exemplos de Aplicações 4)Modelo de Programação 5)Linguagens Suportadas
Gerenciamento de memória
 Gerenciamento de memória Adriano J. Holanda 19/11/2015 Revisão: processos Visão geral Composto por código do programa em execução, arquivos abertos, sinais pendentes, dados internos do núcleo do SO, estado
Gerenciamento de memória Adriano J. Holanda 19/11/2015 Revisão: processos Visão geral Composto por código do programa em execução, arquivos abertos, sinais pendentes, dados internos do núcleo do SO, estado
SIMULAÇÃO CLIMÁTICA DE DADOS DE VENTO EM REDES P2P UTILIZANDO GPU
 UNIVERSIDADE ESTADUAL DE PONTA GROSSA PRÓ-REITORIA DE PESQUISA E PÓS-GRADUAÇÃO PROGRAMA DE PÓS-GRADUAÇÃO EM COMPUTAÇÃO APLICADA CIRO BARON NETO SIMULAÇÃO CLIMÁTICA DE DADOS DE VENTO EM REDES P2P UTILIZANDO
UNIVERSIDADE ESTADUAL DE PONTA GROSSA PRÓ-REITORIA DE PESQUISA E PÓS-GRADUAÇÃO PROGRAMA DE PÓS-GRADUAÇÃO EM COMPUTAÇÃO APLICADA CIRO BARON NETO SIMULAÇÃO CLIMÁTICA DE DADOS DE VENTO EM REDES P2P UTILIZANDO
Introdução aos Sistemas Operacionais. Subsistema de Entrada e Saída
 Introdução aos Sistemas Operacionais Subsistema de Entrada e Saída Eleri Cardozo FEEC/Unicamp Entrada e Saída O subsistema de entrada e saída é responsável pela interface entre o sistema operacional e
Introdução aos Sistemas Operacionais Subsistema de Entrada e Saída Eleri Cardozo FEEC/Unicamp Entrada e Saída O subsistema de entrada e saída é responsável pela interface entre o sistema operacional e
Sistemas Distribuídos
 Sistemas Distribuídos Classificação de Flynn Fonte: Professoras. Sarita UFRJ e Thais V. Batista - UFRN Arquiteturas Paralelas Computação Paralela Conceitos Permite a execução das tarefas em menor tempo,
Sistemas Distribuídos Classificação de Flynn Fonte: Professoras. Sarita UFRJ e Thais V. Batista - UFRN Arquiteturas Paralelas Computação Paralela Conceitos Permite a execução das tarefas em menor tempo,
Medida do Tempo de Execução de um Programa. Bruno Hott Algoritmos e Estruturas de Dados I DECSI UFOP
 Medida do Tempo de Execução de um Programa Bruno Hott Algoritmos e Estruturas de Dados I DECSI UFOP Medida do Tempo de Execução de um Programa O projeto de algoritmos é fortemente influenciado pelo estudo
Medida do Tempo de Execução de um Programa Bruno Hott Algoritmos e Estruturas de Dados I DECSI UFOP Medida do Tempo de Execução de um Programa O projeto de algoritmos é fortemente influenciado pelo estudo
Métodos Computacionais
 Métodos Computacionais Objetivos da Disciplina e Introdução a Linguagem C Construções Básicas Objetivos da Disciplina Objetivo Geral Discutir técnicas de programação e estruturação de dados para o desenvolvimento
Métodos Computacionais Objetivos da Disciplina e Introdução a Linguagem C Construções Básicas Objetivos da Disciplina Objetivo Geral Discutir técnicas de programação e estruturação de dados para o desenvolvimento
ponteiros INF Programação I Prof. Roberto Azevedo
 ponteiros INF1005 -- Programação I -- 2016.1 Prof. Roberto Azevedo razevedo@inf.puc-rio.br ponteiros tópicos o que são ponteiros operadores usados com ponteiros passagem de ponteiros para funções referência
ponteiros INF1005 -- Programação I -- 2016.1 Prof. Roberto Azevedo razevedo@inf.puc-rio.br ponteiros tópicos o que são ponteiros operadores usados com ponteiros passagem de ponteiros para funções referência
Linguagem C Princípios Básicos (parte 1)
") Linguagem C Princípios Básicos (parte 1) Objetivos O principal objetivo deste artigo é explicar alguns conceitos fundamentais de programação em C. No final será implementado um programa envolvendo todos
Linguagem C Princípios Básicos (parte 1) Objetivos O principal objetivo deste artigo é explicar alguns conceitos fundamentais de programação em C. No final será implementado um programa envolvendo todos
Paralela e Distribuída. com o MPI e o OpenMP
 Programação Paralela e Distribuída Programação Híbrida com o e o OpenMP e OpenMP Uma forma de executar um programa em paralelo num cluster multiprocessor é criar um processo por cada processador. Nesse
Programação Paralela e Distribuída Programação Híbrida com o e o OpenMP e OpenMP Uma forma de executar um programa em paralelo num cluster multiprocessor é criar um processo por cada processador. Nesse
Organização de Computadores
 Organização de Computadores Aula 29 Controle Microprogramado Rodrigo Hausen 24 de novembro de 2011 http://cuco.pro.br/ach2034 1/32 Apresentação 1. Bases Teóricas 2. Organização de computadores... 2.6.
Organização de Computadores Aula 29 Controle Microprogramado Rodrigo Hausen 24 de novembro de 2011 http://cuco.pro.br/ach2034 1/32 Apresentação 1. Bases Teóricas 2. Organização de computadores... 2.6.
Barramento CoreConnect
 Barramento CoreConnect MO801 1º semestre de 2006 Prof. Rodolfo Jardim de Azevedo Fabiana Bellette Gil - RA 028671 CoreConnect Agenda Conceitos básicos Introdução ao CoreConnect Arquitetura Referências
Barramento CoreConnect MO801 1º semestre de 2006 Prof. Rodolfo Jardim de Azevedo Fabiana Bellette Gil - RA 028671 CoreConnect Agenda Conceitos básicos Introdução ao CoreConnect Arquitetura Referências
Memória Cache: Funcionamento
 Microcontroladores e Interfaces º Ano Eng. Electrónica Industrial Carlos A. Silva º Semestre de 5/6 http://www.dei.uminho.pt/lic/mint Assunto: Memória Cache Aula #9 9Maio6-M Memória Cache: Funcionamento
Microcontroladores e Interfaces º Ano Eng. Electrónica Industrial Carlos A. Silva º Semestre de 5/6 http://www.dei.uminho.pt/lic/mint Assunto: Memória Cache Aula #9 9Maio6-M Memória Cache: Funcionamento
Fundamentos de Programação
 Fundamentos de Programação CP41F Aula 2 Prof. Daniel Cavalcanti Jeronymo Conceito de algoritmo. Raciocínio lógico na construção de algoritmos. Estrutura de algoritmos. Universidade Tecnológica Federal
Fundamentos de Programação CP41F Aula 2 Prof. Daniel Cavalcanti Jeronymo Conceito de algoritmo. Raciocínio lógico na construção de algoritmos. Estrutura de algoritmos. Universidade Tecnológica Federal
CUDA. José Ricardo da Silva Jr.
 CUDA José Ricardo da Silva Jr. Medialab Ins1tuto de Computação Universidade Federal Fluminense CUDA Research Center & CUDA Teaching Center Centro de excelência da NVIDIA desde julho 2012 Perfil Bacharel
CUDA José Ricardo da Silva Jr. Medialab Ins1tuto de Computação Universidade Federal Fluminense CUDA Research Center & CUDA Teaching Center Centro de excelência da NVIDIA desde julho 2012 Perfil Bacharel
Métodos Computacionais. Vetores e Matrizes Dinâmicas
 Métodos Computacionais Vetores e Matrizes Dinâmicas Vetores Um programa para o cálculo da média Média m n i= = 1 n x i Variância v n i= = 1 ( x i n m) 2 A forma mais simples de estruturar um conjunto de
Métodos Computacionais Vetores e Matrizes Dinâmicas Vetores Um programa para o cálculo da média Média m n i= = 1 n x i Variância v n i= = 1 ( x i n m) 2 A forma mais simples de estruturar um conjunto de
Sistemas Operacionais Aula 3
 Sistemas Operacionais Aula 3 Anderson L. S. Moreira anderson.moreira@recife.ifpe.edu.br http://dase.ifpe.edu.br/~alsm Curso de Análise e Desenvolvimento de Sistemas de Informação Recife - PE O que fazer
Sistemas Operacionais Aula 3 Anderson L. S. Moreira anderson.moreira@recife.ifpe.edu.br http://dase.ifpe.edu.br/~alsm Curso de Análise e Desenvolvimento de Sistemas de Informação Recife - PE O que fazer
Estruturas de Dados. Introdução Definição de Ponteiros Declaração de Ponteiros em C Manipulação de Ponteiros em C
 Estruturas de Dados Revisão de Ponteiros Prof. Ricardo J. G. B. Campello Sumário Introdução Definição de Ponteiros Declaração de Ponteiros em C Manipulação de Ponteiros em C Operações Ponteiros e Arranjos
Estruturas de Dados Revisão de Ponteiros Prof. Ricardo J. G. B. Campello Sumário Introdução Definição de Ponteiros Declaração de Ponteiros em C Manipulação de Ponteiros em C Operações Ponteiros e Arranjos
Universidade Federal do Pampa Matheus da Silva Serpa. Análise de Desempenho de Aplicações Paralelas em Arquiteturas multi-core e many-core
 Universidade Federal do Pampa Matheus da Silva Serpa Análise de Desempenho de Aplicações Paralelas em Arquiteturas multi-core e many-core Alegrete 2015 Matheus da Silva Serpa Análise de Desempenho de
Universidade Federal do Pampa Matheus da Silva Serpa Análise de Desempenho de Aplicações Paralelas em Arquiteturas multi-core e many-core Alegrete 2015 Matheus da Silva Serpa Análise de Desempenho de
Ponteiros e Tabelas. K&R: Capitulo 5 IAED, 2012/2013
 Ponteiros e Tabelas K&R: Capitulo 5 Ponteiros e Tabelas Ponteiros e endereços Ponteiros e argumentos de funções Ponteiros e tabelas Alocação dinâmica de memória Aritmética de ponteiros Tabelas de ponteiros
Ponteiros e Tabelas K&R: Capitulo 5 Ponteiros e Tabelas Ponteiros e endereços Ponteiros e argumentos de funções Ponteiros e tabelas Alocação dinâmica de memória Aritmética de ponteiros Tabelas de ponteiros
Algoritmos de Enumeração
 Em muitos casos para fazer a simulação de um algoritmo é necessário testar-se com um conjunto exaustivo de dados, ou seja, gerar várias ou todas as sequências possíveis de dados e verificar o comportamento
Em muitos casos para fazer a simulação de um algoritmo é necessário testar-se com um conjunto exaustivo de dados, ou seja, gerar várias ou todas as sequências possíveis de dados e verificar o comportamento
Arquitetura Von Neumann Dados e instruções são obtidos da mesma forma, simplificando o desenho do microprocessador;
 1 Microprocessador Um microprocessador é um circuito eletrônico capaz de realizar diversas tarefas conforme os comandos específicos. Para isso ele deve ler esses comandos da memória de programa (ROM) e
1 Microprocessador Um microprocessador é um circuito eletrônico capaz de realizar diversas tarefas conforme os comandos específicos. Para isso ele deve ler esses comandos da memória de programa (ROM) e
ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 02: PROCESSAMENTO PARALELO: PROCESSADORES VETORIAIS
 ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 02: PROCESSAMENTO PARALELO: PROCESSADORES VETORIAIS Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação
ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 02: PROCESSAMENTO PARALELO: PROCESSADORES VETORIAIS Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação
Disciplina: Sistemas Operacionais
 Curso: Análise e Desenvolvimento de Sistemas Disciplina: Sistemas Operacionais Parte 2: Sistemas Multiprocessos, Características dos Multiprocessadores,Sistemas de Clusters, Operações básica do Sistema
Curso: Análise e Desenvolvimento de Sistemas Disciplina: Sistemas Operacionais Parte 2: Sistemas Multiprocessos, Características dos Multiprocessadores,Sistemas de Clusters, Operações básica do Sistema