MINI-CURSO: Introdução à Programação em CUDA
|
|
|
- João Lucas Madeira Furtado
- 10 Há anos
- Visualizações:
Transcrição
1 I Escola Regional de Alto Desempenho de SP ERAD-2010 MINI-CURSO: Introdução à Programação em CUDA Prof. Raphael Y. de Camargo Centro de Matemática, Computação e Cognição Universidade Federal do ABC (UFABC) [email protected]
2 Parte I Introdução às GPUs
3 Placas Gráficas Jogos 3D evoluíram muito nos últimos anos e passaram a exigir um poder computacional gigantesco
4 Jogos modernos: Além de gerar o cenário 3D, é preciso aplicar texturas, iluminação, sombras, reflexões, etc. As folhas individuais das plantas são desenhadas Sombras são calculadas dinamicamente Para tal, as placas gráficas passaram a ser cada vez mais flexíveis e poderosas GPUs
5 NVIDIA GTX480: 480 núcleos preço US$ 500 Desempenho máximo: 0.5 TFLOP (double) e 1.3 TFLOP (float) Intel Core i7 980X: 6 núcleos preço US$ 1000 Desempenho máximo: 0.1 TFLOP (double)
6 NVIDIA GTX480: 480 núcleos preço US$ GB de Memória com acesso a 177 GB/s Intel Core i7 980X: 6 núcleos preço US$ 1000 Acesso à memória a 25.6 GB/s

7 Arquitetura da GPU GPUs utilizam um maior número de transistores para colocar mais ALUs (Arithmetic Logic Unit) simplificadas Permite fazer um maior número de cálculos ao mesmo tempo Controle de fluxo mais simples: - Feita para aplicações paralelas onde as mesmas operações são aplicadas sobre um grande conjunto de dados

8 Arquitetura da GPU Fermi 16 Multiprocessadores: 32 processadores 16 unidades Load/Store 4 unidades funções especiais 64 kb Memória compartilhada registradores Cache de constantes e textura
9 Arquitetura da GPU Os multiprocessadores compartilham uma memória global, onde são armazenados texturas ou dados de aplicações Host Memory CPU
10 TESLA S x 448 processadores
11 O que é CUDA É uma arquitetura paralela de propósito geral destinada a utilizar o poder computacional de GPUs nvidia Extensão da linguagem C, e permite controlar a execução de threads na GPU e gerenciar sua memória Arquitetura de uma GPU nvidia
12 Hierarquia de Memória Cada execução do kernel é composta por: Grade blocos threads Hierarquia de memória: - Registradores por thread - Memória compartilhada por bloco - Memória Global acessível a todas as threads
13 Execução de Aplicações Cada bloco é alocado a um multiprocessador da GPU, que pode executar 1 ou mais blocos simultaneamente Cada multiprocessador executa 16 threads no modelo SIMT: Single Intruction, Multiple Thread
14 Modelo de Execução Execução do programa controlada pela CPU que pode lançar kernels, que são trechos de código executados em paralelo por múltiplas threads na GPU A execução de programas CUDA é composta por ciclos CPU, GPU, CPU, GPU,, CPU, GPU, CPU.
15 Aplicações que rodam bem em GPUs Programas que conseguem bons speedups em GPUs: Podem ser subdivido em pequenos subproblemas, que são alocados a diferentes blocos e threads Cada thread mantém uma pequena quantidade de estado Alta razão (operações de ponto flutuante) / (memória) Os subproblemas são fracamente acoplados Acoplamento: quando um problema pode ser dividido em subproblemas menores, o acoplamento indica o quanto os subproblemas são dependentes entre si.
16 Retirado de
17 Retirado de
18 Retirado de
19 Retirado de
20 Retirado de
21 GPUs vs Supercomputadores Sistemas de multiprocessadores: Conjunto de unidades de processamento e memória conectados por uma rede de interconexão Sistemas classificados como: Memória compartilhada Troca de mensagens Exemplos: Supercomputadores Aglomerados (clusters)
22 Exemplos de Redes Estáticas Alta tolerância a falhas Ponto único de falha e gargalo No de conexões: O(N²) No de conexões: O(N)
23 Exemplos de Redes Estáticas k-cubo: nós: O (2k), Conexões: O (2k*k/2) Malha com k dimensões No de conexões: O(N*k/2) Hypercubo 10-dim Mais fácil de construir 1024 nós e 5120 conexões
24 Exemplos de Redes Estáticas Árvore Árvore Gorda Conexões: O(N) Atraso: O(log N) Nós mais altos com maior largura de banda Nó raiz é gargalo e ponto único de falha Normalmente implementadas com múltiplas conexões
25 Rede Dinâmica: Barramento Simples Todas os processadores ligados à memória por um barramento simples Fácil e barato de implementar Mas o barramento rapidamente se torna um gargalo
26 Múltiplos Barramentos
27 Exemplo: SGI Altix 4700 Fabricante: Silicon Graphics, Inc Memória: 272 GB Processadores: 68 Dual-Core Itanium 9000 (64 bits) Sistemas Operacionais: Linux (SUSE) e Enterprise Server 10 Capacidade de Disco: 30TB (InfiniteStorage 350 e 120) Custo: R$ 2 milhões Fonte:
28 Detalhes do Altix 4700 Projeto modular Placas blade com 2 sockets e 8 DIMM Memória de até 128TB e até centenas de processadores Software C/C++ e Fortran, Depuradores, ferramentas de análise MPI, OpenMP, Ferramentas de threading Rede de Interconexão SGI NUMAlink 4 Topologia árvore gorda (fat tree) 6.4GB/sec bidirectional bandwidth per link Fonte:
29 Fonte:


30 Supercomputador Moderno Jaguar: Oak Ridge National Laboratory
31 Supercomputador Moderno Extraído de
32 Aplicações para Supercomputadores Qualquer tipo de aplicação Quanto menor o acoplamento, maior o desempenho Mas normalmente são aplicações com alto grau acoplamento Justificam o alto preço da rede de interconexão Exemplos: - Previsão do tempo, evolução do clima - Mecânica dos Fluidos (projeto de carros e aviões) - Biologia Computacional: enovelamento de proteínas, redes de interação gênica, etc.


33 TESLA M processadores

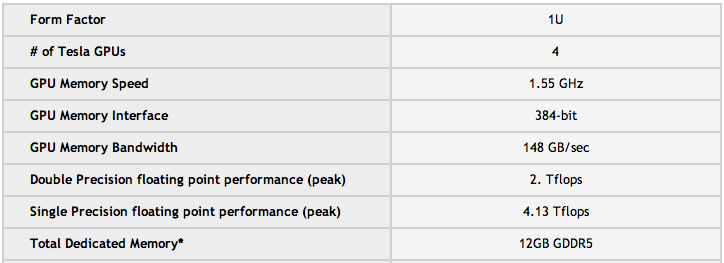
34 TESLA S x 448 processadores
35 Barramento de GPUs Barramento de memória compartilhado Todos os processadores acessam a memória global utilizando o mesmo barramento Mecanismos primitivos de sincronização entre threads Acesso à memória do computador: PCI-Express (8 GB/s)
36 Aplicações que rodam bem em GPUs Programas que conseguem bons speedups em GPUs: Podem ser subdivido em pequenos subproblemas, que são alocados a diferentes blocos e threads Cada thread mantém uma pequena quantidade de estado Alta razão (operações de ponto flutuante) / (memória) Os subproblemas são fracamente acoplados Exemplos: Algoritmos genéticos, codificação de vídeo, processamento de imagens médicas, etc.
37 Parte II Introdução à Programação em CUDA
38 O que é CUDA É uma arquitetura paralela de propósito geral destinada a utilizar o poder computacional de GPUs nvidia Extensão da linguagem C, que permite o uso de GPUs: - Suporte a uma hierarquia de grupos de threads - Definição de kernels que são executados na GPU - API com funções, que permitem o gerenciamento da memória da GPU e outros tipos de controle
39 Obtendo o CUDA CUDA pode ser obtido gratuitamente no site da nvidia: Disponível para Windows (XP, Vista e 7), Linux e MacOS X, em versões de 32 e 64 bits. É composto por: CUDA Driver: Permite o acesso ao hardware CUDA Toolkit: Ferramentas e bibliotecas para programação em CUDA CUDA SKD: Exemplos de código
40 Exemplo de Instalação do CUDA Para instalar o toolkit, basta rodar o instalador: > chmod +x cudatoolkit_2.3_linux_64_ubuntu9.04.run.sh >./cudatoolkit_2.3_linux_64_ubuntu9.04.run.sh Digite os comandos para configurar a instalação: > export PATH=$PATH:/home/raphael/cuda/bin > export LD_LIBRARY_PATH= $LD_LIBRARY_PATH:/home/raphael/cuda/lib64 Agora o Toolkit está instalado e configurado! Vamos para o primeiro exemplo.
41 Modelo de Execução Execução do programa controlada pela CPU que pode lançar kernels, que são trechos de código executados em paralelo por múltiplas threads na GPU A execução de programas CUDA é composta por ciclos CPU, GPU, CPU, GPU,, CPU, GPU, CPU.
42 Hierarquia de Memória Cada execução do kernel é composta por: Grade blocos threads Hierarquia de memória: - Registradores por thread - Memória compartilhada por bloco - Memória Global acessível a todas as threads
43 Exemplo Simples Neste primeiro exemplo iremos aprender como criar um kernel simples, que realiza a soma de 2 vetores. Veremos as principais operações usadas em CUDA: Alocação e liberação de memória, transferência de dados, lançamento do kernel O código abaixo contém erros e limitações que iremos resolver na aula. // Device code global void VecAdd(float* A, float* B, float* C, int n) { int i = threadidx.x; if (i < n) C[i] = A[i] + B[i]; }
44 // Host code int main() { int n = 5; size_t size = n * sizeof(float); float *d_a, *d_b, *d_c; cudamalloc((void**)&d_a, size); cudamalloc((void**)&d_b, size); cudamalloc((void**)&d_c, size); float h_a[] = {1,2,3,4,5}; float h_b[] = {10,20,30,40,50}; float h_c[] = {0,0,0,0,0}; cudamemcpy(d_a, h_a, size, cudamemcpyhosttodevice); cudamemcpy(d_b, h_b, size, cudamemcpyhosttodevice); int nthreadsperblock = 256; int nblocks = n / nthreadsperblock; VecAdd<<<nBlocks, nthreadsperblock>>>(d_a, d_b, d_c); } cudamemcpy(h_c, d_c, size, cudamemcpydevicetohost); cudafree(d_a); cudafree(d_b); cudafree(d_c);
45 Avaliação do Exemplo I Para compilar o código, basta utilizar o comando: nvcc -o ex1 ex1.cu Perguntas: 1) O programa funciona corretamente? Teste seu funcionamento imprimindo o resultado obtido 2) Corrija o programa 3) Aumente o tamanho dos vetores para, por exemplo, Teste o resultado e, se não for o esperado, corrija o programa. Obs: Você deve manter o número de threads por bloco em 256. Dica: O valor de blockidx.x devolve o bloco ao qual a thread pertence
46 Arquitetura da GPU Multiprocessadores, com M processadores em cada Registradores Memória compartilhada Cache de constantes e textura Memória Global Host Memory CPU

47 Execução de Aplicações Cada bloco é alocado a um multiprocessador da GPU, que pode executar 1 ou mais blocos simultaneamente Cada multiprocessador executa 16 threads no modelo SIMT: Single Intruction, Multiple Thread
48 CUDA Runtime vs Driver API Programas em CUDA normalmente utilizam o CUDA Runtime, que fornece primitivas e funções de alto-nível Além disso, é possível utilizar também a API do driver, que permite um melhor controle da aplicação
49 CUDA 3.1 (Junho de 2010) Suporte a múltiplos (16) kernels simultâneos Melhorias no CUDA: - Suporte a printf no código do dispositivo - Suporte a ponteiros com endereços de funções - Suporte a funções recursivas Interoperabilidade entre API do driver e CUDA Runtime Melhorias em bibliotecas matemáticas

50 Arquitetura FERMI Melhoria no desempenho de dupla precisão Suporte a memória ECC Suporte a múltiplos kernels simultâneos
51 Modo de Emulação Neste tutorial, executaremos os códigos em modo emulação. Existem 2 motivos principais para utilizar o modo emulação: - Quando não temos uma placa gráfica compatível :-) - Para realizar debugging (GDB e printf) Mas existem grandes desvantagens: - Desempenho muito inferior - Difícil avaliar qualidade da implementação - Pode mascarar bugs no código (especialmente memória) Hoje é possível realizar debugging diretamente na GPU, de modo que a emulação está sendo descontinuada.
 typedef struct { int width, height; float *elements; } Matrix; global void MatMulKernel(Matrix A, Matrix B, Matrix C) { // Each thread computes one element of C float Cvalue = 0; int")
52 Exemplo 2: Multiplicação de Matrizes // M(row, col) = *(M.elements + row * M.width + col) typedef struct { int width, height; float *elements; } Matrix; global void MatMulKernel(Matrix A, Matrix B, Matrix C) { // Each thread computes one element of C float Cvalue = 0; int row = blockidx.y * blockdim.y + threadidx.y; int col = blockidx.x * blockdim.x + threadidx.x; C.elements[ } ] = Cvalue;
53 Exercício 1) O kernel está correto? Inspecionando o código, procure por erros que impeçam seu funcionamento e o corrija 2) Escreva o código da CPU que chama o kernel. Dica: Use os seguintes comandos para lançar o kernel dim3 dimblock(block_size_x, BLOCK_SIZE_Y); dim3 dimgrid(grid_size_x, GRID_SIZE_Y); MatMulKernel<<<dimGrid, dimblock>>>(d_a, d_b, d_c); 3) Escreva um teste para seu exemplo

54 Uso da Memória Compartilhada A otimização que traz o maior desempenho é o uso da memória compartilhada de cada multiprocessador - O acesso à memória global demora centenas de ciclos Host Memory CPU

55 Otimizações de código Multiplicação de matrizes com memória compartilhada Pedaços da matriz são colocados na memória de cada multiprocessador

56

57
58 Otimizando o código Otimizar o código é a parte mais difícil e trabalhosa durante o desenvolvimento de um programa CUDA. Hoje este processo ainda é artesanal, com a necessidade de tentarmos diferentes estratégias. Alguns pontos importantes a considerar são: - Divergência do controle de fluxo - Ocupação dos processadores - Acesso combinado (coalesced) à memória global - Conflitos de bancos da memória compartilhada - Sobrecarga da chamada do Kernel
59 Divergência do Controle de Fluxo As thread de cada bloco são divididas em warps, contendo 16 ou 32 threads GPUs permitem a execução simultânea de todas as threads do warp, desde que todas executem o mesmo código Quando threads executam códigos diferentes, dizemos que houve uma divergência na execução do código. Exemplos: comandos if, else, while, for, etc. global void VecAdd(float* A, float* B, float* C, int n) { int i = threadidx.x; if (i < n) C[i] = A[i] + B[i]; }
60 Ocupação dos Multiprocessadores O segredo para obter um bom desempenho é manter os processadores da GPU sempre ocupados. Para tal: - Os blocos devem ter tamanhos múltiplos de 32 Assim, coincidem com o tamanho dos warps - Usar o menor número possível de registradores por thread O número de blocos por multiprocessador será maior Com mais blocos por multiprocessador, haverão mais opções de threads para execução Especialmente quando as threads estiverem esperando por dados da memória global
61 Ocupação dos Multiprocessadores
62 Acesso Combinado (Coalesced) Quando 16 threads de um warp acessam a memória ao mesmo tempo, CUDA combina os acessos em uma única requisição Para tal, todas os endereços devem estar localizados em um único intervalo de 128 bytes
63 Acesso Combinado (Coalesced) É melhor que os dados a serem lidos sejam adjacentes No caso de dados com separações de 2 ou mais posições, o desempenho cai consideravelmente Dados com separação de 2
64 Acesso Combinado (Coalesced) Qual é a melhor opção? Um array de estruturas? Ou uma estrutura de arrays? struct Dados { int chave; int valor; }; Dados *vetordados; struct Dados { int *chave; int *valor; }; Dados estruturadados;

65 Bancos de Memória Compartilhada A memória compartilhada é dividida em 16 bancos, com palavras de 32 bits, que podem ser acessados simultaneamente
66 Bancos de Memória Compartilhada Quando ocorrem conflitos, a GPU serializa as requisições
67 Reduza as Chamadas do Kernel As chamadas ao Kernel causam um overhead Além disso, muitas vezes precisamos passar dados para o kernel ou obter resultados da execução Uma maneira de melhorar o desempenho é agrupar um maior número de tarefas em uma chamada Exemplo: Se for preciso resolver diversos sistemas lineares, é melhor resolver todos em uma única chamada do kernel
68 Parte III FireStream, OpenCL e Bibliotecas para CUDA
69 NVIDIA Performance Primitives (NPP) Biblioteca de funções utilizáveis em aplicações para GPUs No momento possui primariamente funções para processamento de imagem e vídeo. Exemplos: - Filtros - Redimensionamento - Histogramas - Aplicação de limiares - Detecção de bordas, etc.
70 GPU Accelerated Linear Algebra Biblioteca de funções para álgebra linear. Exemplos: - Solução de sistemas lineares - Rotinas para autovalores - Triangularizações - Decomposição em valores singulares, etc. Interfaces com C/C++, Fortran, Matlab, Python: - Chamadas realizadas diretamente da aplicação para CPU - Não é preciso programar em CUDA
71 Desempenho Aplicação de Fatorização com precisão simples e dupla
72 AMD FireStream As placas da AMD (antiga ATI) também fornecem suporte a GPGPU, através das placas da Série FireStream FireStream GPU com 800 núcleos - 2GB RAM, 108 GB/s TFlop (single), 240 GFlop (double) 3o trimestre/ FireStream 9370 e GB RAM TFlop (single), 528 GFlop (double)
73 Cyprus Architecture 10 SIMD units with 16 stream cores with 5 ALUs on each = 1600 ALUs - Difícil de usar as 5 ALUs - Relógio das ALUs é igual ao do chip
74 AMD Fusion Irá combinar em um chip: - Núcleos x86 - Núcleos SIMD para processamento paralelo
75 APU (Accelerated Processing Unit) Diferentes tipos de configurações poderão ser criadas a partir de blocos básicos.
76 ATI Stream SDK O acesso ao poder computacional é feito através do uso da ATI Stream SDK. Compatível com as arquiteturas FireStream e Fusion Programação através da linguagem OpenCL 1.0 Anteriormente utilizava o Brooks+
77 OpenCL Diferentes hardwares utilizam diferentes plataformas: - CUDA para nvidia e Brooks+ para AMD/ATI - OpenMP para programação de múltiplos processadores
78 OpenCL O objetivo é permitir que um mesmo programa possa ser executado em múltiplas plataformas de hardware. - Padrão aberto, totalmente livre de royalties. - Suporte da Apple, nvidia, AMD, Intel e outras. - Falta a Microsoft, que tem sua solução própria :-) - DirectCompute, que faz parte do DirectX 10 e 11 - Alguém lembra da disputa DirectX vs OpenGL?
79 OpenCL Apesar das vantagens, existe um certo ceticismos sobre a adoção do OpenCL - Diferentes arquiteturas tem características específicas, que precisam ser levadas em conta na otimização - Programas genéricos acabariam sendo nivelados por baixo - Quando comparado com CUDA, a sintaxe de OpenCL é mais complicada, dado que ela precisa trabalhar com múltiplas plataformas
80 Parte IV Aplicação: Simulação de Redes Neuronais
81 Neurociência Computacional Hoje temos a visão macro e micro do cérebro, mas ainda não somos capazes de ligar adequadamente estas visões Objetivo da neurociência computacional: Entender como um conjunto de neurônios e sua conectividade geram funções cognitivas complexas. Para tal, criamos modelos matemáticos de áreas cerebrais e simulamos estes modelos em computadores Modelos podem ser compostos por até milhões de neurônios Simulação exige um grande poder computacional provindos de grandes aglomerados ou supercomputadores
82 Modelagem de Neurônios Neurônios são um tipo altamente especializado de célula Possuem corpo celular, dendritos e axônio Mantém um potencial de membrana Se comunicam com outros neurônios Fonte: Dayan and Abbott. Theoretical Neuroscience. MITPress
83 Modelagem de Neurônios Cada compartimento é modelado por um circuito elétrico Capacitor - membrana Resistências - membrana - canais iônicos - ligações entre compartimentos
84 Canais Iônicos Ativos Canais iônicos ativos: Canais dependentes da voltagem que permitem a geração de potencias de ação São constituídos por portões que possuem uma dinâmica de abertura e fechamento dependente da voltagem: Fonte: N. Carlson, Physiology of Behavior Pearson Ed.
85 Integração Numérica É preciso integrar uma equação diferencial por neurônio Integração implícita gera melhor estabilidade [ A ] x [ V(t+dt) ] = [ C ] Através de uma cuidadosa numeração dos compartimentos e uma triangularização, a solução do sistema pode ser eficiente
86 Simulação utilizando GPUs Programas que conseguem bons speedups em GPUs: Subdivido em pequenos subproblemas, que são alocados a diferentes blocos e threads Cada thread mantém uma pequena quantidade de estado Alta razão (operações de ponto flutuante) / (memória) Os subproblemas são fracamente acoplados
87 Característica de nosso problema Dezenas de variáveis de estado por thread Cada thread deve representar um neurônio Limite no número de neurônios por bloco (entre 64 e 128) Acoplamento entre neurônios durante a comunicação Padrão de conexões pode ser irregular Atraso no tempo de comunicação entre neurônios Neurônios são diferentes entre si Mas podem ser categorizados em diferentes classes
88 Implementação do Simulador A simulação é divididas em rodadas controladas pela CPU: Inicialização da simulação Enquanto (tempoatual < tempototal) Lança execução do kernel Coleta de resultados da simulação Envio de dados à GPU Fim da simulação
89 Implementação do Kernel Cada neurônio é implementado por uma thread distinta Esta thread executa a diagonalização da matriz e faz substituição dos valores finais Código para a execução de cada neurônio é igual, de modo que não há divergência de execução Versão para CPU portada para GPU: Usava dados diretamente da memória global. O desempenho era ruim, inferior ao da CPU
90 Otimizações Uso da memória compartilhada Memória compartilhada é pequena para armazenar dados de todos os neurônios de um bloco Armazenamos os dados que são utilizados múltiplas vezes por passo de integração (leitura e escrita) Leituras conjunta (coalesced) Organização dos dados de modo que leitura de dados de múltiplos neurônios seja feita de modo simultâneo
91 Comunicação entre Neurônios Neurônios geram spikes, que são entregues a outros neuônios Cada neurônio se conecta a centenas ou milhares de neurônios
92 Comunicação entre Neurônios Hoje a comunicação é coordenada pela CPU Gera um grande gargalo no desempenho Desafio: Comunicação utilizando GPU 1 GPU: Comunicação entre threads de diferentes blocos Tem que ser feita pela memória global Uso de primitivas como AtomicAdd() 2 ou mais GPUs em 1 computador: É preciso passar necessariamente pela CPU 2 ou mais GPUs em múltiplos computadores: É preciso passar necessariamente pela rede
93 Hardware Utilizado Computador Intel Core i7 920, de 2.66GHz, 6 GB de memória RAM 2 duas placas gráficas nvidia GTX 295, com 2 GPUs e 1892 MB em cada Ubuntu 9.04 de 64 bits CUDA versão 2.2, com drivers Compilador g++, com opção -O3.
94 Resultados: Tempo de execução Cresce linearmente com o número de neurônios Mas quando incluímos conexões tempo 10 vezes maior Comunicação entre neurônios é coordenada pela CPU
95 Resultados: Speedup Sem conexões: ganho de 40x Com 100 conexões / neurônio: ganho de 10x

96 Resultados CPU: maior parte do tempo usada na integração numérica GPU: maior parte do tempo é usada para comunicação


97 Estado da Arte em Simulações Supercomputador IBM BlueGene com 4096 processadores Simulação de 4 milhões de neurônios de 6 compartimentos e 2 bilhões de sinapses Cluster com 60 processadores de 3GHz and 1.5 GB of RAM Simulação de 1 milhão de neurônios e meio bilhão de sinapses. 10 minutos para inicializar e 1 minuto para simular 1 segundo de funcionamento da rede
98 Modelos de Grande Escala Já estão sendo realizadas simulações de modelos com 22 milhões de neurônios e 11 bilhões de sinapse Supercomputadores com dezenas de milhares de processadores
99 Parte V Conclusões
100 Conclusões Vimos que as GPUs permitem a obtenção de um excelente desempenho a um baixo custo Composta por centenas processadores simples e um barramento compartilhado para acesso a memória Mas: Não fornecem bom desempenho para qualquer tipo de aplicação
101 Conclusões A plataforma CUDA permite o uso de GPUs para executar aplicações paralelas Extensão da linguagem C, sendo de fácil aprendizado Mas para rodar de modo eficiente, é essencial que o código seja otimizado! A linguagem OpenCL permite criar programas que rodam em múltiplas arquiteturas Mas é difícil fazer um programa genérico que seja eficiente em arquiteturas diferentes
102 Onde Aprender Mais Existem uma grande quantidade de material na Internet sobre CUDA. No site da nvidia existe links para diversos tutoriais e cursos online sobre a arquitetura CUDA - Para quem domina o inglês falado, neste site tem um curso em vídeo sobre CUDA dado por um engenheiro da nvidia na Universidade de Illinois - Outra opção é um curso online (texto) publicado no site Dr. Dobbs. - A distribuição do CUDA vem com 2 guias: CUDA Programming Guide e CUDA Best Practices
Fabrício Gomes Vilasbôas
 Fabrício Gomes Vilasbôas Apresentação Placas Arquitetura Toolkit e Ferramentas de Debug Pensando em CUDA Programação CUDA Python Programação PyCUDA 1) Grids( padrão Globus) 2) Clusters ( padrão MPI) 3)
Fabrício Gomes Vilasbôas Apresentação Placas Arquitetura Toolkit e Ferramentas de Debug Pensando em CUDA Programação CUDA Python Programação PyCUDA 1) Grids( padrão Globus) 2) Clusters ( padrão MPI) 3)
Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot
 Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Tomás Evalero Orellana Universidade Estadual de Santa Cruz Roteiro Breve introdução
Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Tomás Evalero Orellana Universidade Estadual de Santa Cruz Roteiro Breve introdução
Computação Paralela (CUDA)
") Universidade Federal do Amazonas Faculdade de Tecnologia Departamento de Eletrônica e Computação Computação Paralela (CUDA) Hussama Ibrahim [email protected] Notas de Aula Baseado nas Notas de
Universidade Federal do Amazonas Faculdade de Tecnologia Departamento de Eletrônica e Computação Computação Paralela (CUDA) Hussama Ibrahim [email protected] Notas de Aula Baseado nas Notas de
5 Unidades de Processamento Gráfico GPUs
 5 Unidades de Processamento Gráfico GPUs As GPUs são processadores maciçamente paralelos, com múltiplos elementos de processamento, tipicamente utilizadas como aceleradores de computação. Elas fornecem
5 Unidades de Processamento Gráfico GPUs As GPUs são processadores maciçamente paralelos, com múltiplos elementos de processamento, tipicamente utilizadas como aceleradores de computação. Elas fornecem
Processamento Paralelo Utilizando GPU
 Processamento Paralelo Utilizando GPU Universidade Estadual de Santa Cruz Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Evalero Orellana Cronograma Breve introdução sobre processamento paralelo
Processamento Paralelo Utilizando GPU Universidade Estadual de Santa Cruz Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Evalero Orellana Cronograma Breve introdução sobre processamento paralelo
O Sistema de Computação
 Departamento de Ciência da Computação - UFF O Sistema de Computação Profa. Débora Christina Muchaluat Saade [email protected] O Sistema de Computação Capítulo 2 Livro do Mário Monteiro Componentes
Departamento de Ciência da Computação - UFF O Sistema de Computação Profa. Débora Christina Muchaluat Saade [email protected] O Sistema de Computação Capítulo 2 Livro do Mário Monteiro Componentes
Objetivos. Arquitetura x86. Evolução dos Microprocessadores com arquitetura x86. Universidade São Judas Tadeu. Introdução à Computação
 Universidade São Judas Tadeu Prof. André Luiz Ribeiro Prof. Jorge Luis Pirolla Introdução à Computação Microprocessadores e Arquitetura (2) - FEDELI, Ricardo D.; POLLONI, Enrico G.; PERES, Fernando E.
Universidade São Judas Tadeu Prof. André Luiz Ribeiro Prof. Jorge Luis Pirolla Introdução à Computação Microprocessadores e Arquitetura (2) - FEDELI, Ricardo D.; POLLONI, Enrico G.; PERES, Fernando E.
Informática Aplicada
 Informática Aplicada Aula 1 Introdução Diogo Pinheiro Fernandes Pedrosa Departamento de Ciências Exatas e Naturais Universidade Federal Rural do Semi-Árido Introdução Informática informação aplicada; Pressupõe
Informática Aplicada Aula 1 Introdução Diogo Pinheiro Fernandes Pedrosa Departamento de Ciências Exatas e Naturais Universidade Federal Rural do Semi-Árido Introdução Informática informação aplicada; Pressupõe
Arquitetura e Organização de Computadores
 Arquitetura e Organização de Computadores Interconexão do Computador Givanaldo Rocha de Souza http://docente.ifrn.edu.br/givanaldorocha [email protected] Material do prof. Sílvio Fernandes -
Arquitetura e Organização de Computadores Interconexão do Computador Givanaldo Rocha de Souza http://docente.ifrn.edu.br/givanaldorocha [email protected] Material do prof. Sílvio Fernandes -
Prof a Andréa Schwertner Charão DELC/CT/UFSM
 Modelos de Computadores Paralelos Prof a Andréa Schwertner Charão DELC/CT/UFSM Sumário Modelos de computadores paralelos Classificações "acadêmicas" Tendências de mercado TOP500 Impacto na programação
Modelos de Computadores Paralelos Prof a Andréa Schwertner Charão DELC/CT/UFSM Sumário Modelos de computadores paralelos Classificações "acadêmicas" Tendências de mercado TOP500 Impacto na programação
Introdução a CUDA. Esteban Walter Gonzalez Clua. Medialab - Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center START
 Introdução a CUDA START Esteban Walter Gonzalez Clua Medialab - Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center 1536 cores Dynamic Parallelism Hyper - Q Pipeline
Introdução a CUDA START Esteban Walter Gonzalez Clua Medialab - Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center 1536 cores Dynamic Parallelism Hyper - Q Pipeline
Gerenciamento de Memória Minix 3.1.7
 Gerenciamento de Memória Minix 3.1.7 Prof. Alexandre Beletti Introdução Não utiliza paginação Não faz swapping (está disponível, mas inativo) PM = gerencia processos e memória Chamadas de sistemas: Memória
Gerenciamento de Memória Minix 3.1.7 Prof. Alexandre Beletti Introdução Não utiliza paginação Não faz swapping (está disponível, mas inativo) PM = gerencia processos e memória Chamadas de sistemas: Memória
Placas Gráficas. Placas Gráficas. Placas Gráficas. Placas Gráficas. O que é? Para que serve? Resolução (cont.) Resolução
 Resolução") O que é? Para que serve? -A função das placas gráficas é a de construir as imagens que são apresentadas nos monitores dos computadores. -O conteúdo dessa memória está sempre a ser actualizado pela placa
O que é? Para que serve? -A função das placas gráficas é a de construir as imagens que são apresentadas nos monitores dos computadores. -O conteúdo dessa memória está sempre a ser actualizado pela placa
HARDWARE. Prof. Luciano Bertini
 HARDWARE Prof. Luciano Bertini http://www.professores.uff.br/lbertini/ Baseado em publicação do site http://www.guiadopc.com.br/ Baseado em uma série de postagens do site Guia do PC, intitulada Hardware
HARDWARE Prof. Luciano Bertini http://www.professores.uff.br/lbertini/ Baseado em publicação do site http://www.guiadopc.com.br/ Baseado em uma série de postagens do site Guia do PC, intitulada Hardware
Eng. Thársis T. P. Souza
 Introdução à Computação de Alto Desempenho Utilizando GPU Seminário de Programação em GPGPU Eng. Thársis T. P. Souza [email protected] Instituto de Matemática e Estatística - Universidade de São Paulo Introdução
Introdução à Computação de Alto Desempenho Utilizando GPU Seminário de Programação em GPGPU Eng. Thársis T. P. Souza [email protected] Instituto de Matemática e Estatística - Universidade de São Paulo Introdução
Avaliação e Desempenho Aula 1 - Simulação
 Avaliação e Desempenho Aula 1 - Simulação Introdução à simulação Geração de números aleatórios Lei dos grandes números Geração de variáveis aleatórias O Ciclo de Modelagem Sistema real Criação do Modelo
Avaliação e Desempenho Aula 1 - Simulação Introdução à simulação Geração de números aleatórios Lei dos grandes números Geração de variáveis aleatórias O Ciclo de Modelagem Sistema real Criação do Modelo
Introdução. Software Básico Aula 3. Prof. Dr. Rogério Vargas.
 Introdução Software Básico Aula 3 Prof. Dr. Rogério Vargas http://rogerio.in Provocação Você já se perguntou como é que os programas que você escreve são traduzidos em instruções executáveis pelas estruturas
Introdução Software Básico Aula 3 Prof. Dr. Rogério Vargas http://rogerio.in Provocação Você já se perguntou como é que os programas que você escreve são traduzidos em instruções executáveis pelas estruturas
1.1. Definição do Problema
 13 1 Introdução Uma das principais preocupações de área de engenharia de software diz respeito à reutilização [1]. Isso porque a reutilização no contexto de desenvolvimetno de software pode contribuir
13 1 Introdução Uma das principais preocupações de área de engenharia de software diz respeito à reutilização [1]. Isso porque a reutilização no contexto de desenvolvimetno de software pode contribuir
Histórico e Evolução da Computação
 Lista de Exercícios Introdução à Informática Professor: Sérgio Salazar Histórico e Evolução da Computação O 1º computador foi o ENIAC, utilizado para montar tabelas para o cálculo de projéteis na 2ª Guerra
Lista de Exercícios Introdução à Informática Professor: Sérgio Salazar Histórico e Evolução da Computação O 1º computador foi o ENIAC, utilizado para montar tabelas para o cálculo de projéteis na 2ª Guerra
Microcontroladores e Microprocessadores. Conversão de Bases Prof. Samuel Cavalcante
 Microcontroladores e Microprocessadores Conversão de Bases Prof. Samuel Cavalcante Conteúdo Conversão de Qualquer base para Decimal Decimal para Binário Hexadecimal para binário Componentes básicos de
Microcontroladores e Microprocessadores Conversão de Bases Prof. Samuel Cavalcante Conteúdo Conversão de Qualquer base para Decimal Decimal para Binário Hexadecimal para binário Componentes básicos de
Computação Gráfica Aula 0. Alexandre de Barros Barreto - Ms
 Computação Gráfica Aula 0 Alexandre de Barros Barreto - Ms Objetivo da Disciplina Apresentar a computação gráfica, enquanto conjunto de aplicações matemáticas, como ferramenta de representação de dados
Computação Gráfica Aula 0 Alexandre de Barros Barreto - Ms Objetivo da Disciplina Apresentar a computação gráfica, enquanto conjunto de aplicações matemáticas, como ferramenta de representação de dados
Patrício Domingues Dep. Eng. Informática ESTG Instituto Politécnico de Leiria Leiria, Maio Programação Genérica de GPUs
 Patrício Domingues Dep. Eng. Informática ESTG Instituto Politécnico de Leiria Leiria, Maio 2012 http://bit.ly/patricio Programação Genérica de GPUs 1 CUDA Teaching Center A ESTG/IPLeiria é um CUDA Teaching
Patrício Domingues Dep. Eng. Informática ESTG Instituto Politécnico de Leiria Leiria, Maio 2012 http://bit.ly/patricio Programação Genérica de GPUs 1 CUDA Teaching Center A ESTG/IPLeiria é um CUDA Teaching
BARRAMENTO. Caminho de Dados
 BARRAMENTO Caminho de Dados Conceito Um barramento é simplesmente um circuito que conecta uma parte da placa-mãe à outra. Quanto mais dados o barramento consegue ter de uma só vez, mais rápido a informação
BARRAMENTO Caminho de Dados Conceito Um barramento é simplesmente um circuito que conecta uma parte da placa-mãe à outra. Quanto mais dados o barramento consegue ter de uma só vez, mais rápido a informação
Sistemas Operacionais Prof. Esp. André Luís Belini Bacharel em Sistemas de Informações MBA em Gestão Estratégica de Negócios Capítulo 6 - Threads
 Sistemas Operacionais Prof. Esp. André Luís Belini Bacharel em Sistemas de Informações MBA em Gestão Estratégica de Negócios Capítulo 6 - Threads Com o conceito de múltiplos threads (multithread) é possível
Sistemas Operacionais Prof. Esp. André Luís Belini Bacharel em Sistemas de Informações MBA em Gestão Estratégica de Negócios Capítulo 6 - Threads Com o conceito de múltiplos threads (multithread) é possível
Hardware: Componentes Básicos. Sistema de Computador Pessoal. Anatomia de um Teclado. Estrutura do Computador. Arquitetura e Organização
 Hardware: Componentes Básicos Arquitetura dos Computadores Dispositivos de Entrada Processamento Dispositivos de Saída Armazenamento Marco Antonio Montebello Júnior [email protected] Sistema de
Hardware: Componentes Básicos Arquitetura dos Computadores Dispositivos de Entrada Processamento Dispositivos de Saída Armazenamento Marco Antonio Montebello Júnior [email protected] Sistema de
Introdução aos Sistemas Operacionais
 Introdução aos Sistemas Operacionais Prof. M.e Helber Wagner da Silva [email protected] Maio de 2014 Roteiro Introdução Estrutura e Funções do Sistema Operacional Sistemas Operacionais existentes
Introdução aos Sistemas Operacionais Prof. M.e Helber Wagner da Silva [email protected] Maio de 2014 Roteiro Introdução Estrutura e Funções do Sistema Operacional Sistemas Operacionais existentes
O Sistema de Computação
 O Sistema de Computação Professor: Alex Sandro Forghieri [email protected] O Sistema de Computação INTRODUÇÃO Introdução Sistemas Computacionais podem ser divididos em camadas: Aplicativos Sistema
O Sistema de Computação Professor: Alex Sandro Forghieri [email protected] O Sistema de Computação INTRODUÇÃO Introdução Sistemas Computacionais podem ser divididos em camadas: Aplicativos Sistema
Organização e Arquitetura de Computadores I
 Organização e Arquitetura de Computadores I Evolução e Desempenho dos Computadores Slide 1 Conceitos Arquitetura do Computador Refere-se aos atributos que são visíveis para o programador. Ex: conjunto
Organização e Arquitetura de Computadores I Evolução e Desempenho dos Computadores Slide 1 Conceitos Arquitetura do Computador Refere-se aos atributos que são visíveis para o programador. Ex: conjunto
Proporcionar a modelagem de sistemas utilizando todos os conceitos da orientação a objeto;
 Módulo 7 UML Na disciplina de Estrutura de Sistemas de Informação, fizemos uma rápida passagem sobre a UML onde falamos da sua importância na modelagem dos sistemas de informação. Neste capítulo, nos aprofundaremos
Módulo 7 UML Na disciplina de Estrutura de Sistemas de Informação, fizemos uma rápida passagem sobre a UML onde falamos da sua importância na modelagem dos sistemas de informação. Neste capítulo, nos aprofundaremos
Introdução a Programação Aula 01
 Introdução a Programação Aula 01 Prof. Bruno Crestani Calegaro Curso de Sistemas de Informação ELC1064 Lógica e Algoritmo 1 O que é um computador? Máquina programável genérica Constituído por: Processador
Introdução a Programação Aula 01 Prof. Bruno Crestani Calegaro Curso de Sistemas de Informação ELC1064 Lógica e Algoritmo 1 O que é um computador? Máquina programável genérica Constituído por: Processador
Montadores e Compiladores
 Montadores e Compiladores Prof. Idevar Gonçalves de Souza Júnior Conteúdo Programático Resumido Revisão da Arquitetura de Computadores Introdução a Teoria das Linguagens Compilação e Interpretação Análise
Montadores e Compiladores Prof. Idevar Gonçalves de Souza Júnior Conteúdo Programático Resumido Revisão da Arquitetura de Computadores Introdução a Teoria das Linguagens Compilação e Interpretação Análise
Supercomputador Pleiades
 Supercomputador Pleiades Introdução ao Processamento Paralelo e Distribuído Renato Marques Dilli Prof. Adenauer C. Yamin Universidade Católica de Pelotas 1 de maio de 2009 Mestrado em Ciência da Computação
Supercomputador Pleiades Introdução ao Processamento Paralelo e Distribuído Renato Marques Dilli Prof. Adenauer C. Yamin Universidade Católica de Pelotas 1 de maio de 2009 Mestrado em Ciência da Computação
Introdução ao CUDA. Material elaborado por Davi Conte.
 Introdução ao CUDA Material elaborado por Davi Conte. O objetivo deste material é que o aluno possa iniciar seus conhecimentos em programação paralela, entendendo a diferença da execução de forma sequencial
Introdução ao CUDA Material elaborado por Davi Conte. O objetivo deste material é que o aluno possa iniciar seus conhecimentos em programação paralela, entendendo a diferença da execução de forma sequencial
Algoritmos e Estruturas de Dados I. Variáveis Indexadas. Pedro O.S. Vaz de Melo
 Algoritmos e Estruturas de Dados I Variáveis Indexadas Pedro O.S. Vaz de Melo Por que índices são importantes? Como uma loja de sapatos artesanais deve guardar os seus produtos? 1 2 3 4 Tamanhos entre
Algoritmos e Estruturas de Dados I Variáveis Indexadas Pedro O.S. Vaz de Melo Por que índices são importantes? Como uma loja de sapatos artesanais deve guardar os seus produtos? 1 2 3 4 Tamanhos entre
AULA 06: PROGRAMAÇÃO EM MÁQUINAS PARALELAS
 ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 06: PROGRAMAÇÃO EM MÁQUINAS PARALELAS Prof. Max Santana Rolemberg Farias [email protected] Colegiado de Engenharia de Computação PROGRAMAÇÃO PARALELA
ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 06: PROGRAMAÇÃO EM MÁQUINAS PARALELAS Prof. Max Santana Rolemberg Farias [email protected] Colegiado de Engenharia de Computação PROGRAMAÇÃO PARALELA
Oganização e Arquitetura de Computadores
 Oganização e Arquitetura de Computadores Capítulo 14 e 15 Unidade de Controle Parte I Operação da Unidade de Controle 1 Micro-Operações Um computador executa um programa Ciclo: Busca/Executa Cada ciclo
Oganização e Arquitetura de Computadores Capítulo 14 e 15 Unidade de Controle Parte I Operação da Unidade de Controle 1 Micro-Operações Um computador executa um programa Ciclo: Busca/Executa Cada ciclo
Arquitectura interna de um computador
 Arquitectura interna de um computador Trabalho elaborado por: Carla Ventura e Sandra Jacinto 1 Descrição de uma tarefa Fases de execução de uma tarefa Unidades de execução de uma tarefa Computador como
Arquitectura interna de um computador Trabalho elaborado por: Carla Ventura e Sandra Jacinto 1 Descrição de uma tarefa Fases de execução de uma tarefa Unidades de execução de uma tarefa Computador como
Sistema Operacional. Implementação de Processo e Threads. Prof. Dr. Márcio Andrey Teixeira Sistemas Operacionais
 Sistema Operacional Implementação de Processo e Threads O mecanismo básico para a criação de processos no UNIX é a chamada de sistema Fork(). A Figura a seguir ilustra como que o processo e implementado.
Sistema Operacional Implementação de Processo e Threads O mecanismo básico para a criação de processos no UNIX é a chamada de sistema Fork(). A Figura a seguir ilustra como que o processo e implementado.
Trabalho sobre Topologia de Redes
 Trabalho sobre Topologia de Redes Emerson Baptista da Silva 27 de Janeiro de 2013 Topologia das Redes A topologia de rede descreve como o fica a sua situação física através do qual os dados, imagens e
Trabalho sobre Topologia de Redes Emerson Baptista da Silva 27 de Janeiro de 2013 Topologia das Redes A topologia de rede descreve como o fica a sua situação física através do qual os dados, imagens e
Figura 8: modelo de Von Neumann
 3. ORGANIZAÇÃO DE SISTEMA DE COMPUTADORES Olá, caro aluno! Neste capítulo vamos ver como são organizados os componentes que formam um sistema computacional. O conceito é histórico, mas é aplicado até os
3. ORGANIZAÇÃO DE SISTEMA DE COMPUTADORES Olá, caro aluno! Neste capítulo vamos ver como são organizados os componentes que formam um sistema computacional. O conceito é histórico, mas é aplicado até os
1. Estrutura de Dados
 1. Estrutura de Dados Não existe vitória sem sacrifício! Filme Transformers Um computador é uma máquina que manipula informações. O estudo da ciência da computação inclui o exame da organização, manipulação
1. Estrutura de Dados Não existe vitória sem sacrifício! Filme Transformers Um computador é uma máquina que manipula informações. O estudo da ciência da computação inclui o exame da organização, manipulação
Algoritmos APRENDENDO A PROGRAMAR COM C#
 Algoritmos APRENDENDO A PROGRAMAR COM C# Alô Mundo AULA 01 Conhecendo o ambiente O objetivo principal desse programa não é mostrar a mensagem Alo Mundo. O objetivo é apresentar o ambiente de desenvolvimento
Algoritmos APRENDENDO A PROGRAMAR COM C# Alô Mundo AULA 01 Conhecendo o ambiente O objetivo principal desse programa não é mostrar a mensagem Alo Mundo. O objetivo é apresentar o ambiente de desenvolvimento
Introdução à Ciência da Informação
 Introdução à Ciência da Informação Prof. Edberto Ferneda Software 1 Software Níveis de Software Hardware Software Aplicativos Software Tipos de Software Softwares Aplicativos de Sistema (Utilitários) Finalidades
Introdução à Ciência da Informação Prof. Edberto Ferneda Software 1 Software Níveis de Software Hardware Software Aplicativos Software Tipos de Software Softwares Aplicativos de Sistema (Utilitários) Finalidades
AULA 3 Alocação dinâmica de memória: Ponteiros
 UNIP - Ciência da Computação e Sistemas de Informação Estrutura de Dados AULA 3 Alocação dinâmica de memória: Ponteiros Estrutura de Dados 1 Variáveis X Ponteiros VARIÁVEL - Estrutura para armazenamento
UNIP - Ciência da Computação e Sistemas de Informação Estrutura de Dados AULA 3 Alocação dinâmica de memória: Ponteiros Estrutura de Dados 1 Variáveis X Ponteiros VARIÁVEL - Estrutura para armazenamento
Programação de Computadores I. Linguagem C Função
 Linguagem C Função Prof. Edwar Saliba Júnior Fevereiro de 2011 Unidade 07 Função 1 Conceitos As técnicas de programação dizem que, sempre que possível, evite códigos extensos, separando o mesmo em funções,
Linguagem C Função Prof. Edwar Saliba Júnior Fevereiro de 2011 Unidade 07 Função 1 Conceitos As técnicas de programação dizem que, sempre que possível, evite códigos extensos, separando o mesmo em funções,
GPU (Graphics Processing Unit) Bruno Padilha Gregory De Bonis Luciana Kayo
 Bruno Padilha Gregory De Bonis Luciana Kayo") GPU (Graphics Processing Unit) Bruno Padilha - 5745282 Gregory De Bonis - 6431180 Luciana Kayo - 6430992 O que é? O que é? - Processador auxiliar responsável principalmente por operações de ponto flutuante
GPU (Graphics Processing Unit) Bruno Padilha - 5745282 Gregory De Bonis - 6431180 Luciana Kayo - 6430992 O que é? O que é? - Processador auxiliar responsável principalmente por operações de ponto flutuante
INE 5323 Banco de Dados I
 UFSC-CTC-INE Curso de Ciências de Computação INE 5323 Banco de Dados I Ronaldo S. Mello 2006/1 http://www.inf.ufsc.br/~ronaldo/ine5323 Horário Atendimento: Quintas-feiras, das 17h30 às 19h Programa da
UFSC-CTC-INE Curso de Ciências de Computação INE 5323 Banco de Dados I Ronaldo S. Mello 2006/1 http://www.inf.ufsc.br/~ronaldo/ine5323 Horário Atendimento: Quintas-feiras, das 17h30 às 19h Programa da
Organização de Computadores I
 Organização de Computadores I Aula 2 Material: Diego Passos http://www.ic.uff.br/~debora/orgcomp/pdf/parte2.pdf Organização de Computadores I Aula 2 1/29 Tópicos de Computação. de um Sistema de Computação..
Organização de Computadores I Aula 2 Material: Diego Passos http://www.ic.uff.br/~debora/orgcomp/pdf/parte2.pdf Organização de Computadores I Aula 2 1/29 Tópicos de Computação. de um Sistema de Computação..
Arquitetura de Computadores Sistemas Operacionais I
 O que é um Sistema Operacional? Arquitetura de Computadores Sistemas Operacionais I Programa que atua como um intermediário entre um usuário do computador ou um programa e o hardware. Os 4 componentes
O que é um Sistema Operacional? Arquitetura de Computadores Sistemas Operacionais I Programa que atua como um intermediário entre um usuário do computador ou um programa e o hardware. Os 4 componentes
INTRODUÇÃO À PROGRAMAÇÃO II VARIÁVEIS COMPOSTAS HOMOGÊNEAS UNIDIMENSIONAIS
 INTRODUÇÃO À PROGRAMAÇÃO II VARIÁVEIS COMPOSTAS HOMOGÊNEAS UNIDIMENSIONAIS Material da Prof. Ana Eliza Dados e comandos, para serem processados, devem estar na memória do computador. Memória Definição:
INTRODUÇÃO À PROGRAMAÇÃO II VARIÁVEIS COMPOSTAS HOMOGÊNEAS UNIDIMENSIONAIS Material da Prof. Ana Eliza Dados e comandos, para serem processados, devem estar na memória do computador. Memória Definição:
Universidade Federal de Uberlândia - UFU Faculdade de Computação - FACOM Lista de exercícios de programação em linguagem C. Exercícios: Structs
 Universidade Federal de Uberlândia - UFU Faculdade de Computação - FACOM Lista de exercícios de programação em linguagem C Exercícios: Structs 1. Utilizando estrutura, fazer um programa em C que permita
Universidade Federal de Uberlândia - UFU Faculdade de Computação - FACOM Lista de exercícios de programação em linguagem C Exercícios: Structs 1. Utilizando estrutura, fazer um programa em C que permita
PARALELIZAÇÃO DO ALGORITMO AES E ANÁLISE SOBRE GPGPU 1 PARALLELIZATION OF AES ALGORITHM AND GPU ANALYSIS
 Disciplinarum Scientia. Série: Naturais e Tecnológicas, Santa Maria, v. 16, n. 1, p. 83-94, 2015. Recebido em: 11.04.2015. Aprovado em: 30.06.2015. ISSN 2176-462X PARALELIZAÇÃO DO ALGORITMO AES E ANÁLISE
Disciplinarum Scientia. Série: Naturais e Tecnológicas, Santa Maria, v. 16, n. 1, p. 83-94, 2015. Recebido em: 11.04.2015. Aprovado em: 30.06.2015. ISSN 2176-462X PARALELIZAÇÃO DO ALGORITMO AES E ANÁLISE
Instalando o Linux e outros Softwares
 Instalando o Linux e outros Softwares Atualizado em 30 de Outubro de 2013 1 Introdução Nas minhas disciplinas são adotados obrigatoriamente algumas ferramentas computacionais para auxílio no processamento
Instalando o Linux e outros Softwares Atualizado em 30 de Outubro de 2013 1 Introdução Nas minhas disciplinas são adotados obrigatoriamente algumas ferramentas computacionais para auxílio no processamento
4/11/2010. Computadores de grande porte: mainframes e supercomputadores. Sistemas Computacionais Classificação. Sistemas Computacionais Classificação
 Arquitetura de Computadores Quanto ao princípio de construção Computador Analógico: Computadores de grande porte: mainframes e supercomputadores Prof. Marcos Quinet Universidade Federal Fluminense UFF
Arquitetura de Computadores Quanto ao princípio de construção Computador Analógico: Computadores de grande porte: mainframes e supercomputadores Prof. Marcos Quinet Universidade Federal Fluminense UFF
Comparação de eficiência entre OpenCL e CUDA
 Aluno: Thiago de Gouveia Nunes Orientador: Prof. Marcel P. Jackowski GPGPU O que é GPGPU? É programação de propósito geral em GPUs. =D GPGPU Existem 2 linguagens populares no mercado para GPGPU, o CUDA
Aluno: Thiago de Gouveia Nunes Orientador: Prof. Marcel P. Jackowski GPGPU O que é GPGPU? É programação de propósito geral em GPUs. =D GPGPU Existem 2 linguagens populares no mercado para GPGPU, o CUDA
Fundamentos de Arquitetura e Organização de Computadores
 Fundamentos de Arquitetura e Organização de Computadores Dois conceitos fundamentais no estudo dos sistemas de computação são o de Arquitetura e Organização de computadores. O termo arquitetura refere-se
Fundamentos de Arquitetura e Organização de Computadores Dois conceitos fundamentais no estudo dos sistemas de computação são o de Arquitetura e Organização de computadores. O termo arquitetura refere-se
Sistemas Computacionais e Hardware. Disciplina: Informática Prof. Higor Morais
 Sistemas Computacionais e Hardware Disciplina: Informática Prof. Higor Morais 1 Agenda Sistema Computacional O Computador e seus componentes Hardware 2 Unidade de entrada Unidade de saída Unidade de Processamento
Sistemas Computacionais e Hardware Disciplina: Informática Prof. Higor Morais 1 Agenda Sistema Computacional O Computador e seus componentes Hardware 2 Unidade de entrada Unidade de saída Unidade de Processamento
Arquitetura de Computadores - Módulos de E/S. por Helcio Wagner da Silva
 Arquitetura de Computadores - Módulos de E/S por Helcio Wagner da Silva Modelo Geral de um Módulo de E/S Barramento de Endereço Barramento de Dados Barramento de Controle Módulo de E/S Conexões com Dispositivos
Arquitetura de Computadores - Módulos de E/S por Helcio Wagner da Silva Modelo Geral de um Módulo de E/S Barramento de Endereço Barramento de Dados Barramento de Controle Módulo de E/S Conexões com Dispositivos
OUTROS BARRAMENTOS: ISA, AGP, AMR
 OUTROS BARRAMENTOS: ISA, AGP, AMR Introdução Barramentos (ou, em inglês, bus) são, em poucas palavras, padrões de comunicação utilizados em computadores para a interconexão dos mais variados dispositivos.
OUTROS BARRAMENTOS: ISA, AGP, AMR Introdução Barramentos (ou, em inglês, bus) são, em poucas palavras, padrões de comunicação utilizados em computadores para a interconexão dos mais variados dispositivos.
Estrutura de um Computador
 Estrutura de um Computador Tratando-se o computador de uma máquina complexa a sua estrutura pode ser apreciada a diferentes níveis de detalhe, duma forma hierárquica. AC1 3ª aula Arquitectura e Organização
Estrutura de um Computador Tratando-se o computador de uma máquina complexa a sua estrutura pode ser apreciada a diferentes níveis de detalhe, duma forma hierárquica. AC1 3ª aula Arquitectura e Organização
INTRODUÇÃO À INFORMÁTICA
 INSTITUTO FEDERAL DE EDUCAÇÃO, CIÊNCIA E TECNOLOGIA DO RIO GRANDE DO NORTE INTRODUÇÃO À INFORMÁTICA Hardware & Software Macau-RN Novembro/2014 Sumário Introdução... 1 Evolução dos computadores... 1 Hardware...
INSTITUTO FEDERAL DE EDUCAÇÃO, CIÊNCIA E TECNOLOGIA DO RIO GRANDE DO NORTE INTRODUÇÃO À INFORMÁTICA Hardware & Software Macau-RN Novembro/2014 Sumário Introdução... 1 Evolução dos computadores... 1 Hardware...
Motivação Este trabalho apresenta o desenvolvimento do controle da interatividade num sistema para a área de computação gráfica, mais especificamente
 Viabilização da Análise de Interação em um Software Colaborativo para Modelagem de Objetos 3D Eduardo Barrére, Ana Luiza Dias e Claudio Esperança Motivação Este trabalho apresenta o desenvolvimento do
Viabilização da Análise de Interação em um Software Colaborativo para Modelagem de Objetos 3D Eduardo Barrére, Ana Luiza Dias e Claudio Esperança Motivação Este trabalho apresenta o desenvolvimento do
Entrada e Saída Transmissão Serial e Paralela
 Infra-Estrutura de Hardware Entrada e Saída Transmissão Serial e Paralela Prof. Edilberto Silva www.edilms.eti.br [email protected] Sumário Introdução Transmissões Serial (síncrona e assíncrona) e Paralela
Infra-Estrutura de Hardware Entrada e Saída Transmissão Serial e Paralela Prof. Edilberto Silva www.edilms.eti.br [email protected] Sumário Introdução Transmissões Serial (síncrona e assíncrona) e Paralela
TECNÓLOGO EM ANÁLISE E DESENVOLVIMENTO DE SISTEMAS PROGRAMAÇÃO DE COMPUTADORES I
 TECNÓLOGO EM ANÁLISE E DESENVOLVIMENTO DE SISTEMAS PROGRAMAÇÃO DE COMPUTADORES I Aula 02: Organização e Arquitetura de Computadores / Lógica Digital (Parte I) O conteúdo deste documento tem por objetivo
TECNÓLOGO EM ANÁLISE E DESENVOLVIMENTO DE SISTEMAS PROGRAMAÇÃO DE COMPUTADORES I Aula 02: Organização e Arquitetura de Computadores / Lógica Digital (Parte I) O conteúdo deste documento tem por objetivo
Conceitos c++ Prof. Demétrios Coutinho INFORMÁTICA BÁSICA
 INFORMÁTICA BÁSICA Conceitos c++ Prof. Demétrios Coutinho C a m p u s P a u d o s F e r r o s D i s c i p l i n a d e O r g a n i z a ç ã o d e A l g o r i t m o s D e m e t r i o s. c o u t i n h o @
INFORMÁTICA BÁSICA Conceitos c++ Prof. Demétrios Coutinho C a m p u s P a u d o s F e r r o s D i s c i p l i n a d e O r g a n i z a ç ã o d e A l g o r i t m o s D e m e t r i o s. c o u t i n h o @
Aula 01 Introdução Custo de um algoritmo, Funções de complexidad e Recursão
 MC3305 Algoritmos e Estruturas de Dados II Aula 01 Introdução Custo de um algoritmo, Funções de complexidad e Recursão Prof. Jesús P. Mena-Chalco [email protected] 2Q-2015 1 Custo de um algoritmo
MC3305 Algoritmos e Estruturas de Dados II Aula 01 Introdução Custo de um algoritmo, Funções de complexidad e Recursão Prof. Jesús P. Mena-Chalco [email protected] 2Q-2015 1 Custo de um algoritmo
Nosso Site. http://www.cintegrado.com.br/anapolis/
 Nosso Site http://www.cintegrado.com.br/anapolis/ MÓDULO I INFORMÁTICA BÁSICA Endereço do grupo Endereço da web atual: http://douglasddp.wordpress.com.br Endereço de e-mail atual: [email protected]
Nosso Site http://www.cintegrado.com.br/anapolis/ MÓDULO I INFORMÁTICA BÁSICA Endereço do grupo Endereço da web atual: http://douglasddp.wordpress.com.br Endereço de e-mail atual: [email protected]
O SOFTWARE R EM AULAS DE MATEMÁTICA
 O SOFTWARE R EM AULAS DE MATEMÁTICA Renata Teófilo de Sousa (autora) Graduanda - Curso de Matemática UVA Arlécia Albuquerque Melo (co-autora) Graduanda - Curso de Matemática UVA Nilton José Neves Cordeiro
O SOFTWARE R EM AULAS DE MATEMÁTICA Renata Teófilo de Sousa (autora) Graduanda - Curso de Matemática UVA Arlécia Albuquerque Melo (co-autora) Graduanda - Curso de Matemática UVA Nilton José Neves Cordeiro
Aplicando Processamento Paralelo com GPU ao Problema do Fractal de Mandelbrot
 Aplicando Processamento Paralelo com GPU ao Problema do Fractal de Mandelbrot Bruno Pereira dos Santos¹, Dany Sanchez Dominguez¹, Esbel Valero Orellana¹. 1 Departamento de Ciências Exatas e Tecnológicas
Aplicando Processamento Paralelo com GPU ao Problema do Fractal de Mandelbrot Bruno Pereira dos Santos¹, Dany Sanchez Dominguez¹, Esbel Valero Orellana¹. 1 Departamento de Ciências Exatas e Tecnológicas
- Campus Salto. Disciplina: Sistemas de Arquivos Docente: Fernando Santorsula E-mail: [email protected]
 Disciplina: Sistemas de Arquivos Docente: Fernando Santorsula E-mail: [email protected] Sistemas de Arquivos- Parte 2 Pontos importantes de um sistema de arquivos Vários problemas importantes devem
Disciplina: Sistemas de Arquivos Docente: Fernando Santorsula E-mail: [email protected] Sistemas de Arquivos- Parte 2 Pontos importantes de um sistema de arquivos Vários problemas importantes devem
Computadores e Programação (DCC/UFRJ)
") Computadores e Programação (DCC/UFRJ) Aula 3: 1 2 3 Abstrações do Sistema Operacional Memória virtual Abstração que dá a cada processo a ilusão de que ele possui uso exclusivo da memória principal Todo
Computadores e Programação (DCC/UFRJ) Aula 3: 1 2 3 Abstrações do Sistema Operacional Memória virtual Abstração que dá a cada processo a ilusão de que ele possui uso exclusivo da memória principal Todo
LABORATÓRIO DE PERÍCIA DIGITAL
 PÓS-GRADUAÇÃO LATO SENSU EM PERÍCIA DIGITAL LABORATÓRIO DE PERÍCIA DIGITAL PROFESSOR: DIEGO AJUKAS ANÁLISE DE MEMÓRIA RAM Definições Vantagens Processos: Extração Análise Tipos de Análise Análise Visual
PÓS-GRADUAÇÃO LATO SENSU EM PERÍCIA DIGITAL LABORATÓRIO DE PERÍCIA DIGITAL PROFESSOR: DIEGO AJUKAS ANÁLISE DE MEMÓRIA RAM Definições Vantagens Processos: Extração Análise Tipos de Análise Análise Visual
Do alto-nível ao assembly
 Do alto-nível ao assembly Compiladores Cristina C. Vieira 1 Viagem Como são implementadas as estruturas computacionais em assembly? Revisão dos conceitos relacionados com a programação em assembly para
Do alto-nível ao assembly Compiladores Cristina C. Vieira 1 Viagem Como são implementadas as estruturas computacionais em assembly? Revisão dos conceitos relacionados com a programação em assembly para
BC1424 Algoritmos e Estruturas de Dados I Aula 02: Ponteiros, estruturas e alocação de memória
 BC1424 Algoritmos e Estruturas de Dados I Aula 02: Ponteiros, estruturas e alocação de memória Prof. Jesús P. Mena-Chalco 1Q-2016 1 Cloud9 Crie uma conta no c9.io Apenas é requerido criar uma área (máquina
BC1424 Algoritmos e Estruturas de Dados I Aula 02: Ponteiros, estruturas e alocação de memória Prof. Jesús P. Mena-Chalco 1Q-2016 1 Cloud9 Crie uma conta no c9.io Apenas é requerido criar uma área (máquina
Roteiro... Sistemas Distribuídos Aula 4. Troca de mensagens. Comunicação entre processos. Conceitos de SD, vantagens e desvantagens
 Roteiro... Conceitos de SD, vantagens e desvantagens Infra-estrutura de um SD Considerações de projeto Sistemas Distribuídos Aula 4 Karine de Pinho Peralta Modelos de Comunicação - comunicação entre processos
Roteiro... Conceitos de SD, vantagens e desvantagens Infra-estrutura de um SD Considerações de projeto Sistemas Distribuídos Aula 4 Karine de Pinho Peralta Modelos de Comunicação - comunicação entre processos
Aula 01. Breve História dos Computadores Informatiquês O Computador Software vs. Hardware. Introdução à Informática. Prof. Fábio Nelson.
 Aula 01 Breve História dos Computadores Informatiquês O Computador Software vs. Hardware Slide 1 de Qual é a origem etimológica da palavra COMPUTADOR? Computador procede do latim computatore. Ao pé da
Aula 01 Breve História dos Computadores Informatiquês O Computador Software vs. Hardware Slide 1 de Qual é a origem etimológica da palavra COMPUTADOR? Computador procede do latim computatore. Ao pé da
INTEGRAÇÃO JAVA COM ARDUINO
 INTEGRAÇÃO JAVA COM ARDUINO Alessandro A. M. De Oliveira 3, Alexandre O. Zamberlan 3, Reiner F Perozzo 3, Rafael O. Gomes 1 ;Sergio R. H Righi 2,PecilcesP. Feltrin 2 RESUMO A integração de Linguagem de
INTEGRAÇÃO JAVA COM ARDUINO Alessandro A. M. De Oliveira 3, Alexandre O. Zamberlan 3, Reiner F Perozzo 3, Rafael O. Gomes 1 ;Sergio R. H Righi 2,PecilcesP. Feltrin 2 RESUMO A integração de Linguagem de
Apostila de GSO Gestão de Sistemas Operacionais I
 Apostila de GSO Gestão de Operacionais I Prof. Jones Artur Gonçalves / Wendell Santos 1 Arquitetura de Operacionais 1. Histórico... 3 2. Sistema Operacional... 4 3. Tipos de Operacionais... 5 2.1 Monoprogramáveis...
Apostila de GSO Gestão de Operacionais I Prof. Jones Artur Gonçalves / Wendell Santos 1 Arquitetura de Operacionais 1. Histórico... 3 2. Sistema Operacional... 4 3. Tipos de Operacionais... 5 2.1 Monoprogramáveis...
Capítulo 2 Livro do Mário Monteiro Componentes Representação das informações. Medidas de desempenho
 Capítulo 2 Livro do Mário Monteiro Componentes Representação das informações Bit, Caractere, Byte e Palavra Conceito de Arquivos e Registros Medidas de desempenho http://www.ic.uff.br/~debora/fac! 1 2
Capítulo 2 Livro do Mário Monteiro Componentes Representação das informações Bit, Caractere, Byte e Palavra Conceito de Arquivos e Registros Medidas de desempenho http://www.ic.uff.br/~debora/fac! 1 2