Programação Paralela. Simone de Lima Martins Agosto/2002
|
|
|
- Brian de Sousa Deluca
- 8 Há anos
- Visualizações:
Transcrição
1 Programação Paralela Simone de Lima Martins Agosto/2002

2 Computação por Passagem de Mensagens

3 Arquitetura de computadores que utilizam passagem de mensagens Computadores conectados por uma rede estática com passagem de mensagens Computadores conectados por redes locais ou geograficamente distribuídas

4 Multiprocessadores conectados por rede Processadores conectados por uma rede estática com passagem de mensagens P M Computadores P M C C Rede com ligações diretas entre computadores C P M

5 Topologia de interconexão Anel Grade bidimensional ou malha de 16 nós Árvore n-cubo de 8 nós

6 Computadores ligados em rede Nós de multiprocessadores similares a computadores desktop Aumento da velocidade das redes locais Aparecimento de clusters de computadores de prateleira interligados por redes de alta velocidade

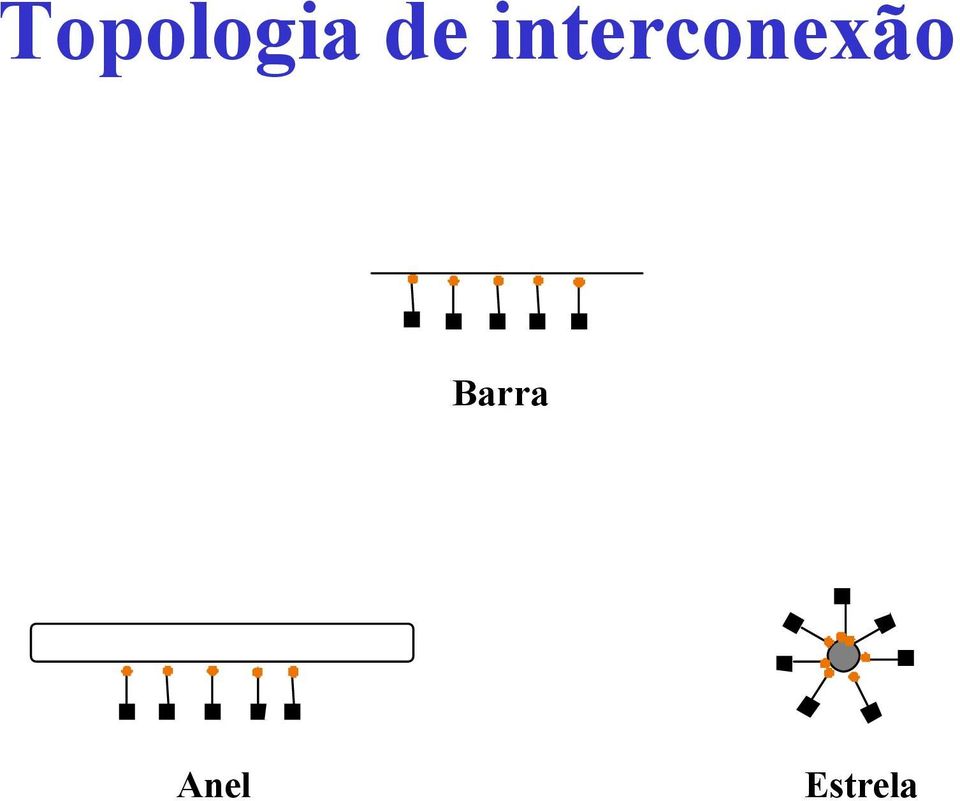
7 Topologia de interconexão Barra Anel Estrela
8 Clusters Aparecimento de clusters de computadores de prateleira interligados por redes de alta velocidade Rede de computador dedicada Exemplos: Sandia Cplant (592 Compaq XP100 workstations interconectadas pela Myrinet) IBM RS/6000 SP2 (512 nós, switch própria) Celera (700 CPUs conectadas por Gigabit Ethernet)
 Celera (700 CPUs conectadas por Gigabit")
9 Clusters - Exemplos IBM ASCI White, SP (mais rápida) 8192 processadores 6 Tbytes de memória e 160 Tbytes de disco Interconexão por switch própria Celera 10 estações com 6 a 12 processadores cada e com 24 Gbytes de memória Um servidor com 16 processadores e 64 Gbytes de memória 150 estações com 4 processadores cada e com memória variando de 2 a 32 Gbytes de memória 70 Tbytes de disco

10 Clusters - Exemplos BioCluster (COMPAQ) 25 estações ALPHA com 4 processadores cada e 4 Gbytes de memória 1 nó com 16 Gbytes de memória 1 servidor de arquivo com 4 Gbytes de memória e 1 Tbytes de disco BLAST, FASTA, CLUSTALW

11 Programação por passagem de mensagens Programação de multiprocessadores conectados por rede pode ser realizada: criando-se uma linguagem de programação paralela especial estendendo-se as palavras reservadas de uma linguagem seqüencial existente de alto nível para manipulação de passagem de mensagens utilizando-se uma linguagem seqüencial existente, provendo uma biblioteca de procedimentos externos para passagem de mensagens

12 Biblioteca de rotinas para troca de mensagens Necessita-se explicitamente definir: quais processos serão executados quando passar mensagens entre processos concorrentes o que passar nas mensagens Dois métodos primários: um para criação de processos separados para execução em diferentes processadores um para enviar e receber mensagens

13 Modelo Single Program Multiple Data (SPMD) Diferentes processos são unidos em um único programa e dentro deste programa existem instruções que customizam o código, selecionando diferentes partes para cada processo por exemplo Executáveis Código fonte Compila para gerar executável para cada processador Processador 0 Processador n-1

14 Modelo Multiple Program, Multiple Data (MPMD) Programas separados escritos para cada processador, geralmente se utiliza o método mestre-escravo onde um processador executa o processo mestre e os outros processos escravos são inicializados por ele. Processo 1 tempo spawn(); Inicia execução do processo 2 Processo 2

15 Rotinas básicas de envio e recebimento Processo 1 x Processo 2 y send(&x, 2); recv(&y, 1);
;")
16 Broadcast Envio da mesma mensagem para todos os processos Multicast: envio da mesma mensagem para um grupo de processos Processo 0 dado Processo 1 dado Processo n-1 dado Ação buf Código bcast(); bcast(); bcast();
; bcast();")
17 Ferramentas de software que utilizam biblioteca de troca de mensagens PVM (Parallel Virtual Machine) desenvolvida pelo Oak Ridge National Laboratories para utilizar um cluster de estações de trabalho como uma plataforma multiprocessada provê rotinas para passagem de mensagens entre máquinas homogêneas e heterogêneas que podem ser utilizadas com programas escritos em C ou Fortran MPI (Message Passing Interface) padrão desenvolvido por um grupo de parceiros acadêmicos e da indústria para prover um maior uso e portabilidade das rotinas de passagem de mensagens

18 PVM O programador decompõe o programa em programas separados e cada um deles será escrito em C ou Fortran e compilado para ser executado nas diferentes máquinas da rede O conjunto de máquinas que será utilizado para processamento deve ser definido antes do início da execução dos programas Cria-se um arquivo (hostfile) com o nome de todas as máquinas disponíveis que será lido pelo PVM O roteamento de mensagens é feito pelos processos daemon do PVM

19 Passagem de mensagens utilizando o PVM Estação de trabalho Daemon PVM Estação de trabalho Programa da aplicação (executável) Mensagens enviadas através da rede Estação de trabalho Daemon PVM Programa da aplicação (executável) Daemon PVM Programa da aplicação (executável)
 Daemon PVM Programa da aplicação")
20 Passagem de mensagens utilizando o PVM Estação de trabalho Daemon PVM Estação de trabalho Daemon PVM Mensagens enviadas através da rede Estação de trabalho Daemon PVM

21 MPI Criação e execução de processos Propositalmente não são definidos e dependem da implementação MPI versão 1 Criação estática de processos: processos devem ser definidos antes da execução e inicializados juntos Utiliza o modelo de programação SPMD
22 Utilizando o modelo SPMD main (int argc, char *argv[]) { MPI_Init(&argc, &argv);.. MPI_Comm_Rank(MPI_COMM_WORLD, &myrank); if (myrank ==0) master(); else slave(); }.. MPI_Finalize();
23 Rotinas com bloqueio MPI_Send (buf, count, datatype, dest, tag, comm) Endereço do buffer de envio Número de ítens a enviar Tipo de dados de cada item Índice da mensagem Rank do processo destino MPI_Recv (buf, count, datatype, src, tag, comm,status) Endereço do buffer de recepção Número máximo de ítens a receber Tipo de dados de cada item Índice da mensagem Rank do processo fonte Communicator Status após operação Communicator
24 Exemplo de rotina com bloqueio Envio de um inteiro x do processo 0 para o processo 1 MPI_Comm_rank(MPI_COMM_WORLD, &myrank); if (myrank ==0) { int x; MPI_Send(&x, 1, MPI_INT, 1, msgtag, MPI_COMM_WORLD); } else if (myrank ==1) { int x; MPI_Recv(&x, 1, MPI_INT, 0, msgtag, MPI_COMM_WORLD, status); }
25 Comunicação coletiva MPI_Bcast(): envio do processo raíz para todos os outros MPI_Alltoall():envia dados de todos os processos para todos os processos
26 Tempo de execução paralela Composto de duas partes: t comp : parte de computação t comm : parte de comunicação t p = t comp + t comm Tempo de computação estimado como em algoritmo seqüencial Tempo de comunicação: t comm = t startup + nt data t startup : tempo para enviar uma mensagem sem dados t data : tempo para transmitir uma palavra de dados n: número de palavras a transmitir
27 Tempo teórico de comunicação Tempo Tempo t startup Número de itens de dados (n)
28 Algoritmos com custo ótimo Custo é considerado ótimo quando o custo de resolver um problema é proporcional ao tempo de execução em um único processador utilizando o mais rápido algoritmo seqüencial conhecido Custo = t p? n = k? t s
29 Depurando e avaliando os programas paralelos Diagrama de espaço-tempo Processo 1 Processo 2 Processo 3 Processando Tempo Esperando Rotina do sistema para passagem de mensagem Mensagem
30 Estratégias de depuração Sugestão de Geist et al. Para depuração de programas paralelos: 1. Execute o programa como um único processo e depure como um programa seqüencial (se possível) 2. Execute o programa utilizando dois ou quatro processos em uma mesma máquina e verifique se mensagens estão sendo enviadas de forma correta (erros são comuns nos índices e destinos das mensagens) 3. Execute o programa utilizando os mesmos dois ou quatro processos em várias máquinas para tentar descobrir problemas na sincronização e temporização no programa que podem aparecer devido a atrasos na rede
31 Avaliando programas empiricamente Medindo tempo de execução L1: time(&t1);.. L2: time(&t2);. elapsed_time = difftime (t2,t1); printf( Elapsed_time = %5.2f segundos, elapsed_time); Rotina MPI_ Wtime() provê hora em segundos
32 Memória Compartilhada
33 Programação com memória compartilhada Nos sistemas multiprocessadores com memória compartilhada, qualquer localização da memória pode ser acessada por qualquer processador Existe um espaço de endereçamento único, ou seja, cada localização de memória possui um único endereço dentro de uma extensão única de endereços
34 Arquitetura com barramento único Barramento Cache Processadores Módulos de memória
35 Alternativas para programação Utilizar uma nova linguagem de programação Modificar uma linguagem seqüencial existente Utilizar uma linguagem seqüencial existente com rotinas de bibliotecas Utilizar uma linguagem de programação seqüencial e deixar a cargo de um compilador paralelizador a geração de um código paralelo executável
36 Algumas linguagens de programação paralelas Linguagem Criador/data Comentários Ada Depto. de defesa americano C* Thinking Machines, 1987 Concurrent C Gehani e Roome, 1989 Nova linguagem Extensão a C para sistemas SIMD Extensão a C Fortran F Foz et al., 1990 Extensão a Fortran para programação por paralelismo de dados Modula-P Braünl, 1986 Extensão a Modula 2 Pascal concorrente Brinch Hansen, 1975 Extensão ao Pascal
37 Elementos básicos Processos Threads
38 Criação de processos concorrentes utilizando a construção fork-join Programa principal FORK FORK FORK JOIN JOIN JOIN JOIN
39 Processos UNIX A chamada do UNIX fork() cria um novo processo, denominado processo filho O processo filho é uma cópia exata do processo que chama a rotina fork(), sendo a única diferença um identificador de processo diferente Esse processo possui uma cópia das variáveis do processo pai inicialmente com os mesmos valores do pai O processo filho inicia a execução no ponto da chamada da rotina Caso a rotina seja executada com sucesso, o valor 0 é retornado ao processo filho e o identificador do processo filho é retornado ao processo pai
40 Processos UNIX Os processos são ligados novamente através das chamadas ao sistema: wait(status): atrasa a execução do chamador até receber um sinal ou um dos seus processos filhos terminar ou parar exit(status): termina o processo Criação de um único processo filho pid = fork(); código a ser executado pelo pai e filho if (pid == 0) exit (0); else wait (0) Filho executando código diferente pid = fork(); if (pid == 0) { código a ser executado pelo filho } else { código a ser executado pelo pai } if (pid == 0) exit (0); else wait (0);
41 Threads Heap Código Processos: programas completamente separados com suas próprias variáveis, pilha e alocação de memória IP Pilha Rotinas de interrupção Arquivos Threads: as rotinas compartilham o mesmo espaço de memória e variáveis globais Pilha Pilha IP IP Código Heap Rotinas de interrupção Arquivos
42 Pthreads Interface portável do sistema operacional, POSIX, IEEE Programa principal thread1 proc1(&arg); { pthread_create(&thread1, NULL, proc1, &arg); return(&status); } pthread_join(thread1, NULL, &status);
43 Rotinas seguras para threads As chamadas ao sistema ou rotinas de bibliotecas são denominadas seguras para threads, quando elas podem ser acionadas por várias threads ao mesmo tempo e sempre produzem resultados corretos Rotinas padrão de E/S: imprimem mensagens sem permitir interrupção entre impressão de caracteres Rotinas que acessam dados compartilhados ou estáticos requerem cuidados especiais para serem seguras para threads Pode-se forçar a execução da rotina somente por uma thread de cada vez, ineficiente
44 Acessando dados compartilhados Considere dois processos que devem ler o valor de uma variável x, somar 1 a esse valor e escrever o novo valor de volta na variável x tempo Instrução x = x + 1 Processo 1 ler x calcular x + 1 escrever x Processo 2 ler x calcular x + 1 escrever x
45 Conflito em acesso a dados compartilhados Variável compartilhada, x Escrever Ler Ler Escrever Processo 1 Processo 2
46 Rotinas de lock Para poder se acessar estas variáveis compartilhadas sem problemas, devem existir rotinas que bloqueiam o acesso a elas enquanto uma das threads está executando Rotinas de lock
47 Deadlock Pode ocorrer com dois processos quando um deles precisa de um recurso que está com outro e esse precisa de um recurso que está com o primeiro R 1 R 2 Recurso P 1 P 2 Processo
48 Exemplo de implementação A procura de um padrão em seqüências de DNA Algoritmo com granulosidade fina Algoritmo com granulosidade média Implementação com troca de mensagens Implementação com threads (memória compartilhada)
49 Exemplo de implementação Algoritmo seqüencial simples que não é o mais eficiente A T C A T G C C A A T G A T G Primeira Comparação A T C A T G C C A A T G Segunda Comparação A T G A T C A T G C C A A T G A T G Terceira Comparação
50 Granulosidade fina Cada processador faz uma comparação A T C A T G C C A A T G A T G P1 Não achou A T C A T G C C A A T G A T G P2 Não achou A T C A T G C C A A T G A T G P10 Achou POS=10
51 Granulosidade fina com troca de mensagens Um processo mestre controla as operações Processos escravos executam as comparações e devolvem resultados Processo Mestre Envia padrão, sequência e posição a comparar Processo Escravo Retorna inidcação de match Envia padrão, sequência e posição a comparar Processo Escravo Retorna indicação de match Envia padrão, sequência e posição a comparar Retorna indicação de match Processo Escravo
52 Granulosidade fina com troca de mensagens - Processo mestre Envia padrão P[1..N] aos escravos Para cada seqüência S i [1..M] faça Envia S i para cada processador Verifica quantas comparações devem ser feitas por cada processador (M-N+1)/NP Envia o intervalo de comparações para cada processador Espera resultado de cada processador Envia indicação de fim de processo para cada processador
53 Granulosidade fina com troca de mensagens - Processo escravo Recebe padrão P[1..N] do mestre Enquanto não recebe indicação de fim de processo do mestre faça Recebe S i Recebe as comparações que devem ser feitas Executa as comparações Envia resultado para mestre
54 Granulosidade fina com troca de mensagens - Exemplo P[1..3]=ATG 300 seqüências de tamanho 12 5 processadores Devem ser executadas 10 comparações Cada processador executa 2 comparações Análise de desempenho
55 Granulosidade fina com threads Um processo mestre controla as operações através de variáveis compartilhadas Processos escravos executam as comparações e devolvem resultados através de variáveis compartilhadas Inicializa todas as variáveis S1 Memória compartilhada Processo Mestre Lê resultados S2 S3 : Sm Número_de_Seqüências Índice_de_Seqüência Inicia Thread Escravo Inicia Thread Escravo Lê e escreve variáveis P1 P2 P3.. Pn Número_de_Posições Posição Lê e escreve variáveis Posições_Encontradas
56 Granulosidade fina com threads - Processo mestre Lê Padrão P[1..N], Número_de_Seqüências e Seqüências S i [1..M] Inicializa variáveis de controle Índice_de_Seqüência=1; Posição=1; Número_de_Posições = (M-N+1)/NP Inicia threads escravas Enquanto Índice_de_Seqüência < Número_de_Seqüências faça Espera todas as threads lerem Índice_de_Seqüência Espera threads executarem comparações Imprime resultados que estão em Posições_Encontradas Incrementa Índice_de_Seqüência
57 Granulosidade fina com threads - Thread escrava Repita Lê Índice_de_Seqüência Espera todas as threads lerem Índice_de_Seqüência Espera Posição estar desbloqueada Bloqueia Posição Lê Posição Incrementa Posição de Número _de_posições Desbloqueia Posição Executa as comparações com Seqüência Índice_de_Seqüência Coloca resultado em Posições_Encontradas Até Índice_de_Seqüência > Número_de_Seqüências
58 Granulosidade fina com threads - Exemplo P[1..3]=ATG 300 seqüências de tamanho 12 5 processadores Devem ser executadas 10 comparações Cada processador executa 2 comparações Análise de desempenho
59 Granulosidade média Divide as seqüências a serem procuradas entre os processadores e cada processador procura o padrão nas suas seqüências Seqüências S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 S13 S14 S15 Procura padrão em S1, S2, S3, S4 e S5 e retorna posições encontradas em cada uma delas P1 Procura padrão em S6, S7, S8, S9 e S10 e retorna posições encontradas em cada uma delas P2 Procura padrão em S11, S12, S13, S14 e S15 e retorna posições encontradas em cada uma delas P3
60 Granulosidade média com troca de mensagens Um processo mestre envia grupos de seqüências para os processadores escravos Processos escravos procuram o padrão em seu grupo de seqüências e enviam resultados para o processo mestre Processo Mestre Envia padrão e grupo de seqüências Processo Escravo Retorna matches de cada seqüência do grupo Envia padrão e grupo de seqüências Processo Escravo Retorna matches de cada seqüência do grupo Envia padrão e grupo de seqüências Retorna matches de cada seqüência do grupo Processo Escravo
61 Granulosidade média com troca de mensagens - Processo mestre Envia (Número_de_Seqüências/NP) seqüências S i [1..M] e padrão P[1..N] para cada processador Espera resultados de cada processador
62 Granulosidade média com troca de mensagens - Processo escravo Recebe grupo de seqüências S i [1..M] e padrão P[1..N] do mestre Para cada seqüência do grupo Encontra posições do padrão e coloca em resultado Envia resultado para mestre
63 Granulosidade média com troca de mensagens - Exemplo P[1..3]=ATG 300 seqüências de tamanho 12 5 processadores Cada processador procura o padrão em um grupo de 60 seqüências Análise de desempenho
64 Granulosidade média com threads Um processo mestre controla as operações através de variáveis compartilhadas Processos escravos executam as comparações e devolvem resultados através de variáveis compartilhadas Memória compartilhada Processo Mestre Inicializa todas as variáveis Lê resultados S1 S2 S3 : Sm Seqüências_por_Grupo Índice_de_Seqüência Inicia Inicia Posições_Enc1 Thread Escravo Thread Escravo Lê e escreve variáveis P1 P2 P3.. Pn Posições_Enc2 Posições_Enc3 : Lê e escreve variáveis Posições_Encm
65 Granulosidade média com threads - Processo mestre Lê Padrão P[1..N] e Seqüências S i [1..M] Inicializa variáveis de controle Seqüências_por_Grupo = Número_de_Seqüências/NP Índice_de_Seqüência=1 Inicia threads escravas Espera todas as threads executarem as comparações Imprime resultados que estão em Posições_Encontradas
66 Granulosidade fina com threads - Phread escrava Lê Seqüências_por_Grupo Espera Índice_de_Seqüência estar desbloqueada Bloqueia Índice_de_Seqüência Lê Índice_de_Seqüência Incrementa Índice_de_Seqüência de Seqüências_por_Grupo Desbloqueia Índice_de_Seqüência Executa as comparações Coloca resultado em Posições_Encontradas
67 Granulosidade média com troca de mensagens - Exemplo P[1..3]=ATG 300 seqüências de tamanho 12 5 processadores Cada processador procura o padrão em um grupo de 60 seqüências Análise de desempenho
68 Bibliografia? Barry Wilkinson; Michael Allen. Parallel Programming; Techniques and Applications using networked workstations and parallel computers. Prentice Hall, 1999.? Gregory R. Andrews. Foundations of Multithreaded, Parallel, and Distributed Programming. Addison-Wesley, 2000.? Ian Foster Designing and Building Parallel Programs. MIT Press 1999, disponivel em Lou Baker and Bradley J. Smith. Parallel Programming.McGraw-Hill, 1996? George S. Almasi and Allan M. Gottlieb Higly Parallel Computing. Benjamin/Cummings 1989? Michael J. Quinn. Parallel Computing: theory and practice. McGraw-Hill, 1994.
Programação Paralela com Troca de Mensagens. Profa Andréa Schwertner Charão DLSC/CT/UFSM
 Programação Paralela com Troca de Mensagens Profa Andréa Schwertner Charão DLSC/CT/UFSM Sumário Modelo de programa MPI Comunicação em MPI Comunicadores Mensagens Comunicação ponto-a-ponto Comunicação coletiva
Programação Paralela com Troca de Mensagens Profa Andréa Schwertner Charão DLSC/CT/UFSM Sumário Modelo de programa MPI Comunicação em MPI Comunicadores Mensagens Comunicação ponto-a-ponto Comunicação coletiva
Parte da Tarefa. Parte da Tarefa. Parte da Tarefa SEND RECEIVE SEND RECEIVE
 Produto Escalar com MPI-2 (C++) Aula Sistemas Distribuídos Prof. Dr. Marcelo Facio Palin profpalin@gmail.com 1 1 O que é Paralelismo? Conceitos Paralelismo é uma técnica usada em tarefas grandes e complexas
Produto Escalar com MPI-2 (C++) Aula Sistemas Distribuídos Prof. Dr. Marcelo Facio Palin profpalin@gmail.com 1 1 O que é Paralelismo? Conceitos Paralelismo é uma técnica usada em tarefas grandes e complexas
APLICAÇÕES EM SISTEMAS DISTRIBUÍDOS Prof. Ricardo Rodrigues Barcelar http://www.ricardobarcelar.com
 - Aula 6 - ALGORÍTIMOS PARALELOS MPI - Parallel Virtual Machine e PVM - Parallel Virtual Machine 1. INTRODUÇÃO Inicialmente é necessário conceber alguns conceitos para entendimento dos algoritmos paralelos:
- Aula 6 - ALGORÍTIMOS PARALELOS MPI - Parallel Virtual Machine e PVM - Parallel Virtual Machine 1. INTRODUÇÃO Inicialmente é necessário conceber alguns conceitos para entendimento dos algoritmos paralelos:
Computação por Passagem de Mensagens
 Computação por Passagem de Mensagens Programação por passagem de mensagens Programação de multiprocessadores conectados por rede pode ser realizada: criando-se uma linguagem de programação paralela especial
Computação por Passagem de Mensagens Programação por passagem de mensagens Programação de multiprocessadores conectados por rede pode ser realizada: criando-se uma linguagem de programação paralela especial
Capítulo 8 Arquitetura de Computadores Paralelos
 Capítulo 8 Arquitetura de Computadores Paralelos Necessidade de máquinas com alta capacidade de computação Aumento do clock => alta dissipação de calor Velocidade limitada dos circuitos => velocidade da
Capítulo 8 Arquitetura de Computadores Paralelos Necessidade de máquinas com alta capacidade de computação Aumento do clock => alta dissipação de calor Velocidade limitada dos circuitos => velocidade da
Centro Tecnológico de Eletroeletrônica César Rodrigues. Atividade Avaliativa
 1ª Exercícios - REDES LAN/WAN INSTRUTOR: MODALIDADE: TÉCNICO APRENDIZAGEM DATA: Turma: VALOR (em pontos): NOTA: ALUNO (A): 1. Utilize 1 para assinalar os protocolos que são da CAMADA DE REDE e 2 para os
1ª Exercícios - REDES LAN/WAN INSTRUTOR: MODALIDADE: TÉCNICO APRENDIZAGEM DATA: Turma: VALOR (em pontos): NOTA: ALUNO (A): 1. Utilize 1 para assinalar os protocolos que são da CAMADA DE REDE e 2 para os
slide 0 Algoritmos Paralelos
 slide 0 Algoritmos Paralelos Slide 2 Demanda por Velocidade Computational Demanda contínua por maior rapidez computational das máquinas que as atualmente disponíveis. As áreas que exigem maior rapidez
slide 0 Algoritmos Paralelos Slide 2 Demanda por Velocidade Computational Demanda contínua por maior rapidez computational das máquinas que as atualmente disponíveis. As áreas que exigem maior rapidez
Arquitecturas Paralelas I Computação Paralela em Larga Escala. Passagem de Mensagens
 Arquitecturas Paralelas I Computação Paralela em Larga Escala LESI/LMCC - 4º/5º Ano Passagem de Mensagens João Luís Ferreira Sobral Departamento do Informática Universidade do Minho Novembro 2004 Passagem
Arquitecturas Paralelas I Computação Paralela em Larga Escala LESI/LMCC - 4º/5º Ano Passagem de Mensagens João Luís Ferreira Sobral Departamento do Informática Universidade do Minho Novembro 2004 Passagem
Sistemas Operacionais
 Sistemas Operacionais Aula 6 Estrutura de Sistemas Operacionais Prof.: Edilberto M. Silva http://www.edilms.eti.br Baseado no material disponibilizado por: SO - Prof. Edilberto Silva Prof. José Juan Espantoso
Sistemas Operacionais Aula 6 Estrutura de Sistemas Operacionais Prof.: Edilberto M. Silva http://www.edilms.eti.br Baseado no material disponibilizado por: SO - Prof. Edilberto Silva Prof. José Juan Espantoso
Sistemas Operacionais
 Sistemas Operacionais SISTEMAS COM MÚLTIPLOS PROCESSADORES LIVRO TEXTO: CAPÍTULO 13, PÁGINA 243 Prof. Pedro Luís Antonelli Anhanguera Educacional INTRODUÇÃO Arquiteturas que possuem duas ou mais CPUs interligadas
Sistemas Operacionais SISTEMAS COM MÚLTIPLOS PROCESSADORES LIVRO TEXTO: CAPÍTULO 13, PÁGINA 243 Prof. Pedro Luís Antonelli Anhanguera Educacional INTRODUÇÃO Arquiteturas que possuem duas ou mais CPUs interligadas
Prof. Marcos Ribeiro Quinet de Andrade Universidade Federal Fluminense - UFF Pólo Universitário de Rio das Ostras - PURO
 Conceitos básicos e serviços do Sistema Operacional Prof. Marcos Ribeiro Quinet de Andrade Universidade Federal Fluminense - UFF Pólo Universitário de Rio das Ostras - PURO Tipos de serviço do S.O. O S.O.
Conceitos básicos e serviços do Sistema Operacional Prof. Marcos Ribeiro Quinet de Andrade Universidade Federal Fluminense - UFF Pólo Universitário de Rio das Ostras - PURO Tipos de serviço do S.O. O S.O.
Processos e Threads (partes I e II)
") Processos e Threads (partes I e II) 1) O que é um processo? É qualquer aplicação executada no processador. Exe: Bloco de notas, ler um dado de um disco, mostrar um texto na tela. Um processo é um programa
Processos e Threads (partes I e II) 1) O que é um processo? É qualquer aplicação executada no processador. Exe: Bloco de notas, ler um dado de um disco, mostrar um texto na tela. Um processo é um programa
Introdução. Definição de um Sistema Distribuído (1) Definição de um Sistema Distribuído(2) Metas de Sistemas Distribuídos (2)
 Definição de um Sistema Distribuído(2) Metas de Sistemas Distribuídos (2)") Definição de um Sistema Distribuído (1) Introdução Um sistema distribuído é: Uma coleção de computadores independentes que aparecem para o usuário como um único sistema coerente. Definição de um Sistema
Definição de um Sistema Distribuído (1) Introdução Um sistema distribuído é: Uma coleção de computadores independentes que aparecem para o usuário como um único sistema coerente. Definição de um Sistema
CAPÍTULO 2 CARACTERÍSTICAS DE E/S E PORTA PARALELA
 8 CAPÍTULO 2 CARACTERÍSTICAS DE E/S E PORTA PARALELA A porta paralela, também conhecida por printer port ou Centronics e a porta serial (RS-232) são interfaces bastante comuns que, apesar de estarem praticamente
8 CAPÍTULO 2 CARACTERÍSTICAS DE E/S E PORTA PARALELA A porta paralela, também conhecida por printer port ou Centronics e a porta serial (RS-232) são interfaces bastante comuns que, apesar de estarem praticamente
Sistemas Paralelos e Distribuídos. Prof. Jorge Dantas de Melo Depto. Eng. Comp. e Automação CT - UFRN
 Sistemas Paralelos e Distribuídos Prof. Jorge Dantas de Melo Depto. Eng. Comp. e Automação CT - UFRN Conceitos preliminares Paralelismo refere-se a ocorrência simultânea de eventos em um computador Processamento
Sistemas Paralelos e Distribuídos Prof. Jorge Dantas de Melo Depto. Eng. Comp. e Automação CT - UFRN Conceitos preliminares Paralelismo refere-se a ocorrência simultânea de eventos em um computador Processamento
Programação Concorrente Processos e Threads
 Programação Concorrente Processos e Threads Prof. Eduardo Alchieri Processos O conceito mais central em qualquer sistema operacional é o processo Uma abstração de um programa em execução Um programa por
Programação Concorrente Processos e Threads Prof. Eduardo Alchieri Processos O conceito mais central em qualquer sistema operacional é o processo Uma abstração de um programa em execução Um programa por
Everson Scherrer Borges João Paulo de Brito Gonçalves
 Everson Scherrer Borges João Paulo de Brito Gonçalves 1 Tipos de Sistemas Operacionais Os tipos de sistemas operacionais e sua evolução estão relacionados diretamente com a evolução do hardware e das
Everson Scherrer Borges João Paulo de Brito Gonçalves 1 Tipos de Sistemas Operacionais Os tipos de sistemas operacionais e sua evolução estão relacionados diretamente com a evolução do hardware e das
Arquitetura de Computadores. Tipos de Instruções
 Arquitetura de Computadores Tipos de Instruções Tipos de instruções Instruções de movimento de dados Operações diádicas Operações monádicas Instruções de comparação e desvio condicional Instruções de chamada
Arquitetura de Computadores Tipos de Instruções Tipos de instruções Instruções de movimento de dados Operações diádicas Operações monádicas Instruções de comparação e desvio condicional Instruções de chamada
Notas da Aula 4 - Fundamentos de Sistemas Operacionais
 Notas da Aula 4 - Fundamentos de Sistemas Operacionais 1. Threads Threads são linhas de execução dentro de um processo. Quando um processo é criado, ele tem uma única linha de execução, ou thread. Esta
Notas da Aula 4 - Fundamentos de Sistemas Operacionais 1. Threads Threads são linhas de execução dentro de um processo. Quando um processo é criado, ele tem uma única linha de execução, ou thread. Esta
SIMULADOR DE ROTEAMENTO DE PACOTES (V. 3 20/05/2010)
") SIMULADOR DE ROTEAMENTO DE PACOTES (V. 3 20/05/2010) OBJETIVO GERAL Este trabalho possui o objetivo de exercitar a lógica de programação dos alunos do Terceiro ano do Curso de BSI e também desenvolver
SIMULADOR DE ROTEAMENTO DE PACOTES (V. 3 20/05/2010) OBJETIVO GERAL Este trabalho possui o objetivo de exercitar a lógica de programação dos alunos do Terceiro ano do Curso de BSI e também desenvolver
Infra-Estrutura de Software. Introdução. (cont.)
") Infra-Estrutura de Software Introdução (cont.) O que vimos Complexidade do computador moderno, do ponto de vista do hardware Necessidade de abstrações software Sistema computacional em camadas SO como
Infra-Estrutura de Software Introdução (cont.) O que vimos Complexidade do computador moderno, do ponto de vista do hardware Necessidade de abstrações software Sistema computacional em camadas SO como
Sistemas Distribuídos. Professora: Ana Paula Couto DCC 064
 Sistemas Distribuídos Professora: Ana Paula Couto DCC 064 Processos- Clientes, Servidores, Migração Capítulo 3 Agenda Clientes Interfaces de usuário em rede Sistema X Window Software do lado cliente para
Sistemas Distribuídos Professora: Ana Paula Couto DCC 064 Processos- Clientes, Servidores, Migração Capítulo 3 Agenda Clientes Interfaces de usuário em rede Sistema X Window Software do lado cliente para
Introdução às arquiteturas paralelas e taxonomia de Flynn
 Introdução às arquiteturas paralelas e taxonomia de Flynn OBJETIVO: definir computação paralela; o modelo de computação paralela desempenhada por computadores paralelos; e exemplos de uso da arquitetura
Introdução às arquiteturas paralelas e taxonomia de Flynn OBJETIVO: definir computação paralela; o modelo de computação paralela desempenhada por computadores paralelos; e exemplos de uso da arquitetura
Programação distribuída e paralela (C. Geyer) RPC 1
 RPC 1") Programação distribuída e paralela (C. Geyer) RPC 1 Autores C. Geyer Local II-UFRGS Versão v6 2008-2 Disciplinas SOII Programação distribuída e paralela (C. Geyer) RPC 2 Bibliografia base original dos
Programação distribuída e paralela (C. Geyer) RPC 1 Autores C. Geyer Local II-UFRGS Versão v6 2008-2 Disciplinas SOII Programação distribuída e paralela (C. Geyer) RPC 2 Bibliografia base original dos
Sistemas Operacionais
 Sistemas Operacionais Aula 3 Software Prof.: Edilberto M. Silva http://www.edilms.eti.br SO - Prof. Edilberto Silva Barramento Sistemas Operacionais Interliga os dispositivos de E/S (I/O), memória principal
Sistemas Operacionais Aula 3 Software Prof.: Edilberto M. Silva http://www.edilms.eti.br SO - Prof. Edilberto Silva Barramento Sistemas Operacionais Interliga os dispositivos de E/S (I/O), memória principal
Sistemas Operacionais
 Sistemas Operacionais Gerência de processos Controle e descrição de processos Edson Moreno edson.moreno@pucrs.br http://www.inf.pucrs.br/~emoreno Sumário Representação e controle de processos pelo SO Estrutura
Sistemas Operacionais Gerência de processos Controle e descrição de processos Edson Moreno edson.moreno@pucrs.br http://www.inf.pucrs.br/~emoreno Sumário Representação e controle de processos pelo SO Estrutura
Computação por Passagem de Mensagens
 Computação por Passagem de Mensagens Programação por passagem de mensagens Programação de multiprocessadores conectados por rede pode ser realizada: criando-se uma linguagem de programação paralela especial
Computação por Passagem de Mensagens Programação por passagem de mensagens Programação de multiprocessadores conectados por rede pode ser realizada: criando-se uma linguagem de programação paralela especial
Interconexão de redes locais. Repetidores. Pontes (Bridges) Hubs. Pontes (Bridges) Pontes (Bridges) Existência de diferentes padrões de rede
 Hubs. Pontes (Bridges) Pontes (Bridges) Existência de diferentes padrões de rede") Interconexão de redes locais Existência de diferentes padrões de rede necessidade de conectá-los Interconexão pode ocorrer em diferentes âmbitos LAN-LAN LAN: gerente de um determinado setor de uma empresa
Interconexão de redes locais Existência de diferentes padrões de rede necessidade de conectá-los Interconexão pode ocorrer em diferentes âmbitos LAN-LAN LAN: gerente de um determinado setor de uma empresa
Organização e Arquitetura de Computadores I. de Computadores
 Universidade Federal de Campina Grande Departamento de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de I Organização Básica B de (Parte V, Complementar)
Universidade Federal de Campina Grande Departamento de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de I Organização Básica B de (Parte V, Complementar)
Introdução. O que vimos. Infraestrutura de Software. (cont.) História dos Sistemas Operacionais. O que vimos 12/03/2012. Primeira geração: 1945-1955
 História dos Sistemas Operacionais. O que vimos 12/03/2012. Primeira geração: 1945-1955") O que vimos Infraestrutura de Software Introdução (cont.) Complexidade do computador moderno, do ponto de vista do hardware Necessidade de abstrações software Sistema computacional em camadas SO como uma
O que vimos Infraestrutura de Software Introdução (cont.) Complexidade do computador moderno, do ponto de vista do hardware Necessidade de abstrações software Sistema computacional em camadas SO como uma
FBV - Linguagem de Programação II. Um pouco sobre Java
 FBV - Linguagem de Programação II Um pouco sobre Java História 1992: um grupo de engenheiros da Sun Microsystems desenvolve uma linguagem para pequenos dispositivos, batizada de Oak Desenvolvida com base
FBV - Linguagem de Programação II Um pouco sobre Java História 1992: um grupo de engenheiros da Sun Microsystems desenvolve uma linguagem para pequenos dispositivos, batizada de Oak Desenvolvida com base
Algoritmos e Programação (Prática) Profa. Andreza Leite andreza.leite@univasf.edu.br
 Profa. Andreza Leite andreza.leite@univasf.edu.br") (Prática) Profa. Andreza Leite andreza.leite@univasf.edu.br Introdução O computador como ferramenta indispensável: Faz parte das nossas vidas; Por si só não faz nada de útil; Grande capacidade de resolução
(Prática) Profa. Andreza Leite andreza.leite@univasf.edu.br Introdução O computador como ferramenta indispensável: Faz parte das nossas vidas; Por si só não faz nada de útil; Grande capacidade de resolução
ESTUDO DE CASO WINDOWS VISTA
 ESTUDO DE CASO WINDOWS VISTA História Os sistemas operacionais da Microsoft para PCs desktop e portáteis e para servidores podem ser divididos em 3 famílias: MS-DOS Windows baseado em MS-DOS Windows baseado
ESTUDO DE CASO WINDOWS VISTA História Os sistemas operacionais da Microsoft para PCs desktop e portáteis e para servidores podem ser divididos em 3 famílias: MS-DOS Windows baseado em MS-DOS Windows baseado
Figura 01 Kernel de um Sistema Operacional
 01 INTRODUÇÃO 1.5 ESTRUTURA DOS SISTEMAS OPERACIONAIS O Sistema Operacional é formado por um Conjunto de rotinas (denominado de núcleo do sistema ou kernel) que oferece serviços aos usuários e suas aplicações
01 INTRODUÇÃO 1.5 ESTRUTURA DOS SISTEMAS OPERACIONAIS O Sistema Operacional é formado por um Conjunto de rotinas (denominado de núcleo do sistema ou kernel) que oferece serviços aos usuários e suas aplicações
Notas da Aula 15 - Fundamentos de Sistemas Operacionais
 Notas da Aula 15 - Fundamentos de Sistemas Operacionais 1. Software de Entrada e Saída: Visão Geral Uma das tarefas do Sistema Operacional é simplificar o acesso aos dispositivos de hardware pelos processos
Notas da Aula 15 - Fundamentos de Sistemas Operacionais 1. Software de Entrada e Saída: Visão Geral Uma das tarefas do Sistema Operacional é simplificar o acesso aos dispositivos de hardware pelos processos
Sistemas Distribuídos
 Sistemas Distribuídos LICENCIATURA EM COMPUTAÇÃO Prof. Adriano Avelar Site: www.adrianoavelar.com Email: eam.avelar@gmail.com Mecanismos de Comunicação Voltando ao exemplo da calculadora... Rede local
Sistemas Distribuídos LICENCIATURA EM COMPUTAÇÃO Prof. Adriano Avelar Site: www.adrianoavelar.com Email: eam.avelar@gmail.com Mecanismos de Comunicação Voltando ao exemplo da calculadora... Rede local
Sistemas Operacionais
 Sistemas Operacionais Sistemas de Entrada/Saída Princípios de Software Sistema de Entrada/Saída Princípios de Software Tratadores (Manipuladores) de Interrupções Acionadores de Dispositivos (Device Drivers)
Sistemas Operacionais Sistemas de Entrada/Saída Princípios de Software Sistema de Entrada/Saída Princípios de Software Tratadores (Manipuladores) de Interrupções Acionadores de Dispositivos (Device Drivers)
Sistemas Operacionais. Prof. M.Sc. Sérgio Teixeira. Aula 05 Estrutura e arquitetura do SO Parte 1. Cursos de Computação
 Cursos de Computação Sistemas Operacionais Prof. M.Sc. Sérgio Teixeira Aula 05 Estrutura e arquitetura do SO Parte 1 Referência: MACHADO, F.B. ; MAIA, L.P. Arquitetura de Sistemas Operacionais. 4.ed. LTC,
Cursos de Computação Sistemas Operacionais Prof. M.Sc. Sérgio Teixeira Aula 05 Estrutura e arquitetura do SO Parte 1 Referência: MACHADO, F.B. ; MAIA, L.P. Arquitetura de Sistemas Operacionais. 4.ed. LTC,
Multiprocessamento. Multiprocessadores com memória distribuída (multicomputador)
") Multiprocessamento Multiprocessadores com memória distribuída (multicomputador) Conjunto de processadores, cada qual com sua memória local Processadores se comunicam por troca de mensagens, via rede de
Multiprocessamento Multiprocessadores com memória distribuída (multicomputador) Conjunto de processadores, cada qual com sua memória local Processadores se comunicam por troca de mensagens, via rede de
Sistemas Operacionais Aula 06: Threads. Ezequiel R. Zorzal ezorzal@unifesp.br www.ezequielzorzal.com
 Sistemas Operacionais Aula 06: Threads Ezequiel R. Zorzal ezorzal@unifesp.br www.ezequielzorzal.com Objetivos Introduzir o conceito de thread Discutir as APIs das bibliotecas de threads Pthreads, Win32
Sistemas Operacionais Aula 06: Threads Ezequiel R. Zorzal ezorzal@unifesp.br www.ezequielzorzal.com Objetivos Introduzir o conceito de thread Discutir as APIs das bibliotecas de threads Pthreads, Win32
Sistemas Operativos. Threads. 3º ano - ESI e IGE (2011/2012) Engenheiro Anilton Silva Fernandes (afernandes@unipiaget.cv)
 Engenheiro Anilton Silva Fernandes (afernandes@unipiaget.cv)") Sistemas Operativos Threads 3º ano - ESI e IGE (2011/2012) Engenheiro Anilton Silva Fernandes (afernandes@unipiaget.cv) Dos Processos para os Threads O conceito de thread foi introduzido na tentativa de
Sistemas Operativos Threads 3º ano - ESI e IGE (2011/2012) Engenheiro Anilton Silva Fernandes (afernandes@unipiaget.cv) Dos Processos para os Threads O conceito de thread foi introduzido na tentativa de
Hardware (Nível 0) Organização. Interface de Máquina (IM) Interface Interna de Microprogramação (IIMP)
 Organização. Interface de Máquina (IM) Interface Interna de Microprogramação (IIMP)") Hardware (Nível 0) Organização O AS/400 isola os usuários das características do hardware através de uma arquitetura de camadas. Vários modelos da família AS/400 de computadores de médio porte estão disponíveis,
Hardware (Nível 0) Organização O AS/400 isola os usuários das características do hardware através de uma arquitetura de camadas. Vários modelos da família AS/400 de computadores de médio porte estão disponíveis,
Capítulo 8. Sistemas com Múltiplos Processadores. 8.1 Multiprocessadores 8.2 Multicomputadores 8.3 Sistemas distribuídos
 Capítulo 8 Sistemas com Múltiplos Processadores 8.1 Multiprocessadores 8.2 Multicomputadores 8.3 Sistemas distribuídos 1 Sistemas Multiprocessadores Necessidade contínua de computadores mais rápidos modelo
Capítulo 8 Sistemas com Múltiplos Processadores 8.1 Multiprocessadores 8.2 Multicomputadores 8.3 Sistemas distribuídos 1 Sistemas Multiprocessadores Necessidade contínua de computadores mais rápidos modelo
Programação de Computadores III
 Programação de Computadores III Introdução a Linguagens de Programação Professor Leandro Augusto Frata Fernandes laffernandes@ic.uff.br Material disponível em http://www.ic.uff.br/~laffernandes/teaching/2013.1/tcc-00.157
Programação de Computadores III Introdução a Linguagens de Programação Professor Leandro Augusto Frata Fernandes laffernandes@ic.uff.br Material disponível em http://www.ic.uff.br/~laffernandes/teaching/2013.1/tcc-00.157
IFPE. Disciplina: Sistemas Operacionais. Prof. Anderson Luiz Moreira
 IFPE Disciplina: Sistemas Operacionais Prof. Anderson Luiz Moreira SERVIÇOS OFERECIDOS PELOS SOS 1 Introdução O SO é formado por um conjunto de rotinas (procedimentos) que oferecem serviços aos usuários
IFPE Disciplina: Sistemas Operacionais Prof. Anderson Luiz Moreira SERVIÇOS OFERECIDOS PELOS SOS 1 Introdução O SO é formado por um conjunto de rotinas (procedimentos) que oferecem serviços aos usuários
Processos. Adão de Melo Neto
 Processos Adão de Melo Neto 1 EXECUTE O SEGUINTE Baixa a aula dos dias 20 MAR 15 e 08 MAI 15 e salve no computador. Feche o browser Inicialize o vmware player e inicialize a máquina virtual ubuntu Inicialize
Processos Adão de Melo Neto 1 EXECUTE O SEGUINTE Baixa a aula dos dias 20 MAR 15 e 08 MAI 15 e salve no computador. Feche o browser Inicialize o vmware player e inicialize a máquina virtual ubuntu Inicialize
Arquiteturas RISC. (Reduced Instructions Set Computers)
") Arquiteturas RISC (Reduced Instructions Set Computers) 1 INOVAÇÕES DESDE O SURGIMENTO DO COMPU- TADOR DE PROGRAMA ARMAZENADO (1950)! O conceito de família: desacoplamento da arquitetura de uma máquina
Arquiteturas RISC (Reduced Instructions Set Computers) 1 INOVAÇÕES DESDE O SURGIMENTO DO COMPU- TADOR DE PROGRAMA ARMAZENADO (1950)! O conceito de família: desacoplamento da arquitetura de uma máquina
Sistemas Distribuídos: Conceitos e Projeto Threads e Migração de Processos
 Sistemas Distribuídos: Conceitos e Projeto Threads e Migração de Processos Francisco José da Silva e Silva Laboratório de Sistemas Distribuídos (LSD) Departamento de Informática / UFMA http://www.lsd.deinf.ufma.br
Sistemas Distribuídos: Conceitos e Projeto Threads e Migração de Processos Francisco José da Silva e Silva Laboratório de Sistemas Distribuídos (LSD) Departamento de Informática / UFMA http://www.lsd.deinf.ufma.br
Linguagens de. Aula 02. Profa Cristiane Koehler cristiane.koehler@canoas.ifrs.edu.br
 Linguagens de Programação III Aula 02 Profa Cristiane Koehler cristiane.koehler@canoas.ifrs.edu.br Linguagens de Programação Técnica de comunicação padronizada para enviar instruções a um computador. Assim
Linguagens de Programação III Aula 02 Profa Cristiane Koehler cristiane.koehler@canoas.ifrs.edu.br Linguagens de Programação Técnica de comunicação padronizada para enviar instruções a um computador. Assim
} Monolíticas Aplicações em um computador centralizado. } Em Rede Aplicações com comunicação em rede. } Distribuídas Comunicação e cooperação em rede
 Prof. Samuel Souza } Monolíticas Aplicações em um computador centralizado } Em Rede Aplicações com comunicação em rede } Distribuídas Comunicação e cooperação em rede } Aplicações que são funcionalmente
Prof. Samuel Souza } Monolíticas Aplicações em um computador centralizado } Em Rede Aplicações com comunicação em rede } Distribuídas Comunicação e cooperação em rede } Aplicações que são funcionalmente
Organização de Computadores 1
 Organização de Computadores 1 SISTEMA DE INTERCONEXÃO (BARRAMENTOS) Prof. Luiz Gustavo A. Martins Arquitetura de von Newmann Componentes estruturais: Memória Principal Unidade de Processamento Central
Organização de Computadores 1 SISTEMA DE INTERCONEXÃO (BARRAMENTOS) Prof. Luiz Gustavo A. Martins Arquitetura de von Newmann Componentes estruturais: Memória Principal Unidade de Processamento Central
Arquitetura de Computadores. Introdução aos Sistemas Operacionais
 Arquitetura de Computadores Introdução aos Sistemas Operacionais O que é um Sistema Operacional? Programa que atua como um intermediário entre um usuário do computador ou um programa e o hardware. Os 4
Arquitetura de Computadores Introdução aos Sistemas Operacionais O que é um Sistema Operacional? Programa que atua como um intermediário entre um usuário do computador ou um programa e o hardware. Os 4
Um processo sob UNIX ocupa uma área de memória formada basicamente por 3 partes:
 Processos O UNIX é um sistema operacional multitarefa (suporta multiprogramação). Isso significa que ele é capaz de gerenciar a execução simultânea de vários programas. O termo processo é usado para caracterizar
Processos O UNIX é um sistema operacional multitarefa (suporta multiprogramação). Isso significa que ele é capaz de gerenciar a execução simultânea de vários programas. O termo processo é usado para caracterizar
Análises Geração RI (representação intermediária) Código Intermediário
 Código Intermediário") Front-end Análises Geração RI (representação intermediária) Código Intermediário Back-End Geração de código de máquina Sistema Operacional? Conjunto de Instruções do processador? Ambiente de Execução O
Front-end Análises Geração RI (representação intermediária) Código Intermediário Back-End Geração de código de máquina Sistema Operacional? Conjunto de Instruções do processador? Ambiente de Execução O
Equipamentos de Redes. Professor Leonardo Larback
 Equipamentos de Redes Professor Leonardo Larback Componentes de Expansão e Segmentação Pontos de rede localizados à distâncias maiores que o limite estabelecido pela mídia utilizada, o aumento no número
Equipamentos de Redes Professor Leonardo Larback Componentes de Expansão e Segmentação Pontos de rede localizados à distâncias maiores que o limite estabelecido pela mídia utilizada, o aumento no número
Conceitos de Sistemas Operacionais: Chamadas de Sistema. Prof Rafael J. Sandim
 Conceitos de Sistemas Operacionais: Chamadas de Sistema Prof Rafael J. Sandim Conceitos de Sistema Operacional Interface entre o SO e os Programas de usuário é definida pelo conjunto de instruções estendidas
Conceitos de Sistemas Operacionais: Chamadas de Sistema Prof Rafael J. Sandim Conceitos de Sistema Operacional Interface entre o SO e os Programas de usuário é definida pelo conjunto de instruções estendidas
Capacidade = 512 x 300 x 20000 x 2 x 5 = 30.720.000.000 30,72 GB
 Calculando a capacidade de disco: Capacidade = (# bytes/setor) x (méd. # setores/trilha) x (# trilhas/superfície) x (# superfícies/prato) x (# pratos/disco) Exemplo 01: 512 bytes/setor 300 setores/trilha
Calculando a capacidade de disco: Capacidade = (# bytes/setor) x (méd. # setores/trilha) x (# trilhas/superfície) x (# superfícies/prato) x (# pratos/disco) Exemplo 01: 512 bytes/setor 300 setores/trilha
Programação Concorrente Introdução
 Introdução Prof. Eduardo Alchieri (definição) Programação Concorrente Do inglês Concurrent Programming, onde Concurrent signifca "acontecendo ao mesmo tempo" Programação Concorrente é diferente de programação
Introdução Prof. Eduardo Alchieri (definição) Programação Concorrente Do inglês Concurrent Programming, onde Concurrent signifca "acontecendo ao mesmo tempo" Programação Concorrente é diferente de programação
Camadas de Serviço de Hardware e Software em Sistemas Distribuídos. Introdução. Um Serviço Provido por Múltiplos Servidores
 Camadas de Serviço de Hardware e Software em Sistemas Distribuídos Arquiteutra de Sistemas Distribuídos Introdução Applications, services Adaptação do conjunto de slides do livro Distributed Systems, Tanembaum,
Camadas de Serviço de Hardware e Software em Sistemas Distribuídos Arquiteutra de Sistemas Distribuídos Introdução Applications, services Adaptação do conjunto de slides do livro Distributed Systems, Tanembaum,
Instruções para uso do MPI - Relatório Técnico -
 Universidade de Passo Fundo Instituto de Ciências Exatas e Geociências Curso de Ciência da Computação Instruções para uso do MPI - Relatório Técnico - ComPaDi Grupo de Pesquisa em Computação Paralela e
Universidade de Passo Fundo Instituto de Ciências Exatas e Geociências Curso de Ciência da Computação Instruções para uso do MPI - Relatório Técnico - ComPaDi Grupo de Pesquisa em Computação Paralela e
Edeyson Andrade Gomes
 Sistemas Operacionais Conceitos de Arquitetura Edeyson Andrade Gomes www.edeyson.com.br Roteiro da Aula Máquinas de Níveis Revisão de Conceitos de Arquitetura 2 Máquina de Níveis Máquina de níveis Computador
Sistemas Operacionais Conceitos de Arquitetura Edeyson Andrade Gomes www.edeyson.com.br Roteiro da Aula Máquinas de Níveis Revisão de Conceitos de Arquitetura 2 Máquina de Níveis Máquina de níveis Computador
Exemplo de Arquitetura: Cliente/Servidor com Mestre e Escravos. Interface em IDL. Dynamic Invocation Interface. Exemplo invocação DII em Java
 Exemplo de Arquitetura: Cliente/Servidor com Mestre e s Arquitetura Mestre- Speed-up / Cliente Mestre Prof João Paulo A Almeida (jpalmeida@infufesbr) Cliente 2009/01 - INF02799 Com alguns slides de Parallel
Exemplo de Arquitetura: Cliente/Servidor com Mestre e s Arquitetura Mestre- Speed-up / Cliente Mestre Prof João Paulo A Almeida (jpalmeida@infufesbr) Cliente 2009/01 - INF02799 Com alguns slides de Parallel
Gerência de Entrada/Saída
 Gerência de Entrada/Saída Prof Clodoaldo Ap Moraes Lima 1 Princípios básicos de hardware Periférico é um dispositivo conectado a um computador de forma a possibilitar sua interação com o mundo externo
Gerência de Entrada/Saída Prof Clodoaldo Ap Moraes Lima 1 Princípios básicos de hardware Periférico é um dispositivo conectado a um computador de forma a possibilitar sua interação com o mundo externo
SISTEMAS OPERACIONAIS ABERTOS Prof. Ricardo Rodrigues Barcelar http://www.ricardobarcelar.com
 - Aula 2-1. PRINCÍPIOS DE SOFTWARE DE ENTRADA E SAÍDA (E/S) As metas gerais do software de entrada e saída é organizar o software como uma série de camadas, com as mais baixas preocupadas em esconder as
- Aula 2-1. PRINCÍPIOS DE SOFTWARE DE ENTRADA E SAÍDA (E/S) As metas gerais do software de entrada e saída é organizar o software como uma série de camadas, com as mais baixas preocupadas em esconder as
BARRAMENTO DO SISTEMA
 BARRAMENTO DO SISTEMA Memória Principal Processador Barramento local Memória cachê/ ponte Barramento de sistema SCSI FireWire Dispositivo gráfico Controlador de vídeo Rede Local Barramento de alta velocidade
BARRAMENTO DO SISTEMA Memória Principal Processador Barramento local Memória cachê/ ponte Barramento de sistema SCSI FireWire Dispositivo gráfico Controlador de vídeo Rede Local Barramento de alta velocidade
Sistemas Operacionais
 Sistemas Operacionais Prof. Jó Ueyama Apresentação baseada nos slides da Profa. Kalinka Castelo Branco, do Prof. Dr. Antônio Carlos Sementille e da Profa. Dra. Luciana A. F. Martimiano e nas transparências
Sistemas Operacionais Prof. Jó Ueyama Apresentação baseada nos slides da Profa. Kalinka Castelo Branco, do Prof. Dr. Antônio Carlos Sementille e da Profa. Dra. Luciana A. F. Martimiano e nas transparências
Arquitetura de Sistemas Operacionais Machado/Maia. Arquitetura de Sistemas
 Arquitetura de Sistemas Operacionais Capítulo 4 Estrutura do Sistema Operacional Cap. 4 Estrutura do Sistema 1 Sistemas Operacionais Pitágoras Fadom Divinópolis Material Utilizado na disciplina Sistemas
Arquitetura de Sistemas Operacionais Capítulo 4 Estrutura do Sistema Operacional Cap. 4 Estrutura do Sistema 1 Sistemas Operacionais Pitágoras Fadom Divinópolis Material Utilizado na disciplina Sistemas
Figura 1 Taxas de transmissão entre as redes
 Conceitos de Redes Locais A função básica de uma rede local (LAN) é permitir a distribuição da informação e a automatização das funções de negócio de uma organização. As principais aplicações que requerem
Conceitos de Redes Locais A função básica de uma rede local (LAN) é permitir a distribuição da informação e a automatização das funções de negócio de uma organização. As principais aplicações que requerem
Sistema Operacional Correção - Exercício de Revisão
 Prof. Kleber Rovai 1º TSI 22/03/2012 Sistema Operacional Correção - Exercício de Revisão 1. Como seria utilizar um computador sem um sistema operacional? Quais são suas duas principais funções? Não funcionaria.
Prof. Kleber Rovai 1º TSI 22/03/2012 Sistema Operacional Correção - Exercício de Revisão 1. Como seria utilizar um computador sem um sistema operacional? Quais são suas duas principais funções? Não funcionaria.
REDES DE COMPUTADORES
 REDES DE COMPUTADORES Rede é um conjunto de módulos processadores capazes de trocar informações e compartilhar recursos. O tipo de rede é definido pela sua área de abrangência, podemos classificar as redes
REDES DE COMPUTADORES Rede é um conjunto de módulos processadores capazes de trocar informações e compartilhar recursos. O tipo de rede é definido pela sua área de abrangência, podemos classificar as redes
Sistemas Distribuídos. Professora: Ana Paula Couto DCC 064
 Sistemas Distribuídos Professora: Ana Paula Couto DCC 064 Questões Em uma rede de sobreposição (overlay), mensagens são roteadas de acordo com a topologia da sobreposição. Qual uma importante desvantagem
Sistemas Distribuídos Professora: Ana Paula Couto DCC 064 Questões Em uma rede de sobreposição (overlay), mensagens são roteadas de acordo com a topologia da sobreposição. Qual uma importante desvantagem
SISTEMAS DISTRIBUÍDOS
 SISTEMAS DISTRIBUÍDOS Modelo cliente e servidor Slide 2 Nielsen C. Damasceno Modelos Cliente - Servidor A principal diferença entre um sistema centralizado e um sistema distribuído está na comunicação
SISTEMAS DISTRIBUÍDOS Modelo cliente e servidor Slide 2 Nielsen C. Damasceno Modelos Cliente - Servidor A principal diferença entre um sistema centralizado e um sistema distribuído está na comunicação
Sistemas Distribuídos Capítulos 3 e 4 - Aula 4
 Sistemas Distribuídos Capítulos 3 e 4 - Aula 4 Aula passada Threads Threads em SDs Processos Clientes Processos Servidores Aula de hoje Clusters de Servidores Migração de Código Comunicação (Cap. 4) Fundamentos
Sistemas Distribuídos Capítulos 3 e 4 - Aula 4 Aula passada Threads Threads em SDs Processos Clientes Processos Servidores Aula de hoje Clusters de Servidores Migração de Código Comunicação (Cap. 4) Fundamentos
Universidade de Brasília
 Universidade de Brasília Introdução a Microinformática Turma H Redes e Internet Giordane Lima Porque ligar computadores em Rede? Compartilhamento de arquivos; Compartilhamento de periféricos; Mensagens
Universidade de Brasília Introdução a Microinformática Turma H Redes e Internet Giordane Lima Porque ligar computadores em Rede? Compartilhamento de arquivos; Compartilhamento de periféricos; Mensagens
Prof. Wilton O. Ferreira Universidade Federal Rural de Pernambuco UFRPE 1º Semestre / 2012
 Prof. Wilton O. Ferreira Universidade Federal Rural de Pernambuco UFRPE 1º Semestre / 2012 As redes de computadores possibilitam que indivíduos possam trabalhar em equipes, compartilhando informações,
Prof. Wilton O. Ferreira Universidade Federal Rural de Pernambuco UFRPE 1º Semestre / 2012 As redes de computadores possibilitam que indivíduos possam trabalhar em equipes, compartilhando informações,
REDE DE COMPUTADORES
 REDE DE COMPUTADORES Tipos de classificação das redes de acordo com sua topologia Prof. Airton Ribeiro de Sousa E-mail: airton.ribeiros@gmail.com 1 Ao longo da historia das redes, varias topologias foram
REDE DE COMPUTADORES Tipos de classificação das redes de acordo com sua topologia Prof. Airton Ribeiro de Sousa E-mail: airton.ribeiros@gmail.com 1 Ao longo da historia das redes, varias topologias foram
Algoritmo. Prof. Anderson Almeida Ferreira. Agradeço ao prof. Guilherme Tavares de Assis por fornecer slides que fazem parte desta apresentação
 1 Algoritmo Prof. Anderson Almeida Ferreira Agradeço ao prof. Guilherme Tavares de Assis por fornecer slides que fazem parte desta apresentação Desenvolvimento de programas 2 Análise do problema Desenvolvimento
1 Algoritmo Prof. Anderson Almeida Ferreira Agradeço ao prof. Guilherme Tavares de Assis por fornecer slides que fazem parte desta apresentação Desenvolvimento de programas 2 Análise do problema Desenvolvimento
Aula 3. Sistemas Operacionais. Prof: Carlos Eduardo de Carvalho Dantas (carloseduardoxpto@gmail.com) http://carloseduardoxp.wordpress.
 http://carloseduardoxp.wordpress.") Sistemas Operacionais Aula 3 Prof: Carlos Eduardo de Carvalho Dantas (carloseduardoxpto@gmail.com) http://carloseduardoxp.wordpress.com Nunca cone em um computador que você não pode jogar pela janela.
Sistemas Operacionais Aula 3 Prof: Carlos Eduardo de Carvalho Dantas (carloseduardoxpto@gmail.com) http://carloseduardoxp.wordpress.com Nunca cone em um computador que você não pode jogar pela janela.
Máquinas Multiníveis
 Infra-Estrutura de Hardware Máquinas Multiníveis Prof. Edilberto Silva www.edilms.eti.br edilms@yahoo.com Sumário Conceitos básicos Classificação de arquiteturas Tendências da tecnologia Família Pentium
Infra-Estrutura de Hardware Máquinas Multiníveis Prof. Edilberto Silva www.edilms.eti.br edilms@yahoo.com Sumário Conceitos básicos Classificação de arquiteturas Tendências da tecnologia Família Pentium
Sistemas Operacionais 2014 Introdução. Alexandre Augusto Giron alexandre.a.giron@gmail.com
 Sistemas Operacionais 2014 Introdução Alexandre Augusto Giron alexandre.a.giron@gmail.com Roteiro Sistemas Operacionais Histórico Estrutura de SO Principais Funções do SO Interrupções Chamadas de Sistema
Sistemas Operacionais 2014 Introdução Alexandre Augusto Giron alexandre.a.giron@gmail.com Roteiro Sistemas Operacionais Histórico Estrutura de SO Principais Funções do SO Interrupções Chamadas de Sistema
Introdução a Threads Java
 Introdução a Threads Java Prof. Gerson Geraldo Homrich Cavalheiro Universidade Federal de Pelotas Departamento de Informática Instituto de Física e Matemática Pelotas RS Brasil http://gersonc.anahy.org
Introdução a Threads Java Prof. Gerson Geraldo Homrich Cavalheiro Universidade Federal de Pelotas Departamento de Informática Instituto de Física e Matemática Pelotas RS Brasil http://gersonc.anahy.org
Paralelismo. Computadores de alto-desempenho são utilizados em diversas áreas:
 Computadores de alto-desempenho são utilizados em diversas áreas: - análise estrutural; - previsão de tempo; - exploração de petróleo; - pesquisa em fusão de energia; - diagnóstico médico; - simulações
Computadores de alto-desempenho são utilizados em diversas áreas: - análise estrutural; - previsão de tempo; - exploração de petróleo; - pesquisa em fusão de energia; - diagnóstico médico; - simulações
Capítulo 2 Processos e Threads Prof. Fernando Freitas
 slide 1 Capítulo 2 Processos e Threads Prof. Fernando Freitas Material adaptado de: TANENBAUM, Andrew S. Sistemas Operacionais Modernos. 3ª edição. Disponível em: http://www.prenhall.com/tanenbaum_br slide
slide 1 Capítulo 2 Processos e Threads Prof. Fernando Freitas Material adaptado de: TANENBAUM, Andrew S. Sistemas Operacionais Modernos. 3ª edição. Disponível em: http://www.prenhall.com/tanenbaum_br slide
SISTEMAS OPERACIONAIS CAPÍTULO 3 CONCORRÊNCIA
 SISTEMAS OPERACIONAIS CAPÍTULO 3 CONCORRÊNCIA 1. INTRODUÇÃO O conceito de concorrência é o princípio básico para o projeto e a implementação dos sistemas operacionais multiprogramáveis. O sistemas multiprogramáveis
SISTEMAS OPERACIONAIS CAPÍTULO 3 CONCORRÊNCIA 1. INTRODUÇÃO O conceito de concorrência é o princípio básico para o projeto e a implementação dos sistemas operacionais multiprogramáveis. O sistemas multiprogramáveis
SISTEMAS OPERACIONAIS
 SISTEMAS OPERACIONAIS Tópico 4 Estrutura do Sistema Operacional Prof. Rafael Gross prof.rafaelgross@fatec.sp.gov.br FUNÇÕES DO NUCLEO As principais funções do núcleo encontradas na maioria dos sistemas
SISTEMAS OPERACIONAIS Tópico 4 Estrutura do Sistema Operacional Prof. Rafael Gross prof.rafaelgross@fatec.sp.gov.br FUNÇÕES DO NUCLEO As principais funções do núcleo encontradas na maioria dos sistemas
Conceitos Básicos de C
 Conceitos Básicos de C Bibliografia Problem Solving & Program design in C, Jeri R. Hanly e Elliot B. Kpffman, 3 a edição Data Structures and Algorithm Analysis in C, Mark Allen Weiss, 2 a edição, Addison-Wesley,
Conceitos Básicos de C Bibliografia Problem Solving & Program design in C, Jeri R. Hanly e Elliot B. Kpffman, 3 a edição Data Structures and Algorithm Analysis in C, Mark Allen Weiss, 2 a edição, Addison-Wesley,
Sistemas Operacionais
 Sistemas Operacionais Aula 07 Arquitetura de Sistemas Operacionais Prof. Maxwell Anderson www.maxwellanderson.com.br Introdução Conceitos já vistos em aulas anteriores: Definição de Sistemas Operacionais
Sistemas Operacionais Aula 07 Arquitetura de Sistemas Operacionais Prof. Maxwell Anderson www.maxwellanderson.com.br Introdução Conceitos já vistos em aulas anteriores: Definição de Sistemas Operacionais
Computaçãoparalelae distribuída
 Computaçãoparalelae distribuída Computaçãoparalelacom a utilizaçãodo PVM (Parallel Virtual Machine) Prof. Dr. Luciano José Senger Parallel Virtual Machine (PVM) O programador decompõe o programa em programas
Computaçãoparalelae distribuída Computaçãoparalelacom a utilizaçãodo PVM (Parallel Virtual Machine) Prof. Dr. Luciano José Senger Parallel Virtual Machine (PVM) O programador decompõe o programa em programas
Introdução à Arquitetura de Computadores
 1 Introdução à Arquitetura de Computadores Hardware e software Organização de um computador: Processador: registradores, ALU, unidade de controle Memórias Dispositivos de E/S Barramentos Linguagens de
1 Introdução à Arquitetura de Computadores Hardware e software Organização de um computador: Processador: registradores, ALU, unidade de controle Memórias Dispositivos de E/S Barramentos Linguagens de
LP II Estrutura de Dados. Introdução e Linguagem C. Prof. José Honorato F. Nunes honorato.nunes@ifbaiano.bonfim.edu.br
 LP II Estrutura de Dados Introdução e Linguagem C Prof. José Honorato F. Nunes honorato.nunes@ifbaiano.bonfim.edu.br Resumo da aula Considerações Gerais Introdução a Linguagem C Variáveis e C Tipos de
LP II Estrutura de Dados Introdução e Linguagem C Prof. José Honorato F. Nunes honorato.nunes@ifbaiano.bonfim.edu.br Resumo da aula Considerações Gerais Introdução a Linguagem C Variáveis e C Tipos de
REDES DE COMPUTADORES Prof. Ricardo Rodrigues Barcelar http://www.ricardobarcelar.com.br
 - Aula Complementar - EQUIPAMENTOS DE REDE 1. Repetidor (Regenerador do sinal transmitido) É mais usado nas topologias estrela e barramento. Permite aumentar a extensão do cabo e atua na camada física
- Aula Complementar - EQUIPAMENTOS DE REDE 1. Repetidor (Regenerador do sinal transmitido) É mais usado nas topologias estrela e barramento. Permite aumentar a extensão do cabo e atua na camada física
Visão do Usuário da DSM
 Memória Compartilhada Distribuída Visão Geral Implementação Produtos 1 Memória Compartilhada Distribuída Mecanismos tradicionais de comunicação via RPC/RMI ou mensagens deixam explícitas as interações
Memória Compartilhada Distribuída Visão Geral Implementação Produtos 1 Memória Compartilhada Distribuída Mecanismos tradicionais de comunicação via RPC/RMI ou mensagens deixam explícitas as interações