Introdução ao Hardware e ao Software Paralelos
|
|
|
- Arthur Caldas
- 4 Há anos
- Visualizações:
Transcrição
1 Introdução ao Hardware e ao Software Paralelos MCZA Programação Paralela Emilio Francesquini e.francesquini@ufabc.edu.br 2020.Q1 Centro de Matemática, Computação e Cognição Universidade Federal do ABC
2 Disclaimer Estes slides foram preparados para o curso de Programação Paralela na UFABC. Estes slides são baseados naqueles produzidos por Peter Pacheco como parte do livro An Introduction to Parallel Programming disponíveis em: Este material pode ser usado livremente desde que sejam mantidos, além deste aviso, os créditos aos autores e instituições. 1
3 Fundamentos

4 Hardware e software sequenciais 2
5 Arquitetura de Von Neumann CPU ALU registers Control registers Interconnect Address Contents Main memory 3
 e seu conteúdo")
6 Memória Principal É uma coleção de posições, cada uma capaz de armazenar tanto instruções como dados Cada posição consiste de um endereço (usado para acessar aquela posição) e seu conteúdo 4
 A Unidade Lógica e Aritimética - ALU (Arithmetic and Logic Unit) é responsável por, de fato, executar as instruções.")
7 Unidade Central de Processamento CPU A CPU (Central Processing Unit) pode ser dividida em duas partes Unidade de controle (Control Unit) é responsável por decidir quais instruções devem ser executadas. (O chefe) A Unidade Lógica e Aritimética - ALU (Arithmetic and Logic Unit) é responsável por, de fato, executar as instruções. (O Trabalhador) 5
 Armazena o endereço da")
 Barramento (Bus) hardware que conecta a CPU à memória e aos demais")
8 Terminologia Chave Registrador (Register) Memória com altíssimo desempenho, parte integrada à CPU Contador de Programa - PC (Program Counter) Armazena o endereço da próxima instrução a ser executada Processadores Intel usam o nome Instruction Pointer (IP) Barramento (Bus) hardware que conecta a CPU à memória e aos demais dispositivos. 6

9 7

10 8

11 O Gargalo da Arquitetura de von Neumann 9
12 Um processo do SO Um processo do sistema operacional - SO (operating system) é um programa que está sendo executado Componentes de um processo O programa em linguagem de máquina Regiões da memória Descritores dos recursos alocados pelo SO ao processo Informações de segurança Informações sobre o estado do processo 10
13 Multitasking Multitasking cria a ilusão de que um processador simples, com apenas um núcleo (core) de processamento, está rodando múltiplos programas simultaneamente Cada processo se reveza no uso do processador (time slice) Quando o tempo alocado a um processo acaba ele é colocado em uma fila e espera novamente pela sua vez. Nestes casos dizemos que o processo está bloqueado (blocked) A entidade responsável por fazer este trabalho é o escalonador (scheduler) do SO 11
14 Threading Threads elementos que compõem um processo Threads permitem os programadores dividirem os seus programas em tarefas virtualmente autônomas e independentes A ideia é de que quando um thread bloqueia por estar esperando um recurso, outro thread estara esperando por sua vez A intenção é promove uma utilização mais otimizada da CPU 12
15 Um processo com duas threads 13
16 Modificações no Modelo de Von Neumann

17 Caching - O Básico Cache Uma coleção de posições de memória que pode ser acessada pelo processador de maneira muito mais rápida que outras posições de memória A cache de uma CPU é tipicamente localizada no mesmo chip ou em uma memória que pode ser acessada muito rapidamente Alguns processadores como o Power8 tem até L4 14
18 Princípio da Localidade O princípio da localidade é uma heurística pela qual os projetistas de hardware esperam que o acesso a uma posição de memória seja seguido por acessos a posições em sua vizinhança Há dois tipos principais de localidade: Localidade Espacial Acessos ocorrerão em posições de memória próximas. Localidade Temporal Acessos ocorrerão em um futuro próximo. As caches de um processador aproveitam-se desses dois casos 15
19 Princípio da Localidade 1 float z[1000]; sum = 0.0; 4 for (i = 0; i < 1000; i++) 5 sum += z[i]; 16

20 Níveis de Cache 17

21 Cache Hit 18

22 Cache Miss 19
23 Alguns dos problemas das caches Quando uma CPU escreve dados na cache, o valor daquele dado pode ficar inconsistente, ou defasado (stale) em relação aos dados na memória principal. write-through os dados são escritos na cache e imediatamente enviados para a memória principal write-back a cache controla os dados armazenados por ela como sujos (dirty). Quando a linha de cache é substituída por uma nova linha a linha suja é enviada para a memória principal. 20
24 Cache Mappings Full associative, completamente associativa uma nova linha pode ser colocada em qualquer posição da cache. Direct mapped, mapeamento direto cada linha da cache tem uma posição única onde ela pode ser colocada. n-way set associative, associativa de n vias cada linha da cache pode ser colocada em n diferentes posições na cache. 21
")
25 n-way set associative Quando mais de uma linha na mamória pode ser mapeada para diversas posições diferentes, acaba aparecendo a necessidade de definir uma política de substituição (replacement policy/eviction policy para decidir qual das linhas precisa ser substituida (replaced/evicted) 22
26 Exemplo Cache Location Memory Index Fully Assoc Direct Mapped 2-way 0 0, 1, 2, or or 1 1 0, 1, 2, or or 3 2 0, 1, 2, or or 1 3 0, 1, 2, or or 3 4 0, 1, 2, or or 1 5 0, 1, 2, or or 3 6 0, 1, 2, or or 1 7 0, 1, 2, or or 3 8 0, 1, 2, or or 1 9 0, 1, 2, or or , 1, 2, or or , 1, 2, or or , 1, 2, or or , 1, 2, or or , 1, 2, or or , 1, 2, or or 3 Associações de uma memória de 16 linhas a uma cache de 4 linhas. 23
27 Caches e programas double A[MAX][MAX], x[max], y[max];... / Initialize A and x, assign y = 0 /... / First pair of loops / for (i = 0; i < MAX; i++) for (j = 0; j < MAX; j++) y[i] += A[i][j] x[j];... / Assign y = 0 /... Cache Line / Second pair of loops / for (j = 0; j < MAX; j++) 0 for (i = 0; i < MAX; i++) 1 y[i] += A[i][j] x[j]; Elements of A A[0][0] A[0][1] A[0][2] A[0][3] A[1][0] A[1][1] A[1][2] A[1][3] 2 A[2][0] A[2][1] A[2][2] A[2][3] 3 A[3][0] A[3][1] A[3][2] A[3][3] Exemplo: Suponha cache de duas linhas direct mapped. 24
28 Memória Virtual
29 Memória virtual (1) Se executarmos um programa grande o suficiente ou um programa que acesse muitos dados, pode acontecer da memória principal não ser grande o suficiente. A memória virtual funciona como uma cache para o dispositivo de armazenamento secundário. 25
30 Memória virtual (2) A memória virtual explora o princípio de localidade espacial e temporal Mantém apenas as partes ativas de programas em execução na memória 26
31 Memória virtual (3) Swap space - As partes da memória ociosas são transferidas para o espaço de armazenamento secundário Páginas - Blocos de dados/instruções Normalmente são relativamente grandes A maior parte dos sistemas tem um tamanho de páginas fixo que varia entre 4 a 16 kilobytes Alguns sistemas, como o Linux, são capazes de utilizar huge pages, que dependendo do processador, podem ser tão grandes quanto 2 megabytes 27

32 Memória virtual (4) 28
33 Virtual page numbers Quando um programa é compilado, as suas páginas são associadas à números de páginas virtuais Quando um programa é executado, uma tabela que mapeia a página virtual aos endereços físicos é criada Uma tabela de páginas é usada para traduzir um endereço virtual em um endereço físico 29

34 Tabela de páginas 30
35 Translation-lookaside buffer (TLB) O simples uso de uma tabela de tradução de endereços poderia causar uma servera perda de desempenho na execução de um programa A TLB é uma cache especial cujo propósito é acelerar a tradução de endereços no processador 31
36 Translation-lookaside buffer (TLB) A TLB funciona cacheando um pequeno número de entradas na tabela de páginas (tipicamente de 16 a 512) da memória principal em uma memória com um desemepnho superior. Page Fault /Falha de página - Ocorre quando um programa em execução tenta acessar um endereço válido na memória física (pós-tradução) mas que não está mais localizado na memória (foi feita a troca/swap para disco) 32
37 Instruction Level Parallelism (ILP)
38 Instruction Level Parallelism (ILP) Tentativa de melhorar o desempenho de um processador através do uso de mais de uma unidade funcional (FU) A idea é que se mais de uma FU trabalhar ao mesmo tempo pode-se diminuir o tempo total de execução 33
39 Há dois tipos principais de ILP Pipelining - as unidades funcionais são organizadas em estágios. Mutiple issue - múltiplas instruções podem ter a sua execução iniciada ao mesmo tempo 34
40 Pipelining 35

41 Exemplo de pipelining Somar os números e
42 Exemplo de pipelining (2) 1 float x[1000], y[1000], z[1000]; for (i = 0; i < 1000; i++) 4 z[i] = x[ i ] + y[i]; Assuma que cada operação leve um nanossegundo (10 9 s) Este loop vai levar aproximadamente 7000 nanossegundos 37
43 Pipelining (3) Divida o FP adder em 7 unidades funcionais distintas A primeira unidade recupera (fetch) os dois operandos, a segunda unidade compara os expoentes, etc Organize as unidades funcionais de modo que a saida de uma seja a entrada da próxima 38
44 Pipelining (4) 39
45 Pipelining (5) Uma operação de ponto flutuante continua levando 7 nanossegundos Mas agora, 1000 operações de ponto flutuante levam 1006 nanossegundos 40


46 Multiple issue (1) Processadores com multiple issue tem unidades funcionais replicadas e tentam executar simultaneamente diferentes instruções de um programa 41
47 Multiple issue (2) Multiple issue estático - o uso das unidades funcionais é definido em tempo de compilação Multiple issue dinâmico - o uso das unidades funcionais é determinado em tempo de execução Processadores com esta característica são chamados de processadores superescalares 42
48 Especulação (1) Para fazer uso do recurso de multiple issue, o processador precisa achar instruções para serem executadas de maneira simultânea Durante a especulação, o compilador ou o processador chutam a próxima instrução e torcem para dar certo 43

 3 w = x; 4 else 5 w = y; 6 7")
49 Especulação (2) Se o sistema especular errado ele deve desfazer os efeitos de todas as instruções especuladas incorretamente. 1 z = x + y; 2 if (z > 0) 3 w = x; 4 else 5 w = y; 6 7 //Outro exemplo 8 z = x + y; 9 w = *a_p; /* a_p é um ponteiro*/ 44
50 Hardware multithreading (1) Nem sempre há boas oportunidades para a execução simultânea de múltiplos threads Hardware multithreading provê uma solução para os sistemas continuarem a execução e fazer trabalho útil quando a tarefa atualmente sendo executada é stalled (temporariamente impedida de executar) Exemplo: aguardando por um acesso à memória 45
51 Hardware multithreading (2) Grão fino - o processador troca automaticamente de tarefa a cada instrução executada e pula threads que estão stalled Prós: potencial de evitar desperdício de tempo do processador devido a stalls Contras: um thread que estiver pronto para executar uma longa sequência de instruções pode ter que esperar para executar cada uma delas 46
52 Hardware multithreading (3) Grão grosso - o processador só troca os threads caso eles tenham entrado em stall Prós: a troca entre threads não é feita a todo momento Contras: o processador pode entrar em ociosidade em stalls curtos e o custo da troca de contexto entre os threads pode ser maior que o ganho 47
53 Hardware multithreading (3) Simultaneous Multithreading (SMT) - é uma variação do mulithreading de granularidade grossa Permite múltiplos threads fazerem uso de múltiplas unidades funcionais 48
54 Hardware Paralelo

55 Taxonomia de Flynn 49
56 SIMD Paralelismo é alcançado dividindo os dados entre os processadores Aplica a mesma instrução a múltiplos dados Também chamado de paralelismo de dados 50

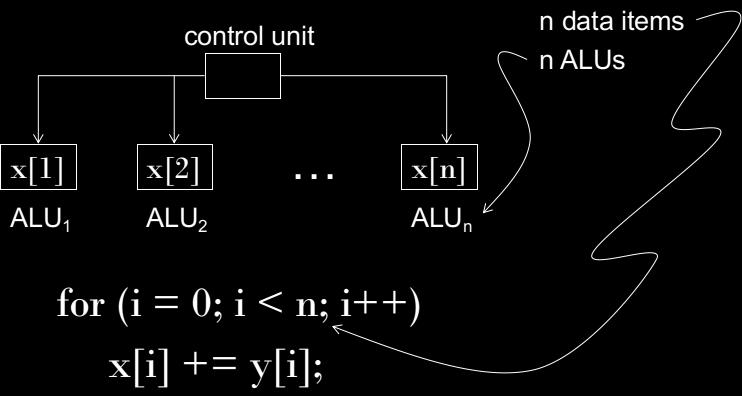
57 SIMD - Exemplo 51

58 SIMD O que ocorre caso não tenhamos ALUs suficientes? Divide-se o trabalho e processa iterativamente Exemplo: 4 ALUs e 15 dados 52
59 SIMD - Desvantagens Todas as ALUs precisam executar a mesma instrução (ou permanecer ociosa) Nos desings mais clássicos, também precisam operar de maneira síncrona As ALUs não têm espaço para armazenamento de instruções Muito eficiente para problemas grandes e paralelos mas não é eficiente para outros tipos de problemas mais complexos 53
60 Processadores vetoriais (1) Operam em arrays ou vetores de dados enquanto processadores convencionais operam em cada um dos dados individualmente (escalares) Registradores vetoriais Capazes de armazenar um vetor de operandos e operar simultaneamente em todos os seus elementos 54
61 Processadores vetoriais (2) Unidades funcionais com pipelines e vetorizadas A mesma operação é aplicada a cada elemento do vetor (ou par de elementos) Instruções vetoriais Operam em vetores em vez de escalares 1 for (i = 0; i < n; i++) 2 x[i] += y [i]; 55
62 Processadores vetoriais (3) Memória interacalada (interleaved) Múltiplos bancos de memória que podem ser acessados de maneira quase que independente Distribuem os elementos de um vetor entre diversos bancos de memória o que diminui o tempo para carregar/armazenar diversos elementos Strided memory access e operações de scatter e gather por hardware O programa acessa elementos de um vetor a intervalos fixos. 56
63 Processadores vetoriais - Vantagens Rápidos Fáceis de se utilizar Compiladores modernos são capazes de extrair vetorização do código automaticamente Também podem avisar sobre códigos que não puderam ser vetorizados e porquê! Alta banda de acesso à memória Usa todos os itens da linha do cache 57
64 Processadores vetoriais - Desvantagens Não são capazes de lidar com estruturas de dados irregulares tão bem quanto outras estruturas de hardware paralelas Tem um limite na sua capacidade de trabalhar com problemas cada vez maiores (limite de escalabilidade) 58
65 Graphic Processing Units (GPU) APIs para geração de gráficos em tempo real usam pontos, linhas, triângulos, para representar o estado de um objeto Um pipeline gráfico converte a representação interna em uma array de pixels que é enviada à tela Vários estágios do pipeline (chamados de shader functions) podem ser programados Tipicamente isto não exige mais do que algumas linhas de código em C 59
66 Graphic Processing Units (GPU) Shader functions também são implicitamente paralelas uma vez que elas podem ser aplicadas a múltiplos elementos simultaneamente no stream gráfico GPUs tipicamente oferecem uma acelaração na execução pelo uso de paralelismo SIMD Contudo a atual geração de GPUs não é, rigorosamente, um sistema SIMD puro 60
67 MIMD Dá suporte a múltiplas linhas de execução de instruções simultâneas Consiste, tipicamente, de um conjunto de processadores (ou cores) totalmente independentes cada qual com a sua própria unidade de controle e ALU 61
68 Sistema com memória compartilhada Um conjunto de processadores autônomos conectados a um sistema de memória por uma rede de interconexão Cada processador pode acessar cada uma das posições de memória Os processadores se comunicam, tipicamente, implicitamente pelo acesso a estruturas de dados compartilhadas na memória 62
69 Sistema com memória compartilhada (2) Os sistemas com memória compartilhada mais comuns oferecem um ou mais processadores multicore Um ou mais cores ou processadores em um único chip 63
70 Sistema com memória compartilhada (2) 64
71 UMA Mulicore System Uniform Memory Access - O tempo para acessar cada uma das posições de memória é sempre o mesmo, independentemente do core ou do endereço 65
72 NUMA Multicore System Non-Uniform Memory Access - O tempo de acesso pode variar entre cada um dos cores ou dependendo do endereço 66
73 Sistemas com memória distribuída Clusters - Modelo mais popular Um conjunto de computadores comuns (com memória compartilhada) Conexão usando redes Nós/Nodos/Nodes de um cluster são cada uma das unidades computacionais ligadas por uma rede de interconexão Também chamados de sistemas híbridos 67
74 Sistemas com memória distribuída 68
75 Redes de interconexão Afetam o desempenho tanto de sistemas distribuídos quanto de memória compartilhada Duas categorias Interconexões de memória compartilhada Interconexões de memória distribuída 69
76 Interconexões de memória compartilhada Barramento / Bus Uma coleção de ligações (fios e cabos) paralelos em conjunto com um hardware que controla o acesso ao barramento As vias de conexão são compartilhadas entre os dispositivos conectados Conforme o número de dispositivos aumenta, também aumenta a contenção e, consequentemente, há uma diminuição no desempenho 70
77 Interconexões de memória compartilhada Interconexão chaveada / Switched interconnect Utiliza chaveadores (switches) para controlar o fluxo e o roteamento dos dados entre os dispositivos Crossbar Permite comunicação simultânea entre vários dispositivos diferentes Mais rápido que barramentos Contudo, o custo é mais elevado do que barramentos 71
78 Crossbar P1 P2 P3 P4 M1 M2 M3 M4 Crossbar conectando 4 processadores e 4 módulos de memória 72
79 Crossbar Switch P1 P2 P3 P4 M1 M2 (i) (ii) M3 M4 ( ) Acesso simultâneo à memória por vários processadores 73
80 Interconexões de memória distribuída Dois grupos Interconexão direta Cada switch é diretamente conectado a um par processador/memória e os switches são conectados uns aos outros Interconexão indireta Os switches podem não estar conectados diretamente a um processador 74
81 Interconexão direta P1 P2 P3 (a) (b) Conexão em (a) anel e (b) toroidal 75
82 Largura da bisseção Medida do número de comunicações simultâneas ou da conectividade Quantas comunicações podem ocorrer ao mesmo tempo através de cada parte? 76
83 Exemplo: Anel A B A B A B B A A B A B A B B A (a) (b) (a) 2 conexões (b) 4 conexões 77
84 Bisseção de uma interconexão toroidal 78
85 Definições Largura de banda / Bandwidth Taxa de transmissão de um link Normalmente dada em megabits ou megabytes por segundo Largura de banda da bisseção Medida da qualidade da rede Em vez de contar o número de links que juntam as duas metades, soma a largura de banda dos links 79
86 Rede completamente conexa Cada switch está conectado a todos os outros switches Impraticável para valores grandes de p Largura de bisseção = p2 4 80
87 Hipercubo Interconexão direta e altamente conectada Construída por indução Um hipercubo unidimensional é um sistema completamente conectado com dois processadores Um hipercubo bidimensional é construído a partir de dois hipercubos unidimensionais pela junção dos switches correspondentes Da mesma maneira, um hipercubo tridimensional é um hipercubo construído a partir de dois hipercubos bidimensionais 81
88 Hipercubo (a) (b) (c) (a) 1D (b) 2D (c) 3D 82
89 Interconexões indiretas Exemplos mais simples de redes de interconexão indiretas Crossbar Omega Network Geralmente são mostradas como redes com links unidirecionais e com uma coleção de processadores, cada um deles com um link de entrada e outro de saída, e uma rede chaveada 83
90 Uma rede indireta genérica Switching Network 84
91 Interconexão Crossbar para memória distribuída 85
92 Omega Network 86
93 Um Switch em uma rede Omega 87
94 Mais algumas definições Para toda troca de dados é importante sabermos quanto tempo que os dados alcancem o seu destino Latência - O tempo que leva entre a origem começar a transmitir os dados e o destino começar a receber o primeiro byte Largura de banda - A taxa pela qual o destinatário recebe os dados após ter começado a receber o primeiro byte 88
95 Tempo de transmissão Tempo de transmissão Tempo = Latência (s) + Tamanho (bytes) / Banda (bytes/s) 89
96 Coerência de cache Core 0 Core 1 Cache 0 Cache 1 Programadores não tem controle algum das caches Conteúdo Política de atualização Interconnect x 2 y1 y0 z1 90
97 Coerência de cache Suponha: y0 mantida privada pelo Core 0 y1 e z1 mantidas privadas pelo Core 1 x = 2; Variável compartilhada Time Core 0 Core 1 0 y0 = x; y1 = 3*x; 1 x = 7; Statement(s) not involving x 2 Statement(s) not involving x z1 = 4*x; y0 termina com 2 y1 termina com 6 z1 termina valendo? 91
98 Snooping Cache Coherence Baseado no fato de que os cores compartilham o barramento Qualquer sinal transmitido no barramento pode ser visto por todos os cores Quando o Core 0 atualiza a sua cópia de x armazenada em sua cache, ele também avisa (broadcast) esta informação no bus Se o Core 1 estiver escutando / snooping o barramento, ele percebe que x foi atualizado e marca a sua cópia local como inválida 92
99 Coerência de cache baseada em diretório Usa uma estrutura de dados chamada diretório que armazena o status de cada uma das linhas de cache Quando uma variável é atualizada, o diretório é consultado e os controladores de cache dos cores que tiverem uma cópia daquela variável em seus caches têm as suas linhas invalidadas 93
100 Software paralelo
101 A batata quente está com o software Mudança na abordagem comum até o início dos anos 2000 Compiladores e software vão ter que por a mão na massa De agora em diante Em programas de memória compartilhada Inicie um único processo e várias threads Threads cuidam das tarefas Em programas de memória distribuída Inicie vários processos Processos cuidam das tarefas 94
102 SPMD - Single Program Multiple Data Um programa SPMD consiste em um executável único que pode se comportar de maneira diferente (como se fossem múltiplos programas) através do uso de condicionais 95
103 Como escrever programas paralelos 1 Divida o trabalho entre os processos/threads De modo que cada processo/thread receba aproximadamente o mesmo tanto de trabalho E de modo que a comunicação seja minimizada 2 Organize o código para que os processos/threads se sincronizem 3 Organize o código para que os processos/threads se comuniquem 96
104 Memória compartilhada Threads dinâmicos Thread principal (master, main) espera por trabalho, cria novos threads, espera a sua conclusão, finaliza Uso eficiente dos recursos, contudo criar e descartar threads é custoso Threads estáticos Pool de threads - Threads são criados e colocados para trabalhar, mas não são descartados até o final da execução Melhor desempenho, mas pode ser uma fonte de desperdício de recursos 97
105 Não-determinismo 98
106 Não-determinismo 1 my_val = Compute_val(my_rank); 2 x += my_val; Time Core 0 Core 1 0 Finish assignment to my val In call to Compute val 1 Load x = 0 into register Finish assignment to my val 2 Load my val = 7 into register Load x = 0 into register 3 Add my val = 7 to x Load my val = 19 into register 4 Store x = 7 Add my val to x 5 Start other work Store x = 19 99
107 Não-determinismo Condições de corrida (race condition) Seção crítica Exclusão mútua Trava de exclusão mútua (mutual exclusion lock, mutex) 100
108 Busy-waiting 1 my_val = Compute_val(my_rank); 2 if (my_rank == 1) 3 while (!ok_for_1); /* Busy wait loop */ 4 x += my_val ; /* Critical section */ 5 if (my_rank == 0) 6 ok_for_1 = true; /* Let thread 1 update x */ 101
109 Passagem de mensagem 1 char message [100]; my_rank = Get_rank(); 4 if (my_rank == 1) { 5 sprintf( message, "Greetings from process 1"); 6 Send(message, MSG_CHAR, 100,0); 7 } else if (my_rank == 0) { 8 Receive(message, MSG_CHAR, 100, 1); 9 printf("process 0 > Received: %s\n", message); 10 } 102
110 PGAS - Partitioned Global Address Space Languages 1 shared int n =...; 2 shared double x[n], y[n]; 3 private int i, my_first_element, my_last_element; 4 my_first_element =...; 5 my_last_element =...; 6 /* Initialize x and y */ for (i = my_first_element; i <= my_last_element; i++) 9 x [i] += y[i]; 103
111 Entrada e Saída Em um programa com memória distribuída, apenas o processo 0 vai acessar a stdin Em um programa com memória compartilhada, apenas o thread principal vai acessar a stdin Em ambos os casos, todos os processos/threads podem acessar a stdout e a stderr 104
112 Entrada e Saída Contudo, devido ao não-determinismo da ordem da saída para stdout tipicamente restringe-se o uso do stdout da mesma maneira que fazemos para a stdin Exceção notável: depuração de código Saída de depuração deve sempre incluir o número do processo/thread para permitir identificação do gerador da mensagem 105
113 Entrada e Saída Apenas um processo deve tentar acessar um arquivo por vez (excluindo-se stdin, stdout e stderr) Por exemplo, cada processo/thread pode abrir seu próprio arquivo de modo privado para leitura e escrita, mas dois processos distintos deveriam abrir o mesmo arquivo ao mesmo tempo 106
114 Desempenho
115 Speedup Número de cores/processadores = p Tempo de execução sequencial = T sequencial Tempo de execução paralelo = T paralelo Se T paralelo = T sequencial p speedup linear Qual é o tempo sequencial que deve ser usado? Melhor implementação sequencial? Implementação base da paralelização? 107
116 Speedup de um programa paralelo S = T sequencial T paralelo 108
117 Eficiência T sequencial E = S P = T paralelo p = T sequencial p T paralelo 109
118 Speedup e eficiência de um programa paralelo Table 2.4 Speedups and Efficiencies of a Parallel Program p S E = S/p
119 Speedup e eficiência de um programa paralelo (múltiplos tamanhos) Table 2.5 Speedups and Efficiencies of a Parallel Program on Different Problem Sizes p Half S E Original S E Double S E
120 Speedup Half size Original Double size 12 Speedup Processes 112
121 Efficiency Efficiency Half size Original Double size Processes 113
122 Efeito do overhead T paralelo = T sequencial p + T overhead Um programa paralelo passa a ter overheads de comunicação, divisão do trabalho, controle para entrada em regiões críticas,. São raríssimas as ocasiões onde é possível ter um speeup perfeitamente linear (ou superlinear) 114
123 Lei de Amdahl Observação feita na década de 60 por Gene Amdahl Mais tarde passou a ser conhecida como A lei de Amdahl Para explicar, pense em um exemplo: T sequencial = 20 Parte paralelizável do programa 90% Qual é o speedup máximo (independentemente do número de processadores) que podemos alcançar? 115
124 Lei de Amdahl A menos que a totalidade de um programa sequencial possa ser paralelizado, o speedup máximo é limitado independentemente do número de cores disponíveis. No nosso exemplo o speedup máximo é 10 De modo geral, o speedup máximo é 1 r do programa que não é paralelizável onde r é a fração E agora, jogamos a toalha? 116
125 Lei de Gustafson A realidade dos programas paralelos não é tão sombria. Quanto maior o problema menor a parte sequencial (proporcionalmente, ou seja r 0) Há milhares de exemplos de problemas com speedups altíssimos usados todos os dias Nem sempre um speedup de 10 ou 20 é pouco, ainda mais se o esforço para a paralelização for pequeno 117
126 Escalabilidade De maneira informal dizemos que um problema (ou a sua solução) é escalável (scalable), se é possível tratar problemas cada vez maiores Porém aqui precisaremos de uma definição mais precisa. 118
127 Escalabilidade Suponha que rodamos a solução para um problema com um determinado número de processos e tamanho de entrada e obtemos uma eficiência E Suponha também que aumentemos o número de processos Dizemos que o problema é escalável se é possível achar um aumento correspondente no tamanho da entrada de modo que a eficiência E permaneça constante. 119
128 Escalabilidade: Exemplo Suponha que T sequencial = n T paralelo = n p + 1 Este problema é escalável? 120
129 Escalabilidade: Exemplo E = n p( n = n p +1) n+p Então Para verificar se o problema é escalável, vamos aumentar o tamanho do problema em um fator de k Precisamos encontrar x tal que E permaneça constante E = n n+p = xn xn+kp 121
130 Escalabilidade: Exemplo E = n n+p = xn xn+kp Tomando x = k temos: xn xn+kp = O problema é escalável. kn kn+kp = n n+p = E 122
131 Tipos de escalabilidade Escalabilidade forte A eficiência é mantida à medida que p cresce sem um aumento no tamanho do problema. Escalabilidade fraca A eficiência é mantida à medida que p cresce quando também há um aumento proporcional do tamanho do problema. Qual é o caso do nosso exemplo? 123
132 Medindo o tempo O que medir? Tempo de processamento Descarta o tempo de carga, por exemplo? E quanto ao tempo de E/S? Tempo de comunicação Tempo de parede (wall-clock time) Como apresentar as medidas? Média Mediana Máximo Mínimo 124
133 Medindo o tempo double start, finish;... start = Get current time(); / Code that we want to time /... finish = Get current time(); printf("the elapsed time = %e seconds\n", finish start); Função teórica Funções reais: MPI_Wtime, omp_get_wtime Na verdade é preciso cuidar de muitos detalhes como: Variabilidade Resolução 125
134 Medindo o tempo E no caso de programas paralelos? private double start, finish;... start = Get current time(); / Code that we want to time /... finish = Get current time(); printf("the elapsed time = %e seconds\n", finish start); 126
135 Medindo o tempo shared double global elapsed; private double my start, my finish, my elapsed;... / Synchronize all processes/threads / Barrier(); my start = Get current time(); / Code that we want to time /... my finish = Get current time(); my elapsed = my finish my start; / Find the max across all processes/threads / global elapsed = Global max(my elapsed); if (my rank == 0) printf("the elapsed time = %e seconds\n", global elapsed); É comum o uso de barreiras (barriers) em programas paralelos quando precisamos que todas as linhas de execução estejam no mesmo ponto. 127
136 Design de programas paralelos
137 O que já sabemos? Precisamos dividir o trabalho em tarefas menores e aproximadamente do mesmo tamanho Precisamos minimizar a comunicação Ian Foster sistematizou estas diretrizes no que ficou conhecido como Metodologia de Foster 128
138 Metodologia de Foster 1 Particionamento - dividir a computação e os dados sobre os quais devemos trabalhar em pequenas tarefas. O foco principal deve ser em identificar tarefas que podem ser executadas em paralelo. 2 Comunicação - determinar o que precisa ser comunicado entre as tarefas identificadas no passo anterior 129
139 Metodologia de Foster 3 Aglomeração/Agregação - combinar as tarefas e as comunicações identificadas no primeiro passo em tarefas maiores. Por exemplo, se a tarefa A só pode executar depois de B, pode fazer sentido agregá-las em uma única tarefa maior. 4 Mapeamento - atribuir as tarefas compostas no passo 3 para processos/threads. Isto deve ser feito de maneira a minimizar a comunicação e de modo a equilibrar a quantidade de tarefas para cada trabalhador. 130
140 Metodologia de Foster - Exemplo - Histograma 1.3, 2.9, 0.4, 0.3, 1.3, 4.4, 1.7, 0.4, 3.2, 0.3, 4.9, 2.4, 3.1, 4.4, 3.9, 0.4, 4.2, 4.5, 4.9,
141 Histograma - Entrada do programa sequencial 1 O número de medidas: data_count 2 Um vetor de data_count floats: data 3 O valor mínimo para a bin contendo os menores valores: min_meas 4 O valor máximo para a bin contendo os maiores valores: max_meas 5 O número de bins: bin_count 132
142 Histograma - Saída do programa sequencial 1 bin_maxes: um vetor de bin_count floats 2 bin_coutns: um vetor de bin_count ints 133
143 Hotspot da implementação sequencial Um hotspot é um trecho quente do código, ou seja, um trecho que gasta boa parte do tempo total de processamento. for (i = 0; i < data count; i++) { bin = Find bin(data[i], bin maxes, bin count, min meas); bin counts[bin]++; } 134
144 Primeiros dois passos da Metodologia de Foster Find_bin data[i 1] data[i] data[i + 1] Increment bin_counts bin_counts[b 1]++ bin_counts[b]++ 135
145 Definição alternativa das tarefas e comunicação Find_bin data[i 1] data[i] data[i + 1] data[i + 2] loc_bin_cts[b 1]++ loc_bin_cts[b]++ loc_bin_cts[b 1]++ loc_bin_cts[b]++ bin_counts[b 1]+= bin_counts[b]+= 136
146 Adicionando os vetores locais
Arquitetura de Computadores. Processamento Paralelo
 Arquitetura de Computadores Processamento Paralelo 1 Multiprogramação e Multiprocessamento Múltiplas organizações de computadores Single instruction, single data stream - SISD Single instruction, multiple
Arquitetura de Computadores Processamento Paralelo 1 Multiprogramação e Multiprocessamento Múltiplas organizações de computadores Single instruction, single data stream - SISD Single instruction, multiple
Sistemas MIMD. CES-25 Arquiteturas para Alto Desmpenho. Paulo André Castro
 Sistemas MIMD Arquiteturas para Alto Desmpenho Prof. pauloac@ita.br Sala 110 Prédio da Computação www.comp.ita.br/~pauloac Arquiteturas Paralelas (SISD) Single Instruction Stream, Single Data Stream: Monoprocessador
Sistemas MIMD Arquiteturas para Alto Desmpenho Prof. pauloac@ita.br Sala 110 Prédio da Computação www.comp.ita.br/~pauloac Arquiteturas Paralelas (SISD) Single Instruction Stream, Single Data Stream: Monoprocessador
Bacharelado em Sistemas de Informação Sistemas Operacionais. Prof. Filipo Mór
 Bacharelado em Sistemas de Informação Sistemas Operacionais Prof. Filipo Mór WWW.FILIPOMOR.COM - REVISÃO ARQUITETURAS PARALELAS Evolução das Arquiteturas Evolução das Arquiteturas Entrada CPU Saída von
Bacharelado em Sistemas de Informação Sistemas Operacionais Prof. Filipo Mór WWW.FILIPOMOR.COM - REVISÃO ARQUITETURAS PARALELAS Evolução das Arquiteturas Evolução das Arquiteturas Entrada CPU Saída von
INTRODUÇÃO À TECNOLOGIA DA INFORMAÇÃO ORGANIZAÇÃO COMPUTACIONAL
 INTRODUÇÃO À TECNOLOGIA DA ORGANIZAÇÃO COMPUTACIONAL PROFESSOR CARLOS MUNIZ ORGANIZAÇÃO DE UM COMPUTADOR TÍPICO Memória: Armazena dados e programas Processador (CPU - Central Processing Unit): Executa
INTRODUÇÃO À TECNOLOGIA DA ORGANIZAÇÃO COMPUTACIONAL PROFESSOR CARLOS MUNIZ ORGANIZAÇÃO DE UM COMPUTADOR TÍPICO Memória: Armazena dados e programas Processador (CPU - Central Processing Unit): Executa
speedup aprimorado aprimorado Fração aprimorada speedup aprimorado Fração aprimorada speedup aprimorado Tempo original Fração aprimorada aprimorado
 Multiprocessadores - A evolução tecnológica dos processadores iria diminuir drasticamente. 2- O caminho para o aumento de desempenho é de unir mais de um processador para realizar a mesma tarefa em menos
Multiprocessadores - A evolução tecnológica dos processadores iria diminuir drasticamente. 2- O caminho para o aumento de desempenho é de unir mais de um processador para realizar a mesma tarefa em menos
Computadores e Programação (DCC/UFRJ)
") Computadores e Programação (DCC/UFRJ) Aula 3: 1 2 3 Abstrações do Sistema Operacional Memória virtual Abstração que dá a cada processo a ilusão de que ele possui uso exclusivo da memória principal Todo
Computadores e Programação (DCC/UFRJ) Aula 3: 1 2 3 Abstrações do Sistema Operacional Memória virtual Abstração que dá a cada processo a ilusão de que ele possui uso exclusivo da memória principal Todo
Universidade Federal do Rio de Janeiro Informática DCC/IM. Arquitetura de Computadores II. Arquiteturas MIMD. Arquiteturas MIMD
 Universidade Federal do Rio de Janeiro Informática DCC/IM Arquitetura de Computadores II Arquiteturas MIMD Arquiteturas MIMD As arquiteturas MIMD dividem-se em dois grandes modelos: Arquiteturas MIMD de
Universidade Federal do Rio de Janeiro Informática DCC/IM Arquitetura de Computadores II Arquiteturas MIMD Arquiteturas MIMD As arquiteturas MIMD dividem-se em dois grandes modelos: Arquiteturas MIMD de
Arquitetura de Computadores
 Arquitetura de Computadores 2018.1 Relembrando... Memória Virtual Relembrando... Memória Virtual Proteção de Memória Relembrando... Memória Virtual Proteção de Memória TLB Relembrando... Memória Virtual
Arquitetura de Computadores 2018.1 Relembrando... Memória Virtual Relembrando... Memória Virtual Proteção de Memória Relembrando... Memória Virtual Proteção de Memória TLB Relembrando... Memória Virtual
Organização Básica de Computadores. Organização Básica de Computadores. Organização Básica de Computadores. Organização Básica de Computadores
 Ciência da Computação Arq. e Org. de Computadores Processadores Prof. Sergio Ribeiro Composição básica de um computador eletrônico digital: Processador Memória Memória Principal Memória Secundária Dispositivos
Ciência da Computação Arq. e Org. de Computadores Processadores Prof. Sergio Ribeiro Composição básica de um computador eletrônico digital: Processador Memória Memória Principal Memória Secundária Dispositivos
Faculdade de Computação 3 a Prova de Arquitetura e Organização de Computadores 2 Parte I Prof. Cláudio C. Rodrigues
 Faculdade de Computação 3 a Prova de Parte I Prof. Cláudio C. Rodrigues Nome: Matrícula: Valor: 15 Nome: Matrícula: Valor: 15 Nome: Matrícula: Valor: 15 Nome: Matrícula: Valor: 15 Problemas: P1. Qual o
Faculdade de Computação 3 a Prova de Parte I Prof. Cláudio C. Rodrigues Nome: Matrícula: Valor: 15 Nome: Matrícula: Valor: 15 Nome: Matrícula: Valor: 15 Nome: Matrícula: Valor: 15 Problemas: P1. Qual o
Multiprocessamento. Patterson & Hennessy Capítulo 9. Arquitetura e Organização de Computadores Juliano M. Vieira (c) 2011
 2011") Multiprocessamento Patterson & Hennessy Capítulo 9 Arquitetura e Organização de Computadores Juliano M. Vieira (c) 2011 Tópicos Abordados Tipos comuns SMP (processamento paralelo) NUMA (placas de alto
Multiprocessamento Patterson & Hennessy Capítulo 9 Arquitetura e Organização de Computadores Juliano M. Vieira (c) 2011 Tópicos Abordados Tipos comuns SMP (processamento paralelo) NUMA (placas de alto
CPU. Control registers. Interconnect. Main memory
 CPU ALU registers Control registers Interconnect Address Contents Main memory 1 2 3 4 5 Cache Location Memory Index Fully Assoc Direct Mapped 2-way 0 0, 1, 2, or 3 0 0 or 1 1 0, 1, 2,
CPU ALU registers Control registers Interconnect Address Contents Main memory 1 2 3 4 5 Cache Location Memory Index Fully Assoc Direct Mapped 2-way 0 0, 1, 2, or 3 0 0 or 1 1 0, 1, 2,
Arquitetura de Computadores. Prof. João Bosco Jr.
 Arquitetura de Computadores Prof. João Bosco Jr. (CPU) Modelo do Computador Von Neumann Processador Memórias E/S Barramentos Simulação Contador http://courses.cs.vt.edu/csonline/machinearchitecture/lessons/cpu/countprogram.html
Arquitetura de Computadores Prof. João Bosco Jr. (CPU) Modelo do Computador Von Neumann Processador Memórias E/S Barramentos Simulação Contador http://courses.cs.vt.edu/csonline/machinearchitecture/lessons/cpu/countprogram.html
Caracterização de Sistemas Distribuídos
 Caracterização de Sistemas Distribuídos Roteiro Conceitos de Hardware Conceitos de Software Classificação de Flynn Classificação baseada no acesso a memória 2 Conceitos de HW Múltiplas CPUs Diferentes
Caracterização de Sistemas Distribuídos Roteiro Conceitos de Hardware Conceitos de Software Classificação de Flynn Classificação baseada no acesso a memória 2 Conceitos de HW Múltiplas CPUs Diferentes
Organização e Arquitetura de Computadores I
 Universidade Federal de Campina Grande Centro de Engenharia Elétrica e Informática Unidade Acadêmica de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de
Universidade Federal de Campina Grande Centro de Engenharia Elétrica e Informática Unidade Acadêmica de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de
Sistemas Operacionais. Conceitos de Hardware
 Sistemas Operacionais Conceitos de Hardware Sumário 1. Introdução 7. RISC e CISC 2. Processador 1. Operações de Processamento 2. Unidade de Controle 3. Ciclos de uma Instrução 3. Memória 1. Memória Principal
Sistemas Operacionais Conceitos de Hardware Sumário 1. Introdução 7. RISC e CISC 2. Processador 1. Operações de Processamento 2. Unidade de Controle 3. Ciclos de uma Instrução 3. Memória 1. Memória Principal
Arquitetura de Computadores
 Arquitetura de Computadores 2018.1 Relembrando... Paralelismo Relembrando... Paralelismo Paralelismo em Instrução Relembrando... Paralelismo Paralelismo em Instrução Paralelismo em Aritmética Relembrando...
Arquitetura de Computadores 2018.1 Relembrando... Paralelismo Relembrando... Paralelismo Paralelismo em Instrução Relembrando... Paralelismo Paralelismo em Instrução Paralelismo em Aritmética Relembrando...
Arquiteturas de Computadores
 Arquiteturas de Computadores Computadores vetoriais Fontes dos slides: Livro Patterson e Hennessy, Quantitative Approach e site do curso EE 7722, GPU Microarchitecture do Prof. David Koppelman Graphical
Arquiteturas de Computadores Computadores vetoriais Fontes dos slides: Livro Patterson e Hennessy, Quantitative Approach e site do curso EE 7722, GPU Microarchitecture do Prof. David Koppelman Graphical
AULA 03: PROCESSAMENTO PARALELO: MULTIPROCESSADORES
 ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 03: PROCESSAMENTO PARALELO: MULTIPROCESSADORES Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação MULTIPROCESSADORES
ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 03: PROCESSAMENTO PARALELO: MULTIPROCESSADORES Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação MULTIPROCESSADORES
SSC510 Arquitetura de Computadores. 6ª aula
 SSC510 Arquitetura de Computadores 6ª aula PARALELISMO EM NÍVEL DE PROCESSOS PROFA. SARITA MAZZINI BRUSCHI Tipos de Paralelismo Instrução (granulosidade fina) Paralelismo entre as instruções Arquiteturas
SSC510 Arquitetura de Computadores 6ª aula PARALELISMO EM NÍVEL DE PROCESSOS PROFA. SARITA MAZZINI BRUSCHI Tipos de Paralelismo Instrução (granulosidade fina) Paralelismo entre as instruções Arquiteturas
Introdução à Computação: Sistemas de Computação
 Introdução à Computação: Sistemas de Computação Beatriz F. M. Souza (bfmartins@inf.ufes.br) http://inf.ufes.br/~bfmartins/ Computer Science Department Federal University of Espírito Santo (Ufes), Vitória,
Introdução à Computação: Sistemas de Computação Beatriz F. M. Souza (bfmartins@inf.ufes.br) http://inf.ufes.br/~bfmartins/ Computer Science Department Federal University of Espírito Santo (Ufes), Vitória,
Barramento. Prof. Leonardo Barreto Campos 1
 Barramento Prof. Leonardo Barreto Campos 1 Sumário Introdução; Componentes do Computador; Funções dos Computadores; Estrutura de Interconexão; Interconexão de Barramentos Elementos de projeto de barramento;
Barramento Prof. Leonardo Barreto Campos 1 Sumário Introdução; Componentes do Computador; Funções dos Computadores; Estrutura de Interconexão; Interconexão de Barramentos Elementos de projeto de barramento;
William Stallings Arquitetura e Organização de Computadores 8 a Edição
 William Stallings Arquitetura e Organização de Computadores 8 a Edição Capítulo 8 Suporte do sistema operacional slide 1 Objetivos e funções Conveniência: Tornar o computador mais fácil de usar. Eficiência:
William Stallings Arquitetura e Organização de Computadores 8 a Edição Capítulo 8 Suporte do sistema operacional slide 1 Objetivos e funções Conveniência: Tornar o computador mais fácil de usar. Eficiência:
Introdução à OpenMP (Dia 1) Prof. Guido Araujo
 Prof. Guido Araujo") Introdução à OpenMP (Dia ) Prof. Guido Araujo www.ic.unicamp.br/~guido Roteiro Escrevendo programas usando OpenMP Usando OpenMP para paralelizar laços seriais com pequenas mudanças no código fonte Explorar
Introdução à OpenMP (Dia ) Prof. Guido Araujo www.ic.unicamp.br/~guido Roteiro Escrevendo programas usando OpenMP Usando OpenMP para paralelizar laços seriais com pequenas mudanças no código fonte Explorar
Memória Cache. Aula 24
 Memória Cache Aula 24 Introdução Objetivo: oferecer o máximo de memória disponível na tecnologia mais barata, enquanto se fornece acesso na velocidade oferecida pela memória mais rápida Velocidade CPU
Memória Cache Aula 24 Introdução Objetivo: oferecer o máximo de memória disponível na tecnologia mais barata, enquanto se fornece acesso na velocidade oferecida pela memória mais rápida Velocidade CPU
Infraestrutura de Hardware. Explorando a Hierarquia de Memória
 Infraestrutura de Hardware Explorando a Hierarquia de Memória Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é entendido e executado pelo
Infraestrutura de Hardware Explorando a Hierarquia de Memória Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é entendido e executado pelo
Organização de Computadores II. Arquiteturas MIMD
 Organização de Computadores II Arquiteturas MIMD Arquiteturas UMA Arquiteturas com memória única global. Tempo de acesso uniforme para todos os nós de processamento. Nós de processamento e memória interconectados
Organização de Computadores II Arquiteturas MIMD Arquiteturas UMA Arquiteturas com memória única global. Tempo de acesso uniforme para todos os nós de processamento. Nós de processamento e memória interconectados
Arquitetura e Organização de Processadores. Aula 4. Pipelines
 Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 4 Pipelines 1. Introdução Objetivo: aumento de
Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 4 Pipelines 1. Introdução Objetivo: aumento de
Carlos Eduardo Batista Centro de Informática - UFPB
 Carlos Eduardo Batista Centro de Informática - UFPB bidu@ci.ufpb.br Motivação Arquitetura de computadores modernos Desafios da programação concorrente Definição de concorrência Correr junto Disputa por
Carlos Eduardo Batista Centro de Informática - UFPB bidu@ci.ufpb.br Motivação Arquitetura de computadores modernos Desafios da programação concorrente Definição de concorrência Correr junto Disputa por
ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 02: PROCESSAMENTO PARALELO: PROCESSADORES VETORIAIS
 ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 02: PROCESSAMENTO PARALELO: PROCESSADORES VETORIAIS Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação
ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 02: PROCESSAMENTO PARALELO: PROCESSADORES VETORIAIS Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação
Organização e Arquitetura de Computadores I
 Organização e Arquitetura de Computadores I BARRAMENTO Slide 1 Sumário Introdução Componentes de Computador Funções dos Computadores Estruturas de Interconexão Interconexão de Barramentos Slide 2 Introdução
Organização e Arquitetura de Computadores I BARRAMENTO Slide 1 Sumário Introdução Componentes de Computador Funções dos Computadores Estruturas de Interconexão Interconexão de Barramentos Slide 2 Introdução
Princípio da Localidade Apenas uma parte relativamente pequena do espaço de endereçamento dos programas é acessada em um instante qualquer Localidade
 Memória Cache Princípio da Localidade Apenas uma parte relativamente pequena do espaço de endereçamento dos programas é acessada em um instante qualquer Localidade Temporal Um item referenciado tende a
Memória Cache Princípio da Localidade Apenas uma parte relativamente pequena do espaço de endereçamento dos programas é acessada em um instante qualquer Localidade Temporal Um item referenciado tende a
SSC0611 Arquitetura de Computadores
 SSC0611 Arquitetura de Computadores 17ª Aula Paralelismos nível de tarefas Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Paralelismo no nível de tarefas Paralelismo a nível de thread (TLP Thread-Level
SSC0611 Arquitetura de Computadores 17ª Aula Paralelismos nível de tarefas Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Paralelismo no nível de tarefas Paralelismo a nível de thread (TLP Thread-Level
É um sinal elétrico periódico que é utilizado para cadenciar todas as operações realizadas pelo processador.
 Universidade Estácio de Sá Curso de Informática Disciplina de Organização de Computadores II Prof. Gabriel P. Silva - 1 o Sem. / 2005 2 ª Lista de Exercícios 1) O que é o relógio de um sistema digital?
Universidade Estácio de Sá Curso de Informática Disciplina de Organização de Computadores II Prof. Gabriel P. Silva - 1 o Sem. / 2005 2 ª Lista de Exercícios 1) O que é o relógio de um sistema digital?
Sistemas Operacionais Gerenciamento de Memória. Carlos Ferraz Jorge Cavalcanti Fonsêca
 Sistemas Operacionais Gerenciamento de Memória Carlos Ferraz (cagf@cin.ufpe.br) Jorge Cavalcanti Fonsêca (jcbf@cin.ufpe.br) Memória Física vs. Memória do Programa Memória P Física Tamanho dos softwares
Sistemas Operacionais Gerenciamento de Memória Carlos Ferraz (cagf@cin.ufpe.br) Jorge Cavalcanti Fonsêca (jcbf@cin.ufpe.br) Memória Física vs. Memória do Programa Memória P Física Tamanho dos softwares
Arquitetura e Organização de Computadores
 Arquitetura e Organização de Computadores Unidade Central de Processamento (CPU) Givanaldo Rocha de Souza http://docente.ifrn.edu.br/givanaldorocha givanaldo.rocha@ifrn.edu.br Baseado nos slides do capítulo
Arquitetura e Organização de Computadores Unidade Central de Processamento (CPU) Givanaldo Rocha de Souza http://docente.ifrn.edu.br/givanaldorocha givanaldo.rocha@ifrn.edu.br Baseado nos slides do capítulo
ARQUITETURA DE COMPUTADORES. Organização de Sistemas Computacionais. Prof.: Agostinho S. Riofrio
 ARQUITETURA DE COMPUTADORES Organização de Sistemas Computacionais Prof.: Agostinho S. Riofrio Agenda 1. Unidade Central de Processamento 2. Organização da CPU 3. Interpretador 4. RISC x CISC 5. Principios
ARQUITETURA DE COMPUTADORES Organização de Sistemas Computacionais Prof.: Agostinho S. Riofrio Agenda 1. Unidade Central de Processamento 2. Organização da CPU 3. Interpretador 4. RISC x CISC 5. Principios
SSC0611 Arquitetura de Computadores
 SSC0611 Arquitetura de Computadores 5ª e 6ª Aulas Revisão de Hierarquia de Memória Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br 1 Memória Memória Todo componente capaz de armazenar bits de informação
SSC0611 Arquitetura de Computadores 5ª e 6ª Aulas Revisão de Hierarquia de Memória Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br 1 Memória Memória Todo componente capaz de armazenar bits de informação
SSC0611 Arquitetura de Computadores
 SSC0611 Arquitetura de Computadores 20ª Aula Arquiteturas Paralelas Arquitetura MIMD com Memória Compartilhada Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Arquiteturas MIMD As arquiteturas MIMD dividem-se
SSC0611 Arquitetura de Computadores 20ª Aula Arquiteturas Paralelas Arquitetura MIMD com Memória Compartilhada Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Arquiteturas MIMD As arquiteturas MIMD dividem-se
Parte I Multiprocessamento
 Sistemas Operacionais I Estrutura dos SO Prof. Gregorio Perez gregorio@uninove.br 2004 Parte I Multiprocessamento Roteiro 1 Multiprocessadores em Sistemas Fortemente Acoplados 1.1 1.2 1.3 Processamento
Sistemas Operacionais I Estrutura dos SO Prof. Gregorio Perez gregorio@uninove.br 2004 Parte I Multiprocessamento Roteiro 1 Multiprocessadores em Sistemas Fortemente Acoplados 1.1 1.2 1.3 Processamento
Processamento Paralelo
 Processamento Paralelo por Helcio Wagner da Silva Introdução Tradicionalmente, o computador tem sido visto como uma máquina seqüencial Esta visão nunca foi completamente verdadeira No nível das µo, vários
Processamento Paralelo por Helcio Wagner da Silva Introdução Tradicionalmente, o computador tem sido visto como uma máquina seqüencial Esta visão nunca foi completamente verdadeira No nível das µo, vários
Sistemas Operacionais
 Sistemas Operacionais Gerência de Memória Memória virtual Edson Moreno edson.moreno@pucrs.br http://www.inf.pucrs.br/~emoreno Slides baseados nas apresentações dos prof. Tiago Ferreto e Alexandra Aguiar
Sistemas Operacionais Gerência de Memória Memória virtual Edson Moreno edson.moreno@pucrs.br http://www.inf.pucrs.br/~emoreno Slides baseados nas apresentações dos prof. Tiago Ferreto e Alexandra Aguiar
Hierarquia de Memória. Sistemas de Computação André Luiz da Costa Carvalho
 Hierarquia de Memória Sistemas de Computação André Luiz da Costa Carvalho 1 Introdução l Pode ser definida como um local para armazenamento de informações, onde as duas únicas ações possíveis são a leitura
Hierarquia de Memória Sistemas de Computação André Luiz da Costa Carvalho 1 Introdução l Pode ser definida como um local para armazenamento de informações, onde as duas únicas ações possíveis são a leitura
Aula 3 Redes de Interconexão
 Aula 3 Redes de Interconexão As redes de interconexão são de fundamental importância nas arquiteturas paralelas Não importa o tipo da arquitetura, todo computador paralelo necessita de uma rede de interconexão
Aula 3 Redes de Interconexão As redes de interconexão são de fundamental importância nas arquiteturas paralelas Não importa o tipo da arquitetura, todo computador paralelo necessita de uma rede de interconexão
PARALELISMO NO NÍVEL DO PROCESSADOR
 UNIP Universidade Paulista. Campus Brasília. PARALELISMO NO NÍVEL DO PROCESSADOR ALUNO: Lucas da Silva Dias ALUNO: Gleidson Rosa da Silva ALUNO: Gustavo da Silva Martins ALUNO: Marcelo Nery Lima RA: C633EB-1
UNIP Universidade Paulista. Campus Brasília. PARALELISMO NO NÍVEL DO PROCESSADOR ALUNO: Lucas da Silva Dias ALUNO: Gleidson Rosa da Silva ALUNO: Gustavo da Silva Martins ALUNO: Marcelo Nery Lima RA: C633EB-1
PROCESSADORES Unidade de Controle Unidade Aritmética e Lógica efetua memória de alta velocidade registradores Program Counter Instruction Register
 PROCESSADORES Um computador digital consiste em um sistema interconectado de processadores, memória e dispositivos de entrada e saída. A CPU é o cérebro do computador. Sua função é executar programas armazenados
PROCESSADORES Um computador digital consiste em um sistema interconectado de processadores, memória e dispositivos de entrada e saída. A CPU é o cérebro do computador. Sua função é executar programas armazenados
1. A pastilha do processador Intel possui uma memória cache única para dados e instruções. Esse processador tem capacidade de 8 Kbytes e é
 1. A pastilha do processador Intel 80486 possui uma memória cache única para dados e instruções. Esse processador tem capacidade de 8 Kbytes e é organizado com mapeamento associativo por conjuntos de quatro
1. A pastilha do processador Intel 80486 possui uma memória cache única para dados e instruções. Esse processador tem capacidade de 8 Kbytes e é organizado com mapeamento associativo por conjuntos de quatro
Arquiteturas de Computadores
 Arquiteturas de Computadores Computadores vetoriais Fontes dos slides: Livro Patterson e Hennessy, Quantitative Approach Introdução Arquiteturas Single Instruction Multiple Data podem explorar paralelismo
Arquiteturas de Computadores Computadores vetoriais Fontes dos slides: Livro Patterson e Hennessy, Quantitative Approach Introdução Arquiteturas Single Instruction Multiple Data podem explorar paralelismo
Paralelismo em Computadores com Tecnologia Multicore
 IFRN - Pau dos Ferros Pau dos Ferros/RN, 25 de fevereiro de 2016 O minicurso Descrição: Para se utilizar os vários núcleos de processamento disponíveis nos computadores atuais de forma eficiente, faz necessário
IFRN - Pau dos Ferros Pau dos Ferros/RN, 25 de fevereiro de 2016 O minicurso Descrição: Para se utilizar os vários núcleos de processamento disponíveis nos computadores atuais de forma eficiente, faz necessário
Organização de Computadores 2005/2006 Processamento Paralelo
 GoBack Organização de Computadores 2005/2006 Processamento Paralelo Paulo Ferreira paf a dei.isep.ipp.pt Maio de 2006 ORGC Processamento Paralelo slide 1 Porquê? Definição de computação paralela Alocação
GoBack Organização de Computadores 2005/2006 Processamento Paralelo Paulo Ferreira paf a dei.isep.ipp.pt Maio de 2006 ORGC Processamento Paralelo slide 1 Porquê? Definição de computação paralela Alocação
Infraestrutura de Hardware. Explorando Desempenho com a Hierarquia de Memória
 Infraestrutura de Hardware Explorando Desempenho com a Hierarquia de Memória Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é entendido e
Infraestrutura de Hardware Explorando Desempenho com a Hierarquia de Memória Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é entendido e
Infraestrutura de Hardware. Funcionamento de um Computador
 Infraestrutura de Hardware Funcionamento de um Computador Computador: Hardware + Software Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é
Infraestrutura de Hardware Funcionamento de um Computador Computador: Hardware + Software Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é
ARQUITETURA DE COMPUTADORES
 01001111 01110010 01100111 01100001 01101110 01101001 01111010 01100001 11100111 11100011 01101111 00100000 01100100 01100101 00100000 01000011 01101111 01101101 01110000 01110101 01110100 01100001 01100100
01001111 01110010 01100111 01100001 01101110 01101001 01111010 01100001 11100111 11100011 01101111 00100000 01100100 01100101 00100000 01000011 01101111 01101101 01110000 01110101 01110100 01100001 01100100
FUNDAMENTOS DE ARQUITETURAS DE COMPUTADORES MEMÓRIA CACHE CAPÍTULO 5. Cristina Boeres
 FUNDAMENTOS DE ARQUITETURAS DE COMPUTADORES MEMÓRIA CACHE CAPÍTULO 5 Cristina Boeres Introdução! Diferença de velocidade entre Processador e MP O processador executa uma operação rapidamente e fica em
FUNDAMENTOS DE ARQUITETURAS DE COMPUTADORES MEMÓRIA CACHE CAPÍTULO 5 Cristina Boeres Introdução! Diferença de velocidade entre Processador e MP O processador executa uma operação rapidamente e fica em
Linguagem de Programação II
 Linguagem de Programação II Carlos Eduardo Ba6sta Centro de Informá6ca - UFPB bidu@ci.ufpb.br Mo6vação Adaptar a estrutura lógica de um problema (Ex.: Servidores Web). Lidar com disposi6vos independentes
Linguagem de Programação II Carlos Eduardo Ba6sta Centro de Informá6ca - UFPB bidu@ci.ufpb.br Mo6vação Adaptar a estrutura lógica de um problema (Ex.: Servidores Web). Lidar com disposi6vos independentes
Multiprogramação leve em arquiteturas multi-core
 Multiprogramação leve em arquiteturas multi-core Prof. Dr. Departamento de Informática Universidade Federal de Pelotas Sumário Arquiteturas multi-core Programação multithread Ferramentas de programação
Multiprogramação leve em arquiteturas multi-core Prof. Dr. Departamento de Informática Universidade Federal de Pelotas Sumário Arquiteturas multi-core Programação multithread Ferramentas de programação
INTRODUÇÃO À ARQUITETURA E ORGANIZAÇÃO DE COMPUTADORES. Função e Estrutura. Introdução Organização e Arquitetura. Organização e Arquitetura
 Introdução Organização e Arquitetura INTRODUÇÃO À ARQUITETURA E ORGANIZAÇÃO DE COMPUTADORES Eduardo Max Amaro Amaral Arquitetura são os atributos visíveis ao programador. Conjunto de instruções, número
Introdução Organização e Arquitetura INTRODUÇÃO À ARQUITETURA E ORGANIZAÇÃO DE COMPUTADORES Eduardo Max Amaro Amaral Arquitetura são os atributos visíveis ao programador. Conjunto de instruções, número
Sistemas Distribuídos
 Sistemas Distribuídos Classificação de Flynn Fonte: Professoras. Sarita UFRJ e Thais V. Batista - UFRN Arquiteturas Paralelas Computação Paralela Conceitos Permite a execução das tarefas em menor tempo,
Sistemas Distribuídos Classificação de Flynn Fonte: Professoras. Sarita UFRJ e Thais V. Batista - UFRN Arquiteturas Paralelas Computação Paralela Conceitos Permite a execução das tarefas em menor tempo,
Gerência de memória II
 Gerência de memória II Eduardo Ferreira dos Santos Ciência da Computação Centro Universitário de Brasília UniCEUB Maio, 2017 1 / 48 Sumário 1 Memória Virtual Segmentação Paginação 2 Alocação de páginas
Gerência de memória II Eduardo Ferreira dos Santos Ciência da Computação Centro Universitário de Brasília UniCEUB Maio, 2017 1 / 48 Sumário 1 Memória Virtual Segmentação Paginação 2 Alocação de páginas
Gerenciamento de Memória
 Gerenciamento de Memória Prof. Clodoaldo Ap. Moraes Lima 1 Segmentação Objetivo Melhorar o aspecto de localidade de referência em sistemas de memória virtual Em sistema paginado, os itens que são transferidos
Gerenciamento de Memória Prof. Clodoaldo Ap. Moraes Lima 1 Segmentação Objetivo Melhorar o aspecto de localidade de referência em sistemas de memória virtual Em sistema paginado, os itens que são transferidos
Arquiteturas de Sistemas de Processamento Paralelo. Arquiteturas SIMD
 Universidade Federal do Rio de Janeiro Pós-Graduação em Informática DCC/IM - NCE/UFRJ Arquiteturas de Sistemas de Processamento Paralelo Arquiteturas SIMD Arquiteturas SIMD Processadores Vetoriais Arquiteturas
Universidade Federal do Rio de Janeiro Pós-Graduação em Informática DCC/IM - NCE/UFRJ Arquiteturas de Sistemas de Processamento Paralelo Arquiteturas SIMD Arquiteturas SIMD Processadores Vetoriais Arquiteturas
2º Estudo Dirigido CAP 3
 2º Estudo Dirigido CAP 3 1. Cite três exemplos de aspecto na definição e implementação de uma arquitetura que são influenciados pelas características do conjunto de instruções? R.: Operações lógicas e
2º Estudo Dirigido CAP 3 1. Cite três exemplos de aspecto na definição e implementação de uma arquitetura que são influenciados pelas características do conjunto de instruções? R.: Operações lógicas e
Gerência de Memória. Endereçamento Virtual (1) Paginação. Endereçamento Virtual (2) Endereçamento Virtual (3)
 Paginação. Endereçamento Virtual (2) Endereçamento Virtual (3)") Endereçamento Virtual (1) Gerência de Memória Paginação Espaço de endereçamento dos processos não linearmente relacionado com a física Cada vez que são usados, os endereços virtuais são convertidos pela
Endereçamento Virtual (1) Gerência de Memória Paginação Espaço de endereçamento dos processos não linearmente relacionado com a física Cada vez que são usados, os endereços virtuais são convertidos pela
Sistemas Operacionais
 Introdução Memória virtual Trabalho sob a Licença Atribuição-SemDerivações-SemDerivados 3.0 Brasil Creative Commons. Para visualizar uma cópia desta licença, visite http://creativecommons.org/licenses/by-nc-nd/3.0/br/
Introdução Memória virtual Trabalho sob a Licença Atribuição-SemDerivações-SemDerivados 3.0 Brasil Creative Commons. Para visualizar uma cópia desta licença, visite http://creativecommons.org/licenses/by-nc-nd/3.0/br/
UNIDADE CENTRAL DE PROCESSAMENTO FELIPE G. TORRES
 Tecnologia da informação e comunicação UNIDADE CENTRAL DE PROCESSAMENTO FELIPE G. TORRES CICLO DE INSTRUÇÕES OU DE EXECUÇÃO Arquitetura de computadores 2 CICLO DE EXECUÇÃO No inicio de cada ciclo de instrução,
Tecnologia da informação e comunicação UNIDADE CENTRAL DE PROCESSAMENTO FELIPE G. TORRES CICLO DE INSTRUÇÕES OU DE EXECUÇÃO Arquitetura de computadores 2 CICLO DE EXECUÇÃO No inicio de cada ciclo de instrução,
Prof. Rômulo Calado Pantaleão Camara Carga Horária: 2h/60h
 Pipelining Avançado Prof. Rômulo Calado Pantaleão Camara Carga Horária: 2h/60h Introdução A técnica de pipelining explora o paralelismo entre as instruções Paralelismo em Nível de Instrução (ILP). Métodos
Pipelining Avançado Prof. Rômulo Calado Pantaleão Camara Carga Horária: 2h/60h Introdução A técnica de pipelining explora o paralelismo entre as instruções Paralelismo em Nível de Instrução (ILP). Métodos
Processador. Processador
 Departamento de Ciência da Computação - UFF Processador Processador Prof. Prof.Marcos MarcosGuerine Guerine mguerine@ic.uff.br mguerine@ic.uff.br 1 Processador Organização básica de um computador: 2 Processador
Departamento de Ciência da Computação - UFF Processador Processador Prof. Prof.Marcos MarcosGuerine Guerine mguerine@ic.uff.br mguerine@ic.uff.br 1 Processador Organização básica de um computador: 2 Processador
ORGANIZAÇÃO DE COMPUTADORES
 Organização de Computadores ORGANIZAÇÃO DE COMPUTADORES Curso: Tecnologia em Gestão da Tecnologia da Informação Ano: 2011 Conhecida como Processador ou é o cerebro do computador Unifica todo sistema e
Organização de Computadores ORGANIZAÇÃO DE COMPUTADORES Curso: Tecnologia em Gestão da Tecnologia da Informação Ano: 2011 Conhecida como Processador ou é o cerebro do computador Unifica todo sistema e
Sistemas de Entrada e Saída
 Sistemas de Entrada e Saída Eduardo Ferreira dos Santos Ciência da Computação Centro Universitário de Brasília UniCEUB Maio, 2016 1 / 33 Sumário 1 Dispositivos de E/S 2 Interrupções 3 Software de E/S 2
Sistemas de Entrada e Saída Eduardo Ferreira dos Santos Ciência da Computação Centro Universitário de Brasília UniCEUB Maio, 2016 1 / 33 Sumário 1 Dispositivos de E/S 2 Interrupções 3 Software de E/S 2
Programação Distribuída e Paralela. Jorge Barbosa
 Programação Distribuída e Paralela Jorge Barbosa 1 Máquinas Paralelas Processadores Memória Rede de interligação Classificação das máquinas paralelas 2 Processador Escalar Processadores Processador que
Programação Distribuída e Paralela Jorge Barbosa 1 Máquinas Paralelas Processadores Memória Rede de interligação Classificação das máquinas paralelas 2 Processador Escalar Processadores Processador que
Gerência de memória III
 Gerência de memória III Eduardo Ferreira dos Santos Ciência da Computação Centro Universitário de Brasília UniCEUB Maio, 2016 1 / 45 Sumário 1 Memória Virtual Segmentação Paginação 2 Alocação de páginas
Gerência de memória III Eduardo Ferreira dos Santos Ciência da Computação Centro Universitário de Brasília UniCEUB Maio, 2016 1 / 45 Sumário 1 Memória Virtual Segmentação Paginação 2 Alocação de páginas
AULA 06: PROGRAMAÇÃO EM MÁQUINAS PARALELAS
 ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 06: PROGRAMAÇÃO EM MÁQUINAS PARALELAS Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação PROGRAMAÇÃO PARALELA
ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 06: PROGRAMAÇÃO EM MÁQUINAS PARALELAS Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação PROGRAMAÇÃO PARALELA
SSC510 Arquitetura de Computadores. 7ª aula
 SSC510 Arquitetura de Computadores 7ª aula ARQUITETURAS SIMD PROFA. SARITA MAZZINI BRUSCHI Arquiteturas SIMD Um único fluxo de dados, vários fluxos de intruções Tipos de arquiteturas Processadores Vetorais
SSC510 Arquitetura de Computadores 7ª aula ARQUITETURAS SIMD PROFA. SARITA MAZZINI BRUSCHI Arquiteturas SIMD Um único fluxo de dados, vários fluxos de intruções Tipos de arquiteturas Processadores Vetorais
Gerência de Memória. Paginação
 Gerência de Memória Paginação Endereçamento Virtual (1) Espaço de endereçamento dos processos não linearmente relacionado com a memória física Cada vez que são usados, os endereços virtuais são convertidos
Gerência de Memória Paginação Endereçamento Virtual (1) Espaço de endereçamento dos processos não linearmente relacionado com a memória física Cada vez que são usados, os endereços virtuais são convertidos
Cache. Cache. Direct Mapping Cache. Direct Mapping Cache. Internet. Bus CPU Cache Memória. Cache. Endereço Byte offset
 -- Internet Bus Memória Fully Associative Direct Mapping Direct Mapping Direct Mapping 7 Endereço Byte offset Hit Tag Endereço Byte offset Index Block offset bits 8 bits bits bits V Tag Valid Tag K entries
-- Internet Bus Memória Fully Associative Direct Mapping Direct Mapping Direct Mapping 7 Endereço Byte offset Hit Tag Endereço Byte offset Index Block offset bits 8 bits bits bits V Tag Valid Tag K entries
periféricos: interfaces humano-computador (HCI) arquivo de informação comunicações
 arquivo de informação comunicações") Introdução aos Sistemas de Computação (6) Análise de componentes num computador Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3.
Introdução aos Sistemas de Computação (6) Análise de componentes num computador Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3.
Capítulo 8: Memória Principal. Operating System Concepts 8 th Edition
 Capítulo 8: Memória Principal Silberschatz, Galvin and Gagne 2009 Objetivos Fornecer uma descrição detalhada das várias formas de organizar a memória do computador Discutir várias técnicas de gerenciamento
Capítulo 8: Memória Principal Silberschatz, Galvin and Gagne 2009 Objetivos Fornecer uma descrição detalhada das várias formas de organizar a memória do computador Discutir várias técnicas de gerenciamento
Sistemas de Computação. Gerenciamento de memória
 Gerenciamento de memória Localização de processos Um programa fica armazenado em disco como um arquivo executável binário e tem que ser colocado na memória para começar a ser executado Os processos podem
Gerenciamento de memória Localização de processos Um programa fica armazenado em disco como um arquivo executável binário e tem que ser colocado na memória para começar a ser executado Os processos podem
30/5/2011. Sistemas computacionais para processamento paralelo e distribuído
 Arquitetura de Computadores Sistemas computacionais para processamento paralelo e distribuído Prof. Marcos Quinet Universidade Federal Fluminense UFF Pólo Universitário de Rio das Ostras - PURO Processamento
Arquitetura de Computadores Sistemas computacionais para processamento paralelo e distribuído Prof. Marcos Quinet Universidade Federal Fluminense UFF Pólo Universitário de Rio das Ostras - PURO Processamento
Infraestrutura de Hardware. Processamento Paralelo Multicores, Multi-Threading e GPUs
 Infraestrutura de Hardware Processamento Paralelo Multicores, Multi-Threading e GPUs Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é entendido
Infraestrutura de Hardware Processamento Paralelo Multicores, Multi-Threading e GPUs Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é entendido
Universidade Federal de Campina Grande Unidade Acadêmica de Sistemas e Computação Curso de Bacharelado em Ciência da Computação.
 Universidade Federal de Campina Grande Unidade Acadêmica de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de Computadores I Organização e Arquitetura Básicas
Universidade Federal de Campina Grande Unidade Acadêmica de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de Computadores I Organização e Arquitetura Básicas
Capítulo 5 Livro do Mário Monteiro Conceituação. Elementos de projeto de memória cache
 Capítulo 5 Livro do Mário Monteiro Conceituação Princípio da localidade Funcionamento da memória cache Elementos de projeto de memória cache Mapeamento de dados MP/cache Algoritmos de substituição de dados
Capítulo 5 Livro do Mário Monteiro Conceituação Princípio da localidade Funcionamento da memória cache Elementos de projeto de memória cache Mapeamento de dados MP/cache Algoritmos de substituição de dados
Memória virtual. Pedro Cruz. EEL770 Sistemas Operacionais
 Memória virtual Pedro Cruz EEL770 Sistemas Operacionais Avisos Menos de um mês para a 1ª apresentação do trabalho Dia 22/9/2017 O que fizeram até agora? Análises Estratégias Problemas Soluções Presenças
Memória virtual Pedro Cruz EEL770 Sistemas Operacionais Avisos Menos de um mês para a 1ª apresentação do trabalho Dia 22/9/2017 O que fizeram até agora? Análises Estratégias Problemas Soluções Presenças
Sistemas Operacionais
 Sistemas Operacionais Aula 2 Introdução: conceitos, máquinas de níveis. Prof.: Edilberto M. Silva http://www.edilms.eti.br SO - Prof. Edilberto Silva O que é um sistema operacional? um provedor de abstrações
Sistemas Operacionais Aula 2 Introdução: conceitos, máquinas de níveis. Prof.: Edilberto M. Silva http://www.edilms.eti.br SO - Prof. Edilberto Silva O que é um sistema operacional? um provedor de abstrações
Processos O conceito de processos é fundamental para a implementação de um sistema multiprogramável. De uma maneira geral, um processo pode ser entend
 Concorrência Nos sistemas Monoprogramáveis somente um programa pode estar em execução por vez, permanecendo o processador dedicado a esta única tarefa. Os recursos como memória, processador e dispositivos
Concorrência Nos sistemas Monoprogramáveis somente um programa pode estar em execução por vez, permanecendo o processador dedicado a esta única tarefa. Os recursos como memória, processador e dispositivos
Memória Cache. Memória Cache. Localidade Espacial. Conceito de Localidade. Diferença de velocidade entre Processador/MP
 Departamento de Ciência da Computação - UFF Memória Cache Profa. Débora Christina Muchaluat Saade debora@midiacom.uff.br Memória Cache Capítulo 5 Livro do Mário Monteiro Conceituação Princípio da localidade
Departamento de Ciência da Computação - UFF Memória Cache Profa. Débora Christina Muchaluat Saade debora@midiacom.uff.br Memória Cache Capítulo 5 Livro do Mário Monteiro Conceituação Princípio da localidade
Tecnólogo em Análise e Desenvolvimento de Sistemas. Sistemas Operacionais (SOP A2)
") Tecnólogo em Análise e Desenvolvimento de Sistemas Sistemas Operacionais (SOP A2) Conceitos de Hardware e Software Referências: Arquitetura de Sistemas Operacionais. F. B. Machado, L. P. Maia. Editora
Tecnólogo em Análise e Desenvolvimento de Sistemas Sistemas Operacionais (SOP A2) Conceitos de Hardware e Software Referências: Arquitetura de Sistemas Operacionais. F. B. Machado, L. P. Maia. Editora
Algoritmos Computacionais
 UNIDADE 1 Processador e instruções Memórias Dispositivos de Entrada e Saída Software ARQUITETURA BÁSICA UCP Unidade central de processamento MEM Memória E/S Dispositivos de entrada e saída UCP UNIDADE
UNIDADE 1 Processador e instruções Memórias Dispositivos de Entrada e Saída Software ARQUITETURA BÁSICA UCP Unidade central de processamento MEM Memória E/S Dispositivos de entrada e saída UCP UNIDADE
Estrutura de Sistemas Operacionais. Capítulo 1: Introdução
 Estrutura de Sistemas Operacionais 1.1 Silberschatz, Galvin and Gagne 2005 Capítulo 1: Introdução O que faz um sistema operacional? Revisão da organização de um computador Revisão de alguns conceitos de
Estrutura de Sistemas Operacionais 1.1 Silberschatz, Galvin and Gagne 2005 Capítulo 1: Introdução O que faz um sistema operacional? Revisão da organização de um computador Revisão de alguns conceitos de
Sistemas de Memória. CES-25 Arquiteturas para Alto Desmpenho. Paulo André Castro
 Sistemas de Memória Arquiteturas para Alto Desmpenho Prof. pauloac@ita.br Sala 110 Prédio da Computação www.comp.ita.br/~pauloac Memória: O Gargalo de Von Neuman Memória principal: considerada como sendo
Sistemas de Memória Arquiteturas para Alto Desmpenho Prof. pauloac@ita.br Sala 110 Prédio da Computação www.comp.ita.br/~pauloac Memória: O Gargalo de Von Neuman Memória principal: considerada como sendo
Organização e comunicação em plataformas paralelas
 Organização e comunicação em plataformas paralelas Processamento Paralelo Prof. Oberlan Romão Departamento de Computação e Eletrônica DCEL Centro Universitário Norte do Espírito Santo CEUNES Universidade
Organização e comunicação em plataformas paralelas Processamento Paralelo Prof. Oberlan Romão Departamento de Computação e Eletrônica DCEL Centro Universitário Norte do Espírito Santo CEUNES Universidade
Arranjo de Processadores
 Um arranjo síncrono de processadores paralelos é chamado arranjo de processadores, consistindo de múltiplos elementos processadores (EPs) sob a supervisão de uma unidade de controle (UC) Arranjo de processadores
Um arranjo síncrono de processadores paralelos é chamado arranjo de processadores, consistindo de múltiplos elementos processadores (EPs) sob a supervisão de uma unidade de controle (UC) Arranjo de processadores
Intel Thread Building Blocks (TBB)
") Intel Thread Building Blocks (TBB) MCZA020-13 - Programação Paralela Emilio Francesquini e.francesquini@ufabc.edu.br 2019.Q1 Centro de Matemática, Computação e Cognição Universidade Federal do ABC Disclaimer
Intel Thread Building Blocks (TBB) MCZA020-13 - Programação Paralela Emilio Francesquini e.francesquini@ufabc.edu.br 2019.Q1 Centro de Matemática, Computação e Cognição Universidade Federal do ABC Disclaimer
Processo. Gerência de Processos. Um programa em execução. Centro de Informática/UFPE :: Infraestrutura de Software
 Processo Um programa em execução Gerência de Processos Contexto de Processo Conjunto de Informações para gerenciamento de processo CPU: Registradores Memória: Posições em uso E/S: Estado das requisições
Processo Um programa em execução Gerência de Processos Contexto de Processo Conjunto de Informações para gerenciamento de processo CPU: Registradores Memória: Posições em uso E/S: Estado das requisições
Elementos de conexão e condições de paralelismo. Aleardo Manacero Jr.
 Elementos de conexão e condições de paralelismo Aleardo Manacero Jr. Elementos de Conexão O que é conectividade? Define como os elementos de processamento (CPU e memória) de um sistema de alto desempenho
Elementos de conexão e condições de paralelismo Aleardo Manacero Jr. Elementos de Conexão O que é conectividade? Define como os elementos de processamento (CPU e memória) de um sistema de alto desempenho
Processo. Gerência de Processos. Um programa em execução. Centro de Informática/UFPE :: Infraestrutura de Software
 Processo Um programa em execução Gerência de Processos Contexto de Processo Conjunto de Informações para gerenciamento de processo CPU: Registradores Memória: Posições em uso E/S: Estado das requisições
Processo Um programa em execução Gerência de Processos Contexto de Processo Conjunto de Informações para gerenciamento de processo CPU: Registradores Memória: Posições em uso E/S: Estado das requisições
Atol Fortin, Bruno da Hora, Lucas Piva, Marcela Ortega, Natan Lima, Pedro Raphael, Ricardo Sider, Rogério Papetti. 28 de novembro de 2008
 Reinventando a Computação Atol Fortin, Bruno da Hora, Lucas Piva, Marcela Ortega, Natan Lima, Pedro Raphael, Ricardo Sider, Rogério Papetti Universidade de São Paulo 28 de novembro de 2008 Introdução Dr.
Reinventando a Computação Atol Fortin, Bruno da Hora, Lucas Piva, Marcela Ortega, Natan Lima, Pedro Raphael, Ricardo Sider, Rogério Papetti Universidade de São Paulo 28 de novembro de 2008 Introdução Dr.
3 Computação de Propósito Geral em Unidades de Processamento Gráfico
 3 Computação de Propósito Geral em Unidades de Processamento Gráfico As Unidades de Processamento Gráfico (GPUs) foram originalmente desenvolvidas para o processamento de gráficos e eram difíceis de programar.
3 Computação de Propósito Geral em Unidades de Processamento Gráfico As Unidades de Processamento Gráfico (GPUs) foram originalmente desenvolvidas para o processamento de gráficos e eram difíceis de programar.
ESTRATÉGIAS DE ALOCAÇÃO AULA 11 Sistemas Operacionais Gil Eduardo de Andrade
 ESTRATÉGIAS DE ALOCAÇÃO AULA 11 Sistemas Operacionais Gil Eduardo de Andrade O conteúdo deste documento é baseado no livro do Prof. Dr. Carlos Alberto Maziero, disponível no link: http://dainf.ct.utfpr.edu.br/~maziero
ESTRATÉGIAS DE ALOCAÇÃO AULA 11 Sistemas Operacionais Gil Eduardo de Andrade O conteúdo deste documento é baseado no livro do Prof. Dr. Carlos Alberto Maziero, disponível no link: http://dainf.ct.utfpr.edu.br/~maziero
Dispositivos de Entrada e Saída
 Departamento de Ciência da Computação - UFF Dispositivos de Entrada e Saída Prof. Marcos A. A. Guerine mguerine@ic.uff.br 1 Dipositivos periféricos ou simplesmente periféricos permitem a comunicação da
Departamento de Ciência da Computação - UFF Dispositivos de Entrada e Saída Prof. Marcos A. A. Guerine mguerine@ic.uff.br 1 Dipositivos periféricos ou simplesmente periféricos permitem a comunicação da