Métodos baseados em árvores
|
|
|
- Lucas Gabriel do Amaral Porto
- 5 Há anos
- Visualizações:
Transcrição

1 Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Métodos baseados em árvores Eduardo Vargas Ferreira
2 Introdução Árvore de decisão é o conjunto de regras que envolvem a estratificação ou segmentação do espaço de predição em regiões simples; Nesta seção vamos descrever os métodos baseados em árvores no contexto de regressão e classificação. 2
3 Exemplo: Hitters data set - Baseball salary Queremos prever o Salary dos jogadores baseado nos Years em que está na Major leagues e número de Hits no ano; Os salários mais baixos são codificados pelas cores azul e verde, e mais altos pelas cores amarelo e vermelho; 3
4 Exemplo: Hitters data set - Baseball salary 238 R 3 Hits R R Years 1 R 1 = {X Years < 4.5} R 2 = {X Years 4.5, Hits < 117.5} R 3 = {X Years 4.5, Hits 117.5} 4
5 Exemplo: Hitters data set - Baseball salary 238 Years < 4.5 R 3 Hits R R Hits < Years R 1 = {X Years < 4.5} R 2 = {X Years 4.5, Hits < 117.5} R 3 = {X Years 4.5, Hits 117.5} 5
6 Como o algoritmo funciona? O objetivo é encontrar os retângulos R 1,..., R J que minimiza a: SQRes = (y i ŷ R1 ) 2 + (y i ŷ R2 ) 2, i:x i R 1 (j,s) i:x i R 2 (j,s) em que R 1(j, s) = {X X j < s} e R 2(j, s) = {X X j s}. 238 R 3 Hits R R Years 1 6
7 Como o algoritmo funciona? Alto vício e baixa variância Baixo vício e alta variância 7
8 Cost complexity pruning Para cada valor de λ, temos uma subárvore T T 0, tal que SQRes λ = seja o menor possível. T m=1 i:x i R m (y i ŷ Rm ) 2 + λ T T indica o número de terminal nodes da árvore T ; R m é o retângulo correspondente ao m-ésimo terminal node; ŷ Rm é a média das observações dos dados de treino em R m. Selecionamos o valor ótimo, ˆλ, através de validação. Em seguida, obtemos a subárvore utilizando ˆλ. 8
9 Exemplo: Hitters data set - Baseball salary O erro mínimo na validação cruzada ocorre na árvore de tamanho 3. Mean Squared Error Training Cross Validation Test Tree Size 9
10 Exemplo: heart disease - HD Os dados contêm o diagnóstico de 303 pacientes com dores no peito: Yes: indica a presença de doença cardíaca; No: indica ausência de doença cardíaca; Os dados apresentam 13 preditores incluindo Age, Sex, Chol, e outras medidas de funções cardíacas e pulmonar; Thal:a Ca < 0.5 Ca < 0.5 Slope < 1.5 Oldpeak < 1.1 Chol < 244 MaxHR < 156 MaxHR < No Yes No RestBP < 157 No MaxHR < Yes No ChestPain:bc Chol < 244 Sex < 0.5 No No No Yes Age < 52 Thal:b ChestPain:a Yes No No No Yes RestECG < 1 Yes Yes Yes 10
11 MaxHR < RestBP < 157 Exemplo: heart Chol < 244 disease - HD No Chol < 244 Sex < 0.5 MaxHR < 156 MaxHR < No Yes No No Yes ChestPain:bc No No No Yes Age < 52 Yes No No Thal:b ChestPain:a No Yes RestECG < 1 Yes Yes Yes Após validação cruzada chegamos na árvore com seis terminal nodes; Error Training Cross Validation Test MaxHR < No No Ca < 0.5 ChestPain:bc Thal:a Yes Ca < 0.5 Yes No Yes Tree Size Note que, em MaxHR temos duas respostas No. Isto se deve a um dos nós ser puro e o outro ser majoritariamente No. 11

12 Árvores versus modelos lineares Modelo linear Árvores 12
13 Prós e contras das Árvores de decisão Podem ser aplicadas em problemas de regressão e classificação; Lidam bem com dados faltantes; São simples e úteis para interpretação. Sendo muito bons nas etapas iniciais de um projeto; χ São mais simples do que deveriam. Por esse motivo, em termos de predição, não são competitivos com outras abordagens de aprendizado supervisionado; Mas, serve de base para outros métodos, como: Bagging; Random Forests; Boosting. 13
14 Ensembles 14
15 Ideia do Bootstrap 15
16 Bagging 16
17 Bagging Geramos B conjuntos de observações (bootstrapped). Treinamos o modelo a fim de obter a predição no ponto x; Em seguida, calculamos a média das predições (chamamos de bagging): ĥ bag (x) = 1 B B ĥ b (x). b=1 17
18 Random Forests 18
19 Random Forests No Random forests, para cada partição, temos uma seleção aleatória de m preditores, de um total de p (tipicamente, m p); Assim, forçamos com que diferentes preditores sejam escolhidos (decorrelating the trees). Se m = p, estaremos no método Bagging. 19
20 Exemplo: Heart data set Abaixo, o erro do teste como função de B. A linha tracejada representa o erro utilizando uma árvore somente; Error Test: Bagging Test: RandomForest OOB: Bagging OOB: RandomForest Number of Trees 20
21 Out-of-Bag Error Estimation 21
22 Métodos boosting 22
23 Qual a importância dos resíduos? 23
24 Qual a importância dos resíduos? Lembrando de regressão n (y i ȳ) 2 = i=1 } {{ } SQT n (ŷ i ȳ) 2 + i=1 } {{ } SQR n (y i ŷ) 2. i=1 } {{ } SQE E, geometricamente, temos Isso quer dizer que toda variabilidade não explicada pela regressão ficará no resíduo (variáveis e funções delas!). 24
25 Qual a importância dos resíduos? No exemplo abaixo, estamos avaliando a relação entre consumo de combustível e potência do automóvel. mpg = β 0 + β 1 (cavalo vapor) + ε Milhas por galão Linear Resíduos Gráfico de resíduos para o ajuste linear Cavalo-vapor Valores ajustados 25
26 Qual a importância dos resíduos? No exemplo abaixo, estamos avaliando a relação entre consumo de combustível e potência do automóvel. mpg = β 0 + β 1 (cavalo vapor) + β 2 (cavalo vapor) 2 + ε Gráfico de resíduos para o ajuste quadrático Milhas por galão Linear Grau 2 Resíduos Cavalo-vapor Valores ajustados 26
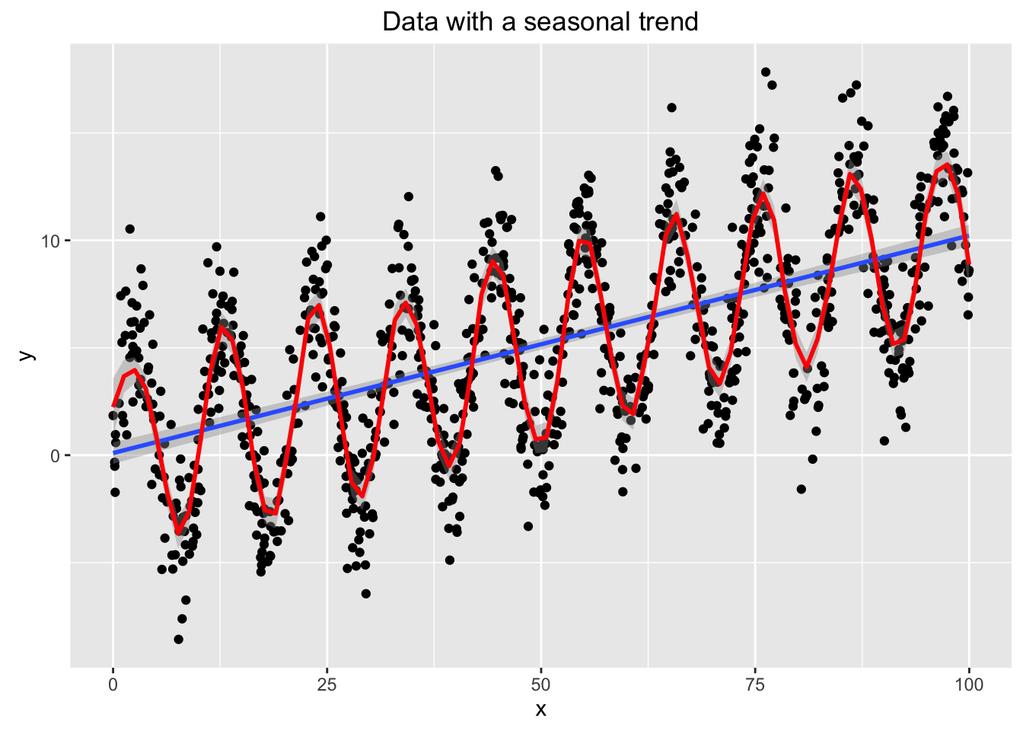

27 Qual a importância dos resíduos? 27
28 Métodos boosting mpg = β 0 + β 1 (cavalo vapor) + residuo Milhas por galão Linear Resíduos Gráfico de resíduos para o ajuste linear Cavalo-vapor Valores ajustados residuo = β 2 (cavalo vapor) 2 + residuo2 mpg = β 0 + β 1 (cavalo vapor) + β 2 (cavalo vapor) 2 + residuo2 28
29 Métodos boosting mpg = β 0 + β 1 (cavalo vapor) + residuo Resíduos Gráfico de resíduos para o ajuste linear Milhas por galão Grau Cavalo-vapor Cavalo-vapor residuo = β 2 (cavalo vapor) 2 + residuo2 mpg = β 0 + β 1 (cavalo vapor) + β 2 (cavalo vapor) 2 + residuo2 29
30 Adaptive Boosting (AdaBoost) 30

31 Adaptive Boosting (AdaBoost) O princípio básico do Boosting é propor um modelo básico (weak learner) e o aprimorá-lo em cada iteração. O processo consiste em filtrar os resultados corretos, e concentrar-se naqueles que o modelo não soube lidar; Nesse caso, os weak learners, são árvores de decisão com uma separação apenas (chamada de decision stumps). 31
32 Como o algoritmo funciona? 1 Inicie com ĥ(x) = 0 e r i = y i, para todo i dos dados de treino; 2 Para b = 1, 2,..., B, repita: a) Ajuste a árvore ĥ b com d divisões para os dados de treino (X, r); b) Atualize ĥ adicionando uma nova versão à árvore anterior: ĥ(x) ĥ(x) + αĥb (x). c) Atualize os resíduos, r i r i αĥb (x i ). 3 O modelo de saída fica então, B ĥ(x) = αĥ b (x). b=1 32
33 Exemplo simulado Considere o exemplo simulado, obtido a partir da função: ( x ) f (x) = , 05x + 2sin 10 33

34 Exemplo simulado O processo consiste em analisar o resíduo decorrente do modelo anterior e somar novas árvores, suprindo tais deficiências. 34


35 Adaptive Boosting (AdaBoost) A ideia é ponderar os erros para que nas próximas árvores eles tenham mais importância. Em seguida, combinar os classificadores. Não vamos entrar em detalhes teóricos da abordagem. Para o aluno interessado sugere-se Elements of Statistical Learning, capítulo
36 Exemplo: Expressão gênica Os dados consistem na medida de expressão de genes dos tecidos de 349 pacientes; Test Classification Error Boosting: depth=1 Boosting: depth=2 RandomForest: m= p Cada paciente possui um marcador qualitativo (de 15 níveis): Normal; Ou 14 tipos de câncer; Number of Trees A forma de construção do boosting (baseado nas árvores anteriores) faz com que ele faça um bom trabalho mesmo com uma partição apenas. 36
37 Referências James, G., Witten, D., Hastie, T. e Tibshirani, An Introduction to Statistical Learning, 2013; Hastie, T., Tibshirani, R. e Friedman, J., The Elements of Statistical Learning, 2009; Lantz, B., Machine Learning with R, Packt Publishing, 2013; Tan, Steinbach, and Kumar, Introduction to Data Mining, Addison-Wesley, 2005; Some of the figures in this presentation are taken from An Introduction to Statistical Learning, with applications in R (Springer, 2013) with permission from the authors: G. James, D. Witten, T. Hastie and R. Tibshirani 37
Métodos baseados em árvores
 Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Métodos baseados em árvores Profs.: Eduardo Vargas Ferreira Walmes Marques Zeviani Introdução Nesta seção vamos descrever
Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Métodos baseados em árvores Profs.: Eduardo Vargas Ferreira Walmes Marques Zeviani Introdução Nesta seção vamos descrever
Support Vector Machines
 Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Support Vector Machines Eduardo Vargas Ferreira Definição Support Vector Machines são baseados no conceito de planos de decisão
Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Support Vector Machines Eduardo Vargas Ferreira Definição Support Vector Machines são baseados no conceito de planos de decisão
Métodos de reamostragem
 Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Métodos de reamostragem Eduardo Vargas Ferreira Função custo 2 Função custo Matriz de confusão: é um layout de tabela que
Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Métodos de reamostragem Eduardo Vargas Ferreira Função custo 2 Função custo Matriz de confusão: é um layout de tabela que
Gradiente descendente
 Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Gradiente descendente Eduardo Vargas Ferreira Solução de quadrados mínimos Teorema: Seja X M n p (R), com n > p e posto(x
Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Gradiente descendente Eduardo Vargas Ferreira Solução de quadrados mínimos Teorema: Seja X M n p (R), com n > p e posto(x
Árvores de decisão e seus refinamentos na predição genômica da resistência à ferrugem alaranjada em café arábica
 Árvores de decisão e seus refinamentos na predição genômica da resistência à ferrugem alaranjada em café arábica Ithalo Coelho de Sousa ithalo.coelho@gmail.com Programa de Pós-Graduação em Estatística
Árvores de decisão e seus refinamentos na predição genômica da resistência à ferrugem alaranjada em café arábica Ithalo Coelho de Sousa ithalo.coelho@gmail.com Programa de Pós-Graduação em Estatística
Aprendizado não supervisionado
 Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Aprendizado não supervisionado Profs.: Eduardo Vargas Ferreira Walmes Marques Zeviani Métodos de aprendizagem não supervisionada
Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Aprendizado não supervisionado Profs.: Eduardo Vargas Ferreira Walmes Marques Zeviani Métodos de aprendizagem não supervisionada
Profs.: Eduardo Vargas Ferreira Walmes Marques Zeviani
 Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Introdução Profs.: Eduardo Vargas Ferreira Walmes Marques Zeviani O que é Machine Learning? Estatística Machine Learning
Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Introdução Profs.: Eduardo Vargas Ferreira Walmes Marques Zeviani O que é Machine Learning? Estatística Machine Learning
Aprendizado não supervisionado
 Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Aprendizado não supervisionado Eduardo Vargas Ferreira Supervisionado vs não supervisionado 2 Análise de Componentes Principais
Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Aprendizado não supervisionado Eduardo Vargas Ferreira Supervisionado vs não supervisionado 2 Análise de Componentes Principais
Regressão Linear. Prof. Dr. Leandro Balby Marinho. Análise de Dados II. Introdução Regressão Linear Regressão Múltipla
 Regressão Linear Prof. Dr. Leandro Balby Marinho Análise de Dados II Prof. Leandro Balby Marinho 1 / 36 UFCG DSC Roteiro 1. Introdução 2. Regressão Linear 3. Regressão Múltipla Prof. Leandro Balby Marinho
Regressão Linear Prof. Dr. Leandro Balby Marinho Análise de Dados II Prof. Leandro Balby Marinho 1 / 36 UFCG DSC Roteiro 1. Introdução 2. Regressão Linear 3. Regressão Múltipla Prof. Leandro Balby Marinho
Múltiplos Classificadores
 Universidade Federal do Paraná (UFPR) Bacharelado em Informátia Biomédica Múltiplos Classificadores David Menotti www.inf.ufpr.br/menotti/ci171-182 Hoje Múltiplos classificadores Combinação de classificadores
Universidade Federal do Paraná (UFPR) Bacharelado em Informátia Biomédica Múltiplos Classificadores David Menotti www.inf.ufpr.br/menotti/ci171-182 Hoje Múltiplos classificadores Combinação de classificadores
Eduardo Vargas Ferreira
 Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Considerações finais Eduardo Vargas Ferreira Como obter boas predições 1 Entenda os dados: explore as características, crie
Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Considerações finais Eduardo Vargas Ferreira Como obter boas predições 1 Entenda os dados: explore as características, crie
Eduardo Vargas Ferreira
 Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Introdução Eduardo Vargas Ferreira O que é Machine Learning? Estatística Machine Learning Ciência da computação Métodos aplicados
Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Introdução Eduardo Vargas Ferreira O que é Machine Learning? Estatística Machine Learning Ciência da computação Métodos aplicados
Prof.: Eduardo Vargas Ferreira
 Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Introdução Prof.: Eduardo Vargas Ferreira O que é Machine Learning? Estatística Data Mining 2 O que é Machine Learning? Estatística
Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Introdução Prof.: Eduardo Vargas Ferreira O que é Machine Learning? Estatística Data Mining 2 O que é Machine Learning? Estatística
Aprendizado de Máquina. Combinando Classificadores
 Universidade Federal do Paraná (UFPR) Departamento de Informática (DInf) Aprendizado de Máquina Combinando Classificadores David Menotti, Ph.D. web.inf.ufpr.br/menotti Introdução O uso de vários classificadores
Universidade Federal do Paraná (UFPR) Departamento de Informática (DInf) Aprendizado de Máquina Combinando Classificadores David Menotti, Ph.D. web.inf.ufpr.br/menotti Introdução O uso de vários classificadores
Profs.: Eduardo Vargas Ferreira Walmes Marques Zeviani
 Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Regularização Profs.: Eduardo Vargas Ferreira Walmes Marques Zeviani Introdução: Regressão Linear Considere o exemplo referente
Universidade Federal do Paraná Laboratório de Estatística e Geoinformação - LEG Regularização Profs.: Eduardo Vargas Ferreira Walmes Marques Zeviani Introdução: Regressão Linear Considere o exemplo referente
Christopher Bishop, Pattern Recognition and Machine Learning, Springer, 2006 capítulo 14
 Combinação de modelos Christopher Bishop, Pattern Recognition and Machine Learning, Springer, 2006 capítulo 4 Motivação Habitualmente, experimenta-se vários algoritmos (ou o mesmo com diferentes hiperparâmetros)
Combinação de modelos Christopher Bishop, Pattern Recognition and Machine Learning, Springer, 2006 capítulo 4 Motivação Habitualmente, experimenta-se vários algoritmos (ou o mesmo com diferentes hiperparâmetros)
TACG GWAS utilizando Random Forest: estudo de caso em bovinos de corte
 TACG GWAS utilizando Random Forest: estudo de caso em bovinos de corte Roberto H. Higa Juiz de Fora, 2 a 6 de setembro de 2013 Sumário» Introdução» Random Forest» Estudo com dados simulados» Estudo de
TACG GWAS utilizando Random Forest: estudo de caso em bovinos de corte Roberto H. Higa Juiz de Fora, 2 a 6 de setembro de 2013 Sumário» Introdução» Random Forest» Estudo com dados simulados» Estudo de
Aula 3: Random Forests
 Aula 3: Random Forests Paulo C. Marques F. Aula ministrada no Insper 26 de Fevereiro de 2016 Insper Random Forests 26 de Fevereiro de 2016 1 / 18 Árvores de classificação Estamos no mesmo contexto de aprendizagem
Aula 3: Random Forests Paulo C. Marques F. Aula ministrada no Insper 26 de Fevereiro de 2016 Insper Random Forests 26 de Fevereiro de 2016 1 / 18 Árvores de classificação Estamos no mesmo contexto de aprendizagem
BERT: Melhorando Classificação de Texto com Árvores Extremamente Aleatórias, Bagging e Boosting
 BERT: Melhorando Classificação de Texto com Árvores Extremamente Aleatórias, Bagging e Boosting Raphael R. Campos 1, Marcos A. Gonçalves 1 1 Departamento de Ciência da Computação - Universidade Federal
BERT: Melhorando Classificação de Texto com Árvores Extremamente Aleatórias, Bagging e Boosting Raphael R. Campos 1, Marcos A. Gonçalves 1 1 Departamento de Ciência da Computação - Universidade Federal
Fundamentos de Aprendizagem Estatística: Regressão
 Fundamentos de Aprendizagem Estatística: Regressão Paulo C. Marques F. e Hedibert F. Lopes Sexta-feira, 20 de Outubro de 2017 1 / 37 Aprendizagem supervisionada (1) Para um determinado fenômeno, temos
Fundamentos de Aprendizagem Estatística: Regressão Paulo C. Marques F. e Hedibert F. Lopes Sexta-feira, 20 de Outubro de 2017 1 / 37 Aprendizagem supervisionada (1) Para um determinado fenômeno, temos
Mineração de Dados - II
 Tópicos Especiais: INTELIGÊNCIA DE NEGÓCIOS II Mineração de Dados - II Sylvio Barbon Junior barbon@uel.br 10 de julho de 2015 DC-UEL Sylvio Barbon Jr 1 Sumário Etapa II Algoritmos Básicos Weka: Framework
Tópicos Especiais: INTELIGÊNCIA DE NEGÓCIOS II Mineração de Dados - II Sylvio Barbon Junior barbon@uel.br 10 de julho de 2015 DC-UEL Sylvio Barbon Jr 1 Sumário Etapa II Algoritmos Básicos Weka: Framework
ANÁLISE DE BIG DATA E INTELIGÊNCIA ARTIFICIAL PARA A ÁREA MÉDICA
 CURTA DURAÇÃO ANÁLISE DE BIG DATA E INTELIGÊNCIA ARTIFICIAL PARA A ÁREA MÉDICA CARGA HORÁRIA: 80 horas COORDENAÇÃO: Prof.ª Dr.ª Alessandra de Ávila Montini OBJETIVOS Introduzir o conceito de Big Data,
CURTA DURAÇÃO ANÁLISE DE BIG DATA E INTELIGÊNCIA ARTIFICIAL PARA A ÁREA MÉDICA CARGA HORÁRIA: 80 horas COORDENAÇÃO: Prof.ª Dr.ª Alessandra de Ávila Montini OBJETIVOS Introduzir o conceito de Big Data,
APRENDIZAGEM DE MÁQUINA
 APRENDIZAGEM DE MÁQUINA (usando Python) Thiago Marzagão ÁRVORE DE DECISÃO & VALIDAÇÃO Thiago Marzagão APRENDIZAGEM DE MÁQUINA 1 / 20 árvore de decisão Aulas passadas: queríamos prever variáveis quantitativas.
APRENDIZAGEM DE MÁQUINA (usando Python) Thiago Marzagão ÁRVORE DE DECISÃO & VALIDAÇÃO Thiago Marzagão APRENDIZAGEM DE MÁQUINA 1 / 20 árvore de decisão Aulas passadas: queríamos prever variáveis quantitativas.
Modelo de Regressão Múltipla
 Modelo de Regressão Múltipla Modelo de Regressão Linear Simples Última aula: Y = α + βx + i i ε i Y é a variável resposta; X é a variável independente; ε representa o erro. 2 Modelo Clássico de Regressão
Modelo de Regressão Múltipla Modelo de Regressão Linear Simples Última aula: Y = α + βx + i i ε i Y é a variável resposta; X é a variável independente; ε representa o erro. 2 Modelo Clássico de Regressão
Thiago Marzagão 1. 1 Thiago Marzagão (Universidade de Brasília) MINERAÇÃO DE DADOS 1 / 21
 MINERAÇÃO DE DADOS 1 / 21") MINERAÇÃO DE DADOS Thiago Marzagão 1 1 marzagao.1@osu.edu ÁRVORE DE DECISÃO & VALIDAÇÃO Thiago Marzagão (Universidade de Brasília) MINERAÇÃO DE DADOS 1 / 21 árvore de decisão Aulas passadas: queríamos
MINERAÇÃO DE DADOS Thiago Marzagão 1 1 marzagao.1@osu.edu ÁRVORE DE DECISÃO & VALIDAÇÃO Thiago Marzagão (Universidade de Brasília) MINERAÇÃO DE DADOS 1 / 21 árvore de decisão Aulas passadas: queríamos
Análise de Regressão Prof. MSc. Danilo Scorzoni Ré FMU Estatística Aplicada
 Aula 2 Regressão Linear Simples Análise de Regressão Prof. MSc. Danilo Scorzoni Ré FMU Estatística Aplicada Conceitos Gerais A análise de regressão é utilizada para explicar ou modelar a relação entre
Aula 2 Regressão Linear Simples Análise de Regressão Prof. MSc. Danilo Scorzoni Ré FMU Estatística Aplicada Conceitos Gerais A análise de regressão é utilizada para explicar ou modelar a relação entre
Combinação de Classificadores (seleção)
") Combinação de Classificadores (seleção) André Tavares da Silva andre.silva@udesc.br Livro da Kuncheva Roteiro Seleção de classificadores Estimativa independente de decisão Estimativa dependente de decisão
Combinação de Classificadores (seleção) André Tavares da Silva andre.silva@udesc.br Livro da Kuncheva Roteiro Seleção de classificadores Estimativa independente de decisão Estimativa dependente de decisão
Prevendo Desempenho dos Candidatos do ENEM Através de Dados Socioeconômicos
 Prevendo Desempenho dos Candidatos do ENEM Através de Dados Socioeconômicos Bernardo Stearns 1, Flavio Rangel 1, Fabrício Firmino 2, Fabio Rangel 12, Jonice Oliveira 12 1 Departamento de Ciência da Computação
Prevendo Desempenho dos Candidatos do ENEM Através de Dados Socioeconômicos Bernardo Stearns 1, Flavio Rangel 1, Fabrício Firmino 2, Fabio Rangel 12, Jonice Oliveira 12 1 Departamento de Ciência da Computação
Agregação de Algoritmos de Aprendizado de Máquina (AM) Professor: Eduardo R. Hruschka Estagiário PAE: Luiz F. S. Coletta
 Professor: Eduardo R. Hruschka Estagiário PAE: Luiz F. S. Coletta") Agregação de Algoritmos de Aprendizado de Máquina (AM) Professor: Eduardo R. Hruschka Estagiário PAE: Luiz F. S. Coletta (luizfsc@icmc.usp.br) Sumário 1. Motivação 2. Bagging 3. Random Forest 4. Boosting
Agregação de Algoritmos de Aprendizado de Máquina (AM) Professor: Eduardo R. Hruschka Estagiário PAE: Luiz F. S. Coletta (luizfsc@icmc.usp.br) Sumário 1. Motivação 2. Bagging 3. Random Forest 4. Boosting
Aula 8: Árvores. Rafael Izbicki 1 / 33
 Mineração de Dados Aula 8: Árvores Rafael Izbicki 1 / 33 Revisão Vimos que a função de risco é dada por R(g) := E[I(Y g(x))] = P (Y g(x)), Nem sempre tal função nos traz toda informação sobre g. É comum
Mineração de Dados Aula 8: Árvores Rafael Izbicki 1 / 33 Revisão Vimos que a função de risco é dada por R(g) := E[I(Y g(x))] = P (Y g(x)), Nem sempre tal função nos traz toda informação sobre g. É comum
Árvores de Classificação e Regressão
 Árvores de Classificação e Regressão Paulo C. Marques F. e Hedibert F. Lopes Sexta-feira, 10 de Novembro de 2017 1 / 28 Árvores de classificação Continuamos no contexto de aprendizagem supervisionada.
Árvores de Classificação e Regressão Paulo C. Marques F. e Hedibert F. Lopes Sexta-feira, 10 de Novembro de 2017 1 / 28 Árvores de classificação Continuamos no contexto de aprendizagem supervisionada.
Métodos de Análise de Dados (AO-802)
") Métodos de Análise de Dados (AO-802) DADOS INFORMAÇÃO CONHECIMENTO Rodrigo A. Scarpel rodrigo@ita.br www.ief.ita.br/~rodrigo INTELIGÊNCIA Introdução: Revolução dos Serviços (final anos 80) Dilúvio de dados
Métodos de Análise de Dados (AO-802) DADOS INFORMAÇÃO CONHECIMENTO Rodrigo A. Scarpel rodrigo@ita.br www.ief.ita.br/~rodrigo INTELIGÊNCIA Introdução: Revolução dos Serviços (final anos 80) Dilúvio de dados
SCC0173 Mineração de Dados Biológicos
 SCC0173 Mineração de Dados Biológicos Classificação I: Algoritmos 1Rule e KNN Prof. Ricardo J. G. B. Campello SCC / ICMC / USP 1 Créditos O material a seguir consiste de adaptações e extensões dos originais:
SCC0173 Mineração de Dados Biológicos Classificação I: Algoritmos 1Rule e KNN Prof. Ricardo J. G. B. Campello SCC / ICMC / USP 1 Créditos O material a seguir consiste de adaptações e extensões dos originais:
Sistema preditivo automatizado de saída em UTI: uma inovação
 Sistema preditivo automatizado de saída em UTI: uma inovação Hudson F. Golino, MSc., Ph.D (Cand.) Sistema preditivo automatizado de saída em UTI: uma inovação tecnológica Conteúdo Conteúdo... 2 Resumo...
Sistema preditivo automatizado de saída em UTI: uma inovação Hudson F. Golino, MSc., Ph.D (Cand.) Sistema preditivo automatizado de saída em UTI: uma inovação tecnológica Conteúdo Conteúdo... 2 Resumo...
Aula 2 Uma breve revisão sobre modelos lineares
 Aula Uma breve revisão sobre modelos lineares Processo de ajuste de um modelo de regressão O ajuste de modelos de regressão tem como principais objetivos descrever relações entre variáveis, estimar e testar
Aula Uma breve revisão sobre modelos lineares Processo de ajuste de um modelo de regressão O ajuste de modelos de regressão tem como principais objetivos descrever relações entre variáveis, estimar e testar
Estatística e Matemática Aplicadas a Data Science. Diógenes Justo BM&FBOVESPA & Professor FIAP
 Estatística e Matemática Aplicadas a Data Science Diógenes Justo BM&FBOVESPA & Professor FIAP Agenda Modelagem para Data Science (Matemática e Estatística) Detecção de Fraudes Forecast (financeiro) Conclusões
Estatística e Matemática Aplicadas a Data Science Diógenes Justo BM&FBOVESPA & Professor FIAP Agenda Modelagem para Data Science (Matemática e Estatística) Detecção de Fraudes Forecast (financeiro) Conclusões
Estratégias para Classificação Binária Um estudo de caso com classificação de s
 CE064 - INTRODUÇÃO AO MACHINE LEARNING Estratégias para Classificação Binária Um estudo de caso com classificação de e-mails Eduardo Elias Ribeiro Junior * 04 de julho de 2016 Resumo Em Machine Learning
CE064 - INTRODUÇÃO AO MACHINE LEARNING Estratégias para Classificação Binária Um estudo de caso com classificação de e-mails Eduardo Elias Ribeiro Junior * 04 de julho de 2016 Resumo Em Machine Learning
Classificação e Predição de Dados - Profits Consulting - Consultoria Empresarial - Serviços SAP- CRM Si
 Classificação e Predição de Dados - Profits Consulting - Consultoria Empresarial - Serviços SAP- CRM Si Classificação de Dados Os modelos de classificação de dados são preditivos, pois desempenham inferências
Classificação e Predição de Dados - Profits Consulting - Consultoria Empresarial - Serviços SAP- CRM Si Classificação de Dados Os modelos de classificação de dados são preditivos, pois desempenham inferências
SISTEMAS BASEADOS EM ENSEMBLES DE CLASSIFICADORES
 SISTEMAS BASEADOS EM ENSEMBLES DE CLASSIFICADORES INTRODUÇÃO PROCESSO DE TOMADA DE DECISÕES Procuramos uma segunda, terceira ou quarta opinião. Tratando de assuntos financeiros, médicos, sociais entre
SISTEMAS BASEADOS EM ENSEMBLES DE CLASSIFICADORES INTRODUÇÃO PROCESSO DE TOMADA DE DECISÕES Procuramos uma segunda, terceira ou quarta opinião. Tratando de assuntos financeiros, médicos, sociais entre
Regressão Linear. Fabrício Olivetti de França. Universidade Federal do ABC
 Regressão Linear Fabrício Olivetti de França Universidade Federal do ABC Tópicos 1. Overfitting 2. Treino e Validação 3. Baseline dos modelos 1 Overfitting Overfit Em muitos casos, a amostra de dados coletada
Regressão Linear Fabrício Olivetti de França Universidade Federal do ABC Tópicos 1. Overfitting 2. Treino e Validação 3. Baseline dos modelos 1 Overfitting Overfit Em muitos casos, a amostra de dados coletada
Boas Maneiras em Aprendizado de Máquinas
 Universidade Federal do Paraná (UFPR) Bacharelado em Informática Biomédica Boas Maneiras em Aprendizado de Máquinas David Menotti www.inf.ufpr.br/menotti/ci171-182 Boas Maneiras Agenda Introdução Métricas
Universidade Federal do Paraná (UFPR) Bacharelado em Informática Biomédica Boas Maneiras em Aprendizado de Máquinas David Menotti www.inf.ufpr.br/menotti/ci171-182 Boas Maneiras Agenda Introdução Métricas
Aprendizado de Máquina
 Aprendizado de Máquina Introdução Luiz Eduardo S. Oliveira Universidade Federal do Paraná Departamento de Informática http://lesoliveira.net Luiz S. Oliveira (UFPR) Aprendizado de Máquina 1 / 19 Introdução
Aprendizado de Máquina Introdução Luiz Eduardo S. Oliveira Universidade Federal do Paraná Departamento de Informática http://lesoliveira.net Luiz S. Oliveira (UFPR) Aprendizado de Máquina 1 / 19 Introdução
Classificação de dados em modelos com resposta binária via algoritmo boosting e regressão logística
 Classificação de dados em modelos com resposta binária via algoritmo boosting e regressão logística Gilberto Rodrigues Liska 1 5 Fortunato Silva de Menezes 2 5 Marcelo Ângelo Cirillo 3 5 Mario Javier Ferrua
Classificação de dados em modelos com resposta binária via algoritmo boosting e regressão logística Gilberto Rodrigues Liska 1 5 Fortunato Silva de Menezes 2 5 Marcelo Ângelo Cirillo 3 5 Mario Javier Ferrua
Universidade de Brasília Instituto de Ciências Exatas Departamento de Estatística. Dissertação de Mestrado
 Universidade de Brasília Instituto de Ciências Exatas Departamento de Estatística Dissertação de Mestrado Métodos Estatísticos em Aprendizado de Máquinas para problemas de Classificação por Luana Lúcia
Universidade de Brasília Instituto de Ciências Exatas Departamento de Estatística Dissertação de Mestrado Métodos Estatísticos em Aprendizado de Máquinas para problemas de Classificação por Luana Lúcia
Modelos Múltiplos. João Gama Diferentes algoritmos de aprendizagem exploram:
 Modelos Múltiplos João Gama jgama@liacc.up.pt Modelos Múltiplos Diferentes algoritmos de aprendizagem exploram: Diferentes linguagens de representação. Diferentes espaços de procura. Diferentes funções
Modelos Múltiplos João Gama jgama@liacc.up.pt Modelos Múltiplos Diferentes algoritmos de aprendizagem exploram: Diferentes linguagens de representação. Diferentes espaços de procura. Diferentes funções
Aprendizagem de Máquina
 Plano de Aula Aprendizagem de Máquina Bagging,, Support Vector Machines e Combinação de Classificadores Alessandro L. Koerich Uma visão geral de diversos tópicos relacionados à Aprendizagem de Máquina:
Plano de Aula Aprendizagem de Máquina Bagging,, Support Vector Machines e Combinação de Classificadores Alessandro L. Koerich Uma visão geral de diversos tópicos relacionados à Aprendizagem de Máquina:
Árvore de Decisão. George Darmiton da Cunha Cavalcanti Tsang Ing Ren CIn/UFPE
 Árvore de Decisão George Darmiton da Cunha Cavalcanti Tsang Ing Ren CIn/UFPE Tópicos Introdução Representando Árvores de Decisão O algoritmo ID3 Definições Entropia Ganho de Informação Overfitting Objetivo
Árvore de Decisão George Darmiton da Cunha Cavalcanti Tsang Ing Ren CIn/UFPE Tópicos Introdução Representando Árvores de Decisão O algoritmo ID3 Definições Entropia Ganho de Informação Overfitting Objetivo
Seleção de Variáveis e Construindo o Modelo
 Seleção de Variáveis e Construindo o Modelo Seleção de modelos candidatos A idéia é selecionar um conjunto menor de variáveis explanatórias de acordo com algum(s) critério(s), e assim selecionar o modelo
Seleção de Variáveis e Construindo o Modelo Seleção de modelos candidatos A idéia é selecionar um conjunto menor de variáveis explanatórias de acordo com algum(s) critério(s), e assim selecionar o modelo
Disciplina de Modelos Lineares
 Disciplina de Modelos Lineares 2012-2 Seleção de Variáveis Professora Ariane Ferreira Em modelos de regressão múltipla é necessário determinar um subconjunto de variáveis independentes que melhor explique
Disciplina de Modelos Lineares 2012-2 Seleção de Variáveis Professora Ariane Ferreira Em modelos de regressão múltipla é necessário determinar um subconjunto de variáveis independentes que melhor explique
Documentos. Utilizando técnicas preditivas que combinam modelagem e seleção de atributos ISSN Dezembro,
 Documentos Dezembro, 2015 135 ISSN 1677-9274 Utilizando técnicas preditivas que combinam modelagem e seleção de atributos Empresa Brasileira de Pesquisa Agropecuária Embrapa Informática Agropecuária Ministério
Documentos Dezembro, 2015 135 ISSN 1677-9274 Utilizando técnicas preditivas que combinam modelagem e seleção de atributos Empresa Brasileira de Pesquisa Agropecuária Embrapa Informática Agropecuária Ministério
Bootstrap Aggregation (Bagging)
") Bootstrap Aggregation (Bagging) Paulo C. Marques F. e Hedibert F. Lopes Sexta-feira, 24 de Novembro de 2017 1 / 19 Função de distribuição empírica (1) Suponha que X 1,..., X n são variáveis aleatórias
Bootstrap Aggregation (Bagging) Paulo C. Marques F. e Hedibert F. Lopes Sexta-feira, 24 de Novembro de 2017 1 / 19 Função de distribuição empírica (1) Suponha que X 1,..., X n são variáveis aleatórias
Regressão. PRE-01 Probabilidade e Estatística Prof. Marcelo P. Corrêa IRN/Unifei
 Regressão PRE-01 Probabilidade e Estatística Prof. Marcelo P. Corrêa IRN/Unifei Regressão Introdução Analisar a relação entre duas variáveis (x,y) através da equação (equação de regressão) e do gráfico
Regressão PRE-01 Probabilidade e Estatística Prof. Marcelo P. Corrêa IRN/Unifei Regressão Introdução Analisar a relação entre duas variáveis (x,y) através da equação (equação de regressão) e do gráfico
Existem diversas formas de tratar dados e este conjunto de formas chama-se Data
 INSTITUCIONAL/IFSP PROJETO DE PESQUISA TÍTULO DO PROJETO: Text Mining na classificação de notícias Área do Conhecimento (Tabela do CNPq): 1. 0 3. 0 3. 0 0-6 1. RESUMO O volume de informações disponíveis
INSTITUCIONAL/IFSP PROJETO DE PESQUISA TÍTULO DO PROJETO: Text Mining na classificação de notícias Área do Conhecimento (Tabela do CNPq): 1. 0 3. 0 3. 0 0-6 1. RESUMO O volume de informações disponíveis
Regression and Clinical prediction models
 Regression and Clinical prediction models Session 6 Introducing statistical modeling Part 2 (Correlation and Linear regression) Pedro E A A do Brasil pedro.brasil@ini.fiocruz.br 2018 Objetivos Continuar
Regression and Clinical prediction models Session 6 Introducing statistical modeling Part 2 (Correlation and Linear regression) Pedro E A A do Brasil pedro.brasil@ini.fiocruz.br 2018 Objetivos Continuar
Aprendizado Bayesiano
 Aprendizado Bayesiano Marcelo K. Albertini 26 de Junho de 2014 2/20 Conteúdo Teorema de Bayes Aprendizado MAP Classificador ótimo de Bayes 3/20 Dois papéis para métodos bayesianos Algoritmos de aprendizado
Aprendizado Bayesiano Marcelo K. Albertini 26 de Junho de 2014 2/20 Conteúdo Teorema de Bayes Aprendizado MAP Classificador ótimo de Bayes 3/20 Dois papéis para métodos bayesianos Algoritmos de aprendizado
Mineração de Dados - Introdução. Elaine Ribeiro de Faria UFU 2018
 Mineração de Dados - Introdução Elaine Ribeiro de Faria UFU 2018 1 Mineração de Dados Processo de automaticamente descobrir informação útil em grandes repositórios de dados Tan P., SteinBack M. e Kumar
Mineração de Dados - Introdução Elaine Ribeiro de Faria UFU 2018 1 Mineração de Dados Processo de automaticamente descobrir informação útil em grandes repositórios de dados Tan P., SteinBack M. e Kumar
Aprendizado de Máquina
 Tópicos Aprendizado de Máquina Aula 3 http://www.ic.uff.br/~bianca/aa/. Introdução Cap. (6/03). Classificação Indutiva Cap. (3/03) 3. Cap. 3 (30/03) 4. Ensembles - Artigo (06/04) 5. Avaliação Experimental
Tópicos Aprendizado de Máquina Aula 3 http://www.ic.uff.br/~bianca/aa/. Introdução Cap. (6/03). Classificação Indutiva Cap. (3/03) 3. Cap. 3 (30/03) 4. Ensembles - Artigo (06/04) 5. Avaliação Experimental
O desempenho dos alunos dos cursos de Música no Enade 2014
 O desempenho dos alunos dos cursos de Música no Enade 2014 Neylson Crepalde, PhD Candidate. neylson.crepalde@izabelahendrix.edu.br http://neylsoncrepalde.github.io Grupo Interdisciplinar de Pesquisa em
O desempenho dos alunos dos cursos de Música no Enade 2014 Neylson Crepalde, PhD Candidate. neylson.crepalde@izabelahendrix.edu.br http://neylsoncrepalde.github.io Grupo Interdisciplinar de Pesquisa em
Tutorial básico de classificação em RapidMiner
 Tutorial básico de classificação em RapidMiner Mineração de dados biológicos Ciências físicas e biomoleculares Neste tutorial, aprenderemos a utilizar as funcionalidades básicas para classificação em Rapidminer.
Tutorial básico de classificação em RapidMiner Mineração de dados biológicos Ciências físicas e biomoleculares Neste tutorial, aprenderemos a utilizar as funcionalidades básicas para classificação em Rapidminer.
Introdução a Sistemas Inteligentes
 Introdução a Sistemas Inteligentes Conceituação Prof. Ricardo J. G. B. Campello ICMC / USP Créditos Parte do material a seguir consiste de adaptações e extensões dos originais gentilmente cedidos pelo
Introdução a Sistemas Inteligentes Conceituação Prof. Ricardo J. G. B. Campello ICMC / USP Créditos Parte do material a seguir consiste de adaptações e extensões dos originais gentilmente cedidos pelo
Tópicos Avançados em IA. Prof. Eduardo R. Hruschka
 Tópicos Avançados em IA Prof. Eduardo R. Hruschka Créditos Este material consiste de adaptações dos originais: Elaborados por Eduardo Hruschka e Ricardo Campello de (Tan et al., 2006) de E. Keogh (SBBD
Tópicos Avançados em IA Prof. Eduardo R. Hruschka Créditos Este material consiste de adaptações dos originais: Elaborados por Eduardo Hruschka e Ricardo Campello de (Tan et al., 2006) de E. Keogh (SBBD
Análise dados de diagnóstico de câncer de mama
 Análise dados de diagnóstico de câncer de mama Alexandre Morales Diaz Eduardo Pereira Lima Pedro Henrique Moraes Trabalho de Modelos Lineares Generalizados (CE-225), Universidade Federal do Paraná, submetido
Análise dados de diagnóstico de câncer de mama Alexandre Morales Diaz Eduardo Pereira Lima Pedro Henrique Moraes Trabalho de Modelos Lineares Generalizados (CE-225), Universidade Federal do Paraná, submetido
REGRESSÃO LINEAR Parte I. Flávia F. Feitosa
 REGRESSÃO LINEAR Parte I Flávia F. Feitosa BH1350 Métodos e Técnicas de Análise da Informação para o Planejamento Julho de 2015 Onde Estamos Para onde vamos Inferência Esta5s6ca se resumindo a uma equação
REGRESSÃO LINEAR Parte I Flávia F. Feitosa BH1350 Métodos e Técnicas de Análise da Informação para o Planejamento Julho de 2015 Onde Estamos Para onde vamos Inferência Esta5s6ca se resumindo a uma equação
ESTATÍSTICA COMPUTACIONAL
 ESTATÍSTICA COMPUTACIONAL Ralph dos Santos Silva Departamento de Métodos Estatísticos Instituto de Matemática Universidade Federal do Rio de Janeiro Sumário (bootstrap) Este método foi proposto por Efron
ESTATÍSTICA COMPUTACIONAL Ralph dos Santos Silva Departamento de Métodos Estatísticos Instituto de Matemática Universidade Federal do Rio de Janeiro Sumário (bootstrap) Este método foi proposto por Efron
Estimativa de demanda potencial de matrículas em ensino superior usando dados públicos e múltiplos modelos de regressão
 Universidade de São Paulo Biblioteca Digital da Produção Intelectual - BDPI Departamento de Ciências de Computação - ICMC/SCC Comunicações em Eventos - ICMC/SCC 2014-10 Estimativa de demanda potencial
Universidade de São Paulo Biblioteca Digital da Produção Intelectual - BDPI Departamento de Ciências de Computação - ICMC/SCC Comunicações em Eventos - ICMC/SCC 2014-10 Estimativa de demanda potencial
Escola Superior de Agricultura Luiz de Queiroz Universidade de São Paulo
 Escola Superior de Agricultura Luiz de Queiroz Universidade de São Paulo Regressão Polinomial e Análise da Variância Piracicaba Setembro 2014 Estatística Experimental 18 de Setembro de 2014 1 / 20 Vimos
Escola Superior de Agricultura Luiz de Queiroz Universidade de São Paulo Regressão Polinomial e Análise da Variância Piracicaba Setembro 2014 Estatística Experimental 18 de Setembro de 2014 1 / 20 Vimos
Valter Eduardo da Silva Júnior
 Valter Eduardo da Silva Júnior UMA NOVA ABORDAGEM DO REAL ADABOOST RESISTENTE A OVERFITTING PARA CLASSIFICAÇÃO DE DADOS BINÁRIOS Dissertação de Mestrado Universidade Federal de Pernambuco posgraduacao@cin.ufpe.br
Valter Eduardo da Silva Júnior UMA NOVA ABORDAGEM DO REAL ADABOOST RESISTENTE A OVERFITTING PARA CLASSIFICAÇÃO DE DADOS BINÁRIOS Dissertação de Mestrado Universidade Federal de Pernambuco posgraduacao@cin.ufpe.br
θ depende de um parâmetro desconhecido θ.
 73 Método de Máxima Verosimilhança (Maximum Likelihood) Seja uma variável aleatória (v. a.) cuja densidade de probabilidade depende de um parâmetro desconhecido. Admite-se conhecida a forma de Exemplo
73 Método de Máxima Verosimilhança (Maximum Likelihood) Seja uma variável aleatória (v. a.) cuja densidade de probabilidade depende de um parâmetro desconhecido. Admite-se conhecida a forma de Exemplo
UNIVERSIDADE TECNOLÓGICA FEDERAL DO PARANÁ (UTFPR) 2016/ PPGCA PPGCA/UTFPR -- CAIA003
 2016/ PPGCA PPGCA/UTFPR -- CAIA003") UNIVERSIDADE TECNOLÓGICA FEDERAL DO PARANÁ (UTFPR) Mineração de Dados 2016/3 Professores Celso e Heitor Jean Avila Rangel 1801317 - PPGCA PPGCA/UTFPR câmpus Curitiba -- CAIA003 - Mineração de Dados --
UNIVERSIDADE TECNOLÓGICA FEDERAL DO PARANÁ (UTFPR) Mineração de Dados 2016/3 Professores Celso e Heitor Jean Avila Rangel 1801317 - PPGCA PPGCA/UTFPR câmpus Curitiba -- CAIA003 - Mineração de Dados --
Inteligência Computacional
 Inteligência Computacional CP78D Redes Neurais Aula 7 Prof. Daniel Cavalcanti Jeronymo Universidade Tecnológica Federal do Paraná (UTFPR) Engenharia Eletrônica 7º Período 1/24 Plano de Aula Perceptron
Inteligência Computacional CP78D Redes Neurais Aula 7 Prof. Daniel Cavalcanti Jeronymo Universidade Tecnológica Federal do Paraná (UTFPR) Engenharia Eletrônica 7º Período 1/24 Plano de Aula Perceptron
Professor: Eduardo R. Hruschka Estagiário PAE: Luiz F. S. Coletta
 Professor: Eduardo R Hruschka Estagiário PAE: Luiz F S Coletta (luizfsc@icmcuspbr) Sumário Definição do projeto 1 Desenvolvimento de algoritmo de Aprendizado de Máquina (AM); 2 Pré-processamento dos dados;
Professor: Eduardo R Hruschka Estagiário PAE: Luiz F S Coletta (luizfsc@icmcuspbr) Sumário Definição do projeto 1 Desenvolvimento de algoritmo de Aprendizado de Máquina (AM); 2 Pré-processamento dos dados;
Algoritmos de Agrupamento - Aprendizado Não Supervisionado
 Algoritmos de Agrupamento - Aprendizado Não Supervisionado Fabrício Jailson Barth fabricio.barth@gmail.com Agosto de 2016 Sumário Introdução e Definições Aplicações Algoritmos de Agrupamento Agrupamento
Algoritmos de Agrupamento - Aprendizado Não Supervisionado Fabrício Jailson Barth fabricio.barth@gmail.com Agosto de 2016 Sumário Introdução e Definições Aplicações Algoritmos de Agrupamento Agrupamento
Inferência para CS Tópico 10 - Princípios de Estimação Pontual
 Inferência para CS Tópico 10 - Princípios de Estimação Pontual Renato Martins Assunção DCC - UFMG 2013 Renato Martins Assunção (DCC - UFMG) Inferência para CS Tópico 10 - Princípios de Estimação Pontual
Inferência para CS Tópico 10 - Princípios de Estimação Pontual Renato Martins Assunção DCC - UFMG 2013 Renato Martins Assunção (DCC - UFMG) Inferência para CS Tópico 10 - Princípios de Estimação Pontual
Modelos de Regressão Linear Simples - parte III
 1 Modelos de Regressão Linear Simples - parte III Erica Castilho Rodrigues 20 de Setembro de 2016 2 3 4 A variável X é um bom preditor da resposta Y? Quanto da variação da variável resposta é explicada
1 Modelos de Regressão Linear Simples - parte III Erica Castilho Rodrigues 20 de Setembro de 2016 2 3 4 A variável X é um bom preditor da resposta Y? Quanto da variação da variável resposta é explicada
EN3604 FILTRAGEM ADAPTATIVA
 EN3604 FILTRAGEM ADAPTATIVA Introdução Filtros adaptativos, os quais têm como meta transformar os sinais portadores de informação em versões limpas ou melhoradas, ajustam suas características de acordo
EN3604 FILTRAGEM ADAPTATIVA Introdução Filtros adaptativos, os quais têm como meta transformar os sinais portadores de informação em versões limpas ou melhoradas, ajustam suas características de acordo
DCBD. Avaliação de modelos. Métricas para avaliação de desempenho. Avaliação de modelos. Métricas para avaliação de desempenho...
 DCBD Métricas para avaliação de desempenho Como avaliar o desempenho de um modelo? Métodos para avaliação de desempenho Como obter estimativas confiáveis? Métodos para comparação de modelos Como comparar
DCBD Métricas para avaliação de desempenho Como avaliar o desempenho de um modelo? Métodos para avaliação de desempenho Como obter estimativas confiáveis? Métodos para comparação de modelos Como comparar
aula ANÁLISE DO DESEMPENHO DO MODELO EM REGRESSÕES
 ANÁLISE DO DESEMPENHO DO MODELO EM REGRESSÕES 18 aula META Fazer com que o aluno seja capaz de realizar os procedimentos existentes para a avaliação da qualidade dos ajustes aos modelos. OBJETIVOS Ao final
ANÁLISE DO DESEMPENHO DO MODELO EM REGRESSÕES 18 aula META Fazer com que o aluno seja capaz de realizar os procedimentos existentes para a avaliação da qualidade dos ajustes aos modelos. OBJETIVOS Ao final
Projeto de Experimentos e Superfícies de Resposta (Design of Experiments DOE Response Surfaces - RS) (ENG03024-Análise de Sistemas Mecânicos)
 (ENG03024-Análise de Sistemas Mecânicos)") UFRGS - Universidade Federal do Rio Grande do Sul EE - Escola de Engenharia DEMEC - Departamento de Engenharia Mecânica e Superfícies de Resposta (Design of Experiments DOE Response Surfaces - RS) (ENG0304-Análise
UFRGS - Universidade Federal do Rio Grande do Sul EE - Escola de Engenharia DEMEC - Departamento de Engenharia Mecânica e Superfícies de Resposta (Design of Experiments DOE Response Surfaces - RS) (ENG0304-Análise
Introdução ao Data Mining Instituto Nacional de Estatística de Fevereiro de 2009
 Introdução ao Data Mining Instituto Nacional de Estatística 16-20 de Fevereiro de 2009 Módulo 2 -Métodos de Data Mining- -Árvores de decisão- -Regressão Linear e Árvores de regressão André Falcão (afalcao@di.fc.ul.pt)
Introdução ao Data Mining Instituto Nacional de Estatística 16-20 de Fevereiro de 2009 Módulo 2 -Métodos de Data Mining- -Árvores de decisão- -Regressão Linear e Árvores de regressão André Falcão (afalcao@di.fc.ul.pt)
Modelos de Regressão Linear Simples - Erro Puro e Falta de Ajuste
 Modelos de Regressão Linear Simples - Erro Puro e Falta de Ajuste Erica Castilho Rodrigues 2 de Setembro de 2014 Erro Puro 3 Existem dois motivos pelos quais os pontos observados podem não cair na reta
Modelos de Regressão Linear Simples - Erro Puro e Falta de Ajuste Erica Castilho Rodrigues 2 de Setembro de 2014 Erro Puro 3 Existem dois motivos pelos quais os pontos observados podem não cair na reta
Mestrado Profissionalizante em Finanças as e Economia Empresarial FGV / EPGE Prof. Eduardo Ribeiro Julho Setembro 2007
 Projeções de Séries S Temporais Econometria dos Mercados Financeiros Mestrado Profissionalizante em Finanças as e Economia Empresarial FGV / EPGE Prof. Eduardo Ribeiro Julho Setembro 2007 Objetivo do curso
Projeções de Séries S Temporais Econometria dos Mercados Financeiros Mestrado Profissionalizante em Finanças as e Economia Empresarial FGV / EPGE Prof. Eduardo Ribeiro Julho Setembro 2007 Objetivo do curso
Reconhecimento de Dígitos Manuscritos em Vídeos Educacionais Utilizando Florestas Aleatórias
 Reconhecimento de Dígitos Manuscritos em Vídeos Educacionais Utilizando Florestas Aleatórias Paulo R. S. Borges, Ismar F. Silveira, Leandro Nunes de Castro Programa de Pós-Graduação em Engenharia Elétrica
Reconhecimento de Dígitos Manuscritos em Vídeos Educacionais Utilizando Florestas Aleatórias Paulo R. S. Borges, Ismar F. Silveira, Leandro Nunes de Castro Programa de Pós-Graduação em Engenharia Elétrica
Transformações e Ponderação para corrigir violações do modelo
 Transformações e Ponderação para corrigir violações do modelo Diagnóstico na análise de regressão Relembrando suposições Os erros do modelo tem média zero e variância constante. Os erros do modelo tem
Transformações e Ponderação para corrigir violações do modelo Diagnóstico na análise de regressão Relembrando suposições Os erros do modelo tem média zero e variância constante. Os erros do modelo tem
Método Simplex dual. Marina Andretta ICMC-USP. 24 de outubro de 2016
 Método Simplex dual Marina Andretta ICMC-USP 24 de outubro de 2016 Baseado no livro Introduction to Linear Optimization, de D. Bertsimas e J. N. Tsitsiklis. Marina Andretta (ICMC-USP) sme0211 - Otimização
Método Simplex dual Marina Andretta ICMC-USP 24 de outubro de 2016 Baseado no livro Introduction to Linear Optimization, de D. Bertsimas e J. N. Tsitsiklis. Marina Andretta (ICMC-USP) sme0211 - Otimização
Modelo Linear Generalizado Exponencial Potência
 Modelo Linear Generalizado Exponencial Potência Cristian Villegas 1 2 1 Introdução Os modelos lineares normais são amplamente aplicados em diversas áreas do conhecimento para modelar a média de dados contínuos
Modelo Linear Generalizado Exponencial Potência Cristian Villegas 1 2 1 Introdução Os modelos lineares normais são amplamente aplicados em diversas áreas do conhecimento para modelar a média de dados contínuos
Weka. Universidade de Waikato - Nova Zelândia. Coleção de algoritmos de aprendizado de máquina para resolução de problemas de Data Mining
 Weka Universidade de Waikato - Nova Zelândia Coleção de algoritmos de aprendizado de máquina para resolução de problemas de Data Mining implementado em Java open source software http://www.cs.waikato.ac.nz/ml/weka/
Weka Universidade de Waikato - Nova Zelândia Coleção de algoritmos de aprendizado de máquina para resolução de problemas de Data Mining implementado em Java open source software http://www.cs.waikato.ac.nz/ml/weka/
Máquinas de Vetores de Suporte - Support Vector Machines (SVM) Germano Vasconcelos
 Germano Vasconcelos") Máquinas de Vetores de Suporte - Support Vector Machines (SVM) Germano Vasconcelos Introdução * Método supervisionado de aprendizagem de máquina * Empregado em classificação de dados Classificação binária
Máquinas de Vetores de Suporte - Support Vector Machines (SVM) Germano Vasconcelos Introdução * Método supervisionado de aprendizagem de máquina * Empregado em classificação de dados Classificação binária
ANÁLISE DE REGRESSÃO
 ANÁLISE DE REGRESSÃO Lucas Santana da Cunha http://www.uel.br/pessoal/lscunha/ Universidade Estadual de Londrina 09 de janeiro de 2017 Introdução A análise de regressão consiste na obtenção de uma equação
ANÁLISE DE REGRESSÃO Lucas Santana da Cunha http://www.uel.br/pessoal/lscunha/ Universidade Estadual de Londrina 09 de janeiro de 2017 Introdução A análise de regressão consiste na obtenção de uma equação
Roteiro. PCC142 / BCC444 - Mineração de Dados Avaliação de Classicadores. Estimativa da Acurácia. Introdução. Estimativa da Acurácia
 Roteiro PCC142 / BCC444 - Mineração de Dados Avaliação de Classicadores Introdução Luiz Henrique de Campos Merschmann Departamento de Computação Universidade Federal de Ouro Preto luizhenrique@iceb.ufop.br
Roteiro PCC142 / BCC444 - Mineração de Dados Avaliação de Classicadores Introdução Luiz Henrique de Campos Merschmann Departamento de Computação Universidade Federal de Ouro Preto luizhenrique@iceb.ufop.br
Data Mining. Felipe E. Barletta Mendes. 21 de maio de 2008
 21 de maio de 2008 O foco principal deste material não é apresentar em minúcia todo o contexto de, muito menos o sobre o processo KDD em que a mineração de dados usualmente está inserida. O objetivo é
21 de maio de 2008 O foco principal deste material não é apresentar em minúcia todo o contexto de, muito menos o sobre o processo KDD em que a mineração de dados usualmente está inserida. O objetivo é
Regressão linear simples
 Regressão linear simples Universidade Estadual de Santa Cruz Ivan Bezerra Allaman Introdução Foi visto na aula anterior que o coeficiente de correlação de Pearson é utilizado para mensurar o grau de associação
Regressão linear simples Universidade Estadual de Santa Cruz Ivan Bezerra Allaman Introdução Foi visto na aula anterior que o coeficiente de correlação de Pearson é utilizado para mensurar o grau de associação
Extracção de Conhecimento
 Programa Doutoral em Engenharia Informática Mestrado Integrado em Engenharia Informática LIACC/FEUP Universidade do Porto www.fe.up.pt/ ec rcamacho@fe.up.pt Outubro 2007 conceitos básicos Conteúdo Definições
Programa Doutoral em Engenharia Informática Mestrado Integrado em Engenharia Informática LIACC/FEUP Universidade do Porto www.fe.up.pt/ ec rcamacho@fe.up.pt Outubro 2007 conceitos básicos Conteúdo Definições
Avaliando Hipóteses. George Darmiton da Cunha Cavalcanti Tsang Ing Ren CIn/UFPE
 Avaliando Hipóteses George Darmiton da Cunha Cavalcanti Tsang Ing Ren CIn/UFPE Pontos importantes Erro da Amostra e Erro Real Como Calcular Intervalo de Confiança Erros de hipóteses Estimadores Comparando
Avaliando Hipóteses George Darmiton da Cunha Cavalcanti Tsang Ing Ren CIn/UFPE Pontos importantes Erro da Amostra e Erro Real Como Calcular Intervalo de Confiança Erros de hipóteses Estimadores Comparando
Correlação e Regressão
 Correlação e Regressão Exemplos: Correlação linear Estudar a relação entre duas variáveis quantitativas Ou seja, a força da relação entre elas, ou grau de associação linear. Idade e altura das crianças
Correlação e Regressão Exemplos: Correlação linear Estudar a relação entre duas variáveis quantitativas Ou seja, a força da relação entre elas, ou grau de associação linear. Idade e altura das crianças
Mistura de modelos. Marcelo K. Albertini. 31 de Julho de 2014
 Mistura de modelos Marcelo K. Albertini 31 de Julho de 2014 2/11 Mistura de modelos Ideia básica Em vez de aprender somente um modelo, aprender vários e combiná-los Isso melhora acurácia Muitos métodos
Mistura de modelos Marcelo K. Albertini 31 de Julho de 2014 2/11 Mistura de modelos Ideia básica Em vez de aprender somente um modelo, aprender vários e combiná-los Isso melhora acurácia Muitos métodos
Métodos de Amostragem. Métodos de Amostragem e Avaliação de Algoritmos. Métodos de Amostragem. Métodos de Amostragem. Métodos de Amostragem
 e Avaliação de s José Augusto Baranauskas Departamento de Física e Matemática FFCLRP-USP AM é uma ferramenta poderosa, mas não existe um único algoritmo que apresente o melhor desempenho para todos os
e Avaliação de s José Augusto Baranauskas Departamento de Física e Matemática FFCLRP-USP AM é uma ferramenta poderosa, mas não existe um único algoritmo que apresente o melhor desempenho para todos os
Classificação Automática de Gêneros Musicais
 Introdução Método Experimentos Conclusões Utilizando Métodos de Bagging e Boosting Carlos N. Silla Jr. Celso Kaestner Alessandro Koerich Pontifícia Universidade Católica do Paraná Programa de Pós-Graduação
Introdução Método Experimentos Conclusões Utilizando Métodos de Bagging e Boosting Carlos N. Silla Jr. Celso Kaestner Alessandro Koerich Pontifícia Universidade Católica do Paraná Programa de Pós-Graduação
Data Science. Data Stream Mining: trabalhando com dados massivos. André Luís Nunes Porto Alegre, Globalcode Open4education
 Data Science Data Stream Mining: trabalhando com dados massivos André Luís Nunes Porto Alegre, 2018 Globalcode Open4education Data Stream Mining trabalhando com dados massivos 2018 agenda andré luís nunes
Data Science Data Stream Mining: trabalhando com dados massivos André Luís Nunes Porto Alegre, 2018 Globalcode Open4education Data Stream Mining trabalhando com dados massivos 2018 agenda andré luís nunes