Programação Paralela e Distribuída
|
|
|
- Rafael Sousa Estrada
- 9 Há anos
- Visualizações:
Transcrição
1 Curso de Informática DCC-IM / UFRJ Programação Paralela e Distribuída Um curso prático Mario J. Júnior Gabriel P. Silva Colaboração: Adriano O. Cruz, Julio S. Aude
2 Ementa Paradigma de Troca de Mensagens PVM MPI Paradigma de Memória Compartilhada OpenMP PThreads
3 Ementa Conceitos Básicos de concorrência e paralelismo. Conceitos de avaliação de desempenho. Modelos de programação paralela. Modelos de programação por troca de mensagens. Programação utilizando PVM e MPI. Exemplos. Modelos de programação com Memória Compartilhada. Conceitos de Thread e Processos. Primitivas de Sincronização em memória compartilhada. Algoritmos paralelos com memória compartilhada. Programação utilizando bibliotecas OpenMP e Pthreads. Exemplos. Ferramentas de avaliação e depuração de programas paralelos.
4 Conceitos Básicos de Paralelismo
5 Processo Um processo é criado para execução de um programa pelo sistema operacional. A criação de um processo envolve os seguintes passos: Preparar o descritor de processo; Reservar um espaço de endereçamento; Carregar um programa no espaço reservado; Passar o descritor de processo para o escalonador. Nos sistemas operacionais modernos, um processo pode gerar cópias, chamadas de processos filhos.
6 Processo Os processos filhos compartilham do mesmo código que os processos pais, contudo não compartilham o mesmo espaço de endereçamento. A troca de contexto entre processos é normalmente um processo lento, que exige uma chamada ao sistema operacional, com salvamento dos registradores e tabelas de gerência na memória, além da restauração dos mesmos para o processo que vai ser executado.
7 Threads Muitos dos sistemas operacionais modernos suportam o conceito de threads, ou seja, tarefas independentes dentro de um mesmo processo que podem ser executadas em paralelo ou de forma intercalada no tempo, concorrentemente. Nesses sistemas, uma aplicação é descrita por um processo composto de várias threads. As threads de um mesmo processo compartilham o espaço de endereçamento de memória, arquivos abertos e outros recursos que caracterizam o contexto global de um processo como um todo.
8 Threads Cada thread, no entanto, tem seu próprio contexto específico, normalmente caracterizado pelo conjunto de registradores em uso, contador de programas e palavra de status do processador. O contexto específico de uma thread é semelhante ao contexto de uma função e, conseqüentemente, a troca de contexto entre threads implica no salvamento e recuperação de contextos relativamente leves, a exemplo do que ocorre numa chamada de função dentro de um programa.
9 Threads Este fato é o principal atrativo em favor do uso de threads para se implementar um dado conjunto de tarefas em contraposição ao uso de múltiplos processos. A comunicação entre tarefas é grandemente simplificada numa implementação baseada em threads, uma vez que neste caso as tarefas compartilham o espaço de endereçamento de memória do processo como um todo que engloba as threads, eliminando a necessidade do uso de esquemas especiais, mais restritos e, usualmente, mais lentos de comunicação entre processos providos pelos sistemas operacionais.
10 Threads Thread 1 Thread 2 Thread 3 PC Dados PC Dados PC Privados Privados Dados Privados Dados Compartilhados
11 Paralelismo x Concorrência Execução concorrente está associada ao modelo de um servidor atendendo a vários clientes através de uma política de escalonamento no tempo. Execução paralela está associada ao modelo de vários servidores atendendo a vários clientes simultaneamente no tempo. As linguagens de programação podem então ser classificadas como seqüenciais, concorrentes e paralelas. Estudaremos diversos padrões de bibliotecas de funções que permitem a codificação de programas paralelos utilizando linguagens convencionais (C, FORTRAN, JAVA, etc.).
12 Paradigmas de Programação Paralela
13 Memória Compartilhada Comunicação através de variáveis em memória compartilhada. Uso de threads e/ou processos para mapeamento de tarefas. Threads ou processos podem ser criados de forma dinâmica ou estática. Sincronização Exclusão Mútua Barreira Alocação de Memória Privada e Global.
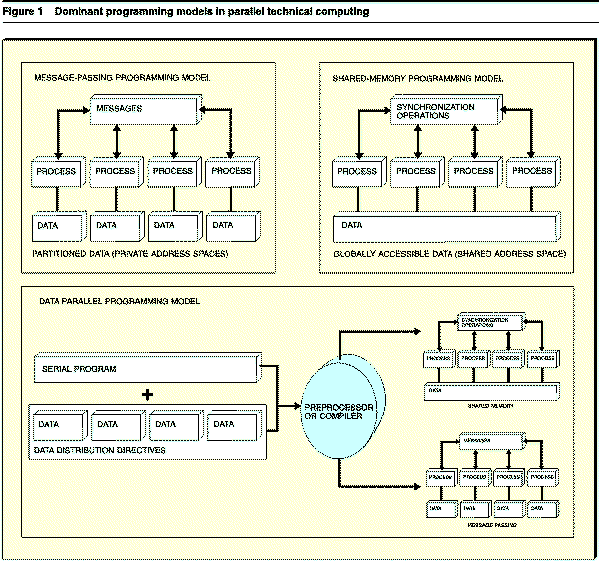
14 Modelos de Programação

15 Arquitetura de Comunicação
16 Troca de Mensagens Comunicação através do envio explícito de mensagens. Tarefas são mapeadas em processos, cada um com sua memória privada. Processos podem ser criados de forma estática ou dinâmica. Sincronização é feita de forma implícita pela troca de mensagens ou por operações coletivas de sincronização (barreiras).
17 Troca de Mensagens - Modelo Processo 1 x Processo 2 y send(&x, 2); Movimento dos Dados recv(&y, 1);
18 Comunicação Síncrona O processo que deseja enviar uma mensagem faz uma requisição inicial de autorização para enviar a mensagem ao processo destinatário. Depois de receber essa autorização, a operação de envio ("send") é realizada. A operação de envio só se completa quando a operação de recepção ( receive ) correspondente retorna uma mensagem de acknowlegement. Portanto, ao se concluir a operação de envio, os buffers e estruturas de dados utilizados na comunicação podem ser reutilizados.
19 Comunicação Síncrona Este modo de comunicação é simples e seguro, contudo elimina a possibilidade de haver superposição entre o processamento da aplicação e o processamento da transmissão das mensagens. Requer um protocolo de quatro fases para a sua implementação do lado do transmissor: pedido de autorização para transmitir; recebimento da autorização; transmissão propriamente dita da mensagem; e recebimento da mensagem de acknowledgement.
20 Comunicação Síncrona Processo 1 Processo 2 Pede para enviar tempo Processo Suspenso send(); Confirmação Mensagem recv(); Ambos continuam
21 Comunicação Síncrona Processo 1 Processo 2 Pede para enviar tempo send(); Confirmação Mensagem recv(); Processo Suspenso Ambos continuam
22 Comunicação Assíncrona Bloqueante A operação de envio ("send") só retorna o controle para o processo que a chamou após ter sido feita a cópia da mensagem a ser enviada de um buffer da aplicação para um buffer do sistema operacional. Portanto, ao haver o retorno da operação de envio, a aplicação está livre para reutilizar o seu buffer, embora não haja nenhuma garantia de que a transmissão da mensagem tenha completado ou vá completar satisfatoriamente.
23 Comunicação Assíncrona Bloqueante A operação de envio bloqueante difere da operação de envio síncrona, uma vez que não é implementado o protocolo de quatro fases entre os processos origem e destino. A operação de recepção ("receive") bloqueante é semelhante à operação de recepção síncrona, só retornando para o processo que a chamou após ter concluído a transferência da mensagem do buffer do sistema para o buffer especificado pela aplicação. A diferença em relação a operação de recepção síncrona é que a mensagem de acknowledgement não é enviada.
24 Comunicação Assíncrona Não Bloqueante Na primeira fase, a operação de "send" retorna imediatamente, tendo apenas dado início ao processo de transmissão da mensagem e a operação de "receive" retorna após notificar a intenção do processo de receber uma mensagem. As operações de envio e recepção propriamente ditas são realizadas de forma assíncrona pelo sistema. O retorno das operações de send e de receive nada garantem e não autoriza a reutilização das estruturas de dados para nova mensagem.
25 Comunicação Assíncrona Não Bloqueante Na segunda fase, é verificado se a operação de troca de mensagens iniciada anteriormente pelas primitivas "send" e"receive" já foi concluída. Somente após esta verificação é que o processo que realizou o envio de dados pode alterar com segurança sua área de dados original. Este modo de comunicação é o que permite maior superposição no tempo entre computações da aplicação e o processamento da transmissão das mensagens.
26 Comunicação Assíncrona Necessita de um buffer para guardar a mensagem Processo 1 Processo 2 tempo send(); Buffer de mensagens recv(); Continua o processo Lê buffer de mensagen
27 Comunicação Assíncrona Processo 1 Processo 2 tempo send(); Buffer de mensagens recv(); Continua o processo Continua o processo
28 Etapas da Criação de um Programa Paralelo
29 Decomposição da Computação em Tarefas Busca expor suficiente paralelismo sem gerar uma sobrecarga de gerenciamento das tarefas que se torne significativo perante o trabalho útil a ser feito. Ou seja, as tarefas de comunicação e sincronização não podem ser mais complexas que as tarefas de computação. Se isto ocorrer, a execução em paralelo certamente será mais ineficiente do que a seqüencial.
30 Mapeamento nos Processadores Os processos e threads devem ser mapeadas para os processadores reais que existam no sistema. Para que isto seja feito de uma maneira eficiente, deve-se explorar a localidade da rede de interconexão, mantendo os processos relacionados alocados ao mesmo processador. Se a rede apresentar custos de comunicação variáveis, alocar os processos com maior carga de comunicação aos nós com menor custo de comunicação entre si.
31 Alocação de Tarefas As tarefas devem ser alocadas a processos ou threads de modo que: Haja um balanceamento de carga adequado e a redução do tempo de espera por conta da sincronização; Possa haver uma redução da comunicação entre processos ou threads; A sobrecarga do gerenciamento dessa alocação, em tempo de execução, seja a mais reduzida possível (estática x dinâmica).
32 Implementação da Funcionalidade A implementação da funcionalidade dos processos ou threads: Depende do modelo de programação adotado e da eficiência com que as primitivas deste modelo são suportadas pela plataforma; Explora a localidade dos dados; Redução da serialização no acesso a recursos compartilhados; Redução do custo de comunicação e da sincronização visto pelos processadores; Escalonar as tarefas de modo que aquelas que tenham uma maior cadeia de dependência sejam executadas mais cedo.
33 Avaliação de Desempenho
34 Medidas de Desempenho Speed-up (Aceleração): Mede a razão entre o tempo gasto para execução de um algoritmo ou aplicação em um único processador e o tempo gasto na execução com n processadores: S(n) = T(1)/T(n) Eficiência: E(n) = S(n)/n
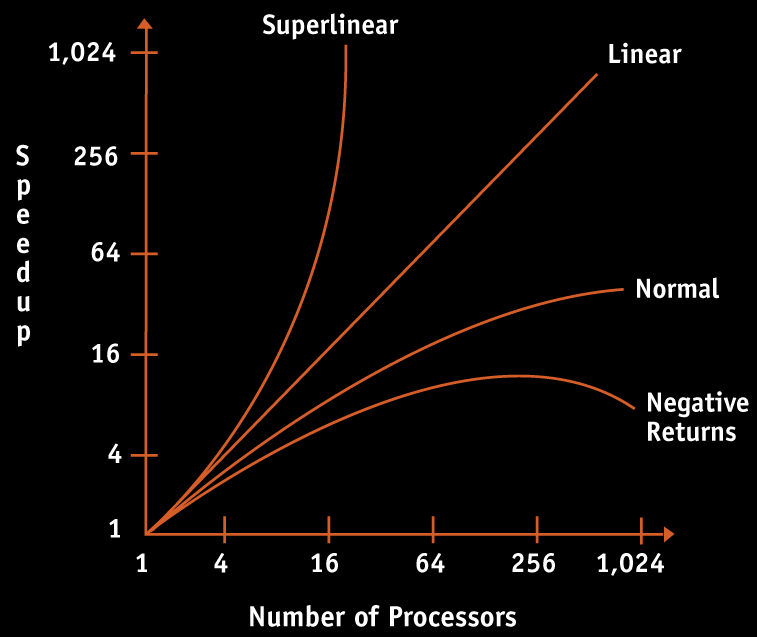
35 Speedup
36 Lei de Amdahl t s (a) Um processador ft s Seção Serial (1- f)t s Seções Paralelizáveis (b) Múltiplos Processadores p processadores t p (1 - f)t s /p
37 Lei de Amdahl O fator de aceleração é dado por: S(p) = t s p = ft s + (1 f )t s /p 1 + (p 1)f Esta equação é conhecida como Lei de Amdahl
38 Speedup x Processadores 20 f = 0% Fator de Aceleração S(p) f = 5% f = 10% f = 20% Número de processadores p
39 Speedup x Processadores Mesmo com um número infinito de processadores, o speedup máximo está limitado a 1/f, onde f é a fração serial do programa. Exemplo: Com apenas 5% da computação sendo serial, o speedup máximo é 20, não interessando o número de processadores em uso.
40 Escalibidade Um sistema é dito escalável quando sua eficiência se mantém constante à medida que o número de processadores (n) aplicado à solução do problema cresce. Se o tamanho do problema é mantido constante e o número de processadores aumenta, o overhead de comunicação tende a crescer e a eficiência a diminuir. A análise da escalabilidade considera a possibilidade de se aumentar proporcionalmente o tamanho do problema a ser resolvido à medida que n cresce, de forma a contrabalançar o natural aumento do overhead de comunicação quando n cresce.
41 Escalibidade A análise da escalabilidade considera a possibilidade de se aumentar proporcionalmente o tamanho do problema a ser resolvido à medida que n cresce de forma a contrabalançar o natural aumento do overhead de comunicação quando n cresce. Um problema de tamanho P usando N processadores leva um tempo T para ser executado. O sistema é dito escalável se um problema de tamanho 2P em 2N processadores leva o mesmo tempo T. Escalabilidade é uma propriedade mais desejável que o speed-up.
42 Granulosidade Granulosidade é a relação entre o quantidade de computação e a quantidade de comunicação. É uma medida de quanto trabalho é realizado antes dos processos se comunicarem. A granulosidade deve estar de acordo com o tipo de arquitetura: fine-grained processors medium-grained multiprocessor coarse/large-grained workstations vector/array shared memory network of
43 Bibliografia PVM: Parallel Virtual Machine A User s Guide and Tutorial for Network Parallel Computing Geist, A.; Beguelin, A.;Dongarra, J.; Jiang, W.; Mancheck, B.; Sunderam, V. The MIT Press, 1994 Parallel Programming with MPI Pacheco, P.S., Morgan Kaufmann Publishers, Using MPI-2: Advanced Features of the Message-Passing Interface Gropp, W.; Lusk, E.; Thakur, R. The MIT Press, Parallel Computing: theory and pratice Quinn, Michael J. McGraw-Hill, 1994.
44 Bibliografia Parallel Programming in OpenMP Chandra, R. et alli; Morgan Kaufman Publishers, 2001 Pthreads Programming Nicholas, D.; Butlar, J.; Farell, P. O`Reilly and Associates Inc., 1999 Programming with Threads Kleiman, S.; Shah, D.; Smaalders, B. Sun Soft Press, Prentice-Hall, 1996 Foundations of Multithreaded, Parallel and Distributed Programming Andrews, Gregory R. Addison-Wesley, 2000 Designing and Building Parallel Programs Foster, Ian Addison-Wesley Pub. Co, 1994
45 Homepage, Listas, gabriel dot silva at ufrj dot br grupo:
46 Avaliação Quatro trabalhos (Individual, prazo de 15 dias) 22/08 19/09 17/10 21/11 Quatro Provas 05/09 10/10 14/11 14/12
Sistemas de Troca de Mensagens
 Universidade Federal do Rio de Janeiro Programa de Pós-Graduação em Informática DCC/IM - NCE/UFRJ Arquitetura de Sistemas Paralelos Sistemas de Troca de Mensagens Sistemas de Comunicação O Sistema de Comunicação
Universidade Federal do Rio de Janeiro Programa de Pós-Graduação em Informática DCC/IM - NCE/UFRJ Arquitetura de Sistemas Paralelos Sistemas de Troca de Mensagens Sistemas de Comunicação O Sistema de Comunicação
Programação de Alto Desempenho - 2. Prof: Carla Osthoff
 Programação de Alto Desempenho - 2 Prof: Carla Osthoff E-mail: [email protected] 3- Modelos de programação paralela Shared Memory/Threads Posix Win32 treads OpenMP Message Passing MPI Data Parallel OpenCL/Cuda
Programação de Alto Desempenho - 2 Prof: Carla Osthoff E-mail: [email protected] 3- Modelos de programação paralela Shared Memory/Threads Posix Win32 treads OpenMP Message Passing MPI Data Parallel OpenCL/Cuda
Programação Concorrente e Paralela. Noemi Rodriguez
 2013 Objetivos princípios e técnicas de programação concorrente multiprocessadores memória compartilhada troca de mensagens obs: diferentes níveis de abstração! que princípios e técnicas são esses? notações
2013 Objetivos princípios e técnicas de programação concorrente multiprocessadores memória compartilhada troca de mensagens obs: diferentes níveis de abstração! que princípios e técnicas são esses? notações
OpenMP: Variáveis de Ambiente
 Treinamento OpenMP C/C++ 1 TREINAMENTO OpenMP C/C++ Módulo 1 Computação de Alto Desempenho Módulo 2 OpenMP: Construtores Paralelos Módulo 3 OpenMP: Diretivas de sincronização Módulo 4 OpenMP: Funções de
Treinamento OpenMP C/C++ 1 TREINAMENTO OpenMP C/C++ Módulo 1 Computação de Alto Desempenho Módulo 2 OpenMP: Construtores Paralelos Módulo 3 OpenMP: Diretivas de sincronização Módulo 4 OpenMP: Funções de
DESENVOLVIMENTO DE UM ALGORITMO PARALELO PARA APLICAÇÃO EM CLUSTER DE COMPUTADORES
 DESENVOLVIMENTO DE UM ALGORITMO PARALELO PARA APLICAÇÃO EM CLUSTER DE COMPUTADORES João Ricardo Kohler Abramoski (PAIC/FUNDAÇÃO ARAUCÁRIA), Sandra Mara Guse Scós Venske (Orientadora), e-mail: [email protected]
DESENVOLVIMENTO DE UM ALGORITMO PARALELO PARA APLICAÇÃO EM CLUSTER DE COMPUTADORES João Ricardo Kohler Abramoski (PAIC/FUNDAÇÃO ARAUCÁRIA), Sandra Mara Guse Scós Venske (Orientadora), e-mail: [email protected]
Ferramentas para Programação em Processadores Multi-Core
 Ferramentas para Programação em Processadores Multi-Core Prof. Dr. Departamento de Informática Universidade Federal de Pelotas Sumário Introdução Arquiteturas multi-core Ferramentas de programação Prática
Ferramentas para Programação em Processadores Multi-Core Prof. Dr. Departamento de Informática Universidade Federal de Pelotas Sumário Introdução Arquiteturas multi-core Ferramentas de programação Prática
Universidade Federal do Rio de Janeiro Informática DCC/IM. Arquitetura de Computadores II. Arquiteturas MIMD. Arquiteturas MIMD
 Universidade Federal do Rio de Janeiro Informática DCC/IM Arquitetura de Computadores II Arquiteturas MIMD Arquiteturas MIMD As arquiteturas MIMD dividem-se em dois grandes modelos: Arquiteturas MIMD de
Universidade Federal do Rio de Janeiro Informática DCC/IM Arquitetura de Computadores II Arquiteturas MIMD Arquiteturas MIMD As arquiteturas MIMD dividem-se em dois grandes modelos: Arquiteturas MIMD de
Sistemas Distribuídos Aula 3
 Sistemas Distribuídos Aula 3 Aula passada Processos IPC Características Ex. sinais, pipes, sockets Aula de hoje Threads Kernel level User level Escalonamento Motivação: Servidor Web Considere Servidor
Sistemas Distribuídos Aula 3 Aula passada Processos IPC Características Ex. sinais, pipes, sockets Aula de hoje Threads Kernel level User level Escalonamento Motivação: Servidor Web Considere Servidor
AULA 06: PROGRAMAÇÃO EM MÁQUINAS PARALELAS
 ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 06: PROGRAMAÇÃO EM MÁQUINAS PARALELAS Prof. Max Santana Rolemberg Farias [email protected] Colegiado de Engenharia de Computação PROGRAMAÇÃO PARALELA
ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 06: PROGRAMAÇÃO EM MÁQUINAS PARALELAS Prof. Max Santana Rolemberg Farias [email protected] Colegiado de Engenharia de Computação PROGRAMAÇÃO PARALELA
speedup aprimorado aprimorado Fração aprimorada speedup aprimorado Fração aprimorada speedup aprimorado Tempo original Fração aprimorada aprimorado
 Multiprocessadores - A evolução tecnológica dos processadores iria diminuir drasticamente. 2- O caminho para o aumento de desempenho é de unir mais de um processador para realizar a mesma tarefa em menos
Multiprocessadores - A evolução tecnológica dos processadores iria diminuir drasticamente. 2- O caminho para o aumento de desempenho é de unir mais de um processador para realizar a mesma tarefa em menos
Programação Concorrente e Paralela. Noemi Rodriguez
 2016 o que é programação concorrente e paralela? programação concorrente: composição de linhas de atividades independentes programação paralela: execução simultânea de linhas de atividades Go blog (Rob
2016 o que é programação concorrente e paralela? programação concorrente: composição de linhas de atividades independentes programação paralela: execução simultânea de linhas de atividades Go blog (Rob
Organização de Computadores II. Arquiteturas MIMD
 Organização de Computadores II Arquiteturas MIMD Arquiteturas UMA Arquiteturas com memória única global. Tempo de acesso uniforme para todos os nós de processamento. Nós de processamento e memória interconectados
Organização de Computadores II Arquiteturas MIMD Arquiteturas UMA Arquiteturas com memória única global. Tempo de acesso uniforme para todos os nós de processamento. Nós de processamento e memória interconectados
SSC PROGRAMAÇÃO CONCORRENTE. Aula 06 Modelos de Programação Prof. Jó Ueyama e Julio Cezar Estrella
 SSC- 0143 PROGRAMAÇÃO CONCORRENTE Aula 06 Modelos de Programação Prof. Jó Ueyama e Julio Cezar Estrella Créditos Os slides integrantes deste material foram construídos a par4r dos conteúdos relacionados
SSC- 0143 PROGRAMAÇÃO CONCORRENTE Aula 06 Modelos de Programação Prof. Jó Ueyama e Julio Cezar Estrella Créditos Os slides integrantes deste material foram construídos a par4r dos conteúdos relacionados
Aluno de Pós-Graduação em Engenharia de Software para Dispositivos Móveis pela UNINTER
 COMPARAÇÃO DE DESEMPENHO NA PROGRAMAÇÃO PARALELA HÍBRIDA (MPI + OPENMP) NA BUSCA DE TEXTO EM ARQUIVOS 1 COMPARISON OF PERFORMANCE IN HYBRID PARALLEL PROGRAMMING (MPI + OPENMP) IN SEARCH OF TEXT IN FILES
COMPARAÇÃO DE DESEMPENHO NA PROGRAMAÇÃO PARALELA HÍBRIDA (MPI + OPENMP) NA BUSCA DE TEXTO EM ARQUIVOS 1 COMPARISON OF PERFORMANCE IN HYBRID PARALLEL PROGRAMMING (MPI + OPENMP) IN SEARCH OF TEXT IN FILES
Modelo de Programação Paralela
 Modelo de Programação Paralela As arquiteturas paralelas e distribuídas possuem muitos detalhes Como especificar uma solução paralela pensando em todos esses detalhes? O que queremos? Eecutar a solução
Modelo de Programação Paralela As arquiteturas paralelas e distribuídas possuem muitos detalhes Como especificar uma solução paralela pensando em todos esses detalhes? O que queremos? Eecutar a solução
Programação Concorrente e Paralela
 projeto de programas paralelos 2016 PCAM problema particionamento comunicacao aglomeracao mapeamento desenhada para memória distribuída mas muitas idéias em comum Particionamento idéia é expor oportunidades
projeto de programas paralelos 2016 PCAM problema particionamento comunicacao aglomeracao mapeamento desenhada para memória distribuída mas muitas idéias em comum Particionamento idéia é expor oportunidades
Programação Concorrente
 INE 5410 Programação Concorrente Professor: Lau Cheuk Lung (turma A) INE UFSC [email protected] Conteúdo Programático 1. 2. Programação Concorrente 3. Sincronização 1. Condição de corrida, região critica
INE 5410 Programação Concorrente Professor: Lau Cheuk Lung (turma A) INE UFSC [email protected] Conteúdo Programático 1. 2. Programação Concorrente 3. Sincronização 1. Condição de corrida, região critica
Fundamentos de Sistemas Operacionais
 Fundamentos de Sistemas Operacionais Aula 6: Monitores, Troca de Mensagens e Deadlock Diego Passos Última Aulas Mecanismos de Exclusão Mútua Operações atômicas. Protocolos de controle de acesso. Spin-locks.
Fundamentos de Sistemas Operacionais Aula 6: Monitores, Troca de Mensagens e Deadlock Diego Passos Última Aulas Mecanismos de Exclusão Mútua Operações atômicas. Protocolos de controle de acesso. Spin-locks.
Programação concorrente (processos e threads)
") Programação concorrente (processos e threads) Programação concorrente Por que precisamos dela? Para utilizar o processador completamente Paralelismo entre CPU e dispositivos de I/O Para modelar o paralelismo
Programação concorrente (processos e threads) Programação concorrente Por que precisamos dela? Para utilizar o processador completamente Paralelismo entre CPU e dispositivos de I/O Para modelar o paralelismo
Sistemas de Informação. Sistemas Operacionais
 Sistemas de Informação Sistemas Operacionais PROCESSOS E THREADS PARTE II SUMÁRIO 3. THREAD: 3.1 Introdução; 3.2 Ambiente Monothread; 3.3 Ambiente Multithread; 3.4 Arquitetura e Implementação; 3.5 Modelos
Sistemas de Informação Sistemas Operacionais PROCESSOS E THREADS PARTE II SUMÁRIO 3. THREAD: 3.1 Introdução; 3.2 Ambiente Monothread; 3.3 Ambiente Multithread; 3.4 Arquitetura e Implementação; 3.5 Modelos
Redes de Computadores. Fundamentos de Sistemas Operacionais - 2º Período
 Redes de Computadores Fundamentos de Sistemas Operacionais - 2º Período PARTE II: PROCESSOS E THREADS SUMÁRIO 6. THREAD: 6.1 Introdução; 6.2 Ambiente Monothread; 6.3 Ambiente Multithread; 6.4 Arquitetura
Redes de Computadores Fundamentos de Sistemas Operacionais - 2º Período PARTE II: PROCESSOS E THREADS SUMÁRIO 6. THREAD: 6.1 Introdução; 6.2 Ambiente Monothread; 6.3 Ambiente Multithread; 6.4 Arquitetura
Arquitetura de Computadores Paralelos. Introdução Conceitos Básicos Ambientes de Programação Modelos de Programação Paralela
 Arquitetura de Computadores Paralelos Introdução Conceitos Básicos Ambientes de Programação Modelos de Programação Paralela Por que estudar Computação Paralela e Distribuída? Os computadores sequenciais
Arquitetura de Computadores Paralelos Introdução Conceitos Básicos Ambientes de Programação Modelos de Programação Paralela Por que estudar Computação Paralela e Distribuída? Os computadores sequenciais
Sistemas Operacionais
 Sistemas Operacionais 04 Processos Introdução Um sistema de computação quase sempre tem mais atividades a executar que o número de processadores disponíveis. Diferentes tarefas têm necessidades distintas
Sistemas Operacionais 04 Processos Introdução Um sistema de computação quase sempre tem mais atividades a executar que o número de processadores disponíveis. Diferentes tarefas têm necessidades distintas
SSC510 Arquitetura de Computadores. 6ª aula
 SSC510 Arquitetura de Computadores 6ª aula PARALELISMO EM NÍVEL DE PROCESSOS PROFA. SARITA MAZZINI BRUSCHI Tipos de Paralelismo Instrução (granulosidade fina) Paralelismo entre as instruções Arquiteturas
SSC510 Arquitetura de Computadores 6ª aula PARALELISMO EM NÍVEL DE PROCESSOS PROFA. SARITA MAZZINI BRUSCHI Tipos de Paralelismo Instrução (granulosidade fina) Paralelismo entre as instruções Arquiteturas
Sistemas Operacionais
 Sistemas Operacionais Slides adaptados de Prof. Dr. Marcos José Santana, Prof. Dra. Regina Helena Carlucci Santana e Sarita Mazzini Bruschi baseados no livro Sistemas Operacionais Modernos de A. Tanenbaum
Sistemas Operacionais Slides adaptados de Prof. Dr. Marcos José Santana, Prof. Dra. Regina Helena Carlucci Santana e Sarita Mazzini Bruschi baseados no livro Sistemas Operacionais Modernos de A. Tanenbaum
Paralelização de Algoritmos de CFD em Clusters Multi-Core MC7. Escola de Verão Arquiteturas Multi-Core
 RSS-Verão-01/08 p.1/36 Paralelização de Algoritmos de CFD em Clusters Multi-Core MC7 Escola de Verão 2008 Arquiteturas Multi-Core Renato S. Silva LNCC - MCT Janeiro de 2008 RSS-Verão-01/08 p.2/36 Objetivo:
RSS-Verão-01/08 p.1/36 Paralelização de Algoritmos de CFD em Clusters Multi-Core MC7 Escola de Verão 2008 Arquiteturas Multi-Core Renato S. Silva LNCC - MCT Janeiro de 2008 RSS-Verão-01/08 p.2/36 Objetivo:
Sistemas Distribuídos e Paralelos
 Sistemas Distribuídos e Paralelos Aula #6: Programação paralela em sistemas de memória compartilhada. ISUTIC - 2016 Eng. Alexander Rodríguez Bonet Aula de hoje Regiões paralelas. Cláusulas de âmbito. Partilha
Sistemas Distribuídos e Paralelos Aula #6: Programação paralela em sistemas de memória compartilhada. ISUTIC - 2016 Eng. Alexander Rodríguez Bonet Aula de hoje Regiões paralelas. Cláusulas de âmbito. Partilha
Sistemas Operacionais. Prof. Fabio Augusto Oliveira
 Sistemas Operacionais Prof. Fabio Augusto Oliveira Threads Um processo representa uma sequência de instruções única, executada paralelamente a outra seqüências de instruções. Um thread é uma maneira de
Sistemas Operacionais Prof. Fabio Augusto Oliveira Threads Um processo representa uma sequência de instruções única, executada paralelamente a outra seqüências de instruções. Um thread é uma maneira de
Sistemas Operacionais. Processos e Threads
 Sistemas Operacionais Processos e Threads Sumário 1. Introdução 2. Estrutura do Processo 1. Contexto de Hardware 2. Contexto de Software 3. Espaço de Endereçamento 3. Estados 1. Mudanças de Estado 2. Criação
Sistemas Operacionais Processos e Threads Sumário 1. Introdução 2. Estrutura do Processo 1. Contexto de Hardware 2. Contexto de Software 3. Espaço de Endereçamento 3. Estados 1. Mudanças de Estado 2. Criação
Introdução OpenMP. Nielsen Castelo Damasceno
 Introdução OpenMP Nielsen Castelo Damasceno Computação de auto desempenho Processamento Paralelo Memória Distribuída e Compartilhada Modelo de programação OpenMP Métricas de Desempenho Computação de auto
Introdução OpenMP Nielsen Castelo Damasceno Computação de auto desempenho Processamento Paralelo Memória Distribuída e Compartilhada Modelo de programação OpenMP Métricas de Desempenho Computação de auto
SOP - TADS Threads. Revisão Ultima aula. Programa em execução Cada processo têm sua própria CPU
 SOP - TADS Threads Prof. Ricardo José Pfitscher [email protected] Material cedido por: Prof. Rafael Rodrigues Obelheiro Prof. Maurício Aronne Pillon Revisão Ultima aula Processos [1/3] Conceito:
SOP - TADS Threads Prof. Ricardo José Pfitscher [email protected] Material cedido por: Prof. Rafael Rodrigues Obelheiro Prof. Maurício Aronne Pillon Revisão Ultima aula Processos [1/3] Conceito:
Programação Distribuída e Paralela Apresentação
 Programação Distribuída e Paralela Apresentação Programação Distribuída e Paralela (C. Geyer) Apresentação V4.2 S 1 Autoria Autoria Local Versão 4.2 Fev 2014 C. Geyer INF UFRGS Disciplinas INF01008 Programação
Programação Distribuída e Paralela Apresentação Programação Distribuída e Paralela (C. Geyer) Apresentação V4.2 S 1 Autoria Autoria Local Versão 4.2 Fev 2014 C. Geyer INF UFRGS Disciplinas INF01008 Programação
PROGRAMAÇÃO PARALELA USANDO MPI
 PROGRAMAÇÃO PARALELA USANDO MPI Maurílio Boaventura DCCE/IBILCE/UNESP São José do Rio Preto - SP Nos computadores convencionais, um programa é um conjunto de instruções que são transmitidas à unidade de
PROGRAMAÇÃO PARALELA USANDO MPI Maurílio Boaventura DCCE/IBILCE/UNESP São José do Rio Preto - SP Nos computadores convencionais, um programa é um conjunto de instruções que são transmitidas à unidade de
AULA 03: PROCESSAMENTO PARALELO: MULTIPROCESSADORES
 ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 03: PROCESSAMENTO PARALELO: MULTIPROCESSADORES Prof. Max Santana Rolemberg Farias [email protected] Colegiado de Engenharia de Computação MULTIPROCESSADORES
ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 03: PROCESSAMENTO PARALELO: MULTIPROCESSADORES Prof. Max Santana Rolemberg Farias [email protected] Colegiado de Engenharia de Computação MULTIPROCESSADORES
Exemplo de Arquitetura: Cliente/Servidor com Mestre e Escravos. Interface. Fator de speed-up. Speed-up
 Exemplo de Arquitetura: Cliente/Servidor com Mestre e s Arquitetura Mestre- Speed-up / Cliente Mestre Prof João Paulo A Almeida (jpalmeida@infufesbr) Cliente 2015/01 - INF02799 Com alguns slides de Parallel
Exemplo de Arquitetura: Cliente/Servidor com Mestre e s Arquitetura Mestre- Speed-up / Cliente Mestre Prof João Paulo A Almeida (jpalmeida@infufesbr) Cliente 2015/01 - INF02799 Com alguns slides de Parallel
LINGUAGENS LÓGICAS E PROGRAMAÇÃO CONCORRENTE
 LINGUAGENS LÓGICAS E PROGRAMAÇÃO CONCORRENTE Adriana Nery Programação lógica Paradigma Predicados Dedutiva) baseado no Cálculo de (Lógica Matemática Exemplo: Zé Carioca é um papagaio. Todo papagaio é uma
LINGUAGENS LÓGICAS E PROGRAMAÇÃO CONCORRENTE Adriana Nery Programação lógica Paradigma Predicados Dedutiva) baseado no Cálculo de (Lógica Matemática Exemplo: Zé Carioca é um papagaio. Todo papagaio é uma
Paralelismo em Computadores com Tecnologia Multicore
 IFRN - Pau dos Ferros Pau dos Ferros/RN, 25 de fevereiro de 2016 O minicurso Descrição: Para se utilizar os vários núcleos de processamento disponíveis nos computadores atuais de forma eficiente, faz necessário
IFRN - Pau dos Ferros Pau dos Ferros/RN, 25 de fevereiro de 2016 O minicurso Descrição: Para se utilizar os vários núcleos de processamento disponíveis nos computadores atuais de forma eficiente, faz necessário
Fundamentos de Sistemas Operacionais. Threads. Prof. Edwar Saliba Júnior Março de Unidade Threads
 Threads Prof. Edwar Saliba Júnior Março de 2007 1 Definição Partes de um processo que compartilham mesmo espaço de endereçamento Sub-rotina de um programa executada paralelamente ao programa chamador (execução
Threads Prof. Edwar Saliba Júnior Março de 2007 1 Definição Partes de um processo que compartilham mesmo espaço de endereçamento Sub-rotina de um programa executada paralelamente ao programa chamador (execução
COMPARAÇÃO DE DESEMPENHO ENTRE IMPLEMENTAÇÕES DO ALGORITMO JOGO DA VIDA COM PTHREAD E OPEMMP 1
 COMPARAÇÃO DE DESEMPENHO ENTRE IMPLEMENTAÇÕES DO ALGORITMO JOGO DA VIDA COM PTHREAD E OPEMMP 1 Márcia Da Silva 2, Igor Gamste Haugg 3, Eliézer Silveira Prigol 4, Édson L. Padoin 5, Rogério S. M. Martins
COMPARAÇÃO DE DESEMPENHO ENTRE IMPLEMENTAÇÕES DO ALGORITMO JOGO DA VIDA COM PTHREAD E OPEMMP 1 Márcia Da Silva 2, Igor Gamste Haugg 3, Eliézer Silveira Prigol 4, Édson L. Padoin 5, Rogério S. M. Martins
Chapter 4: Threads. Operating System Concepts 8th Edition
 Chapter 4: Threads Sobre a apresentação (About the slides) Os slides e figuras dessa apresentação foram criados por Silberschatz, Galvin e Gagne em 2009. Esse apresentação foi modificada por Cristiano
Chapter 4: Threads Sobre a apresentação (About the slides) Os slides e figuras dessa apresentação foram criados por Silberschatz, Galvin e Gagne em 2009. Esse apresentação foi modificada por Cristiano
Introdução. Programação Paralela. Motivação. Conhecimento do Hardware. Análise de Desempenho. Modelagem do Problema
 Introdução Programação Paralela Profa Mariana Kolberg e Prof. Luiz Gustavo Fernandes Programação paralela é a divisão de um problema em partes, de maneira que essas partes possam ser executadas paralelamente
Introdução Programação Paralela Profa Mariana Kolberg e Prof. Luiz Gustavo Fernandes Programação paralela é a divisão de um problema em partes, de maneira que essas partes possam ser executadas paralelamente
Programação Paralela. Profa Mariana Kolberg e Prof. Luiz Gustavo Fernandes
 Programação Paralela Profa Mariana Kolberg e Prof. Luiz Gustavo Fernandes Introdução Programação paralela é a divisão de um problema em partes, de maneira que essas partes possam ser executadas paralelamente
Programação Paralela Profa Mariana Kolberg e Prof. Luiz Gustavo Fernandes Introdução Programação paralela é a divisão de um problema em partes, de maneira que essas partes possam ser executadas paralelamente
Processos O conceito de processos é fundamental para a implementação de um sistema multiprogramável. De uma maneira geral, um processo pode ser entend
 Concorrência Nos sistemas Monoprogramáveis somente um programa pode estar em execução por vez, permanecendo o processador dedicado a esta única tarefa. Os recursos como memória, processador e dispositivos
Concorrência Nos sistemas Monoprogramáveis somente um programa pode estar em execução por vez, permanecendo o processador dedicado a esta única tarefa. Os recursos como memória, processador e dispositivos
Sistemas Distribuídos
 Sistemas Distribuídos Motivação Aplicações Motivam Possibilita Engenharia Motivação! Aplicações cada vez mais complexas! Qual a técnica mais comum para redução de complexidade? " Modularização Dividir
Sistemas Distribuídos Motivação Aplicações Motivam Possibilita Engenharia Motivação! Aplicações cada vez mais complexas! Qual a técnica mais comum para redução de complexidade? " Modularização Dividir
Sistemas Operacionais. Prof. Pedro Luís Antonelli Anhanguera Educacional
 Sistemas Operacionais Prof. Pedro Luís Antonelli Anhanguera Educacional ARQUITETURA E IMPLEMENTAÇÃO Pacote de Threads Conjunto de rotinas disponíveis para que uma aplicação utilize as facilidades dos threads.
Sistemas Operacionais Prof. Pedro Luís Antonelli Anhanguera Educacional ARQUITETURA E IMPLEMENTAÇÃO Pacote de Threads Conjunto de rotinas disponíveis para que uma aplicação utilize as facilidades dos threads.
Comunicação entre Processos
 Comunicação entre Processos Prof. Dr. André Carvalho [email protected] Agenda n Comunicação entre Processos n Características dos mecanismos de comunicação Comunicação direta ou indireta, sincronismos,
Comunicação entre Processos Prof. Dr. André Carvalho [email protected] Agenda n Comunicação entre Processos n Características dos mecanismos de comunicação Comunicação direta ou indireta, sincronismos,
SSC PROGRAMAÇÃO CONCORRENTE. Aula 03 Terminologia Geral de Computação Paralela Prof. Jó Ueyama
 SSC- 0742 PROGRAMAÇÃO CONCORRENTE Aula 03 Terminologia Geral de Computação Paralela Prof. Jó Ueyama Créditos Os slides integrantes deste material foram construídos a par4r dos conteúdos relacionados às
SSC- 0742 PROGRAMAÇÃO CONCORRENTE Aula 03 Terminologia Geral de Computação Paralela Prof. Jó Ueyama Créditos Os slides integrantes deste material foram construídos a par4r dos conteúdos relacionados às
Redes de Computadores. INF201 - Fundamentos de Sistemas Operacionais - 2º Período
 Redes de Computadores INF201 - Fundamentos de Sistemas Operacionais - 2º Período PARTE II: PROCESSOS E THREADS SUMÁRIO 5. PROCESSO: 5.1 Introdução; 5.2 Estrutura do Processo; 5.3 Estados do Processo; 5.4
Redes de Computadores INF201 - Fundamentos de Sistemas Operacionais - 2º Período PARTE II: PROCESSOS E THREADS SUMÁRIO 5. PROCESSO: 5.1 Introdução; 5.2 Estrutura do Processo; 5.3 Estados do Processo; 5.4
Barramento. Prof. Leonardo Barreto Campos 1
 Barramento Prof. Leonardo Barreto Campos 1 Sumário Introdução; Componentes do Computador; Funções dos Computadores; Estrutura de Interconexão; Interconexão de Barramentos Elementos de projeto de barramento;
Barramento Prof. Leonardo Barreto Campos 1 Sumário Introdução; Componentes do Computador; Funções dos Computadores; Estrutura de Interconexão; Interconexão de Barramentos Elementos de projeto de barramento;
Sistemas Operacionais
 Sistemas Operacionais Gerência de Memória Memória virtual Edson Moreno [email protected] http://www.inf.pucrs.br/~emoreno Slides baseados nas apresentações dos prof. Tiago Ferreto e Alexandra Aguiar
Sistemas Operacionais Gerência de Memória Memória virtual Edson Moreno [email protected] http://www.inf.pucrs.br/~emoreno Slides baseados nas apresentações dos prof. Tiago Ferreto e Alexandra Aguiar
Capítulo 2. Multiprogramação. Conteúdo. Objetivo. Recordando. Recordando. DCA-108 Sistemas Operacionais
 DCA-108 Sistemas Operacionais Capítulo 2 Luiz Affonso Guedes www.dca.ufrn.br/~affonso [email protected] Multiprogramação Luiz Affonso Guedes 1 Luiz Affonso Guedes 2 Conteúdo Caracterização de um SO Moderno
DCA-108 Sistemas Operacionais Capítulo 2 Luiz Affonso Guedes www.dca.ufrn.br/~affonso [email protected] Multiprogramação Luiz Affonso Guedes 1 Luiz Affonso Guedes 2 Conteúdo Caracterização de um SO Moderno
Fundamentos de Sistemas Operacionais
 Fundamentos de Sistemas Operacionais Aula 4: Programação Concorrente Diego Passos Últimas Aulas Processos Compostos por: Código (programa). Estado (memória, registradores). Em um sistema com multiprogramação:
Fundamentos de Sistemas Operacionais Aula 4: Programação Concorrente Diego Passos Últimas Aulas Processos Compostos por: Código (programa). Estado (memória, registradores). Em um sistema com multiprogramação:
Bacharelado em Sistemas de Informação Sistemas Operacionais. Prof. Filipo Mór
 Bacharelado em Sistemas de Informação Sistemas Operacionais Prof. Filipo Mór WWW.FILIPOMOR.COM - REVISÃO ARQUITETURAS PARALELAS Evolução das Arquiteturas Evolução das Arquiteturas Entrada CPU Saída von
Bacharelado em Sistemas de Informação Sistemas Operacionais Prof. Filipo Mór WWW.FILIPOMOR.COM - REVISÃO ARQUITETURAS PARALELAS Evolução das Arquiteturas Evolução das Arquiteturas Entrada CPU Saída von
Arquitetura de Computadores. Processamento Paralelo
 Arquitetura de Computadores Processamento Paralelo 1 Multiprogramação e Multiprocessamento Múltiplas organizações de computadores Single instruction, single data stream - SISD Single instruction, multiple
Arquitetura de Computadores Processamento Paralelo 1 Multiprogramação e Multiprocessamento Múltiplas organizações de computadores Single instruction, single data stream - SISD Single instruction, multiple
Processos e Threads e em sistemas distribuídos. Prof. Me. Hélio Esperidião
 Processos e Threads e em sistemas distribuídos. Prof. Me. Hélio Esperidião Processos Sistemas operacionais modernos criam vários processadores virtuais, cada um para executar um programa. Para monitorar
Processos e Threads e em sistemas distribuídos. Prof. Me. Hélio Esperidião Processos Sistemas operacionais modernos criam vários processadores virtuais, cada um para executar um programa. Para monitorar
Sistemas Operacionais
 Sistemas Operacionais Prof. Fabio Augusto Oliveira Processos O processador é projetado apenas para executar instruções, não sendo capaz de distinguir qual programa se encontra em execução. A gerência de
Sistemas Operacionais Prof. Fabio Augusto Oliveira Processos O processador é projetado apenas para executar instruções, não sendo capaz de distinguir qual programa se encontra em execução. A gerência de
Message Passing Interface - MPI
 Message Passing Interface - Pedro de Botelho Marcos Maio/2008 1 Sumário Introdução; Conceitos básicos; Comunicação; Principais rotinas; Compilando e executando códigos ; Exemplos; Referências; 2 Introdução
Message Passing Interface - Pedro de Botelho Marcos Maio/2008 1 Sumário Introdução; Conceitos básicos; Comunicação; Principais rotinas; Compilando e executando códigos ; Exemplos; Referências; 2 Introdução
Sistemas Distribuídos Capítulo 3 - Aula 3
 Sistemas Distribuídos Capítulo 3 - Aula 3 Aula passada Arquitetura de SDs Estilo Arquitetônico Arquitetura de Sistemas Sistemas Autogerenciáveis Aula de hoje Threads Threads em SDs Processos Clientes Processos
Sistemas Distribuídos Capítulo 3 - Aula 3 Aula passada Arquitetura de SDs Estilo Arquitetônico Arquitetura de Sistemas Sistemas Autogerenciáveis Aula de hoje Threads Threads em SDs Processos Clientes Processos
Ruby e JRuby em... Paralelos e Distribuídos. Felipe Barden Lucas Fialho Zawacki
 Ruby e JRuby em... Paralelos e Distribuídos Felipe Barden 151343 Lucas Fialho Zawacki 172072 Sobre o que vamos falar? A linguagem Ruby e suas aplicações em programação paralela e distribuída. A implementação
Ruby e JRuby em... Paralelos e Distribuídos Felipe Barden 151343 Lucas Fialho Zawacki 172072 Sobre o que vamos falar? A linguagem Ruby e suas aplicações em programação paralela e distribuída. A implementação
Arquiteturas Paralelas
 ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES Arquiteturas Paralelas Medidas de desempenho Alexandre Amory Edson Moreno Índice 2 1. Introdução 2. Medidas de Desempenho Introdução 3 Aumento de desempenho dos
ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES Arquiteturas Paralelas Medidas de desempenho Alexandre Amory Edson Moreno Índice 2 1. Introdução 2. Medidas de Desempenho Introdução 3 Aumento de desempenho dos
Processos Concorrentes
 Processos Concorrentes Walter Fetter Lages [email protected] Universidade Federal do Rio Grande do Sul Escola de Engenharia Departamento de Engenharia Elétrica ENG04008 Sistemas de Tempo Real Copyright
Processos Concorrentes Walter Fetter Lages [email protected] Universidade Federal do Rio Grande do Sul Escola de Engenharia Departamento de Engenharia Elétrica ENG04008 Sistemas de Tempo Real Copyright
Vamos fazer um pequeno experimento
 1 Vamos fazer um pequeno experimento Dividam-se em dois grupos: Mestre Escravo Projeto de Sistemas Distribuídos Comunicação entre Processos Prof. Msc. Marcelo Iury de Sousa Oliveira [email protected]
1 Vamos fazer um pequeno experimento Dividam-se em dois grupos: Mestre Escravo Projeto de Sistemas Distribuídos Comunicação entre Processos Prof. Msc. Marcelo Iury de Sousa Oliveira [email protected]
Thread. Thread. Sistemas Operacionais. Leonard B. Moreira. UNIVERSIDADE ESTÁCIO DE SÁ fevereiro, / 41
 Thread Sistemas Operacionais Leonard B. Moreira UNIVERSIDADE ESTÁCIO DE SÁ e-mail: [email protected] fevereiro, 2013 1 / 41 Sumário 1 Introdução 2 Ambientes Monothread 3 Ambientes Multithread
Thread Sistemas Operacionais Leonard B. Moreira UNIVERSIDADE ESTÁCIO DE SÁ e-mail: [email protected] fevereiro, 2013 1 / 41 Sumário 1 Introdução 2 Ambientes Monothread 3 Ambientes Multithread
Sistemas Distribuídos
 Sistemas Distribuídos Classificação de Flynn Fonte: Professoras. Sarita UFRJ e Thais V. Batista - UFRN Arquiteturas Paralelas Computação Paralela Conceitos Permite a execução das tarefas em menor tempo,
Sistemas Distribuídos Classificação de Flynn Fonte: Professoras. Sarita UFRJ e Thais V. Batista - UFRN Arquiteturas Paralelas Computação Paralela Conceitos Permite a execução das tarefas em menor tempo,
Micro-Arquiteturas de Alto Desempenho. Introdução. Ementa
 DCC-IM/NCE UFRJ Pós-Graduação em Informática Micro-Arquiteturas de Alto Desempenho Introdução Gabriel P. Silva Ementa Revisão de Organização de Computadores Hierarquia de Memória Memória Virtual Memória
DCC-IM/NCE UFRJ Pós-Graduação em Informática Micro-Arquiteturas de Alto Desempenho Introdução Gabriel P. Silva Ementa Revisão de Organização de Computadores Hierarquia de Memória Memória Virtual Memória