MPI - Continuação. Qual o output do programa: from mpi4py import MPI comm = MPI.COMM_WORLD nprocs = comm.get_size() rank = comm.
|
|
|
- Tânia Cipriano Lage
- 5 Há anos
- Visualizações:
Transcrição
1 Qual o output do programa: from mpi4py import MPI comm = MPI.COMM_WORLD nprocs = comm.get_size() rank = comm.get_rank() MPI - Continuação if rank == 0: print ("Myrank: %s:" % rank) for proc in range(1, nprocs): msg = comm.recv( source = proc, tag=9 ) print("hello World from %s: " % proc) else: msg = "Hello world from process" + str(rank) print ("Myrank: %s:" % rank) comm.send(msg, dest=0, tag=9); 2.1

2 2.2 MPI - Exemplos Output:
3 2.3 Deadlock from mpi4py import MPI comm=mpi.comm_world rank = comm.rank MPI - Exemplos print("my rank is : ", rank) if rank==1: data_send= "a" destination_process = 5 source_process = 5 data_received = comm.recv (source = source_process) comm.send( data_send, dest = destination_process ) print ("sending data %s " %data_send + \ "to process %d" %destination_process) print ("data received is = %s" %data_received)
4 2.4 MPI - Exemplos Deadlock if rank==5: data_send= "b" destination_process = 1 source_process = 1 data_received = comm.recv (source = source_process) comm.send( data_send, dest = destination_process ) print ("sending data %s :" %data_send + \ "to process %d" %destination_process) print ("data received is = %s" %data_received) - O que acontece?
5 MPI - Exemplos Deadlock E se trocarmos as instruções: if rank==1: comm.send( data_send, dest = destination_process ) data_received = comm.recv (source = source_process) if rank==5: data_received = comm.recv (source = source_process) comm.send( data_send, dest = destination_process ) - O que acontece? Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd Edition, by B. Wilkinson & M. Allen, 2004 Pearson Education Inc. All rights reserved. 2.5

6 Deadlock MPI - Exemplos Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd Edition, by B. Wilkinson & M. Allen, 2004 Pearson Education Inc. All rights reserved. 2.6
7 2.7 Deadlock MPI - Exemplos E se for assim? if rank==1: comm.send( data_send, dest = destination_process ) data_received = comm.recv (source = source_process) if rank==5: comm.send( data_send, dest = destination_process ) data_received = comm.recv (source = source_process)
8 2.8 Instrução sendrecv: MPI - Exemplos Sendrecv(self, sendbuf, int dest, int sendtag=0, recvbuf=none, int source=any_source, int recvtag=any_tag, Status status=none) if rank==1: data_received=comm.sendrecv(data_send,dest=destination_process, source=source_process) if rank==5: data_received=comm.sendrecv(data_send,dest=destination_process, source=source_process)
9 2.9 NumPY MPI Package para computação científica. Permite declarar e manipular arrays: import numpy as np a = np.arange(20) print (a) print() b= a.reshape(4,5) print (b)
10 2.10 Comunicar arrays: comm = MPI.COMM_WORLD size = comm.get_size() rank = comm.get_rank() MPI if rank ==0 : data = np.arange (100, dtype = np.float) comm.send (data, dest=1, tag =10 ) elif rank == 1 : data = np.empty (100, dtype = np.float) comm.recv ( data, source = 0, tag = 10) print ( "Process %s received %s " % (rank, data) )

11 2.11 Comunicar arrays: MPI - Exemplos Output send / recv objetos gerais python, lento Send / Recv - arrays contínuos, mais rápido
12 Comunicar arrays: MPI - Arrays - Objetos python são convertidos para streams de bytes antes do envio. - No recetor as streams de bytes são novamente convertidas para objetos python. - A conversão introduz overhead na comunicação. - Arrays NumPy (contínuos) podem ser transmitidos com baixo overhead usando os métodos: Send(data, dest, tag) Recv(data, source, tag) Notar a diferença na receção: o array tem de já existir. 2.12
13 MPI - Arrays Status data = rank*np.ones(5,dtype = np.float64) print ("process: %s data: %s " % (rank, data)) if rank == 0: comm.send([data,3,mpi.double],dest=1,tag=1) if rank == 1: info = MPI.Status() comm.recv(data, MPI.ANY_SOURCE, MPI.ANY_TAG, info) source = info.get_source() tag = info.get_tag() count = info.get_elements(mpi.double) // nº de doubles size = info.get_count() // nº de bytes print ("on %s process: source: %s tag: %s count: %s, size: %s" % print (data)?? (rank, source, tag, count, size)) 2.13
14 2.14 Output: MPI - Arrays
15 2.15 MPI - Arrays Probe if rank == 0: data = rank*np.ones(5,dtype = np.float64) comm.send([data,3,mpi.double],dest=1,tag=1) if rank == 1: info = MPI.Status() comm.probe(mpi.any_source, MPI.ANY_TAG, info) count = info.get_elements(mpi.double) data = np.empty(count, dtype = np.float64) #! comm.recv(data,mpi.any_source,mpi.any_tag, info) print ("Process: %s data: %s " % (rank, data))! Criar o buffer de receção com a dimensão dos dados a receber.
16 MPI broadcast Um valor é enviado do processo root para todos os outros processos from mpi4py import MPI comm = MPI.COMM_WORLD rank = comm.get_rank() if rank == 0: variable_to_share = 100 else: variable_to_share = None variable_to_share = comm.bcast(variable_to_share, root=0) print("process = %d" %rank + " variable shared = %d " %variable_to_share) mpiexec np 8 python exemplo.py Qual o output? 2.16
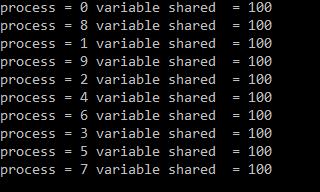
17 2.17 MPI
18 2.18 MPI Broacast de um array: data = np.empty(10, dtype = np.int ) if rank == 0: data = np.arange( 10, dtype = np.int) comm.bcast ( [data, 10, MPI.INT], root = 0) print ("rank %s data: %s" % (rank, data)) output?
19 2.19 MPI Difundir um elemento por todos os processos. Difundir os elementos de um array por todos os processos, seguindo a ordem do seu rank.
20 MPI 2.20 scatter from mpi4py import MPI comm = MPI.COMM_WORLD rank = comm.get_rank() if rank == 0: array_to_share = [1, 2, 3, 4,5,6,7, 8,9,10] else: array_to_share = None recvbuf = comm.scatter(array_to_share, root=0) print("process = %d" %rank + " variable shared = %d " %recvbuf )

21 2.21 MPI mpiexec np 10 python exemplo.py
22 MPI 2.22 Scatter size = comm.get_size() a_size = 4 recvdata = np.empty(a_size,dtype=np.float64) senddata = None if rank == 0: senddata = np.arange(size*a_size,dtype=np.float64) comm.scatter(senddata, recvdata,root=0) print ("on process %s after Scatter: data = %s" % (rank, recvdata)) Output? com mpiexec np 2 python exemplo.py
23 2.23 MPI Scatter E com mpiexec np 4 python exemplo.py?
24 MPI Scatterv size = comm.get_size() a_size = 4 senddata = None recvdata = np.empty(a_size, dtype=np.float64) counts = None dspls = None if rank == 0: senddata = np.arange(100,dtype=np.float64) counts=(1,2,3) <= tamanho de cada bloco dspls=(4,3,10) <= posição inicial de cada bloco comm.scatterv([senddata,counts,dspls, MPI.DOUBLE],recvdata,root=0) print ("X on process %s after Scatter: data = %s" % (rank, recvdata)) 2.24

25 2.25 MPI Scatterv Output:
26 2.26 MPI Gather Recolhe dados de todos os processo e reúne-os no processo root, ordenado pelo rank do processo origem.
27 MPI 2.27 gather from mpi4py import MPI comm = MPI.COMM_WORLD size = comm.get_size() rank = comm.get_rank() data1 = (rank+1)**2 data = comm.gather(data1, root=0) if rank == 0: print ("rank = %s " %rank + "...receiving data from other process") print (data) mpiexec np 10 python exemplo.py Qual o output?
28 MPI 2.28 gather Output:
29 MPI 2.29 Gather (arrays) from mpi4py import MPI import numpy as np comm = MPI.COMM_WORLD size = comm.get_size() rank = comm.get_rank() size = comm.get_size() Output? a_size = 4 recvdata = None senddata = (rank+1)*np.arange(a_size, dtype=np.float64) if rank == 0: recvdata = np.arange(size*a_size,dtype=np.float64) comm.gather(senddata,recvdata,root=0) print ("on process %s, after Gather data = %s" % (rank, recvdata ))
30 2.30 MPI Gather (arrays) Output: (com np = 3)
31 MPI Gatherv (arrays) a_size = 4 recvdata = None senddata = (rank+1)* np.arange(a_size,dtype=np.float64) counts=(2,3,4) dspls=(0,3,8) if rank == 0: recvdata = np.zeros(size*a_size,dtype=np.float64) sendbuf = [senddata, counts[rank] ] recvbuf = [recvdata, counts, dspls, MPI.DOUBLE] comm.gatherv(sendbuf,recvbuf,root=0) print ("on process %s, after Gather data = %s" % (rank, recvdata)) Output? 2.31

32 2.32 MPI Gatherv (arrays)
 O objeto da posição i, do processo j")
33 MPI 2.33 Alltoall (sendbuf, recvbuf) O objeto da posição i, do processo j (sendbuf), é copiado para o objeto j do processo i (recvbuf).
34 MPI 2.34 from mpi4py import MPI import numpy comm = MPI.COMM_WORLD size = comm.get_size() rank = comm.get_rank() a_size = 1 senddata = (rank+1)*numpy.arange(size,dtype=int) recvdata = numpy.empty(size*a_size,dtype=int) comm.alltoall(senddata,recvdata) print(" process %s sending %s receiving %s %(rank, senddata, recvdata))
 Exemplos de aplicação: - Transposição de matrizes; - Transformadas de")
35 MPI 2.35 Alltoall (sendbuf, recvbuf) Exemplos de aplicação: - Transposição de matrizes; - Transformadas de Fourier (Fast Fourier transform); - Operações de ordenação; - Operações de join em bases de dados;
36 2.36 MPI Explorar: alltoallv (sendbuf, recvbuf) e Alltoallv (sendbuf, recvbuf)
37 2.37 MPI Reduce recvobj = comm.reduce(sendobj=none, op=mpi.sum, root=0) comm.reduce(sendbuf, recvbuf, op=mpi.sum, root=0)
38 MPI 2.38 Reduce - exemplo import numpy as np from mpi4py import MPI comm = MPI.COMM_WORLD size = comm.size rank = comm.rank a_size = 3 recvdata = numpy.zeros(a_size,dtype=numpy.int) senddata = (rank+1)*numpy.arange(a_size, dtype=numpy.int) print(" process %s sending %s " %(rank, senddata)) comm.reduce(senddata,recvdata,root=0,op=mpi.sum) print ('on task',rank,'after Reduce: data = ',recvdata)

39 2.39 MPI Reduce - exemplo
40 MPI 2.40 Reduce operações MPI.MIN minimum MPI.MAX maximum MPI.SUM sum MPI.PROD product MPI.LAND logical and MPI.BAND bitwise and MPI.LOR logical or MPI.BOR bitwise or MPI.LXOR logical xor MPI.BXOR bitwise xor MPI.MAXLOC max value and location rank MPI.MINLOC min value and location rank

41 MPI 2.41 allreduce e Allreduce: recvobj = comm.allreduce(sendobj=none, op=mpi.sum) comm.allreduce(sendbuf, recvbuf, op=mpi.sum) (Distribuem os valores por todos os processos, equivalente a MPI_Reduce seguido de MPI_Bcast) root?
Sistemas Distribuídos Message-Passing
 0010010101011101010111100010111100010101010100100111001010001001010100101010100010010100101010110101010101 01100000011111101010010100010101010010010101101001000100101010111010101111000101111 101010101001001110010100010010101001010101000100101001010101101010101010110000001111110101001010001010101001001010110100100010010
0010010101011101010111100010111100010101010100100111001010001001010100101010100010010100101010110101010101 01100000011111101010010100010101010010010101101001000100101010111010101111000101111 101010101001001110010100010010101001010101000100101001010101101010101010110000001111110101001010001010101001001010110100100010010
MPI (Message Passing Interface)
") MPI (Message Passing Interface) Standard desenvolvido por académicos e indústria. Define rotinas, não a implementação. Não define como se criam os processos (depende da implementação) Existem várias implementações
MPI (Message Passing Interface) Standard desenvolvido por académicos e indústria. Define rotinas, não a implementação. Não define como se criam os processos (depende da implementação) Existem várias implementações
Comunicação Coletiva
 Comunicação Coletiva Sempre envolve um grupo de processos; Sempre envolve todos os processos de um comunicador; Podem ser implementadas com as rotinas ponto a ponto (mas é má idéia); Implementam os padrões
Comunicação Coletiva Sempre envolve um grupo de processos; Sempre envolve todos os processos de um comunicador; Podem ser implementadas com as rotinas ponto a ponto (mas é má idéia); Implementam os padrões
Aula 5 Computação Distribuída de Alto Desempenho
 CBPF Centro Brasileiro de Pesquisas Físicas Aula 5 Computação Distribuída de Alto Desempenho Marcelo Portes de Albuquerque Nilton Alves Marcelo Giovanni Rio de Janeiro 17 a 28 de julho de 2006 Sumário
CBPF Centro Brasileiro de Pesquisas Físicas Aula 5 Computação Distribuída de Alto Desempenho Marcelo Portes de Albuquerque Nilton Alves Marcelo Giovanni Rio de Janeiro 17 a 28 de julho de 2006 Sumário
EXERCÍCIO 1 MUDANDO AS CORES
 EXERCÍCIO 1 MUDANDO AS CORES O código abaixo ilustra o uso da comunicação ponto-a-ponto e a comunicação coletiva. Nesse código, uma matriz de três cores (verde, branco, vermelho e) é distribuída para todos
EXERCÍCIO 1 MUDANDO AS CORES O código abaixo ilustra o uso da comunicação ponto-a-ponto e a comunicação coletiva. Nesse código, uma matriz de três cores (verde, branco, vermelho e) é distribuída para todos
Técnicas de Paralelização
 Técnicas de Paralelização 2 Particionar e dividir para conquistar Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by B. Wilkinson &
Técnicas de Paralelização 2 Particionar e dividir para conquistar Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by B. Wilkinson &
Introdução a Computação Paralela: Rotinas MPI em Clusters Beowulf
 Introdução a Computação Paralela: Rotinas MPI em Clusters Beowulf Miguel Dias Costa João Viana Lopes Centro de Física do Porto Estrutura do Curso Motivação Estrutura do Curso Motivação Conceitos de Computação
Introdução a Computação Paralela: Rotinas MPI em Clusters Beowulf Miguel Dias Costa João Viana Lopes Centro de Física do Porto Estrutura do Curso Motivação Estrutura do Curso Motivação Conceitos de Computação
Message Passing Interface - MPI
 Message Passing Interface - Pedro de Botelho Marcos Maio/2008 1 Sumário Introdução; Conceitos básicos; Comunicação; Principais rotinas; Compilando e executando códigos ; Exemplos; Referências; 2 Introdução
Message Passing Interface - Pedro de Botelho Marcos Maio/2008 1 Sumário Introdução; Conceitos básicos; Comunicação; Principais rotinas; Compilando e executando códigos ; Exemplos; Referências; 2 Introdução
Aula 3 Computação Distribuída de Alto Desempenho
 CBPF Centro Brasileiro de Pesquisas Físicas Aula 3 Computação Distribuída de Alto Desempenho Marcelo Portes de Albuquerque Nilton Alves Marcelo Giovanni Rio de Janeiro 17 a 28 de julho de 2006 Sumário
CBPF Centro Brasileiro de Pesquisas Físicas Aula 3 Computação Distribuída de Alto Desempenho Marcelo Portes de Albuquerque Nilton Alves Marcelo Giovanni Rio de Janeiro 17 a 28 de julho de 2006 Sumário
Por que dez milhões de cores?
 O primeiro passo para programar dez milhões de cores Álvaro Fazenda Denise Stringhini ICT-UNIFESP São José dos Campos ERAD-SP 2016 Por que dez milhões de cores? 192 top500.org (junho/2016) E o Brasil no
O primeiro passo para programar dez milhões de cores Álvaro Fazenda Denise Stringhini ICT-UNIFESP São José dos Campos ERAD-SP 2016 Por que dez milhões de cores? 192 top500.org (junho/2016) E o Brasil no
Programação Paralela com Troca de Mensagens. Profa Andréa Schwertner Charão DLSC/CT/UFSM
 Programação Paralela com Troca de Mensagens Profa Andréa Schwertner Charão DLSC/CT/UFSM Sumário Modelo de programa MPI Comunicação em MPI Comunicadores Mensagens Comunicação ponto-a-ponto Comunicação coletiva
Programação Paralela com Troca de Mensagens Profa Andréa Schwertner Charão DLSC/CT/UFSM Sumário Modelo de programa MPI Comunicação em MPI Comunicadores Mensagens Comunicação ponto-a-ponto Comunicação coletiva
Programação Concorrente e Paralela
 Comunicação por Troca de Mensagens 2016 Troca de Mensagens forma básica de comunicação em ambientes de memória distribuída outras camadas podem ser construídas sobre trocas de mensagens básicas mas também
Comunicação por Troca de Mensagens 2016 Troca de Mensagens forma básica de comunicação em ambientes de memória distribuída outras camadas podem ser construídas sobre trocas de mensagens básicas mas também
Programação em sistemas de memória distribuída
 Programação em sistemas de memória distribuída (Message-Passing Computing) Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd Edition, by B.
Programação em sistemas de memória distribuída (Message-Passing Computing) Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd Edition, by B.
Paralela e Distribuída. Memória Distribuída com o MPI
 Programação Paralela e Distribuída Programação em Memória Distribuída com o MPI Programação em Memória Distribuída As aplicações são vistas como um conjunto de programas que são executados de forma independente
Programação Paralela e Distribuída Programação em Memória Distribuída com o MPI Programação em Memória Distribuída As aplicações são vistas como um conjunto de programas que são executados de forma independente
Algoritmos Paralelos usando CGM/MPI. Edson Norberto Cáceres e Siang Wun Song DCT/UFMS e DCC/IME/USP Aula 05
 Algoritmos Paralelos usando CGM/MPI Edson Norberto Cáceres e Siang Wun Song DCT/UFMS e DCC/IME/USP Aula 05 Algoritmos Paralelos BSP/CGM Objetivos Descrever algumas das principais técnicas para o desenvolvimento
Algoritmos Paralelos usando CGM/MPI Edson Norberto Cáceres e Siang Wun Song DCT/UFMS e DCC/IME/USP Aula 05 Algoritmos Paralelos BSP/CGM Objetivos Descrever algumas das principais técnicas para o desenvolvimento
Comunicação Interprocessos
 Comunicação Interprocessos Programação Paralela e Distribuída Conceito de Programa e Execução Graduação em Ciência da Computação Universidade do Vale do Rio dos Sinos Prof. Gerson Cavalheiro Programação
Comunicação Interprocessos Programação Paralela e Distribuída Conceito de Programa e Execução Graduação em Ciência da Computação Universidade do Vale do Rio dos Sinos Prof. Gerson Cavalheiro Programação
Message Passing Interface - MPI. Jorge Barbosa
 Message Passing Interface - MPI Jorge Barbosa Introdução ao MPI Até ao fim dos anos 80, os fabricantes de computadores desenvolviam a sua própria biblioteca de funções para desenvolver programas paralelos.
Message Passing Interface - MPI Jorge Barbosa Introdução ao MPI Até ao fim dos anos 80, os fabricantes de computadores desenvolviam a sua própria biblioteca de funções para desenvolver programas paralelos.
Jorge Barbosa, FEUP-DEI 2008
 Técnicas para paralelização de aplicações Jorge Barbosa, FEUP-DEI 2008 Índice Introdução Técnicas de paralelização de aplicações Nível 1: Usando código sequencial Nível 2: Alteração mínima de código sequencial
Técnicas para paralelização de aplicações Jorge Barbosa, FEUP-DEI 2008 Índice Introdução Técnicas de paralelização de aplicações Nível 1: Usando código sequencial Nível 2: Alteração mínima de código sequencial
Computação por Passagem de Mensagens
 Computação por Passagem de Mensagens Programação por passagem de mensagens Programação de multiprocessadores conectados por rede pode ser realizada: criando-se uma linguagem de programação paralela especial
Computação por Passagem de Mensagens Programação por passagem de mensagens Programação de multiprocessadores conectados por rede pode ser realizada: criando-se uma linguagem de programação paralela especial
Programação Paralela em Memória Compartilhada e Distribuída
 Programação Paralela em Memória Compartilhada e Distribuída Prof. Claudio Schepke claudioschepke@unipampa.edu.br Prof. João V. F. Lima jvlima@inf.ufsm.br (baseado em material elaborado por professores
Programação Paralela em Memória Compartilhada e Distribuída Prof. Claudio Schepke claudioschepke@unipampa.edu.br Prof. João V. F. Lima jvlima@inf.ufsm.br (baseado em material elaborado por professores
Curso de Informática DCC-IM / UFRJ. Gabriel P. Silva MPI
 Curso de Informática DCC-IM / UFRJ MPI Um curso prático Gabriel P. Silva MPI É um padrão de troca de mensagens portátil que facilita o desenvolvimento de aplicações paralelas. Usa o paradigma de programação
Curso de Informática DCC-IM / UFRJ MPI Um curso prático Gabriel P. Silva MPI É um padrão de troca de mensagens portátil que facilita o desenvolvimento de aplicações paralelas. Usa o paradigma de programação
Computação por Passagem de Mensagens
 Computação por Passagem de Mensagens Programação por passagem de mensagens Programação de multiprocessadores conectados por rede pode ser realizada: criando-se uma linguagem de programação paralela especial
Computação por Passagem de Mensagens Programação por passagem de mensagens Programação de multiprocessadores conectados por rede pode ser realizada: criando-se uma linguagem de programação paralela especial
Comunicação orientada a mensagens
 Comunicação orientada a mensagens críticas a RPC sincronismo modelo um a um dificuldades de tratamento de falhas Þ volta ao modelo de troca de mensagens com diferentes níveis de abstração Sistemas de mensagens
Comunicação orientada a mensagens críticas a RPC sincronismo modelo um a um dificuldades de tratamento de falhas Þ volta ao modelo de troca de mensagens com diferentes níveis de abstração Sistemas de mensagens
Carla Osthoff LNCC/MCTI Exemplos: https://goo.gl/amxo7e
 Carla Osthoff LNCC/MCTI osthoff@lncc.br Exemplos: https://goo.gl/amxo7e Message Passing Interface www.mpi-forum.org http://mpi-forum.org/docs/ http://mpi-forum.org/mpi-40/ Manual online: http://www.mpich.org/static/docs/latest/
Carla Osthoff LNCC/MCTI osthoff@lncc.br Exemplos: https://goo.gl/amxo7e Message Passing Interface www.mpi-forum.org http://mpi-forum.org/docs/ http://mpi-forum.org/mpi-40/ Manual online: http://www.mpich.org/static/docs/latest/
Parte da Tarefa. Parte da Tarefa. Parte da Tarefa SEND RECEIVE SEND RECEIVE
 Produto Escalar com MPI-2 (C++) Aula Sistemas Distribuídos Prof. Dr. Marcelo Facio Palin profpalin@gmail.com 1 1 O que é Paralelismo? Conceitos Paralelismo é uma técnica usada em tarefas grandes e complexas
Produto Escalar com MPI-2 (C++) Aula Sistemas Distribuídos Prof. Dr. Marcelo Facio Palin profpalin@gmail.com 1 1 O que é Paralelismo? Conceitos Paralelismo é uma técnica usada em tarefas grandes e complexas
Programação de Arquiteturas com Memória Distribuída Utilizando MPI
 Programação de Arquiteturas com Memória Distribuída Utilizando MPI MCZA020-13 - Programação Paralela Emilio Francesquini e.francesquini@ufabc.edu.br 2019.Q1 Centro de Matemática, Computação e Cognição
Programação de Arquiteturas com Memória Distribuída Utilizando MPI MCZA020-13 - Programação Paralela Emilio Francesquini e.francesquini@ufabc.edu.br 2019.Q1 Centro de Matemática, Computação e Cognição
Aula 10 Introdução ao NumPy
 Aula 10 Introdução ao NumPy Gilberto Ribeiro de Queiroz Thales Sehn Körting Fabiano Morelli 16 de Abril de 2018 NumPy - descrição http://www.numpy.org/ NumPy is the fundamental package for scientific computing
Aula 10 Introdução ao NumPy Gilberto Ribeiro de Queiroz Thales Sehn Körting Fabiano Morelli 16 de Abril de 2018 NumPy - descrição http://www.numpy.org/ NumPy is the fundamental package for scientific computing
Comunicação Ponto a Ponto
 Comunicação Ponto a Ponto Transferência de dados entre processos específicos, que não se encaixam em um padrão global pré definido; Sempre ocorre entre dois processos, um processo que envia e outro que
Comunicação Ponto a Ponto Transferência de dados entre processos específicos, que não se encaixam em um padrão global pré definido; Sempre ocorre entre dois processos, um processo que envia e outro que
Programação Paralela
 Programação Paralela Conteúdo: Introdução Motivação Desafios Modelagem Programação Paralela Memória Compartilhada Pthreads Programação Paralela Troca de Mensagens MPI Métricas de desempenho Introdução
Programação Paralela Conteúdo: Introdução Motivação Desafios Modelagem Programação Paralela Memória Compartilhada Pthreads Programação Paralela Troca de Mensagens MPI Métricas de desempenho Introdução
Message Passing Interface
 Message Passing Interface Gonzalo Travieso 2010 Sumário 1 Conceitos Básicos 1 Inicialização e Finalização...................................................... 1 Processos...............................................................
Message Passing Interface Gonzalo Travieso 2010 Sumário 1 Conceitos Básicos 1 Inicialização e Finalização...................................................... 1 Processos...............................................................
Message Passing Interface
 Message Passing Interface Gonzalo Travieso 2011 Sumário 1 Conceitos Básicos 2 Inicialização e Finalização........................................... 3 Processos....................................................
Message Passing Interface Gonzalo Travieso 2011 Sumário 1 Conceitos Básicos 2 Inicialização e Finalização........................................... 3 Processos....................................................
Curso de Informática DCC-IM / UFRJ MPI. Um curso prático. Gabriel P. Silva
 Curso de Informática DCC-IM / UFRJ MPI Um curso prático Gabriel P. Silva MPI É um padrão de troca de mensagens portátil que facilita o desenvolvimento de aplicações paralelas. Usa o paradigma de programação
Curso de Informática DCC-IM / UFRJ MPI Um curso prático Gabriel P. Silva MPI É um padrão de troca de mensagens portátil que facilita o desenvolvimento de aplicações paralelas. Usa o paradigma de programação
Linguagem Chapel. Autor: Walter Perez Urcia
 Universidade de São Paulo Instituto de Matemática e Estatística MAC 5742 - Computação Paralela e Distribuída Linguagem Chapel Autor: Walter Perez Urcia São Paulo Junio 2015 Resumo Neste artigo o objetivo
Universidade de São Paulo Instituto de Matemática e Estatística MAC 5742 - Computação Paralela e Distribuída Linguagem Chapel Autor: Walter Perez Urcia São Paulo Junio 2015 Resumo Neste artigo o objetivo
Programação Paralela e Distribuída ERAD-SP de julho de 2010 Liria Matsumoto Sato
 Programação Paralela e Distribuída ERAD-SP 2010 31 de julho de 2010 Liria Matsumoto Sato liria.sato@poli.usp.br Apresentação Introdução Arquiteturas Paralelas Programação Paralela para computadores com
Programação Paralela e Distribuída ERAD-SP 2010 31 de julho de 2010 Liria Matsumoto Sato liria.sato@poli.usp.br Apresentação Introdução Arquiteturas Paralelas Programação Paralela para computadores com
Programação Paralela e Distribuída
 Programação Paralela e Distribuída Referência: Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd Edition, by B. Wilkinson & M. Allen, 2004
Programação Paralela e Distribuída Referência: Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd Edition, by B. Wilkinson & M. Allen, 2004
ALGORÍTMOS PARALELOS (Aula 5)
") ALGORÍTMOS PARALELOS (Aula 5) Neyval C. Reis Jr. OUTUBRO/2004 LCAD Laboratório de Computação de Alto Desempenho DI/UFES Programa do Curso LCAD 1. Introdução 2. Arquitetura de Computadores 3. Arquiteturas
ALGORÍTMOS PARALELOS (Aula 5) Neyval C. Reis Jr. OUTUBRO/2004 LCAD Laboratório de Computação de Alto Desempenho DI/UFES Programa do Curso LCAD 1. Introdução 2. Arquitetura de Computadores 3. Arquiteturas
Sistemas de Operação II. Ricardo Rocha
 Programação em Memória Distribuída Ricardo Rocha ricroc@dcc.fc.up.pt Programação em Memória Distribuída As aplicações são vistas como um conjunto de programas que são executados de forma independente em
Programação em Memória Distribuída Ricardo Rocha ricroc@dcc.fc.up.pt Programação em Memória Distribuída As aplicações são vistas como um conjunto de programas que são executados de forma independente em
CAP-387(2016) Tópicos Especiais em
 Tópicos Especiais em") CAP-387(2016) Tópicos Especiais em Computação Aplicada: Construção de Aplicações Massivamente Paralelas Aula 33: Programação Híbrida com MPI Celso L. Mendes, Stephan Stephany LAC / INPE Emails: celso.mendes@inpe.br,
CAP-387(2016) Tópicos Especiais em Computação Aplicada: Construção de Aplicações Massivamente Paralelas Aula 33: Programação Híbrida com MPI Celso L. Mendes, Stephan Stephany LAC / INPE Emails: celso.mendes@inpe.br,
Arquitecturas Paralelas I Computação Paralela em Larga Escala. Passagem de Mensagens
 Arquitecturas Paralelas I Computação Paralela em Larga Escala LESI/LMCC - 4º/5º Ano Passagem de Mensagens João Luís Ferreira Sobral Departamento do Informática Universidade do Minho Novembro 2004 Passagem
Arquitecturas Paralelas I Computação Paralela em Larga Escala LESI/LMCC - 4º/5º Ano Passagem de Mensagens João Luís Ferreira Sobral Departamento do Informática Universidade do Minho Novembro 2004 Passagem
Linguagem Chapel. Walter Perez Urcia. Universidade de São Paulo Instituto de Matemática e Estadística Departamento de Ciências da Computação
 Linguagem Chapel Walter Perez Urcia Universidade de São Paulo Instituto de Matemática e Estadística Departamento de Ciências da Computação 17 de junho de 2015 Walter Perez (IME - USP) Linguagem Chapel
Linguagem Chapel Walter Perez Urcia Universidade de São Paulo Instituto de Matemática e Estadística Departamento de Ciências da Computação 17 de junho de 2015 Walter Perez (IME - USP) Linguagem Chapel
Introdução à programação paralela em Fortran usando OpenMP e MPI
 Introdução à programação paralela em Fortran usando OpenMP e MPI Henrique Gavioli Flores,Alex Lima de Mello, Marcelo Trindade Rebonatto Universidade de Passo Fundo 5 de Abril de 2018 1/28 1 / 28 Sumário
Introdução à programação paralela em Fortran usando OpenMP e MPI Henrique Gavioli Flores,Alex Lima de Mello, Marcelo Trindade Rebonatto Universidade de Passo Fundo 5 de Abril de 2018 1/28 1 / 28 Sumário
Exemplo de Arquitetura: Cliente/Servidor com Mestre e Escravos. Interface. Fator de speed-up. Speed-up
 Exemplo de Arquitetura: Cliente/Servidor com Mestre e s Arquitetura Mestre- Speed-up / Cliente Mestre Prof João Paulo A Almeida (jpalmeida@infufesbr) Cliente 2015/01 - INF02799 Com alguns slides de Parallel
Exemplo de Arquitetura: Cliente/Servidor com Mestre e s Arquitetura Mestre- Speed-up / Cliente Mestre Prof João Paulo A Almeida (jpalmeida@infufesbr) Cliente 2015/01 - INF02799 Com alguns slides de Parallel
QUEBRA DE SENHAS MD5 UTILIZANDO MDCRACK E MPI
 UNIVERSIDADE FEDERAL DE SANTA MARIA CENTRO DE TÉCNOLOGIA CURSO DE CIÊNCIA DA COMPUTAÇÃO QUEBRA DE SENHAS MD5 UTILIZANDO MDCRACK E MPI Cicero Augusto de Lara Pahins, Cristiano Reis dos Santos. Professora:
UNIVERSIDADE FEDERAL DE SANTA MARIA CENTRO DE TÉCNOLOGIA CURSO DE CIÊNCIA DA COMPUTAÇÃO QUEBRA DE SENHAS MD5 UTILIZANDO MDCRACK E MPI Cicero Augusto de Lara Pahins, Cristiano Reis dos Santos. Professora:
PROGRAMAS BÁSICOS EM C++ Disciplina: Introdução à Ciência da Computação Prof. Modesto Antonio Chaves Universidade estadual do Sudoeste da Bahia
 PROGRAMAS BÁSICOS EM C++ Disciplina: Introdução à Ciência da Computação Prof. Modesto Antonio Chaves Universidade estadual do Sudoeste da Bahia Calculo da área de um triângulo Algoritmo Área Var base,
PROGRAMAS BÁSICOS EM C++ Disciplina: Introdução à Ciência da Computação Prof. Modesto Antonio Chaves Universidade estadual do Sudoeste da Bahia Calculo da área de um triângulo Algoritmo Área Var base,
Clusters de Alto Desempenho e programação distribuída
 Roteiro da apresentação Clusters de Alto Desempenho e programação distribuída Nicolas Maillard Instituto de Informática UFRGS 2008 O contexto: do Processamento de Alto Desempenho à programação paralela...
Roteiro da apresentação Clusters de Alto Desempenho e programação distribuída Nicolas Maillard Instituto de Informática UFRGS 2008 O contexto: do Processamento de Alto Desempenho à programação paralela...
Algoritmos Paralelos - ordenação
 Algoritmos Paralelos - ordenação Fernando Silva DCC-FCUP (Alguns dos slides são baseados nos do livro Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers, 2nd
Algoritmos Paralelos - ordenação Fernando Silva DCC-FCUP (Alguns dos slides são baseados nos do livro Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers, 2nd
Computação Aplicada:
 CAP-387(2016) Tópicos Especiais em Computação Aplicada: Construção de Aplicações Massivamente Paralelas Aula 29: Comunicação Unilateral em MPI Celso L. Mendes, Stephan Stephany LAC / INPE Emails: celso.mendes@inpe.br,
CAP-387(2016) Tópicos Especiais em Computação Aplicada: Construção de Aplicações Massivamente Paralelas Aula 29: Comunicação Unilateral em MPI Celso L. Mendes, Stephan Stephany LAC / INPE Emails: celso.mendes@inpe.br,
Introdução. Programação Paralela. Motivação. Conhecimento do Hardware. Análise de Desempenho. Modelagem do Problema
 Introdução Programação Paralela Profa Mariana Kolberg e Prof. Luiz Gustavo Fernandes Programação paralela é a divisão de um problema em partes, de maneira que essas partes possam ser executadas paralelamente
Introdução Programação Paralela Profa Mariana Kolberg e Prof. Luiz Gustavo Fernandes Programação paralela é a divisão de um problema em partes, de maneira que essas partes possam ser executadas paralelamente
Programação Paralela. Profa Mariana Kolberg e Prof. Luiz Gustavo Fernandes
 Programação Paralela Profa Mariana Kolberg e Prof. Luiz Gustavo Fernandes Introdução Programação paralela é a divisão de um problema em partes, de maneira que essas partes possam ser executadas paralelamente
Programação Paralela Profa Mariana Kolberg e Prof. Luiz Gustavo Fernandes Introdução Programação paralela é a divisão de um problema em partes, de maneira que essas partes possam ser executadas paralelamente
apt-get install openssh-client (Debian) yum install openssh-clents (Fedora) slapt-get install openssh (Slackware)
 yum install openssh-clents (Fedora) slapt-get install openssh (Slackware)") Capítulo 1 O CLUSTER Acessando o Cluster O cluster pode ser acessado através de SSH. A partir do *UNIX A maioria dps sistemas unix já oferece um cliente ssh (openssh) na instalação padrão. Caso use uma
Capítulo 1 O CLUSTER Acessando o Cluster O cluster pode ser acessado através de SSH. A partir do *UNIX A maioria dps sistemas unix já oferece um cliente ssh (openssh) na instalação padrão. Caso use uma
2 Arquitetura Paralela
 1 Resumo Esta monografia tem como objetivo o desenvolvimento de uma ferramenta para auxiliar no desenvolvimento de programa que utilizam a biblioteca MPI Esta ferramenta mostra ao usuário qual a carga
1 Resumo Esta monografia tem como objetivo o desenvolvimento de uma ferramenta para auxiliar no desenvolvimento de programa que utilizam a biblioteca MPI Esta ferramenta mostra ao usuário qual a carga
Computação II MAB EE2/ET2/ER2. SciPy & NumPy. Brunno Goldstein.
 Computação II MAB 225 - EE2/ET2/ER2 SciPy & NumPy Brunno Goldstein bfgoldstein@cos.ufrj.br www.lam.ufrj.br/~bfgoldstein Ementa Programação Orientada a Objetos Tratamento de Exceções Módulos Manipulação
Computação II MAB 225 - EE2/ET2/ER2 SciPy & NumPy Brunno Goldstein bfgoldstein@cos.ufrj.br www.lam.ufrj.br/~bfgoldstein Ementa Programação Orientada a Objetos Tratamento de Exceções Módulos Manipulação
Aula 01 Algoritmos e lógica de programação e introdução ao C++
 Aula 01 Algoritmos e lógica de programação e introdução ao C++ Autor: Max Rodrigues Marques Carga Horária: 2h 21 de julho de 2015 1 Algoritmo e lógica de programação Ementa do curso 1. Definições de algoritmo
Aula 01 Algoritmos e lógica de programação e introdução ao C++ Autor: Max Rodrigues Marques Carga Horária: 2h 21 de julho de 2015 1 Algoritmo e lógica de programação Ementa do curso 1. Definições de algoritmo
Exercício de MPI Relatório do Trabalho
 PUC-Rio Programação Concorrente e Paralela Exercício de MPI Relatório do Trabalho Danilo Moret Professora: Noemi Rodriguez Enunciado Leiam os capítulos 7 e 8 do livro Parallel Programming in C with MPI
PUC-Rio Programação Concorrente e Paralela Exercício de MPI Relatório do Trabalho Danilo Moret Professora: Noemi Rodriguez Enunciado Leiam os capítulos 7 e 8 do livro Parallel Programming in C with MPI
Aula de hoje. Python para disciplinas básicas. Computação científica. Introdução. Álgebra Linear. Álgebra linear
 SCC 14 - Introdução à Programação para Engenharias Python para disciplinas básicas Professor: André C. P. L. F. de Carvalho, ICMC-USP Pos-doutorando: Isvani Frias-Blanco Monitor: Henrique Bonini de Britto
SCC 14 - Introdução à Programação para Engenharias Python para disciplinas básicas Professor: André C. P. L. F. de Carvalho, ICMC-USP Pos-doutorando: Isvani Frias-Blanco Monitor: Henrique Bonini de Britto
Profa. Thienne Johnson EACH/USP
 Profa. Thienne Johnson EACH/USP Declarando classes usando generics Métodos que usam um parâmetro de tipo como tipo de retorno Declaração da classe BasicGeneric: class BasicGeneric Contém o parâmetro
Profa. Thienne Johnson EACH/USP Declarando classes usando generics Métodos que usam um parâmetro de tipo como tipo de retorno Declaração da classe BasicGeneric: class BasicGeneric Contém o parâmetro
Centro Nacional de Processamento de Alto Desempenho - SP TREINAMENTO: INTRODUÇÃO AO MPI CENAPAD-SP
 1 Centro Nacional de Processamento de Alto Desempenho - SP TREINAMENTO: INTRODUÇÃO AO MPI CENAPAD-SP 2 CONTEÚDO Introdução a Programação Paralela... pag.02 1 - Idéias e Conceitos... pag.02 2 - Comunicação
1 Centro Nacional de Processamento de Alto Desempenho - SP TREINAMENTO: INTRODUÇÃO AO MPI CENAPAD-SP 2 CONTEÚDO Introdução a Programação Paralela... pag.02 1 - Idéias e Conceitos... pag.02 2 - Comunicação
Curso básico de Python para estudantes de Física
 Curso básico de Python para estudantes de Física Germán A. Racca Universidade do Estado do Rio Grande do Norte Faculdade de Ciências Exatas e Naturais Departamento de Física Mossoró - RN 01 de Junho de
Curso básico de Python para estudantes de Física Germán A. Racca Universidade do Estado do Rio Grande do Norte Faculdade de Ciências Exatas e Naturais Departamento de Física Mossoró - RN 01 de Junho de
Manipulação básica de dados no PDI
 Manipulação básica de dados no PDI Conjunto de steps para transformação Categoria Transform Criação de novos campos Uso de expressões Adição de constantes Cálculo de valores Conversão de formatos Correspondência
Manipulação básica de dados no PDI Conjunto de steps para transformação Categoria Transform Criação de novos campos Uso de expressões Adição de constantes Cálculo de valores Conversão de formatos Correspondência
Estatística Computacional A - Aula SAS 01 Estatísticas Descritivas Prof. José Carlos Fogo
 Estatística Computacional A - Aula SAS 01 Estatísticas Descritivas Prof. José Carlos Fogo /* Linha de comando com configurações de página */ options ps=60 ls=80 nodate pageno=1; /* Entrando com um arquivo
Estatística Computacional A - Aula SAS 01 Estatísticas Descritivas Prof. José Carlos Fogo /* Linha de comando com configurações de página */ options ps=60 ls=80 nodate pageno=1; /* Entrando com um arquivo
Programação Funcional Aulas 5 & 6
 Programação Funcional Aulas 5 & 6 Sandra Alves DCC/FCUP 2016/17 Definições usando outras funções Podemos definir funções usando outras previamente definidas (por exemplo: do prelúdio-padrão). Exemplo:
Programação Funcional Aulas 5 & 6 Sandra Alves DCC/FCUP 2016/17 Definições usando outras funções Podemos definir funções usando outras previamente definidas (por exemplo: do prelúdio-padrão). Exemplo:
Tolerância a Falhas. especialmente em grades
 Tolerância a Falhas especialmente em grades tolerância a falhas em geral falhas em SD crash omissão retardo em respostas respostas erradas respostas arbitrárias simplificadamente: falhas bizantinas falhas
Tolerância a Falhas especialmente em grades tolerância a falhas em geral falhas em SD crash omissão retardo em respostas respostas erradas respostas arbitrárias simplificadamente: falhas bizantinas falhas
Programação Paralela. Simone de Lima Martins Agosto/2002
 Programação Paralela Simone de Lima Martins Agosto/2002 Computação por Passagem de Mensagens Arquitetura de computadores que utilizam passagem de mensagens Computadores conectados por uma rede estática
Programação Paralela Simone de Lima Martins Agosto/2002 Computação por Passagem de Mensagens Arquitetura de computadores que utilizam passagem de mensagens Computadores conectados por uma rede estática
CAP-387(2016) Tópicos Especiais em
 Tópicos Especiais em") CAP-387(2016) Tópicos Especiais em Computação Aplicada: Construção de Aplicações Massivamente Paralelas Aula 34: Programação MPI+OpenMP Celso L. Mendes, Stephan Stephany LAC / INPE Emails: celso.mendes@inpe.br,
CAP-387(2016) Tópicos Especiais em Computação Aplicada: Construção de Aplicações Massivamente Paralelas Aula 34: Programação MPI+OpenMP Celso L. Mendes, Stephan Stephany LAC / INPE Emails: celso.mendes@inpe.br,
O Modelo Síncrono BSP para Computação Paralela
 O Modelo Síncrono BSP para Computação Paralela Raphael Y. de Camargo Ricardo Andrade Departamento de Ciência da Computação Instituto de Matemática e Estatística Universidade de São Paulo, Brasil São Paulo,
O Modelo Síncrono BSP para Computação Paralela Raphael Y. de Camargo Ricardo Andrade Departamento de Ciência da Computação Instituto de Matemática e Estatística Universidade de São Paulo, Brasil São Paulo,
K&R: Capitulo 2 IAED, 2012/2013
 Elementos da Linguagem C K&R: Capitulo 2 Elementos da Linguagem C Identificadores Tipos Constantes Declarações Operadores aritméticos, lógicos e relacionais Conversões de tipos Operadores de incremento
Elementos da Linguagem C K&R: Capitulo 2 Elementos da Linguagem C Identificadores Tipos Constantes Declarações Operadores aritméticos, lógicos e relacionais Conversões de tipos Operadores de incremento
Python - Matrizes e vetores. George Sand
 Python - Matrizes e vetores George Sand Introdução Vamos mostra que podemos executar em Python com o módulo NumPy todos as operações com Matriz: adição Matriz subtração Matriz multiplicação de matrizes
Python - Matrizes e vetores George Sand Introdução Vamos mostra que podemos executar em Python com o módulo NumPy todos as operações com Matriz: adição Matriz subtração Matriz multiplicação de matrizes
RELATÓRIO DO EXEMPLO DO MONTGOMERY (1997, p. 291)
") RELATÓRIO DO EXEMPLO DO MONTGOMERY (1997, p. 291) options nodate ls=80; data fat2p2; input A B @; do rep=1 to 3; input y @; output; end; cards; 15 1 28 25 27 25 1 36 32 32 15 2 18 19 23 25 2 31 30 29 *proc
RELATÓRIO DO EXEMPLO DO MONTGOMERY (1997, p. 291) options nodate ls=80; data fat2p2; input A B @; do rep=1 to 3; input y @; output; end; cards; 15 1 28 25 27 25 1 36 32 32 15 2 18 19 23 25 2 31 30 29 *proc
Jarley Nóbrega
 1 Jarley Nóbrega jpn@cin.ufpe.br Pentaho Data Integration Agenda Manipulação de dados no PDI Controlando o fluxo de dados Transformações no rowset Tratamento de erros e validação de dados Manipulação
1 Jarley Nóbrega jpn@cin.ufpe.br Pentaho Data Integration Agenda Manipulação de dados no PDI Controlando o fluxo de dados Transformações no rowset Tratamento de erros e validação de dados Manipulação
Integração numérica. Prof. Luiz T. F. Eleno. Departamento de Engenharia de Materiais Escola de Engenharia de Lorena Universidade de São Paulo
 Integração numérica Prof. Luiz T. F. Eleno Departamento de Engenharia de Materiais Escola de Engenharia de Lorena Universidade de São Paulo 2018 LOM3260 (EEL-USP, 2018) Integração numérica Prof. Luiz T.
Integração numérica Prof. Luiz T. F. Eleno Departamento de Engenharia de Materiais Escola de Engenharia de Lorena Universidade de São Paulo 2018 LOM3260 (EEL-USP, 2018) Integração numérica Prof. Luiz T.
CAP-387(2016) Tópicos Especiais em
 Tópicos Especiais em") CAP-387(2016) Tópicos Especiais em Computação Aplicada: Construção de Aplicações Massivamente Paralelas Aula 44: MPI IO Celso L. Mendes, Stephan Stephany LAC / INPE Emails: celso.mendes@inpe.br, stephan.stephany@inpe.br
CAP-387(2016) Tópicos Especiais em Computação Aplicada: Construção de Aplicações Massivamente Paralelas Aula 44: MPI IO Celso L. Mendes, Stephan Stephany LAC / INPE Emails: celso.mendes@inpe.br, stephan.stephany@inpe.br
Aula de hoje. Tipos de Dados e Variáveis. Constantes literais. Dados. Variáveis. Tipagem dinâmica. SCC Introdução à Programação para Engenharias
 SCC 12 - Introdução à Programação para Engenharias Tipos de Dados e Variáveis Professor: André C. P. L. F. de Carvalho, ICMC-USP Pos-doutorando: Isvani Frias-Blanco Monitor: Henrique Bonini de Britto Menezes
SCC 12 - Introdução à Programação para Engenharias Tipos de Dados e Variáveis Professor: André C. P. L. F. de Carvalho, ICMC-USP Pos-doutorando: Isvani Frias-Blanco Monitor: Henrique Bonini de Britto Menezes
Universidade de Coimbra - Faculdade de Ciências e Tecnologia Departamento de Matemática
 Universidade de Coimbra - Faculdade de Ciências e Tecnologia Departamento de Matemática COMPUTAÇÃO PARALELA - 2005/2006 4ºANO PROBLEMA 1 DETERMINAÇÃO DOS NÚMEROS PRIMOS *** RELATÓRIO *** Sara Catarina
Universidade de Coimbra - Faculdade de Ciências e Tecnologia Departamento de Matemática COMPUTAÇÃO PARALELA - 2005/2006 4ºANO PROBLEMA 1 DETERMINAÇÃO DOS NÚMEROS PRIMOS *** RELATÓRIO *** Sara Catarina
PRIMEIROS PASSOS COM PYTHON. Prof. Msc. Luis Filipe Alves Pereira 2015
 PRIMEIROS PASSOS COM PYTHON Prof. Msc. Luis Filipe Alves Pereira 2015 PRIMEIROS PASSOS COM PYTHON 02/47 O QUE É PYTHON? Python é uma linguagem de propósito geral, de alto nível e interpretada Python será
PRIMEIROS PASSOS COM PYTHON Prof. Msc. Luis Filipe Alves Pereira 2015 PRIMEIROS PASSOS COM PYTHON 02/47 O QUE É PYTHON? Python é uma linguagem de propósito geral, de alto nível e interpretada Python será
Escola Secundária de Albufeira. Comandos MySQL. (Páginas Web Dinâmicas: PHP e MySQL) Carlos Nunes
 Carlos Nunes") Escola Secundária de Albufeira Comandos MySQL (Páginas Web Dinâmicas: PHP e MySQL) (csmnunes@gmail.com) 2009/2010 Criar Base de Dados CREATE DATABASE basededados; Apagar Base de Dados DROP DATABASE basededados;
Escola Secundária de Albufeira Comandos MySQL (Páginas Web Dinâmicas: PHP e MySQL) (csmnunes@gmail.com) 2009/2010 Criar Base de Dados CREATE DATABASE basededados; Apagar Base de Dados DROP DATABASE basededados;
Comunicação orientada a mensagens
 Comunicação orientada a mensagens críticas a RPC sincronismo modelo um a um dificuldades de tratamento de falhas dificuldades com arquiteturas não clienteservidor volta ao modelo de troca de mensagens
Comunicação orientada a mensagens críticas a RPC sincronismo modelo um a um dificuldades de tratamento de falhas dificuldades com arquiteturas não clienteservidor volta ao modelo de troca de mensagens
Estruturas de controle no nível de sentença
 Estruturas de controle no nível de sentença Linguagens de Programação Marco A L Barbosa cba Este trabalho está licenciado com uma Licença Creative Commons - Atribuição-CompartilhaIgual 4.0 Internacional.
Estruturas de controle no nível de sentença Linguagens de Programação Marco A L Barbosa cba Este trabalho está licenciado com uma Licença Creative Commons - Atribuição-CompartilhaIgual 4.0 Internacional.
Relatório Trabalho 1 Programação Paralela
 Relatório Trabalho 1 Programação Paralela Gustavo Rissetti 1 Rodrigo Exterckötter Tjäder 1 1 Acadêmicos do Curso de Ciência da Computação Universidade Federal de Santa Maria (UFSM) {rissetti,tjader@inf.ufsm.br
Relatório Trabalho 1 Programação Paralela Gustavo Rissetti 1 Rodrigo Exterckötter Tjäder 1 1 Acadêmicos do Curso de Ciência da Computação Universidade Federal de Santa Maria (UFSM) {rissetti,tjader@inf.ufsm.br
Aula 01 Algoritmos e lógica de programação e introdução ao C++
 Aula 01 Algoritmos e lógica de programação e introdução ao C++ Autor: José Martins de Castro Neto Carga Horária: 2h 21 de julho de 2015 1 Algoritmo e lógica de programação Ementa do curso 1. Definições
Aula 01 Algoritmos e lógica de programação e introdução ao C++ Autor: José Martins de Castro Neto Carga Horária: 2h 21 de julho de 2015 1 Algoritmo e lógica de programação Ementa do curso 1. Definições
Programação Paralela Avançada. N. Maillard - M. Cera
 Programação Paralela Avançada N. Maillard - M. Cera Programação Paralela Avançada Introdução Geral 2 Programação Paralela é crítica 3 Programação Paralela é difícil Em nível conceitual + em nível técnico.
Programação Paralela Avançada N. Maillard - M. Cera Programação Paralela Avançada Introdução Geral 2 Programação Paralela é crítica 3 Programação Paralela é difícil Em nível conceitual + em nível técnico.
Trabalho 01: Cliente e Servidor Python
 Trabalho 01: Cliente e Servidor Python Redes de Computadores 1 Descrição Este trabalho deve ser entregue no Moodle até a data correspondente de entrega. Envie sua resposta somente em texto a não ser que
Trabalho 01: Cliente e Servidor Python Redes de Computadores 1 Descrição Este trabalho deve ser entregue no Moodle até a data correspondente de entrega. Envie sua resposta somente em texto a não ser que
LI KUAN CHING ANÁLISE E PREDIÇÃO DE DESEMPENHO DE PROGRAMAS PARALELOS EM REDES DE ESTAÇÕES DE TRABALHO. Escola Politécnica da USP
 Escola Politécnica da USP Departamento de Engenharia da Computação e Sistemas Digitais LI KUAN CHING ANÁLISE E PREDIÇÃO DE DESEMPENHO DE PROGRAMAS PARALELOS EM REDES DE ESTAÇÕES DE TRABALHO Tese Apresentada
Escola Politécnica da USP Departamento de Engenharia da Computação e Sistemas Digitais LI KUAN CHING ANÁLISE E PREDIÇÃO DE DESEMPENHO DE PROGRAMAS PARALELOS EM REDES DE ESTAÇÕES DE TRABALHO Tese Apresentada
Aula de hoje. Expressões. Expressões. Expressões. Exemplos. Programa em Python. SCC Introdução à Programação para Engenharias
 SCC 124 - Introdução à Programação para Engenharias Expressões Professor: André C. P. L. F. de Carvalho, ICMC-USP Pos-doutorando: Isvani Frias-Blanco Monitor: Henrique Bonini de Britto Menezes Aula de
SCC 124 - Introdução à Programação para Engenharias Expressões Professor: André C. P. L. F. de Carvalho, ICMC-USP Pos-doutorando: Isvani Frias-Blanco Monitor: Henrique Bonini de Britto Menezes Aula de
Capítulo II Modelos de Programação Distribuída
 Capítulo II Modelos de Programação Distribuída Exemplos de linguagens com comunicação por mensagens, Ada OCCAM Linda From: M. Ben-Ari Principles of Concurrent and Distributed Programming Prentice Hall
Capítulo II Modelos de Programação Distribuída Exemplos de linguagens com comunicação por mensagens, Ada OCCAM Linda From: M. Ben-Ari Principles of Concurrent and Distributed Programming Prentice Hall
Representação de Dados
 Representação de Dados Representação binária Exemplo: 15213 10 11101101101101 2 Vantagens: Implementação eletrônica Possibilidade de armazenar elementos com dois estados Transmissão eletrônica confiável
Representação de Dados Representação binária Exemplo: 15213 10 11101101101101 2 Vantagens: Implementação eletrônica Possibilidade de armazenar elementos com dois estados Transmissão eletrônica confiável
Programação de Computadores:
 Instituto de C Programação de Computadores: Introdução ao FORTRAN Luis Martí Instituto de Computação Universidade Federal Fluminense lmarti@ic.uff.br - http://lmarti.com Introdução ao FORTRAN Cinco aspectos
Instituto de C Programação de Computadores: Introdução ao FORTRAN Luis Martí Instituto de Computação Universidade Federal Fluminense lmarti@ic.uff.br - http://lmarti.com Introdução ao FORTRAN Cinco aspectos
Expressões e Instruções de Atribuição. George Darmiton da Cunha Cavalcanti
 Expressões e Instruções de Atribuição George Darmiton da Cunha Cavalcanti (gdcc@cin.ufpe.br) Tópicos Introdução Expressões Aritméticas Operadores Sobrecarregados Conversões de Tipo Expressões Relacionais
Expressões e Instruções de Atribuição George Darmiton da Cunha Cavalcanti (gdcc@cin.ufpe.br) Tópicos Introdução Expressões Aritméticas Operadores Sobrecarregados Conversões de Tipo Expressões Relacionais
Revisões de PG. Programação Orientada por Objetos (POO) Centro de Cálculo Instituto Superior de Engenharia de Lisboa
 Centro de Cálculo Instituto Superior de Engenharia de Lisboa") Revisões de PG (POO) Centro de Cálculo Instituto Superior de Engenharia de Lisboa Pedro Alexandre Pereira (palex@cc.isel.ipl.pt) Compilar e executar programas em Java Ficheiro fonte (Prog.java) Ficheiro
Revisões de PG (POO) Centro de Cálculo Instituto Superior de Engenharia de Lisboa Pedro Alexandre Pereira (palex@cc.isel.ipl.pt) Compilar e executar programas em Java Ficheiro fonte (Prog.java) Ficheiro
Linguagens para Programação Paralela. October 26, 2010
 October 26, 2010 Linguagens X Bibliotecas expressividade facilidade de uso integração com programas e programadores Modelos de Linguagens Paralelas (lista não completa) paralelismo de dados (data-parallel)
October 26, 2010 Linguagens X Bibliotecas expressividade facilidade de uso integração com programas e programadores Modelos de Linguagens Paralelas (lista não completa) paralelismo de dados (data-parallel)
SISTEMAS DISTRIBUÍDOS
 SISTEMAS DISTRIBUÍDOS Capítulo 3 - Comunicação em Sistemas Distribuídos Comunicação Direta Material de suporte às aulas de Sistemas Distribuídos de Nuno Preguiça Copyright DI FCT/ UNL / 1 NOTA PRÉVIA A
SISTEMAS DISTRIBUÍDOS Capítulo 3 - Comunicação em Sistemas Distribuídos Comunicação Direta Material de suporte às aulas de Sistemas Distribuídos de Nuno Preguiça Copyright DI FCT/ UNL / 1 NOTA PRÉVIA A
Diagramas Sintáticos
 Diagramas Sintáticos Centro de Cálculo Instituto Superior de Engenharia de Lisboa Pedro Alexandre Pereira (palex@cc.isel.ipl.pt) Classe pública com método main Cada classe X pública é declarada num ficheiro
Diagramas Sintáticos Centro de Cálculo Instituto Superior de Engenharia de Lisboa Pedro Alexandre Pereira (palex@cc.isel.ipl.pt) Classe pública com método main Cada classe X pública é declarada num ficheiro
Fabrizio Borelli Gabriel Nobrega Henrique Dorotea Maitê Balhester
 Fabrizio Borelli Gabriel Nobrega Henrique Dorotea Maitê Balhester Sistemas Centralizados Pode possuir N processadores (sistema multiprogramados) Todos os processadores compartilham: Memória Clock Barramento
Fabrizio Borelli Gabriel Nobrega Henrique Dorotea Maitê Balhester Sistemas Centralizados Pode possuir N processadores (sistema multiprogramados) Todos os processadores compartilham: Memória Clock Barramento
Estruturas de controle no nível de sentença
 Estruturas de controle no nível de sentença Marco A L Barbosa malbarbo.pro.br Departamento de Informática Universidade Estadual de Maringá cba Este trabalho está licenciado com uma Licença Creative Commons
Estruturas de controle no nível de sentença Marco A L Barbosa malbarbo.pro.br Departamento de Informática Universidade Estadual de Maringá cba Este trabalho está licenciado com uma Licença Creative Commons
TE091 Programação Orientada a Objetos Engenharia Elétrica
 TE091 Programação Orientada a Objetos Engenharia Elétrica Revisão Rápida de Programação em C Prof. Carlos Marcelo Pedroso 2015 Revisão Linguagem C Características principais Modularidade: uso de procedimentos
TE091 Programação Orientada a Objetos Engenharia Elétrica Revisão Rápida de Programação em C Prof. Carlos Marcelo Pedroso 2015 Revisão Linguagem C Características principais Modularidade: uso de procedimentos
Módulo 4 Introdução ao VHDL
 1 Módulo 4 Introdução ao VHDL Conceitos básicos do VHDL Modelação, Simulação e Síntese de Sistemas Digitais entity declara o interface de um componente; architecture descreve a realização de um componente;
1 Módulo 4 Introdução ao VHDL Conceitos básicos do VHDL Modelação, Simulação e Síntese de Sistemas Digitais entity declara o interface de um componente; architecture descreve a realização de um componente;
Exemplo de Arquitetura: Cliente/Servidor com Mestre e Escravos. Interface em IDL. Dynamic Invocation Interface. Exemplo invocação DII em Java
 Exemplo de Arquitetura: Cliente/Servidor com Mestre e s Arquitetura Mestre- Speed-up / Cliente Mestre Prof João Paulo A Almeida (jpalmeida@infufesbr) Cliente 2009/01 - INF02799 Com alguns slides de Parallel
Exemplo de Arquitetura: Cliente/Servidor com Mestre e s Arquitetura Mestre- Speed-up / Cliente Mestre Prof João Paulo A Almeida (jpalmeida@infufesbr) Cliente 2009/01 - INF02799 Com alguns slides de Parallel