Hands-on CUDA. Prof. Esteban Walter Gonzalez Clua, Dr. Cuda Fellow Computer Science Department Universidade Federal Fluminense Brazil
|
|
|
- Brian Filipe Sá
- 6 Há anos
- Visualizações:
Transcrição


1 Hands-on CUDA Prof. Esteban Walter Gonzalez Clua, Dr. Cuda Fellow Computer Science Department Universidade Federal Fluminense Brazil
2 How to use the GPU 1) Libraries (ex. Physics) : ready to use 2) Compiler DirecKves (ex. OpenACC) 3) Programming Language (CUDA, OpenCL)
3 Work Proposal: OpenACC


4 Libraries - Don t require any GPU knowledge or even parallel compukng experience

5 Compiler directives Don t requires GPU knowledge, but a litle bit of parallel programming
6 Programming Language More Efficient Flexible: may be beter opkmized for specific plaxorms Verbose: express more details

7 Latency devices (CPU)x Throughput devices (GPU) CPU is much more faster when latency maters GPU is much more faster when througput maters

8 3 coisas que voce deve saber de cor!

")
9 #1 Estamos falando de computação heterogênea Host CPU e sua memória (host memory) Device GPU e sua memória (Global memory) Host Device

![x + RADIUS; // Read input elements into shared memory temp[lindex] = in[gindex]; if (threadidx.](/docs-images/80/80728984/images/10-3.jpg "x < RADIUS) { temp[lindex - RADIUS] = in[gindex - RADIUS]; temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE]; } // Synchronize (ensure all the data is available) syncthreads(); // Apply the stencil")
10 Heterogeneous Computing #include <iostream> #include <algorithm> using namespace std; #define N 1024 #define RADIUS 3 #define BLOCK_SIZE 16 global void stencil_1d(int *in, int *out) { shared int temp[block_size + 2 * RADIUS]; int gindex = threadidx.x + blockidx.x * blockdim.x; int lindex = threadidx.x + RADIUS; // Read input elements into shared memory temp[lindex] = in[gindex]; if (threadidx.x < RADIUS) { temp[lindex - RADIUS] = in[gindex - RADIUS]; temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE]; } // Synchronize (ensure all the data is available) syncthreads(); // Apply the stencil int result = 0; for (int offset = -RADIUS ; offset <= RADIUS ; offset++) result += temp[lindex + offset]; } parallel fn // Store the result out[gindex] = result; void fill_ints(int *x, int n) { fill_n(x, n, 1); } int main(void) { int *in, *out; // host copies of a, b, c int *d_in, *d_out; // device copies of a, b, c int size = (N + 2*RADIUS) * sizeof(int); // Alloc space for host copies and setup values in = (int *)malloc(size); fill_ints(in, N + 2*RADIUS); out = (int *)malloc(size); fill_ints(out, N + 2*RADIUS); // Alloc space for device copies cudamalloc((void **)&d_in, size); cudamalloc((void **)&d_out, size); // Copy to device cudamemcpy(d_in, in, size, cudamemcpyhosttodevice); cudamemcpy(d_out, out, size, cudamemcpyhosttodevice); serial code // Launch stencil_1d() kernel on GPU stencil_1d<<<n/block_size,block_size>>>(d_in + RADIUS, d_out + RADIUS); // Copy result back to host cudamemcpy(out, d_out, size, cudamemcpydevicetohost); } // Cleanup free(in); free(out); cudafree(d_in); cudafree(d_out); return 0; This slide is credited to Mark Harris (nvidia) parallel code serial code
11 #2 Tráfego de memória importa muito!...
12 GPU Computing Flow PCI Bus 1. Copy input data from CPU memory to GPU memory This slide is credited to Mark Harris (nvidia)
13 GPU Computing Flow PCI Bus 1. Copy input data from CPU memory to GPU memory 2. Load GPU program and execute, caching data on chip for performance This slide is credited to Mark Harris (nvidia)
14 GPU Computing Flow PCI Bus 1. Copy input data from CPU memory to GPU memory 2. Load GPU program and execute, caching data on chip for performance 3. Copy results from GPU memory to CPU memory This slide is credited to Mark Harris (nvidia)
 1.")


15 GPU Computing Flow PCI Bus 11TFlops 320GB/s (80 Gfloats/s) 1. Copy input data from CPU memory to GPU memory 2. Load GPU program and execute, caching data on chip for performance 3. Copy results from GPU memory to CPU memory

16 GPU Computing Flow PCI Bus 7TFlops 224GB/s (56 Gfloats/s) 1. Copy input data from CPU memory to GPU memory 2. Load GPU program and execute, caching data on chip for performance 3. Copy results from GPU memory to CPU memory
17 #3 1 kernels, muitos threads...
18 Threads em GPU x CPU F1 F2 F3 F4
19 Threads em GPU x CPU F1 F2 F3 F4 Kernel

20 Modelo SIMT
21 GPU x CPU F1 F2 F3 F4 Intel i7 Bloomfield Only ~1% of CPU is dedicated to computakon, 99% to moving/storing data to combat latency.



22 GPU x CPU F1 F2 F3 Kernel F4 Kepler K10 Intel i7 Bloomfield Only ~1% of CPU is dedicated to computakon, 99% to moving/storing data to combat latency.
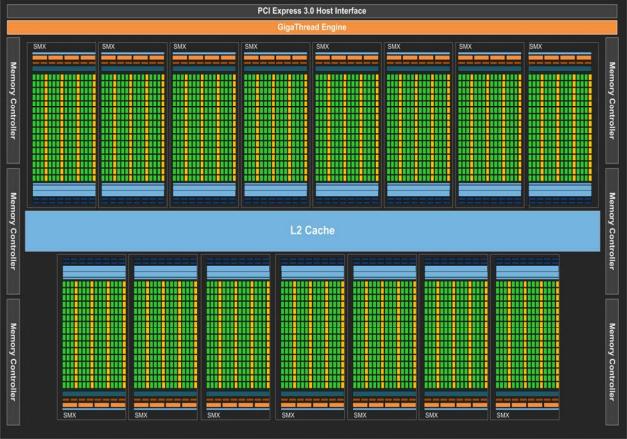
23 GRID
24 Principais conceitos de CUDA Device: a GPU Host: a CPU Kernel Programa que vai para a GPU Thread Instancias do kernel Global Memory: memória principal da GPU Main memory: memória principal da CPU CUDA, PTX and Cubin

25 Threads, Blocks e Grids Um kernel é executado numa GRID Cada bloco é composto por threads (1024) Todas as threads de um bloco podem usar a mesma shared memory Threads de blocos diferentes não podem comparklhar a mesma shared memory, mas podem comparklhar dados pela memória global
26 Kernel, Threads e Warps

27 Memórias... - Hierarquia de memória - Local - Cache L1 and L2 - shared - Constant - Texture - Global
; printf(\"hello World!\n\"); return 0; CPU")
28 Hello World global void mykernel(void){ } GPU int main(void) { } mykernel<<<1,1>>>(); printf("hello World!\n"); return 0; CPU
29 Hello World global void add(int *a, int *b, int *c) { } *c = *a + *b;
30 Alimentando a GPU com dados... Malloc() ~ cudamalloc() Free() ~ cudafree() cudamemcpy() memcpy()
31 Alimentando a GPU com dados... int main(void) { int a, b, c; int *d_a, *d_b, *d_c; int size = sizeof(int); // CPU // GPU // Allocate space for device cudamalloc((void **)&d_a, size); cudamalloc((void **)&d_b, size); cudamalloc((void **)&d_c, size); // Setup input values a = 10; b = 20;
32 Alimentando a GPU com dados... // CPU -> GPU cudamemcpy(d_a, &a, size, cudamemcpyhosttodevice); cudamemcpy(d_b, &b, size, cudamemcpyhosttodevice); // kernel execution: 1 thread add<<<1,1>>>(d_a, d_b, d_c); // GPU -> CPU cudamemcpy(&c, d_c, size, cudamemcpydevicetohost); // Clean memory cudafree(d_a); cudafree(d_b); cudafree(d_c);
33 Memoria unificada cudamallocmanaged() à igual a cudamalloc(), porém permite unificar as duas memórias de forma conceitual. cudamallocmanaged ((void **)&a, size); cudamallocmanaged ((void **)&b, size); cudamallocmanaged ((void **)&c, size); // kernel execution: 1 thread add<<<1,1>>>(a, b, c); // Syncrhonize cudadevicesynchronize(); // Clean memory cudafree(a); cudafree(b); cudafree(c);
34 Memoria unificada managed Global Variable device managed int a[1000]; device managed int b[1000]; device managed int c[1000]; // kernel execution: 1 thread add<<<10,100>>>(); // Syncrhonize cudadevicesynchronize();
35 Para compilar os programas
36 Acesso Remoto a máquinas com Suporte CUDA Instruções para uso das máquinas remotas para programação em CUDA.
37 Instruções Importantes. Você irá uklizar a máquina remota somente para compilar e executar o programa. Existe um diretório chamado Alunos na raiz do usuário, onde cada um deve criar uma pasta para si. Criar um diretório com o seu nome e renomeálo. A criação dessas pastas individuais será necessária pois existem várias pessoas da mesma turma uklizando a mesma conta.
38 Instruções Importantes Para compilar o projeto, digite o comando make Para limpar os códigos de máquina gerados digite o comando make clean. Manual CUDA está disponível neste linkhtp://docs.nvidia.com/cuda/cuda-cprogramming-guide/
39 Usuário e senha u: cudateaching p: teachingcuda2018 Esta conta é uma conta temporária, e será suspensa ao final do curso.
40 Divisão de Acceso da máquina Devem se conectar à máquina: Porta: 22 Para uklizar uma determinada GPU é preciso escrever na frente do comando de execução a variável de ambiente seguinte: CUDA_VISIBLE_DEVICES=1 No caso anterior o 1 é o índice da GPU 1, sendo que a DGX tem 8 GPUs, portanto: Grupo 01 devem rodar os seus testes na GPU 1 Grupo 02 devem rodar os seus testes na GPU 2 Grupo 03 devem rodar os seus testes na GPU 3
41 Orientações Importantes Devido a esta conta ser uma conta comparklhada, você deve criar uma pasta sua ou para sua equipe dentro da pasta Alunos, para que assim os arquivos de cada um fiquem organizados. A pasta NVIDIA_CUDA-9.0_Samples que está na raiz da máquina, é a pasta da NVIDIA contendo todos os exemplos de desenvolvimento do SDK. Você não deve modificar esta pasta! Sempre que quiser uklizar algum código desta pasta, faça uma cópia para sua pasta que você criou.
42 Rodando um Hello World em CUDA 01 Baixe PARA SUA PASTA o seguinte programa através do link htps:// ull/ vectoraddsample.zip Esse código nada mais é que o exemplo padrão da NVIDIA de soma de dois vetores em paralelo.
43 Rodando um Hello World em CUDA 02 Voce pode baixar este so}ware através do comando "wget htps:// ull/ vectoraddsample.zip" Depois deve descompactar o arquivo com o comando "unzip vectoraddsample.zip"
44 Rodando um Hello World em CUDA 03 Para compilar o projeto basta digitar make e pressionar enter. Para executar lembre-se sempre de adicionar a variável de ambiente para selecionar a GPU do seu grupo (por exemplo para os alunos do Grupo 2): CUDA_VISIBLE_DEVICES=2./vectorAdd Para limpar o projeto basta digitar make clean e pressionar enter.
45 Rodando um Hello World em CUDA 04 Fique à vontade para modificar a cópia do projeto da maneira que lhe for mais conveniente. AlternaKvamente este mesmo so}ware que soma dois vetores, também está disponível na pasta NVIDIA_CUDA-9.0_Samples na subpasta 0_Simple, na pasta vectoradd. Você pode copiar esta pasta com o código fonte para a pasta pessoal sua que você criou.
46 Programas sugeridos para acessar a máquina remota a parkr de Windows MOBAXTERM - htp://mobaxterm.mobatek.net/ Através desse so}ware voce se conecta a maquina desejada, e ele dispoe de todas as ferramentas necesarias, desde transferencia de arquivo através de interface, até terminal e editor de texto.

47 winscp- Troca de Arquivos- htp:// winscp.net/

48 PuBy - Terminal de acesso remoto SSH Client - para Windows
49 Terminal (MAC) ssh
50 Compiling a GPU program Name file as.cu Nvcc name.cu./a.out Voilá!...

51 Errors types group CUDART TYPES_g3f51e3575c db0a94a430e0038.html

52 NSight Debuggers

53 CUDA GDB Debuggers

54 CUDA Memcheck Debuggers
55 Profiler tools NSIGHT NVPP NVPROF
56 NVIDIA NVProf Nvprof./a.out Make some tests... Changing vector size...
57 Finalmente... O paralelismo global void vecadd(int *d_a, int *d_b, int *d_c) { } int i = threadidx; d_c[i] = d_a[i] + d_b[i] int main() {... vecadd<<<1, N>>>(d_a, d_b, d_c); }
58 Pequeno concerto.. global void add(int *d_a, int *d_b, int *d_c) { } int i = threadidx.x; d_c[i] = d_a[i] + d_b[i] int main() {... vecadd<<<1, N>>>(d_a, d_b, d_c); } // blockdim.x = N
59 Explorando o paralelismo: Threads global void add(int *d_a, int *d_b, int *d_c) { } int i = threadidx.x; d_c[i] = d_a[i] + d_b[i] At the same time... c[0] = a[0] + b[0]; c[1] = a[1] + b[1]; c[2] = a[2] + b[2]; C[N-1] = a[n-1] + b[n-1];

60 Há um limite de threads... Por bloco...
61 If N > 1024???
![If N > 1024??? global void add(int *d_a, int *d_b, int *d_c) { } int i = threadidx.x; While (i < N) { } d_c[i] = d_a[i] + d_b [i]; i += blockdim.](/docs-images/80/80728984/images/62-3.jpg "x; c[0] = a[0] + b[0]; C[1024]= a[1024]+ b[1024]; C[2048]= a[2048]+ b[2048]; C[1] = a[1] + b[1]; C[1025]= a[1025]+ b[1025]; C[2049]= a[2049]+")
62 If N > 1024??? global void add(int *d_a, int *d_b, int *d_c) { } int i = threadidx.x; While (i < N) { } d_c[i] = d_a[i] + d_b [i]; i += blockdim.x; c[0] = a[0] + b[0]; C[1024]= a[1024]+ b[1024]; C[2048]= a[2048]+ b[2048]; C[1] = a[1] + b[1]; C[1025]= a[1025]+ b[1025]; C[2049]= a[2049]+ b[2049];
63 Apenas estamos usando 1 SM!...
64 Blocos global void add(int *d_a, int *d_b, int *d_c) { int i= threadidx.x + blockidx.x * blockdim.x; } d_c[i] = d_a[i] + d_b[i]; int main() { vecadd <<<K,M>>>(A, B, C); }
65 Blocos global void add(int *d_a, int *d_b, int *d_c) { int i= threadidx.x + blockidx.x * blockdim.x; } d_c[i] = d_a[i] + d_b[i]; int main() { vecadd <<<K,M>>>(A, B, C); } threadidx.x threadidx.x threadidx.x threadidx.x blockidx.x = 0 blockidx.x = 1 blockidx.x = 2 blockidx.x = 3
66 Perigo: indices não refernciados... global void add(int *d_a, int *d_b, int *d_c) { int i= threadidx.x + blockidx.x * blockdim.x; } if (i < N) d_c[i] = d_a[i] + d_b[i]; int main() { vecadd <<<K,M>>>(A, B, C); } // K*M >= N

67 Threads podem ser indexados em 1, 2 ou 3 dimensões (threadidx.x, threadidx.y, threadidx.z)
68 Threads podem ser indexados em 1, 2 ou 3 dimensões global void MatAdd(int *d_a, int *d_b, int *d_c) { int i= threadidx.x; int j= threadidx.y; } d_c[i][j] = d_a[i][j] + d_b[i][j]; int main() { dim3 threadsperblock (N,M) // N*M < 1024 vecadd <<<1,threadsPerBlock>>>(A, B, C); }
69 Multiplicação de Matrizes
70 Multiplicação de Matrizes (implementação trivial) global void add(int *d_a, int *d_b, int *d_c, int K) { int col= threadidx.x + blockidx.x * blockdim.x; int row= threadidx.y + blockidx.y * blockdim.y; cvalue = 0.0f; for (int k = 0; k < K; k++) cvalue += d_a[col][k] * d_b[k][row]; } d_c[col][row]= cvalue
71 Multiplicação de Matrizes (implementação trivial) global void add(int *d_a, int *d_b, int *d_c, int K) { int i= threadidx.x + blockidx.x * blockdim.x; int j= threadidx.y + blockidx.y * blockdim.y; cvalue = 0; for (int k = 0; k < K; k++) cvalue += d_a[i][k] * d_b[k][j]; } d_c[i][j]= cvalue PORQUE NÃO É UMA BOA SOLUÇÃO???
72 Divergencia de Threads global void add(int *d_a) { int i= threadidx.x + blockidx.x * blockdim.x; } if ((i%2)!= 0) //i is odd d_a[i] *=2; else // i is even d_a[i] /=2;
73 Warps Independent of the Architecture, it consists on 32 threads per warp. Thread mulkple of 32 will opkmize the occupacy rate Coalescence is storng in the same warp Thread Divergence is also strong in the same warp
74 Aviso importante Respect the amount of register size for each Warp
75 Kernels concorrentes
76 Shared Memory - Available for a complete Block. Can only be manipulated by the Device - Kepler support banks of 8 bytes of shared memory. Previous architectures accepted 4.
77 Shared Memory global void copy_vector(float *data) { int index = threadidx.x; shared float temp_data[256]; temp_data[index] = data[index];
78 Shared Memory global void copy_vector(float *data) { int index = threadidx.x; shared float temp_data[256]; temp_data[index] = data[index]; syncthread(); Is this code more efficient than only using the global memory???
79 Analisando a eficiência da Shared Memory global void copy_vector(float *data) { int index = threadidx.x; int i, aux=0; shared float temp_data[256]; temp_data[index] = data[index]; syncthread(); for (i=0; i<25; i++) { aux += temp_data[i]; } data[index] = aux;
80 Aviso importante Respect the amount of shared memory available for each Block
81 Implementando o Parallel Reduce (Shared Memory) global void reduceshared (float *d_in, *d_out) { external shared s_data[]; int index = blockidx.x*blockdim.x + threadidx.x; int tid = threadidx.x; s_data = d_in[index] syncthread(); } for (int stride = blockdim.x/2; stride > 0; stride >>==1) { if (tid < stride){ s_data [index] += s_data[index+s]; } syncthread(); if (tid == 0){ } d_out[blockidx.x] = s_data[0];
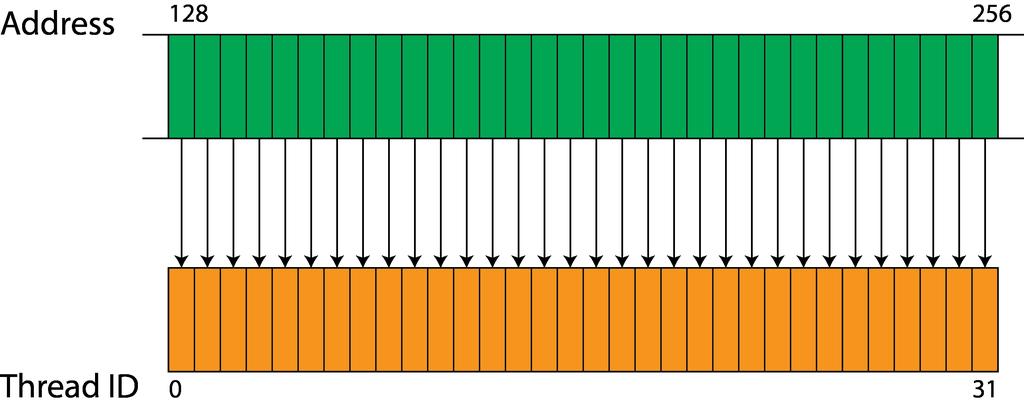
82 Coalescencia
83 Otimizando o código Each SM fetches 128 bytes per memory access. Good opkmizakon is obtained when reading 32 bytes. Reading 64 bits requires one fetch finish for making another.

84 Examplo de Coalescence Array of Structures Data of parkcle #0 begins in posikon 0 of the memory, the atributes of parkcle #2 starts in posikon 96 bytes of memory and so on.
85 Examplo de Coalescencia Structure of Arrays
86 Atomic Operations
87 Exercicio: o que acontece com este código??? #define BLOCKS 1000 #define THREADSPERBLOCK 1000 #define size 10 global void incrementvector (float *data) { int index = blockidx.x*blockdim.x + threadidx.x; data[index] = data[index] + 1; }
88 E agora? #define BLOCKS 1000 #define THREADSPERBLOCK 1000 #define size 10 global void incrementvector (float *data) { int index = blockidx.x*blockdim.x + threadidx.x; index = index % size; data[index] = data[index] + 1; }
89 Exercicio: corrigir usando barreiras #define BLOCKS 1000 #define THREADSPERBLOCK 1000 #define size 10 global void incrementvector (float *data) { int index = blockidx.x*blockdim.x + threadidx.x; index = index % size; data[index] = data[index] + 1; }
90 Atomic Operation #define BLOCKS 1000 #define THREADSPERBLOCK 1000 #define size 10 global void incrementvector (float *data) { int index = blockidx.x*blockdim.x + threadidx.x; index = index % size; atomicadd(&data[index], 1); }
91 Lista de Atomic Operation int atomicadd(int* address, int val); int atomicsub(int* address, int val); int atomicexch(int* address, int val); int atomicmin(int* address, int val); int atomicmax(int* address, int val); unsigned int atomicinc(unsigned int* address, unsigned int val); // old >= val? 0 : (old+1) unsigned int atomicdec(unsigned int* address, unsigned int val); int atomicand(int* address, int val); // Or and Xor also available Works fine for int. Only add and exchange work for float and double
92 Limitações de Atomic Operation 1. only a set of operakons are supported 2. Restricted to data types 3. Random order in operakon 4. Serialize access to the memory (there is no magic!) Great improvements on latest archictectures
93 Streams Task Parallelism: two or more completely different tasks in parallel
94 Streams cudahostalloc: malloc memory in the Host Differs from tradikonal malloc() since it guarantees that the memory will be pagelocked, i.e., it will never be paged to memory out to disk (assures that data will allways be resident at physical memory) Constraint: doing so the memory may run out much faster that when using malloc
95 Streams Knowing the physical adress buffer allows the GPU to use the DMA (Direct Memory Access), which proceeds without the intervenkon of the CPU
96 Streams int *a, *dev_a; a = (int*)malloc(size*sizeof(*a)); cudamalloc ( (void**)&dev_a, size * sizeof (*dev_a))); cudamemcpy (dev_a, a, size * sizeof(*dev_a), cudamemcpyhosttodevice));
97 Streams int *a, *dev_a; cudahostalloc ( (void**)&a, size * sizeof (*a), cudahostallocdefault )); cudamalloc ( (void**)&dev_a, size * sizeof (*dev_a))); cudamemcpy (dev_a, a, size * sizeof(*dev_a), cudamemcpyhosttodevice)); cudafreehost ( a ); cudafree (dev_a);
98 Streams GPU allow to create specific order of operakons using streams. In some situakons it allows to create parallel tasks.
99 Streams int *a, *dev_a; cudastream_t stream; cudastreamcreate(&stream); cudamalloc ( (void**)&dev_a, size * sizeof (*dev_a))); cudahostalloc ( (void**)&a, size * sizeof (*a), cudahostallocdefault )); cudamemcpyasync (dev_a, a, size * sizeof(*dev_a), cudamemcpyhosttodevice, stream)); // A stream operation is Asynchronous. Each stram opeartion only starts // after the previous stream operation have finished Kernel <<<GridDim, BlockDim, stream>>> (dev_a); cudamemcpyasync (dev_a, a, size * sizeof(*dev_a), cudamemcpyhosttodevice, stream)); cudastreamdestroy (stream);
100 Streams int *a, *dev_a; cudastream_t stream; cudastreamcreate(&stream); cudamalloc ( (void**)&dev_a, size * sizeof (*dev_a))); cudahostalloc ( (void**)&a, size * sizeof (*a), cudahostallocdefault )); cudamemcpyasync (dev_a, a, size * sizeof(*dev_a), cudamemcpyhosttodevice, stream)); // Async copy only works with page locked memory // A stream operation is Asynchronous. Each stram opeartion only starts // after the previous stream operation have finished Kernel <<<GridDim, BlockDim, stream>>> (dev_a); cudamemcpyasync (dev_a, a, size * sizeof(*dev_a), cudamemcpyhosttodevice, stream)); cudastreamdestroy (stream);
101 Streams int *a, *dev_a; cudastream_t stream; cudastreamcreate(&stream); cudamalloc ( (void**)&dev_a, size * sizeof (*dev_a))); cudahostalloc ( (void**)&a, size * sizeof (*a), cudahostallocdefault )); cudamemcpyasync (dev_a, a, size * sizeof(*dev_a), cudamemcpyhosttodevice, stream)); // A stream operation is Asynchronous. Each stram opeartion only starts // after the previous stream operation have finished Kernel <<<GridDim, BlockDim, stream>>> (dev_a); cudamemcpyasync (dev_a, a, size * sizeof(*dev_a), cudamemcpyhosttodevice, stream)); cudastreamdestroy (stream);

102 Optimizing code with Asynchronous operations
103 Stream overlaps #define N (1024 * 1024) #define TOTAL_SIZE (N*20) Int *h_a, *h_b, *h_c; Int *d_a0, *d_b0, *d_c0; Int *d_a1, *d_b1, *d_c1; cudastream_t stream0, stream1; cudastreamcreate(&stream0); cudastreamcreate(&stream1); cudamalloc cudamalloc cudamalloc cudamalloc cudamalloc cudamalloc ( (void**)&d_a0, N*sizeof (int))); ( (void**)&d_b0, N*sizeof (int))); ( (void**)&d_c0, N*sizeof (int))); ( (void**)&d_a1, N*sizeof (int))); ( (void**)&d_b1, N*sizeof (int))); ( (void**)&d_c1, N*sizeof (int)));
104 Stream overlaps cudahostalloc ( (void**)&h_a, TOTAL_SIZE*sizeof (int), cudahostallocdefault )); cudahostalloc ( (void**)&h_b, TOTAL_SIZE*sizeof (int), cudahostallocdefault )); cudahostalloc ( (void**)&h_c, TOTAL_SIZE*sizeof (int), cudahostallocdefault )); For (int i=0; i<total_size; i++){ h_a[i] = rand(); h_b[i] = rand(); }
105 Stream overlaps For (int i=o; i < TOTAL_SIZE ; i+=n*2) { cudamemcpyasync (dev_a0, h_a+i, N* sizeof(int), cudamemcpyhosttodevice, stream0)); cudamemcpyasync (dev_b0, h_b+i, N* sizeof(int), cudamemcpyhosttodevice, stream0)); kernel<<<n/256, 256, 0, stream0>>> (d_a0, d_b0, d_c0); cudamemcpyasync (h_c+i, dc_0, N* sizeof(int), cudamemcpydevicetohost, stream0)); cudamemcpyasync (dev_a1, h_a+i+n, N* sizeof(int), cudamemcpyhosttodevice, stream1)); cudamemcpyasync (dev_b1, h_b+i+n, N* sizeof(int), cudamemcpyhosttodevice, stream1)); kernel<<<n/256, 256, 0, stream0>>> (d_a1, d_b1, d_c1); } cudamemcpyasync (h_c+i+n, dc_1, N* sizeof(int), cudamemcpydevicetohost, stream1));
106 Stream overlaps cudamemcpyasync (dev_a1, h_a+i+n, N* sizeof(int), cudamemcpyhosttodevice, stream1)); cudamemcpyasync (dev_b1, h_b+i+n, N* sizeof(int), cudamemcpyhosttodevice, stream1)); kernel<<<n/256, 256, 0, stream0>>> (d_a1, d_b1, d_c1); } cudamemcpyasync (h_c+i+n, dc_1, N* sizeof(int), cudamemcpydevicetohost, stream1)); cudastreamsynchronize (stream0); cudastreamsynchronize (stream1); // frees and destroys
107 Stream overlaps cudamemcpyasync (dev_a1, h_a+i+n, N* sizeof(int), cudamemcpyhosttodevice, stream1)); cudamemcpyasync (dev_b1, h_b+i+n, N* sizeof(int), cudamemcpyhosttodevice, stream1)); kernel<<<n/256, 256, 0, stream0>>> (d_a1, d_b1, d_c1); } cudamemcpyasync (h_c+i+n, dc_1, N* sizeof(int), cudamemcpydevicetohost, stream1)); cudastreamsynchronize (stream0); cudastreamsynchronize (stream1); // frees and destroys Esta versão ainda não traz okmizações: Sobrecarga do engine de memória e kernel
108 Improving Stream For (int i=o; i < TOTAL_SIZE ; i+=n*2) { cudamemcpyasync (dev_a0, h_a+i, N* sizeof(int), cudamemcpyhosttodevice, stream0)); cudamemcpyasync (dev_b0, h_b+i, N* sizeof(int), cudamemcpyhosttodevice, stream0)); cudamemcpyasync (dev_a1, h_a+i+n, N* sizeof(int), cudamemcpyhosttodevice, stream1)); cudamemcpyasync (dev_b1, h_b+i+n, N* sizeof(int), cudamemcpyhosttodevice, stream1)); kernel<<<n/256, 256, 0, stream0>>> (d_a0, d_b0, d_c0); kernel<<<n/256, 256, 0, stream0>>> (d_a1, d_b1, d_c1); } cudamemcpyasync (h_c+i, dc_0, N* sizeof(int), cudamemcpydevicetohost, stream0)); cudamemcpyasync (h_c+i+n, dc_1, N* sizeof(int), cudamemcpydevicetohost, stream1));
109 Optimizing with compiler directives
110 Directives nvcc -arch=compute_20 -code=sm_20,sm_32, sm_35, sm_50,sm_52,sm_53 foo.cu -o foo nvcc -arch=compute_35 -code=sm_35 foo.cu -o foo nvcc -use_fast_math foo.cu -o foo
111 Last advices Find ways to parallelize sequenkal code, Minimize data transfers between the host and the device, Adjust kernel launch configurakon to maximize device uklizakon, Ensure global memory accesses are coalesced, Minimize redundant accesses to global memory whenever possible, Avoid different execukon paths within the same warp. Read more at: htp://docs.nvidia.com/cuda/kepler-tuning-guide/ index.html#ixzz3jgmjoxlj
112 NVLink
113 Mixed Precision Deep learning have found that deep neural network architectures have a natural resilience to errors due to the backpropagakon algorithm used in training them, and some developers have argued that 16-bit floakng point (half precision, or FP16) is sufficient for training neural networks. P100: 21.2 Tflops for Half precision half a, b
114
115 Curso completo de Programação em GPUs: (legendado para Português) htp://www2.ic.uff.br/~gpu/kit-de-ensino-gpgpu/ htp://www2.ic.uff.br/~gpu/learn-gpu-compukng/deep-learning/
116
Tópicos em Física Computacional: Introdução a Linguagem CUDA
 Tópicos em Física Computacional: Introdução a Linguagem CUDA Aula 06: Introdução a Linguagem CUDA Otimização do Código Carine P. Beatrici IF UFRGS 1 Da Aula Passada... Programa que soma matrizes linearizadas;
Tópicos em Física Computacional: Introdução a Linguagem CUDA Aula 06: Introdução a Linguagem CUDA Otimização do Código Carine P. Beatrici IF UFRGS 1 Da Aula Passada... Programa que soma matrizes linearizadas;
Programação em Paralelo. N. Cardoso & P. Bicudo. Física Computacional - MEFT 2010/2011
 Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 11 CUDA Parte 2 N. Cardoso & P. Bicudo Programação em
Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 11 CUDA Parte 2 N. Cardoso & P. Bicudo Programação em
Programação em Paralelo. N. Cardoso & P. Bicudo. Física Computacional - MEFT 2010/2011
 Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 12 CUDA Parte 3 N. Cardoso & P. Bicudo Programação em
Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2010/2011 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 12 CUDA Parte 3 N. Cardoso & P. Bicudo Programação em
Aula 10 - Streams (Parte I)
") Disciplina de TICs 1 - Introdução a Programação em GPGPU Aula 10 - Streams (Parte I) Introdução Até então foi visto como engenho de processamento paralelo massivo de dados nas GPUs pode aumentar assombrosamente
Disciplina de TICs 1 - Introdução a Programação em GPGPU Aula 10 - Streams (Parte I) Introdução Até então foi visto como engenho de processamento paralelo massivo de dados nas GPUs pode aumentar assombrosamente
Eng. Thársis T. P. Souza
 Introdução à Computação de Alto Desempenho Utilizando GPU Seminário de Programação em GPGPU Eng. Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo Introdução
Introdução à Computação de Alto Desempenho Utilizando GPU Seminário de Programação em GPGPU Eng. Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo Introdução
Aplicações em CUDA. Medialab Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center
 Aplicações em CUDA Medialab Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center Roteiro l Introdução l Eventos l Aspectos históricos l Operações atômicas l Introdução sobre
Aplicações em CUDA Medialab Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center Roteiro l Introdução l Eventos l Aspectos históricos l Operações atômicas l Introdução sobre
Arquitetura e Programação de GPU. Leandro Zanotto RA: 001962 Anselmo Ferreira RA: 023169 Marcelo Matsumoto RA: 085973
 Arquitetura e Programação de GPU Leandro Zanotto RA: 001962 Anselmo Ferreira RA: 023169 Marcelo Matsumoto RA: 085973 Agenda Primeiras Placas de Vídeo Primeira GPU Arquitetura da GPU NVIDIA Arquitetura
Arquitetura e Programação de GPU Leandro Zanotto RA: 001962 Anselmo Ferreira RA: 023169 Marcelo Matsumoto RA: 085973 Agenda Primeiras Placas de Vídeo Primeira GPU Arquitetura da GPU NVIDIA Arquitetura
5 Unidades de Processamento Gráfico GPUs
 5 Unidades de Processamento Gráfico GPUs As GPUs são processadores maciçamente paralelos, com múltiplos elementos de processamento, tipicamente utilizadas como aceleradores de computação. Elas fornecem
5 Unidades de Processamento Gráfico GPUs As GPUs são processadores maciçamente paralelos, com múltiplos elementos de processamento, tipicamente utilizadas como aceleradores de computação. Elas fornecem
Processamento de Alto Desempenho utilizando Unidade de Processamento Gráfico - GPU
 Processamento de Alto Desempenho utilizando Unidade de Processamento Gráfico - GPU Francisco Ribacionka e Ettore Enrico (STI ) USP/STI/InterNuvem internuvem@usp.br Março -2016 Processamento de Alto Desempenho
Processamento de Alto Desempenho utilizando Unidade de Processamento Gráfico - GPU Francisco Ribacionka e Ettore Enrico (STI ) USP/STI/InterNuvem internuvem@usp.br Março -2016 Processamento de Alto Desempenho
Computação Paralela (CUDA)
") Universidade Federal do Amazonas Faculdade de Tecnologia Departamento de Eletrônica e Computação Computação Paralela (CUDA) Hussama Ibrahim hussamaibrahim@ufam.edu.br Notas de Aula Baseado nas Notas de
Universidade Federal do Amazonas Faculdade de Tecnologia Departamento de Eletrônica e Computação Computação Paralela (CUDA) Hussama Ibrahim hussamaibrahim@ufam.edu.br Notas de Aula Baseado nas Notas de
Programação em Paralelo. N. Cardoso & P. Bicudo. Física Computacional - MEFT 2012/2013
 Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 23 CUDA "Compute Unified Device Architecture" Parte 2
Programação em Paralelo CUDA N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: CUDA 1 / 23 CUDA "Compute Unified Device Architecture" Parte 2
Patrício Domingues Dep. Eng. Informática ESTG Instituto Politécnico de Leiria Leiria, Maio Programação Genérica de GPUs
 Patrício Domingues Dep. Eng. Informática ESTG Instituto Politécnico de Leiria Leiria, Maio 2012 http://bit.ly/patricio Programação Genérica de GPUs 1 CUDA Teaching Center A ESTG/IPLeiria é um CUDA Teaching
Patrício Domingues Dep. Eng. Informática ESTG Instituto Politécnico de Leiria Leiria, Maio 2012 http://bit.ly/patricio Programação Genérica de GPUs 1 CUDA Teaching Center A ESTG/IPLeiria é um CUDA Teaching
Waldemar Celes. 25 de Agosto de 2014
 Introdução a CUDA INF2062 Tópicos em Simulação e Visualização Waldemar Celes celes@inf.puc-rio.br Tecgraf, DI/PUC-Rio 25 de Agosto de 2014 W. Celes Introdução a CUDA 1 GPGPU Programação de propósito geral
Introdução a CUDA INF2062 Tópicos em Simulação e Visualização Waldemar Celes celes@inf.puc-rio.br Tecgraf, DI/PUC-Rio 25 de Agosto de 2014 W. Celes Introdução a CUDA 1 GPGPU Programação de propósito geral
TEMA DE CAPA. Introdução à Programação em CUDA
 TEMA DE CAPA Introdução à Programação em CUDA Introdução à Programação em CUDA Nos últimos anos, as placas gráficas (GPU Graphical Processing Unit) ganharam relevância no âmbito da computação paralela.
TEMA DE CAPA Introdução à Programação em CUDA Introdução à Programação em CUDA Nos últimos anos, as placas gráficas (GPU Graphical Processing Unit) ganharam relevância no âmbito da computação paralela.
Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot
 Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Tomás Evalero Orellana Universidade Estadual de Santa Cruz Roteiro Breve introdução
Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Tomás Evalero Orellana Universidade Estadual de Santa Cruz Roteiro Breve introdução
Processamento Paralelo Utilizando GPU
 Processamento Paralelo Utilizando GPU Universidade Estadual de Santa Cruz Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Evalero Orellana Cronograma Breve introdução sobre processamento paralelo
Processamento Paralelo Utilizando GPU Universidade Estadual de Santa Cruz Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Evalero Orellana Cronograma Breve introdução sobre processamento paralelo
Aula 21 Ordenação externa
 MC3305 Algoritmos e Estruturas de Dados II Aula 21 Ordenação externa Slides adaptados de Brian Cooper (Yahoo Research) Prof. Jesús P. Mena-Chalco jesus.mena@ufabc.edu.br 2Q-2015 1 Números de Ackermann
MC3305 Algoritmos e Estruturas de Dados II Aula 21 Ordenação externa Slides adaptados de Brian Cooper (Yahoo Research) Prof. Jesús P. Mena-Chalco jesus.mena@ufabc.edu.br 2Q-2015 1 Números de Ackermann
Uma introdução para computação paralela de modelos massivos. Adriano Brito Pereira inf.puc-rio.br
 Uma introdução para computação paralela de modelos massivos Adriano Brito Pereira 1021752 apereira @ inf.puc-rio.br Departamento de Informática Novembro / 2010 1 Resultados obtivos com Manta Framework
Uma introdução para computação paralela de modelos massivos Adriano Brito Pereira 1021752 apereira @ inf.puc-rio.br Departamento de Informática Novembro / 2010 1 Resultados obtivos com Manta Framework
Thársis T. P. Souza
 Computação em Finanças em Hardware Gráfico SEMAC 2012 - UNESP Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo GPU Computing CUDA Aplicações em Finanças
Computação em Finanças em Hardware Gráfico SEMAC 2012 - UNESP Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo GPU Computing CUDA Aplicações em Finanças
MC4: Introdução à Programação Paralela em GPU para a Implementação de Métodos Numéricos
 MC4: Introdução à Programação Paralela em GPU para a Implementação de Métodos Numéricos Aula 1: Introdução à programação paralela e ao ambiente de programação CUDA Profs.: Daniel Alfaro e Silvana Rossetto
MC4: Introdução à Programação Paralela em GPU para a Implementação de Métodos Numéricos Aula 1: Introdução à programação paralela e ao ambiente de programação CUDA Profs.: Daniel Alfaro e Silvana Rossetto
Fabrício Gomes Vilasbôas
 Fabrício Gomes Vilasbôas Apresentação Placas Arquitetura Toolkit e Ferramentas de Debug Pensando em CUDA Programação CUDA Python Programação PyCUDA 1) Grids( padrão Globus) 2) Clusters ( padrão MPI) 3)
Fabrício Gomes Vilasbôas Apresentação Placas Arquitetura Toolkit e Ferramentas de Debug Pensando em CUDA Programação CUDA Python Programação PyCUDA 1) Grids( padrão Globus) 2) Clusters ( padrão MPI) 3)
Hierarquia de memória
 Hierarquia de memória Capítulo 6, Secção.{3..} Caches Slides adaptados dos slides do professor Pedro Pereira Centro de Cálculo Instituto Superior de Engenharia de Lisboa João Pedro Patriarca (jpatri@cc.isel.ipl.pt)
Hierarquia de memória Capítulo 6, Secção.{3..} Caches Slides adaptados dos slides do professor Pedro Pereira Centro de Cálculo Instituto Superior de Engenharia de Lisboa João Pedro Patriarca (jpatri@cc.isel.ipl.pt)
Introdução à linguagem C++
 Estrutura de Dados e Algoritmos e Programação e Computadores II Aula 2: Introdução à linguagem C++ Introdução à linguagem C++ Conceitos básicos: variáveis, tipos de dados, constantes, I/O, etc. Estruturas
Estrutura de Dados e Algoritmos e Programação e Computadores II Aula 2: Introdução à linguagem C++ Introdução à linguagem C++ Conceitos básicos: variáveis, tipos de dados, constantes, I/O, etc. Estruturas
Paralelismo de dados. (execução de simultaneidade) Tipo de arquitetura paralela SIMD. SIMD (Single Instruction Multiple Data)
 Tipo de arquitetura paralela SIMD. SIMD (Single Instruction Multiple Data)") Paralelismo de dados (execução de simultaneidade) Em métodos tradicionais de programação (processamento sequencial), uma grande quantidade de dados é processada em um único núcleo de uma CPU, enquanto
Paralelismo de dados (execução de simultaneidade) Em métodos tradicionais de programação (processamento sequencial), uma grande quantidade de dados é processada em um único núcleo de uma CPU, enquanto
VGM. VGM information. ALIANÇA VGM WEB PORTAL USER GUIDE June 2016
 Overview The Aliança VGM Web portal is an application that enables you to submit VGM information directly to Aliança via our e-portal Web page. You can choose to enter VGM information directly, or to download
Overview The Aliança VGM Web portal is an application that enables you to submit VGM information directly to Aliança via our e-portal Web page. You can choose to enter VGM information directly, or to download
Hierarquia de memória
 Hierarquia de memória Capítulo 6, Secção.{3..} Caches Slides adaptados dos slides do professor Pedro Pereira Consultar slides originais no moodle Centro de Cálculo Instituto Superior de Engenharia de Lisboa
Hierarquia de memória Capítulo 6, Secção.{3..} Caches Slides adaptados dos slides do professor Pedro Pereira Consultar slides originais no moodle Centro de Cálculo Instituto Superior de Engenharia de Lisboa
Ambientes e Ferramentas de Programação para GPU. Denise Stringhini (Mackenzie) Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP)
 Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP)") Ambientes e Ferramentas de Programação para GPU Denise Stringhini (Mackenzie) Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP) Conteúdo Conceitos de paralelismo Arquitetura de GPU CUDA OpenCL
Ambientes e Ferramentas de Programação para GPU Denise Stringhini (Mackenzie) Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP) Conteúdo Conceitos de paralelismo Arquitetura de GPU CUDA OpenCL
Pragmática das Linguagens de
 Instituto Superior Técnico Pragmática das Linguagens de Programação 2004/2005 Primeiro Exame/Segundo Teste 17/12/2004 Número: Turma: Nome: Escreva o seu número em todas as folhas do teste. O tamanho das
Instituto Superior Técnico Pragmática das Linguagens de Programação 2004/2005 Primeiro Exame/Segundo Teste 17/12/2004 Número: Turma: Nome: Escreva o seu número em todas as folhas do teste. O tamanho das
Transcript name: 1. Introduction to DB2 Express-C
 Transcript name: 1. Introduction to DB2 Express-C Transcript name: 1. Introduction to DB2 Express-C Welcome to the presentation Introduction to DB2 Express-C. In this presentation we answer 3 questions:
Transcript name: 1. Introduction to DB2 Express-C Transcript name: 1. Introduction to DB2 Express-C Welcome to the presentation Introduction to DB2 Express-C. In this presentation we answer 3 questions:
ALOCAÇÃO DINÂMICA DE MEMORIA Lista 10. A linguagem C/C++ possui recursos para alocação dinâmica de memoria.
 ALOCAÇÃO DINÂMICA DE MEMORIA Lista 10 A linguagem C/C++ possui recursos para alocação dinâmica de memoria. As funções que trabalham com alocação de memoria se encontram na biblioteca void *calloc(int
ALOCAÇÃO DINÂMICA DE MEMORIA Lista 10 A linguagem C/C++ possui recursos para alocação dinâmica de memoria. As funções que trabalham com alocação de memoria se encontram na biblioteca void *calloc(int
ecos - Gestores de dispositivos
 ecos - Gestores de dispositivos gestores de dispositivos ( device drivers ) interface aplicacional (API) gestor de linha série raw serial driver tty driver ecos - device driver - user API cyg_io_lookup
ecos - Gestores de dispositivos gestores de dispositivos ( device drivers ) interface aplicacional (API) gestor de linha série raw serial driver tty driver ecos - device driver - user API cyg_io_lookup
Programação. Cap. 12 Gestão de Memória Dinâmica
 Programação Engenharia Informática (11543) 1º ano, 1º semestre Tecnologias e Sistemas de Informação (6619) 1º ano, 1º semestre Cap. 12 Gestão de Memória Dinâmica Sumário : Utilização de memória Alocação
Programação Engenharia Informática (11543) 1º ano, 1º semestre Tecnologias e Sistemas de Informação (6619) 1º ano, 1º semestre Cap. 12 Gestão de Memória Dinâmica Sumário : Utilização de memória Alocação
O PRíNCIPE FELIZ E OUTRAS HISTóRIAS (EDIçãO BILíNGUE) (PORTUGUESE EDITION) BY OSCAR WILDE
 (PORTUGUESE EDITION) BY OSCAR WILDE") Read Online and Download Ebook O PRíNCIPE FELIZ E OUTRAS HISTóRIAS (EDIçãO BILíNGUE) (PORTUGUESE EDITION) BY OSCAR WILDE DOWNLOAD EBOOK : O PRíNCIPE FELIZ E OUTRAS HISTóRIAS (EDIçãO Click link bellow and
Read Online and Download Ebook O PRíNCIPE FELIZ E OUTRAS HISTóRIAS (EDIçãO BILíNGUE) (PORTUGUESE EDITION) BY OSCAR WILDE DOWNLOAD EBOOK : O PRíNCIPE FELIZ E OUTRAS HISTóRIAS (EDIçãO Click link bellow and
ATLAS DE ACUPUNTURA VETERINáRIA. CãES E GATOS (EM PORTUGUESE DO BRASIL) BY CHOO HYUNG KIM
 BY CHOO HYUNG KIM") Read Online and Download Ebook ATLAS DE ACUPUNTURA VETERINáRIA. CãES E GATOS (EM PORTUGUESE DO BRASIL) BY CHOO HYUNG KIM DOWNLOAD EBOOK : ATLAS DE ACUPUNTURA VETERINáRIA. CãES E GATOS Click link bellow
Read Online and Download Ebook ATLAS DE ACUPUNTURA VETERINáRIA. CãES E GATOS (EM PORTUGUESE DO BRASIL) BY CHOO HYUNG KIM DOWNLOAD EBOOK : ATLAS DE ACUPUNTURA VETERINáRIA. CãES E GATOS Click link bellow
Memory-level and Thread-level Parallelism Aware GPU Architecture Performance Analytical Model
 Memory-level and Thread-level Parallelism Aware GPU Architecture Performance Analytical Model Sunpyo Hong Hyesoon Kim ECE School of Computer Science Georgia Institute of Technology April 6, 2011 Visão
Memory-level and Thread-level Parallelism Aware GPU Architecture Performance Analytical Model Sunpyo Hong Hyesoon Kim ECE School of Computer Science Georgia Institute of Technology April 6, 2011 Visão
Programação em Paralelo OpenMP
 Programação em Paralelo OpenMP N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: OpenMP 1 / 15 Introdução Potencial do GPU vs CPU Cálculo: 367
Programação em Paralelo OpenMP N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: OpenMP 1 / 15 Introdução Potencial do GPU vs CPU Cálculo: 367
A necessidade da oração (Escola da Oração) (Portuguese Edition)
 (Portuguese Edition)") A necessidade da oração (Escola da Oração) (Portuguese Edition) Click here if your download doesn"t start automatically A necessidade da oração (Escola da Oração) (Portuguese Edition) A necessidade da
A necessidade da oração (Escola da Oração) (Portuguese Edition) Click here if your download doesn"t start automatically A necessidade da oração (Escola da Oração) (Portuguese Edition) A necessidade da
Otimização do desempenho (no h/w) Objectivo. Problemas: Estrutura do tema Avaliação de Desempenho (IA-32)
 Objectivo. Problemas: Estrutura do tema Avaliação de Desempenho (IA-32)") Avaliação de Desempenho no IA-32 (3) Análise do desempenho em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas
Avaliação de Desempenho no IA-32 (3) Análise do desempenho em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas
Sparse Matrix-Vector Multiplication on GPU: When Is Rows Reordering Worthwhile?
 Sparse Matrix-Vector Multiplication on GPU: When Is Rows Reordering Worthwhile? Paula Prata João Muranho Instituto de Telecomunicações Departamento de Informática Universidade da Beira Interior Instituto
Sparse Matrix-Vector Multiplication on GPU: When Is Rows Reordering Worthwhile? Paula Prata João Muranho Instituto de Telecomunicações Departamento de Informática Universidade da Beira Interior Instituto
Aula 12 - Correção de erros
 Aula 12 - Correção de erros Prof. Renan Sebem Disciplina de Eletrônica Digital Graduação em Engenharia Elétrica Universidade do Estado de Santa Catarina Joinville-SC Brasil 5 de abril de 2016 ELD0001 Prof.
Aula 12 - Correção de erros Prof. Renan Sebem Disciplina de Eletrônica Digital Graduação em Engenharia Elétrica Universidade do Estado de Santa Catarina Joinville-SC Brasil 5 de abril de 2016 ELD0001 Prof.
Gilberto A. S. Segundo. 24 de agosto de 2011
 Exercícios - Alocação Dinâmica Gilberto A. S. Segundo Programação Aplicada de Computadores Engenharia Elétrica Universidade Federal do Espírito Santo - UFES 24 de agosto de 2011 1 / 23 Grupo de e-mail
Exercícios - Alocação Dinâmica Gilberto A. S. Segundo Programação Aplicada de Computadores Engenharia Elétrica Universidade Federal do Espírito Santo - UFES 24 de agosto de 2011 1 / 23 Grupo de e-mail
Patricia Akemi Ikeda
 Um estudo do uso eficiente de programas em placas gráficas Patricia Akemi Ikeda Dissertação apresentada ao Instituto de Matemática e Estatística da Universidade de São Paulo para obtenção do título de
Um estudo do uso eficiente de programas em placas gráficas Patricia Akemi Ikeda Dissertação apresentada ao Instituto de Matemática e Estatística da Universidade de São Paulo para obtenção do título de
Introdução aos Sistemas Operacionais. Subsistema de Entrada e Saída
 Introdução aos Sistemas Operacionais Subsistema de Entrada e Saída Eleri Cardozo FEEC/Unicamp Entrada e Saída O subsistema de entrada e saída é responsável pela interface entre o sistema operacional e
Introdução aos Sistemas Operacionais Subsistema de Entrada e Saída Eleri Cardozo FEEC/Unicamp Entrada e Saída O subsistema de entrada e saída é responsável pela interface entre o sistema operacional e
Como Mudar a Senha do Roteador Pelo IP o.1.1. Configure e Altere a Senha do seu Roteador acessando o IP Acesse o Site e Confira!
 Como Mudar a Senha do Roteador Pelo IP 192.168.o.1.1. Configure e Altere a Senha do seu Roteador acessando o IP 192.168.1.1. Acesse o Site e Confira! If you are using the IP address 192.168.0.1.1, take
Como Mudar a Senha do Roteador Pelo IP 192.168.o.1.1. Configure e Altere a Senha do seu Roteador acessando o IP 192.168.1.1. Acesse o Site e Confira! If you are using the IP address 192.168.0.1.1, take
Otimização do desempenho (no h/w) Objetivo
 Objetivo") Avaliação de Desempenho no IA-32 (3) Eficiência em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação
Avaliação de Desempenho no IA-32 (3) Eficiência em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação
Da Emoção à Lesão: um Guia de Medicina Psicossomática (Portuguese Edition)
") Da Emoção à Lesão: um Guia de Medicina Psicossomática (Portuguese Edition) Geraldo José Ballone, Ida Vani Ortolani, Eurico Pereira Neto Click here if your download doesn"t start automatically Download
Da Emoção à Lesão: um Guia de Medicina Psicossomática (Portuguese Edition) Geraldo José Ballone, Ida Vani Ortolani, Eurico Pereira Neto Click here if your download doesn"t start automatically Download
Bíblia de Estudo Conselheira - Gênesis: Acolhimento Reflexão Graça (Portuguese Edition)
") Bíblia de Estudo Conselheira - Gênesis: Acolhimento Reflexão Graça (Portuguese Edition) Sociedade Bíblica do Brasil Click here if your download doesn"t start automatically Download and Read Free Online
Bíblia de Estudo Conselheira - Gênesis: Acolhimento Reflexão Graça (Portuguese Edition) Sociedade Bíblica do Brasil Click here if your download doesn"t start automatically Download and Read Free Online
PARALELIZAÇÃO DE APLICAÇÕES NA ARQUITETURA CUDA: UM ESTUDO SOBRE VETORES 1
 PARALELIZAÇÃO DE APLICAÇÕES NA ARQUITETURA CUDA: UM ESTUDO SOBRE VETORES 1 DUTRA, Evandro Rogério Fruhling 2 ; VARINI, Andre Luis 2 ; CANAL, Ana Paula 2 1 Trabalho de Iniciação Científica _UNIFRA 2 Ciência
PARALELIZAÇÃO DE APLICAÇÕES NA ARQUITETURA CUDA: UM ESTUDO SOBRE VETORES 1 DUTRA, Evandro Rogério Fruhling 2 ; VARINI, Andre Luis 2 ; CANAL, Ana Paula 2 1 Trabalho de Iniciação Científica _UNIFRA 2 Ciência
ENGENHARIA DE SERVIÇOS SERVICES ENGINEERING
 Mestrado em Engenharia de Redes de Comunicações MSc in Communication Networks Engineering ENGENHARIA DE SERVIÇOS SERVICES ENGINEERING 2012-2013 Sistemas de Suporte às Operações 2 - Operations Support Systems
Mestrado em Engenharia de Redes de Comunicações MSc in Communication Networks Engineering ENGENHARIA DE SERVIÇOS SERVICES ENGINEERING 2012-2013 Sistemas de Suporte às Operações 2 - Operations Support Systems
Aplicando Processamento Paralelo com GPU ao Problema do Fractal de Mandelbrot
 Aplicando Processamento Paralelo com GPU ao Problema do Fractal de Mandelbrot Bruno Pereira dos Santos¹, Dany Sanchez Dominguez¹, Esbel Valero Orellana¹. 1 Departamento de Ciências Exatas e Tecnológicas
Aplicando Processamento Paralelo com GPU ao Problema do Fractal de Mandelbrot Bruno Pereira dos Santos¹, Dany Sanchez Dominguez¹, Esbel Valero Orellana¹. 1 Departamento de Ciências Exatas e Tecnológicas
PL/SQL: Domine a linguagem do banco de dados Oracle (Portuguese Edition)
") PL/SQL: Domine a linguagem do banco de dados Oracle (Portuguese Edition) Eduardo Gonçalves Click here if your download doesn"t start automatically PL/SQL: Domine a linguagem do banco de dados Oracle (Portuguese
PL/SQL: Domine a linguagem do banco de dados Oracle (Portuguese Edition) Eduardo Gonçalves Click here if your download doesn"t start automatically PL/SQL: Domine a linguagem do banco de dados Oracle (Portuguese
EXCEL PARA FINANçAS PESSOAIS (PORTUGUESE EDITION) BY FABRíCIO AUGUSTO FERRARI
 BY FABRíCIO AUGUSTO FERRARI") Read Online and Download Ebook EXCEL PARA FINANçAS PESSOAIS (PORTUGUESE EDITION) BY FABRíCIO AUGUSTO FERRARI DOWNLOAD EBOOK : EXCEL PARA FINANçAS PESSOAIS (PORTUGUESE EDITION) Click link bellow and free
Read Online and Download Ebook EXCEL PARA FINANçAS PESSOAIS (PORTUGUESE EDITION) BY FABRíCIO AUGUSTO FERRARI DOWNLOAD EBOOK : EXCEL PARA FINANçAS PESSOAIS (PORTUGUESE EDITION) Click link bellow and free
Mestrado em Informática
 Sistemas de Computação e Desempenho Arquitecturas Paralelas Mestrado em Informática 2010/11 A.J.Proença Tema Arquitecturas Paralelas (2) Estrutura do tema AP 1. A evolução das arquitecturas pelo paralelismo
Sistemas de Computação e Desempenho Arquitecturas Paralelas Mestrado em Informática 2010/11 A.J.Proença Tema Arquitecturas Paralelas (2) Estrutura do tema AP 1. A evolução das arquitecturas pelo paralelismo
Orientação a Objetos - Programação em C++
 OO Engenharia Eletrônica Orientação a Objetos - Programação em C++ Slides 14: As classes List e Vector da STL (Standard Template Library). Prof. Jean Marcelo SIMÃO Classe List Uma classe Predefinida na
OO Engenharia Eletrônica Orientação a Objetos - Programação em C++ Slides 14: As classes List e Vector da STL (Standard Template Library). Prof. Jean Marcelo SIMÃO Classe List Uma classe Predefinida na
Linguagem de Programação. Thiago Leite Francisco Barretto
 Linguagem de Programação Thiago Leite Francisco Barretto SCHILDT, H. C Completo e Total. 3ª Edição. São Paulo: Makron, 1997. Bibliografia Ementa
Linguagem de Programação Thiago Leite Francisco Barretto SCHILDT, H. C Completo e Total. 3ª Edição. São Paulo: Makron, 1997. Bibliografia Ementa
Guia Rápido: GCC, Makefile e Valgrind.
 Guia Rápido: GCC, Makefile e Valgrind. Alexandro Ramos 10 de setembro de 2015 1 Sumário 1 Introdução 3 2 GCC 3 2.1 Outros parâmetros úteis no GCC....................... 4 3 Makefiles 6 3.1 Makefile 1....................................
Guia Rápido: GCC, Makefile e Valgrind. Alexandro Ramos 10 de setembro de 2015 1 Sumário 1 Introdução 3 2 GCC 3 2.1 Outros parâmetros úteis no GCC....................... 4 3 Makefiles 6 3.1 Makefile 1....................................
Infra-Estrutura de Software. Introdução
 Infra-Estrutura de Software Introdução Objetivos das duas próximas aulas Ao final da aula de quinta-feira você deverá ser capaz de: Descrever os componentes básicos de um computador Explicar como o sistema
Infra-Estrutura de Software Introdução Objetivos das duas próximas aulas Ao final da aula de quinta-feira você deverá ser capaz de: Descrever os componentes básicos de um computador Explicar como o sistema
Soluções em GPU para o Problema do Alinhamento Spliced
 Soluções em GPU para o Problema do Alinhamento Spliced Anisio Vitorino Nolasco Dissertação de Mestrado apresentada à Faculdade de Computação da Universidade Federal de Mato Grosso do Sul Orientadora: Profa.
Soluções em GPU para o Problema do Alinhamento Spliced Anisio Vitorino Nolasco Dissertação de Mestrado apresentada à Faculdade de Computação da Universidade Federal de Mato Grosso do Sul Orientadora: Profa.
Linguagem C. IF61A/IF71A - Computação 1 Prof. Leonelo Almeida. Universidade Tecnológica Federal do Paraná
 Linguagem C IF61A/IF71A - Computação 1 Prof. Leonelo Almeida Universidade Tecnológica Federal do Paraná Até agora... Sabemos construir algoritmos que tenham: Variáveis Comandos sequenciais Entrada e saída
Linguagem C IF61A/IF71A - Computação 1 Prof. Leonelo Almeida Universidade Tecnológica Federal do Paraná Até agora... Sabemos construir algoritmos que tenham: Variáveis Comandos sequenciais Entrada e saída
Abraçado pelo Espírito (Portuguese Edition)
") Abraçado pelo Espírito (Portuguese Edition) Charles Swindoll Click here if your download doesn"t start automatically Abraçado pelo Espírito (Portuguese Edition) Charles Swindoll Abraçado pelo Espírito
Abraçado pelo Espírito (Portuguese Edition) Charles Swindoll Click here if your download doesn"t start automatically Abraçado pelo Espírito (Portuguese Edition) Charles Swindoll Abraçado pelo Espírito
UFRJ IM - DCC. Sistemas Operacionais I. Unidade IV Gerência de Recursos Entrada e Saída. 02/12/2014 Prof. Valeria M. Bastos
 UFRJ IM - DCC Sistemas Operacionais I Unidade IV Gerência de Recursos Entrada e Saída 02/12/2014 Prof. Valeria M. Bastos 1 ORGANIZAÇÃO DA UNIDADE Gerência de Entrada e Saída Fundamentos Evolução Estrutura
UFRJ IM - DCC Sistemas Operacionais I Unidade IV Gerência de Recursos Entrada e Saída 02/12/2014 Prof. Valeria M. Bastos 1 ORGANIZAÇÃO DA UNIDADE Gerência de Entrada e Saída Fundamentos Evolução Estrutura
TEN CATE. HISTOLOGIA ORAL (EM PORTUGUESE DO BRASIL) BY ANTONIO NANCI
 BY ANTONIO NANCI") Read Online and Download Ebook TEN CATE. HISTOLOGIA ORAL (EM PORTUGUESE DO BRASIL) BY ANTONIO NANCI DOWNLOAD EBOOK : TEN CATE. HISTOLOGIA ORAL (EM PORTUGUESE DO Click link bellow and free register to download
Read Online and Download Ebook TEN CATE. HISTOLOGIA ORAL (EM PORTUGUESE DO BRASIL) BY ANTONIO NANCI DOWNLOAD EBOOK : TEN CATE. HISTOLOGIA ORAL (EM PORTUGUESE DO Click link bellow and free register to download
Utilizando cin: primeiros passos
 Utilizando cin: primeiros passos Já sabemos Que cout é usado para imprimir informações na tela Uma alterna6va em C é o prin9. Procure mais informações dele O que poderia ser usado para fazer entrada? Se
Utilizando cin: primeiros passos Já sabemos Que cout é usado para imprimir informações na tela Uma alterna6va em C é o prin9. Procure mais informações dele O que poderia ser usado para fazer entrada? Se
CUDA. José Ricardo da Silva Jr.
 CUDA José Ricardo da Silva Jr. Medialab Ins1tuto de Computação Universidade Federal Fluminense CUDA Research Center & CUDA Teaching Center Centro de excelência da NVIDIA desde julho 2012 Perfil Bacharel
CUDA José Ricardo da Silva Jr. Medialab Ins1tuto de Computação Universidade Federal Fluminense CUDA Research Center & CUDA Teaching Center Centro de excelência da NVIDIA desde julho 2012 Perfil Bacharel
ATLAS DE ACUPUNTURA VETERINáRIA. CãES E GATOS (EM PORTUGUESE DO BRASIL) BY CHOO HYUNG KIM
 BY CHOO HYUNG KIM") Read Online and Download Ebook ATLAS DE ACUPUNTURA VETERINáRIA. CãES E GATOS (EM PORTUGUESE DO BRASIL) BY CHOO HYUNG KIM DOWNLOAD EBOOK : ATLAS DE ACUPUNTURA VETERINáRIA. CãES E GATOS Click link bellow
Read Online and Download Ebook ATLAS DE ACUPUNTURA VETERINáRIA. CãES E GATOS (EM PORTUGUESE DO BRASIL) BY CHOO HYUNG KIM DOWNLOAD EBOOK : ATLAS DE ACUPUNTURA VETERINáRIA. CãES E GATOS Click link bellow
COMO ESCREVER PARA O ENEM: ROTEIRO PARA UMA REDAçãO NOTA (PORTUGUESE EDITION) BY ARLETE SALVADOR
 BY ARLETE SALVADOR") Read Online and Download Ebook COMO ESCREVER PARA O ENEM: ROTEIRO PARA UMA REDAçãO NOTA 1.000 (PORTUGUESE EDITION) BY ARLETE SALVADOR DOWNLOAD EBOOK : COMO ESCREVER PARA O ENEM: ROTEIRO PARA UMA SALVADOR
Read Online and Download Ebook COMO ESCREVER PARA O ENEM: ROTEIRO PARA UMA REDAçãO NOTA 1.000 (PORTUGUESE EDITION) BY ARLETE SALVADOR DOWNLOAD EBOOK : COMO ESCREVER PARA O ENEM: ROTEIRO PARA UMA SALVADOR
GERENCIAMENTO PELAS DIRETRIZES (PORTUGUESE EDITION) BY VICENTE FALCONI
 BY VICENTE FALCONI") Read Online and Download Ebook GERENCIAMENTO PELAS DIRETRIZES (PORTUGUESE EDITION) BY VICENTE FALCONI DOWNLOAD EBOOK : GERENCIAMENTO PELAS DIRETRIZES (PORTUGUESE Click link bellow and free register to
Read Online and Download Ebook GERENCIAMENTO PELAS DIRETRIZES (PORTUGUESE EDITION) BY VICENTE FALCONI DOWNLOAD EBOOK : GERENCIAMENTO PELAS DIRETRIZES (PORTUGUESE Click link bellow and free register to
As 100 melhores piadas de todos os tempos (Portuguese Edition)
") As 100 melhores piadas de todos os tempos (Portuguese Edition) Click here if your download doesn"t start automatically As 100 melhores piadas de todos os tempos (Portuguese Edition) As 100 melhores piadas
As 100 melhores piadas de todos os tempos (Portuguese Edition) Click here if your download doesn"t start automatically As 100 melhores piadas de todos os tempos (Portuguese Edition) As 100 melhores piadas
Tutorial presentation of RBO Online
 Apresentação do tutorial da RBO Online Prezado autor, Esse tutorial visa ajudar o autor na submissão de artigos na plataforma da RBO online, desejamos que ele seja um instrumento de apoio e facilite o
Apresentação do tutorial da RBO Online Prezado autor, Esse tutorial visa ajudar o autor na submissão de artigos na plataforma da RBO online, desejamos que ele seja um instrumento de apoio e facilite o
Mitologia - Deuses, Heróis e Lendas (Portuguese Edition)
") Mitologia - Deuses, Heróis e Lendas (Portuguese Edition) Maurício Horta, José Francisco Botelho, Salvador Nogueira Click here if your download doesn"t start automatically Mitologia - Deuses, Heróis e Lendas
Mitologia - Deuses, Heróis e Lendas (Portuguese Edition) Maurício Horta, José Francisco Botelho, Salvador Nogueira Click here if your download doesn"t start automatically Mitologia - Deuses, Heróis e Lendas
CIVILIZAçãO EM TRANSIçãO (OBRAS COMPLETAS DE CARL GUSTAV JUNG) (PORTUGUESE EDITION) BY CARL GUSTAV JUNG
 (PORTUGUESE EDITION) BY CARL GUSTAV JUNG") Read Online and Download Ebook CIVILIZAçãO EM TRANSIçãO (OBRAS COMPLETAS DE CARL GUSTAV JUNG) (PORTUGUESE EDITION) BY CARL GUSTAV JUNG DOWNLOAD EBOOK : CIVILIZAçãO EM TRANSIçãO (OBRAS COMPLETAS DE Click
Read Online and Download Ebook CIVILIZAçãO EM TRANSIçãO (OBRAS COMPLETAS DE CARL GUSTAV JUNG) (PORTUGUESE EDITION) BY CARL GUSTAV JUNG DOWNLOAD EBOOK : CIVILIZAçãO EM TRANSIçãO (OBRAS COMPLETAS DE Click
PARALELIZAÇÃO DO ALGORITMO AES E ANÁLISE SOBRE GPGPU 1 PARALLELIZATION OF AES ALGORITHM AND GPU ANALYSIS
 Disciplinarum Scientia. Série: Naturais e Tecnológicas, Santa Maria, v. 16, n. 1, p. 83-94, 2015. Recebido em: 11.04.2015. Aprovado em: 30.06.2015. ISSN 2176-462X PARALELIZAÇÃO DO ALGORITMO AES E ANÁLISE
Disciplinarum Scientia. Série: Naturais e Tecnológicas, Santa Maria, v. 16, n. 1, p. 83-94, 2015. Recebido em: 11.04.2015. Aprovado em: 30.06.2015. ISSN 2176-462X PARALELIZAÇÃO DO ALGORITMO AES E ANÁLISE
Introdução OpenMP. Nielsen Castelo Damasceno
 Introdução OpenMP Nielsen Castelo Damasceno Computação de auto desempenho Processamento Paralelo Memória Distribuída e Compartilhada Modelo de programação OpenMP Métricas de Desempenho Computação de auto
Introdução OpenMP Nielsen Castelo Damasceno Computação de auto desempenho Processamento Paralelo Memória Distribuída e Compartilhada Modelo de programação OpenMP Métricas de Desempenho Computação de auto
Power Estimation FPGA ASIC
 Power Estimation FPGA ASIC Power in CMOS Total Current is composed of two types of current Static Dynamic Static Current Leakage current in the turned off transistor channel Ideally zero (varies with technology)
Power Estimation FPGA ASIC Power in CMOS Total Current is composed of two types of current Static Dynamic Static Current Leakage current in the turned off transistor channel Ideally zero (varies with technology)
Psicologia da Gratidão (Série Psicologica Joanna de Ângelis) (Portuguese Edition)
 (Portuguese Edition)") Psicologia da Gratidão (Série Psicologica Joanna de Ângelis) (Portuguese Edition) Divaldo Franco, Joanna de Ângelis Click here if your download doesn"t start automatically Psicologia da Gratidão (Série
Psicologia da Gratidão (Série Psicologica Joanna de Ângelis) (Portuguese Edition) Divaldo Franco, Joanna de Ângelis Click here if your download doesn"t start automatically Psicologia da Gratidão (Série
Tempo de processador desperdiçado a fazer nada. Processor register 1 clock cycle (0.5 2 GHz) $??? DRAM semiconductor memory ns $10 $20
 $??? DRAM semiconductor memory ns $10 $20") Caches Cache Acesso à memória é lento Tempo de processador desperdiçado a fazer nada CPU Memória Memory technology Typical access time $ per GiB in 2012 Processor register 1 clock cycle (0.5 ns @ 2 GHz)
Caches Cache Acesso à memória é lento Tempo de processador desperdiçado a fazer nada CPU Memória Memory technology Typical access time $ per GiB in 2012 Processor register 1 clock cycle (0.5 ns @ 2 GHz)
3 Computação de Propósito Geral em Unidades de Processamento Gráfico
 3 Computação de Propósito Geral em Unidades de Processamento Gráfico As Unidades de Processamento Gráfico (GPUs) foram originalmente desenvolvidas para o processamento de gráficos e eram difíceis de programar.
3 Computação de Propósito Geral em Unidades de Processamento Gráfico As Unidades de Processamento Gráfico (GPUs) foram originalmente desenvolvidas para o processamento de gráficos e eram difíceis de programar.
Para iniciar um agente SNMP, usamos o comando snmpd. Por padrão, aceita requisições na porta 161 (UDP).
.") EN3610 Gerenciamento e interoperabilidade de redes Prof. João Henrique Kleinschmidt Prática SNMP Net-SNMP (http://www.net-snmp.org) é um conjunto de aplicações usado para implementar SNMPv1, SNMPv2 e SNMPv3.
EN3610 Gerenciamento e interoperabilidade de redes Prof. João Henrique Kleinschmidt Prática SNMP Net-SNMP (http://www.net-snmp.org) é um conjunto de aplicações usado para implementar SNMPv1, SNMPv2 e SNMPv3.
OpenStereo: open source, cross-platform software for structural geology analysis
 OpenStereo: open source, cross-platform software for structural geology analysis Carlos Henrique Grohmann & Ginaldo A.C. Campanha guano@usp.br Institute of Geosciences, University of São Paulo, Brazil
OpenStereo: open source, cross-platform software for structural geology analysis Carlos Henrique Grohmann & Ginaldo A.C. Campanha guano@usp.br Institute of Geosciences, University of São Paulo, Brazil
Universidade Federal de Uberlândia Faculdade de Computação. Linguagem C: ponteiros e alocação dinâmica
 Universidade Federal de Uberlândia Faculdade de Computação Linguagem C: ponteiros e alocação dinâmica Prof. Renato Pimentel 1 Ponteiros 2 Prof. Renato Pimentel 1 Ponteiros: introdução Toda a informação
Universidade Federal de Uberlândia Faculdade de Computação Linguagem C: ponteiros e alocação dinâmica Prof. Renato Pimentel 1 Ponteiros 2 Prof. Renato Pimentel 1 Ponteiros: introdução Toda a informação
TDD Desenvolvimento Guiado por Testes (Portuguese Edition)
") TDD Desenvolvimento Guiado por Testes (Portuguese Edition) Kent Beck Click here if your download doesn"t start automatically TDD Desenvolvimento Guiado por Testes (Portuguese Edition) Kent Beck TDD Desenvolvimento
TDD Desenvolvimento Guiado por Testes (Portuguese Edition) Kent Beck Click here if your download doesn"t start automatically TDD Desenvolvimento Guiado por Testes (Portuguese Edition) Kent Beck TDD Desenvolvimento
Celso L. Mendes LAC /INPE
 Arquiteturas para Processamento de Alto Desempenho (PAD) Aula 9 Celso L. Mendes LAC /INPE Email: celso.mendes@inpe.br Aula 9 (3/5): E. Aceleradores Estrutura Planejada i. Estruturas mais Populares ii.
Arquiteturas para Processamento de Alto Desempenho (PAD) Aula 9 Celso L. Mendes LAC /INPE Email: celso.mendes@inpe.br Aula 9 (3/5): E. Aceleradores Estrutura Planejada i. Estruturas mais Populares ii.
A ENTREVISTA COMPREENSIVA: UM GUIA PARA PESQUISA DE CAMPO (PORTUGUESE EDITION) BY JEAN-CLAUDE KAUFMANN
 BY JEAN-CLAUDE KAUFMANN") Read Online and Download Ebook A ENTREVISTA COMPREENSIVA: UM GUIA PARA PESQUISA DE CAMPO (PORTUGUESE EDITION) BY JEAN-CLAUDE KAUFMANN DOWNLOAD EBOOK : A ENTREVISTA COMPREENSIVA: UM GUIA PARA CLAUDE KAUFMANN
Read Online and Download Ebook A ENTREVISTA COMPREENSIVA: UM GUIA PARA PESQUISA DE CAMPO (PORTUGUESE EDITION) BY JEAN-CLAUDE KAUFMANN DOWNLOAD EBOOK : A ENTREVISTA COMPREENSIVA: UM GUIA PARA CLAUDE KAUFMANN
Professor Marcelo Josué Telles Porta LPT, programação, componentes eletrônicos, sistema binário...
 Objetivos: - Conhecer a porta paralela LPT (explore as referências!) - Explorar uma linguagem de programação - Montagem de um circuito de comunicação via LPT - Revisão do sistema numérico binário INTRODUÇÃO
Objetivos: - Conhecer a porta paralela LPT (explore as referências!) - Explorar uma linguagem de programação - Montagem de um circuito de comunicação via LPT - Revisão do sistema numérico binário INTRODUÇÃO
Linguagem C Introdução. Contexto Histórico Principais diferenças do Java Funções em C Compilar programas em C no Linux
 Linguagem C Introdução Contexto Histórico Principais diferenças do Java Funções em C Compilar programas em C no Linux Porquê C em AC? A linguagem C fornece um modelo de programação próximo da máquina física
Linguagem C Introdução Contexto Histórico Principais diferenças do Java Funções em C Compilar programas em C no Linux Porquê C em AC? A linguagem C fornece um modelo de programação próximo da máquina física
INF Programação Distribuída e Paralela
 INF01008 - Programação Distribuída e Paralela Trabalho Final Multiplicação de Matrizes com APIs de Programação Paralela Cristiano Medeiros Dalbem John Gamboa Introdução Neste trabalho comparamos diferentes
INF01008 - Programação Distribuída e Paralela Trabalho Final Multiplicação de Matrizes com APIs de Programação Paralela Cristiano Medeiros Dalbem John Gamboa Introdução Neste trabalho comparamos diferentes
Vaporpunk - A fazenda-relógio (Portuguese Edition)
") Vaporpunk - A fazenda-relógio (Portuguese Edition) Octavio Aragão Click here if your download doesn"t start automatically Vaporpunk - A fazenda-relógio (Portuguese Edition) Octavio Aragão Vaporpunk - A
Vaporpunk - A fazenda-relógio (Portuguese Edition) Octavio Aragão Click here if your download doesn"t start automatically Vaporpunk - A fazenda-relógio (Portuguese Edition) Octavio Aragão Vaporpunk - A
Para iniciar um agente SNMP, usamos o comando snmpd. Por padrão, aceita requisições na porta 161 (UDP).
.") EN3610 Gerenciamento e interoperabilidade de redes Prof. João Henrique Kleinschmidt Prática SNMP 1 MIBs RMON No Linux os arquivos MIB são armazenados no diretório /usr/share/snmp/mibs. Cada arquivo MIB
EN3610 Gerenciamento e interoperabilidade de redes Prof. João Henrique Kleinschmidt Prática SNMP 1 MIBs RMON No Linux os arquivos MIB são armazenados no diretório /usr/share/snmp/mibs. Cada arquivo MIB
Edison Gustavo Muenz. Estudo e implementação de um algoritmo de processamento de imagens com técnicas GPGPU
 Edison Gustavo Muenz Estudo e implementação de um algoritmo de processamento de imagens com técnicas GPGPU Florianópolis SC Agosto / 2008 Edison Gustavo Muenz Estudo e implementação de um algoritmo de
Edison Gustavo Muenz Estudo e implementação de um algoritmo de processamento de imagens com técnicas GPGPU Florianópolis SC Agosto / 2008 Edison Gustavo Muenz Estudo e implementação de um algoritmo de
CUDA: Compute Unified Device Architecture. Marco Antonio Simões Teixeira
 CUDA: Compute Unified Device Architecture Marco Antonio Simões Teixeira Sumário Introdução; CUDA: História; CUDA: programando; CUDA e deep learning; Links úteis; Considerações finais. 2 INTRODUÇÃO 3 O
CUDA: Compute Unified Device Architecture Marco Antonio Simões Teixeira Sumário Introdução; CUDA: História; CUDA: programando; CUDA e deep learning; Links úteis; Considerações finais. 2 INTRODUÇÃO 3 O
UTILIZANDO O CODE BLOCKS
 UTILIZANDO O CODE BLOCKS Prof. André Backes INTRODUÇÃO Existem diversos ambientes de desenvolvimento integrado ou IDEs (Integrated Development Environment) que podem ser utilizados para a programação em
UTILIZANDO O CODE BLOCKS Prof. André Backes INTRODUÇÃO Existem diversos ambientes de desenvolvimento integrado ou IDEs (Integrated Development Environment) que podem ser utilizados para a programação em
VGM. VGM information. ALIANÇA VGM WEB PORTAL USER GUIDE September 2016
 Overview The Aliança VGM Web portal is an application that enables you to submit VGM information directly to Aliança via our e-portal Web page. You can choose to enter VGM information directly, or to download
Overview The Aliança VGM Web portal is an application that enables you to submit VGM information directly to Aliança via our e-portal Web page. You can choose to enter VGM information directly, or to download
Step by step to make the appointment at the Federal Police
 Step by step to make the appointment at the Federal Police Before you start, check if you have these documents with you: Visa Application Form; Birth Certificate (original); Passport; Brazilian home address
Step by step to make the appointment at the Federal Police Before you start, check if you have these documents with you: Visa Application Form; Birth Certificate (original); Passport; Brazilian home address
Os 7 Hábitos das Pessoas Altamente Eficazes (Portuguese Edition)
") Os 7 Hábitos das Pessoas Altamente Eficazes (Portuguese Edition) Click here if your download doesn"t start automatically Os 7 Hábitos das Pessoas Altamente Eficazes (Portuguese Edition) Os 7 Hábitos das
Os 7 Hábitos das Pessoas Altamente Eficazes (Portuguese Edition) Click here if your download doesn"t start automatically Os 7 Hábitos das Pessoas Altamente Eficazes (Portuguese Edition) Os 7 Hábitos das
Anhanguera Educacional S.A. Centro Universitário Ibero-Americano
 O C++ foi inicialmente desenvolvido por Bjarne Stroustrup durante a década de 1980 com o objetivo de melhorar a linguagem de programação C, mantendo a compatibilidade com esta linguagem. Exemplos de Aplicações
O C++ foi inicialmente desenvolvido por Bjarne Stroustrup durante a década de 1980 com o objetivo de melhorar a linguagem de programação C, mantendo a compatibilidade com esta linguagem. Exemplos de Aplicações
Farmácia Homeopática: Teoria e Prática (Portuguese Edition)
") Farmácia Homeopática: Teoria e Prática (Portuguese Edition) Olney Leite Fontes Click here if your download doesn"t start automatically Farmácia Homeopática: Teoria e Prática (Portuguese Edition) Olney
Farmácia Homeopática: Teoria e Prática (Portuguese Edition) Olney Leite Fontes Click here if your download doesn"t start automatically Farmácia Homeopática: Teoria e Prática (Portuguese Edition) Olney
Introdução à Programação Paralela através de Padrões. Denise Stringhini Calebe Bianchini Luciano Silva
 Introdução à Programação Paralela através de Padrões Denise Stringhini Calebe Bianchini Luciano Silva Sumário Introdução: conceitos de paralelismo Conceitos básicos sobre padrões de programação paralela
Introdução à Programação Paralela através de Padrões Denise Stringhini Calebe Bianchini Luciano Silva Sumário Introdução: conceitos de paralelismo Conceitos básicos sobre padrões de programação paralela
Medicina e Meditação - Um Médico Ensina a Meditar (Portuguese Edition)
") Medicina e Meditação - Um Médico Ensina a Meditar (Portuguese Edition) Roberto Cardoso Click here if your download doesn"t start automatically Medicina e Meditação - Um Médico Ensina a Meditar (Portuguese
Medicina e Meditação - Um Médico Ensina a Meditar (Portuguese Edition) Roberto Cardoso Click here if your download doesn"t start automatically Medicina e Meditação - Um Médico Ensina a Meditar (Portuguese
Esboços e Sermões Completos para Ocasiões e Datas Especiais: Mensagens Bíblicas para Todas as Datas da Vida Cristã (Portuguese Edition)
") Esboços e Sermões Completos para Ocasiões e Datas Especiais: Mensagens Bíblicas para Todas as Datas da Vida Cristã (Portuguese Edition) Adelson Damasceno Santos Click here if your download doesn"t start
Esboços e Sermões Completos para Ocasiões e Datas Especiais: Mensagens Bíblicas para Todas as Datas da Vida Cristã (Portuguese Edition) Adelson Damasceno Santos Click here if your download doesn"t start
Planejamento de comunicação integrada (Portuguese Edition)
") Planejamento de comunicação integrada (Portuguese Edition) Click here if your download doesn"t start automatically Planejamento de comunicação integrada (Portuguese Edition) Planejamento de comunicação
Planejamento de comunicação integrada (Portuguese Edition) Click here if your download doesn"t start automatically Planejamento de comunicação integrada (Portuguese Edition) Planejamento de comunicação