Evolução das Aquiteturas Stream Computing: Desempenho de Algoritmos Dwarf Mine em GPGPU
|
|
|
- Isaac Peralta Carvalhal
- 6 Há anos
- Visualizações:
Transcrição





1 Evolução das Aquiteturas Stream Computing: Desempenho de Algoritmos Dwarf Mine em GPGPU Professor: Philippe O. A. Navaux Doutorando: Laércio Pilla Institute of Informatics - UFRGS Parallel and Distributed Processing Group
2 Index Stream Processors Evolution Processamento SISD Pipeline Processamento SIMD Arquiteturas Superescalares - ILP Arquiteturas Multithreading - TLP Aquiteturas Multi core, Many core Processamento Stream Experimental Evaluation Map Reduce Spectral Methods Sparse Linear Algebra Architecture and Software Evolution 2 Conclusion
3 Stream Processing Evolution 3
4 Evolução dos Processadores Ao longo do tempo sempre houve uma preocupação em obter mais desempenho das CPUs para atender demandas crescentes de processamento. Num primeiro tempo o desenvolvimento de CPUs mais rápidas, graças ao aumento do clock, eram suficientes para atender a demanda. Logo, verificou-se que os investimentos para obter CPUs mais rápidas tornavam estas custosas demais, a partir deste momento procuraram-se soluções através do paralelismo na execução de instruções. 4
5 Processamento Serial - SISD 5
6 Processamento serial - SISD Arquiteturas tradicionais de CPUs são SISD, o que subentende que conceitualmente somente uma operação será executada a cada tempo. Na figura ao lado verifica-se que a cada vez entra uma instrução e um dado para gerar um resultado. 6
7 Primeiros momentos do Paralelismo em CPUs Observando a evolução das CPUs verifica-se que o emprego da técnica pipeline é empregada como uma das primeira formas de obter um paralelismo temporal na execução das instruções. O aumento de desempenho é obtido pela sobreposição temporal na execuçao das instruções. Na mesma época surge o paralelismo de recursos, com o surgimento das arquiteturas SIMD, também conhecidas por Array Processors. 7
8 Arquitetura Pipeline 8

9 Pipeline Architecture 5 stages depth. Clock frequency depends on the slower stage. More stages, more registers to save the states between them. 9


10 Pipeline Architecture No instruction parallelism. Hardware reuse. CPI ideal = 1 (full pipeline). 10
11 Arquitetura SIMD 11

12 Processamento Paralelo - SIMD Numa arquitetura SIMD, o paradigma de programação permite a aplicação de uma instrução sobre várias instâncias de dados em paralelo, por exemplo elementos de uma matriz. Na figura ao lado verifica-se que uma instrução age sobre multíplos dados. 12
13 Arquitetura SIMD Funcionamento da Arquitetura SIMD: Múltiplas unidades de processamento, PEs, supervisionadas por uma unidade de controle comum. Mesma instrução é executada sobre diferentes dados. Processor Memory PE M PE M PE M PE M PE M PE M PE M PE M PE M PE M PE M PE M PE M PE M PE M A memória compartilhada é PE dividida em múltiplos módulos. M Cada PE acessa seu próprio módulo de memória simultaneamente. 13

14 ILLIAC IV SIMD Supercomputer The ILLIAC IV was built by the University of Illinois, 1972, at the request of the Department of Defense Advanced Research Projects Agency. The ILLIAC IV was build as a large-scale array, parallel processing computer. 14
15 Arquitetura Superescalar 15
16 Arquiteturas Superescalares - ILP Logo mais, visando melhorar o emprego do hardware surgem as arquiteturas superescalares com o paralelismo de instruçoes, ILP. A razão maior era que as arquiteturas pipeline começaram a ter uma estrutura com várias unidades funcionais que eram apenas empregadas uma de cada vez, ficando portanto as outras em idle. O IPC (instruction per cycle) era no máximo 1. 16

17 Superscalar Architecture - ILP Beginning of the parallelism. Fetch, Decode and execute more than one instruction per cycle. Aggressive Parallelism Dispatch and Out-ofOrder execution (OOO). 17


18 Superscalar Architecture - ILP Pipelining stills alive. IPC ideal > 1 Instruction Level Parallelism - ILP. 18

19 Processors Evolution Pawlowski, 2006 Intel 19
20 Arquiteturas Multithreading 20
21 Multithreading Architecture - TLP PROBLEMS Even supporting instruction level parallelism, the maximum parallelism obtained was 2 instructions per cycle, keeping some units on idle. MOTIVATION Usage of MULTITHREADING techniques. Gains with the parallel execution of more than one thread per cycle. TLP. 21

22 Multithreading Architecture - TLP Many active threads 22
23 Multithreading Architecture - TLP Only one physical processors. Multiples virtual processors. Beginning of the TLP (Thread Level Paralelism) The ILP (Instruction Level Paralelism) still alive. 23

24 Multithreading Architecture - TLP Small hardware increase on: PC, ROB, Register File Bottleneck on shared resources Functional Units Cache Memory Main Memory 24

25 Chip Multithreading - TLP 25
26 Arquiteturas Multi-core e Many-core 26
27 Multi-Core Architecture PROBLEMS Although the multirhreading architectures improves the performance, the bottleneck for data and instructions still occurring. Cache memory problem. MOTIVATION Usage of MULTI-CORE architectures. Gains using simple cores, in order to better distribute the resources and threads. 27


28 Multi-Core Architecture It also represents a multithread. Many active threads. Can also combine techniques such as IMT, BMT and SMT. 28
29 Arquitetura Multi-Core AMD Barcelona Nehalem i7 29
30 Many-Core Architectures PROBLEM Chips with tens of cores are emerging. It is necessary to define new interconections, ways to communicate and bind threads. MOTIVATION Usage of MANY-CORE architectures. Gains using tens of cores and adoption of NoC (Network-on-Chip). NOWADAYS 30

31 Evolution of Multi-Core = Many Core Pawlowski, Intel

32 Many-Core Architectures Intel Tera-Scale Tera-flops scale. 80 cores VLIW. Each core has a NoC router integrated. L1 Cache integrated. NoC Interconexion. 32
33 Arquiteturas Stream 33
34 Processamento Stream Dado um conjunto de dados, stream, uma série de operações, kernel functions, são aplicadas nos elementos do stream. Na figura verifica-se que os kernels são aplicados aos streams de dados 34
35 Motivação no surgimento de Stream Processors A complexidade do processamento: de midia 3D graphics, Compressão de imagens, e processamento de sinais, Necessita dezenas a centenas de bilhõess de computações por segundo. Para alcançar este nível de computação, surgem os processadores de midia, que empregam arquiteturas special-purpose, projetadas para uma específica aplicação.. 35
36 Processamento Stream Processamento em Stream é adaptado para aplicações com características de. Computação Intensiva a relação entre o número de operações aritméticas em relação ao de operações de E/S é muito grande. Localidade dos dados os dados necessários ao processamento são locais, minimizando a necessidade/ espera por dados externos de acesso mais lento. Paralelismo de dados a mesma função é aplicada aos dados de uma stream sendo processados simultaneamente, sem espera por 36 resultados.
37 What is a Stream Processor? A processor that is optimized to execute a stream program Features include Exploit parallelism TLP with multiple processors DLP with multiple clusters within each processor ILP with multiple ALUs within each cluster Exploit locality with a bandwidth hierarchy Kernel locality within each cluster Producer -consumer locality within each processor 37 Many different possible architectures
38 Stream Processors Act as accelerators Compared to the usual multi-core processors, stream processors have: A higher performance Higher paralellism A better energy efficiency (flop/watt) Example: NVIDIA s CUDA architecture 38
39 Stream Processors Execution model CPU GPU Process Time Kernel 39
40 Stream Processors CUDA s processing hierarchy Logical Physical Thread Scalar Processor 1 Block (0,0) Streaming Multiprocessor 1... SP 1 SP 2 SP 3 SP 4 SP 5 SP 6... SP x Grid (kernel) (0,0) (1,0) (0,1) (1,1) GPU 0 (x,0) (x,1)... SM1 SM2 SM3 SM4 SM5 SM6... SMn 40
41 Stream Processors CUDA s memory hierarchy (older models) SM n SM 2 SM 1 GPU s Memory Local Memory Shared Memory... Local Memory Registers SP 1 SP 2... Threads SP 8 Global Memory Constants Cache Constants Memory Textures Cache Textures Memory 41
42 Stream Processors CUDA s memory hierarchy (newer models) SM n SM 2 SM 1 GPU s Memory Local Memory Shared Memory... Local Memory Registers SP 1 SP 2 L1 Cache L2 Cache... Threads SP x Global Memory Constants Memory Textures Memory 42
43 Experimental Evaluation of GPGPU Processing Laercio Pilla 43
44 Experimental Evaluation Performance comparison Stream Processors x Multi-cores Core 2 Duo Baseline Core 2 Duo + GTX 280 Second Generation GPU, 1 GB memory 2x Nehalem Nehalem + GTX 480 Third Generation GPU, 1 GB memory Xeon + Tesla C1060 Second Generation GPU, 4 GB memory, lower frequency 44
45 Experimental Evaluation NAS Parallel Benchmarks (NPB) Metrics: time and MOPS Baseline: parallel time on Core 2 Duo Use of double precision floating point operations Statistical confidence (minimum of 20 runs) CUDA on the GPUs OpenMP on the CPUs 45
46 Dwarf Mine - Berkeley 13 Dwarfs Classification that organizes algorithm methods according to their behavioral patterns Computations Communications Independent of implementation 46
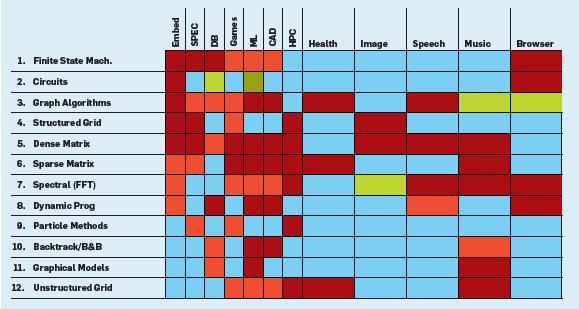
47 Computational Patterns 47
48 Dwarf Mine 1. Dense Linear Algebra 2. Sparse Linear Algebra 3. Spectral Methods 4. N-Body 5. Structured Grids 6. Unstructured Grids 7. MapReduce 8. Combinational Logic 9. Graph Traversal 10. Dynamic Programming 11. Backtrack & Branch+Bound 12. Construct Graphical Models 13. Finite State Machines 48
49 1 Map Reduce Map + Reduce EP benchmark Embarrassingly parallel High arithmetic intensity Regular computations Regular memory access 49
50 1 Map Reduce Map... Reduce... 50
51 bigger 1 Map Reduce Results Newer GPU up to 10x better than 2x Nehalem better 51
52 2 Spectral Methods FFT FT benchmark Low arithmetic intensity Regular computations Different patterns for memory access Data dependencies Communications 52
53 2 Spectral Methods y Step 1 x z y Step 2 x Tim e z y Step 3 x z 53

54 bigger 2 Spectral Methods Results GPUs performance affected by non coalesced memory access better 54
55 3 Sparse Linear Algebra Sparse matrices CG benchmark Low performance Regular computations Irregular memory access Data dependencies 55
56 3 Sparse Linear Algebra... y... x 56

57 bigger 3 Sparse Linear Algebra Results Small speedups, dependencies affect the parallelism better 57
58 Stream Processors Some Experimental Conclusions: Very good for embarrasingly parallel apps For other apps, there is still a lot of work to be done New FFT libraries Use of reduced precision (single/float) Newer GPUs do not bring a better performance automatically 58
59 Architecture and Software Evolution 59
60 Multiple cores / Heterogeneity Multiple cores and customization will be the major drivers for future microprocessor performance (total chip performance). Multiple cores can increase computational throughput (such as a 1x 4x increase could result from four cores), Customization can reduce execution latency. Chip architects must consider more radical options of smaller cores in greater numbers, along with innovative ways to coordinate them, Heterogeneous implementation are an important part of increasing performance 60 Borkar & Chien 2011

61 Multiple cores / Heterogeneity 61 Borkar & Chien 2011


62 Heterogeneity Choices in multiple cores Core size and number of cores, and the related choices in an heterogeneous implementation increase performance. 62 Borkar & Chien 2011

63 GPUs in HPC Top
64 Fusing CPU GPU Fusing CPU and GPU cores reduce data transfer overheads to a great extent AMD Fusion, Intel Knights Ferry, and NVIDIA Tegra are all steps in the right direction. 64

65 Actual Architecture of GPUs Mayank Daga, AshwinM. Aji, and Wu-chunFeng 65

66 Overhead Data Transfer Mayank Daga, AshwinM. Aji, and Wu-chunFeng 66

67 New Architecture for CPUs - GPUs Mayank Daga, AshwinM. Aji, and Wu-chunFeng 67

68 AMD Fusion APU A Fused CPU+GPUThread Mayank Daga, AshwinM. Aji, and Wu-chunFeng 68

69 Nvidia Tegra2 Harmony development board 69 Mehaut

70 Nvidia Tegra 2 70 NVidia

71 Nvidia Tegra 2 71 NVidia

72 Nvidia Tegra 3 72 NVidia
73 Mont Blanc Project based on ARM & GPU 73 Mateo Valero 2011

74 Mont Blanc 200 PF machine on 10 MW 74 Mateo Valero 2011

75 New programming standard OpenACC 75
76 Conclusão 76
77 Conclusões - Melhorias Os seguintes pontos são objetos de gargalos no desempenho de GPGPUs mas que com o avanço da tecnologia podem melhorar: Tamanho da Cache, Tamanho da Memória, Transferência entre CPU e GPU, Precisão dupla (já melhorada), 77
78 Conclusões - Gargalos Os pontos abaixo são gargalos inerentes ao funcionamento das arquiteturas GPGPUs: Aplicação com falta de paralelismo ou Irregularidade no paralelismo, Falta de Dados, a largura de banda pode ser grande mas se os acessos são irregulares não adianta. Falta de reuso dos dados - intensidade aritmética. 78
79 Evolução das Aquiteturas Stream Computing: Desempenho de Algoritmos Dwarf Mine em GPGPU Professor: Philippe O. A. Navaux Doutorando: Laércio Pilla Institute of Informatics - UFRGS OBRIGADO! navaux@inf.ufrgs.br Parallel and Distributed Processing Group
Desafios do Mapeamento de Processos em Arquiteturas Many-Core
 Desafios do Mapeamento de Processos em Arquiteturas Many-Core Professor: Philippe O. A. Navaux Instituto de Informática - UFRGS Escola Regional de Alto Desempenho São Paulo 1 Indíce Evolução dos Processadores
Desafios do Mapeamento de Processos em Arquiteturas Many-Core Professor: Philippe O. A. Navaux Instituto de Informática - UFRGS Escola Regional de Alto Desempenho São Paulo 1 Indíce Evolução dos Processadores
Memory-level and Thread-level Parallelism Aware GPU Architecture Performance Analytical Model
 Memory-level and Thread-level Parallelism Aware GPU Architecture Performance Analytical Model Sunpyo Hong Hyesoon Kim ECE School of Computer Science Georgia Institute of Technology April 6, 2011 Visão
Memory-level and Thread-level Parallelism Aware GPU Architecture Performance Analytical Model Sunpyo Hong Hyesoon Kim ECE School of Computer Science Georgia Institute of Technology April 6, 2011 Visão
Introdução à Programação Paralela através de Padrões. Denise Stringhini Calebe Bianchini Luciano Silva
 Introdução à Programação Paralela através de Padrões Denise Stringhini Calebe Bianchini Luciano Silva Sumário Introdução: conceitos de paralelismo Conceitos básicos sobre padrões de programação paralela
Introdução à Programação Paralela através de Padrões Denise Stringhini Calebe Bianchini Luciano Silva Sumário Introdução: conceitos de paralelismo Conceitos básicos sobre padrões de programação paralela
Arquitetura de Computadores. Processamento Paralelo
 Arquitetura de Computadores Processamento Paralelo 1 Multiprogramação e Multiprocessamento Múltiplas organizações de computadores Single instruction, single data stream - SISD Single instruction, multiple
Arquitetura de Computadores Processamento Paralelo 1 Multiprogramação e Multiprocessamento Múltiplas organizações de computadores Single instruction, single data stream - SISD Single instruction, multiple
Universidade Federal da Bahia Instituto de Matemática Departamento de Ciência da Computação MATA49 Programação de software básico Arquitetura Intel
 Universidade Federal da Bahia Instituto de Matemática Departamento de Ciência da Computação MATA49 Programação de software básico Arquitetura Intel Processadores 8086 Registradores: 16 bits 1978 Data bus:
Universidade Federal da Bahia Instituto de Matemática Departamento de Ciência da Computação MATA49 Programação de software básico Arquitetura Intel Processadores 8086 Registradores: 16 bits 1978 Data bus:
periféricos: interfaces humano-computador (HCI) arquivo de informação comunicações
 arquivo de informação comunicações") Introdução aos Sistemas de Computação (6) Análise de componentes num computador Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3.
Introdução aos Sistemas de Computação (6) Análise de componentes num computador Estrutura do tema ISC 1. Representação de informação num computador 2. Organização e estrutura interna dum computador 3.
5 Unidades de Processamento Gráfico GPUs
 5 Unidades de Processamento Gráfico GPUs As GPUs são processadores maciçamente paralelos, com múltiplos elementos de processamento, tipicamente utilizadas como aceleradores de computação. Elas fornecem
5 Unidades de Processamento Gráfico GPUs As GPUs são processadores maciçamente paralelos, com múltiplos elementos de processamento, tipicamente utilizadas como aceleradores de computação. Elas fornecem
Arquiteturas paralelas Parte 1
 Arquiteturas paralelas Parte 1 Processamento Paralelo Prof. Oberlan Romão Departamento de Computação e Eletrônica DCEL Centro Universitário Norte do Espírito Santo CEUNES Universidade Federal do Espírito
Arquiteturas paralelas Parte 1 Processamento Paralelo Prof. Oberlan Romão Departamento de Computação e Eletrônica DCEL Centro Universitário Norte do Espírito Santo CEUNES Universidade Federal do Espírito
COMPUTAÇÃO PARALELA COM ACELERADORES GPGPU 1. Emilio Hoffmann De Oliveira 2, Edson Luiz Padoin 3.
 COMPUTAÇÃO PARALELA COM ACELERADORES GPGPU 1 Emilio Hoffmann De Oliveira 2, Edson Luiz Padoin 3. 1 Trabalho de Conclusão de Curso 2 Aluno do Curso de Ciência da Computação - emiliohoffmann@hotmail.com
COMPUTAÇÃO PARALELA COM ACELERADORES GPGPU 1 Emilio Hoffmann De Oliveira 2, Edson Luiz Padoin 3. 1 Trabalho de Conclusão de Curso 2 Aluno do Curso de Ciência da Computação - emiliohoffmann@hotmail.com
Sparse Matrix-Vector Multiplication on GPU: When Is Rows Reordering Worthwhile?
 Sparse Matrix-Vector Multiplication on GPU: When Is Rows Reordering Worthwhile? Paula Prata João Muranho Instituto de Telecomunicações Departamento de Informática Universidade da Beira Interior Instituto
Sparse Matrix-Vector Multiplication on GPU: When Is Rows Reordering Worthwhile? Paula Prata João Muranho Instituto de Telecomunicações Departamento de Informática Universidade da Beira Interior Instituto
Celso L. Mendes LAC /INPE
 Arquiteturas para Processamento de Alto Desempenho (PAD) Aula 9 Celso L. Mendes LAC /INPE Email: celso.mendes@inpe.br Aula 9 (3/5): E. Aceleradores Estrutura Planejada i. Estruturas mais Populares ii.
Arquiteturas para Processamento de Alto Desempenho (PAD) Aula 9 Celso L. Mendes LAC /INPE Email: celso.mendes@inpe.br Aula 9 (3/5): E. Aceleradores Estrutura Planejada i. Estruturas mais Populares ii.
Paradigmas de Computação
 UCE- Computação Paralela e Distribuída Paradigmas de Computação João Luís Ferreira Sobral www.di.uminho.pt/~jls jls@... http://alba.di.uminho.pt/... 1 Paradigmas de Computação paralela Resultados da Aprendizagem
UCE- Computação Paralela e Distribuída Paradigmas de Computação João Luís Ferreira Sobral www.di.uminho.pt/~jls jls@... http://alba.di.uminho.pt/... 1 Paradigmas de Computação paralela Resultados da Aprendizagem
SSC510 Arquitetura de Computadores. 6ª aula
 SSC510 Arquitetura de Computadores 6ª aula PARALELISMO EM NÍVEL DE PROCESSOS PROFA. SARITA MAZZINI BRUSCHI Tipos de Paralelismo Instrução (granulosidade fina) Paralelismo entre as instruções Arquiteturas
SSC510 Arquitetura de Computadores 6ª aula PARALELISMO EM NÍVEL DE PROCESSOS PROFA. SARITA MAZZINI BRUSCHI Tipos de Paralelismo Instrução (granulosidade fina) Paralelismo entre as instruções Arquiteturas
Suporte à Execução Eficiente de Aplicações em Plataformas com Paralelismo Multi-Nível
 Suporte à Execução Eficiente de Aplicações em Plataformas com Paralelismo Multi-Nível Vinícius Garcia Pinto Lucas Mello Schnorr Nicolas Maillard Grupo de Processamento Paralelo e Distribuído (GPPD) Instituto
Suporte à Execução Eficiente de Aplicações em Plataformas com Paralelismo Multi-Nível Vinícius Garcia Pinto Lucas Mello Schnorr Nicolas Maillard Grupo de Processamento Paralelo e Distribuído (GPPD) Instituto
Transparent application acceleration by intelligent scheduling of shared library calls on heterogeneous systems September 9, 2013
 Transparent application acceleration by intelligent scheduling of shared library calls on heterogeneous systems João Colaço, Adrian Matoga, Aleksandar Ilic, Nuno Roma, Pedro Tomás, Ricardo Chaves adrian.matoga@inesc-id.pt
Transparent application acceleration by intelligent scheduling of shared library calls on heterogeneous systems João Colaço, Adrian Matoga, Aleksandar Ilic, Nuno Roma, Pedro Tomás, Ricardo Chaves adrian.matoga@inesc-id.pt
Disciplina de Arquitetura de Computadores
 USP - ICMC - SSC SSC 0510 - Informática - 2o. Semestre 2009 Disciplina de Prof. Fernando Santos Osório Email: fosorio [at] { icmc. usp. br, gmail. com } Página Pessoal: http://www.icmc.usp.br/~fosorio/
USP - ICMC - SSC SSC 0510 - Informática - 2o. Semestre 2009 Disciplina de Prof. Fernando Santos Osório Email: fosorio [at] { icmc. usp. br, gmail. com } Página Pessoal: http://www.icmc.usp.br/~fosorio/
Multiprogramação leve em arquiteturas multi-core
 Multiprogramação leve em arquiteturas multi-core Prof. Dr. Departamento de Informática Universidade Federal de Pelotas Sumário Arquiteturas multi-core Programação multithread Ferramentas de programação
Multiprogramação leve em arquiteturas multi-core Prof. Dr. Departamento de Informática Universidade Federal de Pelotas Sumário Arquiteturas multi-core Programação multithread Ferramentas de programação
Eng. Thársis T. P. Souza
 Introdução à Computação de Alto Desempenho Utilizando GPU Seminário de Programação em GPGPU Eng. Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo Introdução
Introdução à Computação de Alto Desempenho Utilizando GPU Seminário de Programação em GPGPU Eng. Thársis T. P. Souza t.souza@usp.br Instituto de Matemática e Estatística - Universidade de São Paulo Introdução
Infraestrutura de Hardware. Processamento Paralelo Multicores, Multi-Threading e GPUs
 Infraestrutura de Hardware Processamento Paralelo Multicores, Multi-Threading e GPUs Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é entendido
Infraestrutura de Hardware Processamento Paralelo Multicores, Multi-Threading e GPUs Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem de alto nível é entendido
Programação Paralela e Distribuída
 Programação Paralela e Distribuída Referência: Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd Edition, by B. Wilkinson & M. Allen, 2004
Programação Paralela e Distribuída Referência: Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd Edition, by B. Wilkinson & M. Allen, 2004
Processadores para computação de alto desempenho
 Processadores para computação de alto desempenho Aleardo Manacero Jr. DCCE/UNESP Grupo de Sistemas Paralelos e Distribuídos Introdução Nesta aula apresentaremos características de processadores e como
Processadores para computação de alto desempenho Aleardo Manacero Jr. DCCE/UNESP Grupo de Sistemas Paralelos e Distribuídos Introdução Nesta aula apresentaremos características de processadores e como
Análise de Desempenho da Arquitetura CUDA Utilizando os NAS Parallel Benchmarks
 UNIVERSIDADE FEDERAL DO RIO GRANDE DO SUL INSTITUTO DE INFORMÁTICA CURSO DE BACHARELADO EM CIÊNCIA DA COMPUTAÇÃO LAÉRCIO LIMA PILLA Análise de Desempenho da Arquitetura CUDA Utilizando os NAS Parallel
UNIVERSIDADE FEDERAL DO RIO GRANDE DO SUL INSTITUTO DE INFORMÁTICA CURSO DE BACHARELADO EM CIÊNCIA DA COMPUTAÇÃO LAÉRCIO LIMA PILLA Análise de Desempenho da Arquitetura CUDA Utilizando os NAS Parallel
Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot
 Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Tomás Evalero Orellana Universidade Estadual de Santa Cruz Roteiro Breve introdução
Técnicas de Processamento Paralelo na Geração do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Tomás Evalero Orellana Universidade Estadual de Santa Cruz Roteiro Breve introdução
Comparação de eficiência entre OpenCL e CUDA
 Aluno: Thiago de Gouveia Nunes Orientador: Prof. Marcel P. Jackowski GPGPU O que é GPGPU? É programação de propósito geral em GPUs. =D GPGPU Existem 2 linguagens populares no mercado para GPGPU, o CUDA
Aluno: Thiago de Gouveia Nunes Orientador: Prof. Marcel P. Jackowski GPGPU O que é GPGPU? É programação de propósito geral em GPUs. =D GPGPU Existem 2 linguagens populares no mercado para GPGPU, o CUDA
CHPC Computational Platforms
 CHPC Computational Platforms Dorah Thobye Acting Technical Manager Slide 1 OUTLINE CHPC HPC PLATFORMS IBM IBM E1350 LINUX CLUSTER BLUE GENE/P CHALLENGES MACHINE USAGE STATS SUN MICROSYSTEMS SUN Fusion
CHPC Computational Platforms Dorah Thobye Acting Technical Manager Slide 1 OUTLINE CHPC HPC PLATFORMS IBM IBM E1350 LINUX CLUSTER BLUE GENE/P CHALLENGES MACHINE USAGE STATS SUN MICROSYSTEMS SUN Fusion
Arquiteturas de Computadores
 Arquiteturas de Computadores Computadores vetoriais Fontes dos slides: Livro Patterson e Hennessy, Quantitative Approach e site do curso EE 7722, GPU Microarchitecture do Prof. David Koppelman Graphical
Arquiteturas de Computadores Computadores vetoriais Fontes dos slides: Livro Patterson e Hennessy, Quantitative Approach e site do curso EE 7722, GPU Microarchitecture do Prof. David Koppelman Graphical
Parallel Computing Paradigms
 João Luís Ferreira Sobral www.di.uminho.pt/~jls jls@... Web: Elearning 1 At the end of the course, students should be able to: Design and optimise parallel applications that can efficiently run on a wide
João Luís Ferreira Sobral www.di.uminho.pt/~jls jls@... Web: Elearning 1 At the end of the course, students should be able to: Design and optimise parallel applications that can efficiently run on a wide
Bacharelado em Sistemas de Informação Sistemas Operacionais. Prof. Filipo Mór
 Bacharelado em Sistemas de Informação Sistemas Operacionais Prof. Filipo Mór WWW.FILIPOMOR.COM - REVISÃO ARQUITETURAS PARALELAS Evolução das Arquiteturas Evolução das Arquiteturas Entrada CPU Saída von
Bacharelado em Sistemas de Informação Sistemas Operacionais Prof. Filipo Mór WWW.FILIPOMOR.COM - REVISÃO ARQUITETURAS PARALELAS Evolução das Arquiteturas Evolução das Arquiteturas Entrada CPU Saída von
SSC0510 Arquitetura de Computadores
 SSC0510 Arquitetura de Computadores 11ª Aula Paralelismo Avançado em Nível de Instrução e em Nível de Tarefas (Threads) Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Tipos de Paralelismo BLP: Bit Level
SSC0510 Arquitetura de Computadores 11ª Aula Paralelismo Avançado em Nível de Instrução e em Nível de Tarefas (Threads) Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Tipos de Paralelismo BLP: Bit Level
Processadores para computação de alto desempenho
 Processadores para computação de alto desempenho Aleardo Manacero Jr. DCCE/UNESP Grupo de Sistemas Paralelos e Distribuídos Introdução Nesta aula apresentaremos características de processadores e como
Processadores para computação de alto desempenho Aleardo Manacero Jr. DCCE/UNESP Grupo de Sistemas Paralelos e Distribuídos Introdução Nesta aula apresentaremos características de processadores e como
SSC0611 Arquitetura de Computadores
 SSC0611 Arquitetura de Computadores 17ª Aula Paralelismos nível de tarefas Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Paralelismo no nível de tarefas Paralelismo a nível de thread (TLP Thread-Level
SSC0611 Arquitetura de Computadores 17ª Aula Paralelismos nível de tarefas Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Paralelismo no nível de tarefas Paralelismo a nível de thread (TLP Thread-Level
Otimizando o uso do Subsistema de Memória de GPUs para Aplicações Baseadas em Estênceis
 Otimizando o uso do Subsistema de Memória de GPUs para Aplicações Baseadas em Estênceis Ricardo K. Lorenzoni, Matheus S. Serpa, Edson L. Padoin,, Jairo Panetta Philippe O. A. Navaux, Jean-François Méhaut
Otimizando o uso do Subsistema de Memória de GPUs para Aplicações Baseadas em Estênceis Ricardo K. Lorenzoni, Matheus S. Serpa, Edson L. Padoin,, Jairo Panetta Philippe O. A. Navaux, Jean-François Méhaut
Otimização do desempenho (no h/w) Objetivo
 Objetivo") Avaliação de Desempenho no IA-32 (3) Eficiência em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação
Avaliação de Desempenho no IA-32 (3) Eficiência em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação
Avaliação de Desempenho. September 28, 2010
 September 28, 2010 O que é desempenho? em primeiro lugar, uma ótima tradução para performance... :-) tempo de execução (o centro das atenções!) outras: projeto, ciclo de vida, manutenção,... mesmo outras
September 28, 2010 O que é desempenho? em primeiro lugar, uma ótima tradução para performance... :-) tempo de execução (o centro das atenções!) outras: projeto, ciclo de vida, manutenção,... mesmo outras
Broadband Engine Cell Processor. Arquitetura e Organização de Processadores (CPM237) Rodrigo Bittencourt Motta
 Rodrigo Bittencourt Motta") Broadband Engine Cell Processor Arquitetura e Organização de Processadores (CPM237) Rodrigo Bittencourt Motta rbmotta@inf.ufrgs.br Junho/06 Plano de Apresentação Introdução Visão Geral Organização Interna
Broadband Engine Cell Processor Arquitetura e Organização de Processadores (CPM237) Rodrigo Bittencourt Motta rbmotta@inf.ufrgs.br Junho/06 Plano de Apresentação Introdução Visão Geral Organização Interna
Atol Fortin, Bruno da Hora, Lucas Piva, Marcela Ortega, Natan Lima, Pedro Raphael, Ricardo Sider, Rogério Papetti. 28 de novembro de 2008
 Reinventando a Computação Atol Fortin, Bruno da Hora, Lucas Piva, Marcela Ortega, Natan Lima, Pedro Raphael, Ricardo Sider, Rogério Papetti Universidade de São Paulo 28 de novembro de 2008 Introdução Dr.
Reinventando a Computação Atol Fortin, Bruno da Hora, Lucas Piva, Marcela Ortega, Natan Lima, Pedro Raphael, Ricardo Sider, Rogério Papetti Universidade de São Paulo 28 de novembro de 2008 Introdução Dr.
Estrutura do tema Avaliação de Desempenho (IA-32)
") Avaliação de Desempenho no IA-32 (3) Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação 2. Técnicas de otimização de código (IM) 3. Técnicas de otimização de hardware
Avaliação de Desempenho no IA-32 (3) Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação 2. Técnicas de otimização de código (IM) 3. Técnicas de otimização de hardware
Introdução à Computação: Sistemas de Computação
 Introdução à Computação: Sistemas de Computação Beatriz F. M. Souza (bfmartins@inf.ufes.br) http://inf.ufes.br/~bfmartins/ Computer Science Department Federal University of Espírito Santo (Ufes), Vitória,
Introdução à Computação: Sistemas de Computação Beatriz F. M. Souza (bfmartins@inf.ufes.br) http://inf.ufes.br/~bfmartins/ Computer Science Department Federal University of Espírito Santo (Ufes), Vitória,
Paralelização de Algoritmos de CFD em Clusters Multi-Core MC7. Escola de Verão Arquiteturas Multi-Core
 RSS-Verão-01/08 p.1/36 Paralelização de Algoritmos de CFD em Clusters Multi-Core MC7 Escola de Verão 2008 Arquiteturas Multi-Core Renato S. Silva LNCC - MCT Janeiro de 2008 RSS-Verão-01/08 p.2/36 Objetivo:
RSS-Verão-01/08 p.1/36 Paralelização de Algoritmos de CFD em Clusters Multi-Core MC7 Escola de Verão 2008 Arquiteturas Multi-Core Renato S. Silva LNCC - MCT Janeiro de 2008 RSS-Verão-01/08 p.2/36 Objetivo:
Otimização do desempenho (no h/w) Objectivo
 Objectivo") Avaliação de Desempenho no IA-32 (3) Eficiência em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação
Avaliação de Desempenho no IA-32 (3) Eficiência em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas de computação
Carlos Eduardo Batista Centro de Informática - UFPB
 Carlos Eduardo Batista Centro de Informática - UFPB bidu@ci.ufpb.br Motivação Arquitetura de computadores modernos Desafios da programação concorrente Definição de concorrência Correr junto Disputa por
Carlos Eduardo Batista Centro de Informática - UFPB bidu@ci.ufpb.br Motivação Arquitetura de computadores modernos Desafios da programação concorrente Definição de concorrência Correr junto Disputa por
Organização de Computadores
 Capítulo 2-B Organização de Computadores Orlando Loques setembro 2006 Referências: principal: Capítulo 2, Structured Computer Organization, A.S. Tanenbaum, (c) 2006 Pearson Education Inc Computer Organization
Capítulo 2-B Organização de Computadores Orlando Loques setembro 2006 Referências: principal: Capítulo 2, Structured Computer Organization, A.S. Tanenbaum, (c) 2006 Pearson Education Inc Computer Organization
Collaborative Execution Environment for Heterogeneous Parallel Systems CHPS*
 Collaborative Execution Environment for Heterogeneous Parallel Systems CHPS* Aleksandar Ilić and Leonel Sousa *In 12th Workshop on Advances in Parallel and Distributed Computational Models (APDCM/IPDPS
Collaborative Execution Environment for Heterogeneous Parallel Systems CHPS* Aleksandar Ilić and Leonel Sousa *In 12th Workshop on Advances in Parallel and Distributed Computational Models (APDCM/IPDPS
Análise de desempenho e eficiência energética de aceleradores NVIDIA Kepler
 Análise de desempenho e eficiência energética de aceleradores NVIDIA Kepler Emilio Hoffmann, Bruno M. Muenchen, Taís T. Siqueira, Edson L. Padoin e Philippe O. A. Navaux Universidade Regional do Noroeste
Análise de desempenho e eficiência energética de aceleradores NVIDIA Kepler Emilio Hoffmann, Bruno M. Muenchen, Taís T. Siqueira, Edson L. Padoin e Philippe O. A. Navaux Universidade Regional do Noroeste
PROCESSADORES Unidade de Controle Unidade Aritmética e Lógica efetua memória de alta velocidade registradores Program Counter Instruction Register
 PROCESSADORES Um computador digital consiste em um sistema interconectado de processadores, memória e dispositivos de entrada e saída. A CPU é o cérebro do computador. Sua função é executar programas armazenados
PROCESSADORES Um computador digital consiste em um sistema interconectado de processadores, memória e dispositivos de entrada e saída. A CPU é o cérebro do computador. Sua função é executar programas armazenados
Otimização do desempenho (no h/w) Objectivo. Problemas: Estrutura do tema Avaliação de Desempenho (IA-32)
 Objectivo. Problemas: Estrutura do tema Avaliação de Desempenho (IA-32)") Avaliação de Desempenho no IA-32 (3) Análise do desempenho em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas
Avaliação de Desempenho no IA-32 (3) Análise do desempenho em Sistemas de Computação: oportunidades para otimizar na arquitetura Estrutura do tema Avaliação de Desempenho (IA-32) 1. A avaliação de sistemas
speedup aprimorado aprimorado Fração aprimorada speedup aprimorado Fração aprimorada speedup aprimorado Tempo original Fração aprimorada aprimorado
 Multiprocessadores - A evolução tecnológica dos processadores iria diminuir drasticamente. 2- O caminho para o aumento de desempenho é de unir mais de um processador para realizar a mesma tarefa em menos
Multiprocessadores - A evolução tecnológica dos processadores iria diminuir drasticamente. 2- O caminho para o aumento de desempenho é de unir mais de um processador para realizar a mesma tarefa em menos
Multiprocessamento. Patterson & Hennessy Capítulo 9. Arquitetura e Organização de Computadores Juliano M. Vieira (c) 2011
 2011") Multiprocessamento Patterson & Hennessy Capítulo 9 Arquitetura e Organização de Computadores Juliano M. Vieira (c) 2011 Tópicos Abordados Tipos comuns SMP (processamento paralelo) NUMA (placas de alto
Multiprocessamento Patterson & Hennessy Capítulo 9 Arquitetura e Organização de Computadores Juliano M. Vieira (c) 2011 Tópicos Abordados Tipos comuns SMP (processamento paralelo) NUMA (placas de alto
ARQUITETURA DE COMPUTADORES
 RCM00014 Haswell wafer ARQUITETURA DE COMPUTADORES Prof. Luciano Bertini Site: http://www.professores.uff.br/lbertini/ Objetivos do Curso Entendimento mais aprofundado do funcionamento
RCM00014 Haswell wafer ARQUITETURA DE COMPUTADORES Prof. Luciano Bertini Site: http://www.professores.uff.br/lbertini/ Objetivos do Curso Entendimento mais aprofundado do funcionamento
Sistemas Distribuídos
 Sistemas Distribuídos Classificação de Flynn Fonte: Professoras. Sarita UFRJ e Thais V. Batista - UFRN Arquiteturas Paralelas Computação Paralela Conceitos Permite a execução das tarefas em menor tempo,
Sistemas Distribuídos Classificação de Flynn Fonte: Professoras. Sarita UFRJ e Thais V. Batista - UFRN Arquiteturas Paralelas Computação Paralela Conceitos Permite a execução das tarefas em menor tempo,
Sistemas MIMD. CES-25 Arquiteturas para Alto Desmpenho. Paulo André Castro
 Sistemas MIMD Arquiteturas para Alto Desmpenho Prof. pauloac@ita.br Sala 110 Prédio da Computação www.comp.ita.br/~pauloac Arquiteturas Paralelas (SISD) Single Instruction Stream, Single Data Stream: Monoprocessador
Sistemas MIMD Arquiteturas para Alto Desmpenho Prof. pauloac@ita.br Sala 110 Prédio da Computação www.comp.ita.br/~pauloac Arquiteturas Paralelas (SISD) Single Instruction Stream, Single Data Stream: Monoprocessador
Faculdade de Computação 3 a Prova de Arquitetura e Organização de Computadores 2 Parte I Prof. Cláudio C. Rodrigues
 Faculdade de Computação 3 a Prova de Parte I Prof. Cláudio C. Rodrigues Nome: Matrícula: Valor: 15 Nome: Matrícula: Valor: 15 Nome: Matrícula: Valor: 15 Nome: Matrícula: Valor: 15 Problemas: P1. Qual o
Faculdade de Computação 3 a Prova de Parte I Prof. Cláudio C. Rodrigues Nome: Matrícula: Valor: 15 Nome: Matrícula: Valor: 15 Nome: Matrícula: Valor: 15 Nome: Matrícula: Valor: 15 Problemas: P1. Qual o
Processadores para computação de alto desempenho
 Processadores para computação de alto desempenho Aleardo Manacero Jr. DCCE/UNESP Grupo de Sistemas Paralelos e Distribuídos Introdução Nesta aula apresentaremos características de processadores e como
Processadores para computação de alto desempenho Aleardo Manacero Jr. DCCE/UNESP Grupo de Sistemas Paralelos e Distribuídos Introdução Nesta aula apresentaremos características de processadores e como
Máquinas mais rápidas do mundo
 Máquinas mais rápidas do mundo Jorge Melegati Instituto de Matemática e Estatística Introdução à Computação Paralela e Distribuída melegati@ime.usp.br Junho de 2015 Jorge Melegati (IME) Máquinas mais rápidas
Máquinas mais rápidas do mundo Jorge Melegati Instituto de Matemática e Estatística Introdução à Computação Paralela e Distribuída melegati@ime.usp.br Junho de 2015 Jorge Melegati (IME) Máquinas mais rápidas
PROPOSTA DE UMA ESTRATÉGIA DE PROGRAMAÇÃO EXPLÍCITA COM ANOTAÇÃO EM CÓDIGO EM BUSCA DE EFICIÊNCIA ENERGÉTICA 1
 PROPOSTA DE UMA ESTRATÉGIA DE PROGRAMAÇÃO EXPLÍCITA COM ANOTAÇÃO EM CÓDIGO EM BUSCA DE EFICIÊNCIA ENERGÉTICA 1 Bruno Mokan Muenchen 2, João Vicente Ferreira Lima 3. 1 Projeto de pesquisa realizado pelo
PROPOSTA DE UMA ESTRATÉGIA DE PROGRAMAÇÃO EXPLÍCITA COM ANOTAÇÃO EM CÓDIGO EM BUSCA DE EFICIÊNCIA ENERGÉTICA 1 Bruno Mokan Muenchen 2, João Vicente Ferreira Lima 3. 1 Projeto de pesquisa realizado pelo
Multiprocessadores e Paralelismo nível de Thread
 Multiprocessadores e Paralelismo nível de Thread Roteiro da Aula Conceitos básicos Paralelismo de Thread Taxonomia dos processadores Modelos de memória e de comunicação Problema da coerência de memória
Multiprocessadores e Paralelismo nível de Thread Roteiro da Aula Conceitos básicos Paralelismo de Thread Taxonomia dos processadores Modelos de memória e de comunicação Problema da coerência de memória
gssjoin: a GPU-based Set Similarity Join Algorithm
 gssjoin: a GPU-based Set Similarity Join www.inf.ufg.br 1 / 35 Agenda 1 2 3 4 5 6 2 / 35 Set similarity join returns all pairs of similar sets from a dataset. Sets are considered similar if the value returned
gssjoin: a GPU-based Set Similarity Join www.inf.ufg.br 1 / 35 Agenda 1 2 3 4 5 6 2 / 35 Set similarity join returns all pairs of similar sets from a dataset. Sets are considered similar if the value returned
Taxonomia de Flynn. Procura classificar todas as arquitecturas de computadores com base no processamento das instruções e dos dado.
 Multi-processamento Taxonomia de Flynn Arquitecturas SIMD Instruções vectoriais Arquitecturas MIMD Tipos de arquitectura MIMD Memória partilhada Multi-cores Taxonomia de Flynn Procura classificar todas
Multi-processamento Taxonomia de Flynn Arquitecturas SIMD Instruções vectoriais Arquitecturas MIMD Tipos de arquitectura MIMD Memória partilhada Multi-cores Taxonomia de Flynn Procura classificar todas
ARQUITETURA DE COMPUTADORES
 RCM00014 Haswell wafer ARQUITETURA DE COMPUTADORES Prof. Luciano Bertini Site: http://www.professores.uff.br/lbertini/ Objetivos do Curso Entendimento mais aprofundado do funcionamento
RCM00014 Haswell wafer ARQUITETURA DE COMPUTADORES Prof. Luciano Bertini Site: http://www.professores.uff.br/lbertini/ Objetivos do Curso Entendimento mais aprofundado do funcionamento
Introdução. Arquitetura e Organização de Computadores I. Programa. Arquitetura e Organização de. Computadores. Capítulo 1.
 Arquitetura e Organização de Computadores I Prof. Cláudio C. Rodrigues Arquitetura e Organização de Computadores I Objetivo: Entender a regra dos componentes de um sistema computador e como eles trabalham
Arquitetura e Organização de Computadores I Prof. Cláudio C. Rodrigues Arquitetura e Organização de Computadores I Objetivo: Entender a regra dos componentes de um sistema computador e como eles trabalham
Ambientes e Ferramentas de Programação para GPU. Denise Stringhini (Mackenzie) Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP)
 Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP)") Ambientes e Ferramentas de Programação para GPU Denise Stringhini (Mackenzie) Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP) Conteúdo Conceitos de paralelismo Arquitetura de GPU CUDA OpenCL
Ambientes e Ferramentas de Programação para GPU Denise Stringhini (Mackenzie) Rogério Gonçalves (UFTPR/IME- USP) Alfredo Goldman (IME- USP) Conteúdo Conceitos de paralelismo Arquitetura de GPU CUDA OpenCL
Processamento de áudio em tempo real utilizando dispositivos não convencionais:
 Processamento de áudio em tempo real utilizando dispositivos não convencionais: Processamento paralelo com Pure Data e GPU. André Jucovsky Bianchi ajb@ime.usp.br Departamento de Ciência da Computação Instituto
Processamento de áudio em tempo real utilizando dispositivos não convencionais: Processamento paralelo com Pure Data e GPU. André Jucovsky Bianchi ajb@ime.usp.br Departamento de Ciência da Computação Instituto
Processamento Paralelo Utilizando GPU
 Processamento Paralelo Utilizando GPU Universidade Estadual de Santa Cruz Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Evalero Orellana Cronograma Breve introdução sobre processamento paralelo
Processamento Paralelo Utilizando GPU Universidade Estadual de Santa Cruz Bruno Pereira dos Santos Dany Sanchez Dominguez Esbel Evalero Orellana Cronograma Breve introdução sobre processamento paralelo
Paralelismo de dados. (execução de simultaneidade) Tipo de arquitetura paralela SIMD. SIMD (Single Instruction Multiple Data)
 Tipo de arquitetura paralela SIMD. SIMD (Single Instruction Multiple Data)") Paralelismo de dados (execução de simultaneidade) Em métodos tradicionais de programação (processamento sequencial), uma grande quantidade de dados é processada em um único núcleo de uma CPU, enquanto
Paralelismo de dados (execução de simultaneidade) Em métodos tradicionais de programação (processamento sequencial), uma grande quantidade de dados é processada em um único núcleo de uma CPU, enquanto
Paralelismo de dados. (execução de simultaneidade) Tipo de arquitetura paralela SIMD. SIMD (Single Instruction Multiple Data)
 Tipo de arquitetura paralela SIMD. SIMD (Single Instruction Multiple Data)") Paralelismo de dados (execução de simultaneidade) Em métodos tradicionais de programação (processamento sequencial), uma grande quantidade de dados é processada em um único núcleo de uma CPU, enquanto
Paralelismo de dados (execução de simultaneidade) Em métodos tradicionais de programação (processamento sequencial), uma grande quantidade de dados é processada em um único núcleo de uma CPU, enquanto
Escalonamento Através de Perfilamento em Sistemas Multi-core. Emilio de Camargo Francesquini
 Escalonamento Através de Perfilamento em Sistemas Multi-core Emilio de Camargo Francesquini emilio@ime.usp.br Dezembro de 2009 Cenário Atual Eterno crescimento da necessidade de poder de processamento
Escalonamento Através de Perfilamento em Sistemas Multi-core Emilio de Camargo Francesquini emilio@ime.usp.br Dezembro de 2009 Cenário Atual Eterno crescimento da necessidade de poder de processamento
The future is parallel but it may not be easy
 The future is parallel but it may not be easy Adriano Tabarelli, Alex Morinaga, Caio Silva, Cássia Ferreira, Daniel Santos, Eduardo Apolinário, Hugo Posca, Thiago Batista, Paulo Floriano Universidade de
The future is parallel but it may not be easy Adriano Tabarelli, Alex Morinaga, Caio Silva, Cássia Ferreira, Daniel Santos, Eduardo Apolinário, Hugo Posca, Thiago Batista, Paulo Floriano Universidade de
Paralelização Eficiente para o Algoritmo Binário de Exponenciação Modular
 Paralelização Eficiente para o Algoritmo Binário de Exponenciação Modular Pedro Carlos da Silva Lara Fábio Borges de Oliveira Renato Portugal Laboratório Nacional de Computação Científica Índice 1 Introdução
Paralelização Eficiente para o Algoritmo Binário de Exponenciação Modular Pedro Carlos da Silva Lara Fábio Borges de Oliveira Renato Portugal Laboratório Nacional de Computação Científica Índice 1 Introdução
Introdução a CUDA. Esteban Walter Gonzalez Clua. Medialab - Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center START
 Introdução a CUDA START Esteban Walter Gonzalez Clua Medialab - Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center 1536 cores Dynamic Parallelism Hyper - Q Pipeline
Introdução a CUDA START Esteban Walter Gonzalez Clua Medialab - Instituto de Computação Universidade Federal Fluminense NVIDIA CUDA Research Center 1536 cores Dynamic Parallelism Hyper - Q Pipeline
Paralelização do Detector de Bordas Canny para a Biblioteca ITK usando CUDA
 Paralelização do Detector de Bordas Canny para a Biblioteca ITK usando CUDA Luis Henrique Alves Lourenço Grupo de Visão, Robótica e Imagens Universidade Federal do Paraná 7 de abril de 2011 Sumário 1 Introdução
Paralelização do Detector de Bordas Canny para a Biblioteca ITK usando CUDA Luis Henrique Alves Lourenço Grupo de Visão, Robótica e Imagens Universidade Federal do Paraná 7 de abril de 2011 Sumário 1 Introdução
30/5/2011. Sistemas computacionais para processamento paralelo e distribuído
 Arquitetura de Computadores Sistemas computacionais para processamento paralelo e distribuído Prof. Marcos Quinet Universidade Federal Fluminense UFF Pólo Universitário de Rio das Ostras - PURO Processamento
Arquitetura de Computadores Sistemas computacionais para processamento paralelo e distribuído Prof. Marcos Quinet Universidade Federal Fluminense UFF Pólo Universitário de Rio das Ostras - PURO Processamento
Arquitetura e Organização de Processadores. Aula 1. Introdução Arquitetura e Organização
 Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 1 Introdução Arquitetura e Organização 1. Arquitetura
Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 1 Introdução Arquitetura e Organização 1. Arquitetura
Ambientes de computação de alto desempenho no LNCC
 Ambientes de computação de alto desempenho no LNCC Roberto Pinto Souto MCTI/LNCC/CSR - CENAPAD-RJ rpsouto@lncc.br 24 de Março de 2014 (Seminário da Pós-graduaçao) 24 de Março de 2014 1 / 78 Roteiro 1 Introdução
Ambientes de computação de alto desempenho no LNCC Roberto Pinto Souto MCTI/LNCC/CSR - CENAPAD-RJ rpsouto@lncc.br 24 de Março de 2014 (Seminário da Pós-graduaçao) 24 de Março de 2014 1 / 78 Roteiro 1 Introdução
Universidade Federal do Rio de Janeiro Pós-Graduação em Informática. Introdução. Gabriel P. Silva. Gabriel P. Silva
 Universidade Federal do Rio de Janeiro Pós-Graduação em Informática Microarquiteturas de Alto Desempenho Introdução Introdução Bibliografia: Computer Architecture: A Quantitative Approach. John L. Hennesy,
Universidade Federal do Rio de Janeiro Pós-Graduação em Informática Microarquiteturas de Alto Desempenho Introdução Introdução Bibliografia: Computer Architecture: A Quantitative Approach. John L. Hennesy,
1.1 Descrição do problema A programação genética (PG) é uma meta-heurística utilizada para gerar programas de computadores, de modo que o computador
 é uma meta-heurística utilizada para gerar programas de computadores, de modo que o computador") 1 Introdução 1.1 Descrição do problema A programação genética (PG) é uma meta-heurística utilizada para gerar programas de computadores, de modo que o computador possa resolver problemas de forma automática
1 Introdução 1.1 Descrição do problema A programação genética (PG) é uma meta-heurística utilizada para gerar programas de computadores, de modo que o computador possa resolver problemas de forma automática
INTRODUÇÃO À TECNOLOGIA DA INFORMAÇÃO ORGANIZAÇÃO COMPUTACIONAL
 INTRODUÇÃO À TECNOLOGIA DA ORGANIZAÇÃO COMPUTACIONAL PROFESSOR CARLOS MUNIZ ORGANIZAÇÃO DE UM COMPUTADOR TÍPICO Memória: Armazena dados e programas Processador (CPU - Central Processing Unit): Executa
INTRODUÇÃO À TECNOLOGIA DA ORGANIZAÇÃO COMPUTACIONAL PROFESSOR CARLOS MUNIZ ORGANIZAÇÃO DE UM COMPUTADOR TÍPICO Memória: Armazena dados e programas Processador (CPU - Central Processing Unit): Executa
Introdução. Edna Barros
 Arquitetura de Computadores Introdução Edna Barros Objetivos do curso Entender a operação dos microprocessadores modernos à nível arquitetural. Entender a operação dos subsistemas de memória e de E/S e
Arquitetura de Computadores Introdução Edna Barros Objetivos do curso Entender a operação dos microprocessadores modernos à nível arquitetural. Entender a operação dos subsistemas de memória e de E/S e
Aula 21 Ordenação externa
 MC3305 Algoritmos e Estruturas de Dados II Aula 21 Ordenação externa Slides adaptados de Brian Cooper (Yahoo Research) Prof. Jesús P. Mena-Chalco jesus.mena@ufabc.edu.br 2Q-2015 1 Números de Ackermann
MC3305 Algoritmos e Estruturas de Dados II Aula 21 Ordenação externa Slides adaptados de Brian Cooper (Yahoo Research) Prof. Jesús P. Mena-Chalco jesus.mena@ufabc.edu.br 2Q-2015 1 Números de Ackermann
Microprocessadores. Família x86 - Evolução
 Família x86 - Evolução António M. Gonçalves Pinheiro Departamento de Física Covilhã - Portugal pinheiro@ubi.pt i8086 16 bits de dados 20 bits de endereços 1MByte Clock 2 [4,8] MHz i80286 24 bits de endereço
Família x86 - Evolução António M. Gonçalves Pinheiro Departamento de Física Covilhã - Portugal pinheiro@ubi.pt i8086 16 bits de dados 20 bits de endereços 1MByte Clock 2 [4,8] MHz i80286 24 bits de endereço
Frederico Tavares - MICEI 06/07. Frederico Tavares
 ICCA 07 8th Internal Conference on Computer Architecture FAQ - 05 Ao nível das últimas gerações do IA32 (Pentium III e ) quais as principais diferenças entre os processadores da Intel e da AMD? "IA32 processors:
ICCA 07 8th Internal Conference on Computer Architecture FAQ - 05 Ao nível das últimas gerações do IA32 (Pentium III e ) quais as principais diferenças entre os processadores da Intel e da AMD? "IA32 processors:
Arquitetura do SET de instruções Instruction SET. CISC vs RISC. What s assembly as to do with it?
 Arquitetura do SET de instruções Instruction SET CISC vs RISC What s assembly as to do with it? Low-level - high-level programming language Assambley CODE section.text global _start ;must be declared for
Arquitetura do SET de instruções Instruction SET CISC vs RISC What s assembly as to do with it? Low-level - high-level programming language Assambley CODE section.text global _start ;must be declared for
William Stallings Organização de computadores digitais. Capítulo 11 Estrutura e função da CPU
 William Stallings Organização de computadores digitais Capítulo 11 Estrutura e função da CPU Encruzilhada na arquitetura de computadores 2004/2005 Antiga opinião Nova visão a energia é de graça, os transistores
William Stallings Organização de computadores digitais Capítulo 11 Estrutura e função da CPU Encruzilhada na arquitetura de computadores 2004/2005 Antiga opinião Nova visão a energia é de graça, os transistores
Infraestrutura de Hardware. Melhorando Desempenho de Pipeline Processadores Superpipeline, Superescalares, VLIW
 Infraestrutura de Hardware Melhorando Desempenho de Pipeline Processadores Superpipeline, Superescalares, VLIW Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem
Infraestrutura de Hardware Melhorando Desempenho de Pipeline Processadores Superpipeline, Superescalares, VLIW Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem
Investigando a Influência da Organização de Caches L2 no Desempenho de Processadores Multicore Superescalares
 Investigando a Influência da Organização de Caches L2 no Desempenho de Processadores Multicore Superescalares Pedro H. Penna, Henrique C. Freitas 1 Grupo de Arquitetura de Computadores e Processamento
Investigando a Influência da Organização de Caches L2 no Desempenho de Processadores Multicore Superescalares Pedro H. Penna, Henrique C. Freitas 1 Grupo de Arquitetura de Computadores e Processamento
COMPARAÇÃO DE DESEMPENHO E EFICIÊNCIA ENERGÉTICA ENTRE MPSOC DE BAIXO CONSUMO E UM COMPUTADOR PESSOAL 1
 COMPARAÇÃO DE DESEMPENHO E EFICIÊNCIA ENERGÉTICA ENTRE MPSOC DE BAIXO CONSUMO E UM COMPUTADOR PESSOAL 1 Ricardo Klein Lorenzoni 2, Edson Luiz Padoin 3, Philippe Olivier Alexandre Navaux 4, Marlon Vinícius
COMPARAÇÃO DE DESEMPENHO E EFICIÊNCIA ENERGÉTICA ENTRE MPSOC DE BAIXO CONSUMO E UM COMPUTADOR PESSOAL 1 Ricardo Klein Lorenzoni 2, Edson Luiz Padoin 3, Philippe Olivier Alexandre Navaux 4, Marlon Vinícius
Arquitetura de Computadores Aula 11 - Multiprocessamento
 Arquitetura de Computadores Aula 11 - Multiprocessamento Prof. Dr. Eng. Fred Sauer http://www.fredsauer.com.br fsauer@gmail.com 1/28 PROCESSAMENTO PARALELO OBJETIVO: aumentar a capacidade de processamento.
Arquitetura de Computadores Aula 11 - Multiprocessamento Prof. Dr. Eng. Fred Sauer http://www.fredsauer.com.br fsauer@gmail.com 1/28 PROCESSAMENTO PARALELO OBJETIVO: aumentar a capacidade de processamento.
Microprocessadores II - ELE 1084
 Microprocessadores II - ELE 1084 CAPÍTULO III PROCESSADORES P5 3.1 Gerações de Processadores 3.1 Gerações de Processadores Quinta Geração (P5) Pentium (586) 32 bits; Instruções MMX; Concorrente K5 (AMD).
Microprocessadores II - ELE 1084 CAPÍTULO III PROCESSADORES P5 3.1 Gerações de Processadores 3.1 Gerações de Processadores Quinta Geração (P5) Pentium (586) 32 bits; Instruções MMX; Concorrente K5 (AMD).
Computação Paralela (CUDA)
") Universidade Federal do Amazonas Faculdade de Tecnologia Departamento de Eletrônica e Computação Computação Paralela (CUDA) Hussama Ibrahim hussamaibrahim@ufam.edu.br Notas de Aula Baseado nas Notas de
Universidade Federal do Amazonas Faculdade de Tecnologia Departamento de Eletrônica e Computação Computação Paralela (CUDA) Hussama Ibrahim hussamaibrahim@ufam.edu.br Notas de Aula Baseado nas Notas de
3 Computação de Propósito Geral em Unidades de Processamento Gráfico
 3 Computação de Propósito Geral em Unidades de Processamento Gráfico As Unidades de Processamento Gráfico (GPUs) foram originalmente desenvolvidas para o processamento de gráficos e eram difíceis de programar.
3 Computação de Propósito Geral em Unidades de Processamento Gráfico As Unidades de Processamento Gráfico (GPUs) foram originalmente desenvolvidas para o processamento de gráficos e eram difíceis de programar.
PROCESSAMENTO PARALELO EM CUDA APLICADO AO MODELO DE GERAÇÃO DE CENÁRIOS SINTÉTICOS DE VAZÕES E ENERGIAS - GEVAZP. André Emanoel Rabello Quadros
 PROCESSAMENTO PARALELO EM CUDA APLICADO AO MODELO DE GERAÇÃO DE CENÁRIOS SINTÉTICOS DE VAZÕES E ENERGIAS - GEVAZP André Emanoel Rabello Quadros Dissertação de Mestrado apresentada ao Programa de Pós-Graduação
PROCESSAMENTO PARALELO EM CUDA APLICADO AO MODELO DE GERAÇÃO DE CENÁRIOS SINTÉTICOS DE VAZÕES E ENERGIAS - GEVAZP André Emanoel Rabello Quadros Dissertação de Mestrado apresentada ao Programa de Pós-Graduação
Usando o benchmark Rodinia para comparação de OpenCL e OpenMP em aplicações paralelas no coprocessador Intel Xeon Phi
 Usando o benchmark Rodinia para comparação de OpenCL e OpenMP em aplicações paralelas no coprocessador Intel Xeon Phi Leonardo Tavares Oliveira 1, Ricardo Menotti 1 1 Departamento de Computação Universidade
Usando o benchmark Rodinia para comparação de OpenCL e OpenMP em aplicações paralelas no coprocessador Intel Xeon Phi Leonardo Tavares Oliveira 1, Ricardo Menotti 1 1 Departamento de Computação Universidade
Frustum Culling Híbrido Utilizando CPU e GPU. Aluno: Eduardo Telles Carlos Orientador: Alberto Raposo Co-Orientador: Marcelo Gattass
 Frustum Culling Híbrido Utilizando CPU e GPU Aluno: Eduardo Telles Carlos Orientador: Alberto Raposo Co-Orientador: Marcelo Gattass Agenda Objetivos Motivação Algoritmos de visibilidade Frustum Culling
Frustum Culling Híbrido Utilizando CPU e GPU Aluno: Eduardo Telles Carlos Orientador: Alberto Raposo Co-Orientador: Marcelo Gattass Agenda Objetivos Motivação Algoritmos de visibilidade Frustum Culling
Paradigmas de Processamento Paralelo na Resolução do Fractal de Mandelbrot
 Paradigmas de Processamento Paralelo na Resolução do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Universidade Estadual de Santa Cruz Cronograma Introdução Serial vs Processamento
Paradigmas de Processamento Paralelo na Resolução do Fractal de Mandelbrot Bruno Pereira dos Santos Dany Sanchez Dominguez Universidade Estadual de Santa Cruz Cronograma Introdução Serial vs Processamento
Impacto do Emprego da Afinidade de Processador em uma Arquitetura com Tecnologia Clustered MultiThreading
 Impacto do Emprego da Afinidade de Processador em uma Arquitetura com Tecnologia Clustered MultiThreading Carlos Alexandre de Almeida Pires 1, Marcelo Lobosco 1 1 Grupo de Educação Tutorial do Curso de
Impacto do Emprego da Afinidade de Processador em uma Arquitetura com Tecnologia Clustered MultiThreading Carlos Alexandre de Almeida Pires 1, Marcelo Lobosco 1 1 Grupo de Educação Tutorial do Curso de
Online Thread and Data Mapping Using the Memory Management Unit
 Online Thread and Data Mapping Using the Memory Management Unit Eduardo H. M. Cruz, Philippe O. A. Navaux 1 Instituto de Informática Universidade Federal do Rio Grande do Sul (UFRGS) {ehmcruz, navaux}@inf.ufrgs.br
Online Thread and Data Mapping Using the Memory Management Unit Eduardo H. M. Cruz, Philippe O. A. Navaux 1 Instituto de Informática Universidade Federal do Rio Grande do Sul (UFRGS) {ehmcruz, navaux}@inf.ufrgs.br
Jônatas Lopes de Paiva Instituto de Matemática e Estatística Universidade de São Paulo. 06 de maio de 2011
 Jônatas Lopes de Paiva jlp@ime.usp.br Instituto de Matemática e Estatística Universidade de São Paulo 06 de maio de 2011 Introdução String-matching O que é? Em que é utilizado Tipos GPU GPGPU String-matching
Jônatas Lopes de Paiva jlp@ime.usp.br Instituto de Matemática e Estatística Universidade de São Paulo 06 de maio de 2011 Introdução String-matching O que é? Em que é utilizado Tipos GPU GPGPU String-matching
Fabrício Gomes Vilasbôas
 Fabrício Gomes Vilasbôas Apresentação Placas Arquitetura Toolkit e Ferramentas de Debug Pensando em CUDA Programação CUDA Python Programação PyCUDA 1) Grids( padrão Globus) 2) Clusters ( padrão MPI) 3)
Fabrício Gomes Vilasbôas Apresentação Placas Arquitetura Toolkit e Ferramentas de Debug Pensando em CUDA Programação CUDA Python Programação PyCUDA 1) Grids( padrão Globus) 2) Clusters ( padrão MPI) 3)
Análise de Desempenho de Aplicações Paralelas do Padrão Pipeline em Processadores com Múltiplos Núcleos
 Análise de Desempenho de Aplicações Paralelas do Padrão Pipeline em Processadores com Múltiplos Núcleos Giuseppe G. P. Santana 1, Luís F. W. Goés 1 1 Departamento de Ciência da Computação Pontifícia Universidade
Análise de Desempenho de Aplicações Paralelas do Padrão Pipeline em Processadores com Múltiplos Núcleos Giuseppe G. P. Santana 1, Luís F. W. Goés 1 1 Departamento de Ciência da Computação Pontifícia Universidade
PARALELIZAÇÃO DO ALGORITMO AES E ANÁLISE SOBRE GPGPU 1 PARALLELIZATION OF AES ALGORITHM AND GPU ANALYSIS
 Disciplinarum Scientia. Série: Naturais e Tecnológicas, Santa Maria, v. 16, n. 1, p. 83-94, 2015. Recebido em: 11.04.2015. Aprovado em: 30.06.2015. ISSN 2176-462X PARALELIZAÇÃO DO ALGORITMO AES E ANÁLISE
Disciplinarum Scientia. Série: Naturais e Tecnológicas, Santa Maria, v. 16, n. 1, p. 83-94, 2015. Recebido em: 11.04.2015. Aprovado em: 30.06.2015. ISSN 2176-462X PARALELIZAÇÃO DO ALGORITMO AES E ANÁLISE