Paradigmas de Computação Paralela (UCE Computação Paralela Distribuída)
|
|
|
- Luna Castelhano Canto
- 7 Há anos
- Visualizações:
Transcrição
1 Paradigmas de Computação Paralela (UCE Computação Paralela Distribuída) Modelos de consistência de memória João Luís Ferreira Sobral 29 Março 2011

2 Resumo Revisão: modelos de threads Qual a necessidade do modelos de consistência? Modelos de consistência sequencial Modelos de consistência relaxada Consistência fraca Consistência na libertação (release) Estudo de casos OpenMP Java Threads

3 Execução de programas multi-threaded em uniprocessadores (unicore) O processador executa todos os fios de execução do programa A política de escalonamento não é especificada As operações efectuadas por cada fio de execução são executadas por ordem Sincronização entre fios de execução através de operações atómicas (c/ locks) As instruções executadas por cada fio são intercaladas Não determinismo: o resultado do programa depende da forma como são escalonados os fios de execução; ex: Thread 1 Thread 2.. x := 1; print(x); x := 2;

4 Execução de programas multi-threaded em muli-processadores Cada processador executa um fio de execução do programa (consideramos o número de fios igual ao número de processadores) As operações efectuadas por cada fio de execução são executadas por ordem Um processador pode aceder à memória global para fazer load/store/operações atómicas Não há caching da dados globais Os resultados possíveis de um programa são iguais aos de um uniprocessador. Considerações mais realistas: Caching de dados globais para melhorar a eficiência Requer um protocolo de coesão de caches Execução fora de ordem de instruções Pode alterar a semântica do programa => obriga a um modelo de consistência de memória

5 Execução fora de ordem de instruções (execution out-of-order ) Os processadores reordenam as instruções para melhorar o desempenho As re-ordenações devem respeitar as dependências Dados e.g., loads/stores devem ser executados pela ordem especificada Controlo As re-ordenações podem ser efectuadas pelo processador ou pelo compilador Re-odenações permitidas Stores em diferentes localizações store v1, data store b1, flag store b1, flag ß à store v1, data Loads de diferentes localizações load flag, r1 load data,r2 load data, r2 ß à load flag, r1 Loads e stores em diferentes localizações

6 Execução fora de ordem de instruções Exemplo de reordenação efectuada pelo hardware Load bypassing Store buffer Memory system O store buffer armazena operações de store para a enviar para a memória Os loads têm prioridade sobre os stores para manter o processador ocupado Ultrapassam os stores no buffer Os loads verificam se existe um store nesse mesmo endereço Resultado: os load e stores não são efectuados pela ordem do programa

7 Execução fora de ordem de instruções em multiprocessadores Modelo canónico Operações realizadas por um dado processador são efectuadas por ordem As operações realizadas em memória por vários processadores são intercaladas Se um processador reordenar o seu fluxo de instruções, será que a execução produz o mesmo resultado que o modelo canónico? Inicialmente A = Flag = 0 P1 P2 A = 23; while (Flag!= 1) {;} Flag = 1;... = A; P1 escreve dados em A e assinala isso a P2 através da Flag P2 espera até a Flag estar activa, então lê o A O que acontece se P1 trocar a ordem dos stores?

8 Execução fora de ordem de instruções em multiprocessadores Exemplo II Flag1 = Flag2 = 0 P1 P2 Flag1 = 1; Flag2 = 1; If (Flag2 == 0) If (Flag1 == 0) critical section critical section Uma possível ordem de execução P1 P2 Write Flag1, 1 Write Flag2, 1 Read Flag2 //get 0 Read Flag1 // get 1? => só se os load e stores forem efectuados por ordem

9 Conclusões Modelos de consistência de memória Os sistemas uni-processador podem reordenar as instruções para melhorar o desempenho, respeitando as dependências de dados e de controlo (locais!) Este pressuposto não é válido para ambientes multi-processador de memória partilhada Um programa paralelo pode produzir resultados contra-intuitivos Quais as limitações que se devem impor à reordenação de instruções para que: A programação seja intuitiva Não se perca o desempenho uni-processador Solução: modelo de consistência de memória suportado pelo processador Modelo de consistência sequencial (o mais simples): O processador não pode reordenar as leituras e escritas na memória global Reduz o desempenho uni-processador

10 Modelos de consistência relaxada (relaxed consistency) Consistência fraca (weak consistency) O programador especifica regiões onde as operações devem ser ordenadas Instruções de fence As operações antes de fence devem completar antes do fence ser executado As operações depois de fence têm que esperar que o fence termine. Os fences são executados por ordem Implementação de fence Contador incrementado a cada iniciação de uma operação de fence Exemplo: Instrução SYNC no PowerPC flush em OpenMP Operações de sincronização do tipo lock/unlock fence fence As operações nestas regioes podem ser reordenadas Ordem de execução fence

11 Modelos de consistência relaxada Consistência fraca (weak consistency) Exemplo I - Revisto Inicialmente A = Flag = 0 P1 P2 A = 23; flush while (Flag!= 1) {;} Flag = 1;... = A; P1 escreve dados em A O flush espera que a escrita de A seja completada P1 escreve dados na Flag P2 vai ler Flag==1 quando a escrita em A completou, mesmo que as operações antes do flush sejam executadas fora de ordem Será necessário um flush entre as duas operações em P2?

12 Modelos de consistência relaxada Consistência de release Mais relaxada que a consistência fraca O modelo de consistência fraca não diferencia entre leituras e escritas (a instrução de fence implica a escrita/leitura de todos os valores alterados) O modelo de consistência de libertação atualiza os valores locais (lidos da memória) à entrada da região crítica e escreve os valores na memória à saída da região. Acessos de sincronização divididos em: Aquisição: operações do tipo lock deve ser efectuada antes realizar acessos à memória não espera pelos acessos que a precedem (1) (1) L/S ACQ Libertação: operações do tipo unlock Deve ser efetuada após todas as escritas Acessos após o release não têm que esperar pelo release (2) L/S REL L/S (2)
 (1) L/S ACQ")
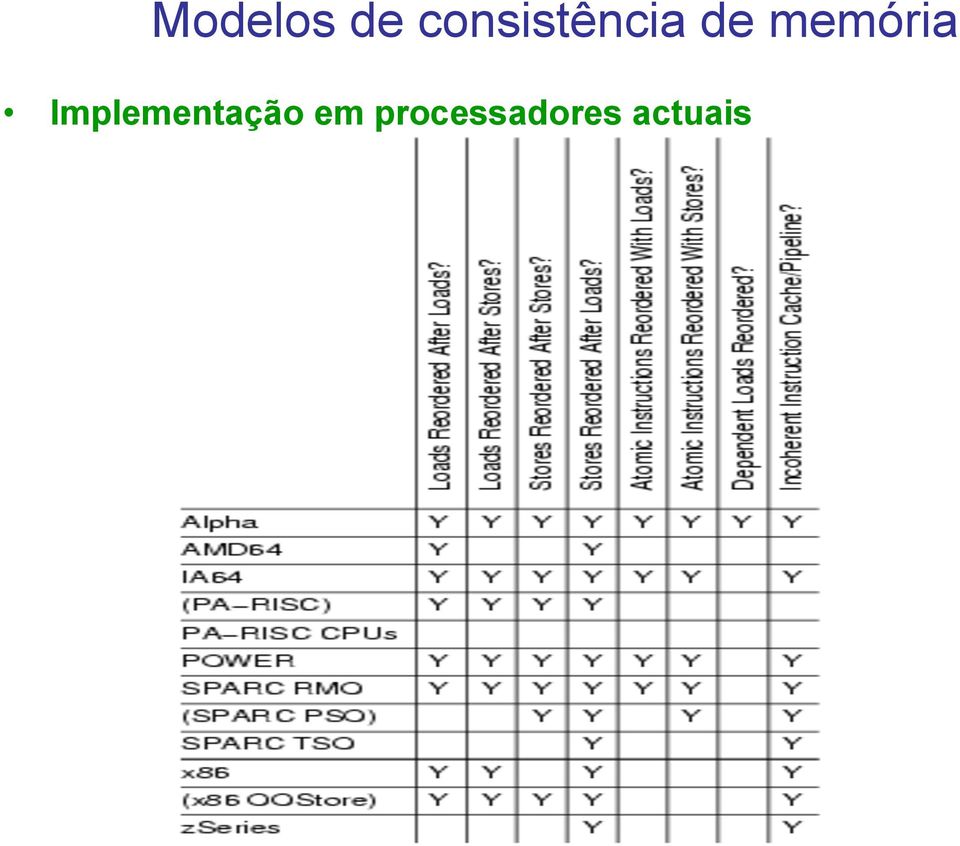
13 Implementação em processadores actuais
14 Modelos de consistência Impõe restrições à reordenação de instruções de um processador Não estão relacionadas com as operações na memória de diferentes processadores Existem muitos modelos de consistência de memória Consenso emergente em torno de fraco/ release É fácil escrever um programa cujo comportamento seja dependente do modelo de consistência de memória utilizado Coesão da memória (visto anteriormente) Cria a ilusão de uma só localização lógica correspondente a cada variável do programa mesmo que existam múltiplas localizações para essa variável
 Cria a ilusão de uma só localização lógica correspondente a cada variável do programa mesmo que existam múltiplas")
15 Modelo do OpenMP Baseia-se num modelo de consistência fraca Os fios de execução podem ter uma vista temporária da memória (registos, cache, etc..) As escritas e leituras podem ser efectuadas na memória local Instrução fence #pragma omp flush Força a consistência entre a vista temporária e a memória (para a lista de variáveis fornecida no flush) As variáveis alteradas localmente são escritas na memória As cópias locais de variáveis são descartadas para que a próxima leitura seja efectuada da memória A operação termina quando todas as variáveis foram actualizadas na memória Não é garantida a ordenação entre flush se a lista de variáveis for disjunta A memória/variáveis privadas (threadprivate, private) não são afectadas pelo flush O flush é implícito em: Barrier, set_lock, unset_lock, atomic Entrada e saída de parallel, critical e ordered A sincronização através de variáveis em memória é desaconselhada
 não são afectadas pelo flush")
16 Modelo do Java Modelos de consistência de memória O modelo original foi revisto em 2004 (Java 5.0) por limitar demasiado as optimizações do compilador e não fornecer garantias suficientes ao programador Baseia-se num modelo de consistência relaxada (ordenação parcial de eventos) Os fios de execução podem manter cópias locais dos dados que não estão sincronizadas com os valores na memória. As variáveis declaradas como voláteis não são armazenadas localmente Memória partilhada entre fios de execução Variáveis de instância, variáveis estáticas, elementos de arrays Variáveis locais, parâmetros e handler de excepções não são partilhados. Regiões synchronized: Na entrada invalida cópias locais dos dados Na saída faz flush das variáveis Implica ordenação entre regiões consecutivas (protegidas pelo mesmo lock!) Problema do modelo antigo: não força a semântica sequencial de outras variáveis relativamente às voláteis Inicialmente A = Flag = 0 Flag declarada como volátil P1 P2 A = 23; while (Flag!= 1) {;} Flag = 1;... = A; P1 escreve dados em A e assinala isso a P2 através da Flag P2 espera até a Flag estar activa, então lê o A

Construtores de Sicronização em OpenMP
 Construtores de Sicronização em OpenMP Esbel Tomás Valero Orellana Bacharelado em Ciência da Computação Departamento de Ciências Exatas e Tecnológicas Universidade Estadual de Santa Cruz evalero@uesc.br
Construtores de Sicronização em OpenMP Esbel Tomás Valero Orellana Bacharelado em Ciência da Computação Departamento de Ciências Exatas e Tecnológicas Universidade Estadual de Santa Cruz evalero@uesc.br
OpenMP: Variáveis de Ambiente
 Treinamento OpenMP C/C++ 1 TREINAMENTO OpenMP C/C++ Módulo 1 Computação de Alto Desempenho Módulo 2 OpenMP: Construtores Paralelos Módulo 3 OpenMP: Diretivas de sincronização Módulo 4 OpenMP: Funções de
Treinamento OpenMP C/C++ 1 TREINAMENTO OpenMP C/C++ Módulo 1 Computação de Alto Desempenho Módulo 2 OpenMP: Construtores Paralelos Módulo 3 OpenMP: Diretivas de sincronização Módulo 4 OpenMP: Funções de
Programação em Paralelo OpenMP
 Programação em Paralelo OpenMP N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: OpenMP 1 / 15 Introdução Potencial do GPU vs CPU Cálculo: 367
Programação em Paralelo OpenMP N. Cardoso & P. Bicudo Física Computacional - MEFT 2012/2013 N. Cardoso & P. Bicudo Programação em Paralelo: OpenMP 1 / 15 Introdução Potencial do GPU vs CPU Cálculo: 367
Arquitetura e Organização de Processadores. Aula 4. Pipelines
 Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 4 Pipelines 1. Introdução Objetivo: aumento de
Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aula 4 Pipelines 1. Introdução Objetivo: aumento de
Introdução OpenMP. Nielsen Castelo Damasceno
 Introdução OpenMP Nielsen Castelo Damasceno Computação de auto desempenho Processamento Paralelo Memória Distribuída e Compartilhada Modelo de programação OpenMP Métricas de Desempenho Computação de auto
Introdução OpenMP Nielsen Castelo Damasceno Computação de auto desempenho Processamento Paralelo Memória Distribuída e Compartilhada Modelo de programação OpenMP Métricas de Desempenho Computação de auto
for(int x=0; x < width; x++) { for(int y=0; y < height; y++) { finalimage[x][y]=renderpixel(x,y, &scenedata); } }
![for(int x=0; x < width; x++) { for(int y=0; y < height; y++) { finalimage[x][y]=renderpixel(x,y, &scenedata); } }](/thumbs/67/56404372.jpg "for(int x=0; x < width; x++) { for(int y=0; y < height; y++) { finalimage[x][y]=renderpixel(x,y, &scenedata); } }") Paralelização em OpenMP Identifique os loops pesados ; Distribua-os: Versão sequencial double res[10000]; calculo_pesado(&res[i]); Versão paralela double res[10000]; for calculo_pesado(&res[i]); OMP for
Paralelização em OpenMP Identifique os loops pesados ; Distribua-os: Versão sequencial double res[10000]; calculo_pesado(&res[i]); Versão paralela double res[10000]; for calculo_pesado(&res[i]); OMP for
AULA 06: PROGRAMAÇÃO EM MÁQUINAS PARALELAS
 ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 06: PROGRAMAÇÃO EM MÁQUINAS PARALELAS Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação PROGRAMAÇÃO PARALELA
ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 06: PROGRAMAÇÃO EM MÁQUINAS PARALELAS Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação PROGRAMAÇÃO PARALELA
Sistemas Operacionais: Sincronização entre processos
 Sistemas Operacionais: Sincronização entre processos Sincronização Programa concorrente Executado por diversos processos Acesso concorrente a dados Paralelismo real x Paralelismo aparente Multiprocessadores:
Sistemas Operacionais: Sincronização entre processos Sincronização Programa concorrente Executado por diversos processos Acesso concorrente a dados Paralelismo real x Paralelismo aparente Multiprocessadores:
Replicação. Modelos de Consistência.
 Replicação. Modelos de Consistência. December 1, 2009 Sumário Introdução Questões Centrais da Replicação Modelos de Consistência Replicação O que é? O uso de múltiplas cópias de dados ou serviços (e estado
Replicação. Modelos de Consistência. December 1, 2009 Sumário Introdução Questões Centrais da Replicação Modelos de Consistência Replicação O que é? O uso de múltiplas cópias de dados ou serviços (e estado
Programação Concorrente e Paralela. Noemi Rodriguez
 2016 o que é programação concorrente e paralela? programação concorrente: composição de linhas de atividades independentes programação paralela: execução simultânea de linhas de atividades Go blog (Rob
2016 o que é programação concorrente e paralela? programação concorrente: composição de linhas de atividades independentes programação paralela: execução simultânea de linhas de atividades Go blog (Rob
Arquitetura e Organização de Processadores. Aulas 06 e 07. Superescalaridade
 Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aulas 06 e 07 Superescalaridade 1. Introdução princípios
Universidade Federal do Rio Grande do Sul Instituto de Informática Programa de Pós-Graduação em Computação Arquitetura e Organização de Processadores Aulas 06 e 07 Superescalaridade 1. Introdução princípios
Sistemas Distribuídos e Paralelos
 Sistemas Distribuídos e Paralelos Aula #6: Programação paralela em sistemas de memória compartilhada. ISUTIC - 2016 Eng. Alexander Rodríguez Bonet Aula de hoje Regiões paralelas. Cláusulas de âmbito. Partilha
Sistemas Distribuídos e Paralelos Aula #6: Programação paralela em sistemas de memória compartilhada. ISUTIC - 2016 Eng. Alexander Rodríguez Bonet Aula de hoje Regiões paralelas. Cláusulas de âmbito. Partilha
Variáveis em OpenMP. Esbel Tomás Valero Orellana
 Variáveis em OpenMP Esbel Tomás Valero Orellana Bacharelado em Ciência da Computação Departamento de Ciências Exatas e Tecnológicas Universidade Estadual de Santa Cruz evalero@uesc.br 31 de Maio de 2010
Variáveis em OpenMP Esbel Tomás Valero Orellana Bacharelado em Ciência da Computação Departamento de Ciências Exatas e Tecnológicas Universidade Estadual de Santa Cruz evalero@uesc.br 31 de Maio de 2010
Programação Concorrente e Paralela. Noemi Rodriguez
 2013 Objetivos princípios e técnicas de programação concorrente multiprocessadores memória compartilhada troca de mensagens obs: diferentes níveis de abstração! que princípios e técnicas são esses? notações
2013 Objetivos princípios e técnicas de programação concorrente multiprocessadores memória compartilhada troca de mensagens obs: diferentes níveis de abstração! que princípios e técnicas são esses? notações
Arquiteturas de Sistemas de Processamento Paralelo Modelos de Consistência de Memória em Multiprocessadores
 Universidade Federal do Rio de Janeiro Pós-Graduação em Informática DCC/IM - NCE/UFRJ Arquiteturas de Sistemas de Processamento Paralelo Modelos de Consistência de Memória em Multiprocessadores Gabriel
Universidade Federal do Rio de Janeiro Pós-Graduação em Informática DCC/IM - NCE/UFRJ Arquiteturas de Sistemas de Processamento Paralelo Modelos de Consistência de Memória em Multiprocessadores Gabriel
Bibliografia. OpenMP. Disponibilidade de OpenMP. Abordagem SPMD. Nicolas Maillard
 Bibliografia Nicolas Maillard nicolas@inf.ufrgs.br Instituto de Informática Universidade Federal do Rio Grande do Sul home-page: http://www.openmp.org/presentations Parallel Programming in. R. Chandra
Bibliografia Nicolas Maillard nicolas@inf.ufrgs.br Instituto de Informática Universidade Federal do Rio Grande do Sul home-page: http://www.openmp.org/presentations Parallel Programming in. R. Chandra
Microprocessadores. Execução em Paralelo Pipelines
 Execução em Paralelo Pipelines António M. Gonçalves Pinheiro Departamento de Física Covilhã - Portugal pinheiro@ubi.pt Pipelines de Instrucções Instrucções são divididas em diferentes Estágios Pipelines
Execução em Paralelo Pipelines António M. Gonçalves Pinheiro Departamento de Física Covilhã - Portugal pinheiro@ubi.pt Pipelines de Instrucções Instrucções são divididas em diferentes Estágios Pipelines
SSC PROGRAMAÇÃO CONCORRENTE. Aula 06 Modelos de Programação Prof. Jó Ueyama e Julio Cezar Estrella
 SSC- 0143 PROGRAMAÇÃO CONCORRENTE Aula 06 Modelos de Programação Prof. Jó Ueyama e Julio Cezar Estrella Créditos Os slides integrantes deste material foram construídos a par4r dos conteúdos relacionados
SSC- 0143 PROGRAMAÇÃO CONCORRENTE Aula 06 Modelos de Programação Prof. Jó Ueyama e Julio Cezar Estrella Créditos Os slides integrantes deste material foram construídos a par4r dos conteúdos relacionados
SSC0611 Arquitetura de Computadores
 SSC0611 Arquitetura de Computadores 8ª Aula Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Estágios para execução da instrução: A instrução LOAD é a mais longa Todas as instruções seguem ao menos os
SSC0611 Arquitetura de Computadores 8ª Aula Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Estágios para execução da instrução: A instrução LOAD é a mais longa Todas as instruções seguem ao menos os
Paralela e Distribuída. Memórias Cache e Arquitecturas Multi-Processador
 Programação Paralela e Distribuída Memórias Cache e Arquitecturas Multi-Processador Memórias Cache e Arquitecturas Multi-Processador A principal motivação para utilizar o OpenMP é conseguir maximizar a
Programação Paralela e Distribuída Memórias Cache e Arquitecturas Multi-Processador Memórias Cache e Arquitecturas Multi-Processador A principal motivação para utilizar o OpenMP é conseguir maximizar a
UFRJ IM - DCC. Sistemas Operacionais I. Unidade IV Gerência de Recursos Entrada e Saída. 02/12/2014 Prof. Valeria M. Bastos
 UFRJ IM - DCC Sistemas Operacionais I Unidade IV Gerência de Recursos Entrada e Saída 02/12/2014 Prof. Valeria M. Bastos 1 ORGANIZAÇÃO DA UNIDADE Gerência de Entrada e Saída Fundamentos Evolução Estrutura
UFRJ IM - DCC Sistemas Operacionais I Unidade IV Gerência de Recursos Entrada e Saída 02/12/2014 Prof. Valeria M. Bastos 1 ORGANIZAÇÃO DA UNIDADE Gerência de Entrada e Saída Fundamentos Evolução Estrutura
Universidade Federal do Rio de Janeiro Informática DCC/IM. Arquitetura de Computadores II. Arquiteturas MIMD. Arquiteturas MIMD
 Universidade Federal do Rio de Janeiro Informática DCC/IM Arquitetura de Computadores II Arquiteturas MIMD Arquiteturas MIMD As arquiteturas MIMD dividem-se em dois grandes modelos: Arquiteturas MIMD de
Universidade Federal do Rio de Janeiro Informática DCC/IM Arquitetura de Computadores II Arquiteturas MIMD Arquiteturas MIMD As arquiteturas MIMD dividem-se em dois grandes modelos: Arquiteturas MIMD de
Introdução à Computação: Sistemas de Computação
 Introdução à Computação: Sistemas de Computação Beatriz F. M. Souza (bfmartins@inf.ufes.br) http://inf.ufes.br/~bfmartins/ Computer Science Department Federal University of Espírito Santo (Ufes), Vitória,
Introdução à Computação: Sistemas de Computação Beatriz F. M. Souza (bfmartins@inf.ufes.br) http://inf.ufes.br/~bfmartins/ Computer Science Department Federal University of Espírito Santo (Ufes), Vitória,
OpenMP. Adaptado do Material do Calebe de Paula Bianchini
 OpenMP Adaptado do Material do Calebe de Paula Bianchini calebe.bianchini@mackenzie.br HelloWorld #pragma omp parallel // Code inside this region runs in parallel. printf("hello!\n"); 2 O que é OpenMP*?
OpenMP Adaptado do Material do Calebe de Paula Bianchini calebe.bianchini@mackenzie.br HelloWorld #pragma omp parallel // Code inside this region runs in parallel. printf("hello!\n"); 2 O que é OpenMP*?
Linguagem de Programação II
 Linguagem de Programação II Carlos Eduardo Ba6sta Centro de Informá6ca - UFPB bidu@ci.ufpb.br Mo6vação Adaptar a estrutura lógica de um problema (Ex.: Servidores Web). Lidar com disposi6vos independentes
Linguagem de Programação II Carlos Eduardo Ba6sta Centro de Informá6ca - UFPB bidu@ci.ufpb.br Mo6vação Adaptar a estrutura lógica de um problema (Ex.: Servidores Web). Lidar com disposi6vos independentes
Organização e Arquitetura de Computadores I
 Universidade Federal de Campina Grande Centro de Engenharia Elétrica e Informática Unidade Acadêmica de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de
Universidade Federal de Campina Grande Centro de Engenharia Elétrica e Informática Unidade Acadêmica de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de
Programação Concorrente
 + XV Jornada de Cursos CITi Programação Concorrente Aula 9 Benito Fernandes Fernando Castor João Paulo Oliveira Weslley Torres + Agenda Acesso Atômico Variáveis atômicas Daemon Thread + Acesso Atômico
+ XV Jornada de Cursos CITi Programação Concorrente Aula 9 Benito Fernandes Fernando Castor João Paulo Oliveira Weslley Torres + Agenda Acesso Atômico Variáveis atômicas Daemon Thread + Acesso Atômico
Arquitetura de Computadores. Processamento Paralelo
 Arquitetura de Computadores Processamento Paralelo 1 Multiprogramação e Multiprocessamento Múltiplas organizações de computadores Single instruction, single data stream - SISD Single instruction, multiple
Arquitetura de Computadores Processamento Paralelo 1 Multiprogramação e Multiprocessamento Múltiplas organizações de computadores Single instruction, single data stream - SISD Single instruction, multiple
Organização de Computadores II. Arquiteturas MIMD
 Organização de Computadores II Arquiteturas MIMD Arquiteturas UMA Arquiteturas com memória única global. Tempo de acesso uniforme para todos os nós de processamento. Nós de processamento e memória interconectados
Organização de Computadores II Arquiteturas MIMD Arquiteturas UMA Arquiteturas com memória única global. Tempo de acesso uniforme para todos os nós de processamento. Nós de processamento e memória interconectados
Exclusão Mútua (mutex)
") 2004-2017 Volnys Bernal 1 Exclusão Mútua (mutex) Volnys Borges Bernal volnys@lsi.usp.br Departamento de Sistemas Eletrônicos Escola Politécnica da USP 2004-2017 Volnys Bernal 2 Tópicos Exclusão Mútua (Mutex)
2004-2017 Volnys Bernal 1 Exclusão Mútua (mutex) Volnys Borges Bernal volnys@lsi.usp.br Departamento de Sistemas Eletrônicos Escola Politécnica da USP 2004-2017 Volnys Bernal 2 Tópicos Exclusão Mútua (Mutex)
09 Unidade de controlo. v0.1
 09 Unidade de controlo v0.1 Introdução Um micro-processador pode consistir apenas em alguns elementos: ALU Registers Lógica de controlo (ou unidade de controlo) 18 December 2014 Sistemas Digitais 2 Lógica
09 Unidade de controlo v0.1 Introdução Um micro-processador pode consistir apenas em alguns elementos: ALU Registers Lógica de controlo (ou unidade de controlo) 18 December 2014 Sistemas Digitais 2 Lógica
Sistemas Distribuídos Aula 7
 Sistemas Distribuídos Aula 7 Aula passada Atomicidade Test-and-set Locks revisitado Semáforos Dois problemas Aula de hoje Limitação dos semáforos Monitores Variáveis de condição Semântica do signal Sincronização
Sistemas Distribuídos Aula 7 Aula passada Atomicidade Test-and-set Locks revisitado Semáforos Dois problemas Aula de hoje Limitação dos semáforos Monitores Variáveis de condição Semântica do signal Sincronização
ü Capítulo 4 Livro do Mário Monteiro ü Introdução ü Hierarquia de memória ü Memória Principal ü Memória principal ü Memória cache
 Departamento de Ciência da Computação - UFF Principal Profa. Débora Christina Muchaluat Saade debora@midiacom.uff.br Principal ü Capítulo 4 Livro do Mário Monteiro ü Introdução ü Hierarquia de memória
Departamento de Ciência da Computação - UFF Principal Profa. Débora Christina Muchaluat Saade debora@midiacom.uff.br Principal ü Capítulo 4 Livro do Mário Monteiro ü Introdução ü Hierarquia de memória
Boas Práticas de Programação Concorrente
 Boas Práticas de Programação Concorrente Evitando surpresas inconvenientes Ronny Moura Súmario Principais problemas da programação concorrente e os mecanismos Java para resolvê-los. Race condition(synchronized,
Boas Práticas de Programação Concorrente Evitando surpresas inconvenientes Ronny Moura Súmario Principais problemas da programação concorrente e os mecanismos Java para resolvê-los. Race condition(synchronized,
Organização e Arquitetura de Computadores INTRODUÇÃO
 Organização e Arquitetura de Computadores INTRODUÇÃO A Arquitetura de Computadores trata do comportamento funcional de um sistema computacional, do ponto de vista do programador (ex. tamanho de um tipo
Organização e Arquitetura de Computadores INTRODUÇÃO A Arquitetura de Computadores trata do comportamento funcional de um sistema computacional, do ponto de vista do programador (ex. tamanho de um tipo
Memórias Cache em Arquiteturas Multiprocessador e Multicore
 Memórias Cache em Arquiteturas Multiprocessador e Multicore Ricardo Rocha Departamento de Ciência de Computadores Faculdade de Ciências Universidade do Porto Computação Paralela 2015/2016 R. Rocha (DCC-FCUP)
Memórias Cache em Arquiteturas Multiprocessador e Multicore Ricardo Rocha Departamento de Ciência de Computadores Faculdade de Ciências Universidade do Porto Computação Paralela 2015/2016 R. Rocha (DCC-FCUP)
Estruturas de Sistemas Operacionais
 Estruturas de Sistemas Operacionais Sistemas Operacionais - Tópicos Componentes do Sistema Serviços de Sistemas Operacionais Chamadas ao Sistema Estrutura do Sistema Máquinas Virtuais Chamadas ao Sistema
Estruturas de Sistemas Operacionais Sistemas Operacionais - Tópicos Componentes do Sistema Serviços de Sistemas Operacionais Chamadas ao Sistema Estrutura do Sistema Máquinas Virtuais Chamadas ao Sistema
Parte I Multiprocessamento
 Sistemas Operacionais I Estrutura dos SO Prof. Gregorio Perez gregorio@uninove.br 2004 Parte I Multiprocessamento Roteiro 1 Multiprocessadores em Sistemas Fortemente Acoplados 1.1 1.2 1.3 Processamento
Sistemas Operacionais I Estrutura dos SO Prof. Gregorio Perez gregorio@uninove.br 2004 Parte I Multiprocessamento Roteiro 1 Multiprocessadores em Sistemas Fortemente Acoplados 1.1 1.2 1.3 Processamento
Universidade Estadual de Mato Grosso do Sul UEMS Curso de Ciência da Computação Disciplina de Algoritmos Paralelos e Distribuídos
 Universidade Estadual de Mato Grosso do Sul UEMS Curso de Ciência da Computação Disciplina de Algoritmos Paralelos e Distribuídos Pensando em Paralelo Pensar em paralelo é uma tarefa que exige disciplina
Universidade Estadual de Mato Grosso do Sul UEMS Curso de Ciência da Computação Disciplina de Algoritmos Paralelos e Distribuídos Pensando em Paralelo Pensar em paralelo é uma tarefa que exige disciplina
Sistemas MIMD. CES-25 Arquiteturas para Alto Desmpenho. Paulo André Castro
 Sistemas MIMD Arquiteturas para Alto Desmpenho Prof. pauloac@ita.br Sala 110 Prédio da Computação www.comp.ita.br/~pauloac Arquiteturas Paralelas (SISD) Single Instruction Stream, Single Data Stream: Monoprocessador
Sistemas MIMD Arquiteturas para Alto Desmpenho Prof. pauloac@ita.br Sala 110 Prédio da Computação www.comp.ita.br/~pauloac Arquiteturas Paralelas (SISD) Single Instruction Stream, Single Data Stream: Monoprocessador
Infraestrutura de Hardware. Melhorando Desempenho de Pipeline Processadores Superpipeline, Superescalares, VLIW
 Infraestrutura de Hardware Melhorando Desempenho de Pipeline Processadores Superpipeline, Superescalares, VLIW Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem
Infraestrutura de Hardware Melhorando Desempenho de Pipeline Processadores Superpipeline, Superescalares, VLIW Perguntas que Devem ser Respondidas ao Final do Curso Como um programa escrito em uma linguagem
INE5645 PROGRAMAÇAO PARALELA E DISTRIBUÍDA PROVA 1 18/09/2017 ALUNO: Prof. Bosco
 INE5645 PROGRAMAÇAO PARALELA E DISTRIBUÍDA PROVA 1 18/09/2017 ALUNO: Prof. Bosco 1. a. (Verdade/Falso) Threads ou processos são programas sequenciais. Programação concorrente é aquela onde diversos processos/threads
INE5645 PROGRAMAÇAO PARALELA E DISTRIBUÍDA PROVA 1 18/09/2017 ALUNO: Prof. Bosco 1. a. (Verdade/Falso) Threads ou processos são programas sequenciais. Programação concorrente é aquela onde diversos processos/threads
Concorrência em Processos
 Concorrência em Processos Anderson L. S. Moreira anderson.moreira@recife.ifpe.edu.br http://dase.ifpe.edu.br/~alsm Baseado nas aulas do professor Alberto Costa Neto da UFS 1 O que fazer com essa apresentação
Concorrência em Processos Anderson L. S. Moreira anderson.moreira@recife.ifpe.edu.br http://dase.ifpe.edu.br/~alsm Baseado nas aulas do professor Alberto Costa Neto da UFS 1 O que fazer com essa apresentação
OpenMP: Variáveis de Ambiente
 Treinamento OpenMP C/C++ 1 TREINAMENTO OpenMP C/C++ Módulo 1 Computação de Alto Desempenho Módulo 2 OpenMP: Construtores Paralelos Módulo 3 OpenMP: Diretivas de sincronização Módulo 4 OpenMP: Funções de
Treinamento OpenMP C/C++ 1 TREINAMENTO OpenMP C/C++ Módulo 1 Computação de Alto Desempenho Módulo 2 OpenMP: Construtores Paralelos Módulo 3 OpenMP: Diretivas de sincronização Módulo 4 OpenMP: Funções de
 http://www.ic.uff.br/~debora/fac! 1 Capítulo 4 Livro do Mário Monteiro Introdução Hierarquia de memória Memória Principal Organização Operações de leitura e escrita Capacidade 2 Componente de um sistema
http://www.ic.uff.br/~debora/fac! 1 Capítulo 4 Livro do Mário Monteiro Introdução Hierarquia de memória Memória Principal Organização Operações de leitura e escrita Capacidade 2 Componente de um sistema
Computadores e Programação (DCC/UFRJ)
") Computadores e Programação (DCC/UFRJ) Aula 3: 1 2 3 Abstrações do Sistema Operacional Memória virtual Abstração que dá a cada processo a ilusão de que ele possui uso exclusivo da memória principal Todo
Computadores e Programação (DCC/UFRJ) Aula 3: 1 2 3 Abstrações do Sistema Operacional Memória virtual Abstração que dá a cada processo a ilusão de que ele possui uso exclusivo da memória principal Todo
Arquitetura e Organização de Computadores
 Arquitetura e Organização de Computadores Unidade Central de Processamento (CPU) Givanaldo Rocha de Souza http://docente.ifrn.edu.br/givanaldorocha givanaldo.rocha@ifrn.edu.br Baseado nos slides do capítulo
Arquitetura e Organização de Computadores Unidade Central de Processamento (CPU) Givanaldo Rocha de Souza http://docente.ifrn.edu.br/givanaldorocha givanaldo.rocha@ifrn.edu.br Baseado nos slides do capítulo
Consistência. ncia. Sistemas Distribuídos e Tolerância a Falhas. Trabalho realizado por:
 Sistemas Distribuídos e Tolerâ a Falhas Consistê Trabalho realizado por: Gonçalo Dias, Nº. 14638 João Tavares, Nº 14888 Rui Brás, Nº 14820 Consistê Índice Consistent Global States; Distributed Consensus;
Sistemas Distribuídos e Tolerâ a Falhas Consistê Trabalho realizado por: Gonçalo Dias, Nº. 14638 João Tavares, Nº 14888 Rui Brás, Nº 14820 Consistê Índice Consistent Global States; Distributed Consensus;
Memória Principal. Tiago Alves de Oliveira
 Memória Principal Tiago Alves de Oliveira tiago@div.cefetmg.br Memória Principal Capítulo 4 Livro do Mário Monteiro Introdução Hierarquia de memória Memória Principal Organização Operações de leitura e
Memória Principal Tiago Alves de Oliveira tiago@div.cefetmg.br Memória Principal Capítulo 4 Livro do Mário Monteiro Introdução Hierarquia de memória Memória Principal Organização Operações de leitura e
Programação de Alto Desempenho - 2. Prof: Carla Osthoff
 Programação de Alto Desempenho - 2 Prof: Carla Osthoff E-mail: osthoff@lncc.br 3- Modelos de programação paralela Shared Memory/Threads Posix Win32 treads OpenMP Message Passing MPI Data Parallel OpenCL/Cuda
Programação de Alto Desempenho - 2 Prof: Carla Osthoff E-mail: osthoff@lncc.br 3- Modelos de programação paralela Shared Memory/Threads Posix Win32 treads OpenMP Message Passing MPI Data Parallel OpenCL/Cuda
Bacharelado em Sistemas de Informação Sistemas Operacionais. Prof. Filipo Mór
 Bacharelado em Sistemas de Informação Sistemas Operacionais Prof. Filipo Mór WWW.FILIPOMOR.COM - REVISÃO ARQUITETURAS PARALELAS Evolução das Arquiteturas Evolução das Arquiteturas Entrada CPU Saída von
Bacharelado em Sistemas de Informação Sistemas Operacionais Prof. Filipo Mór WWW.FILIPOMOR.COM - REVISÃO ARQUITETURAS PARALELAS Evolução das Arquiteturas Evolução das Arquiteturas Entrada CPU Saída von
ORGANIZAÇÃO DE COMPUTADORES CAPÍTULO4: MEMÓRIAPRINCIPAL
 ORGANIZAÇÃO DE COMPUTADORES CAPÍTULO4: MEMÓRIAPRINCIPAL MEMÓRIA Componente de um sistema de computação cuja função é armazenar informações que são manipuladas pelo sistema para que possam ser recuperadas
ORGANIZAÇÃO DE COMPUTADORES CAPÍTULO4: MEMÓRIAPRINCIPAL MEMÓRIA Componente de um sistema de computação cuja função é armazenar informações que são manipuladas pelo sistema para que possam ser recuperadas
INE 5645 PROGRAMAÇÃO PARALELA E DISTRIBUIDA PROVA 2 12/06/2017 ALUNO
 INE 5645 PROGRAMAÇÃO PARALELA E DISTRIBUIDA PROVA 2 12/06/2017 ALUNO 1. Sockets - Indicar (Verdade/Falso): (a) (Verdade/Falso) Sockets são abstrações utilizadas nos protocolos de comunicação UDP e TCP,
INE 5645 PROGRAMAÇÃO PARALELA E DISTRIBUIDA PROVA 2 12/06/2017 ALUNO 1. Sockets - Indicar (Verdade/Falso): (a) (Verdade/Falso) Sockets são abstrações utilizadas nos protocolos de comunicação UDP e TCP,
Organização de Computadores 2005/2006 Processamento Paralelo
 GoBack Organização de Computadores 2005/2006 Processamento Paralelo Paulo Ferreira paf a dei.isep.ipp.pt Maio de 2006 ORGC Processamento Paralelo slide 1 Porquê? Definição de computação paralela Alocação
GoBack Organização de Computadores 2005/2006 Processamento Paralelo Paulo Ferreira paf a dei.isep.ipp.pt Maio de 2006 ORGC Processamento Paralelo slide 1 Porquê? Definição de computação paralela Alocação
Programação Concorrente e Paralela
 2010.2 Objetivos princípios e técnicas de programação paralela multiprocessadores memória compartilhada troca de mensagens arquiteturas alternativas multicomputadores troca de mensagens obs: Essa troca
2010.2 Objetivos princípios e técnicas de programação paralela multiprocessadores memória compartilhada troca de mensagens arquiteturas alternativas multicomputadores troca de mensagens obs: Essa troca
SSC0112 Organização de Computadores Digitais I
 SSC0112 Organização de Computadores Digitais I 3ª Aula Visão Geral e Conceitos Básicos Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Copyright William Stallings & Adrian J Pullin Tradução, revisão e
SSC0112 Organização de Computadores Digitais I 3ª Aula Visão Geral e Conceitos Básicos Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Copyright William Stallings & Adrian J Pullin Tradução, revisão e
Introdução aos Sistemas Operacionais
 1 Introdução aos Sistemas Operacionais 1.1 O que é um sistema operacional 1.2 História dos sistemas operacionais 1.3 O zoológico de sistemas operacionais 1.4 Conceitos sobre sistemas operacionais 1.5 Chamadas
1 Introdução aos Sistemas Operacionais 1.1 O que é um sistema operacional 1.2 História dos sistemas operacionais 1.3 O zoológico de sistemas operacionais 1.4 Conceitos sobre sistemas operacionais 1.5 Chamadas
FUNDAMENTOS DE ARQUITETURAS DE COMPUTADORES MEMÓRIA PRINCIPAL CAPÍTULO 4. Cristina Boeres
 FUNDAMENTOS DE ARQUITETURAS DE COMPUTADORES MEMÓRIA PRINCIPAL CAPÍTULO 4 Cristina Boeres Memória! É um dos componentes de um sistema de computação! Sua função é armazenar informações que são ou serão manipuladas
FUNDAMENTOS DE ARQUITETURAS DE COMPUTADORES MEMÓRIA PRINCIPAL CAPÍTULO 4 Cristina Boeres Memória! É um dos componentes de um sistema de computação! Sua função é armazenar informações que são ou serão manipuladas
Consistência e Replicação
 Consistência e Replicação Fernando Silva DCC-FCUP Fernando Silva (DCC-FCUP) Consistência e Replicação 1 / 33 Agenda Slides baseados nos slides de Maarten van Steen e no cap. 7 do seu livro com Andrew Tanenbaum.
Consistência e Replicação Fernando Silva DCC-FCUP Fernando Silva (DCC-FCUP) Consistência e Replicação 1 / 33 Agenda Slides baseados nos slides de Maarten van Steen e no cap. 7 do seu livro com Andrew Tanenbaum.
Arquitetura de Sistemas Operativos
 Arquitetura de Sistemas Operativos Sistemas Operativos 2011/2012 1 Requisitos de uma Secção Crítica Requisitos de uma Secção Crítica Antes de analisarmos as várias soluções para assegurar que um bloco
Arquitetura de Sistemas Operativos Sistemas Operativos 2011/2012 1 Requisitos de uma Secção Crítica Requisitos de uma Secção Crítica Antes de analisarmos as várias soluções para assegurar que um bloco
UNIVERSIDADE ESTADUAL VALE DO ACARAÚ- UEVA. Assunto: Programação Concorrente.
 UNIVERSIDADE ESTADUAL VALE DO ACARAÚ- UEVA Assunto: Programação Concorrente. Alunos: Valdeclébio Farrapo Costa Paulo Roberto Gabriel Barbosa Curso: Ciência da Computação Disciplina: Linguagem de Programação
UNIVERSIDADE ESTADUAL VALE DO ACARAÚ- UEVA Assunto: Programação Concorrente. Alunos: Valdeclébio Farrapo Costa Paulo Roberto Gabriel Barbosa Curso: Ciência da Computação Disciplina: Linguagem de Programação
Programação Concorrente
 INE 5410 Programação Concorrente Professor: Lau Cheuk Lung (turma A) INE UFSC lau.lung@inf.ufsc.br Conteúdo Programático 1. 2. Programação Concorrente 3. Sincronização 1. Condição de corrida, região critica
INE 5410 Programação Concorrente Professor: Lau Cheuk Lung (turma A) INE UFSC lau.lung@inf.ufsc.br Conteúdo Programático 1. 2. Programação Concorrente 3. Sincronização 1. Condição de corrida, região critica
Agenda. O que é OpenMP? Regiões Paralelas Construtores para Compartilhamento de
 Programando OpenMP Agenda O que é OpenMP? Regiões Paralelas Construtores para Compartilhamento de Trabalho Montando um escopo de dados para proteger de condições de corrida Cláusulas de agendamento O que
Programando OpenMP Agenda O que é OpenMP? Regiões Paralelas Construtores para Compartilhamento de Trabalho Montando um escopo de dados para proteger de condições de corrida Cláusulas de agendamento O que
Fundamentos de Sistemas Operacionais
 Fundamentos de Sistemas Operacionais Aula 5: Exclusão Mútua Diego Passos Última Aula Programação Concorrente Programas compostos por mais de um processo ou thread. Pode trazer benefícios: Simplificar o
Fundamentos de Sistemas Operacionais Aula 5: Exclusão Mútua Diego Passos Última Aula Programação Concorrente Programas compostos por mais de um processo ou thread. Pode trazer benefícios: Simplificar o
1. A pastilha do processador Intel possui uma memória cache única para dados e instruções. Esse processador tem capacidade de 8 Kbytes e é
 1. A pastilha do processador Intel 80486 possui uma memória cache única para dados e instruções. Esse processador tem capacidade de 8 Kbytes e é organizado com mapeamento associativo por conjuntos de quatro
1. A pastilha do processador Intel 80486 possui uma memória cache única para dados e instruções. Esse processador tem capacidade de 8 Kbytes e é organizado com mapeamento associativo por conjuntos de quatro
Paralelismo em Computadores com Tecnologia Multicore
 IFRN - Pau dos Ferros Pau dos Ferros/RN, 25 de fevereiro de 2016 O minicurso Descrição: Para se utilizar os vários núcleos de processamento disponíveis nos computadores atuais de forma eficiente, faz necessário
IFRN - Pau dos Ferros Pau dos Ferros/RN, 25 de fevereiro de 2016 O minicurso Descrição: Para se utilizar os vários núcleos de processamento disponíveis nos computadores atuais de forma eficiente, faz necessário
INTRODUÇÃO À TECNOLOGIA DA INFORMAÇÃO ORGANIZAÇÃO COMPUTACIONAL
 INTRODUÇÃO À TECNOLOGIA DA ORGANIZAÇÃO COMPUTACIONAL PROFESSOR CARLOS MUNIZ ORGANIZAÇÃO DE UM COMPUTADOR TÍPICO Memória: Armazena dados e programas Processador (CPU - Central Processing Unit): Executa
INTRODUÇÃO À TECNOLOGIA DA ORGANIZAÇÃO COMPUTACIONAL PROFESSOR CARLOS MUNIZ ORGANIZAÇÃO DE UM COMPUTADOR TÍPICO Memória: Armazena dados e programas Processador (CPU - Central Processing Unit): Executa
Sistemas Distribuídos. Capítulo 7 - Aula 16
 Sistemas Distribuídos Aula Passada Capítulo 7 - Aula 16 Comunicação Confiável de Grupo Multicast Atômico Sincronia Virtual Ordenação de Mensagens Recuperação Aula de hoje Modelos de Consistência Protocolos
Sistemas Distribuídos Aula Passada Capítulo 7 - Aula 16 Comunicação Confiável de Grupo Multicast Atômico Sincronia Virtual Ordenação de Mensagens Recuperação Aula de hoje Modelos de Consistência Protocolos
SSC0611 Arquitetura de Computadores
 SSC0611 Arquitetura de Computadores 10ª Aula Pipeline Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Dependências ou Conflitos (Hazards) Conflitos Estruturais Pode haver acessos simultâneos à memória
SSC0611 Arquitetura de Computadores 10ª Aula Pipeline Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Dependências ou Conflitos (Hazards) Conflitos Estruturais Pode haver acessos simultâneos à memória
Modelo de Programação Paralela
 Modelo de Programação Paralela As arquiteturas paralelas e distribuídas possuem muitos detalhes Como especificar uma solução paralela pensando em todos esses detalhes? O que queremos? Eecutar a solução
Modelo de Programação Paralela As arquiteturas paralelas e distribuídas possuem muitos detalhes Como especificar uma solução paralela pensando em todos esses detalhes? O que queremos? Eecutar a solução
AULA DE REVISÃO 3 ILP
 AULA DE REVISÃO 3 ILP Exercício 1: Considere um bloco de código com 15 instruções cada uma com tempo de execução Tex. Elas são executadas numa unidade pipeline de 5 estágios. Os overheads do pipeline são
AULA DE REVISÃO 3 ILP Exercício 1: Considere um bloco de código com 15 instruções cada uma com tempo de execução Tex. Elas são executadas numa unidade pipeline de 5 estágios. Os overheads do pipeline são
Arquitetura de Computadores
 Arquitetura de Computadores 2018.1 Relembrando... Memória Virtual Relembrando... Memória Virtual Proteção de Memória Relembrando... Memória Virtual Proteção de Memória TLB Relembrando... Memória Virtual
Arquitetura de Computadores 2018.1 Relembrando... Memória Virtual Relembrando... Memória Virtual Proteção de Memória Relembrando... Memória Virtual Proteção de Memória TLB Relembrando... Memória Virtual
Paradigmas de Computação Paralela
 Paradigmas de Computação Paralela Modelos e Linguagens de Computação Paralela João Luís Ferreira Sobral jls@... 1 Dezembro 2015 Razões para a computação paralela (cf. Skillicorn & Talia 1998) O mundo é
Paradigmas de Computação Paralela Modelos e Linguagens de Computação Paralela João Luís Ferreira Sobral jls@... 1 Dezembro 2015 Razões para a computação paralela (cf. Skillicorn & Talia 1998) O mundo é
Universidade Federal de Campina Grande Unidade Acadêmica de Sistemas e Computação Curso de Bacharelado em Ciência da Computação.
 Universidade Federal de Campina Grande Unidade Acadêmica de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de Computadores I Organização e Arquitetura Básicas
Universidade Federal de Campina Grande Unidade Acadêmica de Sistemas e Computação Curso de Bacharelado em Ciência da Computação Organização e Arquitetura de Computadores I Organização e Arquitetura Básicas
Multiprogramação leve em arquiteturas multi-core
 Multiprogramação leve em arquiteturas multi-core Prof. Dr. Departamento de Informática Universidade Federal de Pelotas Sumário Arquiteturas multi-core Programação multithread Ferramentas de programação
Multiprogramação leve em arquiteturas multi-core Prof. Dr. Departamento de Informática Universidade Federal de Pelotas Sumário Arquiteturas multi-core Programação multithread Ferramentas de programação
Memória Compartilhada e Distribuída. _ Notas de Aula _ Prof. Tiago Garcia de Senna Carneiro DECOM/UFOP
 Introdução Memória Compartilhada e Distribuída _ Notas de Aula _ Prof. Tiago Garcia de Senna Carneiro DECOM/UFOP Um sistema de memória compartilhada faz a memória física global de um sistema igualmente
Introdução Memória Compartilhada e Distribuída _ Notas de Aula _ Prof. Tiago Garcia de Senna Carneiro DECOM/UFOP Um sistema de memória compartilhada faz a memória física global de um sistema igualmente
SSC-0742 PROGRAMAÇÃO CONCORRENTE. Aula 04 Revisão de Arquiteturas Paralelas -Parte 2 Prof. Jó Ueyama e Julio Cezar Estrella
 SSC-0742 PROGRAMAÇÃO CONCORRENTE Aula 04 Revisão de Arquiteturas Paralelas -Parte 2 Prof. Jó Ueyama e Julio Cezar Estrella Créditos Os slides integrantes deste material foram construídos a partr dos conteúdos
SSC-0742 PROGRAMAÇÃO CONCORRENTE Aula 04 Revisão de Arquiteturas Paralelas -Parte 2 Prof. Jó Ueyama e Julio Cezar Estrella Créditos Os slides integrantes deste material foram construídos a partr dos conteúdos
Memória Cache. Adriano J. Holanda. 12 e 16/5/2017
 Memória Cache Adriano J Holanda 12 e 16/5/2017 Memória: princípios físicos Revisão: Hierarquia de memória; Memória RAM: estática, dinâmica; Memória ROM: PROM, EPROM, EEPROM; Memória flash Memória: fundamentos
Memória Cache Adriano J Holanda 12 e 16/5/2017 Memória: princípios físicos Revisão: Hierarquia de memória; Memória RAM: estática, dinâmica; Memória ROM: PROM, EPROM, EEPROM; Memória flash Memória: fundamentos
Prof. Rômulo Calado Pantaleão Camara Carga Horária: 2h/60h
 Pipelining Avançado Prof. Rômulo Calado Pantaleão Camara Carga Horária: 2h/60h Introdução A técnica de pipelining explora o paralelismo entre as instruções Paralelismo em Nível de Instrução (ILP). Métodos
Pipelining Avançado Prof. Rômulo Calado Pantaleão Camara Carga Horária: 2h/60h Introdução A técnica de pipelining explora o paralelismo entre as instruções Paralelismo em Nível de Instrução (ILP). Métodos
Infraestrutura de Hardware. Implementação Monociclo de um Processador Simples
 Infraestrutura de Hardware Implementação Monociclo de um Processador Simples Componentes de um Computador Unid. Controle Controle Memória Registradores PC MAR IR AC Programa + Dados Instrução Endereço
Infraestrutura de Hardware Implementação Monociclo de um Processador Simples Componentes de um Computador Unid. Controle Controle Memória Registradores PC MAR IR AC Programa + Dados Instrução Endereço
Classes e Objetos. Sintaxe de classe em Java
 Classes e Objetos Classes e Objetos A Programação Orientada a Objetos (POO) é uma técnica de programação que se baseia na construção de classes e utilização de objetos. Os objetos são formados por dados
Classes e Objetos Classes e Objetos A Programação Orientada a Objetos (POO) é uma técnica de programação que se baseia na construção de classes e utilização de objetos. Os objetos são formados por dados
SSC0510 Arquitetura de Computadores
 SSC0510 Arquitetura de Computadores 9ª Aula Pipeline Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Dependências ou Conflitos (Hazards) Conflitos Estruturais Pode haver acessos simultâneos à memória
SSC0510 Arquitetura de Computadores 9ª Aula Pipeline Profa. Sarita Mazzini Bruschi sarita@icmc.usp.br Dependências ou Conflitos (Hazards) Conflitos Estruturais Pode haver acessos simultâneos à memória
Organização Básica de Computadores. Organização Básica de Computadores. Organização Básica de Computadores. Organização Básica de Computadores
 Ciência da Computação Arq. e Org. de Computadores Processadores Prof. Sergio Ribeiro Composição básica de um computador eletrônico digital: Processador Memória Memória Principal Memória Secundária Dispositivos
Ciência da Computação Arq. e Org. de Computadores Processadores Prof. Sergio Ribeiro Composição básica de um computador eletrônico digital: Processador Memória Memória Principal Memória Secundária Dispositivos
Algoritmos Computacionais
 UNIDADE 1 Processador e instruções Memórias Dispositivos de Entrada e Saída Software ARQUITETURA BÁSICA UCP Unidade central de processamento MEM Memória E/S Dispositivos de entrada e saída UCP UNIDADE
UNIDADE 1 Processador e instruções Memórias Dispositivos de Entrada e Saída Software ARQUITETURA BÁSICA UCP Unidade central de processamento MEM Memória E/S Dispositivos de entrada e saída UCP UNIDADE
AULA 03: PROCESSAMENTO PARALELO: MULTIPROCESSADORES
 ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 03: PROCESSAMENTO PARALELO: MULTIPROCESSADORES Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação MULTIPROCESSADORES
ORGANIZAÇÃO E ARQUITETURA DE COMPUTADORES II AULA 03: PROCESSAMENTO PARALELO: MULTIPROCESSADORES Prof. Max Santana Rolemberg Farias max.santana@univasf.edu.br Colegiado de Engenharia de Computação MULTIPROCESSADORES
Comunicação entre Processos
 Programação Paralela e Distribuída Ordenação e Sincronização Prof. Msc. Marcelo Iury de Sousa Oliveira marceloiury@gmail.com http://sites.google.com/site/marceloiury/ Comunicação entre Processos Processos
Programação Paralela e Distribuída Ordenação e Sincronização Prof. Msc. Marcelo Iury de Sousa Oliveira marceloiury@gmail.com http://sites.google.com/site/marceloiury/ Comunicação entre Processos Processos
UNIDADE CENTRAL DE PROCESSAMENTO FELIPE G. TORRES
 Tecnologia da informação e comunicação UNIDADE CENTRAL DE PROCESSAMENTO FELIPE G. TORRES CICLO DE INSTRUÇÕES OU DE EXECUÇÃO Arquitetura de computadores 2 CICLO DE EXECUÇÃO No inicio de cada ciclo de instrução,
Tecnologia da informação e comunicação UNIDADE CENTRAL DE PROCESSAMENTO FELIPE G. TORRES CICLO DE INSTRUÇÕES OU DE EXECUÇÃO Arquitetura de computadores 2 CICLO DE EXECUÇÃO No inicio de cada ciclo de instrução,
Carlos Eduardo Batista Centro de Informática - UFPB
 Carlos Eduardo Batista Centro de Informática - UFPB bidu@ci.ufpb.br Motivação Arquitetura de computadores modernos Desafios da programação concorrente Definição de concorrência Correr junto Disputa por
Carlos Eduardo Batista Centro de Informática - UFPB bidu@ci.ufpb.br Motivação Arquitetura de computadores modernos Desafios da programação concorrente Definição de concorrência Correr junto Disputa por
Memória Compatilhada Distribuída. Bruno M. Carvalho Sala: 3F2 Horário: 35M34
 Memória Compatilhada Distribuída Bruno M. Carvalho Sala: 3F2 Horário: 35M34 Introdução Como compartilhar informações entre processadores? Mensagens em multicomputadores Memória compartilhada em multiprocessadores
Memória Compatilhada Distribuída Bruno M. Carvalho Sala: 3F2 Horário: 35M34 Introdução Como compartilhar informações entre processadores? Mensagens em multicomputadores Memória compartilhada em multiprocessadores
Sistemas Distribuídos Aula 3
 Sistemas Distribuídos Aula 3 Aula passada Processos IPC Características Ex. sinais, pipes, sockets Aula de hoje Threads Kernel level User level Escalonamento Motivação: Servidor Web Considere Servidor
Sistemas Distribuídos Aula 3 Aula passada Processos IPC Características Ex. sinais, pipes, sockets Aula de hoje Threads Kernel level User level Escalonamento Motivação: Servidor Web Considere Servidor
Disciplina: Arquitetura de Computadores
 Disciplina: Arquitetura de Computadores Estrutura e Funcionamento da CPU Prof a. Carla Katarina de Monteiro Marques UERN Introdução Responsável por: Processamento e execução de programas armazenados na
Disciplina: Arquitetura de Computadores Estrutura e Funcionamento da CPU Prof a. Carla Katarina de Monteiro Marques UERN Introdução Responsável por: Processamento e execução de programas armazenados na
Consistência e Replicação
 Consistência e Replicação - Razões para a replicação - Replicação para obter escalabilidade - Modelos de consistência centrados nos dados 1 Razões para a replicação Fiabilidade - Enquanto pelo menos um
Consistência e Replicação - Razões para a replicação - Replicação para obter escalabilidade - Modelos de consistência centrados nos dados 1 Razões para a replicação Fiabilidade - Enquanto pelo menos um
Sistemas de Tempo-Real. Acesso exclusivo a recursos partilhados
 Sistemas de Tempo-Real Aula 7 Acesso exclusivo a recursos partilhados O acesso exclusivo a recursos partilhados A inversão de prioridades como consequência do bloqueio Técnicas básicas para acesso exclusivo
Sistemas de Tempo-Real Aula 7 Acesso exclusivo a recursos partilhados O acesso exclusivo a recursos partilhados A inversão de prioridades como consequência do bloqueio Técnicas básicas para acesso exclusivo
Resumão de Infra-estrutura de Hardware
 Resumão de Infra-estrutura de Hardware Referência: Patterson & Hennessy - Organização e Projeto de Computadores Vanessa Gomes de Lima vgl2@cin.ufpe.br 1 MELHORANDO O DESEMPENHO COM PIPELINING Pipelining
Resumão de Infra-estrutura de Hardware Referência: Patterson & Hennessy - Organização e Projeto de Computadores Vanessa Gomes de Lima vgl2@cin.ufpe.br 1 MELHORANDO O DESEMPENHO COM PIPELINING Pipelining
COMPUTADORES. Arquiteturas de Computadores Paralelos. Prof.: Agostinho S. Riofrio
 PROJETO LÓGICO DE COMPUTADORES Arquiteturas de Computadores Paralelos l Prof.: Agostinho S. Riofrio Agenda 1. Introdução 2. Memória Virtual 3. Paginação 4. Segmentação 5. Instruçoes virtuais de E/S 6.
PROJETO LÓGICO DE COMPUTADORES Arquiteturas de Computadores Paralelos l Prof.: Agostinho S. Riofrio Agenda 1. Introdução 2. Memória Virtual 3. Paginação 4. Segmentação 5. Instruçoes virtuais de E/S 6.
Capítulo 11 Sistemas de Arquivos
 Sistemas Operacionais Prof. Esp. André Luís Belini Bacharel em Sistemas de Informações MBA em Gestão Estratégica de Negócios Capítulo Sistemas de s Introdução O armazenamento e a recuperação de informações
Sistemas Operacionais Prof. Esp. André Luís Belini Bacharel em Sistemas de Informações MBA em Gestão Estratégica de Negócios Capítulo Sistemas de s Introdução O armazenamento e a recuperação de informações
Sistemas de Ficheiros Distribuídos. Pedro Ferreira DI - FCUL
 Sistemas de Ficheiros Distribuídos Pedro Ferreira DI - FCUL Serviços do Sistema de Ficheiros Revisão de alguns aspectos do serviço de ficheiros O que é um ficheiro? uma sequência não interpretada de bytes
Sistemas de Ficheiros Distribuídos Pedro Ferreira DI - FCUL Serviços do Sistema de Ficheiros Revisão de alguns aspectos do serviço de ficheiros O que é um ficheiro? uma sequência não interpretada de bytes
INE 5645 PROGRAMAÇÃO PARALELA E DISTRIBUIDA PROVA 2 12/06/2017. ALUNO Prof. Bosco
 INE 5645 PROGRAMAÇÃO PARALELA E DISTRIBUIDA PROVA 2 12/06/2017 ALUNO Prof. Bosco 1. Sockets - Indicar (Verdade/Falso): (a) (Verdade/Falso) Sockets são abstrações utilizadas nos protocolos de comunicação
INE 5645 PROGRAMAÇÃO PARALELA E DISTRIBUIDA PROVA 2 12/06/2017 ALUNO Prof. Bosco 1. Sockets - Indicar (Verdade/Falso): (a) (Verdade/Falso) Sockets são abstrações utilizadas nos protocolos de comunicação
Sistemas Distribuídos
 Sistemas Distribuídos Transações atômicas Conteúdo O modelo transacional Armazenamento estável Primitivas transacionais Propriedades das transações Transações aninhadas Implementação Área de trabalho privada
Sistemas Distribuídos Transações atômicas Conteúdo O modelo transacional Armazenamento estável Primitivas transacionais Propriedades das transações Transações aninhadas Implementação Área de trabalho privada
Definindo melhor alguns conceitos
 Definindo melhor alguns conceitos Concorrência termo mais geral, um programa pode ser constituído por mais de um thread/processo concorrendo por recursos Paralelismo uma aplicação é eecutada por um conjunto
Definindo melhor alguns conceitos Concorrência termo mais geral, um programa pode ser constituído por mais de um thread/processo concorrendo por recursos Paralelismo uma aplicação é eecutada por um conjunto